
Всем привет! Меня зовут Максим Рындин, я тимлид двух команд в Gett – Billing и Infrastructure. Хочу рассказать про продуктовую веб-разработку, которую мы в Gett ведем преимущественно на языке Go. Я расскажу, как в 2015-2017 годах мы переходили на этот язык, почему вообще его выбрали, с какими проблемами столкнулись во время перехода и какие решения нашли. А о текущей ситуации расскажу уже в следующей статье.
Для тех, кто не знает: Gett — это международный сервис заказа такси, который был основан в Израиле в 2011 году. Сейчас Gett представлен в 4 странах: Израиль, Великобритания, Россия и США. Основные продукты нашей компании — это мобильные приложения для клиентов и водителей, веб-портал для корпоративных клиентов, где можно заказать машину, и еще куча внутренних админок, через которые наши сотрудники настраивают тарифные планы, подключают новых водителей, мониторят случаи мошенничества и многое другое. В конце 2016 года в Москве открылся глобальный офис R&D, который работает в интересах всей компании.
Как мы пришли к Go
В 2011 году основной продукт компании представлял из себя монолитное приложение на Ruby on Rails, потому что в то время этот фреймворк был очень популярен. Были успешные примеры бизнесов, довольно быстро разработанных и запущенных на Ruby on Rails, поэтому он ассоциировался с успехом в бизнесе. Компания развивалась, к нам приходили новые водители и пользователи, нагрузки росли. И стали появляться первые проблемы.
Чтобы в клиентском приложении отображать местоположение машины, и чтобы её движение выглядело как плавная кривая, водители должны довольно часто посылать свои координаты. Поэтому конечная точка, отвечавшая за прием координат от водителей, практически всегда была самой высоконагруженной. А фреймворк веб-сервера в Ruby on Rails с этим справлялся плохо. Масштабироваться можно было только экстенсивно, добавляя новые серверы приложений, а это дорого и неэффективно. В итоге мы вынесли функциональный сбор координат в отдельный сервис, который изначально был написан на JS. На время это решило проблему. Однако по мере роста нагрузки, когда мы подошли к 80 тыс. RPM, сервис на Node.js перестал нас спасать.
Тогда мы объявили хакатон. У всех сотрудников в компании была возможность за день написать прототип, который должен был собирать координаты водителей. Здесь приведены бенчмарки двух версий того сервиса: работавшей на проде и переписанной на Go.
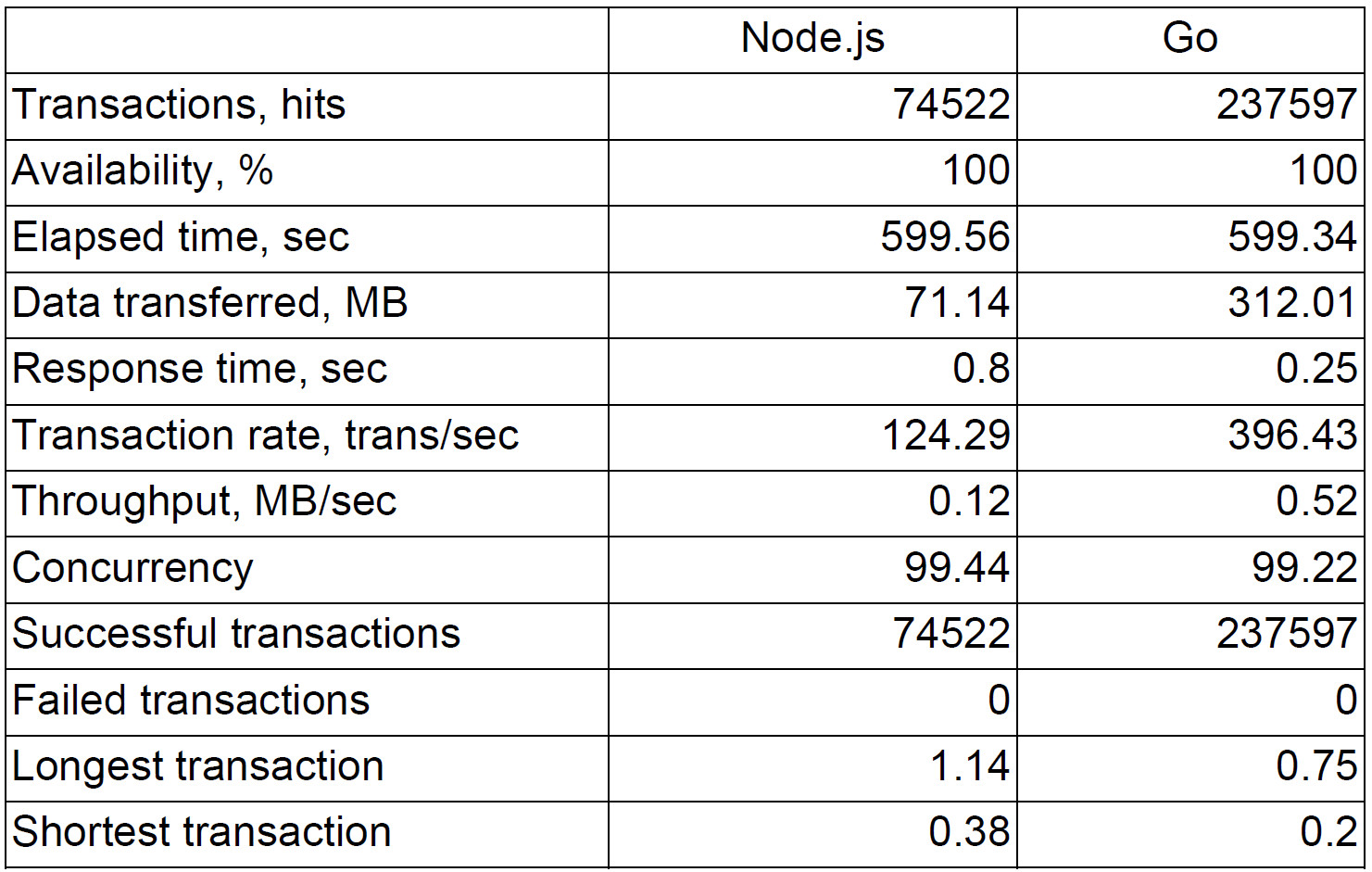
