Здравствуйте, дорогие читатели! В этой статье я хочу рассказать об архитектуре своего проекта, который я рефакторил 4 раза на его старте, так как не был удовлетворен результатом. Расскажу о минусах популярных подходов и покажу свой.
Сразу хочу сказать что это моя первая статья, я не говорю что делать как я — правильно. Я лишь хочу показать что у меня получилось, рассказать как я дошел до конечного результата и самое главное — получить мнения других.
Я работал в нескольких кампаниях и видел кучу всего что я б сделал по другому.
К примеру, часто вижу N-Слойную архитектуру, есть слой работы с данными (DA), есть слой с бизнес логикой (BL), который работает используя DA и возможно ещё какие-то сервисы, а так же есть слой вьюшки\API в котором принимается запрос, обрабатывается используя BL. Вроде удобно, но посмотрев на код вижу такую ситуацию:
- [DA] вытягивает\записывает\меняет данные, пусть даже сложный запрос — OK
- [BL] 80% вызывает 1 метод и прокидывает результат выше — Зачем этот пустой слой?
- [View] 80% Вызывает 1 метод BL прокидывает результат выше — Зачем этот пустой слой?
Кроме этого, модно оборачивать в интерфейсы чтоб потом замокать и тестить — вау, просто вау!
- А зачем мокать?
- Ну, чтоб выпилить сайд эффекты на время тестов.
- То-есть протестим без сайд-эффктов, а в прод с ними?
...
Это основанная вещь которая мне не нравилась в этой архитектуре, так как чтоб решить задачу по типу: "Вывести список лайков пользователя" это большой процесс, а на деле 1 запрос в БД и возможно маппинг.
1) [DA] Добавить запрос в DA
2) [BL] Пробросить ответ DA
3) [View] Пробросить результат BA, может промаппить
Не забываем про то, что все эти методы ещё нужно добавить в interface, мы ж пишем проект ради того чтоб мокать, а не для решения.
В другом месте я видел реализацию API с подходом CQRS.
Решение выглядело не плохо, 1 папка — 1 фича. Разработчик делающий фичу сидит в своей папке и практически всегда может забыть про влияние своего кода на другие фичи, но файлов было так много, что просто кошмар. Модели запросов\ответов, валидаторы, хелперы, сама логика. Поиск в студии практически отказывался работать, ставились расширения для поиска нужных вещей в коде.
Ещё много чего можно рассказать, но я выделил основные причины которые заставили меня от этого отказаться
И наконец к моему проекту
Как я говорил, я рефакторил свой проект несколько раз, в тот момент у меня была "депрессия программиста", я просто был не доволен своим кодом, и рефакторил его, снова и снова, в итоге начал смотреть видео про архитектуру приложения, чтоб увидеть как делают другие. Наткнулся на доклады Антона Молдована про DDD и функциональное программирование, и подумал: "Вот оно, мне нужен F#!".
Потратив пару дней на F# я понял что в принципе тоже-самое сделаю на C# и не хуже. В видео показывали:
- Вот код C#, он говно
- Вот F# классный, меньше написал — супер.
Но прикол в том что решение на F# реализовали по другому, и против этого показывали плохую реализацию на C#. Главный принцип был в том, что BL это не штука которая вызывает DA, сервисы и делает всю работу, а это чистая функция.
Конечно F# хорош, мне понравились некие фичи но, как и C# это всего лишь инструмент, который можно использовать по-разному.
И я снова вернулся к C# и начал творить.
Создал я такие проекты в решении:
- API
- Core
- Services
- Tests
Так же я использовал фичи C# 8, особенно nullable refence type, её применение покажу.
Коротко о задачах слоев, которые я им дал.
