
Новая работа Google предлагает архитектуру нейронных сетей, способных имитировать врожденные инстинкты и рефлексы живых существ, с последующим дообучением в течение жизни.
А также значительно уменьшающую количество связей внутри сети, повышая тем самым их быстродействие.
Искусственные нейронные сети, хоть и похожи по принципу действия на биологические, все же слишком отличаются от них, чтобы их можно было применить в чистом виде для создания сильного ИИ. Например, сейчас нельзя создать в симуляторе модель человека (или мыши, или даже насекомого), дать ему "мозг" в виде современной нейронной сети и обучить ее. Это просто так не работает.
Даже отбросив отличия в механизме обучения (в мозге нет точного аналога алгоритма обратного распространения ошибки, например) и отсутствие разномасштабных временных корреляций, на основании которых биологический мозг строит свою работу, у искусственных нейронных сетей есть еще несколько проблем, не позволяющих им в достаточной степени имитировать живой мозг. Вероятно, из-за этих врожденных проблем используемого сейчас математического аппарата, обучение с подкреплением (Reinforcement Learning), призванное максимально имитировать обучение живых существ на основе награды, на практике работает далеко не так хорошо, как хотелось бы. Хотя в его основе лежат действительно хорошие и правильные идеи. Сами разработчики шутят, что мозг — это RNN + A3C (т.е. рекуррентная сеть + алгоритм актер-критик для ее обучения).
Одним из самых заметных отличий биологического мозга от искусственных нейронных сетей является то, что структура живого мозга преднастроена миллионами лет эволюции. И хотя неокортекс, отвечающий за высшую нервную деятельность у млекопитающих, имеет примерно однородную структуру, общая структура мозга явно задана генами. Более того, отличные от млекопитающих животные (птицы, рыбы) вообще не имеют неокортекса, но при этом демонстрируют сложное поведение, недостижимое современными нейронными сетями. У человека тоже имеются физические ограничения в структуре мозга, которые сложно объяснить. Например, разрешение одного глаза примерно 100 Мп (~100 млн светочувствительных палочек и колбочек), а значит от двух глаз видеопоток должен быть около 200 Мп с частотой не менее 15 кадров в секунду. Но в реальности зрительный нерв способен пропустить через себя не более 2-3 Мп. И его соединения направлены вовсе не к ближайшей части мозга, а в затылочную часть в зрительную кору.
Поэтому не умаляя значения неокортекса (его, грубо говоря, при рождении можно считать аналогом случайно инициированных современных нейронных сетей), факты говорят о том, что даже у человека огромную роль играет заранее заданная структура мозга. К примеру, если младенцу родом всего несколько минут показать язык, то благодаря зеркальным нейронам, он тоже высунет язык. Аналогично происходит с детским смехом. Хорошо известно, что у младенцев с рождения "вшито" превосходное распознавание человеческих лиц. Но что еще важнее, нервная система всех живых существ оптимизирована для условий их жизни. Младенец не будет часами кричать, если голоден. Он устанет. Или испугается чего-то и замолчит. Лиса не будет до полного изнеможения вплоть до голодной смерти тянуться за недоступным виноградом. Она сделает несколько попыток, решит что он горький(с) и уйдет. И это не процесс обучения, а заранее заданное биологией поведение. Причем у разных видов разное. Некоторые хищники сразу бросаются за добычей, а другие долго сидят в засаде. И они этому выучились не в процессе проб и ошибок, а такова их биология, заданная инстинктами. Аналогично, многие животные имеют вшитые программы избегания хищников начиная с первых минут жизни, хотя они физически еще не могли их выучить.
Теоретически, современные способы обучения нейросетей способны из полносвязной сети создать подобие такого предобученного мозга, обнулив ненужные связи (по сути, обрезав их) и оставив только нужные. Но для этого нужно огромное количество примеров, неизвестно как их обучать, а главное — на данный момент не существует хороших способов зафиксировать эту "начальную" структуру мозга. Последующее обучение изменяет эти веса и все портится.
Исследователи из Google тоже задались этим вопросом. Нельзя ли создать начальную структуру мозга, аналогичную биологической, то есть уже хорошо оптимизированную для решения задачи, а потом лишь дообучить ее? Теоретически, это резко сузит пространство решений и позволит быстрее обучать нейросети.
К сожалению, существующие алгоритмы оптимизации структуры сети, такие как Neural Architecture Search (NAS), оперируют целыми блоками. После добавления или удаления которых, нейросеть приходится обучать заново с нуля. Это ресурсоемкий процесс и не полностью решает проблему.
Поэтому исследователи предложили упрощенную версию, которая получила название "Weight Agnostic Neural Networks" (WANN). Идея заключается в том, чтобы заменить все веса нейросети одним "общим" весом. И в процессе обучения подбирать не веса между нейронами, как в обычных нейросетях, а подбирать структуру самой сети (количество и расположение нейронов), которая с одинаковыми весами показывает наилучшие результаты. А после еще и оптимизировать ее, чтобы сеть хорошо работала со всеми возможными значениями этого общего веса (общим для всех соединений между нейронами!).
В итоге это дает структуру нейронной сети, которая не зависит от конкретных значений весов, а работает хорошо со всеми. Потому что работает за счет общей структуры сети. Это похоже на еще не инициализированный конкретными весами мозг животного при рождении, но уже содержащий вшитые инстинкты за счет своей общей структуры. А последующая тонкая настройка весов во время обучения в течение жизни, делает эту нейросеть еще лучше.
Побочным положительным эффектом такого подхода является значительное уменьшение числа нейронов в сети (так как остаются только наиболее важные соединения), что увеличивает ее быстродействие. Ниже сравнение сложности классической полносвязной нейросети (слева) и подобранной новой (справа).
Для поиска такой архитектуры исследователи воспользовались алгоритмом Topology search algorithm (NEAT). Сначала создается набор простых нейросетей, а потом делается одно из трех действий: добавляется новый нейрон в существующее соединение между двумя нейронами, добавляется новое соединение со случайными другим нейроном, либо меняется функция активации в нейроне (см. рисунки ниже). А дальше, в отличие от классических NAS, где ищутся оптимальные веса между нейронами, здесь все веса инициализируются одним единственным числом. И оптимизация осуществляется для поиска структуры сети, которая лучше всех работает в широком диапазоне значений этого одного общего веса. Таким образом получается сеть, которая не зависит от конкретного веса между нейронами, а хорошо работает во всем диапазоне (но все веса по-прежнему инициируется одним числом, а не разными как в обычных сетях). При этом в качестве дополнительной цели для оптимизации стараются минимизировать число нейронов в сети.