Практически по всем показателям сервис на Go показывал лучшие результаты. Cервис на Node.js использовал кластер, это технология использования всех ядер машины. То есть эксперимент был плюс-минус честным. Хотя Node.js имеет недостаток в виде однопоточного runtime’а, однако он никак не влиял на результаты.
Постепенно наши продуктовые запросы росли. Мы разрабатывали всё больше функциональности, и однажды столкнулись с такой проблемой: когда добавляешь какой-то кусочек кода в одном месте, то может что-то сломаться в другом месте, где проект сильно связан. Решили побороть эту напасть с помощью перехода на сервис-ориентированную архитектуру. Но в результате ухудшилась производительность: когда при исполнении кода интерпретатором Ruby on Rails встречается сетевой запрос, он блокируется и воркер простаивает. А операций сетевого ввода-вывода у нас становилось всё больше.
В результате мы решили принять Go в качестве одного из основных языков разработки.
Особенности нашей продуктовой разработки
Во-первых, у нас очень разные требования к продукту. Поскольку наши машины ездят в трёх странах с абсолютно разным законодательством, нужно реализовывать и очень сильно различающиеся наборы функциональности. Например, в Израиле законодательно требуется, чтобы стоимость поездки считал таксометр — это прибор, который проходит обязательную сертификацию раз в несколько лет. Когда водитель начинает поездку, то нажимает кнопку «поехали», а когда заканчивает, то нажимает кнопку «стоп», и вводит показанную таксометром цену в приложение.
В России таких жестких законов нет. Здесь мы можем сами настраивать политику формирования цены. Например, привязывать её к длительности поездки или к расстоянию. Порой, когда мы хотим реализовать одну и ту же функциональность, то сначала выкатываем её в одной стране, а потом адаптируем и выкатываем в других странах.
Наши продакт-менеджеры задают требования в виде продуктовых историй, мы стараемся придерживаться именно такого подхода. Это автоматически накладывает отпечаток и на тестирование: мы используем методологию behaviour driven-разработки, чтобы можно было проецировать поступающие продуктовые требования на тестовые ситуации. Так легче люди, далёкие от программирования, могут просто читать результаты тестов и понимать, что к чему.
Также мы хотели избавиться от дублирования каких-то работ. Ведь если у нас есть сервис, который реализует какую-то функциональность, и нам нужно написать второй сервис, заново решая все проблемы, которые мы решили в первом, заново интегрировать с инструментами мониторинга и миграции, то это будет неэффективно.
