Возможно, вы что-то уже знаете про open source библиотеку Celesta. Если нет — не беда, сейчас всё расскажем. Прошёл ещё один год, вышла версия 7.x, много чего изменилось, и настала пора изменения подытожить, а заодно и напомнить о том, что такое Celesta вообще.

Если вы ещё ничего не слышали про Celesta, и в процессе чтения этой статьи захотите знать, для каких бизнес-задач её применение наиболее эффективно, то я могу рекомендовать первую часть старого поста или это получасовое видео (кроме слов про использование языка Python). Но лучше всё-таки сначала почитайте эту статью. Я начну с изменений, которые произошли в 7-й версии, а затем разберу полный технический пример использования современной версии Celesta для написания небольшого backend-сервиса для приложения на Java с использованием Spring Boot.
Что изменилось в версии 7.x?
- Мы отказались от использования Jython как встроенного в Celesta языка. Если раньше мы начинали разговор о Celesta с того, что бизнес-логика пишется на Питоне, то теперь… языком бизнес-логики может служить любой Java-язык: Java, Groovy, JRuby или тот же Jython. Теперь не Celesta вызывает код бизнес-логики, а код бизнес-логики использует Celesta и её классы доступа к данным как самую обычную Java-библиотеку. Да, из-за этого нарушилась обратная совместимость, но это цена, которую мы были готовы заплатить. К сожалению, наша ставка на Jython проиграла. Когда несколько лет назад мы начинали использовать Jython, это был живой и перспективный проект, но с годами его развитие замедлилось, отставание от спецификации языка накопилось, проблемы с совместимостью большинства pip-библиотек не решились. Последней каплей стали новые баги в свежих релизах языка, проявившиеся при работе на production-нагрузке. Ресурсов самим поддерживать проект Jython у нас нет, и мы решили с ним расстаться. Celesta больше не зависит от Jython.
- Классы доступа к данным теперь кодогенерируются на языке Java (а не Python, как раньше) с помощью Maven-плагина. И так как из-за этого мы перешли от динамической типизации к статической, то появилось больше возможностей для рефакторинга и субъективно корректный код писать стало легче.
- Появился Extension для JUnit5, так что тесты логики, работающей с базой данных, стало очень удобно писать на JUnit5 (о чём здесь ещё будет рассказано).
- Появился отдельный проект — spring-boot-starter-celesta, который, как следует из названия, является стартером Celesta в Spring Boot. Возможность упаковывать Celesta-приложения в легко разворачиваемые сервисы Spring Boot компенсировала утрату возможности обновлять приложение на сервере путём простой подмены папки с Python-скриптами.
- Мы перевели всю документацию с Wiki на формат AsciiDoctor, поместили её в контроль версий вместе с кодом и теперь у нас имеется актуальная документация на каждый релиз Celesta. К самому свежему релизу документация в онлайне доступна здесь: https://courseorchestra.github.io/celesta/ru
- Нас часто спрашивали, можно ли использовать миграцию базы данных через идемпотентный DDL отдельно от Celesta. Теперь такая возможность есть с помощью инструмента 2bass.
Что такое Сelesta и что она умеет?
В двух словах, Celesta это:
- промежуточный слой между реляционной базой и кодом бизнес-логики, опирающийся на database-first подход к проектированию,
- механизм миграции структуры БД,
- фреймворк для тестирования кода, работающего с данными.
Мы поддерживаем четыре типа реляционных БД: PostgreSQL, MS SQL Server, Oracle и H2.
Основные функциональные возможности Celesta:
- Принцип, очень похожий на основной принцип Java: «Write once, run on every supported RDBMS». Код бизнес-логики не знает, на каком типе базы данных он будет исполняться. Вы можете написать код бизнес-логики и запускать его в MS SQL Server, потом перейти на PostgreSQL, и это произойдет без осложнений (ну, почти :)
- Автоматическое изменение структуры на «живой» базе данных. Большая часть жизненного цикла Celesta-проектов происходит, когда рабочая база данных уже есть и она наполняется данными, которые нужно сохранять, но также при этом необходимо постоянно менять их структуру. Одна из ключевых возможностей Celesta — способность самостоятельно автоматически «подгонять» структуру БД под вашу модель данных.
- Тестирование. Большое внимание уделено тому, чтобы код для Celesta был тестируемым, чтобы мы могли автоматически тестировать методы, изменяющие данные в базе, делая это легко, быстро и изящно, без использования внешних инструментов типа DbUnit и контейнеров.