API
1) Получение запросов, модели запросов + валидация, ограничения
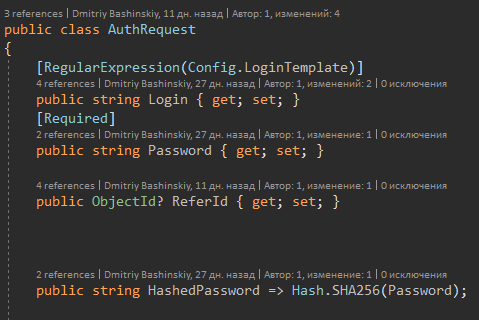
2) Вызов функций из Core и Services
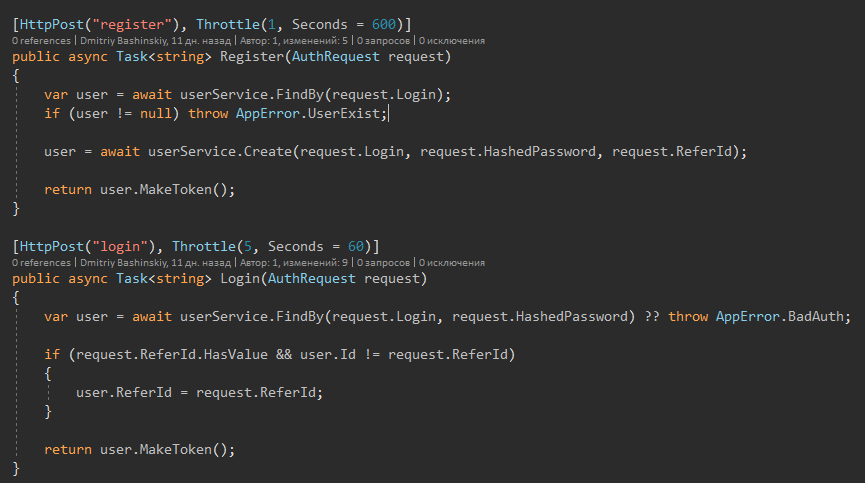
Тут мы видим простой, читабельный код, я думаю каждый поймет что тут написано.
Наблюдается четкий шаблон
1) Достать данные
2) Обработать, изменить и тд — Именно эту часть нужно тестировать.
3) Сохранить.
3) Маппинг, если нужен
4) Обработка ошибок (логирование + человеческий ответ)
В этом классе собраны все возможные ошибки приложения, на которые реагирует exception handler
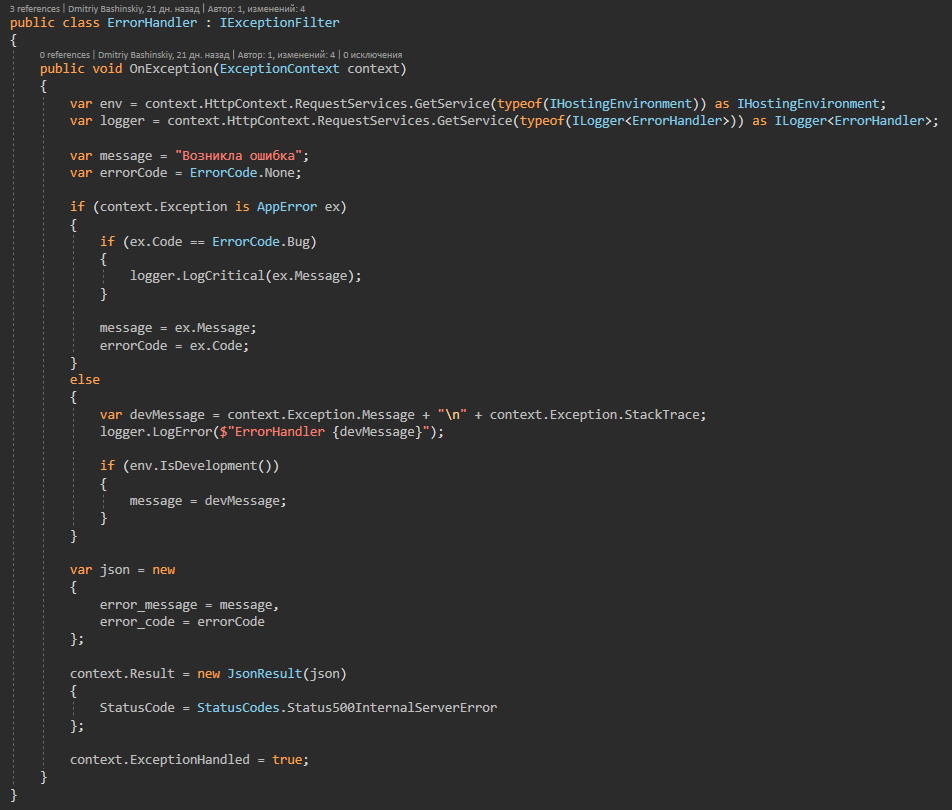
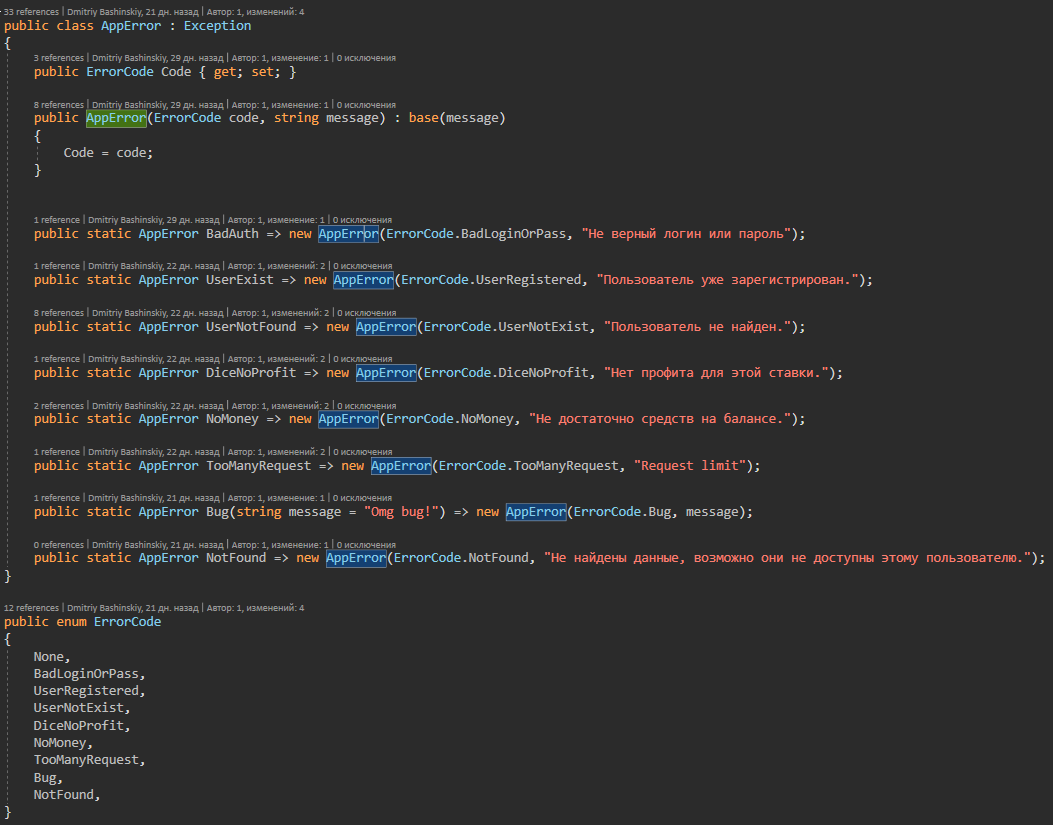
Получается так, что приложение либо работает, либо дает конкретную ошибку, а не обработанные ошибки это либо сайд эффект, либо бага, лог таких ошибок летит сразу мне в телеграм в чат с ботом.
