При выборе формата сериализации сообщений, которые будут записаны в очередь, лог или куда-либо еще, часто возникает ряд вопросов, так или иначе влияющих на конечный выбор. Одними из таких ключевых вопросов являются скорость сериализации и размер полученного сообщения. Так как форматов для подобных целей немало, я решил протестировать некоторые из них и поделиться результатами.
Тестироваться будут следующие форматы:
В качестве ЯП выбрана Scala.
Основным инструментом для тестирования будет Scalameter.
Измеряться и сравниваться будут следующие параметры: время, затраченное на сериализацию и десериализацию, и размер получившихся файлов.
Удобство пользования, возможность эволюции схемы и другие немаловажные параметры в данном сравнении участвовать не будут.
Для чистоты экспериментов необходимо предварительно сгенерировать набор данных. Формат входных данных — CSV файл. Данные генерируются с помощью простого `Random.next[...]` для числовых значений и `UUID.randomUUID()` для строковых. Сгенерированные данные записываются в csv файл с помощью kantan. Всего сгенерировано 3 сета данных по 100k записей каждый:
Каждая запись состоит из 20 полей. Значение каждого поле опционально.
Характеристики ПК, на котором происходило тестирование, версия scala и java:
ПК: 1,8 GHz Intel Core i5-5350U (2 physical cores), 8 GB 1600 MHz DDR3, SSD SM0128G
Java version: 1.8.0_144-b01; Hotspot: build 25.144-b01
Scala version: 2.12.8
Avro схема генерировалась на ходу перед непосредственным тестированием. Для этого использовалась библиотека avro4s.
Для генерации protobuf3 классов использовался плагин ScalaPB.
Для генерации scala-like thrift классов использовался плагин Scrooge.
Учитывая тот факт, что результаты, не являются абсолютно точными, на их основе все-таки можно сделать некоторые наблюдения:
Что касается размеров выходных файлов, то наблюдения вполне однозначные:
Теперь давайте попробуем разобраться в полученных результатах на примере сериализации строки длиной 36 символов (UUID) без учета разделителей между записями, различных идентификаторов начала и конца записи — только запись 1 строкового поля, но с учетом таких параметров, как, например, тип и номер поля. Рассмотрение сериализации строки вполне покрывает сразу несколько аспектов:
Начнем с avro. Так как все поля имеют тип `Option`, то схема для таких полей будет следующей: `union: [“null”, “string”]`. Зная это, можно получить следующий результат:
1 байт на указание типа записи (null или string), 1 байт на длину строки (1 байт потому, что avro использует variable-length для записи целых чисел) и 36 байт на саму строку. Итого: 38 байт.
Теперь рассмотрим msgpack. Msgpack для записи целых чисел использует похожий на variable-length подход: spec. Попробуем посчитать, сколько фактически уйдет на запись строкового поля: 2 байта на длину строки (так как строка > 31 байта, то потребуется 2 байта), 36 байт на данные. Итого: 38 байт.
Protobuf для кодирования чисел также использует variable-length. Однако помимо длины строки protobuf добавляет еще байт с номером и типом поля. Итого: 38 байт.
Thrift binary не использует никаких оптимизация для записи длины строки, зато вместо 1 байта на номер и тип поля у thrift уходит 3. Поэтому получается следующий результат: 1 байт на номер поля, 2 байта на тип, 4 байта на длину строки, 36 байт на строку. Итого: 43 байта.
Thrift compact в отличии от binary использует variable-length подход, для записи целых чисел и дополнительно по возможности использует сокращенную запись хедера поля. Исходя из этого, получаем: 1 байт на тип и номер поля, 1 байт на длину, 36 байт на данные. Итого: 38 байт.
Java сериализации потребовалось 45 байт на запись строки, из которых 36 байт — строка, 9 байт — 2 байта на длину и 7 байт на некоторую дополнительную информацию, расшифровать которую мне не удалось.