Для чего нужна независимость от типа СУБД?
Независимость кода бизнес-логики от типа СУБД мы поставили первым пунктом не случайно: код, написанный для Celesta, вообще не знает, на какой СУБД он исполняется. Зачем?
Во-первых, из-за того, что выбор типа СУБД – это вопрос не технологический, а политический. Приходя к новому бизнес-заказчику, мы часто обнаруживаем, что у него уже есть любимый тип СУБД, в который инвестированы средства, и заказчик хочет видеть и другие решения на существующей инфраструктуре. Технологический ландшафт меняется: в госструктурах и частных компаниях все больше встречается PostgreSQL, хотя ещё несколько лет назад в нашей практике превалировал MS SQL Server. Celesta поддерживает наиболее часто встречающиеся СУБД, и нас эти изменения не тревожат.
Во-вторых, код, уже созданный для решения стандартных задач, хотелось бы переносить от одного проекта к другому, создавать переиспользуемую библиотеку. Вещи вроде иерархических справочников или модулей рассылки уведомлений на email по сути своей стандартны, и зачем нам поддерживать несколько версий под заказчиков с разными реляционками?
В-третьих — последнее по порядку, но не важности — возможность запуска модульных тестов без использования DbUnit и контейнеров с использованием базы данных H2, работающей в режиме in-memory. В этом режиме база H2 запускается моментально. Celesta очень быстро создаёт в ней схему данных, после чего можно провести необходимые тесты и «забыть» базу. Так как код бизнес-логики действительно не знает, на какой базе он выполняется, то соответственно, если он без ошибок отрабатывает на H2, то без ошибок он будет работать и на PostgreSQL. Конечно, в задачу разработчиков самой системы Celesta входит сделать все тесты с задействованием реальных СУБД, чтобы убедиться, что наша платформа одинаково выполняет свой API на разных реляционках. И мы это делаем. Но разработчику бизнес-логики это уже не требуется.
CelestaSQL
За счёт чего достигается «кроссбазданческость»? Конечно, ценой того, что с данными можно работать только через специальный API, изолирующий логику от любой специфики БД. Celesta кодогенирирует Java-классы для доступа к данным, с одной стороны, и SQL-код и некоторые вспомогательные объекты внутри базы данных, с другой стороны.
Celesta не предоставляет object-relational mapping в чистом виде, потому что при проектировании модели данных мы исходим не от классов, а от структуры базы данных. Т. е. сначала выстраиваем ER-модель таблиц, а затем на основе этой модели Celesta сама генерирует классы-курсоры для доступа к данным.
Достигнуть одинаковой работы на всех поддерживаемых СУБД можно только лишь для той функциональности, которая приблизительно одинаково реализована в каждой из них. Если условно в виде «кругов Эйлера» изобразить множества функциональных возможностей каждой из поддерживаемых нами баз, то получается такая картина:
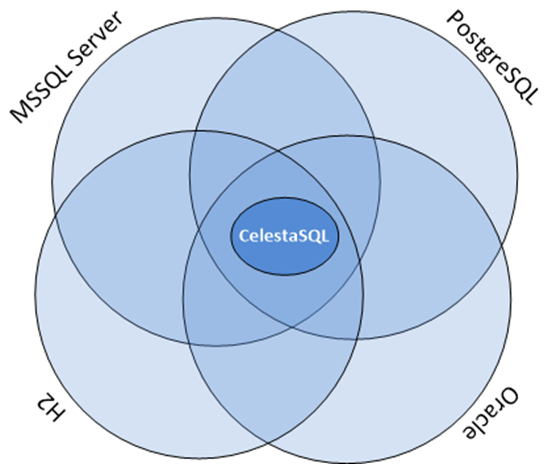
Если мы обеспечиваем полную независимость от типа БД, то те функциональные возможности, которые мы открываем программистам бизнес-логики, должны лежать внутри пересечения по всем базам. На первый взгляд кажется, что это существенное ограничение. Да: какие-то специфические возможности, допустим, SQL Server мы не можем использовать. Но все без исключения реляционные базы поддерживают таблицы, внешние ключи, представления (views), последовательности (sequences), SQL-запросы с JOIN и GROUP BY. Соответственно, мы можем дать эти возможности разработчикам. Мы предоставляем разработчикам «обезличенный SQL», который называем «CelestaSQL», а в процессе работы мы генерируем SQL-запросы для диалектов соответствующих баз.
