Цели и требования к тестированию «1С Бухгалтерии»
Основной целью проводимого тестирования является сравнение поведения системы 1С на двух разных СУБД при прочих одинаковых условиях. Т.е. конфигурация баз данных 1С и первоначальная заполненность данными должны быть одинаковыми при проведении каждого тестирования.
Основными параметрами, которые должны быть получены при тестировании:
- Время выполнения каждого теста (снимается отделом Разработки 1С)
- Нагрузка на СУБД и серверное окружение во время выполнения теста снимается- администраторами СУБД, а также по серверному окружению системными администраторами
Тестирование системы 1С должно выполняться с учетом клиент-серверной архитектуры, поэтому необходимо произвести полноценную эмуляцию работы пользователя или нескольких пользователей в системе с отработкой ввода информации в интерфейсе и сохранением этой информации в базе данных. При этом, необходимо, чтобы большой объем периодической информации был разнесен по большому отрезку времени для создания итогов в регистрах накопления.
Для выполнения тестирования разработан алгоритм в виде скрипта сценарного тестирования, для конфигурации 1С Бухгалтерия 3.0, в котором выполняется последовательный ввод тестовых данных в систему 1С. Скрипт позволяет указать различные настройки по выполняемым действиям и количеству тестовых данных. Детальное описание ниже по тексту.
Описание настроек и характеристик тестируемых сред
Мы в компании Fortis решили перепроверить результаты, в том числе с помощью известного теста Гилева.
Также нас подстегнуло к тестированию в том числе и некоторые публикации по результатам изменения производительности при переходе от MS SQL Server к PostgreSQL. Такие как: 1С Батл: PostgreSQL 9,10 vs MS SQL 2016.
Итак, вот инфраструктура для тестирования:
| 1С | PostgreSQL | ||
|---|---|---|---|
| 8 | 8 | 8 | |
| 16 | 32 | 32 | |
| ОС | |||
| Разрядность | x64 | x64 | x64 |
| 8.3.13.1865 | - | - | |
| Версия СУБД | - | 13.0.5264.1 | 10.5 (4.8.5.20150623) |
Сервера для MS SQL и PostgreSQL являлись виртуальными и запускались поочередно для нужного теста. 1С стоял на отдельном сервере.
Детали
Спецификация гипервизора:
Model: Supermicro SYS-6028R-TRT
CPU: Intel® Xeon® CPU E5-2630 v3 @2.40GHz (2 sockes * 16 CPU HT = 32CPU)
RAM: 212 GB
ОС: VMWare ESXi 6.5
PowerProfile: Performance
Дисковая подсистема гипервизора:
Контроллер: Adaptec 6805, Cache size: 512MB
Volume: RAID 10, 5.7 TB
Stripe-size: 1024 KB
Write-cache: on
Read-cache: off
Диски: 6 шт. HGST HUS726T6TAL,
Sector-Size: 512 Bytes
Write Cache: on
PostgreSQL был настроен следующим образом:
Все содержимое файла postgresql.conf:
MS SQL был настроен следующим образом:

и

Настройки кластера 1С оставили стандартными:

и

Model: Supermicro SYS-6028R-TRT
CPU: Intel® Xeon® CPU E5-2630 v3 @2.40GHz (2 sockes * 16 CPU HT = 32CPU)
RAM: 212 GB
ОС: VMWare ESXi 6.5
PowerProfile: Performance
Дисковая подсистема гипервизора:
Контроллер: Adaptec 6805, Cache size: 512MB
Volume: RAID 10, 5.7 TB
Stripe-size: 1024 KB
Write-cache: on
Read-cache: off
Диски: 6 шт. HGST HUS726T6TAL,
Sector-Size: 512 Bytes
Write Cache: on
PostgreSQL был настроен следующим образом:
- postgresql.conf:
Базовая настройка делалась по калькулятору — pgconfigurator.cybertec.at, параметры huge_pages, checkpoint_timeout, max_wal_size, min_wal_size, random_page_cost менялись на основе информации, полученной из источников, упомянутых в конце публикации. Значение параметра temp_buffers увеличивалось, исходя из предложения, что 1С активно использует временные таблицы:
listen_addresses = '*' max_connections = 1000 #Выделяемый под кэш данных размер ОЗУ. Работа со строками происходит в основном в этом участке памяти. На системах с 32ГБ ОЗУ рекомендуется выделять около 25% от общего объема памяти. shared_buffers = 9GB #Использование больших страницы памяти(Настройка ядра Linux - vm.nr_hugepages). huge_pages = on #Лимит памяти для временных таблиц на сессию. temp_buffers = 256MB #Лимит памяти на одну операцию типа ORDER BY, DISTINCT, merge joins, join, hash-based aggregation, hash-based processing of IN subqueries. #Выставлен из расчета, что 1С делает сложные большие запросы (профиль "Mostly complicated real-time SQL queries" в калькуляторе). Возможно стоит уменьшить до 64MB. work_mem = 128MB #Лимит памяти для служебных операций. VACUUM, создание индексов, etc. maintenance_work_mem = 512MB #Совместно с настройками ядра (vm.dirty_background_bytes, vm.dirty_bytes), данные параметры позволяют устранить всплески нагрузки на IO в процессе CHECKPOINT. checkpoint_timeout = 30min max_wal_size = 3GB min_wal_size = 512MB checkpoint_completion_target = 0.9 seq_page_cost = 1 #Настройки для планировщика запросов. Значение по-умолчанию - 4. Для RAID10 рекомендуется уменьшать. random_page_cost = 2.5 #Указание планировщику примерного потенциального размера всей занимаемой postgres памяти, включая страницы в PageCache. effective_cache_size = 22GB
- Ядро, параметры ОС:
Настройки заданы в формате файла профиля для демона tuned:
[sysctl] #Параметры задающие объем грязных страниц (PageCache), по достижении которого ядро должно начинать фоновую/принудительную запись этих страниц на диск. #По-умолчанию объем задан в процентах(10,30) что на современных системах с большим количеством ОЗУ приводит к всплескам нагрузки на систему ввода/вывода. #Важно для оптимизации производительности CHECKPOINT и устранения всплесков на I/O. #Заданные абсолютные значения применимы для использования с RAID-контроллером имеющим write-back cache объемом 512MB. vm.dirty_background_bytes = 67108864 vm.dirty_bytes = 536870912 #Использовать SWAP по-минимуму. Совсем отключать не стоит, чтобы минимизировать вероятность OOM. vm.swappiness = 1 #Планировщик подразумевает, что заданный период времени процесс использует кеш CPU. #Увеличение этого параметра снижает количество миграций процессов с одного CPU на другой. #Параметр заметно влияет на производительность. kernel.sched_migration_cost_ns = 5000000 #Отключение группировки процессов по CPU на основе сессии. #Для серверов этот параметр нужно выставлять в 0. Заметно влияет на производительность. kernel.sched_autogroup_enabled = 0 #Выделение памяти под большие страницы. Параметр заметно влияет на производительность. #Способ расчетам описан в документации - https://www.postgresql.org/docs/11/kernel-resources.html#LINUX-HUGE-PAGES vm.nr_hugepages = 5000 [vm] #Отключение прозрачных больших страниц. Так как СУБД не использует однородные продолжительные сегменты памяти, этот параметр рекомендуется отключать. Тем более, что включены нормальные большие страницы. transparent_hugepages=never #Параметры энергосбережения CPU. В виртуальной машине едва ли имеют смысл, но на железном сервере просто необходимы. [cpu] force_latency=1 governor=performance energy_perf_bias=performance min_perf_pct=100
