
Уважаемые Хаброжители! Уважаемые эксперты! Представляю на вашу оценку новую концепцию идентификации пользователей на веб-сайтах, которая, как я надеюсь, с вашей помощью станет открытым интернет-стандартом, сделав этот интернет-мир чуточку лучше. Это вариант черновика протокола беспарольной идентификации, оформленный в виде вольной статьи. И если идея, положенная в его основу, получит от вас, уважаемый читатель, положительную оценку, я продолжу публикацию его на reddit.com и rfc-editor.org. И надеюсь, мне удастся заинтересовать в его реализации разработчиков ведущих браузеров. Потому ожидаю от вас конструктивную критику.
Внимание: очень много текста.
Итак, вопрос. Возможна ли однозначная идентификация посетителей сайта без раскрытия их персональных данных и отслеживания между разными сайтами? Можно ли, решая такую задачу, вообще отказаться от самой примитивной формы авторизации по логину/паролю и использования cookie/localStorage?
С одной стороны, сайтам необходимо узнавать клиента, чтобы, например, «восстановить» его настройки, корзину продуктов, объявления, статьи и т.п. С другой, посетителям хочется оставаться максимально анонимными, не раскрывая свои персональные данные, и не давая сторонним сайтам отследить их. А последние, могут это сделать, путём обмена между собой собранными данными.
Звучит как задача сделать так, чтобы и волки были сыты, да овцы целы. Реально ли это?
Я, думаю, что до определенной степени, – реально.
Оглавление
1 Концепция беспарольной идентификации
1.1 Ключи и токены вместо логинов и паролей
1.2 Структура токена
1.3 HTTP-заголовки протокола
1.4 Как происходит идентификация клиентов сайтами?
1.4.2 Как узнать, что сайт поддерживает этот протокол?
1.5 Как происходит авторизация клиентов сайтами?
1.6 А как реализовать надежную идентификацию клиентов?
1.7 Авторизация на сайте глазами пользователя
1.8 Как происходит смена ключа сайта?
1.9 Как реализуется кросс-доменная авторизация?
1.10 Как реализовать меж-доменную идентификацию?
1.11 Мобильность учетных записей
2 Техническое описание протокола
2.0 Алгоритм формирования ключа домена
2.1 Алгоритм вычисления исходного токена
2.2 Алгоритм защиты токена при передаче
2.3 Процедура обмена солью между браузером и сервером
2.4 Правила формирования поля Context
2.5 Правила определения полей Sender и Recipient
2.6 Подробнее о значениях таблиц определения Context
2.7 Сценарии работы протокола
2.8 Обработка токенов на сервере
2.9 Меж-доменная идентификация
3 Рекомендации по безопасности
3.1 Защита ключевой информации от НСД
3.2 О паролях в качестве ключей доменов
3.3 Риски потери/компрометации ключей и их минимизация
4 Атаки на схему авторизации
4.1 Трекинг пользователя
4.2 Атака вида XSS
4.3 Атака вида СSRF
4.4 Трекинг с использованием схемы SSO
4.5 Компрометация ключа для SSO
4.6 Компрометация токена при передаче
4.7 Взлом сайта и компрометация токенов
Заключение
А что не так с паролями?
Да всё не так. Их можно потерять. Их могут угнать. Их надо запоминать. Да и вообще, почему я обязан заполнять какую-то форму регистрации и придумывать очередной пароль, чтобы посмотреть погоду или скачать этот файл? Наконец, паролей чуть менее, чем много. Сколько вы любите сайтов, столько у вас и паролей. А потому, многие реально используют один пароль на все сайты. Кое кто использует хитрый алгоритм их запоминания. Или менеджер паролей. Или, тупо, – блокнот. Или предпочитает кросс-доменную авторизацию: авторизуешься однократно на одном сайте, и всё! Да не всё. Это, если сайт поддерживает её.
Все эти подходы имеют недостатки.
Использовать один пароль на разных сайтах – моветон. Что знают двое – знает и свинья. Не все сайты (даже крупные и авторитетные) честно выполняют правила безопасности по хранению ваших паролей. Некоторые сайты хранят пароли в отрытом виде, а другие думают, то хранение хэшей паролей уже достаточно их защищает. Как результат, утечки паролей и других персональных данных клиентов случаются регулярно.
С менеджером паролей уже лучше. Правда никто не гарантирует вам, что он не сливает ваши пароли куда-то. Да и поди найди менеджер, который может синхронизировать ваши учётки на всех устройствах (домашний нетбук, телефон, рабочий комп). Не исключаю, что такой существует.
Но в любом случае, сама идея: сначала зарегистрируйся на нашем сайте (при этом сообщи email, mobile, сдай кровь на анализы), потом сам придумай/запомни свой логин и пароль и будь добр их как-то помни, да храни в тайне – подход, я скажу вам, так себе. И его не решит ни один менеджер паролей. Зато решает SSO.
Вот только незадача: если потеряешь пароль от SSO-сайта и забудешь, или его у тебя угонят… Ты разом теряешь доступ от всех своих сайтов или добровольно отдаешь его непонятно кому и не понятно с какими намерениями. Не храните все яйца в одной корзине!
И ещё не факт, что SSO-сайт надёжен. Или не хранит ваши пароли в открытом виде. Или не сливает вообще их добровольно, плюс предоставляет возможность другим отслеживать вас между сайтами. Ну вы поняли.
Поэтому: логин + пароль = зло. А всё зло в мире должно быть выпилено всерьез и надолго. И cookie тоже. Вместе с его сессионными крокодилами PHPSESSIONID, JSESSIONID, и их аналогами.
Все эти подходы имеют недостатки.