Язык CelestaSQL включает в себя DDL для определения объектов базы данных и SELECT-запросы для представлений и фильтров, но не содержит команд DML: для модификации данных применяются курсоры, о которых речь ещё впереди.
У каждой базы данных есть свой набор типов данных. В языке CelestaSQL тоже есть свой набор типов. На момент написания статьи их девять, и в этой таблице дано их сопоставление с реальными типами в различных базах данных и типами данных Java.
Может показаться, что девять типов — это мало (по сравнению с тем, что поддерживает, например, PostgreSQL), но на самом деле это те самые типы, которых достаточно, чтобы хранить финансовую, торговую, логистическую информацию: строк, целых чисел, дробных, дат, boolean-значений и BLOB-ов всегда хватит для представления таких данных.
Сам язык CelestaSQL описан в документации с большим количеством синтаксических диаграмм.
Модификация структуры базы данных. Идемпотентный DDL
Еще одна ключевая функциональная возможность Celesta – это подход к миграции структуры рабочей базы данных по мере развития проекта. Для этого применяется встроенный в Celesta подход с использованием идемпотентного DDL.
В двух словах, когда мы пишем на CelestaSQL следующий текст:
CREATE TABLE OrderLine( order_id VARCHAR(30) NOT NULL, line_no INT NOT NULL, item_id VARCHAR(30) NOT NULL, item_name VARCHAR(100), qty INT NOT NULL DEFAULT 0, cost REAL NOT NULL DEFAULT 0.0, CONSTRAINT Idx_OrderLine PRIMARY KEY (order_id, line_no) );
— этот текст интерпретируется Celesta не как «создай таблицу, а если таблица уже есть, то выдай ошибку», а «приведи таблицу к желаемой структуре». То есть: «если таблицы нет — создай, если таблица есть, посмотри, какие в ней поля, с какими типами, какие индексы, какие внешние ключи, какие default-значения и т. п. и не надо ли что-то изменить в этой таблице, чтобы привести её к нужному виду».
При таком подходе мы реализуем возможность рефакторинга и контроля версий на скриптах определения структуры базы:
- мы видим в скрипте текущий «желаемый образ» структуры,
- что, кем и почему в структуре изменялось со временем, мы можем посмотреть с помощью системы контроля версий,
- что до ALTER-команд, то их автоматически, «под капотом» формирует и выполняет Celesta по мере необходимости.
Разумеется, у этого подхода есть свои ограничения. Celesta прикладывает максимальные усилия, чтобы автоматическая миграция прошла безболезненно и незаметно, но это возможно не во всех случаях. Мотивацию, возможности и ограничения такого подхода мы изложили в этом посте (доступна также его англоязычная версия).
Для того, чтобы ускорить процесс проверки / обновления структуры базы данных, Celesta применяет сохранение в базе данных контрольных сумм DDL-скриптов (пока контрольная сумма не изменяется, процесс сверки и обновления структуры БД не стартует). Чтобы процесс обновления проходил без проблем, связанных с порядком изменения зависимых друг от друга объектов, применяется топологическая сортировка зависимостей между схемами по внешним ключам. Более подробно процесс автоматической миграции описан в документации.
Создание проекта Celesta и модели данных
Демо-проект, который мы будем рассматривать, доступен на гитхабе. Давайте посмотрим, как можно задействовать Celesta при написании Spring Boot приложения. Вот какие понадобятся Maven-зависимости:
org.springframework.boot:spring-boot-starter-webиru.curs:spring-boot-starter-celesta(подробности на этот счёт даны в документации).- Если вы не используете Spring Boot, то можете подключать зависимость
ru.curs:celesta-system-servicesнапрямую. - Для кодогенерации классов доступа к данным на основе Celesta-SQL скриптов нужен
ru.curs:celesta-maven-plugin— в исходниках демо-примера или документации описано, как его подключать. - Чтобы воспользоваться возможностью писать JUnit5 модульные тесты на методы, модифицирующие данные, необходимо в тестовом scope подключить
ru.curs:celesta-unit.
Создадим теперь модель данных и скомпилируем классы доступа к данным.