- Файловая система:
#Создание ФС: #stride и stripe_width рассчитывались для упомянутого RAID 10 из 6-ти дисков с размером stripe в 1024kb mkfs.ext4 -E stride=256,stripe_width=768 /dev/sdb #Опции монтирования: /dev/sdb /var/lib/pgsql ext4 noatime,nodiratime,data=ordered,barrier=0,errors=remount-ro 0 2 #noatime,nodiratime - отключить запись времени доступа к файлам и каталогам #data=ordered - Журнал включен только для метаданных. Метаданные записываются после данных #barrier=0 - Барьер обеспечивает последовательную запись данных журнала ФС. На RAID-контроллерах с батарейкой барьер можно отключить.
Все содержимое файла postgresql.conf:
# ----------------------------- # PostgreSQL configuration file # ----------------------------- # # This file consists of lines of the form: # # name = value # # (The "=" is optional.) Whitespace may be used. Comments are introduced with # "#" anywhere on a line. The complete list of parameter names and allowed # values can be found in the PostgreSQL documentation. # # The commented-out settings shown in this file represent the default values. # Re-commenting a setting is NOT sufficient to revert it to the default value; # you need to reload the server. # # This file is read on server startup and when the server receives a SIGHUP # signal. If you edit the file on a running system, you have to SIGHUP the # server for the changes to take effect, run "pg_ctl reload", or execute # "SELECT pg_reload_conf()". Some parameters, which are marked below, # require a server shutdown and restart to take effect. # # Any parameter can also be given as a command-line option to the server, e.g., # "postgres -c log_connections=on". Some parameters can be changed at run time # with the "SET" SQL command. # # Memory units: kB = kilobytes Time units: ms = milliseconds # MB = megabytes s = seconds # GB = gigabytes min = minutes # TB = terabytes h = hours # d = days #------------------------------------------------------------------------------ # FILE LOCATIONS #------------------------------------------------------------------------------ # The default values of these variables are driven from the -D command-line # option or PGDATA environment variable, represented here as ConfigDir. #data_directory = 'ConfigDir' # use data in another directory # (change requires restart) #hba_file = 'ConfigDir/pg_hba.conf' # host-based authentication file # (change requires restart) #ident_file = 'ConfigDir/pg_ident.conf' # ident configuration file # (change requires restart) # If external_pid_file is not explicitly set, no extra PID file is written. #external_pid_file = '' # write an extra PID file # (change requires restart) #------------------------------------------------------------------------------ # CONNECTIONS AND AUTHENTICATION #------------------------------------------------------------------------------ # - Connection Settings - listen_addresses = '*' # what IP address(es) to listen on; # comma-separated list of addresses; # defaults to 'localhost'; use '*' for all # (change requires restart) #port = 5432 # (change requires restart) max_connections = 1000 # (change requires restart) #superuser_reserved_connections = 3 # (change requires restart) #unix_socket_directories = '/var/run/postgresql, /tmp' # comma-separated list of directories # (change requires restart) #unix_socket_group = '' # (change requires restart) #unix_socket_permissions = 0777 # begin with 0 to use octal notation # (change requires restart) #bonjour = off # advertise server via Bonjour # (change requires restart) #bonjour_name = '' # defaults to the computer name # (change requires restart) # - Security and Authentication - #authentication_timeout = 1min # 1s-600s ssl = off #ssl_ciphers = 'HIGH:MEDIUM:+3DES:!aNULL' # allowed SSL ciphers #ssl_prefer_server_ciphers = on #ssl_ecdh_curve = 'prime256v1' #ssl_dh_params_file = '' #ssl_cert_file = 'server.crt' #ssl_key_file = 'server.key' #ssl_ca_file = '' #ssl_crl_file = '' #test #password_encryption = md5 # md5 or scram-sha-256 #db_user_namespace = off row_security = off # GSSAPI using Kerberos #krb_server_keyfile = '' #krb_caseins_users = off # - TCP Keepalives - # see "man 7 tcp" for details #tcp_keepalives_idle = 0 # TCP_KEEPIDLE, in seconds; # 0 selects the system default #tcp_keepalives_interval = 0 # TCP_KEEPINTVL, in seconds; # 0 selects the system default #tcp_keepalives_count = 0 # TCP_KEEPCNT; # 0 selects the system default #------------------------------------------------------------------------------ # RESOURCE USAGE (except WAL) #------------------------------------------------------------------------------ # - Memory - shared_buffers = 9GB # min 128kB # (change requires restart) huge_pages = on # on, off, or try # (change requires restart) temp_buffers = 256MB # min 800kB #max_prepared_transactions = 0 # zero disables the feature # (change requires restart) # Caution: it is not advisable to set max_prepared_transactions nonzero unless # you actively intend to use prepared transactions. # work_mem = 128MB # min 64kB maintenance_work_mem = 512MB # min 1MB #replacement_sort_tuples = 150000 # limits use of replacement selection sort #autovacuum_work_mem = -1 # min 1MB, or -1 to use maintenance_work_mem #max_stack_depth = 2MB # min 100kB dynamic_shared_memory_type = posix # the default is the first option # supported by the operating system: # posix # sysv # windows # mmap # use none to disable dynamic shared memory # (change requires restart) # - Disk - #temp_file_limit = -1 # limits per-process temp file space # in kB, or -1 for no limit # - Kernel Resource Usage - max_files_per_process = 10000 # min 25 # (change requires restart) shared_preload_libraries = 'online_analyze, plantuner' # (change requires restart) # - Cost-Based Vacuum Delay - #vacuum_cost_delay = 0 # 0-100 milliseconds #vacuum_cost_page_hit = 1 # 0-10000 credits #vacuum_cost_page_miss = 10 # 0-10000 credits #vacuum_cost_page_dirty = 20 # 0-10000 credits #vacuum_cost_limit = 200 # 1-10000 credits # - Background Writer - bgwriter_delay = 20ms # 10-10000ms between rounds