Когда в нашей стране люди слышат название компании NEC первым делом люди старшего поколения вспоминают вот это:

Те кто чуть моложе вот это:

(под катом много картинок)
Звучит примерно как «Эн-и-си». А на английском это расшифровывается как Nippon Electric Corporation. Хотя у нас в стране обычно произносят как НЭК :).

Компания была зарегистрирована в Токио в 1899 году и первые годы занималась производством телефонного оборудования.
Сегодня NEC производит довольно большой спектр решений, ознакомиться с которыми можно на официальном сайте компании

Но мне хотелось бы рассказать уважаемому сообществу о линейке систем хранения для резервных копий с дедупликацией NEC HYDRAstor и в первую очередь о старшем семействе HS8.
Что меня удивило с самого начала, так это то, что вышло уже 5-ое поколение этих систем, а в России про них почти ничего не известно. По крайней мере общаясь с людьми из вендоров, интеграторов или заказчиков я чаще видел удивление в качестве первой реакции при упоминании этих решений.
На картинках ниже представлен актуальный модельный ряд NEC HYDRAstor HS8 и основные характеристики моделей.

СХД HYDRAstor – это системы построенные на базе scale-out архитектуры. Соответственно СХД NEC HS8 горизонтально масштабируемая система и может быть расширена до 165 узлов для увеличения емкости и производительности. Это позволяет начать с маленькой менее дорогой конфигурации (Н-р: однонодовой) и затем последовательно ее расширять по мере растущих потребностей в резервном копировании. Как видно из картинок, кластера HS8 могут содержать ноды двух типов. Гибридные ноды (Hybrid Node), совмещающие в себе функции контроллеров (Accelerator Node), взаимодействующих с серверами резервного копирования, а так же функцию хранения данных (Storage Node). И отдельные ноды хранения (Storage Node), которые используются для увеличения доступного дискового пространства в системе хранения. В зависимости от модели системы и требований заказчика соотношение Hybrid и Storage нод в кластере может варьироваться.

2 — One (1) Terabyte (TB) = 1,000,000,000,000 bytes.
3 — Assumption: full backup weekly and incremental backup daily, and 3 months retention period to achieve 20:1 data reduction ratio; 9+3 resiliency level.

Возможна конфигурация нод дисками по 8TB по запросу заказчика. Максимальная производительность на ноду по данным вендора 61TB/ч или 72TB/h при 1HN+1SN, но это при условии использования дедупликации на источнике (Deduped Transfer) и данных, которые хорошо поддаются дедупликации. Как и у многих вендоров это больше маркетинговая цифра — так называемый Best Case. А самый плохой случай это 450MB/s на одну ноду на 12 SATA дисков — это при условии, что данные не поддаются дудупликации и компрессии совсем. Т.е. весь не сжатый и не дедуплицируемый поток идет на SATA диски, что называется — Worst Case. Таким образом выше описанное это своего рода крайние значения, а реальность в каждом конкретном кейсе будет где-то в промежутке между ними.
Внешний вид нод HS8-5000 спереди представлен ниже. Фактически это собственные сервера NEC с дисками и сетевыми картами. CPU во всех нодах E5-2600v3 поколения.

Вид сзади гибридной ноды с internal и external портами на 1Gbe. Internal порты используются для внутрикластерных соединений между нодами HydraStor. External порты используются для внешних клиентских подключений к кластеру (например для медиа-серверов бэкапа). Справа видны два SAS диска, на которых размещается операционная система ноды.

Вид сзади гибридной ноды с internal и external портами на 1Gbe и двумя 10Gbe external портами.

Вид сзади гибридной ноды с internal и external портами на 1Gbe и четырьмя 10Gbe external портами.

Вид сзади сторадж ноды с internal портами на 1Gbe.

Внутренние подключения в двухнодовом кластере, состоящем из двух гибридных нод без использования свитчей. При апгрейде с одно-нодовой конфигурации до двух нодового кластера требуется планировать 4 часовой down time для переконфигурации внутренних LSN (Logical storage nodes). Данные уже записанные на кластер при этом не теряются.

Внутренние подключения в двухнодовом кластере, состоящем из гибридной ноды и сторадж ноды без использования свитчей.

Схематичное подключение кластера состояещего из более чем 2 нод с использованием внутри-кластерных Ethernet свитчей.

Для работы внутри кластера используются L2 свитчи NEC собственного производства. Ниже представлен пример стекирования внутри-кластерных свитчей NEC, которые используются для подключения internal портов нод HydraStor. В зависимости от размеров кластера может использоваться от двух до трех 48 портовых Ethernet свитчей на один телекоммуникационный шкаф. Всего максимум 39 одноюнитовых свитчей на кластер (с учетом “Top-of-Rack” L3 свитчей). Свитчи поставляются в комплекте с кластером в составе единого решения.

Пример таблицы коммутации портов на internal Ethernet свитчах.
HNxxxx-M: Connect to Maintenance Port of Hybrid Node
HNxxxx-1/2/3/4: Connect to iLAN1/2/3/4 Port of Hybrid Node
SNxxxx-M: Connect to Maintenance Port of Storage Node
SNxxxx-1/2/3/4: Connect to iLAN1/2/3/4 Port of Storage Node
L3xxxxx-xx: Connect to L3 switches
Через L3 свитчи обеспечивается связанность между телекоммуникационными шкафами в больших конфигурациях.

Пример поставки готового кластера NEC HydraStor для установки в телекоммуникационном шкафу заказчика. 15 нод на шкаф, до 11 шкафов в максимальной конфигурации.

В HYDRAstor используется inline глобальная дедупликация в пределах всего кластера — DataRedux.
При дедупликации данные разбиваются на блоки переменной длинны, что позволяет более точно реагировать на изменение файлов при последующих бэкапах. Для уникальных блоков дополнительно используется алгоритм компрессии LZO для уменьшения размера хранимых данных.

