
Порассуждаем об имплементации map в языке без дженериков, рассмотрим что такое хэш таблица, как она устроена в Go, какие есть плюсы и минусы данной реализации и на что стоит обратить внимание при использовании данной структуры.
Детали под катом.
Внимание! Кто уже знаком с хэш-таблицами в Go, советую пропустить основы и отправиться сюда, иначе есть риск устать к самому интересному моменту.
Что такое хэш таблица
Для начала все-таки напомню, что такое хэш таблица. Это структура данных, которая позволяет хранить пары ключ-значение, и, как правило, обладающая функциями:
- Маппинга:
map(key) → value
- Вставки:
insert(map, key, value)
- Удаления:
delete(map, key)
- Поиска:
lookup(key) → value
Хэш таблица в языке go
Хэш таблица в языке go представлена ключевым словом map и может быть объявлена одним из способов ниже (подробнее о них позже):
m := make(map[key_type]value_type) m := new(map[key_type]value_type) var m map[key_type]value_type m := map[key_type]value_type{key1: val1, key2: val2}
Основные операции производятся так:
- Вставка:
m[key] = value
- Удаление:
delete(m, key)
- Поиск:
value = m[key]
или
value, ok = m[key]
Обход таблицы в go
Рассмотрим следующую программу:
package main import "fmt" func main() { m := map[int]bool{} for i := 0; i < 5; i++ { m[i] = ((i % 2) == 0) } for k, v := range m { fmt.Printf("key: %d, value: %t\n", k, v) } }
Запуск 1:
key: 3, value: false key: 4, value: true key: 0, value: true key: 1, value: false key: 2, value: true
Запуск 2:
key: 4, value: true key: 0, value: true key: 1, value: false key: 2, value: true key: 3, value: false
Как видим, вывод разнится от запуска к запуску. А все потому, что мапа в Go unordered, то есть не упорядоченная. Это значит, что полагаться на порядок при обходе не надо. Причину можно найти в исходном коде рантайма языка:
// mapiterinit initializes the hiter struct used for ranging over maps. func mapiterinit(t *maptype, h *hmap, it *hiter) {... // decide where to start r := uintptr(fastrand()) ... it.startBucket = r & bucketMask(h.B)...}
Место поиска определяется рандомно, запомните это! Ходят слухи, что так разработчики рантайма заставляют пользователей не полагаться на порядок.
Поиск в таблице Go
Снова рассмотрим кусок кода. Предположим, мы хотим создать пары «число»-«число умноженное на 10»:
package main import ( "fmt" ) func main() { m := map[int]int{0: 0, 1: 10} fmt.Println(m, m[0], m[1], m[2]) }
Запускаем:
map[0:0 1:10] 0 10 0
И видим, что при попытке получить значение двойки (которую забыли положить) получили 0. Находим в документации строки, объясняющие это поведение: «An attempt to fetch a map value with a key that is not present in the map will return the zero value for the type of the entries in the map.», а в переводе на русский это означает, что когда мы пытаемся получить значение из мапы, а его там нет, получаем «нулевое значение типа», что в случае числа 0. Что же делать, если мы хотим различать случаи 0 и отсутствия 2? Для этого придумали специальную форму «multiple assignment» — форма, когда вместо привычного одного значения мапа возвращает пару: само значение и еще одно булевое, отвечающее на вопрос, присутствует ли запрошенный ключ в мапе или нет"
Правильно предыдущий кусок кода будет выглядеть так:
package main import ( "fmt" ) func main() { m := map[int]int{0: 0, 1: 10} m2, ok := m[2] if !ok { // somehow process this case m2 = 20 } fmt.Println(m, m[0], m[1], m2) }
И при запуске получим:
map[0:0 1:10] 0 10 20
Создание таблицы в Go.
Допустим, мы хотим посчитать количество вхождений каждого слова в строке, заведем для этого словарь и пройдемся по нему.
package main func main() { var m map[string]int for _, word := range []string{"hello", "world", "from", "the", "best", "language", "in", "the", "world"} { m[word]++ } for k, v := range m { println(k, v) } }
Вы

При попытке запуска такой программы получим панику и сообщение «assignment to entry in nil map». А все потому что мапа — ссылочный тип и мало объявить переменную, надо ее проинициализировать:
m := make(map[string]int)
Чуть пониже будет понятно почему это работает именно так. В начале было представлено аж 4 способа создания мапы, два из них мы рассмотрели — это объявление как переменную и создание через make. Еще можно создать с помощью "Composite literals" конструкции
map[key_type]value_type{}
и при желании даже сразу проинициализировать значениями, этот способ тоже валидный. Что касается создания с помощью new — на мой взгляд, оно не имеет смысла, потому что эта функция выделяет память под переменную и возвращает указатель на нее, заполненную zero value типа, что в случае с map будет nil (мы получим тот же результат, что в var, точнее указатель на него).