bgwriter_lru_maxpages = 400 # 0-1000 max buffers written/round bgwriter_lru_multiplier = 4.0 # 0-10.0 multiplier on buffers scanned/round bgwriter_flush_after = 0 # measured in pages, 0 disables # - Asynchronous Behavior - effective_io_concurrency = 3 # 1-1000; 0 disables prefetching max_worker_processes = 8 # (change requires restart) max_parallel_workers_per_gather = 4 # taken from max_parallel_workers max_parallel_workers = 8 # maximum number of max_worker_processes that # can be used in parallel queries #old_snapshot_threshold = -1 # 1min-60d; -1 disables; 0 is immediate # (change requires restart) #backend_flush_after = 0 # measured in pages, 0 disables #------------------------------------------------------------------------------ # WRITE AHEAD LOG #------------------------------------------------------------------------------ # - Settings - wal_level = minimal # minimal, replica, or logical # (change requires restart) #fsync = on # flush data to disk for crash safety # (turning this off can cause # unrecoverable data corruption) #synchronous_commit = on # synchronization level; # off, local, remote_write, remote_apply, or on wal_sync_method = fdatasync # the default is the first option # supported by the operating system: # open_datasync # fdatasync (default on Linux) # fsync # fsync_writethrough # open_sync #wal_sync_method = open_datasync #full_page_writes = on # recover from partial page writes wal_compression = on # enable compression of full-page writes #wal_log_hints = off # also do full page writes of non-critical updates # (change requires restart) wal_buffers = -1 # min 32kB, -1 sets based on shared_buffers # (change requires restart) wal_writer_delay = 200ms # 1-10000 milliseconds wal_writer_flush_after = 1MB # measured in pages, 0 disables commit_delay = 1000 # range 0-100000, in microseconds #commit_siblings = 5 # range 1-1000 # - Checkpoints - checkpoint_timeout = 30min # range 30s-1d max_wal_size = 3GB min_wal_size = 512MB checkpoint_completion_target = 0.9 # checkpoint target duration, 0.0 - 1.0 #checkpoint_flush_after = 256kB # measured in pages, 0 disables #checkpoint_warning = 30s # 0 disables # - Archiving - #archive_mode = off # enables archiving; off, on, or always # (change requires restart) #archive_command = '' # command to use to archive a logfile segment # placeholders: %p = path of file to archive # %f = file name only # e.g. 'test ! -f /mnt/server/archivedir/%f && cp %p /mnt/server/archivedir/%f' #archive_timeout = 0 # force a logfile segment switch after this # number of seconds; 0 disables #------------------------------------------------------------------------------ # REPLICATION #------------------------------------------------------------------------------ # - Sending Server(s) - # Set these on the master and on any standby that will send replication data. max_wal_senders = 0 # max number of walsender processes # (change requires restart) #wal_keep_segments = 130 # in logfile segments, 16MB each; 0 disables #wal_sender_timeout = 60s # in milliseconds; 0 disables #max_replication_slots = 10 # max number of replication slots # (change requires restart) #track_commit_timestamp = off # collect timestamp of transaction commit # (change requires restart) # - Master Server - # These settings are ignored on a standby server. #synchronous_standby_names = '' # standby servers that provide sync rep # method to choose sync standbys, number of sync standbys, # and comma-separated list of application_name # from standby(s); '*' = all #vacuum_defer_cleanup_age = 0 # number of xacts by which cleanup is delayed # - Standby Servers - # These settings are ignored on a master server. #hot_standby = on # "off" disallows queries during recovery # (change requires restart) #max_standby_archive_delay = 30s # max delay before canceling queries # when reading WAL from archive; # -1 allows indefinite delay #max_standby_streaming_delay = 30s # max delay before canceling queries # when reading streaming WAL; # -1 allows indefinite delay #wal_receiver_status_interval = 10s # send replies at least this often # 0 disables #hot_standby_feedback = off # send info from standby to prevent # query conflicts #wal_receiver_timeout = 60s # time that receiver waits for # communication from master # in milliseconds; 0 disables #wal_retrieve_retry_interval = 5s # time to wait before retrying to # retrieve WAL after a failed attempt # - Subscribers - # These settings are ignored on a publisher. #max_logical_replication_workers = 4 # taken from max_worker_processes # (change requires restart) #max_sync_workers_per_subscription = 2 # taken from max_logical_replication_workers #------------------------------------------------------------------------------ # QUERY TUNING #------------------------------------------------------------------------------ # - Planner Method Configuration - #enable_bitmapscan = on #enable_hashagg = on #enable_hashjoin = on #enable_indexscan = on #enable_indexonlyscan = on #enable_material = on #enable_mergejoin = on #enable_nestloop = on #enable_seqscan = on #enable_sort = on #enable_tidscan = on # - Planner Cost Constants - seq_page_cost = 1 # measured on an arbitrary scale random_page_cost = 2.5 # same scale as above #cpu_tuple_cost = 0.01 # same scale as above #cpu_index_tuple_cost = 0.005 # same scale as above #cpu_operator_cost = 0.0025 # same scale as above #parallel_tuple_cost = 0.1 # same scale as above #parallel_setup_cost = 1000.0 # same scale as above #min_parallel_table_scan_size = 8MB #min_parallel_index_scan_size = 512kB effective_cache_size = 22GB # - Genetic Query Optimizer - #geqo = on #geqo_threshold = 12 #geqo_effort = 5 # range 1-10 #geqo_pool_size = 0 # selects default based on effort #geqo_generations = 0 # selects default based on effort #geqo_selection_bias = 2.0 # range 1.5-2.0 #geqo_seed = 0.0 # range 0.0-1.0 # - Other Planner Options - #default_statistics_target = 100 # range 1-10000 #constraint_exclusion = partition # on, off, or partition #cursor_tuple_fraction = 0.1 # range 0.0-1.0 from_collapse_limit = 20 join_collapse_limit = 20 # 1 disables collapsing of explicit # JOIN clauses #force_parallel_mode = off #------------------------------------------------------------------------------ # ERROR REPORTING AND LOGGING #------------------------------------------------------------------------------ # - Where to Log - log_destination = 'stderr' # Valid values are