Использовать один пароль на разных сайтах – моветон. Что знают двое – знает и свинья. Не все сайты (даже крупные и авторитетные) честно выполняют правила безопасности по хранению ваших паролей. Некоторые сайты хранят пароли в отрытом виде, а другие думают, то хранение хэшей паролей уже достаточно их защищает. Как результат, утечки паролей и других персональных данных клиентов случаются регулярно.
С менеджером паролей уже лучше. Правда никто не гарантирует вам, что он не сливает ваши пароли куда-то. Да и поди найди менеджер, который может синхронизировать ваши учётки на всех устройствах (домашний нетбук, телефон, рабочий комп). Не исключаю, что такой существует.
Но в любом случае, сама идея: сначала зарегистрируйся на нашем сайте (при этом сообщи email, mobile, сдай кровь на анализы), потом сам придумай/запомни свой логин и пароль и будь добр их как-то помни, да храни в тайне – подход, я скажу вам, так себе. И его не решит ни один менеджер паролей. Зато решает SSO.
Вот только незадача: если потеряешь пароль от SSO-сайта и забудешь, или его у тебя угонят… Ты разом теряешь доступ от всех своих сайтов или добровольно отдаешь его непонятно кому и не понятно с какими намерениями. Не храните все яйца в одной корзине!
И ещё не факт, что SSO-сайт надёжен. Или не хранит ваши пароли в открытом виде. Или не сливает вообще их добровольно, плюс предоставляет возможность другим отслеживать вас между сайтами. Ну вы поняли.
Поэтому: логин + пароль = зло. А всё зло в мире должно быть выпилено всерьез и надолго. И cookie тоже. Вместе с его сессионными крокодилами PHPSESSIONID, JSESSIONID, и их аналогами.
И что же делать?
Для начала необходимо рассмотреть типовые ситуации, из которых будет ясно: для чего сайты хотят запомнить своих клиентов и так ли это им на самом деле необходимо?
Понятно, что в разных ситуациях, могут быть разные риски. В одних случаях, неправильная идентификация, потеря аутентификационных данных или даже кража/подделка их, не приведет к каким-либо значимым последствиям как для сайта, так и для пользователя. В других, просто будет неприятно (потерял карму на Хабре – «беда-то какая...») или приведет к неудобству (не могу зайти под собой в Юлу, посмотреть свои объявления; профукал доступ к своим проектам на github, – ладно заведу новую учётку, форкну проекты). В третьих – может повлечь юридические и финансовые последствия. Поэтому, надо полагать, предлагаемая схема авторизации не «серебренная пуля» на все случаи, тем более «в голом виде». Там где проводится управление чувствительной информацией стоит использовать другие способы идентификации и аутентификации или их комбинации (двухфакторная авторизация, криптография на ассиметричных ключах, 3D-secure, eToken, OTP-Token и т.п.).
Ну хорошо. Какое ваше ТЗ?
- Персональный блог «Васи Пупкина», в котором, например, разрешены комментарии. Регистрация нужна лишь для того, чтобы защититься от ботов, проводить голосования без накруток, подсчитывать «лайки» и другие «мяу-мяу», назначать рейтинг комментаторам. Т.е. здесь функционал отслеживания нужен исключительно сайту, и лишь в малой степени – пользователю (если он дорожит своим рейтингом «комментатора» на этом сайте).
- Сайты соц.сетей и другие интернет-говорильни (аська, skype – туда же). Регистрация нужна для реализации именованного (авторского) контента, идентификации посетителей друг другом. Т.е. здесь функционал идентификации нужен в большей степени самим пользователям. Хотя сайты соц.сетей первые в списке «грешников», собирающих о посетителях максимально полную информацию и запоминающими вас в серьез и надолго. Так что ещё не известно, кому больше нужна идентификация.
- Корпоративный сайт с закрытым контентом. Регистрация или авторизация здесь нужны в основном для ограничения доступа к контенту. Всякие: онлайн школы, библиотеки, частные непубличные сайты, и прочее. Здесь функционал авторизации нужен в большей степени сайту. Открытых форм регистраций, как правило, нет. Учетные данные раздаются по другим каналам.
- Интернет-магазин и другая подобная площадка по продаже предметов, услуг или контента. Сюда же отнесу и сайты подачи платных/бесплатных объявлений. Регистрация, в основном, нужна, чтобы хранить историю заказов клиента, и чтобы он мог отслеживать их актуальный статус, хранить свои предпочтения (избранное); чтобы формировать клиенту персональные предложения на основе истории покупок и предпочтений. Здесь функционал идентификации нужен в равной степени как самому клиенту, так и магазину. Но больше, конечно же, магазину. Чтобы впаривать, впаривать и впаривать.
- Всякие личные кабинеты пользователей сервисов интернет-услуг: электронная почта, госуслуги, сбербанк-онлайн, мегафон-онлайн, кабинеты провайдеров, CMS от хостеров, и т.п. Здесь в правильной и надежной идентификации заинтересован в первую очередь сам пользователь. Ведь он управляет значимой для себя информацией, имеющей в некоторых ситуациях юридические и финансовые последствия. Тут анонимностью не пахнет. Она здесь вредна.
- Роутеры, консоли управления, web-версии управления чем-либо в домашней или корпоративной сети.
Понятно, что в разных ситуациях, могут быть разные риски. В одних случаях, неправильная идентификация, потеря аутентификационных данных или даже кража/подделка их, не приведет к каким-либо значимым последствиям как для сайта, так и для пользователя. В других, просто будет неприятно (потерял карму на Хабре – «беда-то какая...») или приведет к неудобству (не могу зайти под собой в Юлу, посмотреть свои объявления; профукал доступ к своим проектам на github, – ладно заведу новую учётку, форкну проекты). В третьих – может повлечь юридические и финансовые последствия. Поэтому, надо полагать, предлагаемая схема авторизации не «серебренная пуля» на все случаи, тем более «в голом виде». Там где проводится управление чувствительной информацией стоит использовать другие способы идентификации и аутентификации или их комбинации (двухфакторная авторизация, криптография на ассиметричных ключах, 3D-secure, eToken, OTP-Token и т.п.).