Как передается map в функцию?
Допустим у нас есть функция, которая пытается поменять число, которое ей передали. Посмотрим, что будет до и после вызова:
package main func foo(n int) { n = 10 } func main() { n := 15 println("n before foo =", n) foo(n) println("n after foo =", n) }
Пример, думаю, достаточно очевидный, но все-таки включу вывод:
n before foo = 15 n after foo = 15
Как вы наверное догадались, в функцию n пришло по значению, а не по ссылке, поэтому исходная переменная не поменялась.
Проделаем похожий трюк с мапой:
package main func foo(m map[int]int) { m[10] = 10 } func main() { m := make(map[int]int) m[10] = 15 println("m[10] before foo =", m[10]) foo(m) println("m[10] after foo =", m[10]) }
И о чудо:
m[10] before foo = 15 m[10] after foo = 10
Значение поменялось. «Что же, мапа передается по ссылке?», — спросите вы. Нет. В Go не бывает ссылок. Невозможно создать 2 переменные с 1 адресом, как в С++ например. Но зато можно создать 2 переменные, указывающие на один адрес (но это уже указатели, и они в Go есть).
Пусть у нас есть функция fn, которая инициализирует мапу m. В основной функции мы просто объявляем переменную, отправляем на инициализацию и смотрим что получилось после.
package main import "fmt" func fn(m map[int]int) { m = make(map[int]int) fmt.Println("m == nil in fn?:", m == nil) } func main() { var m map[int]int fn(m) fmt.Println("m == nil in main?:", m == nil) }
Вывод:
m == nil in fn?: false
m == nil in main?: true
Итак, переменная m передалась по значению, поэтому, как в случае с передачей в функцию обычного int, не поменялась (поменялась локальная копия значения в fn). Тогда почему же меняется значение, лежащее в самой m? Для ответа на этот вопрос рассмотрим код из рантайма языка:
// A header for a Go map. type hmap struct { // Note: the format of the hmap is also encoded in cmd/compile/internal/gc/reflect.go. // Make sure this stays in sync with the compiler's definition. count int // # live cells == size of map. Must be first (used by len() builtin) flags uint8 B uint8 // log_2 of # of buckets (can hold up to loadFactor * 2^B items) noverflow uint16 // approximate number of overflow buckets; see incrnoverflow for details hash0 uint32 // hash seed buckets unsafe.Pointer // array of 2^B Buckets. may be nil if count==0. oldbuckets unsafe.Pointer // previous bucket array of half the size, non-nil only when growing nevacuate uintptr // progress counter for evacuation (buckets less than this have been evacuated) extra *mapextra // optional fields }