combinations of # stderr, csvlog, syslog, and eventlog, # depending on platform. csvlog # requires logging_collector to be on. # This is used when logging to stderr: logging_collector = on # Enable capturing of stderr and csvlog # into log files. Required to be on for # csvlogs. # (change requires restart) # These are only used if logging_collector is on: log_directory = 'pg_log' # directory where log files are written, # can be absolute or relative to PGDATA log_filename = 'postgresql-%a.log' # log file name pattern, # can include strftime() escapes #log_file_mode = 0600 # creation mode for log files, # begin with 0 to use octal notation log_truncate_on_rotation = on # If on, an existing log file with the # same name as the new log file will be # truncated rather than appended to. # But such truncation only occurs on # time-driven rotation, not on restarts # or size-driven rotation. Default is # off, meaning append to existing files # in all cases. log_rotation_age = 1d # Automatic rotation of logfiles will # happen after that time. 0 disables. log_rotation_size = 0 # Automatic rotation of logfiles will # happen after that much log output. # 0 disables. # These are relevant when logging to syslog: #syslog_facility = 'LOCAL0' #syslog_ident = 'postgres' #syslog_sequence_numbers = on #syslog_split_messages = on # This is only relevant when logging to eventlog (win32): # (change requires restart) #event_source = 'PostgreSQL' # - When to Log - #client_min_messages = notice # values in order of decreasing detail: # debug5 # debug4 # debug3 # debug2 # debug1 # log # notice # warning # error #log_min_messages = warning # values in order of decreasing detail: # debug5 # debug4 # debug3 # debug2 # debug1 # info # notice # warning # error # log # fatal # panic #log_min_error_statement = error # values in order of decreasing detail: # debug5 # debug4 # debug3 # debug2 # debug1 # info # notice # warning # error # log # fatal # panic (effectively off) #log_min_duration_statement = -1 # -1 is disabled, 0 logs all statements # and their durations, > 0 logs only # statements running at least this number # of milliseconds # - What to Log - #debug_print_parse = off #debug_print_rewritten = off #debug_print_plan = off #debug_pretty_print = on log_checkpoints = on log_connections = on log_disconnections = on log_duration = on #log_error_verbosity = default # terse, default, or verbose messages #log_hostname = off log_line_prefix = '< %m >' # special values: # %a = application name # %u = user name # %d = database name # %r = remote host and port # %h = remote host # %p = process ID # %t = timestamp without milliseconds # %m = timestamp with milliseconds # %n = timestamp with milliseconds (as a Unix epoch) # %i = command tag # %e = SQL state # %c = session ID # %l = session line number # %s = session start timestamp # %v = virtual transaction ID # %x = transaction ID (0 if none) # %q = stop here in non-session # processes # %% = '%' # e.g. '<%u%%%d> ' log_lock_waits = on # log lock waits >= deadlock_timeout log_statement = 'all' # none, ddl, mod, all #log_replication_commands = off log_temp_files = 0 # log temporary files equal or larger # than the specified size in kilobytes; # -1 disables, 0 logs all temp files log_timezone = 'W-SU' # - Process Title - #cluster_name = '' # added to process titles if nonempty # (change requires restart) #update_process_title = on #------------------------------------------------------------------------------ # RUNTIME STATISTICS #------------------------------------------------------------------------------ # - Query/Index Statistics Collector - #track_activities = on #track_counts = on #track_io_timing = on #track_functions = none # none, pl, all #track_activity_query_size = 1024 # (change requires restart) #stats_temp_directory = 'pg_stat_tmp' # - Statistics Monitoring - #log_parser_stats = off #log_planner_stats = off #log_executor_stats = off #log_statement_stats = off #------------------------------------------------------------------------------ # AUTOVACUUM PARAMETERS #------------------------------------------------------------------------------ autovacuum = on # Enable autovacuum subprocess? 'on' # requires track_counts to also be on. log_autovacuum_min_duration = 0 # -1 disables, 0 logs all actions and # their durations, > 0 logs only # actions running at least this number # of milliseconds. autovacuum_max_workers = 4 # max number of autovacuum subprocesses # (change requires restart) #autovacuum_naptime = 20s # time between autovacuum runs #autovacuum_vacuum_threshold = 50 # min number of row updates before # vacuum #autovacuum_analyze_threshold = 50 # min number of row updates before # analyze #autovacuum_vacuum_scale_factor = 0.2 # fraction of table size before vacuum #autovacuum_analyze_scale_factor = 0.1 # fraction of table size before analyze #autovacuum_freeze_max_age = 200000000 # maximum XID age before forced vacuum # (change requires restart) #autovacuum_multixact_freeze_max_age = 400000000 # maximum multixact age # before forced vacuum # (change requires restart) #autovacuum_vacuum_cost_delay = 20ms # default vacuum cost delay for # autovacuum, in milliseconds; # -1 means use vacuum_cost_delay #autovacuum_vacuum_cost_limit = -1 # default vacuum cost limit for # autovacuum, -1 means use # vacuum_cost_limit #------------------------------------------------------------------------------ # CLIENT CONNECTION DEFAULTS #------------------------------------------------------------------------------ # - Statement Behavior - #search_path = '"$user", public' # schema names #default_tablespace = '' # a tablespace name, '' uses the default #temp_tablespaces = '' # a list of tablespace names, '' uses # only default tablespace #check_function_bodies = on #default_transaction_isolation = 'read committed' #default_transaction_read_only = off #default_transaction_deferrable = off #session_replication_role = 'origin' #statement_timeout = 0 # in milliseconds, 0 is disabled #lock_timeout = 0 # in milliseconds, 0 is disabled #idle_in_transaction_session_timeout = 0 # in milliseconds, 0 is disabled #vacuum_freeze_min_age = 50000000 #vacuum_freeze_table_age = 150000000 #vacuum_multixact_freeze_min_age = 5000000 #vacuum_multixact_freeze_table_age = 150000000 #bytea_output = 'hex' # hex, escape #xmlbinary = 'base64' #xmloption = 'content' #gin_fuzzy_search_limit = 0 #gin_pending_list_limit = 4MB # - Locale and