Ну хорошо. Какое ваше ТЗ?
Что предлагает новый протокол?
С точки зрения конечного пользователя:
Понятно. А какие бонусы должны получить с этого разработчики сайтов?
Наконец:
Отталкиваясь от указанных требований, перейдем к самому интересному: проектированию нового протокола.
- Сайт должен запоминать и узнавать посетителя без какого-либо ввода данных со стороны пользователя; сайт должен узнавать вас как в пределах сессии, так и между разными сессиями. Никаких cookie, паролей и регистраций. При этом разные сайты не должны получать возможность взаимно однозначно идентифицировать одного и того же посетителя, получая возможность отслеживать его активность на этих и других сайтах. Т.е. сайты не должны получить возможность агрегирования информации по своим посетителям.
- Пользователь должен получить возможность «забыть любой сайт» в любое время; и сайт забудет пользователя. Должна быть возможность предоставления прав сайту запомнить клиента по инициативе клиента (без навязчивых popup). Пользователь должен получить возможность безопасной миграции своей виртуальной личности между разными устройствами и браузерами (если ему это нужно), чтобы иметь единую авторизацию на любимых сайтах.
Понятно. А какие бонусы должны получить с этого разработчики сайтов?
- Более простая процедура идентификации: нет необходимости создавать в тысячный раз очередную форму логина, логаута, регистрации, изменения и восстановления пароля. Достаточно активировать модуль поддержки протокола под ваш любимый framework, реализованный на базе стандарта.
- Дизайнеру нет необходимости рисовать форму логина и думать, куда бы её спрятать на маленьком мобильном экране. Протокол делает формы ненужными вообще. Ну разве что форму регистрации. Куда же без них то. Увы.
Наконец:
- Протокол аутентификации должен быть единым и стандартизированным; проверенным экспертами по безопасности; одобрен и рекомендован комитетами по стандартизации веб-стандартов. Как результат, должна быть исключена возможность допуска классических ошибок веб-мастерами при разработке стандартных форм логина/логаута, смены/восстановления пароля (передача паролей в открытом виде, неправильное применение хеширования, хранение в базе паролей или «незасоленных» хешей, угон паролей пользователей при взломе сайта).
- Авторизация должна быть в определенной степени надежна (защищена от подделки, неправомерного доступа, с гарантированной аутентификацией); не создавать новых уязвимостей на веб-страницах и в браузерах; по возможности снизить риски известных сетевых атак «из коробки». Ну или по крайней мере, существенное уменьшение рисков успешного их проведения.
Отталкиваясь от указанных требований, перейдем к самому интересному: проектированию нового протокола.
1 Концепция беспарольной идентификации
1.1 Ключи и токены вместо логинов и паролей
Для каждого домена, включая дочерние, браузер клиента генерирует случайным образом уникальный 256-битный ключ
 . Этот ключ никогда не передается. Остается постоянным в пределах сессии пользователя. При каждой новой сессии создается новый ключ.
. Этот ключ никогда не передается. Остается постоянным в пределах сессии пользователя. При каждой новой сессии создается новый ключ.На основе ключа
браузер по специальному алгоритму генерирует 256-битный* токен  для идентификации пользователя конкретным доменом. Идентификационный токен пользователя (далее просто – токен) служит заменой сессионных cookie, подобных PHPSESSIONID и JSESSIONID.
для идентификации пользователя конкретным доменом. Идентификационный токен пользователя (далее просто – токен) служит заменой сессионных cookie, подобных PHPSESSIONID и JSESSIONID.Ключ
может быть «зафиксирован» пользователем. Фиксация ключа позволит пользователю оставаться авторизованным на сайте не ограниченно долго в разных сессиях браузера и возвращать ранее имевшуюся авторизацию. Это аналог функции «запомнить меня».При отмене фиксации, браузер «забудет» этот ключ и снова начнет формировать случайный ключ для данного домена при каждой новой сессии (начиная с текущей), что является аналогом «выхода» пользователя из сайта. Выход мгновенный, не требующий перезагрузки страницы.
Пользователь может создать для домена постоянный ключ. Постоянный ключ, как и зафиксированный, позволит пользователю возвращать ранее имевшуюся авторизацию. Фактически этот ключ становится заменой связи «логин-пароль».
Пользователь получает возможность управлять моментами, когда браузер для домена будет использовать постоянный ключ, а когда – случайный. Это аналог функции «логин / логаут». Концепция представлена на скриншотах ниже.
Способы формирования постоянных ключей доменов обеспечивают мобильность учетных записей пользователя между разными устройствам. Протоколом определяются следующие:
- формирование ключа домена на базе мастер-ключа пользователя
- формирование индивидуально ключа домена на базе биологического датчика случайных чисел
- импортирование существующих ключей из ключевого файла с другого устройства
1.2 Структура токена
Токен представляет собой 256-битную структуру, представляемую в виде шестнадцатеричной строки:
| 84bc3da1b3e33a18e8d5e1bdd7a18d7a | 166d77ac1b46a1ec38aa35ab7e628ab5 |
| идентификационная часть | аутентификационная часть |
Идентификационная часть токена (старшие 128 бит) аналогична логину. По этой последовательности бит сервер может однозначно идентифицировать пользователя.
Аутентификационная часть токена (младшие 128 бит) аналогична паролю. Эта последовательность бит помогает серверу валидировать токен.
Правила валидации токена описаны ниже.