Мапа в Go — это просто указатель на структуру hmap. Это и является ответом на вопрос, почему при том, что мапа передается в функцию по значению, сами значения, лежащие в ней меняются — все дело в указателе. Так же структура hmap содержит в себе следующее: количество элементов, количество «ведер» (представлено в виде логарифма для ускорения вычислений), seed для рандомизации хэшей (чтобы было сложнее заddosить — попытаться подобрать ключи так, что будут сплошные коллизии), всякие служебные поля и главное указатель на buckets, где хранятся значения. Давайте посмотрим на рисунок:
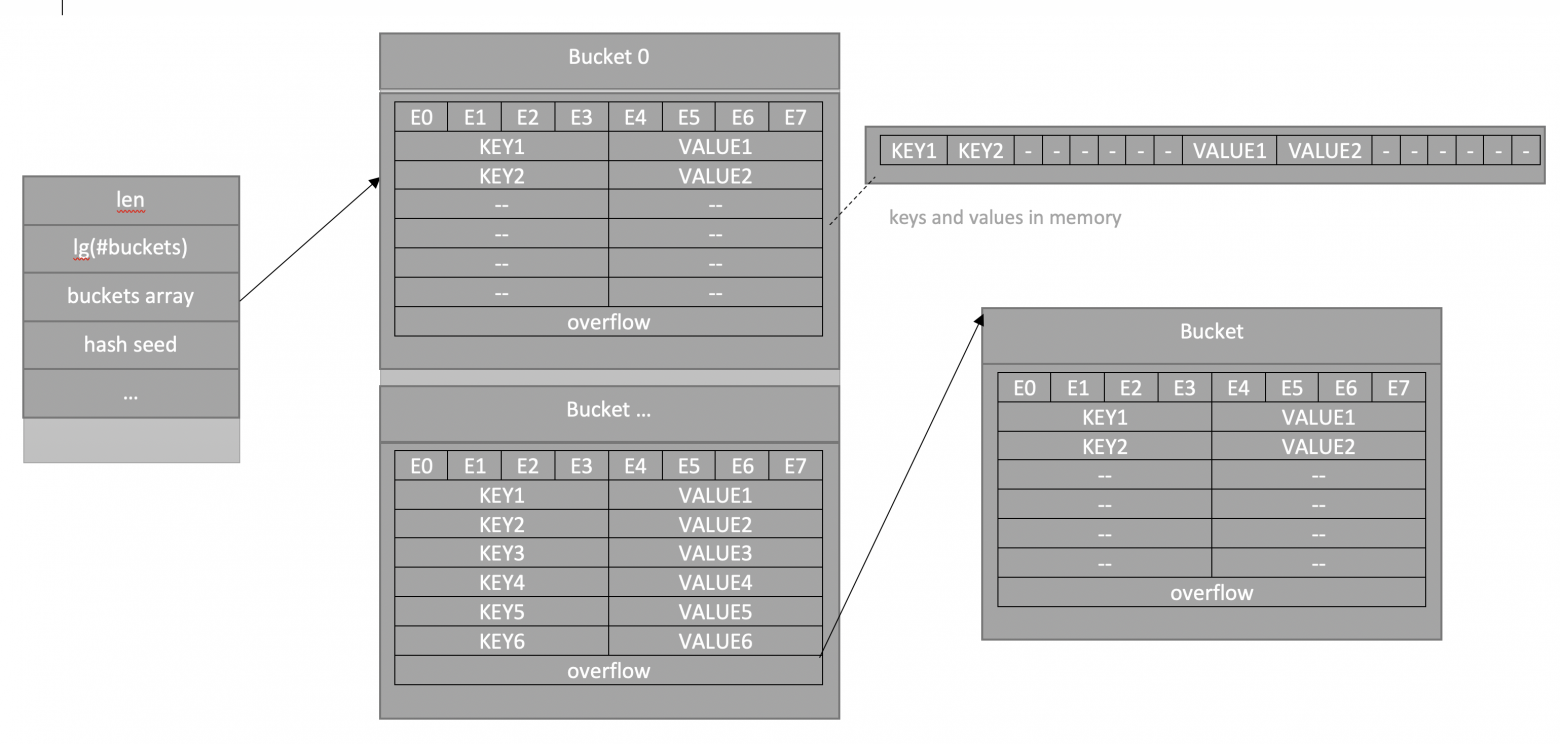
На картинке схематичное изображение структуры в памяти — есть хэдер hmap, указатель на который и есть map в Go (именно он создается при объявлении с помощью var, но не инициализируется, из-за чего падает программа при попытке вставки). Поле buckets — хранилище пар ключ-значение, таких «ведер» несколько, в каждом лежит 8 пар. Сначала в «ведре» лежат слоты для дополнительных битов хэшей (e0..e7 названо e — потому что extra hash bits). Далее лежат ключи и значения как сначала список всех ключей, потом список всех значений.
По хэш функции определяется в какое «ведро» мы кладем значение, внутри каждого «ведра» может лежать до 8 коллизий, в конце каждого «ведра» есть указатель на дополнительное, если вдруг предыдущее переполнилось.
Как растет map?
В исходном коде можно найти строчку:
// Maximum average load of a bucket that triggers growth is 6.5.
то есть, если в каждом «ведре» в среднем более 6,5 элементов, происходит увеличение массива buckets. При этом выделяется массив в 2 раза больше, а старые данные копируются в него маленькими порциями каждые вставку или удаление, чтобы не создавать очень крупные задержки. Поэтому все операции будут чуть медленнее в процессе эвакуации данных (при поиске тоже, нам же приходится искать в двух местах). После успешной эвакуации начинают использоваться новые данные.

Взятие адреса элемента map.
Еще один достаточно интересный момент — мне в самом начале использования языка хотелось сделать вот так:
package main import ( "fmt" ) func main() { m := make(map[int]int) m[1] = 10 a := &m[1] fmt.Println(m[1], *a) }
Но Go говорит: «cannot take the address of m[1]». Объяснение почему же нельзя взять адрес значения кроется процедуре эвакуации данных. Представьте, что мы взяли адрес значения, а потом мапа выросла, выделилась новая память, данные эвакуировались, старые удалились, указатель стал неправильным, поэтому такие операции запрещены.
Как реализована map без genericов?