Formatting - datestyle = 'iso, dmy' #intervalstyle = 'postgres' timezone = 'W-SU' #timezone_abbreviations = 'Default' # Select the set of available time zone # abbreviations. Currently, there are # Default # Australia (historical usage) # India # You can create your own file in # share/timezonesets/. #extra_float_digits = 0 # min -15, max 3 #client_encoding = sql_ascii # actually, defaults to database # encoding # These settings are initialized by initdb, but they can be changed. lc_messages = 'ru_RU.UTF-8' # locale for system error message # strings lc_monetary = 'ru_RU.UTF-8' # locale for monetary formatting lc_numeric = 'ru_RU.UTF-8' # locale for number formatting lc_time = 'ru_RU.UTF-8' # locale for time formatting # default configuration for text search default_text_search_config = 'pg_catalog.russian' # - Other Defaults - #dynamic_library_path = '$libdir' #local_preload_libraries = '' #session_preload_libraries = '' #------------------------------------------------------------------------------ # LOCK MANAGEMENT #------------------------------------------------------------------------------ #deadlock_timeout = 1s max_locks_per_transaction = 256 # min 10 # (change requires restart) #max_pred_locks_per_transaction = 64 # min 10 # (change requires restart) #max_pred_locks_per_relation = -2 # negative values mean # (max_pred_locks_per_transaction # / -max_pred_locks_per_relation) - 1 #max_pred_locks_per_page = 2 # min 0 #------------------------------------------------------------------------------ # VERSION/PLATFORM COMPATIBILITY #------------------------------------------------------------------------------ # - Previous PostgreSQL Versions - #array_nulls = on #backslash_quote = safe_encoding # on, off, or safe_encoding #default_with_oids = off escape_string_warning = off #lo_compat_privileges = off #operator_precedence_warning = off #quote_all_identifiers = off standard_conforming_strings = off #synchronize_seqscans = on # - Other Platforms and Clients - #transform_null_equals = off #------------------------------------------------------------------------------ # ERROR HANDLING #------------------------------------------------------------------------------ #exit_on_error = off # terminate session on any error? #restart_after_crash = on # reinitialize after backend crash? #------------------------------------------------------------------------------ # CONFIG FILE INCLUDES #------------------------------------------------------------------------------ # These options allow settings to be loaded from files other than the # default postgresql.conf. #include_dir = 'conf.d' # include files ending in '.conf' from # directory 'conf.d' #include_if_exists = 'exists.conf' # include file only if it exists #include = 'special.conf' # include file #------------------------------------------------------------------------------ # CUSTOMIZED OPTIONS #------------------------------------------------------------------------------ online_analyze.threshold = 50 online_analyze.scale_factor = 0.1 online_analyze.enable = on online_analyze.verbose = off online_analyze.local_tracking = on online_analyze.min_interval = 10000 online_analyze.table_type = 'temporary' online_analyze.verbose='off' plantuner.fix_empty_table='on'
MS SQL был настроен следующим образом:
и
Настройки кластера 1С оставили стандартными:

и
На серверах не стояла антивирусная программа и не было установлено ничего стороннего.
Для MS SQL, БД tempdb была вынесена на отдельный логический диск. Однако, файлы данных и файлы журналов транзакций для баз данных располагались на одном логическом диске (т е не было сделано разнесения файлов данных и журналов транзакций на отдельные логические диски).
Индексирование дисков в Windows, где располагалась MS SQL Server, было отключено на всех логических дисках (как это принято делать в большинстве случаев на продовских средах).
Описание основного алгоритма сценария автоматизированного тестирования
Основной предполагаемый период тестирования — 1 год, в течении которого по указанным параметрам на каждый день создаются документы и справочная информация.
На каждый день выполнения запускаются блоки ввода и вывода информации:
В конце каждого месяца, в котором производилось создание документов выполняются блоки ввода и вывода информации:
По итогу выполнения выдается информация о времени проведения теста в часах, минутах, секундах и миллисекундах.
Основные возможности скрипта тестирования:
План основных тестов для каждой из баз:
План дополнительных тестов для каждой из баз:
На каждый день выполнения запускаются блоки ввода и вывода информации:
- Блок 1 «СПР_ПТУ» — «Поступление товаров и услуг»
- Открывается справочник «Контрагенты»
- Создается новый элемент справочника «Контрагенты» с видом «Поставщик»
- Создается новый элемент справочника «Договоры» с видом «С поставщиком» для нового контрагента
- Открывается справочник «Номенклатура»
- Создается набор элементов справочника «Номенклатура» с видом «Товар»
- Создается набор элементов справочника «Номенклатура» с видом «Услуга»
- Открывается список документов «Поступления товаров и услуг»
- Создается новый документ «Поступление товаров и услуг» в котором заполняются табличные части «Товары» и «Услуги» созданными наборами данных
- Формируется отчет «Карточка счета 41» за текущий месяц (если указан интервал дополнительного формирования)
- Блок 2 «СПР_РТУ» — «Реализация товаров и услуг»
- Открывается справочник «Контрагенты»
- Создается новый элемент справочника «Контрагенты» с видом «Покупатель»
- Создается новый элемент справочника «Договоры» с видом «С покупателем» для нового контрагента
- Открывается список документов «Реализация товаров и услуг»
- Создается новый документ «Реализация товаров и услуг» в котором заполняются табличные части «Товары» и «Услуги» по указанным параметрам из ранее созданных данных
- Формируется отчет «Карточка счета 41» за текущий месяц (если указан интервал дополнительного формирования)
- Формируется отчет «Карточка счета 41» за текущий месяц
В конце каждого месяца, в котором производилось создание документов выполняются блоки ввода и вывода информации:
- Формируется отчет «Карточка счета 41» с начала года на конец месяца
- Формируется отчет «Оборотно-сальдовая ведомость» с начала года на конец месяца
- Выполняется регламентная процедура «Закрытие месяца»
По итогу выполнения выдается информация о времени проведения теста в часах, минутах, секундах и миллисекундах.
