Всем привет. До старта курса «Machine Learning» остается чуть больше недели. В преддверии начала занятий мы подготовили полезный перевод, который будет интересен как нашим студентам, так и всем читателям блога. Начнем.

Пора избавиться от черных ящиков и укрепить веру в машинное обучение!
В своей книге “Interpretable Machine Learning” Кристоф Мольнар прекрасно выделяет суть интерпретируемости Машинного Обучения с помощью следующего примера: Представьте, что вы эксперт Data Science, и в свободное время пытаетесь спрогнозировать куда ваши друзья отправятся в отпуск летом, основываясь на их данных из facebook и twitter. Итак, если прогноз окажется верным, то ваши друзья будут считать вас волшебником, который может видеть будущее. Если прогнозы будут неверны, то это не принесет вреда ничему, кроме вашей репутации аналитика. Теперь представим, что это был не просто забавный проект, а к нему были привлечены инвестиции. Скажем, вы хотели инвестировать в недвижимость, где ваши друзья, вероятно, будут отдыхать. Что произойдёт, если предсказания модели будут неудачными? Вы потеряете деньги. Пока модель не оказывает существенного влияния, ее интерпретируемость не имеет большого значения, но когда есть финансовые или социальные последствия, связанные с предсказаниями модели, ее интерпретируемость приобретает совершенно другое значение.
Интерпретировать, значит, объяснить или показать в понятных терминах. В контексте ML-системы, интерпретируемость – это способность объяснить ее действие или показать его в понятном человеку виде.
Модели машинного обучения многие люди окрестили «черными ящиками». Это означает, что несмотря на то, что мы можем получить от них точный прогноз, мы не можем понятно объяснить или понять логику их составления. Но каким образом можно извлечь инсайты из модели? Какие вещи следует иметь в виду и какие инструменты нам понадобятся для этого? Это важные вопросы, которые приходят на ум, когда речь идет об интерпретируемости модели.
Вопрос, которым задаются некоторые люди, звучит как, почему бы просто не радоваться тому, что мы получаем конкретный результат работы модели, почему так важно знать, как было принято то или иное решение? Ответ кроется в том, что модель может оказывать определенное влияние на последующие события в реальном мире. Для моделей, которые предназначены для рекомендации фильмов интерпретируемость будет гораздо менее важна, чем для тех моделей, которые используются для прогнозирования результата воздействия медицинского препарата.
«Проблема заключается в том, что всего одна метрика, такая как точность классификации, является недостаточным описанием большинства реальных задач.» (Доши-Велес и Ким 2017)
Вот большая картинка про объяснимое машинное обучение. В каком-то смысле мы захватываем мир (а точнее информацию из него), собирая необработанные данные и используя их для дальнейших прогнозов. По сути, интерпретируемость – это всего лишь еще один слой модели, который помогает людям понять весь процесс.
