Всем привет. Считанные дни остаются до старта курса «Machine Learning». В преддверии начала занятий мы подготовили полезный перевод, который будет интересен как нашим студентам, так и всем читателям блога. И сегодня делимся с вами завершающей частью данного перевода.

Partial Dependence Plots (графики частичной зависимости или же PDP, PD-графики) показывают незначительное влияние одного или двух признаков на прогнозируемый результат модели машинного обучения ( J. H. Friedman 2001 ). PDP может показать связь между целью и выбранными признаками с помощью 1D или 2D графиков.
PDP также высчитываются уже после того, как модель обучена. В задаче с футболом, которую мы обсуждали выше, было много признаков, таких как переданные пассы, попытки забить в ворота, забитые голы и т.д. Начнем с рассмотрения одной строки. Скажем строка представляет из себя команду, у которой мяч был 50% времени, которая сделала 100 передач, 10 попыток забить и 1 гол.
Мы действуем, обучая нашу модель и вычисляя вероятность того, что у команды есть игрок, который получил “Man of the Game”, что является нашей целевой переменной. Затем мы выбираем переменную и непрерывно изменяем ее значение. Например, мы рассчитаем результат, при условии, что команда забила 1 гол, 2 гола, 3 гола и т.д. Все эти значения отражаются на графике, в итоге мы получаем график зависимости прогнозируемых результатов от забитых голов.
Мы также можем визуализировать частичную зависимость двух признаков одновременно, используя 2D графики.
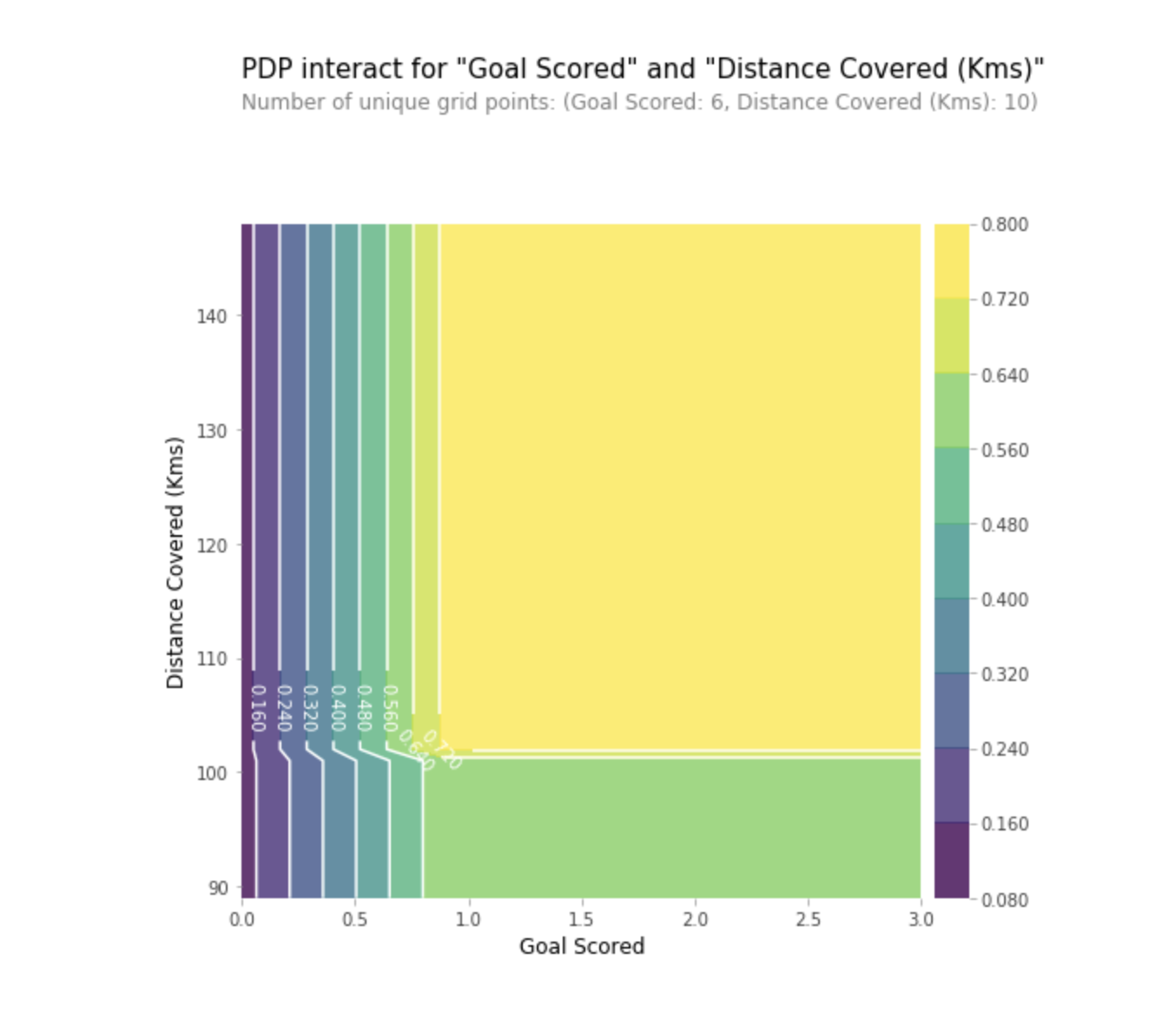
Практика
SHAP расшифровывается как SHapley Additive explanation. Этот метод помогает разбить на части прогноз, чтобы выявить значение каждого признака. Он основан на Векторе Шепли, принципе, используемом в теории игр для определения, насколько каждый игрок при совместной игре способствует ее успешному исходу (https://medium.com/civis-analytics/demystifying-black-box-models-with-shap-value-analysis-3e20b536fc80). Как правило, нахождение компромисса между точностью и интерпретируемостью может оказаться трудным балансом, однако значения SHAP могут обеспечить и то, и другое.