Остались только avro, msgpack, protobuf и thrift compact. Каждый из этих форматов потребует 38 байт на запись utf-8 строки длиной 36 символов. Почему же тогда при упаковке 100k строковых записей меньший объем получился у avro, хотя вместе с данными записалась и не сжатая схема? У avro отрыв небольшой от остальных форматов и причина этого отрыва в отсутствии дополнительных 4 байт на упаковку длины всей записи. Дело в том, что ни msgpack, ни protobuf, ни thrift не обладают специальным разделителем записей. Поэтому, чтобы я мог корректно распаковать записи обратно, мне необходимо было знать точный размер каждой записи. Если бы не этот факт, то, с большой вероятностью, меньший по объему файл был бы у msgpack.
Для числового набора данных главной причиной победы msgpack оказалось отсутствие информации о схеме в упакованных данных и то, что данные были разреженными. У thrift и protobuf даже на пустые значения уйдет больше 1 байта из-за необходимости упаковки информации о типе и номере поля. Avro и msgpack требуют ровно 1 байт на запись пустого значения, но avro, как уже было упомянуто, сохраняет вместе с данными схему.
Msgpack также упаковал в меньший по объему файл и смешанный набор, который то же был разреженным. Причинами этому являются все те же факторы.
Таким образом, получается, что упакованные в msgpack данные занимают меньше всего места. Это вполне справедливое утверждение — не зря в качестве формата хранения данных для tarantool и aerospike был выбран именно msgpack.
После проведенного тестирования я могу сделать следующие выводы:
Исходный код можно посмотреть здесь: github
Подготовка к тестированию
Тестироваться будут следующие форматы:
- Java serialization
- Json
- Avro
- Protobuf
- Thrift (binary, compact)
- Msgpack
В качестве ЯП выбрана Scala.
Основным инструментом для тестирования будет Scalameter.
Измеряться и сравниваться будут следующие параметры: время, затраченное на сериализацию и десериализацию, и размер получившихся файлов.
Удобство пользования, возможность эволюции схемы и другие немаловажные параметры в данном сравнении участвовать не будут.
Генерация входных данных
Для чистоты экспериментов необходимо предварительно сгенерировать набор данных. Формат входных данных — CSV файл. Данные генерируются с помощью простого `Random.next[...]` для числовых значений и `UUID.randomUUID()` для строковых. Сгенерированные данные записываются в csv файл с помощью kantan. Всего сгенерировано 3 сета данных по 100k записей каждый:
- Смешанные данные — 28 mb
Mixed datafinal case class MixedData( f1: Option[String], f2: Option[Double], f3: Option[Long], f4: Option[Int], f5: Option[String], f6: Option[Double], f7: Option[Long], f8: Option[Int], f9: Option[Int], f10: Option[Long], f11: Option[Float], f12: Option[Double], f13: Option[String], f14: Option[String], f15: Option[Long], f16: Option[Int], f17: Option[Int], f18: Option[String], f19: Option[String], f20: Option[String], ) extends Data
- Только строки — 71 mb
OnlyStringsfinal case class OnlyStrings( f1: Option[String], f2: Option[String], f3: Option[String], f4: Option[String], f5: Option[String], f6: Option[String], f7: Option[String], f8: Option[String], f9: Option[String], f10: Option[String], f11: Option[String], f12: Option[String], f13: Option[String], f14: Option[String], f15: Option[String], f16: Option[String], f17: Option[String], f18: Option[String], f19: Option[String], f20: Option[String], ) extends Data
- Только числа (long) — 20 mb
OnlyLongsfinal case class OnlyLongs( f1: Option[Long], f2: Option[Long], f3: Option[Long], f4: Option[Long], f5: Option[Long], f6: Option[Long], f7: Option[Long], f8: Option[Long], f9: Option[Long], f10: Option[Long], f11: Option[Long], f12: Option[Long], f13: Option[Long], f14: Option[Long], f15: Option[Long], f16: Option[Long], f17: Option[Long], f18: Option[Long], f19: Option[Long], f20: Option[Long], ) extends Data
Каждая запись состоит из 20 полей. Значение каждого поле опционально.