1.3 HTTP-заголовки протокола
Заголовки, используемые клиентом:
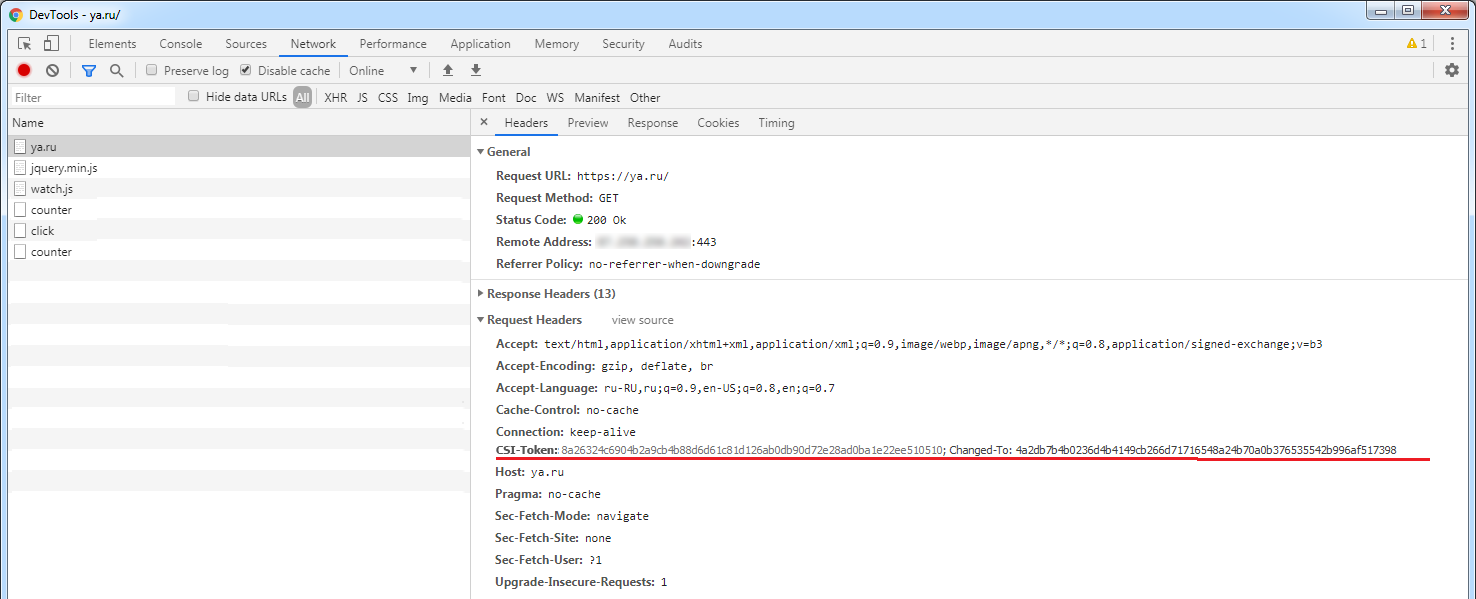
CSI-Token: <Token> используется для отправки токена серверу
CSI-Token: <Token1>; Changed-To <Token2> используется для изменения текущего токена:
- при авторизации на постоянном ключе,
- при регистрации постоянного ключа,
- при изменении постоянного ключа.
CSI-Token: <Token> Permanent используется при фиксации текущего случайного ключа пользователем.
CSI-Token: <Token> Logout используется для досрочного завершения текущей сессии.
Заголовки, используемые сервером:
CSI-Support: yes указывает клиенту, что сервер поддерживает протокол авторизации CSI.
CSI-Token-Action: success используется для уведомления браузера о принятии нового токена пользователя (ключ Change-To).
CSI-Token-Action: abort отменяет процедуру смены токенов (откат к предыдущему токену).
CSI-Token-Action: registration сообщает браузеру, что новый токен пользователя всё ещё находится в процессе регистрации.
CSI-Token-Action: invalid ошибка верификации токена на стороне сервера.
Наконец,
CSI-Salt посылается и браузером, и сервером при обмене «солью», используемой для защиты токена (аутентификационной части). Подробнее смотрите ниже.
1.4 Как происходит идентификация клиентов сайтами?
Сайт может использовать токен для идентификации посетителя сайта. При этом схема генерации токенов и их 256-битная разрядность гарантирует уникальность токенов для каждой пары: пользователь-домен. Другой домен будет видеть уже другой токен пользователя. Даже если исполняется в контексте целевого сайта (через IFRAME, IMG, LINK, SCRIPT). Кроме того, специальный алгоритм генерации токенов защищает пользователей от атак XSS, СSRF и делает невозможным трекинг пользователя без его ведома. Но при этом оставляет возможным технологию SSO с его разрешения и меж-доменную идентификацию.
Токен передается в HTTP-заголовке CSI-Token при каждом запросе к любому ресурсу домена (страница, документ, изображение, скрипт, стиль, шрифт, файл, ajax-запрос, ...):
Токен вычисляется заново при каждом HTTP(S)-запросе: страница, картинка, ajax-запрос.
В целях оптимизации вычислений, допускается кэширование токенов браузером, но только на время действия сессии и только в случае неизменности условий выполнения запроса.
Как уже было отмечено выше, токен может служить заменой сессионных cookie, подобных PHPSESSIONID и JSESSIONID. С той лишь разницей, если раньше сайт генерировал посетителю идентификатор, чтобы отслеживать конкретного пользователя между его разными запросами (ведь на сайт одновременно приходят тысячи запросов от разных пользователей), то теперь эту функцию выполняет сам клиент.
Такая идентификация вполне достаточна для того, чтобы позволить совершать покупки в интернет-магазине, давать объявления на соответствующих площадках, писать на форумах, в социальных сетях, статьи на Википедии или Хабре.