Допустим, мы делаем проект для компании интернет-торговли, которая недавно объединилась с другой компанией. У каждой есть своя база данных. Они собирают заказы, но пока они не слили свои базы данных воедино, нужна единая точка входа для того, чтобы собирать заказы, поступающие извне.
Реализация этой «точки входа» должна быть вполне традиционной: HTTP-сервис с CRUD-операциями, сохраняющими данные в реляционную БД.
В силу того, что Celesta реализует Database-first подход к проектированию, для начала нам надо создать структуру таблиц, хранящих заказы. Заказ, как известно, сущность составная: он состоит из заголовка, где хранится информация о клиенте, дате заказа и прочих атрибутов заказа, а также из множества строк (товарных позиций).
Итак, за дело: создаём
- папку
src/main/celestasql— по умолчанию, это путь к CelestaSQL скриптам проекта - в ней подпапки, повторяющие структуру папок java-пакетов (
ru/curs/demoв нашем случае). - в папке пакета создаём
.sqlфайл следующего содержания:
CREATE SCHEMA demo VERSION '1.0'; /**Заголовок счёта*/ CREATE TABLE OrderHeader( id VARCHAR(30) NOT NULL, date DATETIME, customer_id VARCHAR(30), /**Название клиента */ customer_name VARCHAR(50), manager_id VARCHAR(30), CONSTRAINT Pk_OrderHeader PRIMARY KEY (id) ); /**Строка счёта*/ CREATE TABLE OrderLine( order_id VARCHAR(30) NOT NULL, line_no INT NOT NULL, item_id VARCHAR(30) NOT NULL, item_name VARCHAR(100), qty INT NOT NULL DEFAULT 0, cost REAL NOT NULL DEFAULT 0.0, CONSTRAINT Idx_OrderLine PRIMARY KEY (order_id, line_no) ); ALTER TABLE OrderLine ADD CONSTRAINT fk_OrderLine FOREIGN KEY (order_id) REFERENCES OrderHeader(id); CREATE VIEW OrderedQty AS SELECT item_id, sum(qty) AS qty FROM OrderLine GROUP BY item_id;
Здесь мы описали две таблицы, соединённые внешним ключом, и одно представление, которое будет возвращать сводное количество по товарам, присутствующим во всех заказах. Как видим, это не отличается от обычного SQL, за исключением команды CREATE SCHEMA, в которой мы задекларировали версию схемы demo (про то, как номер версии влияет на автоматическую миграцию, см. в документации). Но есть и особенности. Например, все имена таблиц и полей, которые мы используем, могут быть только такими, чтобы их можно было превратить в допустимые в языке Java имена классов и переменных. Поэтому пробелы, спецсимволы исключены. Ещё можно заметить, что комментарии, которые мы поставили над названиями таблиц и некоторых из полей, мы начали не с /*, как обычно, а с /**, как начинаются комментарии JavaDoc — и это неспроста! Комментарий, определённый над некоторой сущностью, начинающийся с /**, будет доступен во время исполнения в свойстве .getCelestaDoc() данной сущности. Это бывает полезно, когда мы хотим снабдить элементы базы дополнительной мета-информацией: например, human readable названиями полей, информацией о том, как представлять поля в пользовательском интерфейсе и т. п.
CelestaSQL скрипт служит двум одинаково важным задачам: во-первых, для разворачивания / модификации структуры реляционной БД, и во-вторых, для кодогенерации классов доступа к данным.
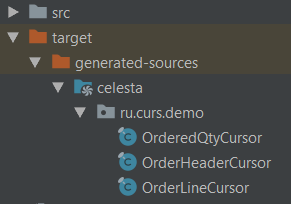
Сгенерировать классы доступа к данным мы можем уже сейчас, для этого достаточно выполнить команду mvn generate-sources или, если вы работаете в IDEA, нажать на кнопку 'Generate sources and update folders' в панели управления Maven. Во втором случае IDEA «подхватит» созданную в target/generated-sources/celesta папку и сделает её содержимое доступным для импорта в исходных кодах проекта. Результат кодогенерации будет выглядеть следующим образом — по одному классу на каждый объект в базе данных:
Подключение к базе данных прописывается в настройках приложения, в нашем случае — в файле src/main/resources/application.yml. При использовании spring-boot-starter-celesta, IDEA подскажет вам в code completion доступные варианты настроек.