Есть у меня AppError.Bug эта ошибка на не понятный случай.
У меня есть CallBack от другого сервиса, в нем будет userId в моей системе, и если я не найду юзера с этим ID значит либо с юзером что-то случилось, либо вообще не понятно, такая ошибка летит мне как CRITICAL, по идее не должна возникать, но если возникнет, то требует моё вмешательство.
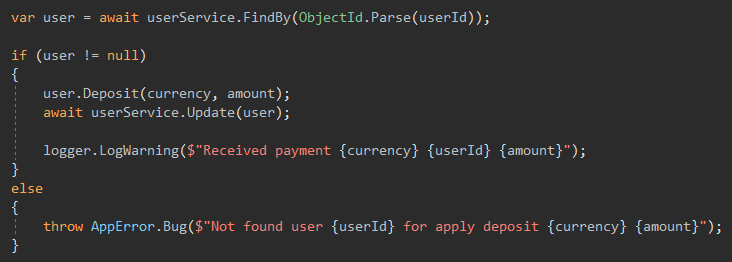
Core, самое интересное
Я всегда держал в голове, что BL это просто функции которые при одинаковом входе дают одинаковый результат. Сложность кода в этом слое была на уровне лабораторной работы, не большие функции, которые четко и без ошибок делают свою работу. И важно было чтоб внутри функций не было сайд эффектов, все что нужно функции заходит ей параметром.