И снова вернемся к примеру с футболом, где мы хотели предсказать вероятность того, что в команде есть игрок, который выиграл награду “Man of the Game”. SHAP – значения интерпретируют влияние определенного значения признака в сопоставлении с прогнозом, которое мы сделали бы, если бы этот признак принял бы некоторое базовое значение.
SHAP – значения показывают, насколько данный конкретный признак изменил наше предсказание (по сравнению с тем, как мы сделали бы это предсказание при некотором базовом значении этого признака). Допустим, мы хотели узнать, каким был бы прогноз, если бы команда забила 3 гола, вместо фиксированного базового количества. Если мы можем ответить на этот вопрос, мы можем выполнить те же шаги для других признаков следующим образом:
Следовательно, прогноз может быть представлен в виде следующего графика:

Вот ссылка на большую картинку.
В примере выше показаны признаки, каждый из которых способствует перемещению выходных данных модели при базовом значении (среднестатистические выходные данные модели по датасету для обучения, который мы передали в нее ранее) в окончательные выходные данные модели. Признаки, продвигающие прогноз выше, показаны красным цветом, а те, что понижают его точность – ниже.
SHAP – значения имеют гораздо более глубокое теоретическое обоснование, чем то, что я затронул здесь. Для лучшего понимания вопроса, пройдите по ссылке.
Агрегирование множества SHAP-значений поможет сформировать более детальное представление о модели.
Чтобы получить представление о том, какие признаки наиболее важны для модели, мы можем построить SHAP – значения для каждого признака и для каждой выборки. Сводный график показывает, какие признаки являются наиболее важными, а также их диапазон влияния на датасет.

Для каждой точки:
Точка в левом верхнем углу означает команду, которая забила несколько голов, но уменьшила вероятность успешного прогноза на 0,25.
В то время, как сводный график SHAP дает общий обзор каждого признака, график зависимости SHAP показывает, как выходные данные модели зависят от значения признака. График зависимости вклада SHAP обеспечивает аналогичное PDP понимание, но добавляет больше деталей.