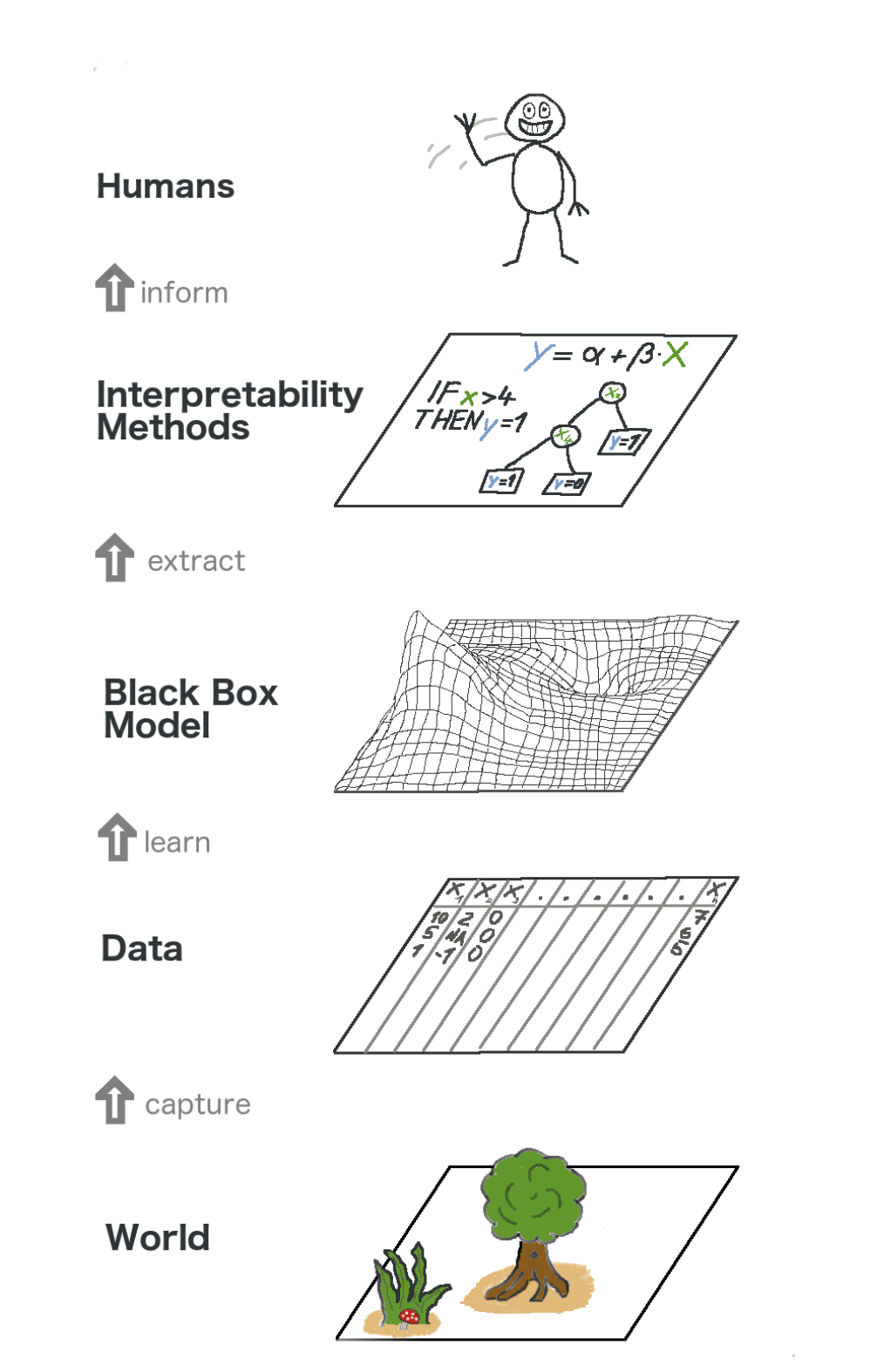
Текст на картинке снизу вверх: Мир -> Получение информации -> Данные -> Обучение -> Black Box модель -> Извлечение -> Методы интерпретации -> Люди
Некоторые из преимуществ, которые приносит интерпретируемость:
Теория имеет смысл только до тех пор, пока мы можем применять ее на практике. В случае, если вы действительно хотите разобраться с этой темой, можете попробовать пройти курс Machine Learning Explainability от Kaggle. В нем вы найдете правильное соотношение теории и кода, чтобы понять концепции и уметь применять на практике к реальным кейсам концепции интерпретируемости (объяснимости) моделей.
Нажмите на скриншот ниже, чтобы перейти непосредственно на страницу курса. Если вы хотите сначала получить краткий обзор темы, продолжайте чтение.