Да, пользователь остается для сайта анонимным. Но это может быть «знакомый» сайту аноним. И сервер может сохранить токен такого пользователя на своей стороне, вместе с его данными (личный кабинет с покупками, предпочтениями, кармой, плюшками, лайками и другими бонусами). Но только сохранить при условии завершения какого-либо бизнес-процесса: покупки, подачи объявления, и т.п. Условия определяет сам сайт.
Как видно, протокол максимально прост для сайтов, которым нет необходимости регистрировать вас прежде, чем дать возможность совершить какие-либо действия. А вот тем, кому это необходимо, придется чуть сложнее. Но об этом ниже.
1.4.2 Как узнать, что сайт поддерживает этот протокол?
Сайт должен передавать http-заголовок CSI-Support: yes в секции Response Headers своего ответа:

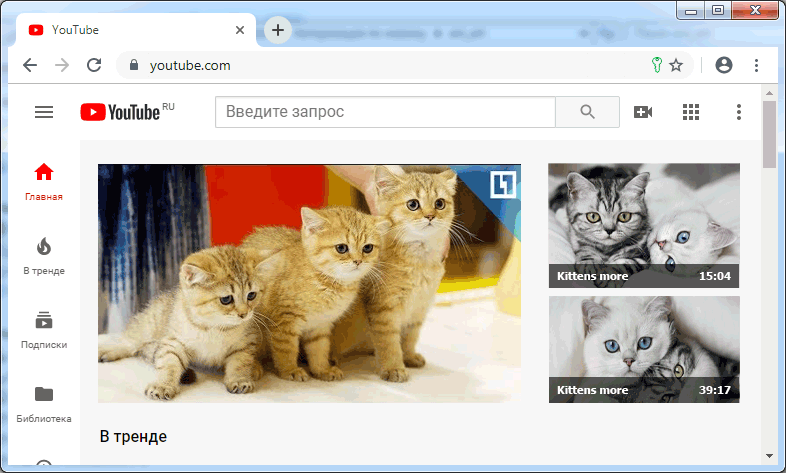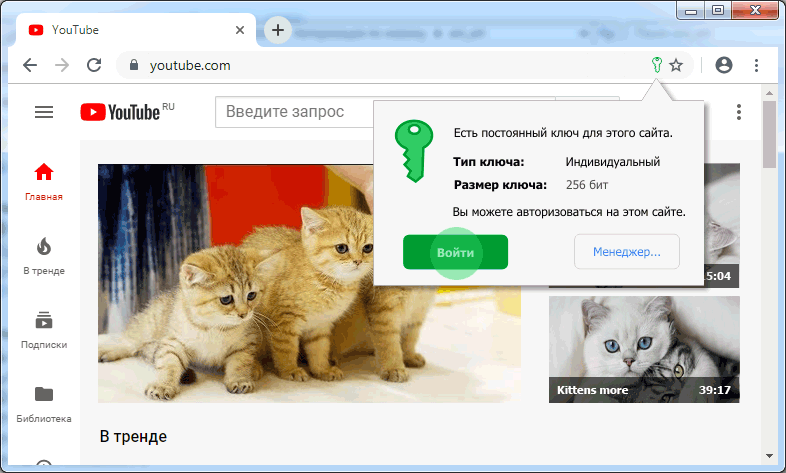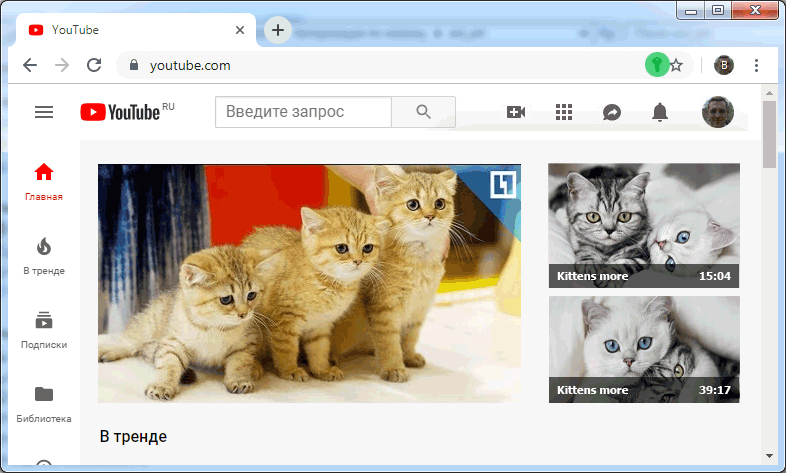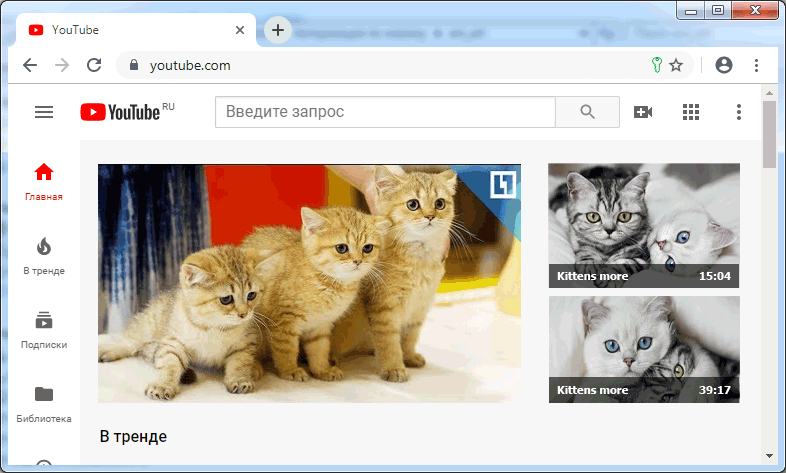