Если мы не хотим для целей демонстрации заморачиваться с разворачиванием «настоящей» РСУБД, мы можем заставить Celesta работать со встроенной базой данных H2 в in-memory режиме с помощью следующей конфигурации:
celesta: h2: inMemory: true
Для подключения «настоящей» БД поменяйте конфигурацию на что-нибудь типа
celesta: jdbc: url: jdbc:postgresql://127.0.0.1:5432/celesta username: <your_username> password: <your_password>
(в этом случае вам также необходимо будет через Maven-зависимость добавить в ваше приложение PostgreSQL JDBC-драйвер).
При запуске Celesta-приложения с подключением к серверу базы данных, можно наблюдать, что необходимые таблицы, представления, индексы и т. п. для пустой базы данных создаются, а для непустой — обновляются до заданных в DDL структур.
Создание методов, работающих с данными
Разобравшись с созданием структуры базы данных, можно приступать к написанию бизнес-логики.
Для того, чтобы можно было реализовать требования распределения прав доступа и логирования действий, любая операция над данными в Celesta производится от имени некоторого пользователя, «анонимных» операций не существует. Поэтому любой Celesta-код выполняется в контексте вызова, описываемом в классе CallContext.
- Перед началом операции, которая может изменять данные в базе,
CallContextактивируется. - В момент активации из пула соединений берётся соединение с базой данных и начинается транзакция.
- После окончания операции на
CallContext-е выполняется либоcommit(), если операция прошла успешно, либоrollback(), если в процессе выполнения произошло необработанное исключение,CallContextзакрывается и соединение с базой данных возвращается в пул.
Если мы используем spring-boot-starter-celesta, то эти действия выполняются автоматически для всех методов, аннотированных @CelestaTransaction.
Допустим, мы хотим написать хендлер, сохраняющий документ в базу. Его код на уровне контроллера может выглядеть следующим образом:
@RestController @RequestMapping("/api") public class DocumentController { private final DocumentService srv; public DocumentController(DocumentService srv) { this.srv = srv; } @PutMapping("/save") public void saveOrder(@RequestBody OrderDto order) { CallContext ctx = new CallContext("user1"); //new SystemCallContext(); srv.postOrder(ctx, order); }
Как правило, на уровне метода контроллера (т. е. когда аутентификация уже пройдена) мы знаем идентификатор пользователя и можем его использовать при создании CallContext. Привязка пользователя к контексту определяет разрешения на доступ к таблицам, а также обеспечивает возможность логирования изменений, производимых от его имени. Правда, в данном случае для работоспособности кода, взаимодействующего с базой данных, в системных таблицах должны быть указаны права на пользователя "user1". Если же вы не желаете пользоваться системой распределения прав доступа Celesta и дать контексту сессии все права на любые таблицы, то можно создать объект SystemCallContext.
Метод сохранения инвойса на уровне сервиса может выглядеть так:
@Service public class DocumentService { @CelestaTransaction public void postOrder(CallContext context, OrderDto doc) { try (OrderHeaderCursor header = new OrderHeaderCursor(context); OrderLineCursor line = new OrderLineCursor(context)) { header.setId(doc.getId()); header.setDate(Date.from(doc.getDate().atStartOfDay(ZoneId.systemDefault()).toInstant())); header.setCustomer_id(doc.getCustomerId()); header.setCustomer_name(doc.getCustomerName()); header.insert(); int lineNo = 0; for (OrderLineDto docLine : doc.getLines()) { lineNo++; line.setLine_no(lineNo); line.setOrder_id(doc.getId()); line.setItem_id(docLine.getItemId()); line.setQty(docLine.getQty()); line.insert(); } } }
Обратим внимание на аннотацию @CelestaTransaction. Благодаря ей прокси-объект DocumentService будет выполнять все те служебные действия с параметром CallContext ctx, которые описаны выше. Т. е. в начале выполнения метода он уже будет привязан к соединению с базой данных, и транзакция будет готова начаться. Мы же можем сосредоточиться на написании бизнес-логики. В нашем случае — чтении объекта OrderDto и сохранении его в базу данных.
Для этого мы используем так называемые курсоры — классы, сгенерированные с помощью celesta-maven-plugin. Мы уже видели, что они из себя представляют. По одному классу создаётся на каждый из объектов схемы – на две таблицы и одно представление. И теперь эти классы мы можем использовать для доступа к объектам базы данных в нашей бизнес-логике.