Для понимания модели нам потребуются следующие инсайты:
Давайте обсудим несколько методов, которые помогают извлекать вышеперечисленные инсайты из модели:
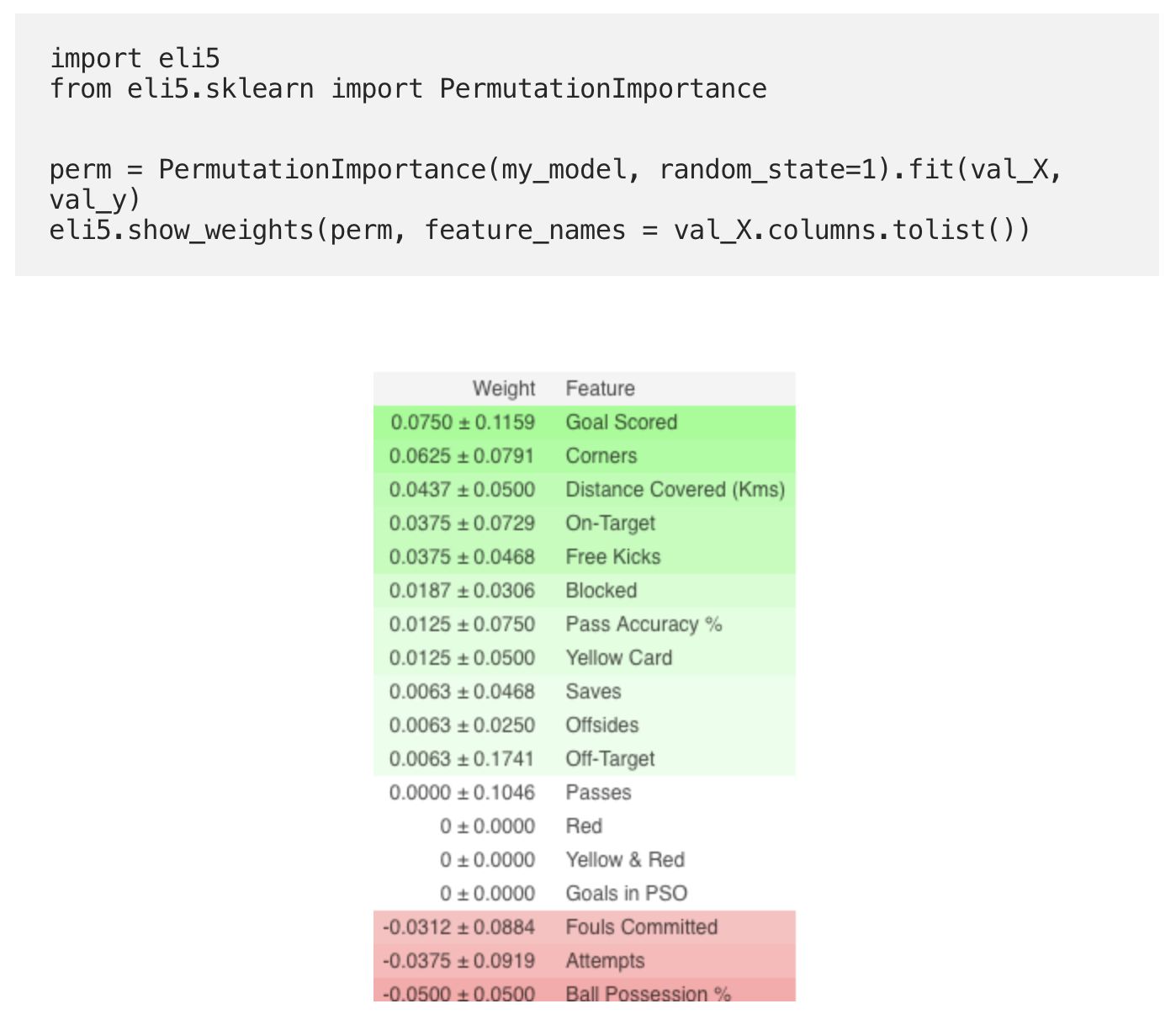
Какие признаки модель считает важными? Какие признаки оказывают наибольшее влияние? Эта концепция называется важностью признаков (feature importance), а Permutation Importance – это метод, широко используемый для вычисления важности признаков. Он помогает нам увидеть, в какой момент модель выдает неожиданные результаты, он же помогает нам показать другим, что наша модель работает именно так, как нужно.