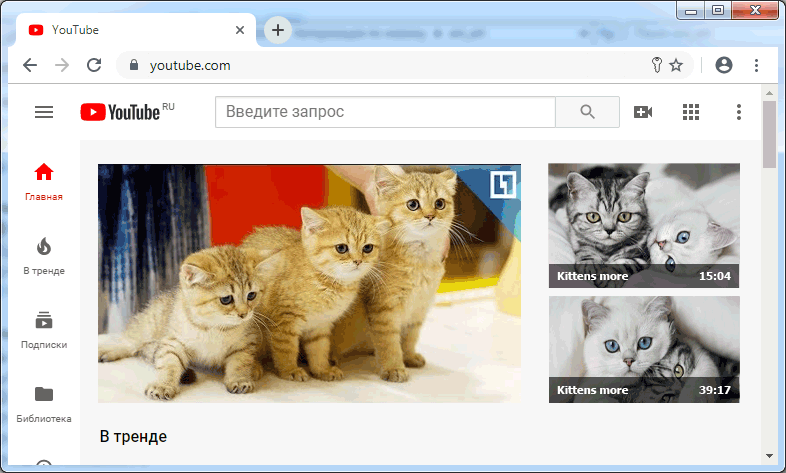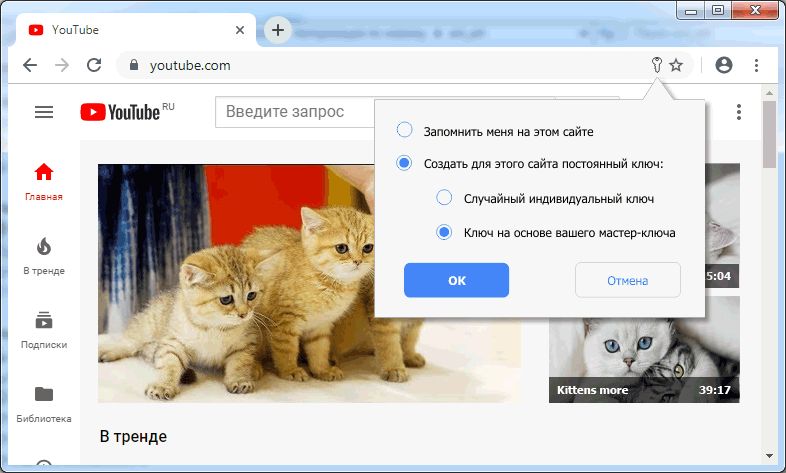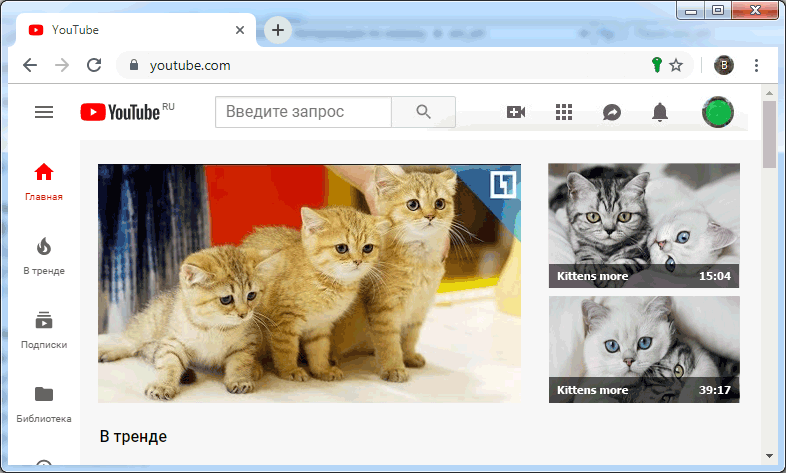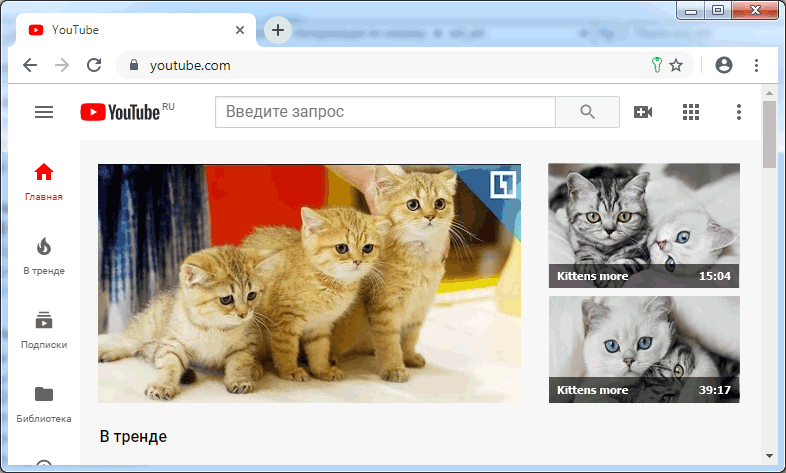
Увидев такой заголовок, браузер ненавязчиво сообщит пользователю, что тот может сохранить себя на сайте. Например, символом ключа в адресной строке:

Щелчок по ключу, например, позволит создать ключ для домена www.youtube.com:

Формирование нового ключа не приводит к его автоматическому использованию.
Постоянный ключ начинает использоваться только при его активации пользователем.
1.5 Как происходит авторизация клиентов сайтами?
Важно понимать, что токен ещё не делает пользователя авторизованным на конкретном сайте, – только узнаваемым. Но, как уже было ранее сказано, для него вы пока – просто узнаваемый «аноним».
Если сайту необходимо связать ваш токен с вами лично, регистрации на таком сайте, увы, не избежать. Но в предлагаемом протоколе это делается чуть проще.