Основные возможности скрипта тестирования:
- Возможность отключения/включения отдельных блоков
- Возможность указания общего количества документов для каждого из блоков
- Возможность указания количества документов для каждого из блоков за день
- Возможность указания количества товаров и услуг внутри документов
- Возможность задания списков количественных и ценовых показателей для записи. Служит для создания различных наборов значений в документах
План основных тестов для каждой из баз:
- «Первый тест». Под одним пользователем создается небольшое количество документов с простыми таблицами, формируются «закрытия месяцев»
- Ожидаемое время выполнения — 20 минут. Заполнение на 1 месяц. Данные: 50 документов «ПТУ», 50 документов «РТУ», 100 элементов «Номенклатура», 50 элементов «Поставщиков» + «Договор», 50 элементов «Покупателей» + «Договор», 2 операции «Закрытие месяца». В документах 1 товар и 1 услуга
- «Второй тест». Под одним пользователем создается существенное количество документов с заполнением таблиц, формируются закрытия месяцев
- Ожидаемое время выполнения — 50-60 минут. Заполнение на 3 месяца. Данные: 90 документов «ПТУ», 90 документов «РТУ», 540 элементов «Номенклатура», 90 элементов «Поставщиков» + «Договор», 90 элементов «Покупателей» + «Договор», 3 операции «Закрытие месяца». В документах 3 товара и 3 услуги
- «Третий тест». Под двумя пользователями запускается одновременное выполнение скрипта. Создается существенное количество документов с заполнением таблиц. Итоговым временем выполнения теста считается максимальное
- Ожидаемое время выполнения — 40-60 минут. Заполнение на 2 месяца. Данные: 50 документов «ПТУ», 50 документов «РТУ», 300 элементов «Номенклатура», 50 элементов «Поставщиков» + «Договор», 50 элементов «Покупателей» + «Договор». В документах 3 товара и 3 услуги
План дополнительных тестов для каждой из баз:
- Изменение структуры базы данных, проверка времени реструктуризации таблиц базы данных:
- Изменение справочника Договора
- Изменение справочника Контрагенты
- Изменение документа «Реализация товаров и услуг»
- Перепроведение документов «Поступление товаров и услуг» и «Реализация товаров и услуг» за указанный период