Если функции нужен баланс юзера, то МЫ достаем баланс, и передаем в функцию, а НЕ пихаем сервис юзеров в BL.
1) Основные действия сущностей
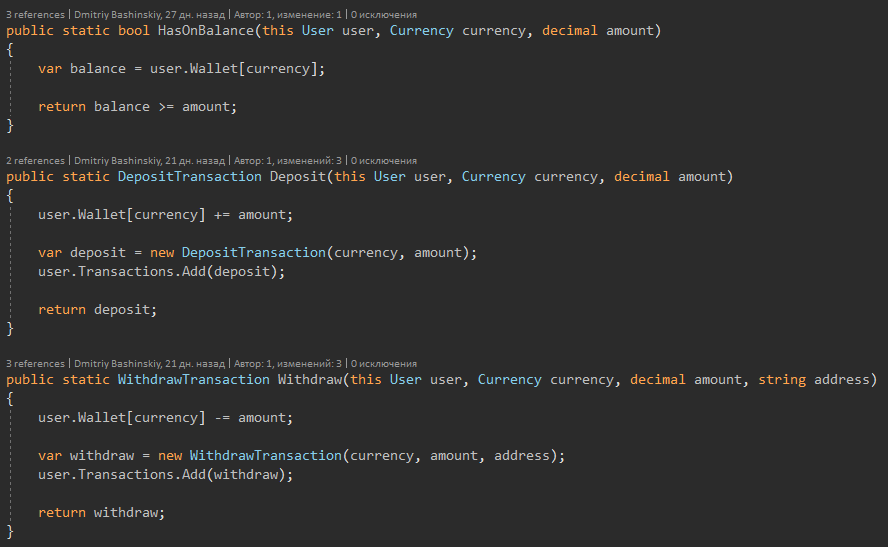
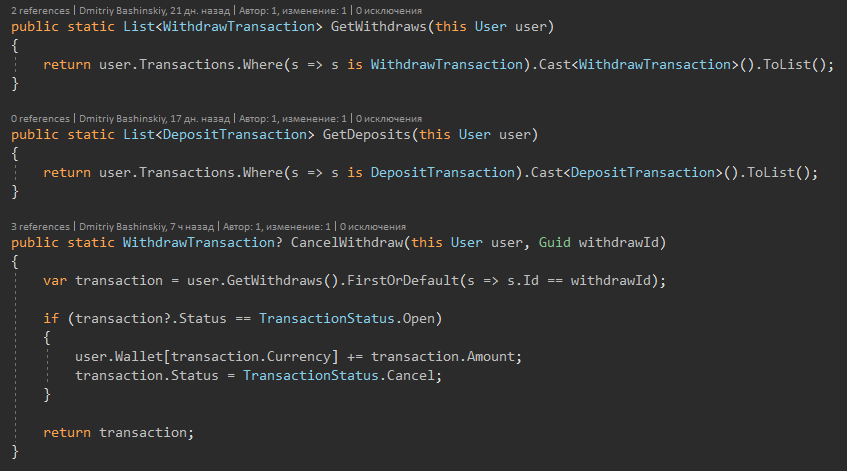
Я вынес методы как методы расширения дабы класс не раздувался, а функционал можно группировать по фичам.
Не менее важной темой считаю хорошее построение моделей сущностей.
Вот к примеру, у меня есть юзер, у юзера есть балансы в нескольких валютах. Одно из типичных решений которое я взял не задумываясь это сущность "Баланс" и просто засунуть массив балансов в юзера. Но какие не удобности принесло такое решение?
1) Добавление\удаление валюты. Эта задача сразу означает для нас не только написание нового кода, а и миграция, с наполнением\удалением всех существующих пользователей и это самый просто вариант. Не дай бог, чтоб добавить новую валюту пришлось бы делать кнопку для юзера, которую он нажмет и инициирует создание нового кошелька по какому-то бизнес процессу. В итоге нужно было всего enum расширить для новой валюты, а написали ещё фичу по созданию кошельков по кнопке, ещё задачу фронту кинули.