Разработчикам важно понимать: анкета не обязательно нужна большинству сайтов. Избегайте принуждения посетителей к обязательной регистрации. В большинстве типовых ситуаций вы можете осуществить бизнес-процесс без сбора ПДн посетителей.
Заполнение нудных форм регистрации «по поводу и без» неприятно. Но с новым протоколом придумывать очередной логин и пароль не уже требуется. Только кнопка «Подтвердить и сохранить меня»:

Вам, конечно же, придется предварительно создать постоянный ключ для сайта. Но это вопрос пары кликов мышкой.
И, наверняка, вас попросят подтвердить свой телефон или почтовый адрес. Но это уже зависит от сайта.
После успешной авторизации сервер, посредством специального HTTP-заголовка CSI-Token-Action сообщит браузеру, что он принял новый ключ. Более подробно в главе II.
1.6 А как реализовать надежную идентификацию клиентов?
В более серьезных ситуациях (личный кабинет провайдера, хостинга, банка) должна и может осуществляться двухфакторная аутентификация, а доказательство обладанием токена производиться через предварительную регистрацию и подтверждение личности иными способами: по электронной почте, СМС, или даже бумажной фиксацией токена пользователя. (Да, да. Сертификаты фиксируются бумажными носителями, почему бы и токенам не быть).
1.7 Авторизация на сайте глазами пользователя
Браузер уведомляет пользователя, что сайт поддерживает авторизацию CSI, через иконку замка в адресной строке. Если вы совершаете на сайте некоторые действия, вы можете попросить сайт запомнить вас. С этого момента сервер будет узнавать пользователя даже между разными сессиями:

На иллюстрации
Вначале мы бродим по сайту, смотрим товары. Затем решаем сохранить в избранном понравившийся товар, чтобы в дальнейшем, может быть, купить его здесь. Чтобы сайт запоминал нас, мы фиксируем ключ. Добавляем товар в избранное. А затем закрываем вкладку. Через несколько дней, вернувшись на сайт, видим, что в избранном лежат наши товары. Сайт узнал нас. Делаем покупки.
Вместо фиксации ключа, пользователь может создать постоянный ключ для сайта и пройти там регистрацию. Анимированная иллюстрация:

На иллюстрации
Входит на сайт. Создает постоянный ключ. Активирует его. Сайт переводит пользователя на форму регистрации.
Пользователь заполняет поля формы регистрации, нажимает «Зарегистрировать меня». Сайт пускает пользователя в закрытый раздел.
Пользователь заполняет поля формы регистрации, нажимает «Зарегистрировать меня». Сайт пускает пользователя в закрытый раздел.
А когда пользователь имеет постоянный ключ для сайта и этот ключ там зарегистрирован, то процесс входа существенно упрощается:
На иллюстрации
Входит на сайт. Видит, что есть постоянный ключ. Активирует его, делая «Вход». Сайт узнает пользователя, подгружая профиль.
Наибольшая сила протокола проявляется, когда пользователь создает ключ для сайта на базе мастер-ключа. В этом случае легко решается задача вашей идентификации на сайтах на других устройствах. Следующая анимация демонстрирует это. Предполагается, что вы предварительно однажды распространили свой мастер-ключ между своими устройствами / браузерами:
На иллюстрации
Входит на сайт с другого устройства. Создает постоянный ключ сайта на базе мастер-ключа. Активирует его. Сайт узнает пользователя (демонстрируется его профиль).
Для сайтов с двух-факторной авторизацией «узнавание» может выглядеть так:

На иллюстрации
Входит на сайт. Активирует постоянный ключ. Сайт узнает пользователя и предлагает продолжить аутентификацию. Пользователь нажимает продолжить; вводит код из СМС. Сайт авторизует пользователя.
Выход осуществляется ещё проще. Нажимаете в браузере «Выйти» и всё:

Браузер посылает сайту запрос (на любую его страницу) с методом HEAD, в котором передает заголовок CSI-Token <>; Logout.

Сервер, видя такой заголовок, делает Logout. Если это был фиксированный ключ, то сайт удаляет всю информацию о пользователе (более такой ключ никогда не появится). Если это был постоянный ключ, просто разрывает сессию.
Любая дальнейшая активность сайта превращает пользователя в неизвестного сайту анонима: перезагрузка страницы, попытка сделать ajax-запрос, скачать файл и т.п. – браузер будет посылать токен, сформированный уже на базе случайного ключа.
Вы можете управлять ключами в менеджере ключей: поменять постоянный ключ, экспортировать постоянный ключ в файл, импортировать из файла с другого устройства. Настроить «автовыход» после закрытия вкладки или браузера. Задать время действия фиксированного ключа.
1.8 Как происходит смена ключа сайта?
Замена постоянного ключа сайта технически происходит также, как и переход со случайного ключа на постоянный. Более подробнее это описано в главе II.
В случае смены постоянного ключа сайта, браузер уведомляет сайт о соответствующем изменении токена, посылая в каждом последующем запросе заголовок CSI-Token с ключом Changed-To:
Сайт должен корректно обработать такой запрос. И, если данный токен пользователя сохранен в его базе, должен сделать соответствующую замену. При этом сайт должен ответить браузеру об успешном изменении токена на своей стороне. Делает он это в заголовке ответа (Response Headers) параметром: CSI-Token-Action: success, с указанием примененного токена.
Сайт имеет право отвергнуть попытку изменения токена (например, если такого токена в его базе не было или он их вообще их не сохраняет) параметром CSI-Token-Action: aborted.
До тех пор, пока браузер не получит заголовок CSI-Token-Action, он в каждый запрос к сайту в заголовок CSI-Token будет добавлять ключ Changed-To.
Это аналог «смены пароля» пользователя.
1.9 Как реализуется кросс-доменная авторизация?