Тестирование
Характеристики ПК, на котором происходило тестирование, версия scala и java:
ПК: 1,8 GHz Intel Core i5-5350U (2 physical cores), 8 GB 1600 MHz DDR3, SSD SM0128G
Java version: 1.8.0_144-b01; Hotspot: build 25.144-b01
Scala version: 2.12.8
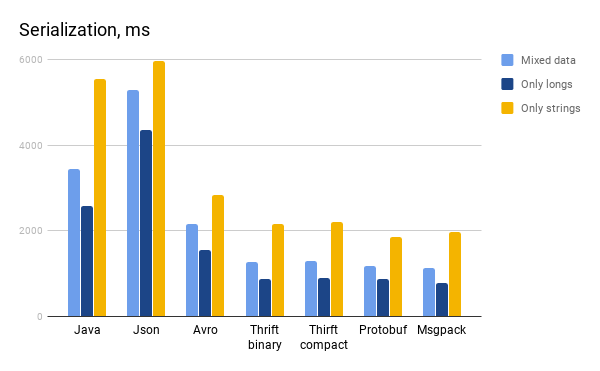
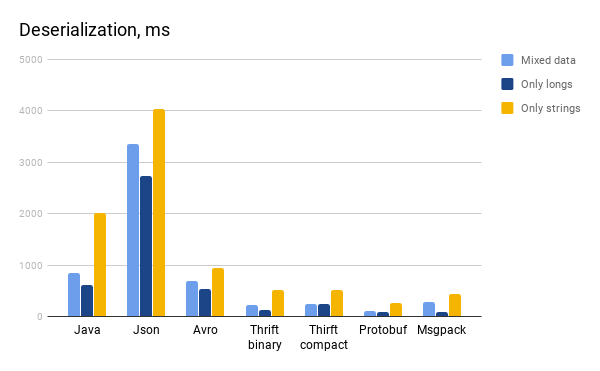
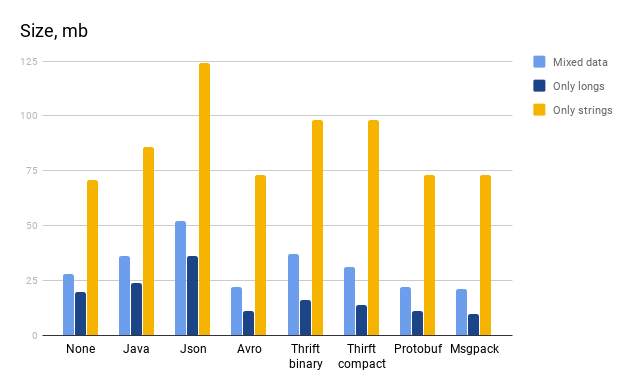
Java serialization
| Mixed data | Only longs | Only strings | |
|---|---|---|---|
| Serialization, ms | 3444,53 | 2586,23 | 5548,63 |
| Deserialization, ms | 852,62 | 617,65 | 2006,41 |
| Size, mb | 36 | 24 | 86 |
Json
| Mixed data | Only longs | Only strings | |
|---|---|---|---|
| Serialization, ms | 5280,67 | 4358,13 | 5958,92 |
| Deserialization, ms | 3347,20 | 2730,19 | 4039,24 |
| Size, mb | 52 | 36 | 124 |
Avro
Avro схема генерировалась на ходу перед непосредственным тестированием. Для этого использовалась библиотека avro4s.