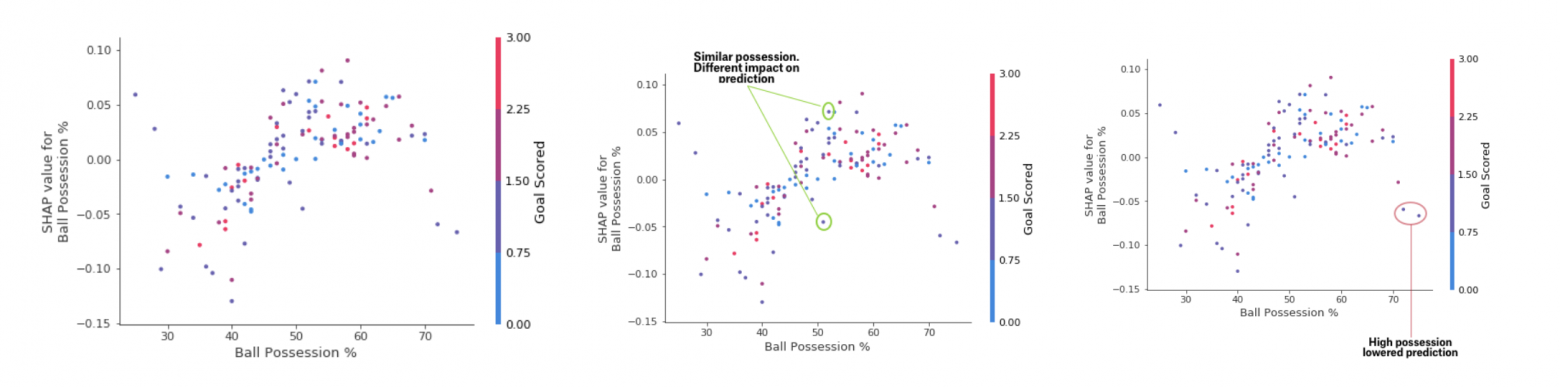
График зависимости от вклада
Графики, представленные выше, говорят о том, что наличие меча увеличивает шансы команды на то, что именно их игрок получит награду. Но если команда забивает всего один гол, то эта тенденция меняется, поскольку судьи могут решить, что игроки команды слишком долго держат у себя мяч, и слишком мало голов забивают.
Практика
Машинное обучение больше не должно быть черным ящиком. Какая польза от хорошей модели, если мы не моем объяснить результаты ее работы другим? Интерпретируемость стала такой же важной, как и качество модели. Для того, чтобы добиться признания, крайне важно, чтобы системы машинного обучения могли предоставить понятные объяснения своих решений. Как сказал Альберт Эйнштейн: «Если вы не можете объяснить что-то простым языком, вы этого не понимаете».
Источники:
Читать первую часть
Partial Dependence Plots
Partial Dependence Plots (графики частичной зависимости или же PDP, PD-графики) показывают незначительное влияние одного или двух признаков на прогнозируемый результат модели машинного обучения ( J. H. Friedman 2001 ). PDP может показать связь между целью и выбранными признаками с помощью 1D или 2D графиков.
Как это работает?
PDP также высчитываются уже после того, как модель обучена. В задаче с футболом, которую мы обсуждали выше, было много признаков, таких как переданные пассы, попытки забить в ворота, забитые голы и т.д. Начнем с рассмотрения одной строки. Скажем строка представляет из себя команду, у которой мяч был 50% времени, которая сделала 100 передач, 10 попыток забить и 1 гол.
Мы действуем, обучая нашу модель и вычисляя вероятность того, что у команды есть игрок, который получил “Man of the Game”, что является нашей целевой переменной. Затем мы выбираем переменную и непрерывно изменяем ее значение. Например, мы рассчитаем результат, при условии, что команда забила 1 гол, 2 гола, 3 гола и т.д. Все эти значения отражаются на графике, в итоге мы получаем график зависимости прогнозируемых результатов от забитых голов.
Библиотека, используемая в Python для построения PDP называется python partial dependence plot toolbox или просто PDPbox.
from matplotlib import pyplot as plt from pdpbox import pdp, get_dataset, info_plots # Create the data that we will plot pdp_goals = pdp.pdp_isolate(model=my_model, dataset=val_X, model_features=feature_names, feature='Goal Scored') # plot it pdp.pdp_plot(pdp_goals, 'Goal Scored') plt.show()
Интерпретация
- Ось Y отражает изменение прогноза вследствие того, что было предсказано в исходном или в крайнем левом значении.
- Синяя область обозначает интервал доверия.
- Для графика «Goal Scored» мы видим, что забитый гол увеличивает вероятность получения награды ‘Man of the game’, но через некоторое время происходит насыщение.
Мы также можем визуализировать частичную зависимость двух признаков одновременно, используя 2D графики.