Изменение каких-то данных в середине файла, не приводит к образованию новых уникальных блоков, как при дедупликации с использованием блоков постоянной длинны. Алгоритм довольно точно определяет измененный участок файла, а все последующие блоки остаются неизменными и дедуплицируются.

СХД NEC HS8 предлагает высокий уровень резервирования хранимых данных, превосходящий используемый обычными СХД. Записываемые данные разделяются на множество блоков, добавляя к этим блокам специальные контрольные суммы, а затем распределяются по дискам в различных узлах, СХД NEC HS8 обеспечивает восстановление данных даже в случае отказов в нескольких точках одновременно. Она может справится не только с одновременными отказами 3 дисков, но и узлов, предотвращая потерю информации при отказе. Для защиты данных используются алгоритмы Erasure Coding.

За счет того, что на HYDRAStor не используется RAID и выделенные HS диски, восстановление после сбоев (дисков или нод) происходит намного быстрее чем при использовании RAID. Так как восстановление идет по схеме от многих к многим, используя свободное пространство для восстановления данных.

Хранимые данные периодически подвергаются проверке на целостность. Если выясняется, что данные повреждены, то они автоматически восстанавливаются из контрольных сумм.

Distributed Resilient Data (DRD) это:
1. Определяемая пользователем защита от сбоя диска или ноды
2. Лучшая защита с меньшими затратами
3. Более быстрое восстановление с меньшей деградацией производительности
Ниже представлена таблица зависимости количества допустимых сбоев дисков или нод для одно и двух-нодовых конфигураций.
Отличный от дефолтного (3) уровень защиты можно назначить на каждую вновь создаваемую файловую систему. Чем выше указанный Resilience уровень, тем надежнее защищены данные от потери, но и тем больше затраты по месту на дисках, которое требуется для этой защиты. Если сравнивать с конкурентными решениями, то примерно такие же затраты дискового пространства в 25% получаются у конкурентов при использовании Raid6, который позволяет потерять не более чем 2 диска из одной Raid группы. HydraStor же может потерять до 3 дисков без потери данных при тех же 25% дискового пространства, затраченного на защиту хранимых данных.

Аналогичная таблица, только для моногонодовых конфигураций.

Полезная емкость на нодах HS8 без учета дедупликации и компрессии.

Добавление новых нод в кластер:

Емкость СХД NEC HS8 можно легко увеличить по мере роста количества данных. СХД NEC HS8 может безопасно хранить данные в течении продолжительных периодов времени, используя технологию распределенной отказоустойчивости. Данные автоматически мигрируют со старого узла на новый во время замены. Это позволяет менять узлы в реальном времени, не создавая неудобств пользователям. Замена узлов также значительно сокращает затраты, продлевая жизнь существующей системы, по сравнению с полной заменой системы на новую. В одном кластере одновременно могут находиться ноды трех поколений.

Universal Express I/O — облегченный I/O протокол NEC (устанавливается отдельным плагином на backup медиасервер)
1. Имеет меньше накладных расходов чем NFS/CIFS, а значит более производителен
2. Работает со многими приложениями резервного копирования, например: RMAN, NetWorker, NetVault etc.
3. Поддерживает следующие функции:

Universal Express I/O Deduped Transfer — отдельно лицензируемый функционал Universal Express I/O, который позволяет включить дедупликацию на источнике.
Deduped Transfer имеет несколько ограничений и не будет работать если количество конкурентных заданий резервного копирования превысит:
Для работы Deduped Transfer требуется дополнительно или лицензия на Universal Express I/O или OST Suite (OpenStorage — Suite).

Требования к Backup серверу, использующему Deduped трансфер:

Synchronized Access Grid – позволяет включить доступ к одной файловой системе через несколько гибридных нод одновременно. Фича требует отдельной лицензии. Фактически включается единое пространство имен для конкретной файловой системы через несколько физических гибридных нод. При этом клиент может не знать, через какую конкретную ноду он подключен в текущий момент. Для увеличения производительности такаой файловой системы можно просто добавить еще одну гибридную ноду в Synchronized Node Group. Одновременная запись в один и тот же файл с разных нод не возможна.
Synchronized Access Grid позволяет облегчить проектирование системы и обеспечить хорошую производительность без необходимости создавать отдельные файловые системы на каждой гибридной ноде.

Dynamic I/O – адаптивная балансировка внешних потоков. Динамическое распределение потоков резервного копирования по всем внешним (front-end) Ethernet портам всех Hybrid нод.

Работает Dynamic I/O при наличии на кластере лицензий Synchronized Access Grid и Universal Express I/O. Потоки данных равномерно балансируются по нескольким гибридным нодам и/или подсетям в пределах кластера. В пределах однонодовой конфигурации так же можно настроить балансировку потоков по физическим портам ноды (не используя лицензию Synchronized Access Grid), но потребуется использовать различные подсети на каждом физическом external порту ноды. Однако альтернативой обоим лицензиям в пределах маленькой однонодовой конфигурации может быть так же собирание нескольких external интерфейсов в Bonding Port. Поддерживаются следующие типы агрегирования:
Естественно кроме Bonding-а и Universal Express I/O можно настраивать Jumbo Frames на всем пути следования трафика (на сетевых интерфейсах HydraStor включительно).
Для интеграции с Veritas NetBackup поддерживается OST плагины для различных операционных систем. В случае если не используется Universal Express I/O, то OST обеспечивает хорошую производительность по CIFS или NFS протоколам. Так же NetBackup умеет балансировать свои Job-ы по нескольким нодам NEC HS. Для включения дедупликации на источнике так же требуется лицензия Deduped Transfer. Кроме того поддерживается Optimized Copy функционал, который позволяет реплицировать на удаленную площадку только уникальные блоки.

OST Auto Image Replication — функционал, который автоматизирует импорт каталога резервных копий на Backup сервер на удаленной площадке. Что позволяет ускорить восстановление данных на удаленной площадке в случае полного выхода из строя исходного сайта.