| Mixed data | Only longs | Only strings | |
|---|---|---|---|
| Serialization, ms | 2146,72 | 1546,95 | 2829,31 |
| Deserialization, ms | 692,56 | 535,96 | 944,27 |
| Size, mb | 22 | 11 | 73 |
Protobuf
Protobuf schema
syntax = "proto3"; package protoBenchmark; option java_package = "protobufBenchmark"; option java_outer_classname = "data"; message MixedData { string f1 = 1; double f2 = 2; sint64 f3 = 3; sint32 f4 = 4; string f5 = 5; double f6 = 6; sint64 f7 = 7; sint32 f8 = 8; sint32 f9 = 9; sint64 f10 = 10; double f11 = 11; double f12 = 12; string f13 = 13; string f14 = 14; sint64 f15 = 15; sint32 f16 = 16; sint32 f17 = 17; string f18 = 18; string f19 = 19; string f20 = 20; } message OnlyStrings { string f1 = 1; string f2 = 2; string f3 = 3; string f4 = 4; string f5 = 5; string f6 = 6; string f7 = 7; string f8 = 8; string f9 = 9; string f10 = 10; string f11 = 11; string f12 = 12; string f13 = 13; string f14 = 14; string f15 = 15; string f16 = 16; string f17 = 17; string f18 = 18; string f19 = 19; string f20 = 20; } message OnlyLongs { sint64 f1 = 1; sint64 f2 = 2; sint64 f3 = 3; sint64 f4 = 4; sint64 f5 = 5; sint64 f6 = 6; sint64 f7 = 7; sint64 f8 = 8; sint64 f9 = 9; sint64 f10 = 10; sint64 f11 = 11; sint64 f12 = 12; sint64 f13 = 13; sint64 f14 = 14; sint64 f15 = 15; sint64 f16 = 16; sint64 f17 = 17; sint64 f18 = 18; sint64 f19 = 19; sint64 f20 = 20; }
Для генерации protobuf3 классов использовался плагин ScalaPB.
| Mixed data | Only longs | Only strings | |
|---|---|---|---|
| Serialization, ms | 1169,40 | 865,06 | 1856,20 |
| Deserialization, ms | 113,56 | 77,38 | 256,02 |
| Size, mb | 22 | 11 | 73 |
Thrift
Thrift schema
namespace java thriftBenchmark.java #@namespace scala thriftBenchmark.scala typedef i32 int typedef i64 long struct MixedData { 1:optional string f1, 2:optional double f2, 3:optional long f3, 4:optional int f4, 5:optional string f5, 6:optional double f6, 7:optional long f7, 8:optional int f8, 9:optional int f9, 10:optional long f10, 11:optional double f11, 12:optional double f12, 13:optional string f13, 14:optional string f14, 15:optional long f15, 16:optional int f16, 17:optional int f17, 18:optional string f18, 19:optional string f19, 20:optional string f20, } struct OnlyStrings { 1:optional string f1, 2:optional string f2, 3:optional string f3, 4:optional string f4, 5:optional string f5, 6:optional string f6, 7:optional string f7, 8:optional string f8, 9:optional string f9, 10:optional string f10, 11:optional string f11, 12:optional string f12, 13:optional string f13, 14:optional string f14, 15:optional string f15, 16:optional string f16, 17:optional string f17, 18:optional string f18, 19:optional string f19, 20:optional string f20, } struct OnlyLongs { 1:optional long f1, 2:optional long f2, 3:optional long f3, 4:optional long f4, 5:optional long f5, 6:optional long f6, 7:optional long f7, 8:optional long f8, 9:optional long f9, 10:optional long f10, 11:optional long f11, 12:optional long f12, 13:optional long f13, 14:optional long f14, 15:optional long f15, 16:optional long f16, 17:optional long f17, 18:optional long f18, 19:optional long f19, 20:optional long f20, }
Для генерации scala-like thrift классов использовался плагин Scrooge.