2) В коде постоянные FirstOrDefault(s=> s.Currency == currency) и проверка на null
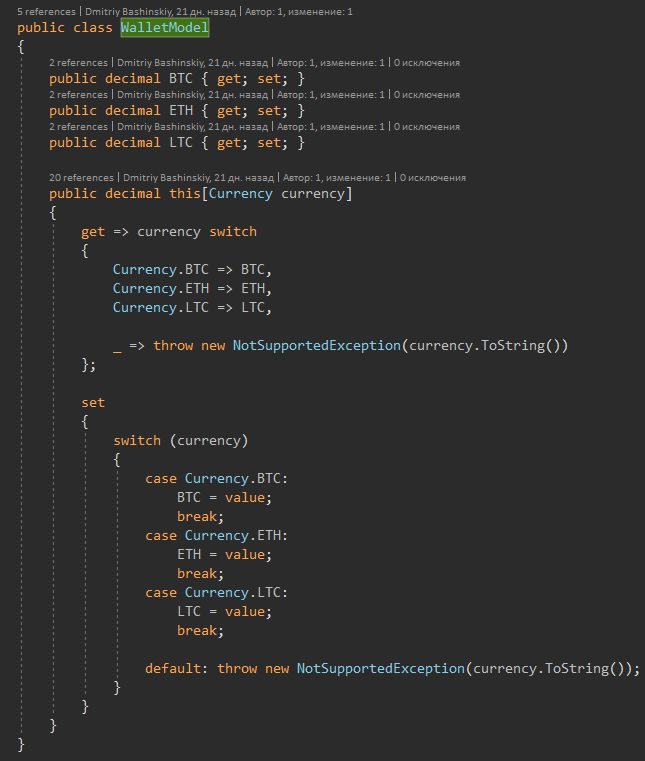
Самой моделью я гарантирую себе, что баланс будет и никаких null, а создав оператор indexer я упростил себе код во всех местах взаимодействия с балансом.
Services
Этот слой предоставляет мне удобные иструмены для работы с различными сервисами.
В своем проекте я использую MongoDB и для удобной работы с ней, обернул колекции в такой себе репозиторий.
Сам репозиторий
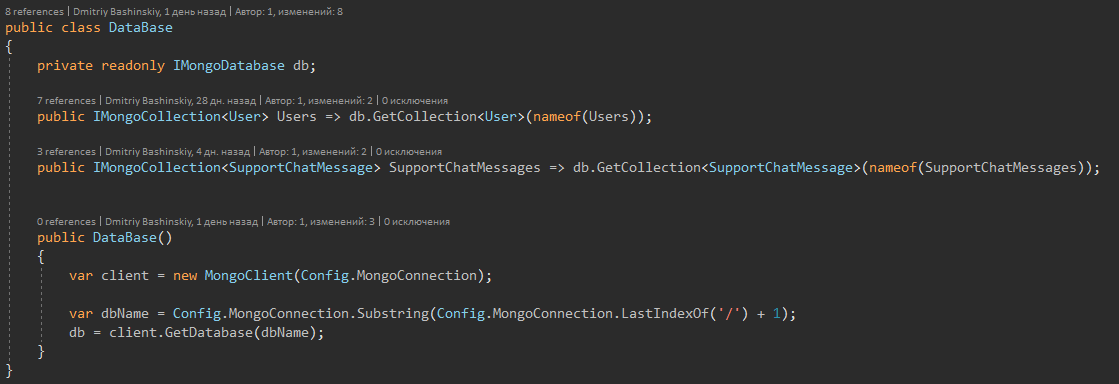
Монга блокирует документ на момент работы с ним, соответсвенно это поможет нам с решение проблем в конкуренции запросов. А ещё в монге есть методы для поиска сущности + действию над ней, например: "Найти юзера с id и добавить к его текущему балансу 10"
А теперь про фичу C# 8.