- Выгрузка базы данных в файл формата 1С "*.dt" и загрузка из него обратно
- Выполнение регламентной процедуры «Закрытие месяца» для одного из старых периодов
Результаты
А теперь самое интересное-результаты на СУБД MS SQL Server:
Детали
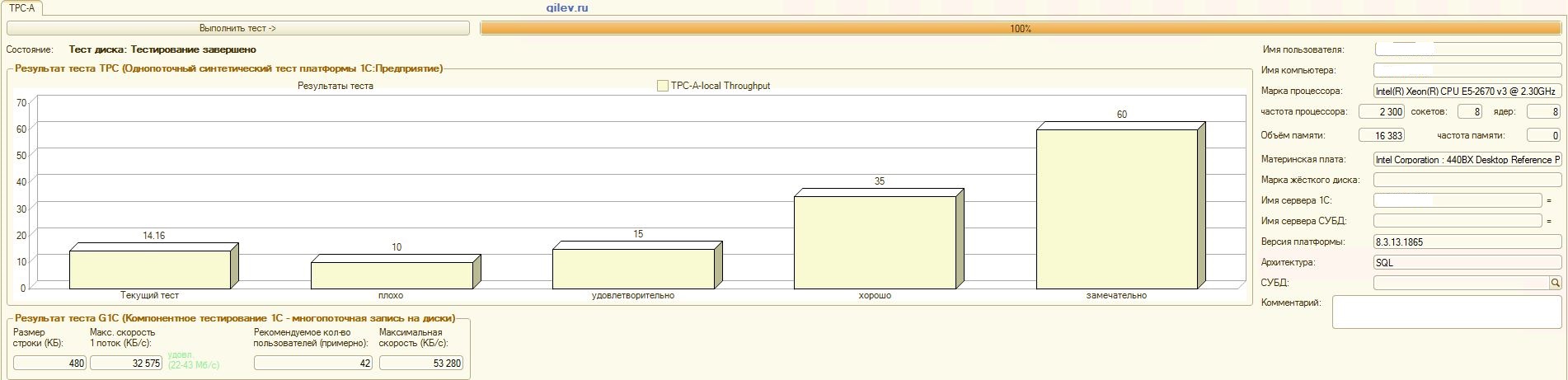
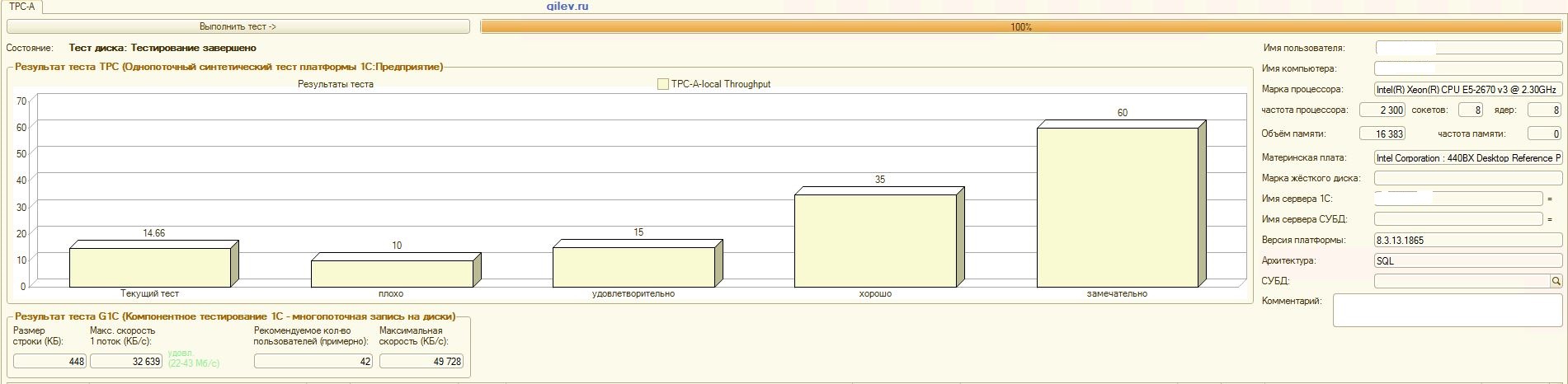

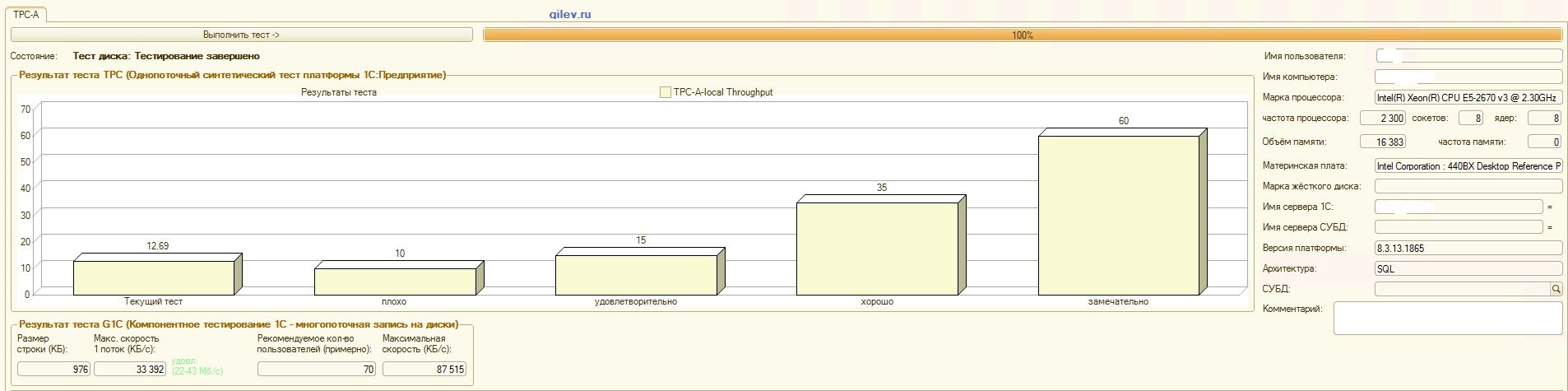
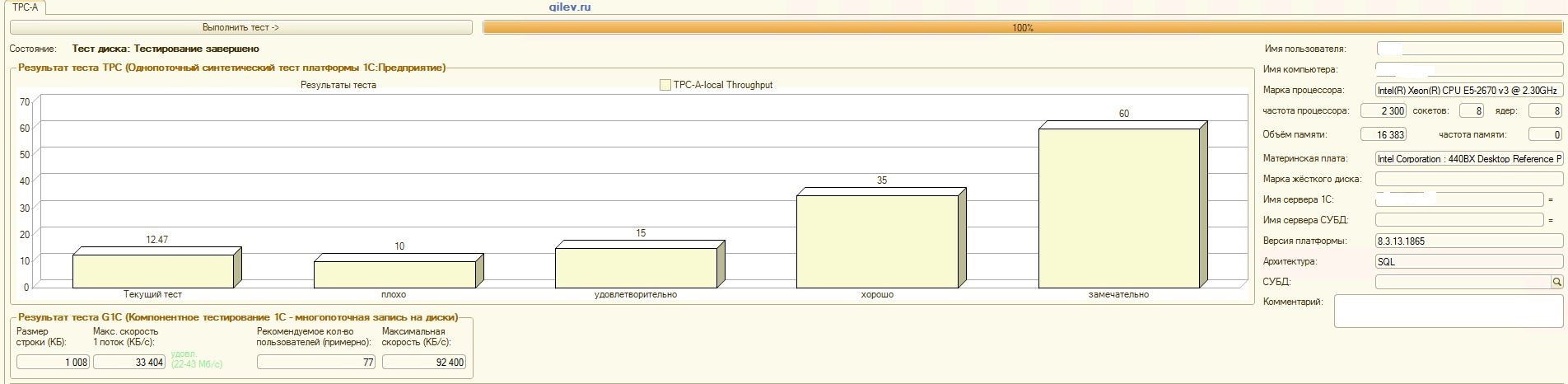

Тест Гилева:
| Показатель | PostgreSQL | % разности (улучшение) в СУБД PostgreSQL относительно СУБД MS SQL | |
|---|---|---|---|
| 14,41 | 12,55 | -14,82 | |
| +3,3 | |||
| +66,83 | |||
| 42 | 70 | +66,67 |
Как видно из результатов, в общем синтетическом тесте СУБД PostgreSQL проиграла по производительности СУБД MS SQL в среднем на 14,82%. Однако, по последним двум показателям PostgreSQL показал значительно лучше результат, чем MS SQL.
Специализированные тесты для 1С Бухгалтерии:
| Описание теста | PostgreSQL, сек | % разности (улучшение) в СУБД PostgreSQL относительно СУБД MS SQL | |
|---|---|---|---|
| 1056,45 | 1064 | -0,7 | |
| 3230,8 | 3236,6 | -0,2 | |
| 1707,45 | 1738,8 | -1,8 | |
| 1859,1 | 1864,9 | -0,3 | |
| Изменение структуры базы данных и реструктуризация | 30 | 22 | +26,7 |
| Проведение документов ПТУ и РТУ за период с 01.01.2018 по 31.12.2018 | 138,5 | 164,5 | -15,8 |
| Проведение всех документов ПТУ и РТУ в базе | 316 | 397 | -20,4 |
| Выгрузка базы данных в файл формата *.dt | 87 | 87 | 0 |
| Загрузка базы данных из файла формата *.dt | 201 | 207 | -2,9 |
| Выполнение процедуры «Закрытие месяца за декабрь 2018 г. | 78 | 64,5 | +17,3 |
Как видно из результатов, 1С Бухгалтерия примерно одинаково работает и на MS SQL, и на PostgreSQL при данных выше настройках.
В обоих случаях СУБД работала стабильно.
Конечно возможно нужен более тонкий тюнинг как со стороны СУБД, так и со стороны ОС и файловой системы. Все делалось так, как вещали публикации, которые говорили, что будет значительный прирост в производительности или примерно будет одинаково при переходе с MS SQL на PostgreSQL. Более того, в данном тестировании проводился ряд мероприятий по оптимизации самой ОС и файловой системы для CentOS, которые описаны выше.