Ни пустой интерфейс, ни кодогенерация тут ни при чем, все дело в замене во время компиляции. Рассмотрим во что превращаются знакомые нам функции из Go:
v := m["k"] → func mapaccess1(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer v, ok := m["k"] → func mapaccess2(t *maptype, h *hmap, key unsafe.Pointer) (unsafe.Pointer, bool) m["k"] = 9001 → func mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer delete(m, "k") → func mapdelete(t *maptype, h *hmap, key unsafe.Pointer)
Мы видим, что для доступов есть функции mapaccess, для записи и удаления mapassign и mapdelete соответственно. Все операции используют unsafe.Pointer, которому все равно, на какой тип он указывает, а информация о каждом значении описывается дескриптором типа.
type mapType struct { key *_type elem *_type ...} type _type struct { size uintptr alg *typeAlg ...} type typeAlg struct { hash func(unsafe.Pointer, uintptr) uintptr equal func(unsafe.Pointer, unsafe.Pointer) bool...}
В mapType хранятся дескрипторы (_type) ключа и значения. Для дескриптора типа определены операции (typeAlg) сравнения, взятия хэша, размера и так далее, поэтому мы всегда знаем как произвести их.
Немного поподробнее о том как это работает. Когда мы пишем v = m[k] (пытаемся получить значение v по ключу k), компилятор генерирует примерно следующее:
kPointer := unsafe.Pointer(&k) vPointer := mapaccess1(typeOf(m), m, kPointer) v = *(*typeOfvalue)vPointer
То есть берем указатель на ключ, структуру mapType, из которой узнаем какие дескрипторы у ключа и значения, сам указатель на hmap (то есть мапу) и передаем это все в mapaccess1, которая вернет указатель на значение. Указатель мы приводим к нужному типу, разыменовываем и получаем значение.
Теперь посмотрим на код поиска из рантайма (который немного адаптирован для чтения):
func lookup(t *mapType, m *mapHeader, key unsafe.Pointer) unsafe.Pointer {
Функция ищет ключ в мапе и возвращает указатель на соответствующее значение, аргументы нам уже знакомы — это mapType, который хранит дескрипторы типов ключа и значения, сама map (mapHeader) и указатель на память, хранящую ключ. Возвращаем указатель на память, хранящую значение.
if m == nil || m.count == 0 { return zero }
Далее мы проверяем не нулевой ли указатель на хэдер мапы, не лежит ли там 0 элементов и возвращаем нулевое значение, если это так.
hash := t.key.hash(key, m.seed) // hash := hashfn(key) bucket := hash & (1<<m.logB-1) // bucket := hash % nbuckets extra := byte(hash >> 56) // extra := top 8 bits of hash b := (*bucket)(add(m.buckets, bucket*t.bucketsize)) // b := &m.buckets[bucket]
Вычисляем хэш ключа (знаем как вычислить для данного ключа из дескриптора типа). Затем пытаемся понять в какое «ведро» надо пойти и посмотреть (остаток от деления на количество «ведер», просто немного ускорены вычисления). Затем вычисляем дополнительный хэш (берем 8 старших бит хэша) и определяем положение «ведра» в памяти (адресная арифметика).
for { for i := 0; i < 8; i++ { if b.extra[i] != extra { // check 8 extra hash bits continue } k := add(b, dataOffset+i*t.key.size) // pointer to ki in bucket if t.key.equal(key, k) { // return pointer to vi return add(b, dataOffset+8*t.key.size+i*t.value.size) } } b = b.overflow if b == nil { return zero } }
Поиск, если разобраться, устроен не так уж и сложно: проходимся по цепочкам «ведер», переходя в следующее, если в этом не нашли. Поиск в «ведре» начинается с быстрого сравнения дополнительного хэша (вот для чего эти e0...e7 в начале каждого — это «мини» хэш пары для быстрого сравнения). Если не совпало, идем дальше, если совпало, то проверяем тщательнее — определяем где лежит в памяти ключ, подозреваемый как искомый, сравниваем равен ли он тому, что запросили. Если равен, определяем положение значения в памяти и возвращаем. Как видите, ничего сверхъестественного.
Заключение
Используйте мапы, но знайте и понимайте как они работают! Можно избежать граблей, поняв некоторые тонкости — почему нельзя взять адрес значения, почему все падает при объявлении без инициализации, почему лучше выделить память заранее, если известно количество элементов (избежим эвакуаций) и многое другое.
Список литературы:
«Go maps in action», Andrew Gerrand
«How the go runtime implements maps efficiently», Dave Cheney
«Understanding type in go», William Kennedy
Inside map implementation, Keith Randall
map source code, Go Runtime
golang spec
effective go
картинки с гоферами