Решаем проблемы
Фреймворк
Ruby on Rails построен по архитектуре MVC. На момент перехода мы очень не хотели от неё отказываться, чтобы облегчить жизнь тем разработчикам, которые умеют программировать только на этом фреймворке. Смена инструментария и без того не добавляет комфорта, а если при этом ещё и меняешь архитектуру приложения, это всё равно, что человека, не умеющего плавать, столкнуть с лодки. Мы не хотели так травмировать разработчиков, поэтому взяли один из немногих на тот момент MVC-фреймворков, который называется Beego.
Попробовали с помощью Beego, как на Ruby on Rails, сделать серверный рендеринг. Однако отрисованная на сервере страница нам очень сильно не понравилась. Пришлось выкинуть один компонент, и сегодня Beego выдает с бэкенда только JSON, а всю отрисовку выполняет React на фронте.
Beego позволяет собирать проект автоматически. Некоторым разработчикам было очень тяжело переходить со скриптового языка к необходимости компилировать. Были смешные истории, когда человек реализовывал какую-то фичу, и только на код-ревью или вообще случайно узнавал, что, оказывается, нужно делать Go-сборку. А задача уже закрыта.
В Beego рутер генерируется из комментария, в который разработчик пишет путь к экшенам контроллеров. Отношение к этой идее у нас неоднозначное, потому что если в пути опечатка, — например, пересобрался рутер, — то тем, кто не искушен в таком подходе, тяжело найти ошибку. Люди, порой, не могли разобраться в причинах даже после нескольких часов увлекательного дебага.
База данных
В качестве БД мы используем PostgreSQL. Есть такая практика — контролировать схему базы данных из кода приложения. Это удобно по нескольким причинам: все о них знают; их легко развёртывать, база всегда синхронизирована с кодом. И эти плюшки мы тоже хотели сохранить.
Когда у вас есть несколько проектов и команд, иногда для реализации функциональности приходится залезать в чужие проекты. И бывает очень велик соблазн добавить в таблицу колонку, в которой может оказаться 10 млн записей. А человек, который не погружен в этот проект, может не догадываться о размере таблицы. Чтобы это предотвращать, мы сделали предупреждение об опасных миграциях, которые могут заблокировать базу на запись, и давали разработчикам средство, чтобы это предупреждение убрать.
Миграция
Мигрировать мы решили с помощью Swan, который представляет собой пропатченный goose, в который внесли пару доработок. Эти двое, как и многие инструменты миграции, всё хотят делать в одной транзакции, чтобы в случае проблем можно было легко откатиться. Иногда бывает, что нужно построить индекс, а таблица заблокировалась. В PostgreSQL есть параметр
concurrently, который позволяет этого избегать. Проблема в том, что если в PostgreSQL начинаешь строить индекс на этом concurrently, да ещё и в транзакции, то выскочит ошибка. Сначала мы хотели добавить флаг, чтобы не открывать транзакцию. А в итоге поступили так:COMMIT; CREATE INDEX CONCURRENTLY huge_index ON huge_table (column_one, column_two); BEGIN;
Теперь, когда кто-то добавляет индекс с параметром
concurrently, ему выпадает эта подсказка. Обратите внимание, commit и begin не перепутаны местами. Этот код закрывает транзакцию, которую открыл инструмент миграции, затем накатывает индекс с параметром concurrently, а после этого открывает еще одну транзакцию, чтобы инструмент что-то закрыл.Тестирование
Мы стараемся придерживаться behaviour driven-разработки. В Go это можно сделать с помощью инструмента Ginkgo. Он хорош тем, что в нем есть привычные для BDD ключевые слова, «describe», «when» и другие, а также позволяет просто проецировать текст, написанный продакт-менеджером, на тестовые ситуации, которые хранятся в исходном коде. Но мы столкнулись с проблемой: люди, которые пришли из мира Ruby on Rails, считают, что в любом языке программирования есть нечто, похожее на factory girl — фабрику для создания начальных условий. Однако в Go ничего подобного не было. В итоге мы решили, что не будем изобретать велосипед: просто перед каждым тестом, в хуках до и после выполнения теста наполняем базу нужными данными, а потом её чистим, чтобы не было побочных эффектов.
Мониторинг
Если у вас есть production-сервис, к которому обращаются люди, то нужно отслеживать его работу: нет ли пятисотых ошибок, быстро ли обрабатываются запросы. В мире Ruby on Rails для этого очень часто используют NewRelic, и многие наши разработчики хорошо им владели. Они понимали, как работает инструмент, куда нужно посмотреть, если есть какие-то проблемы. NewRelic позволяет анализировать время обработки запросов по HTTP, выявлять медленные внешние вызовы и запросы в базу данных, отслеживать потоки данных, предоставляет интеллектуальный анализ ошибок и выдаёт предупреждения.