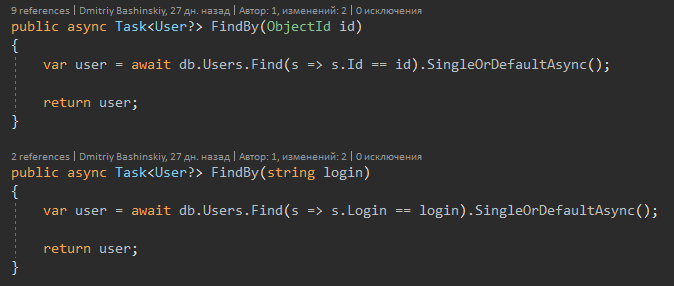
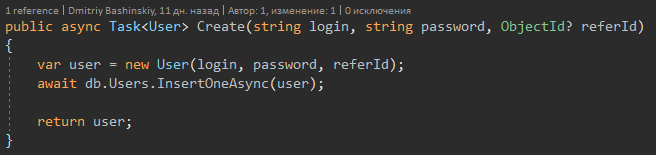
Сигнатура метода мне говорит, что может вернутся User, а может Null, соответственно когда я вижу User? Я сразу получаю предупреждение компилятора, и делаю проверку на null.
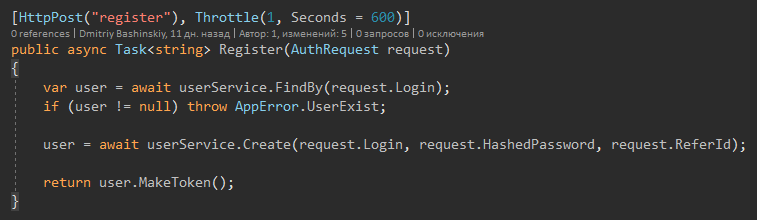
Когда метод возвращает User я уверенно с ним работаю.
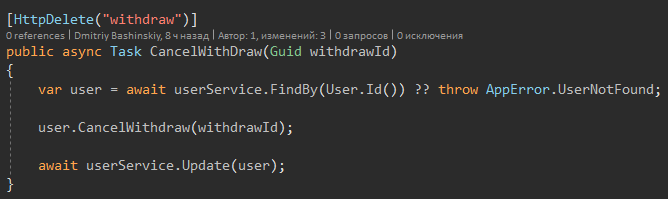
Ещё хочу обратить внимание на то, что нет try catch потому как исключения могут быть только от "странных ситуаций" и не верных данных, которые сюда доходить не должны так как есть валидация. В слое API тоже нет try catch, есть только один глобальный exception handler.
Есть только один метод который бросит Exception это метод Update.
В нем реализована защита от потери данных при многопоточном режиме.
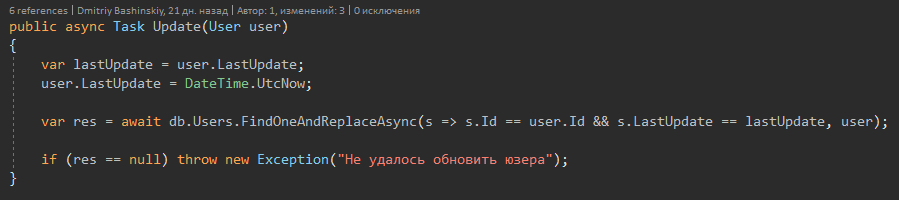
Почему не использовал методы монги, про которые говорил выше?
Есть места где я ещё точно не знаю могу ли я вообще работать с юзером, возможно у него банально нет денег для этого действия, потому в начале достаю пользователя проверяю его, после мутирую и сохраняю.
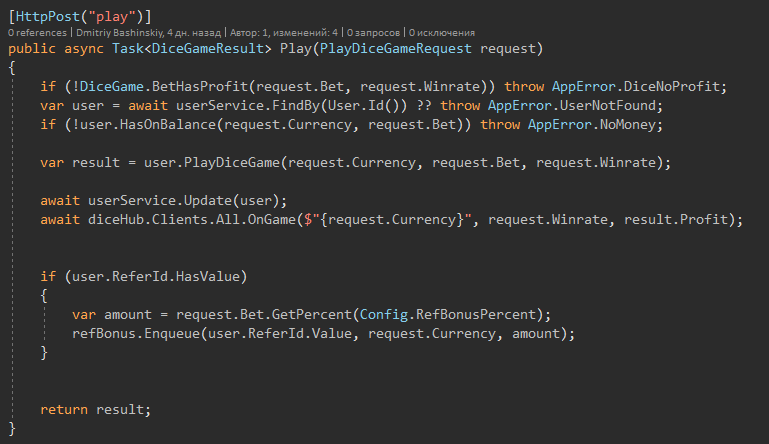
Моё приложение в теории будет менять юзеру баланс чаще чем 1 раз в секунду, так как это будут быстрые игры.