| Binary | Mixed data | Only longs | Only strings |
|---|---|---|---|
| Serialization, ms | 1274,69 | 877,98 | 2168,27 |
| Deserialization, ms | 220,58 | 133,64 | 514,96 |
| Size, mb | 37 | 16 | 98 |
| Compact | Mixed data | Only longs | Only strings |
|---|---|---|---|
| Serialization, ms | 1294,87 | 900,02 | 2199,94 |
| Deserialization, ms | 240,23 | 232,53 | 505,03 |
| Size, mb | 31 | 14 | 98 |
Msgpack
| Mixed data | Only longs | Only strings | |
|---|---|---|---|
| Serialization, ms | 1142,56 | 791,55 | 1974,73 |
| Deserialization, ms | 289,60 | 80,36 | 428,36 |
| Size, mb | 21 | 9,6 | 73 |
Итоговое сравнение
Точность результатов
Важно: результаты скорости работы сериализации и десериализации не являются на 100% точными. Здесь присутствует большая погрешность. Несмотря на то, что тесты были запущены множество раз с дополнительным прогревом JVM, стабильными и точными полученные результаты назвать сложно. Именно поэтому я крайне не рекомендую делать окончательные выводы относительно того или иного формата сериализации, ориентируясь на временные графики.
Учитывая тот факт, что результаты, не являются абсолютно точными, на их основе все-таки можно сделать некоторые наблюдения:
- Еще раз убедились, что java сериализация медленная и не самая экономичная с точки зрения объема выходных данных. Одной из основных причин медленной работы — обращение к полям объектов с помощью рефлексии. Кстати, обращение к полям и их дальнейшая запись происходит не в том порядке, в котором вы их объявили в классе, а в отсортированном в лексикографическом порядке. Это просто интересный факт;
- Json — единственный текстовый формат из представленных в данном сравнении. Почему сериализованные в json данные занимают много места очевидно — каждая запись записывается вместе со схемой. Это также влияет и на скорость записи в файл: чем больше байтов необходимо записать, тем больше на это требуется времени. Также не стоит забывать о том, что для каждой записи создается json-объект, что тоже не убавляет время;
- Avro при сериализации объекта анализирует схему, чтобы в дальнейшем решить, каким образом обрабатывать то или иное поле. Это дополнительные затраты, ведущие к увеличению общего времени сериализации;
- Thrift по сравнению, например, с protobuf и msgpack требует для записи одного поля больший объем памяти, так как вместе со значением поля сохраняется и его мета информация. Также, если посмотреть на выходные файлы thrift, то можно увидеть, что не малую долю от общего объема занимают различные идентификаторы начала и конца записи и размер всей записи в качестве разделителя. Все это безусловно лишь увеличивает время, затраченное на упаковку;
- Protobuf так же, как и thrift упаковывает мета информацию, но делает это несколько более оптимизировано. Также разница в самом алгоритме упаковки и распаковки позволяет этому формату в некоторых случаях работать быстрее остальных;
- Msgpack работает довольно шустро. Одной из причин скорости является тот факт, что никакая дополнительная мета информация не сериализуется. Это одновременно и хорошо, и плохо: хорошо потому, что занимает мало место на диске и не требует дополнительного времени на запись, плохо потому, что в общем-то ничего о структуре записи неизвестно, поэтому определение того, как нужно упаковывать и распаковывать то или иное значение выполняется для каждого поля каждой записи.
Что касается размеров выходных файлов, то наблюдения вполне однозначные:
- Самый маленький файл для числового набора получился у msgpack;
- Самый маленький файл для строкового набора оказался у исходного файла :) Если не считать исходный файл, то победил avro с небольшим отрывом от msgpack и protobuf;
- Самый маленький файл для смешанного набора снова получился у msgpack. Однако отрыв не такой заметный и совсем рядом находятся avro и protobuf;
- Самые большие файлы получились у json. Однако необходимо сделать важное замечание — json текстовый формат и сравнивать его с бинарными по объему (да и по скорости сериализации) не совсем корректно;
- Самый большой файл для числового набора получился у стандартной java сериализации;
- Самый большой файл для строкового набора получился у thrift binary;
- Самый большой файл для смешанного набора получился у thrift binary. Следом за ним идет стандартная java сериализация.