OST plugin – FC configuration — для HYDRAStor доступна конфигурация, при которой можно писать (читать) данные на гибридные ноды в том числе и по FiberChannel протоколу. Изначально поддерживался только NetBackup с OST плагином. Но недавно вышел патч (доступен уже сейчас), функционал которого будет добавлен в следующий релиз софта, и в нем реализована уже работа с FC по протоколу Universal Express IO. Что сильно расширяет спектр софта резервного копирования, который сможет через Universal Express IO работать с данными на кластере по FC.

Ниже на рисунке представлены конфигурации гибридных нод с установленными FC HBA карточками.

Failover Functionality for Business Continuity — это Failover механизм кластера HYDRAstor. Hybrid ноды (HNs) отслеживают состояние друг друга и в случае выхода из строя одной из нод, здоровая нода перехватывает ввод\вывод со сломавшейся ноды на себя.
При использовании NFS протокола ввод/вывод не останавливается и сессии на Backup сервере не сбрасываются. В остальных случаях требуется переподключение.

Чуть более наглядный пример, чем на предыдущей картинке. Переезжают не только файловые системы с ноды на ноду, но и IP адреса, через которые экспортированы эти файловые системы.

WAN-оптимизированная репликация

Для репликации поддерживается двунаправленная топология 1-к-1

Так же поддерживается двунаправленная топология N-к-M (или многие к многим)
Допускается копирование данных на 16 других систем при одноузловой конфигурации HYDRAstor. А так же копирование данных на 50 других систем в многоузловой конфигурации HYDRAstor.

Space Reclamation — место на кластере, как и на многих стороджах с дедупликацией, освобождается не сразу после удаления файлов или файловых систем. Требуется выполнения процесса Space Reclamation, который идет в два этапа: анализ и поиск больше неиспользуемых блоков данных и собственно сам процесс удаления этих блоков. Space Reclamation можно запускать как вручную, так и по настраиваемому расписанию (н-р в часы когда не идут активные бэкапы данных).

WORM (HydraLock) — Write Once Read Many. Технология, которая позволяет с течением времени блокировать файлы от внесения в них изменений и дальше хранить их заданное количество лет. По умолчанию данные хранятся в неизменяемом состоянии 10 лет.

Encryption — HYDRAStor поддерживает шифрование данных при передаче и на дисках. Но данный функционал не доступен в России в соответствии с нашим законодательством.

Список отдельно приобретаемых опциональных лицензий на Hydrastor HS8

Почти весь функционал из списка разобран выше в статье. Кроме DirectDataShadow, который позволяет выполнять прямое резервное копирование томов с СХД M-серии компании NEC (без дополнительных серверов и софта резервного копирования).
При покупке NEC HYDRAstor не требуется отдельное лицензирование дедупликации+компрессии (DataRedux), а также протоколов файлового доступа Cifs, NFS.
Monitoring and Notification — администратор системы может получать оповещения с системы на почту по протоколу SMTP (a), а также через протокол SNMP (b) или просматривать их в интерфейсе управления ©.

HS Data Reduction Estimation Tool — утилита командной строки от вендора, предоставляемая по запросу. Используется для тестирования дедуплицируемости и сжимаемости данных заказчика. Доступна под Windows и Linux. На картинке ниже приведен пример листинга BAT файла, который можно запускать с какой-то периодичностью руками или поставить в планировщик задач в Windows, что бы например сделать имитацию ежедневного бэкапа данных. Фактически при помощи утилиты можно выполнить приблизительную оценку емкости HydraStor, которая потребуется под хранение бэкапов заказчика.
Пример запуска утилиты из CMD в Windows:
Пример BAT файла для автоматизации запуска утилиты по расписанию:
В итоге работы BAT файла получаем CSV файл с датой и временем в названии: test-10-06-2019_17.30.11.csv
А еще у NEC есть маленький HYDRAStor HS3-50, который отличается от старших HS8 моделей меньшей производительностью и отсутствием поддержки кластеризации. Т.е. может использоваться только в виде одной отдельно ноды. На данной модели используется так же CPU поколения E5-2600v3. Функционал полностью сопоставим с однонодовой моделью HS8-5001S. Лицензироваться может кратно 8TB, а максимальная сырая емкость составляет 24TB. Позиционируется он для небольших инсталляций и удаленных офисов компаний с возможностью репликации данных на старшие системы в центральный офис.

Полезная емкость на нодах HS3 без учета дедупликации и компрессии:

HYDRAStor Virtual Appliance – виртуальный апплайнс с тем же софтом, что и на железных версиях HS3/HS8 и с возможностью репликации на эти железные версии. Масштабируется до 15TB полезной емкости. Требования к установке представлены на картинке ниже. Позиционируется так же для небольших компаний и удаленных офисов как и HS3-50.
По запросу вендор может предоставлять триальные лицензии для HYDRAStor Virtual Appliance на 90 дней.

Сноски в таблицах
1. Типичное для резервного копирования сжатие, зависит от типа данных.
2. Емкость рассчитана, исходя из: 1 GB = 1,000,000,000 bytes, 1 TB = 1,000 GB.
3. Расчет для HS VA на хост сервере VMware ESXi с 2-мя Intel Xeon E5-2470 @2.30GHz (8 ядер каждый), 96ГБ памяти, 6x SATA HDD (7,200RPM 4ТБ) в RAID6
4. Предполагается, что отношение сжатия данных составляет 20:1.
5. Тип ЦПУ должен быть Nehalem-C(Westmere) или выше (напр., Intel Xeon Processor E56xx/L56xx/X56xx) с частотой 1.5GHz или выше.
6. Значения емкости рассчитаны, исходя из: 1GiB = 1,073,741,824 bytes, 1 GB = 1,000,000,000 bytes, 1 TB = 1,000 GB.
У NEC существует еще одно более дешевое решение чем HS8 семейство систем HYDRAstor Позиционируется оно для архивного хранения (в первую очередь медиаконтента). В нем используется дедупликация не переменным, а фиксированным блоком. В остальном доступны все те же технологии, что и для HS8. В последнем столбце в строке Емкость опечатка, имеются в виду Петабайты, а не Терабайты.