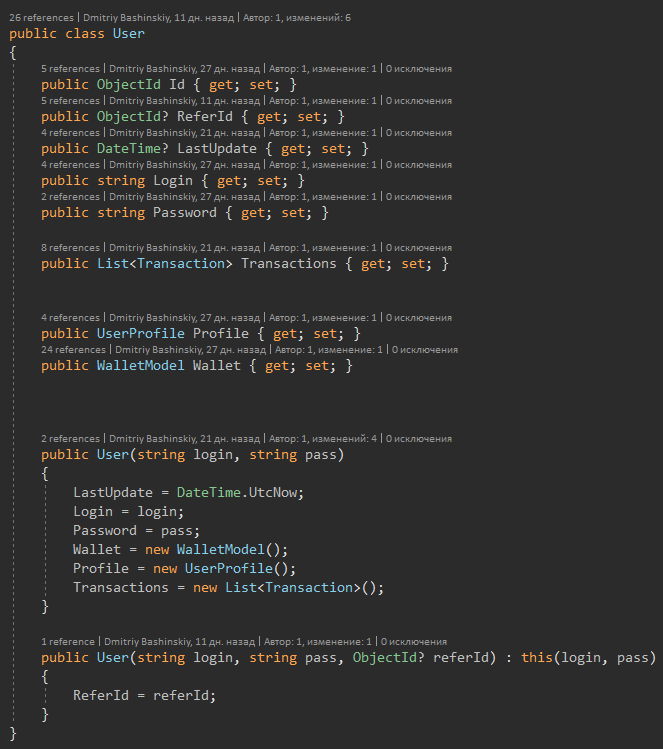
А вот сама модель юзера, тут четко видно что реферал у юзера не обязательный, а со всем остальным можно работать не думая о null.
И наконец Tests
Как я и говорил тестировать нужно только логику, а логика у нас функции, без сайд эффектов.
Потому мы может прогонять наши тесты очень быстро и с разными параметрами.
Я скачал nuget FSCheck который генерит рандомно входящие данные и позволяет проводить много разных кейсов.
Мне лишь нужно создавать различных юзеров, кормить их тесту и проверять изменения.
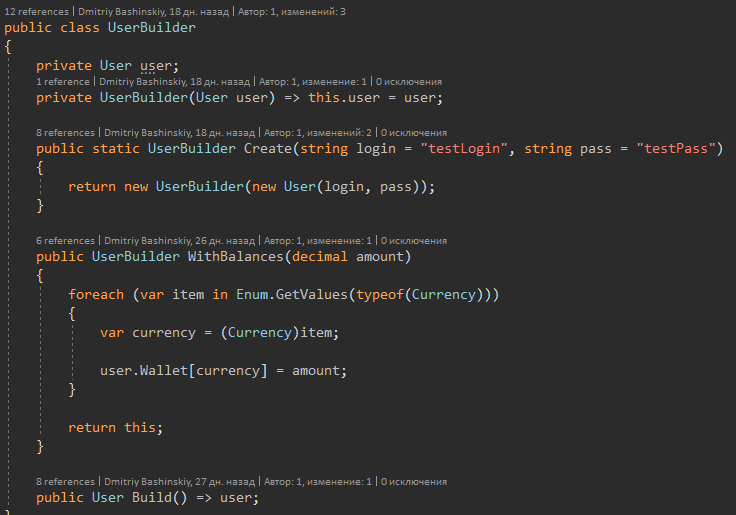
Для создания таких юзеров есть билдер, пока что маленький, но его легко расширять.