Практика
SHAP-значения
SHAP расшифровывается как SHapley Additive explanation. Этот метод помогает разбить на части прогноз, чтобы выявить значение каждого признака. Он основан на Векторе Шепли, принципе, используемом в теории игр для определения, насколько каждый игрок при совместной игре способствует ее успешному исходу (https://medium.com/civis-analytics/demystifying-black-box-models-with-shap-value-analysis-3e20b536fc80). Как правило, нахождение компромисса между точностью и интерпретируемостью может оказаться трудным балансом, однако значения SHAP могут обеспечить и то, и другое.
Как это работает?
И снова вернемся к примеру с футболом, где мы хотели предсказать вероятность того, что в команде есть игрок, который выиграл награду “Man of the Game”. SHAP – значения интерпретируют влияние определенного значения признака в сопоставлении с прогнозом, которое мы сделали бы, если бы этот признак принял бы некоторое базовое значение.
SHAP – значения рассчитываются с помощью библиотеки Shap, которую можно легко установить из PyPI или conda.
SHAP – значения показывают, насколько данный конкретный признак изменил наше предсказание (по сравнению с тем, как мы сделали бы это предсказание при некотором базовом значении этого признака). Допустим, мы хотели узнать, каким был бы прогноз, если бы команда забила 3 гола, вместо фиксированного базового количества. Если мы можем ответить на этот вопрос, мы можем выполнить те же шаги для других признаков следующим образом:
sum(SHAP values for all features) = pred_for_team - pred_for_baseline_values
Следовательно, прогноз может быть представлен в виде следующего графика:
Вот ссылка на большую картинку.
Интерпретация
В примере выше показаны признаки, каждый из которых способствует перемещению выходных данных модели при базовом значении (среднестатистические выходные данные модели по датасету для обучения, который мы передали в нее ранее) в окончательные выходные данные модели. Признаки, продвигающие прогноз выше, показаны красным цветом, а те, что понижают его точность – ниже.
- Базовое значение здесь 0.4979, тогда как спрогнозированное 0.7.
- При
Goal Scores= 2 проявляется наибольшее влияние признака на улучшение прогноза, тогда как - Признак
ball possessionимеет самый высокий эффект понижения конечного прогноза.
Практика
SHAP – значения имеют гораздо более глубокое теоретическое обоснование, чем то, что я затронул здесь. Для лучшего понимания вопроса, пройдите по ссылке.
Продвинутое использование SHAP-значений
Агрегирование множества SHAP-значений поможет сформировать более детальное представление о модели.
- Сводные графики SHAP
Чтобы получить представление о том, какие признаки наиболее важны для модели, мы можем построить SHAP – значения для каждого признака и для каждой выборки. Сводный график показывает, какие признаки являются наиболее важными, а также их диапазон влияния на датасет.
Для каждой точки:
- Вертикальное расположение показывает, какой признак она отражает;
- Цвет показывает, является ли этот объект сильно значимым или слабо значимым для этой строки датасета;
- Горизонтальное расположение показывает, привело ли влияние значения этого признака к более точному прогнозу или нет.
Точка в левом верхнем углу означает команду, которая забила несколько голов, но уменьшила вероятность успешного прогноза на 0,25.
- График зависимости от вклада SHAP
В то время, как сводный график SHAP дает общий обзор каждого признака, график зависимости SHAP показывает, как выходные данные модели зависят от значения признака. График зависимости вклада SHAP обеспечивает аналогичное PDP понимание, но добавляет больше деталей.
График зависимости от вклада
Графики, представленные выше, говорят о том, что наличие меча увеличивает шансы команды на то, что именно их игрок получит награду. Но если команда забивает всего один гол, то эта тенденция меняется, поскольку судьи могут решить, что игроки команды слишком долго держат у себя мяч, и слишком мало голов забивают.
Практика
Заключение
Машинное обучение больше не должно быть черным ящиком. Какая польза от хорошей модели, если мы не моем объяснить результаты ее работы другим? Интерпретируемость стала такой же важной, как и качество модели. Для того, чтобы добиться признания, крайне важно, чтобы системы машинного обучения могли предоставить понятные объяснения своих решений. Как сказал Альберт Эйнштейн: «Если вы не можете объяснить что-то простым языком, вы этого не понимаете».
Источники:
- «Interpretable Machine Learning: A Guide for Making Black Box Models Explainable.» Christoph Molnar
- Курс Machine Learning Explainability Micro Course на Kaggle
Читать первую часть


{kind=link}