А дальше насколько картинок, которые показывают как NEC видит себя на фоне конкурентов :).
NEC HS8 vs DataDomain

NEC HS8 vs StoreOnce

Сравнение производительности (на контроллер TB/h)

Сравнение производительности (на систему TB/h)

Вот собственно и все что удалось мне «скомпилировать» из разрозненной и обширной документации NEC по этим системам :).
Те кто чуть моложе вот это:
(под катом много картинок)
Корпорация NEC
Звучит примерно как «Эн-и-си». А на английском это расшифровывается как Nippon Electric Corporation. Хотя у нас в стране обычно произносят как НЭК :).
- Штаб Квартира – Токио, Япония (на картинке)
- Оборот за 2018 год — $29 млрд
- Общее число сотрудников 109 000+
- Основные заводы находятся на территории Японии, несколько заводов в Малайзии
- 65% оборота – продажи внутри Японии
- 18 представительств в 18 странах
- 4 научно-исследовательских центра в 4 странах
Компания была зарегистрирована в Токио в 1899 году и первые годы занималась производством телефонного оборудования.
Сегодня NEC производит довольно большой спектр решений, ознакомиться с которыми можно на официальном сайте компании
Но мне хотелось бы рассказать уважаемому сообществу о линейке систем хранения для резервных копий с дедупликацией NEC HYDRAstor и в первую очередь о старшем семействе HS8.
NEC HYDRAstor HS8
Что меня удивило с самого начала, так это то, что вышло уже 5-ое поколение этих систем, а в России про них почти ничего не известно. По крайней мере общаясь с людьми из вендоров, интеграторов или заказчиков я чаще видел удивление в качестве первой реакции при упоминании этих решений.
На картинках ниже представлен актуальный модельный ряд NEC HYDRAstor HS8 и основные характеристики моделей.
СХД HYDRAstor – это системы построенные на базе scale-out архитектуры. Соответственно СХД NEC HS8 горизонтально масштабируемая система и может быть расширена до 165 узлов для увеличения емкости и производительности. Это позволяет начать с маленькой менее дорогой конфигурации (Н-р: однонодовой) и затем последовательно ее расширять по мере растущих потребностей в резервном копировании. Как видно из картинок, кластера HS8 могут содержать ноды двух типов. Гибридные ноды (Hybrid Node), совмещающие в себе функции контроллеров (Accelerator Node), взаимодействующих с серверами резервного копирования, а так же функцию хранения данных (Storage Node). И отдельные ноды хранения (Storage Node), которые используются для увеличения доступного дискового пространства в системе хранения. В зависимости от модели системы и требований заказчика соотношение Hybrid и Storage нод в кластере может варьироваться.
2 — One (1) Terabyte (TB) = 1,000,000,000,000 bytes.
3 — Assumption: full backup weekly and incremental backup daily, and 3 months retention period to achieve 20:1 data reduction ratio; 9+3 resiliency level.
Возможна конфигурация нод дисками по 8TB по запросу заказчика. Максимальная производительность на ноду по данным вендора 61TB/ч или 72TB/h при 1HN+1SN, но это при условии использования дедупликации на источнике (Deduped Transfer) и данных, которые хорошо поддаются дедупликации. Как и у многих вендоров это больше маркетинговая цифра — так называемый Best Case. А самый плохой случай это 450MB/s на одну ноду на 12 SATA дисков — это при условии, что данные не поддаются дудупликации и компрессии совсем. Т.е. весь не сжатый и не дедуплицируемый поток идет на SATA диски, что называется — Worst Case. Таким образом выше описанное это своего рода крайние значения, а реальность в каждом конкретном кейсе будет где-то в промежутке между ними.
Внешний вид нод HS8-5000 спереди представлен ниже. Фактически это собственные сервера NEC с дисками и сетевыми картами. CPU во всех нодах E5-2600v3 поколения.
Вид сзади гибридной ноды с internal и external портами на 1Gbe. Internal порты используются для внутрикластерных соединений между нодами HydraStor. External порты используются для внешних клиентских подключений к кластеру (например для медиа-серверов бэкапа). Справа видны два SAS диска, на которых размещается операционная система ноды.
Вид сзади гибридной ноды с internal и external портами на 1Gbe и двумя 10Gbe external портами.
Вид сзади гибридной ноды с internal и external портами на 1Gbe и четырьмя 10Gbe external портами.
Вид сзади сторадж ноды с internal портами на 1Gbe.
