Как узнать наверняка, что внутри у колобка?
Может, ты его проглотишь, а внутри него река? © Таня Задорожная
Что такое Data Science сегодня, кажется, знают уже не только дети, но и домашние животные. Спроси любого котика, и он скажет: статистика, Python, R, BigData, машинное обучение, визуализация и много других слов, в зависимости от квалификации. Но не все котики, а также те, кто хочет стать специалистом по Data Science, знают, как именно устроен Data Science-проект, из каких этапов он состоит и как каждый из них влияет на конечный результат, насколько ресурсоемким является каждый из этапов проекта. Для ответа на эти вопросы как правило служит методология. Однако бОльшая часть обучающих курсов, посвященных Data Science, ничего не говорит о методологии, а просто более или менее последовательно раскрывает суть упомянутых выше технологий, а уж со структурой проекта каждый начинающий Data Scientist знакомится на собственном опыте (и граблях). Но лично я люблю ходить в лес с картой и компасом и мне нравится заранее представлять план маршрута, которым двигаешься. После некоторых поисков неплохую методологию мне удалось найти у IBM — известного производителя гайдов и методик по управлению чем угодно.
Итак, в Data Science-проекте выделяется 3 блока по 3 этапа в каждом, всего 9 этапов. Если совсем коротко, то проект состоит из работы с бизнес-требованиями, с данными и собственно с моделью.
Работа с бизнес-требованиями
На этом шаге мы ничего не знаем о том, какие у нас есть данные. Мы должны вникнуть в постановку задачи, понять, какой результат требуется получить от проекта, узнать все про участников и заинтересованных лиц. Далее в соответствии с определенной задачей мы должны решить, каким методом задача будет решаться. Результатом этого шага будут требования к данным: ок, задача ясна, метод выбрали, теперь подумаем, а что нам может понадобиться для успешного решения?
Работа с данными
На втором шаге мы приступаем к поиску данных для решения задачи: узнаем, какие источники нам доступны, и формируем выборку, с которой в дальнейшем будем работать. После того как данные собраны, необходимо провести ряд исследований, чтобы лучше понимать, как устроена выборка: исследовать центральное положение и вариабельность, выявить корреляции между признаками, построить графики распределения. После этого этапа можно приступать к подготовке данных. Как правило, этот этап самый трудоемкий и на него может уходить до 90% от всего времени проекта, но от того, насколько качественно он выполнен, зависит успех всего проекта.
Разработка и внедрение
Наконец, третий шаг. После того, как данные готовы, можно приступать собственно к разработке и внедрению. Программируем модель, натравливаем на обучающую выборку, проверяем на тестовой, если результат устраивает, то демонстрируем заказчику, внедряем, собираем фидбэк и… можно начинать все сначала.
Весь процесс представляется в виде замкнутого круга: по-хорошему DS-проект никогда не может считаться окончательно завершенным (примерно, как ремонт, который, как известно, нельзя закончить, а можно только прекратить):
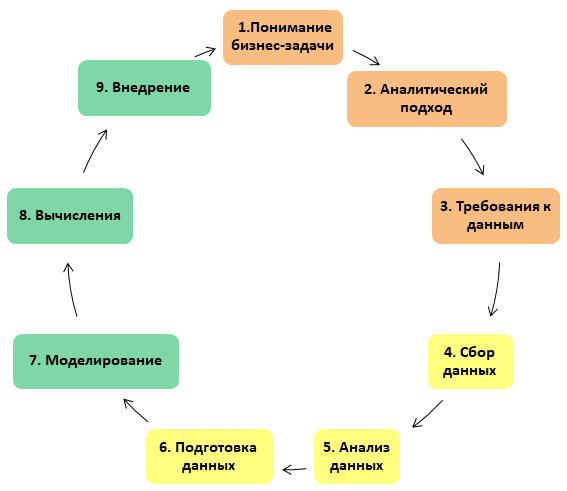
Пройдемся подробнее по каждому из этапов.
1. Понимание бизнес-задачи
Этот этап как фундамент для всей последующей работы: без него ничего не построишь. На нем необходимо четко определить цель исследования: что является проблемой? Почему проблема должна быть решена? Кого затрагивает проблема? Какие есть альтернативы? И самое главное: по каким метрикам будет оцениваться успешность проекта?
Иными словами, необходимо четко выявить цель заказчика. Например, владелец бизнеса спрашивает: можем ли мы снизить затраты на определенную деятельность? Нужно уточнить: является ли целью повысить эффективность этой деятельности? Или повысить доход от бизнеса?
Как только цель определена, можно переходить к следующему шагу.
2. Аналитический подход
Теперь необходимо выбрать аналитический подход для решения бизнес-задачи. Выбор подхода зависит от того, какой тип ответа нужно получить в итоге: если ответ должен быть вида да/нет, подойдет наивный байесовский классификатор. Если нужен ответ в виде численного признака, то подойдут регрессионные модели. Деревья принятия решений могут иметь дело как с численными, так и с категориальными данными. Если вопрос в том, чтобы определить вероятности определенных исходов, необходимо использовать предиктивную модель. Если необходимо выявить связи, используется дескриптивный подход.