Чтобы создать курсор на таблицу заказов и выбрать первую запись, нужно написать такой код:
OrderHeaderCursor header = new OrderHeaderCursor(context); header.tryFirst();
После создания объекта header мы можем получить доступ к полям записи таблицы через геттеры и сеттеры:

При создании курсора мы обязаны использовать активный контекст вызова — это единственный способ создать курсор. Контекст вызова несёт в себе информацию о текущем пользователе и его правах доступа.
С объектом-курсором мы можем производить разные вещи: фильтровать, переходить по записям, а также, естественно, вставлять, удалять и обновлять записи. Весь API курсоров подробно описан в документации.
Например, код нашего примера можно было бы развить следующим образом:
OrderHeaderCursor header = new OrderHeaderCursor(context); header.setRange("manager_id", "manager1"); header.tryFirst(); header.setCounter(header.getCounter() + 1); header.update();
В этом примере мы выставляем фильтр по полю manager_id, затем находим первую запись методом tryFirst.
Методы get, first, insert, update имеют два варианта: без приставки try (просто get(...) и т. д.) и с приставкой try (tryGet(...), tryFirst() и т. д.). Методы без приставки try вызывают исключение, если в базе данных нет подходящих данных для выполнения действия. К примеру, first() вызовет исключение, если в установленный на курсор фильтр не попадёт ни одной записи. В то же время методы с приставкой try исключения не вызывают, а вместо этого возвращают булевское значение, сигнализирующее об успешности или неуспешности соответствующей операции. Рекомендуемой практикой является использование методов без приставки try везде, где это возможно. Таким образом создаётся «сам себя тестирующий» код, вовремя сигнализирующий об ошибках в логике и/или в данных базы данных.
В момент срабатывания tryFirst переменные курсора заполняются данными одной записи, мы можем читать и присваивать им значения. А когда данные в курсоре полностью подготовлены, мы выполняем update(), и он сохраняет содержимое курсора в базе данных.
Какой проблеме может быть подвержен этот код? Конечно же, возникновению race condition/lost update! Потому что между моментом, когда мы получили данные в строке с «tryFirst», и моментом, когда мы пытаемся обновить эти данные в точке «update», кто-то другой уже может получить, изменить и обновить эти данные в базе. После того, как данные прочитаны, курсор никаким образом не блокирует их использование другими пользователями! Для защиты от потерянных обновлений Celesta использует принцип optimistic lock. В каждой таблице по умолчанию Celesta создаёт поле recversion, и на уровне ON UPDATE-триггера выполняет инкремент номера версии и проверяет, что обновляемые данные имеют ту же версию, что и в таблице. Если произошла проблема — выбрасывает исключение. Подробнее об этом можно прочитать в статье документации «защита от потерянных обновлений».
Ещё раз напомним, что с объектом CallContext связана транзакция. Если Celesta-процедура заканчивается успешно, происходит commit. Если Celesta-метод заканчивается с необработанным исключением, происходит rollback. Таким образом, если ошибка происходит в какой-то сложной процедуре — откатывается вся связанная с контекстом вызова транзакция, как будто бы мы ничего и не начинали делать с данными, данные не испорчены. Если же зачем-то нужен commit в середине, допустим, какой-то большой процедуры, то явный commit можно выполнить, вызвав context.commit().
Тестирование методов, работающих с данными
Создадим модульный тест, проверяющий корректность работы сервисного метода, сохраняющего OrderDto в базу данных.
При использовании JUnit5 и доступного в модуле celesta-unit расширения для JUnit5, делать это очень легко. Структура теста следующая:
@CelestaTest public class DocumentServiceTest { DocumentService srv = new DocumentService(); @Test void documentIsPutToDb(CallContext context) { OrderDto doc =... srv.postOrder(context, doc); //Check the fact that records are in the database OrderHeaderCursor header = new OrderHeaderCursor(context); header.tryFirst(); assertEquals(doc.getId(), header.getId()); OrderLineCursor line = new OrderLineCursor(context); line.setRange("order_id", doc.getId()); assertEquals(2, line.count()); } }
Благодаря аннотации @CelestaTest, которая является расширением для JUnit5, мы имеем возможность объявлять параметр CallContext context в тестовых методах. Данный контекст уже активирован и привязан к базе данных (in-memory H2), и поэтому у нас нет необходимости в том, чтобы оборачивать класс сервиса в прокси — мы создаём его с помощью new, а не при помощи Spring. Впрочем, при необходимости инжектить сервис в тест средствами Spring, препятствий к этому нет никаких.