Permutation Importance работает для многих оценок scikit-learn. Идея проста: Произвольным образом переставить или перетасовать один столбец в наборе датасета валидации, оставив все остальные столбцы нетронутыми. Признак считается «важным», если точность модели падает и его изменение вызывает увеличение ошибок. С другой стороны, признак считается «неважным», если перетасовка его значений не влияет на точность модели.
Рассмотрим модель, которая предсказывает, получит ли футбольная команда награду “Man of the Game” или нет, на основе определенных параметров. Эту награду получает игрок, который демонстрирует лучшие навыки игры.
Permutation Importance вычисляется после обучения модели. Итак, давайте обучим и подготовим модель
Permutation Importance вычисляется с использованием библиотеки ELI5. ELI5 – это библиотека в Python, которая позволяет визуализировать и отлаживать различные модели машинного обучения с помощью унифицированного API. Она имеет встроенную поддержку для нескольких ML-фреймворков и обеспечивает способы интерпретации black-box модели.
Вычисление и визуализация важности с помощью библиотеки ELI5:
(Здесь
А теперь, чтобы посмотреть на полный пример и проверить правильно ли вы все поняли, перейдите на страницу Kaggle по ссылке.
Вот и подошла к концу первая часть перевода. Пишите ваши комментарии и дл встречи на курсе!
Читать вторую часть.
Пора избавиться от черных ящиков и укрепить веру в машинное обучение!
В своей книге “Interpretable Machine Learning” Кристоф Мольнар прекрасно выделяет суть интерпретируемости Машинного Обучения с помощью следующего примера: Представьте, что вы эксперт Data Science, и в свободное время пытаетесь спрогнозировать куда ваши друзья отправятся в отпуск летом, основываясь на их данных из facebook и twitter. Итак, если прогноз окажется верным, то ваши друзья будут считать вас волшебником, который может видеть будущее. Если прогнозы будут неверны, то это не принесет вреда ничему, кроме вашей репутации аналитика. Теперь представим, что это был не просто забавный проект, а к нему были привлечены инвестиции. Скажем, вы хотели инвестировать в недвижимость, где ваши друзья, вероятно, будут отдыхать. Что произойдёт, если предсказания модели будут неудачными? Вы потеряете деньги. Пока модель не оказывает существенного влияния, ее интерпретируемость не имеет большого значения, но когда есть финансовые или социальные последствия, связанные с предсказаниями модели, ее интерпретируемость приобретает совершенно другое значение.
Объяснимое машинное обучение
Интерпретировать, значит, объяснить или показать в понятных терминах. В контексте ML-системы, интерпретируемость – это способность объяснить ее действие или показать его в понятном человеку виде.
Модели машинного обучения многие люди окрестили «черными ящиками». Это означает, что несмотря на то, что мы можем получить от них точный прогноз, мы не можем понятно объяснить или понять логику их составления. Но каким образом можно извлечь инсайты из модели? Какие вещи следует иметь в виду и какие инструменты нам понадобятся для этого? Это важные вопросы, которые приходят на ум, когда речь идет об интерпретируемости модели.
Важность интерпретируемости
Вопрос, которым задаются некоторые люди, звучит как, почему бы просто не радоваться тому, что мы получаем конкретный результат работы модели, почему так важно знать, как было принято то или иное решение? Ответ кроется в том, что модель может оказывать определенное влияние на последующие события в реальном мире. Для моделей, которые предназначены для рекомендации фильмов интерпретируемость будет гораздо менее важна, чем для тех моделей, которые используются для прогнозирования результата воздействия медицинского препарата.