Внутренние подключения в двухнодовом кластере, состоящем из двух гибридных нод без использования свитчей. При апгрейде с одно-нодовой конфигурации до двух нодового кластера требуется планировать 4 часовой down time для переконфигурации внутренних LSN (Logical storage nodes). Данные уже записанные на кластер при этом не теряются.
Внутренние подключения в двухнодовом кластере, состоящем из гибридной ноды и сторадж ноды без использования свитчей.
Схематичное подключение кластера состояещего из более чем 2 нод с использованием внутри-кластерных Ethernet свитчей.
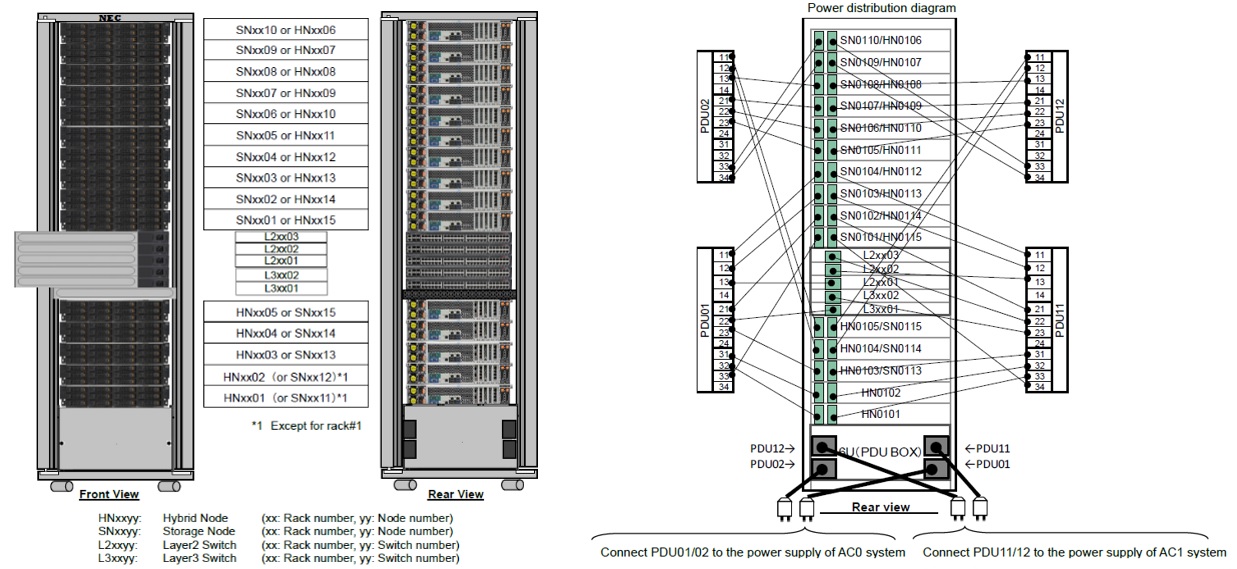
Для работы внутри кластера используются L2 свитчи NEC собственного производства. Ниже представлен пример стекирования внутри-кластерных свитчей NEC, которые используются для подключения internal портов нод HydraStor. В зависимости от размеров кластера может использоваться от двух до трех 48 портовых Ethernet свитчей на один телекоммуникационный шкаф. Всего максимум 39 одноюнитовых свитчей на кластер (с учетом “Top-of-Rack” L3 свитчей). Свитчи поставляются в комплекте с кластером в составе единого решения.
Пример таблицы коммутации портов на internal Ethernet свитчах.
HNxxxx-M: Connect to Maintenance Port of Hybrid Node
HNxxxx-1/2/3/4: Connect to iLAN1/2/3/4 Port of Hybrid Node
SNxxxx-M: Connect to Maintenance Port of Storage Node
SNxxxx-1/2/3/4: Connect to iLAN1/2/3/4 Port of Storage Node
L3xxxxx-xx: Connect to L3 switches
Через L3 свитчи обеспечивается связанность между телекоммуникационными шкафами в больших конфигурациях.
Пример поставки готового кластера NEC HydraStor для установки в телекоммуникационном шкафу заказчика. 15 нод на шкаф, до 11 шкафов в максимальной конфигурации.
В HYDRAstor используется inline глобальная дедупликация в пределах всего кластера — DataRedux.
При дедупликации данные разбиваются на блоки переменной длинны, что позволяет более точно реагировать на изменение файлов при последующих бэкапах. Для уникальных блоков дополнительно используется алгоритм компрессии LZO для уменьшения размера хранимых данных.
Изменение каких-то данных в середине файла, не приводит к образованию новых уникальных блоков, как при дедупликации с использованием блоков постоянной длинны. Алгоритм довольно точно определяет измененный участок файла, а все последующие блоки остаются неизменными и дедуплицируются.
СХД NEC HS8 предлагает высокий уровень резервирования хранимых данных, превосходящий используемый обычными СХД. Записываемые данные разделяются на множество блоков, добавляя к этим блокам специальные контрольные суммы, а затем распределяются по дискам в различных узлах, СХД NEC HS8 обеспечивает восстановление данных даже в случае отказов в нескольких точках одновременно. Она может справится не только с одновременными отказами 3 дисков, но и узлов, предотвращая потерю информации при отказе. Для защиты данных используются алгоритмы Erasure Coding.
За счет того, что на HYDRAStor не используется RAID и выделенные HS диски, восстановление после сбоев (дисков или нод) происходит намного быстрее чем при использовании RAID. Так как восстановление идет по схеме от многих к многим, используя свободное пространство для восстановления данных.
Хранимые данные периодически подвергаются проверке на целостность. Если выясняется, что данные повреждены, то они автоматически восстанавливаются из контрольных сумм.
Distributed Resilient Data (DRD) это:
1. Определяемая пользователем защита от сбоя диска или ноды
- Защита от 3 параллельных сбоев по умолчанию
- Возможность использования нескольких уровней (1-6) защиты для различных приложений в одной системе (разные файловые системы с нужным уровнем защиты под разные приложения)
2. Лучшая защита с меньшими затратами
- По умолчанию используется 75% емкости под хранение данных и 25% под их защиту
- В 1.5 раза надежнее чем RAID 6 с меньшими затратами и более быстрым восстановлением
- Нет необходимости в запасных дисках (Hot Spare), восстановление идет в свободное место в кластере
3. Более быстрое восстановление с меньшей деградацией производительности
- Восстанавливаются только данные, а не диск целиком
- Данные восстанавливаются в режиме многие к многим в отличии от RAID
Ниже представлена таблица зависимости количества допустимых сбоев дисков или нод для одно и двух-нодовых конфигураций.