3. Требования к данным
Когда четко определена цель исследования и выбран подход, то есть мы четко понимаем, какого рода ответ на вопрос мы ищем, необходимо определиться с тем, какие данные позволят дать искомый ответ. Мы должны подготовить требования к данным: контент, форматы и источники, которые будут использованы на следующей стадии проекта.
4. Сбор данных
На этом этапе мы выполняем сбор данных из имеющихся источников: убеждаемся, что источники доступны, надежны и могут быть использованы для получения искомых данных в требуемом качестве. После того, как выполнен первоначальный сбор данных, необходимо понять, получили ли мы те данные, какие хотели. На этой стадии можно пересмотреть требования к данным и принять решения о необходимости дополнительных данных (то есть существует вероятность, что придется вернуться на этап 3). Могут быть выявлены лакуны в данных и составлен план, как их закрыть или найти замену.
5. Анализ данных
Анализ данных включает в себя все работы по конструированию выборки. На этом этапе необходимо получить ответ на вопрос: репрезентативны ли собранные данные относительно поставленной задачи?
Здесь нам понадобится описательная статистика. Она применяется ко всем переменным, которые будут использоваться в выбранной модели: исследуется центральное положение (среднее, медиана, мода), ищутся выбросы и выполняется оценка вариабельности (как правило, это размах, дисперсия и стандартное отклонение). Также строятся гистограммы распределения переменных. Гистограммы — это хороший инструмент, чтобы понять, как распределяются значения данных и какого рода подготовка нужна, чтобы переменная была максимально полезна при построении модели. Также могут быть полезны другие инструменты визуализации, например, ящики с усами.
Далее выполняется попарное сравнение: вычисляются корреляции между переменными, чтобы определить, какие из них связаны и насколько. Если найдутся значительные корреляции между переменными, какие то из них могут быть отброшены, как избыточные.
6. Подготовка данных
Вместе со сбором и анализом данных, подготовка данных является одной из самых ресурсоемких активностей проекта: эти фазы могут занимать 70, а то и 90% времени проекта. На этой стадии мы перерабатываем данные в такую форму, чтобы с ними было удобно работать: удаляем дубликаты, обрабатываем отсутствующие или неверные данные, проверяем и при необходимости исправляем ошибки форматирования.
Также на этом этапе мы конструируем набор факторов, с которым на следующих этапах будет работать машинное обучение: проводим извлечение и отбор признаков, которые потенциально помогут решить бизнес-задачу. Ошибки на этом этапе могут оказаться критическими для всего проекта, поэтому к нему стоит отнестись особенно внимательно: избыточное количество признаков может привести к тому, что модель будет переобучена, а недостаточное — к тому, что модель будет недообучена.
7. Построение модели
Выбор модели, как можно было заметить, осуществляется в самом начале работы и зависит от бизнес-задачи. Таким образом, когда тип модели определен и имеется обучающая выборка, аналитик разрабатывает модель и проверяет, как она работает на созданном на этапе 6 наборе признаков.
8. Применение модели
Применение модели идет в тесной связке с собственно построением модели: вычисления чередуются с настройкой модели. На этом этапе мы должны ответить на вопрос, отвечает ли построенная модель бизнес-задаче.
Вычисление модели имеет две фазы: проводятся диагностические измерения, которые помогают понять, работает ли модель, так как задумано. Если используется предиктивная модель, может использоваться дерево решений, чтобы понять, что выдача модели соответствует изначальному плану. На второй фазе проводится проверка статистической значимости гипотезы. Она необходима, чтобы убедиться, что данные в модели правильно используются и интерпретируются и полученный результат выходит за пределы статистической погрешности.
9. Внедрение
Если модель дает нам удовлетворительный ответ на поставленный вопрос, этот ответ должен начать приносить пользу. Когда модель разработана, и аналитик уверен в результате своей работы, необходимо познакомить заказчика с разработанным инструментом. Имеет смысл привлечь не только владельца продукта, но и других заинтересованных лиц: маркетинг, разработчиков, системные администраторы: всех, кто хоть как то может оказать влияние на дальнейшее использование результатов проекта. Далее необходимо переходить к внедрению. Внедрение может происходить поэтапно, например, на ограниченную группу пользователей или в тестовом окружении. Также необходимо наладить систему фидбэка, чтобы отслеживать, насколько успешно разработанная модель справляется с поставленной задачей. Через некоторое время этот фидбэк будет полезен для того, чтобы усовершенствовать модель. Также могут появиться новые источники данных, новые заинтересованные лица, не говоря уже о том, что сама бизнес-задача может быть уточнена. Таким образом, нет предела совершенству: даже внедренная модель никогда не может считаться идеальной.