«Проблема заключается в том, что всего одна метрика, такая как точность классификации, является недостаточным описанием большинства реальных задач.» (Доши-Велес и Ким 2017)
Вот большая картинка про объяснимое машинное обучение. В каком-то смысле мы захватываем мир (а точнее информацию из него), собирая необработанные данные и используя их для дальнейших прогнозов. По сути, интерпретируемость – это всего лишь еще один слой модели, который помогает людям понять весь процесс.
Текст на картинке снизу вверх: Мир -> Получение информации -> Данные -> Обучение -> Black Box модель -> Извлечение -> Методы интерпретации -> Люди
Некоторые из преимуществ, которые приносит интерпретируемость:
- Надежность;
- Удобство отладки;
- Информирование об инженерии признаков;
- Управление сбором данных для признаков;
- Информирование о принятии решений;
- Выстраивание доверия.
Методы Интерпретации моделей
Теория имеет смысл только до тех пор, пока мы можем применять ее на практике. В случае, если вы действительно хотите разобраться с этой темой, можете попробовать пройти курс Machine Learning Explainability от Kaggle. В нем вы найдете правильное соотношение теории и кода, чтобы понять концепции и уметь применять на практике к реальным кейсам концепции интерпретируемости (объяснимости) моделей.
Нажмите на скриншот ниже, чтобы перейти непосредственно на страницу курса. Если вы хотите сначала получить краткий обзор темы, продолжайте чтение.
Инсайты, которые можно извлечь из моделей
Для понимания модели нам потребуются следующие инсайты:
- Наиболее важные признаки в модели;
- Для любого конкретного прогноза модели влияние каждого отдельного признака на конкретный прогноз.
- Влияние каждого признака на большое количество возможных прогнозов.
Давайте обсудим несколько методов, которые помогают извлекать вышеперечисленные инсайты из модели:
Permutation Importance
Какие признаки модель считает важными? Какие признаки оказывают наибольшее влияние? Эта концепция называется важностью признаков (feature importance), а Permutation Importance – это метод, широко используемый для вычисления важности признаков. Он помогает нам увидеть, в какой момент модель выдает неожиданные результаты, он же помогает нам показать другим, что наша модель работает именно так, как нужно.
Permutation Importance работает для многих оценок scikit-learn. Идея проста: Произвольным образом переставить или перетасовать один столбец в наборе датасета валидации, оставив все остальные столбцы нетронутыми. Признак считается «важным», если точность модели падает и его изменение вызывает увеличение ошибок. С другой стороны, признак считается «неважным», если перетасовка его значений не влияет на точность модели.
Как это работает?
Рассмотрим модель, которая предсказывает, получит ли футбольная команда награду “Man of the Game” или нет, на основе определенных параметров. Эту награду получает игрок, который демонстрирует лучшие навыки игры.
Permutation Importance вычисляется после обучения модели. Итак, давайте обучим и подготовим модель
RandomForestClassifier, обозначенную как my_model, на обучающих данных.Permutation Importance вычисляется с использованием библиотеки ELI5. ELI5 – это библиотека в Python, которая позволяет визуализировать и отлаживать различные модели машинного обучения с помощью унифицированного API. Она имеет встроенную поддержку для нескольких ML-фреймворков и обеспечивает способы интерпретации black-box модели.
Вычисление и визуализация важности с помощью библиотеки ELI5:
(Здесь
val_X,val_y обозначают соответственно наборы валидации)Интерпретация
- Признаки сверху – наиболее важные, снизу – наименее. Для этого примера, самым важным признаком были забитые голы.
- Число после ± отражает, как производительность изменялась от одной перестановки к другой.
- Некоторые веса отрицательны. Это связано с тем, что в этих случаях прогнозы по перетасованным данным оказались более точными, чем реальные данные.
Практика
А теперь, чтобы посмотреть на полный пример и проверить правильно ли вы все поняли, перейдите на страницу Kaggle по ссылке.
Вот и подошла к концу первая часть перевода. Пишите ваши комментарии и дл встречи на курсе!
Читать вторую часть.