Отличный от дефолтного (3) уровень защиты можно назначить на каждую вновь создаваемую файловую систему. Чем выше указанный Resilience уровень, тем надежнее защищены данные от потери, но и тем больше затраты по месту на дисках, которое требуется для этой защиты. Если сравнивать с конкурентными решениями, то примерно такие же затраты дискового пространства в 25% получаются у конкурентов при использовании Raid6, который позволяет потерять не более чем 2 диска из одной Raid группы. HydraStor же может потерять до 3 дисков без потери данных при тех же 25% дискового пространства, затраченного на защиту хранимых данных.
Аналогичная таблица, только для моногонодовых конфигураций.
Полезная емкость на нодах HS8 без учета дедупликации и компрессии.
Добавление новых нод в кластер:
- Добавление новых HN (Hybrid Node) линейно увеличивает производительность и емкость кластера
- Добавление новых SN (Storage Node) линейно увеличивает емкость кластера
- При добавлении новых нод автоматически запускается процесс перераспределения хранимых данных на новые ноды
Емкость СХД NEC HS8 можно легко увеличить по мере роста количества данных. СХД NEC HS8 может безопасно хранить данные в течении продолжительных периодов времени, используя технологию распределенной отказоустойчивости. Данные автоматически мигрируют со старого узла на новый во время замены. Это позволяет менять узлы в реальном времени, не создавая неудобств пользователям. Замена узлов также значительно сокращает затраты, продлевая жизнь существующей системы, по сравнению с полной заменой системы на новую. В одном кластере одновременно могут находиться ноды трех поколений.
Universal Express I/O — облегченный I/O протокол NEC (устанавливается отдельным плагином на backup медиасервер)
1. Имеет меньше накладных расходов чем NFS/CIFS, а значит более производителен
2. Работает со многими приложениями резервного копирования, например: RMAN, NetWorker, NetVault etc.
3. Поддерживает следующие функции:
- Сжатие данных при передаче
- Шифрование данных при передаче
- Балансировка нагрузки по подсетям
Universal Express I/O Deduped Transfer — отдельно лицензируемый функционал Universal Express I/O, который позволяет включить дедупликацию на источнике.
Deduped Transfer имеет несколько ограничений и не будет работать если количество конкурентных заданий резервного копирования превысит:
- 50 параллельных бэкапов на один Backup сервер (51-й бэкап будет выполняться без дедупликации на источнике)
- 100 параллельных бэкапов на одну Hybryd ноду (101-й бэкап будет выполняться без дедупликации на источнике)
Для работы Deduped Transfer требуется дополнительно или лицензия на Universal Express I/O или OST Suite (OpenStorage — Suite).
Требования к Backup серверу, использующему Deduped трансфер:
Synchronized Access Grid – позволяет включить доступ к одной файловой системе через несколько гибридных нод одновременно. Фича требует отдельной лицензии. Фактически включается единое пространство имен для конкретной файловой системы через несколько физических гибридных нод. При этом клиент может не знать, через какую конкретную ноду он подключен в текущий момент. Для увеличения производительности такаой файловой системы можно просто добавить еще одну гибридную ноду в Synchronized Node Group. Одновременная запись в один и тот же файл с разных нод не возможна.
Synchronized Access Grid позволяет облегчить проектирование системы и обеспечить хорошую производительность без необходимости создавать отдельные файловые системы на каждой гибридной ноде.
Dynamic I/O – адаптивная балансировка внешних потоков. Динамическое распределение потоков резервного копирования по всем внешним (front-end) Ethernet портам всех Hybrid нод.
Работает Dynamic I/O при наличии на кластере лицензий Synchronized Access Grid и Universal Express I/O. Потоки данных равномерно балансируются по нескольким гибридным нодам и/или подсетям в пределах кластера. В пределах однонодовой конфигурации так же можно настроить балансировку потоков по физическим портам ноды (не используя лицензию Synchronized Access Grid), но потребуется использовать различные подсети на каждом физическом external порту ноды. Однако альтернативой обоим лицензиям в пределах маленькой однонодовой конфигурации может быть так же собирание нескольких external интерфейсов в Bonding Port. Поддерживаются следующие типы агрегирования:
- balance-rr — последовательно кидает пакеты, с первого по последний интерфейс
- balance-alb — является первой альтернативой к рассмотрению, если не используется LACP. Адаптивно выравнивает нагрузку на все интерфейсы, не требуя поддержки со стороны свитчей. Но может вызывать алерты в системах мониторинга сети на предмет дублирования IP адресов.
- active-backup — один из интерфейсов активен. Если активный интерфейс выходит из строя (link down и т.д.), другой интерфейс заменяет активный. Не требует дополнительной настройки коммутатора
- IEEE 802.3ad или LACP (требуется настройка на стороне свитчей заказчика)
Естественно кроме Bonding-а и Universal Express I/O можно настраивать Jumbo Frames на всем пути следования трафика (на сетевых интерфейсах HydraStor включительно).
Для интеграции с Veritas NetBackup поддерживается OST плагины для различных операционных систем. В случае если не используется Universal Express I/O, то OST обеспечивает хорошую производительность по CIFS или NFS протоколам. Так же NetBackup умеет балансировать свои Job-ы по нескольким нодам NEC HS. Для включения дедупликации на источнике так же требуется лицензия Deduped Transfer. Кроме того поддерживается Optimized Copy функционал, который позволяет реплицировать на удаленную площадку только уникальные блоки.
OST Auto Image Replication — функционал, который автоматизирует импорт каталога резервных копий на Backup сервер на удаленной площадке. Что позволяет ускорить восстановление данных на удаленной площадке в случае полного выхода из строя исходного сайта.
OST plugin – FC configuration — для HYDRAStor доступна конфигурация, при которой можно писать (читать) данные на гибридные ноды в том числе и по FiberChannel протоколу. Изначально поддерживался только NetBackup с OST плагином. Но недавно вышел патч (доступен уже сейчас), функционал которого будет добавлен в следующий релиз софта, и в нем реализована уже работа с FC по протоколу Universal Express IO. Что сильно расширяет спектр софта резервного копирования, который сможет через Universal Express IO работать с данными на кластере по FC.
Ниже на рисунке представлены конфигурации гибридных нод с установленными FC HBA карточками.
Failover Functionality for Business Continuity — это Failover механизм кластера HYDRAstor. Hybrid ноды (HNs) отслеживают состояние друг друга и в случае выхода из строя одной из нод, здоровая нода перехватывает ввод\вывод со сломавшейся ноды на себя.
При использовании NFS протокола ввод/вывод не останавливается и сессии на Backup сервере не сбрасываются. В остальных случаях требуется переподключение.
Чуть более наглядный пример, чем на предыдущей картинке. Переезжают не только файловые системы с ноды на ноду, но и IP адреса, через которые экспортированы эти файловые системы.
WAN-оптимизированная репликация
- Отправляет только уникальные данные
- Значительно уменьшает нагрузку на сети между площадками
- Избавляет от затрат на обслуживание лент
- Защищает данные за счет шифрования «на лету»
Для репликации поддерживается двунаправленная топология 1-к-1
Так же поддерживается двунаправленная топология N-к-M (или многие к многим)
Допускается копирование данных на 16 других систем при одноузловой конфигурации HYDRAstor. А так же копирование данных на 50 других систем в многоузловой конфигурации HYDRAstor.
Space Reclamation — место на кластере, как и на многих стороджах с дедупликацией, освобождается не сразу после удаления файлов или файловых систем. Требуется выполнения процесса Space Reclamation, который идет в два этапа: анализ и поиск больше неиспользуемых блоков данных и собственно сам процесс удаления этих блоков. Space Reclamation можно запускать как вручную, так и по настраиваемому расписанию (н-р в часы когда не идут активные бэкапы данных).
WORM (HydraLock) — Write Once Read Many. Технология, которая позволяет с течением времени блокировать файлы от внесения в них изменений и дальше хранить их заданное количество лет. По умолчанию данные хранятся в неизменяемом состоянии 10 лет.
Encryption — HYDRAStor поддерживает шифрование данных при передаче и на дисках. Но данный функционал не доступен в России в соответствии с нашим законодательством.
Список отдельно приобретаемых опциональных лицензий на Hydrastor HS8