Ниже представлена общая схема алгоритма.

- создается популяция простых нейросетей
- каждая сеть инициализирует все свои веса одним числом, причем для широкого диапазона чисел: w=-2...+2
- полученные сети сортируются по качеству решения задачи и по числу нейронов (в сторону уменьшения)
- в части лучших представителей добавляется один нейрон, одна связь или меняется функция активации в одном нейроне
- эти модифицированные сети используются в качестве начальных в пункте 1)
Все это хорошо, но для нейронных сетей предложены сотни, если не тысячи разных идей. Работает ли это на практике? Да, работает. Ниже пример результата поиска такой архитектуры сети для классической задачи тележки с обратным маятником. Как видно из рисунка, нейросеть неплохо работает со всеми вариантами общего веса (лучше с +1.0, но с -1.5 тоже пытается поднять маятник). А после оптимизации этого единственного веса, начинает работать вообще идеально (вариант Fine-Tuned Weights на рисунке).
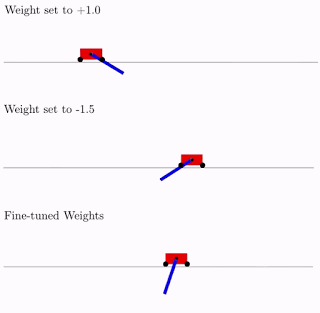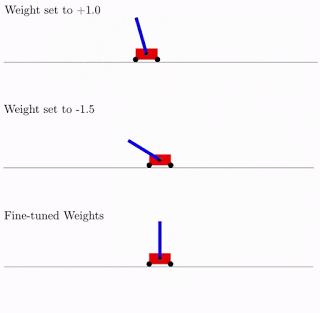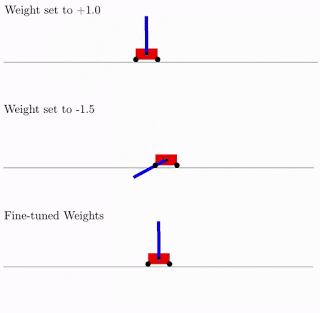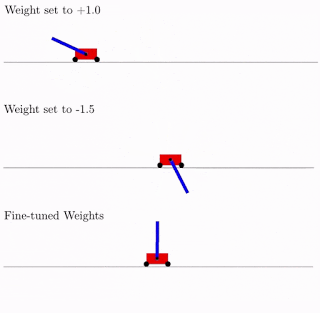
Что характерно, дообучать можно как этот единственный общий вес, так как подбор архитектуры делается на ограниченном дискретном числе параметров (в примере выше -2,-1,1,2). А получить можно в итоге более точный оптимальный параметр, скажем, 1.5. А можно лучший общий вес использовать как начальную точку для дообучения всех весов, как в классическом обучении нейросетей.
Это похоже на то, как обучаются животные. Имея при рождении близкие к оптимальным инстинкты, и используя эту заданную генами структуру мозга как начальную, в процессе своей жизни животные дообучают свой мозг под конкретные внешние условия. Подробнее в недавней статье в журнале Nature.
Ниже пример найденной WANN сети для задачи управления машинкой на основе пикселей. Обратите внимание, что это езда на "голых инстинктах", с единым общим весом во всех соединениях, без классической точной настройки всех весов. При этом нейросеть получается крайне простой по своей структуре.


Другим вариантом использования WANN исследователи предлагают создавать ансамбли из WANN сетей. Так, обычная случайно инициализированная нейросеть на MNIST показывает точность около 10%. Подобранная единичная WANN нейросеть выдает около 80%, но ансамбль из WANN с разными общими весами, показывает уже >90%.
Как итог, предложенный исследователями из Google способ поиска начальной архитектуры оптимальной нейросети не только имитирует обучение животных (рождение со встроенными оптимальными инстинктами и дообучение в течение жизни), но также позволяет избежать симуляции всей жизни животных с полноценным обучением всей сети в классических эволюционных алгоритмах, создавая сразу простые и быстрые сети. Которые достаточно лишь слегка дообучить, чтобы получить полностью оптимальную нейросеть.