Анализ форматов
Теперь давайте попробуем разобраться в полученных результатах на примере сериализации строки длиной 36 символов (UUID) без учета разделителей между записями, различных идентификаторов начала и конца записи — только запись 1 строкового поля, но с учетом таких параметров, как, например, тип и номер поля. Рассмотрение сериализации строки вполне покрывает сразу несколько аспектов:
- Сериализация чисел (в данном случае — длина строки)
- Сериализация строк
Начнем с avro. Так как все поля имеют тип `Option`, то схема для таких полей будет следующей: `union: [“null”, “string”]`. Зная это, можно получить следующий результат:
1 байт на указание типа записи (null или string), 1 байт на длину строки (1 байт потому, что avro использует variable-length для записи целых чисел) и 36 байт на саму строку. Итого: 38 байт.
Теперь рассмотрим msgpack. Msgpack для записи целых чисел использует похожий на variable-length подход: spec. Попробуем посчитать, сколько фактически уйдет на запись строкового поля: 2 байта на длину строки (так как строка > 31 байта, то потребуется 2 байта), 36 байт на данные. Итого: 38 байт.
Protobuf для кодирования чисел также использует variable-length. Однако помимо длины строки protobuf добавляет еще байт с номером и типом поля. Итого: 38 байт.
Thrift binary не использует никаких оптимизация для записи длины строки, зато вместо 1 байта на номер и тип поля у thrift уходит 3. Поэтому получается следующий результат: 1 байт на номер поля, 2 байта на тип, 4 байта на длину строки, 36 байт на строку. Итого: 43 байта.
Thrift compact в отличии от binary использует variable-length подход, для записи целых чисел и дополнительно по возможности использует сокращенную запись хедера поля. Исходя из этого, получаем: 1 байт на тип и номер поля, 1 байт на длину, 36 байт на данные. Итого: 38 байт.
Java сериализации потребовалось 45 байт на запись строки, из которых 36 байт — строка, 9 байт — 2 байта на длину и 7 байт на некоторую дополнительную информацию, расшифровать которую мне не удалось.
Остались только avro, msgpack, protobuf и thrift compact. Каждый из этих форматов потребует 38 байт на запись utf-8 строки длиной 36 символов. Почему же тогда при упаковке 100k строковых записей меньший объем получился у avro, хотя вместе с данными записалась и не сжатая схема? У avro отрыв небольшой от остальных форматов и причина этого отрыва в отсутствии дополнительных 4 байт на упаковку длины всей записи. Дело в том, что ни msgpack, ни protobuf, ни thrift не обладают специальным разделителем записей. Поэтому, чтобы я мог корректно распаковать записи обратно, мне необходимо было знать точный размер каждой записи. Если бы не этот факт, то, с большой вероятностью, меньший по объему файл был бы у msgpack.
Для числового набора данных главной причиной победы msgpack оказалось отсутствие информации о схеме в упакованных данных и то, что данные были разреженными. У thrift и protobuf даже на пустые значения уйдет больше 1 байта из-за необходимости упаковки информации о типе и номере поля. Avro и msgpack требуют ровно 1 байт на запись пустого значения, но avro, как уже было упомянуто, сохраняет вместе с данными схему.
Msgpack также упаковал в меньший по объему файл и смешанный набор, который то же был разреженным. Причинами этому являются все те же факторы.
Таким образом, получается, что упакованные в msgpack данные занимают меньше всего места. Это вполне справедливое утверждение — не зря в качестве формата хранения данных для tarantool и aerospike был выбран именно msgpack.
Заключение
После проведенного тестирования я могу сделать следующие выводы:
- Получить стабильные результаты бенчмарков сложно;
- Выбор формата — это компромисс между скоростью сериализации и размером выходных данных. В то же время, не стоит забывать о таких важных параметрах как удобство использования формата и возможность эволюции схемы (часто эти параметры играют доминирующую роль).
Исходный код можно посмотреть здесь: github