В NewRelic есть агрегатная функция Apdex, которая зависит от гистограммы распределения длительности ответов и каких-то значений, которые вы считаете нормальными и которые задаются в самом начале. Эта функция также зависит от уровня ошибок в приложении. NewRelic вычисляет Apdex и выдаёт предупреждение, если её значение падает ниже какого-то уровня.
Также NewRelic хорош тем, что с недавнего времени появился официальный агент для Go. Вот так выглядит общий обзор мониторинга:

Слева диаграмма обработки запросов, каждый из которых разбит на сегменты. Сегменты включают в себя request queuing, обработку промежуточными обработчиками (middleware), длительность пребывания в интерпретаторе Ruby on Rails и обращения к хранилищам.
Справа сверху выводится график Apdex. Снизу справа — частота обработки запросов.
Интрига заключается в том, что в Ruby on Rails для подключения NewRelic нужно добавить одну строчку кода и дописать в конфигурацию свои учетные данные. И всё волшебным образом работает. Такое возможно благодаря тому, что в Ruby on Rails есть monkey patching, которого нет в Go, поэтому приходится много чего делать вручную.
В первую очередь мы хотели измерять длительность обработки запросов. Это удалось сделать с помощью хуков, которые предоставляет Beego.
beego.InsertFilter("*", beego.BeforeRouter, StartTransaction, false) beego.InsertFilter("*", beego.AfterExec, NameTransaction, false) beego.InsertFilter("*", beego.FinishRouter, EndTransaction, false)
Единственный нетривиальный момент заключался в том, что мы разделили открытие транзакции и её именование. Почему мы это сделали? Хотелось измерять длительность обработки запроса с учётом затрат времени на маршрутизацию. При этом нужны отчёты, агрегированные по конечным точкам, на которые приходили запросы. Но на момент открытия транзакции у нас пока еще не определен шаблон URL, по которому произойдет совпадение. Поэтому при поступлении запроса мы открываем транзакцию, затем на хуке, после выполнения контроллера, именуем её, а после отработки — закрываем. Поэтому сегодня наши отчёты выглядят так:

Мы использовали ORM под названием GORM, потому что хотелось сохранить абстракцию и не заставлять разработчиков писать чистый SQL. У этого подхода есть как достоинства, так и недостатки. В мире Ruby on Rails есть ORM Active Record, которая очень избаловала людей. Разработчики забывают о том, что можно писать чистый SQL, и оперируют только вызовами ORM.
db.Callback().Create().Before("gorm:begin_transaction"). Register("newrelicStart", startSegment) db.Callback().Create().After("gorm:commit_or_rollback_transaction"). Register("newrelicStop", endSegment)
Чтобы измерить длительность выполнения запросов в базе данных при использовании GORM, нужно взять объект
db. Вызов Callback говорит о том, что мы хотим зарегистрировать обратный вызов. Он должен вызываться при создании новой сущности — вызове Create. Затем укажем, когда именно нужно запускать Callback. За это отвечает Before с аргументом gorm: begin_transaction — это некоторая точка в момент открытия транзакции. Далее мы с именем newrelicStart регистрируем функцию startSegment, которая просто вызывает Go-агент и открывает новый сегмент обращения к базе данных.ORM вызовет эту функцию перед тем, как мы откроем транзакцию, и тем самым откроет сегмент. То же самое мы должны сделать для закрытия сегмента: просто навесим Callback.