Почти весь функционал из списка разобран выше в статье. Кроме DirectDataShadow, который позволяет выполнять прямое резервное копирование томов с СХД M-серии компании NEC (без дополнительных серверов и софта резервного копирования).
При покупке NEC HYDRAstor не требуется отдельное лицензирование дедупликации+компрессии (DataRedux), а также протоколов файлового доступа Cifs, NFS.
Monitoring and Notification — администратор системы может получать оповещения с системы на почту по протоколу SMTP (a), а также через протокол SNMP (b) или просматривать их в интерфейсе управления ©.
HS Data Reduction Estimation Tool — утилита командной строки от вендора, предоставляемая по запросу. Используется для тестирования дедуплицируемости и сжимаемости данных заказчика. Доступна под Windows и Linux. На картинке ниже приведен пример листинга BAT файла, который можно запускать с какой-то периодичностью руками или поставить в планировщик задач в Windows, что бы например сделать имитацию ежедневного бэкапа данных. Фактически при помощи утилиты можно выполнить приблизительную оценку емкости HydraStor, которая потребуется под хранение бэкапов заказчика.
Пример запуска утилиты из CMD в Windows:
hsSimulator.exe -d <tempDBfile> -o <CSVfile 1> <Files/directories to be measured (before update)> hsSimulator.exe -d <tempDBfile> -o <CSVfile 2> <Files/directories to be measured (after update)>
Пример BAT файла для автоматизации запуска утилиты по расписанию:
@echo off set h=%TIME:~0,2% if "%h:~0,1%" equ " " set h=0%h:~1,1% set m=%TIME:~3,2% set s=%TIME:~6,2% set dd=%DATE:~0,2% set mm=%DATE:~3,2% set yyyy=%DATE:~6,4% c:\hsSimulator\hsSimulator.exe -d c:\hsSimulator\temp.db ^ -o c:\hsSimulator\test-%dd%-%mm%-%yyyy%_%h%.%m%.%s%.csv c:\temp
В итоге работы BAT файла получаем CSV файл с датой и временем в названии: test-10-06-2019_17.30.11.csv
Single Node HYDRAStor HS3-50
А еще у NEC есть маленький HYDRAStor HS3-50, который отличается от старших HS8 моделей меньшей производительностью и отсутствием поддержки кластеризации. Т.е. может использоваться только в виде одной отдельно ноды. На данной модели используется так же CPU поколения E5-2600v3. Функционал полностью сопоставим с однонодовой моделью HS8-5001S. Лицензироваться может кратно 8TB, а максимальная сырая емкость составляет 24TB. Позиционируется он для небольших инсталляций и удаленных офисов компаний с возможностью репликации данных на старшие системы в центральный офис.
Полезная емкость на нодах HS3 без учета дедупликации и компрессии:
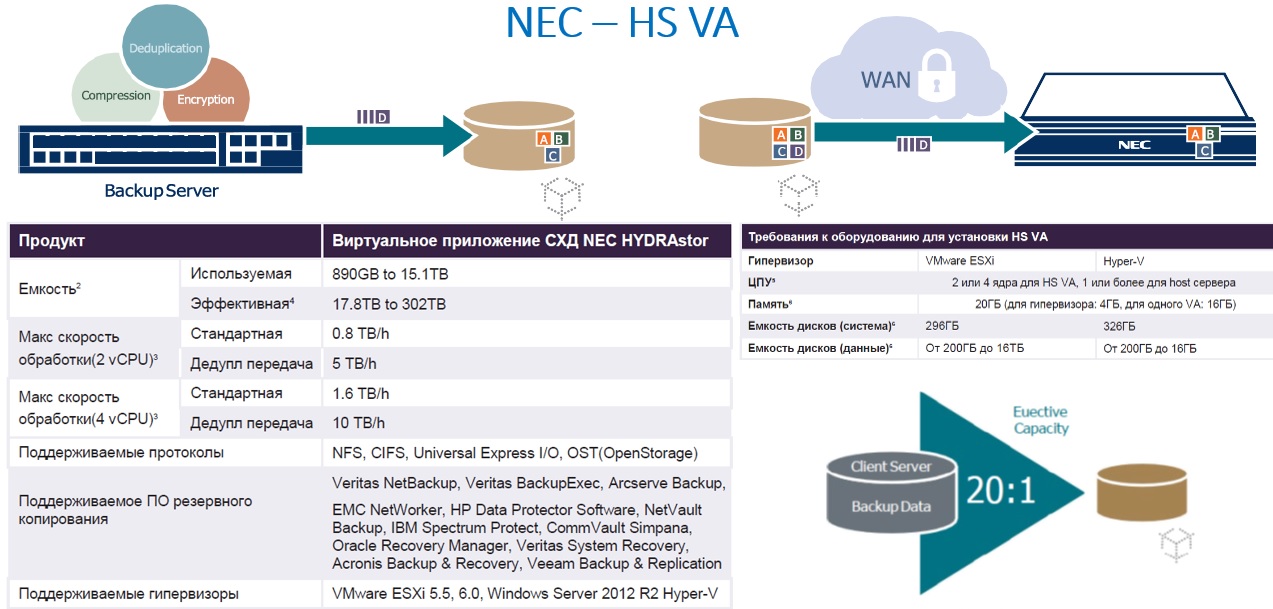
HYDRAStor Virtual Appliance
HYDRAStor Virtual Appliance – виртуальный апплайнс с тем же софтом, что и на железных версиях HS3/HS8 и с возможностью репликации на эти железные версии. Масштабируется до 15TB полезной емкости. Требования к установке представлены на картинке ниже. Позиционируется так же для небольших компаний и удаленных офисов как и HS3-50.
По запросу вендор может предоставлять триальные лицензии для HYDRAStor Virtual Appliance на 90 дней.
Сноски в таблицах
1. Типичное для резервного копирования сжатие, зависит от типа данных.
2. Емкость рассчитана, исходя из: 1 GB = 1,000,000,000 bytes, 1 TB = 1,000 GB.
3. Расчет для HS VA на хост сервере VMware ESXi с 2-мя Intel Xeon E5-2470 @2.30GHz (8 ядер каждый), 96ГБ памяти, 6x SATA HDD (7,200RPM 4ТБ) в RAID6
4. Предполагается, что отношение сжатия данных составляет 20:1.
5. Тип ЦПУ должен быть Nehalem-C(Westmere) или выше (напр., Intel Xeon Processor E56xx/L56xx/X56xx) с частотой 1.5GHz или выше.
6. Значения емкости рассчитаны, исходя из: 1GiB = 1,073,741,824 bytes, 1 GB = 1,000,000,000 bytes, 1 TB = 1,000 GB.
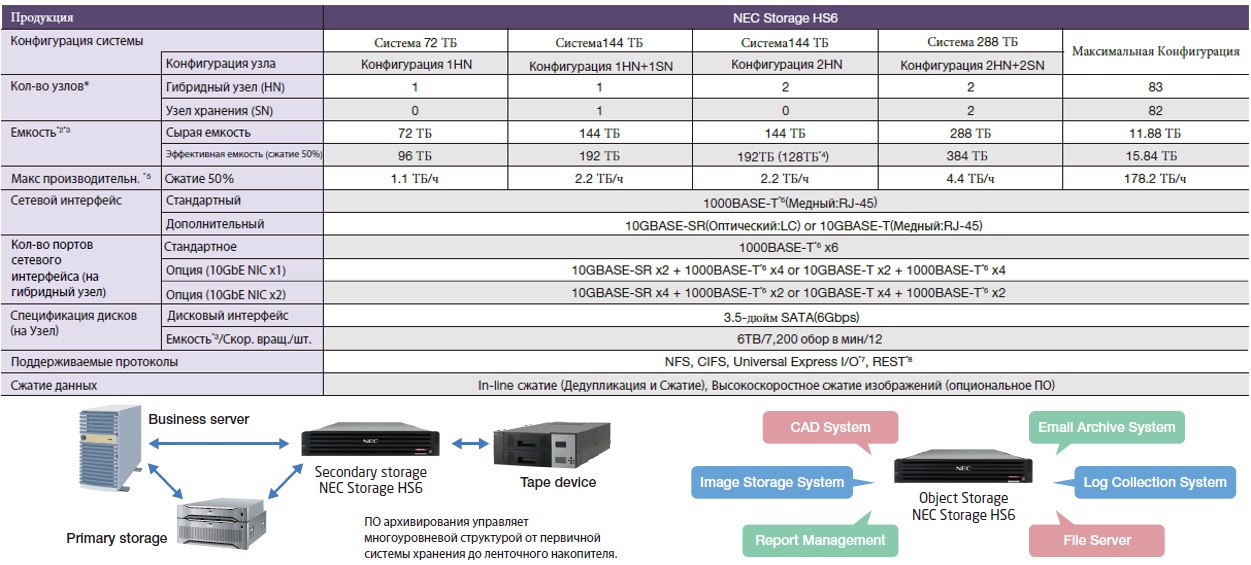
NEC HYDRAStor HS6
У NEC существует еще одно более дешевое решение чем HS8 семейство систем HYDRAstor Позиционируется оно для архивного хранения (в первую очередь медиаконтента). В нем используется дедупликация не переменным, а фиксированным блоком. В остальном доступны все те же технологии, что и для HS8. В последнем столбце в строке Емкость опечатка, имеются в виду Петабайты, а не Терабайты.
А дальше насколько картинок, которые показывают как NEC видит себя на фоне конкурентов :).
NEC HS8 vs DataDomain
NEC HS8 vs StoreOnce
Сравнение производительности (на контроллер TB/h)
Сравнение производительности (на систему TB/h)
Вот собственно и все что удалось мне «скомпилировать» из разрозненной и обширной документации NEC по этим системам :).