Мы создаём модульные тесты в предположении, что к моменту их выполнения база данных будет абсолютно пустой, но со структурой, которая нам нужна, а после их выполнения мы можем не заботиться о том, что мы оставили «мусор» в базе. Эти тесты выполняются с очень высокой скоростью.
Давайте создадим вторую процедуру, возвращающую JSON с агрегированными значениями, показывающими, сколько каких товаров заказали у нас.
Тест записывает в базу два заказа, после чего проверяет суммарное значение, возвращаемое новым методом getAggregateReport:
@Test void reportReturnsAggregatedQuantities(CallContext context) { srv.postOrder(context, . . .); srv.postOrder(context, . . .); Map<String, Integer> result = srv.getAggregateReport(context); assertEquals(5, result.get("A").intValue()); assertEquals(7, result.get("B").intValue()); }
Для реализации метода getAggregateReport мы воспользуемся представлением OrderedQty, которое, напомню, в CelestaSQL-файле выглядит так:
create view OrderedQty as select item_id, sum(qty) as qty from OrderLine group by item_id;
Запрос стандартный: мы суммируем строки заказов по количеству и группируем по коду товара. Для представления уже создался курсор OrderedQtyCursor, которым мы можем воспользоваться. Мы объявляем этот курсор, итерируем по нему и собираем нужный Map<String, Integer>:
@CelestaTransaction public Map<String, Integer> getAggregateReport(CallContext context) { Map<String, Integer> result = new HashMap<>(); try (OrderedQtyCursor ordered_qty = new OrderedQtyCursor(context)) { for (OrderedQtyCursor line : ordered_qty) { result.put(ordered_qty.getItem_id(), ordered_qty.getQty()); } } return result; }
Материализованные представления Celesta
Чем плохо использование представления для получения агрегированных данных? Этот подход вполне работоспособен, но в действительности он подкладывает бомбу замедленного действия под всю нашу систему: ведь представление, которое является SQL-запросом, выполняется все медленнее и медленнее по мере накопления данных в системе. Ему придется суммировать и группировать все больше строк. Как этого избежать?
Celesta старается все стандартные задачи, с которыми постоянно сталкиваются программисты бизнес-логики, реализовать на уровне платформы.
В MS SQL Server есть концепция материализованных (индексированных) представлений, которые хранятся как таблицы и быстро обновляются по мере того, как изменяются данные в исходных таблицах. Если бы мы работали в «чистом» MS SQL Server, то для нашего случая замена представления на индексированное была бы как раз то, что надо: извлечение агрегированного отчёта не замедлялось бы по мере накопления данных, а работа по обновлению агрегированного отчёта выполнялась бы в момент вставки данных в таблицу строк заказа и также не сильно увеличивалась бы при росте числа строк.
Но в случае, если мы работаем с PostgreSQL через Celesta, что мы можем сделать? Переопределим представление, добавив слово materialized:
create materialized view OrderedQty as select item_id, sum(qty) as qty from OrderLine group by item_id;
Запустим систему и посмотрим, что сделалось с базой данных.
Мы заметим, что представление OrderedQty исчезло, а вместо него появилась таблица OrderedQty. При этом, по мере наполнения данными таблицы OrderLine, в таблице OrderedQty будет «волшебным образом» обновляться информация, так, как будто бы OrderedQty являлось бы представлением.
Никакого волшебства тут нет, если мы взглянем на триггеры, построенные на таблице OrderLine. Celesta, получив задачу создать «материализованное представление», проанализировала запрос и создала триггеры на таблице OrderLine, обновляющие OrderedQty. Вставкой единственного ключевого слова — materialized — в CelestaSQL-файл мы решили проблему деградации производительности, а код бизнес-логики даже не потребовалось изменять!
Естественно, этот подход имеет свои, и довольно жёсткие, ограничения. «Материализованными» в Celesta могут становиться только представления, построенные на одной таблице, без JOIN-ов, с агрегацией по GROUP BY. Однако этого достаточно для того, чтобы строить, например, ведомости остатков средств по счетам, товаров по ячейкам склада и т. п. часто встречающиеся на практике отчёты.
Заключение
Мы пробежались по основным возможностям системы Celesta. Если вас заинтересовала технология — добро пожаловать на гитхаб и в документацию.