Стоит отметить, что тест Гилева запускался многократно для PostgreSQL-приведены самые лучшие результаты. По MS SQL был запущен тест Гилева 3 раза, т к далее оптимизацией по MS SQL не занимались. Все последующие попытки были привести слона к показателям MS SQL.
После достижения оптимальной разности по синтетическому тесту Гилева между MS SQL и PostgreSQL, были проведены специализированные тесты для 1С Бухгалтерии, описанные выше.
Общий вывод заключается в том, что, несмотря на существенную просадку в производительности по синтетическому тесту Гилева СУБД PostgreSQL относительно MS SQL, при должных настройках, данных выше, 1С Бухгалтерию можно установить как на СУБД MS SQL, так и на СУБД PostgreSQL.
Замечания
Сразу необходимо отметить, что данный анализ делался только для сравнения производительности 1С в разных СУБД.
Данный анализ и вывод корректны только для 1С Бухгалтерии при условиях и версиях ПО, описанных выше. На основе полученного анализа невозможно точно сделать вывод, что будет при других настройках и версий ПО, а также при другой конфигурации 1С.
Однако, результат теста Гилева позволяет предположить, что на всех конфигурациях 1С версии 8.3 и новее при должных настройках максимальная просадка в производительности вероятнее всего составит не более 15% для СУБД PostgreSQL относительно СУБД MS SQL. Также стоит учесть, что любое детальное тестирование для точного сравнения занимает значительное время и ресурсы. Исходя из этого, можно сделать более вероятное предположение, что 1С версии 8.3 и новее можно перенести с MS SQL на PostgreSQL с максимальной потерей производительности до 15%. Объективных препятствий для перехода не выявлено, т к эти 15% могут и не проявиться, а в случае их проявления, достаточно просто закупить немного мощнее оборудование при необходимости.
Также важно отметить, что тестируемые БД были небольшими, т е значительно меньше 100 ГБ размером данных, а также максимальное количество одновременно работающих потоков было 4. Это означает, что для больших баз, размер которых существенно больше 100 ГБ (например, около 1 ТБ), а также для баз с интенсивными обращениями (десятки и сотни одновременных активных потоков) данные результаты могут быть некорректными.
Для более объективного анализа, будет полезно в будущем сравнить выпущенную MS SQL Server 2019 Developer и PostgreSQL 12, установленных на одной и той же ОС CentOS, а также когда MS SQL стоит на последней версии ОС Windows Server. Сейчас же PostgreSQL никто не ставит на ОС Windows, т к просадка в производительности у СУБД PostgreSQL при этом будет весьма существенной.
Конечно, тест Гилева говорит в общем о производительности и не только для 1С. Однако, на данный момент говорить, что СУБД MS SQL всегда будет существенно лучше СУБД PostgreSQL рано, т к недостаточно фактов. Для подтверждения или опровержения данного высказывания, необходимо сделать ряд других тестов. Например, для .NET нужно написать как атомарные действия, так и комплексные тесты, запустить их многократно и в разных условиях, зафиксировать время выполнения и взять среднее значение. После этого сравнить эти значения. Это и будет объективный анализ.
На данный момент пока мы не готовы провести такой анализ, но в будущем вполне возможно его проведем. Тогда мы и напишем более подробно при каких операциях PostgreSQL лучше MS SQL и на сколько в процентах, а где MS SQL лучше PostgreSQL и на сколько в процентах.
Также в нашем тесте не были применены методы оптимизации для MS SQL, которые описаны здесь. Возможно в этой статье просто забыли выключить индексирование дисков Windows.
При сравнении двух СУБД надо помнить об еще одном весомом моменте: СУБД PostgreSQL бесплатная и открытая, тогда как СУБД MS SQL платная и имеет закрытый исходный код.
Теперь на счет самого теста Гилева. Вне тестов были сняты трассировки на синтетический тест (первый тест) и на все остальные тесты. По первом тесту в основном идут запросы как на атомарные операции (вставка, обновление, удаление и чтение), так и на сложные (с обращением к нескольким таблицам, а также создание, изменение и удаление таблиц в БД) с разными объемами обрабатывающих данных. Потому синтетический тест Гилева можно считать вполне объективным для сравнения средней унифицированной производительности двух сред (включая и СУБД) относительно друг друга. Т е сами абсолютные величины ничего не говорят, а вот их отношение двух разных сред вполне объективно.
На счет остальных тестов Гилева. По трассировке видно, что максимальное количество потоков было 7, однако вывод о количестве пользователей было более 50. Также по запросом не совсем понятно как вычисляются и прочие показатели. Потому остальные тесты не являются объективными и носят крайне вариативный и приближенный характер. Более точные значения дадут лишь специализированные тесты, учитывающие специфику не только самой системы, но и работы самих пользователей.
Благодарности
- проводили настройку 1С и запускали тесты Гилева, а также внесли значительный вклад в создании данной публикации:
- Роман Буц — тимлид команды 1С
- Александр Грязнов — 1С программист
- коллеги компании Fortis, которые внесли существенный вклад в настройке оптимизации CentOS, PostgreSQL и т д, но пожелали остаться инкогнито
Также отдельное спасибо uaggster и BP1988 за консультацию в некоторых моментах по MS SQL и Windows.
Послесловие
Также любопытный анализ делался в этой статье.
А какие результаты были у вас и как вы проводили тестирование?
Источники
- PostgreSQL 10.9 Documentation
- Документация к Postgres Pro Standard 10.7.1
- 1С Батл: PostgreSQL 9,10 vs MS SQL 2016
- Тест Гилева
- Приложение I. Настройка Postgres Pro для решений 1С
- Cybertec PostgreSQL Configurator
- PostgreSQL vs MS SQL для 1С
- Basics of Tuning Checkpoints
- Настройка PostgreSQL для высокой производительности
- Илья Космодемьянский: „Linux tuning to improve PostgreSQL performance“
- Как PostgreSQL работает с диском / Илья Космодемьянский (PostgreSQL Consulting)
- Сравнение производительности 1С при использовании СУБД PostgreSQL и MS SQL
- Настройки PostgreSQL для работы с 1С: Предприятием. Часть 2