А вот и сами тесты
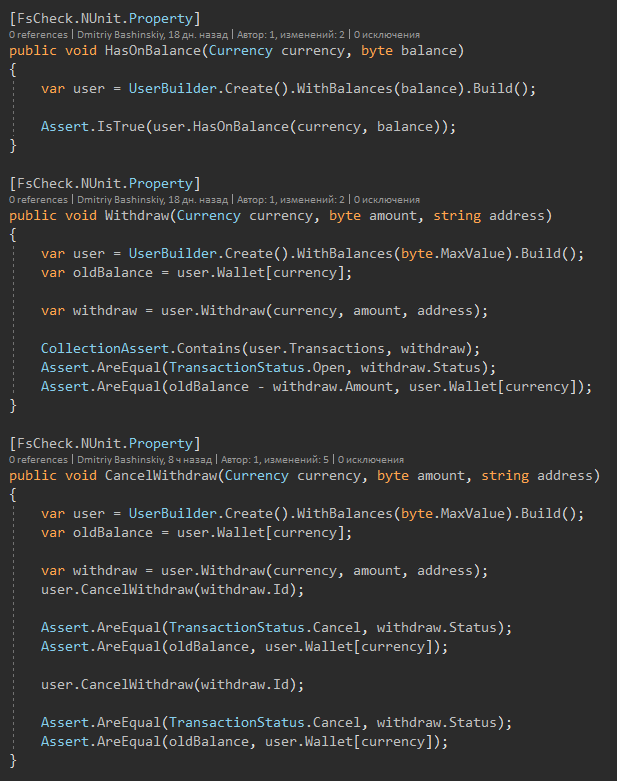

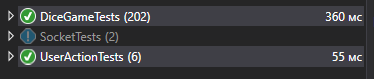
После каких-то изменения я запускаю тесты, через 1-2 секунду вижу что все в порядке.
Так же в планах написать E2E тесты, дабы проверять всю API из вне и быть уверенным что она работает так как нужно, от запроса, до ответа.
Фишки
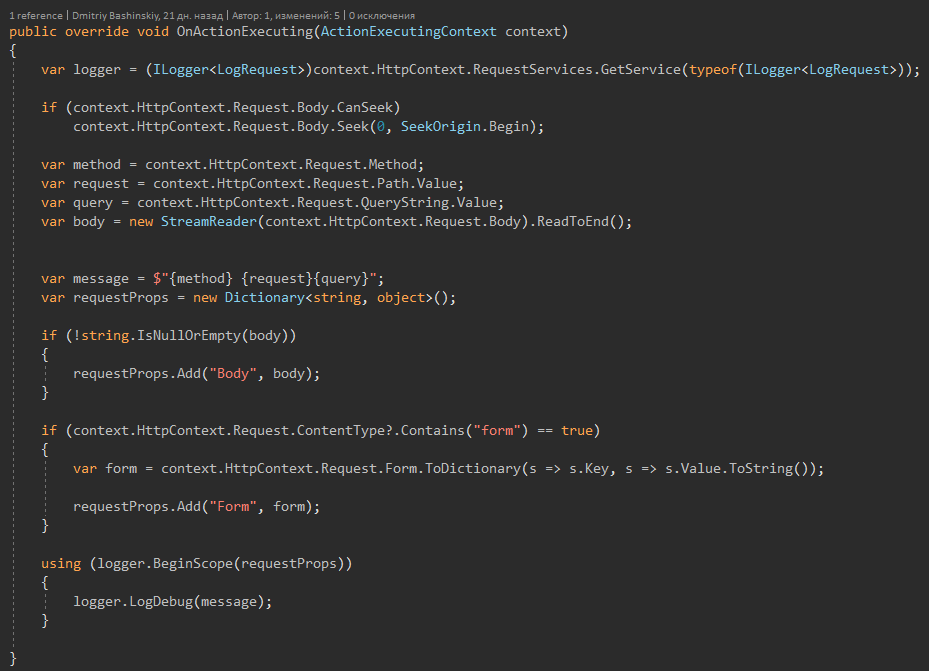
Каждый мой запрос легируется, при возникновении бага, я нахожу requestId и могу легко воспроизвести баг, повторив запрос, ведь у моего API нет состояния, и каждый запрос зависит только от параметров запроса.
Подведем итог.
Мы написали действительно решение, а не фреймворк в котором куча лишних абстракций, а так же моков. Мы сделали обработку ошибок в одном месте и те должны возникать очень редко. Мы отделили BL и сайд эффекты, теперь BL это просто локальная логика, которую можно переиспользовать. Мы не писали лишних функций которые просто пробрасывают вызов других функций. Буду активно читать комментарии и дополнять статью, спасибо!