Кроме PostgreSQL мы используем Redis, с которым тоже не всё гладко. Для этого мониторинга мы написали обертку над стандартным клиентом, и то же самое сделали для вызова внешних сервисов. Вот что получилось:
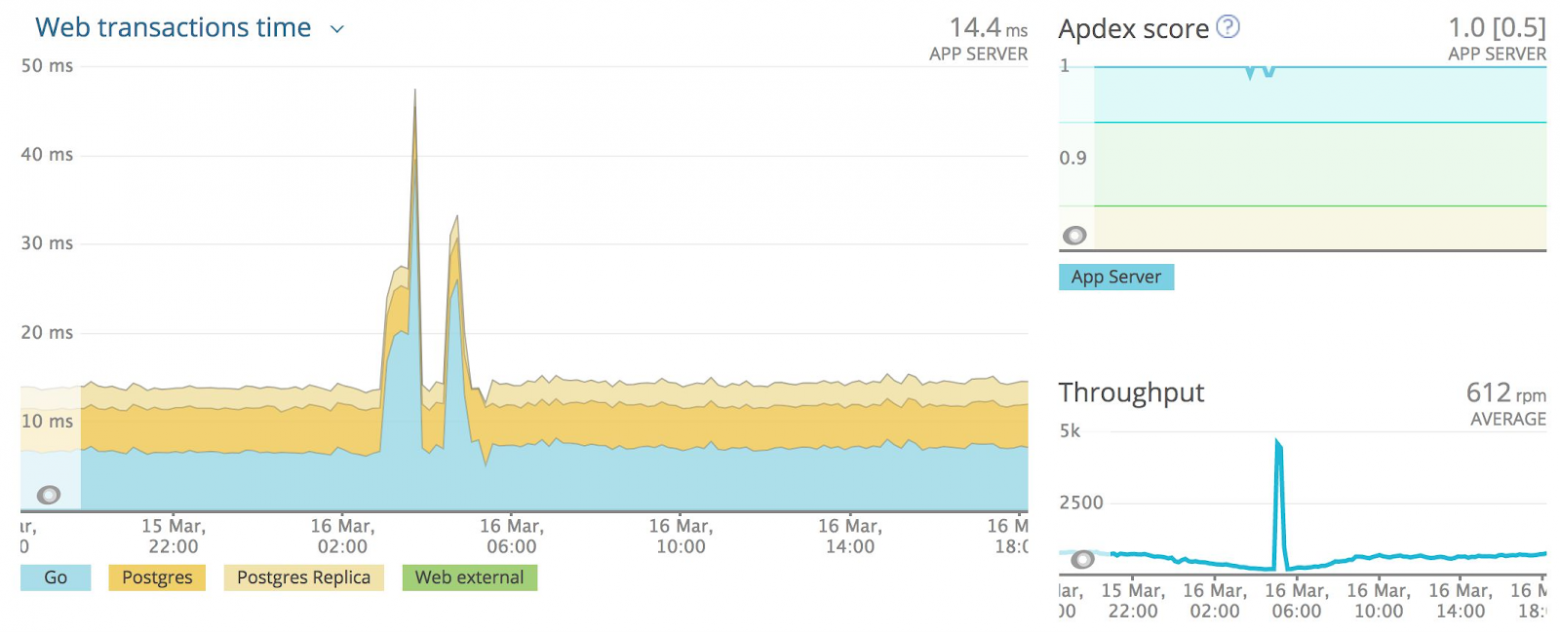
Так выглядит мониторинг для приложения, написанного на Go. Слева отчет по длительности обработки запросов, состоящей из сегментов: исполнение самого кода в Go, обращение к базам PostgreSQL и Replica. На этом графике не отображаются обращения ко внешним сервисам, потому что их очень мало и при усреднении просто незаметны. Также у нас есть информацию по Apdex и по частоте обработки запросов. В целом мониторинг получился довольно информативным и полезным для использования.
Что касается потоков данных, то благодаря нашим оберткам над HTTP-клиентом мы можем отслеживать запросы ко внешним сервисам. Здесь обозначена схема запросов сервиса promotion: он обращается к четырём другим нашим сервисам и двум хранилищам.

Заключение
Сегодня у нас более 75 % production-сервисов написаны на Go, активную разработку на Ruby не ведём, а только поддерживаем. И в связи с этим хочу отметить:
- Опасения, что скорость разработки уменьшится, не подтвердились. Программисты вливались в новую технологию каждый в своём режиме, но, в среднем, через пару недель активной работы разработка на Go становилась такой же предсказуемой и быстрой, как и на Ruby on Rails.
- Производительность приложений на Go под нагрузкой приятно удивляет по сравнению c прошлым опытом. Мы ощутимо сэкономили на использовании инфраструктуры в AWS, в разы уменьшив количество используемых инстансов.
- Смена технологии заметно взбодрила программистов, а это важная часть успешного проекта.
- Сегодня мы уже ушли от Beego и Gorm, подробнее об этом будет в следующей статье.
Резюмируя, хочу сказать, что если вы пишете не на Go, страдаете от проблем высоких нагрузок и соскучились по движухе — переходите на этот язык. Только не забудьте договориться с бизнесом.