Классическая кросс-доменная авторизация по технологии SSO имеет для пользователя много плюсов. Вам нет необходимости помнить кучу паролей от кучи сайтов. Нет необходимости в регистрации и заполнении муторных форм. Некоторые сервера авторизации спрашивают какие права предоставить сайту, запросившему SSO.
Но есть и недостатки. Вы в зависимости от поставщика SSO. Если не работает сервер SSO, на целевой сайт вы не попадете. Если вы теряете пароль или у вас угоняют вашу учётку – вы разом теряете доступ от всех сайтов.
Для веб-разработчиков всё чуть сложнее. С начала необходимо зарегистрировать свой сайт на сервере авторизации, получить ключи, научиться работать с протоколом (SAML, OAuth и т.п.) и соответствующими библиотеками, следить, чтобы не истёк срок ключа, чтобы сервер авторизации не заблокировал ваш сайт по своим разумениям и т.п. Это плата за то, что вам нет необходимости хранить у себя учетные записи пользователей, делать формы регистрации, логина и т.п. Правда увеличивает стоимость сопровождения (в виде починки внезапных отказов). Опять же, если сервер внезапно недоступен сайту, то увы.
Данная схема авторизации делает SSO чуть более безопасной, а авторизацию для всех участников более простой. Про безопасность будет сказано ниже в разделе «Компрометация ключа для SSO».
Пусть вы заходите на сайт S, поддерживающем SSO от Google. Пусть у вас есть учётная запись на Google. Чтобы авторизоваться, вы нажимаете ссылку «Войти через Google», которая откроет вкладку авторизации Google. Браузер сообщит вам, что вы имеете ключ для Google. А Google сообщит, какие права запрашивает S.
Если вы согласны, нажмете «Войти» в менеджере ключей. Страница перезагрузится. Уже Google получит свой валидный токен, узнает и авторизует вас. И меж-серверным запросом сообщит сайту S информацию о вашей учетной записи в соответствии с запрошенными полями.
Перезагруженная страница будет содержать кнопку «Далее», возвращающая вас на целевой сайт.
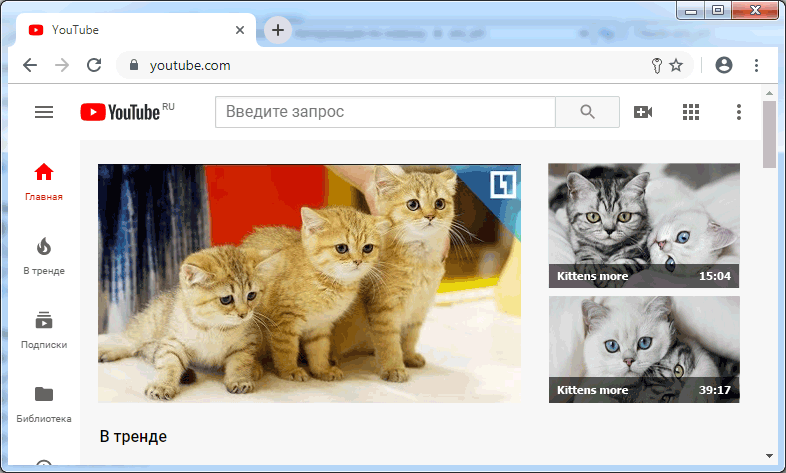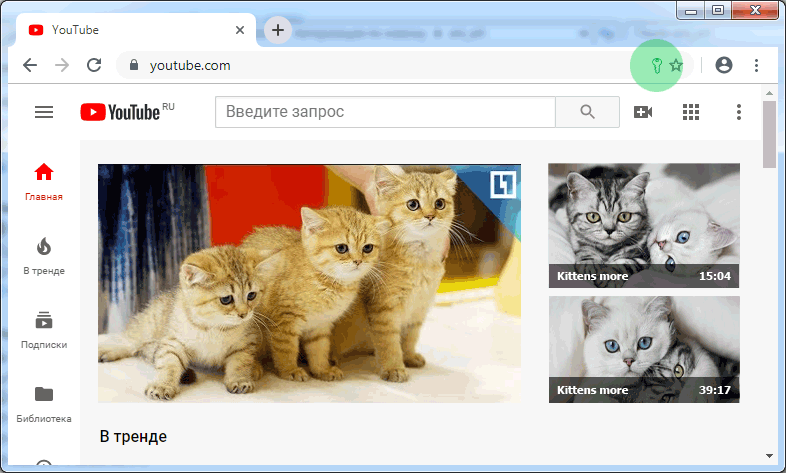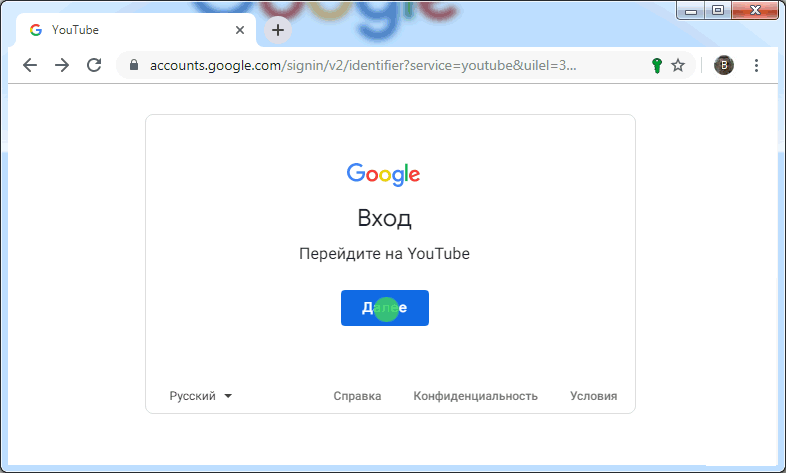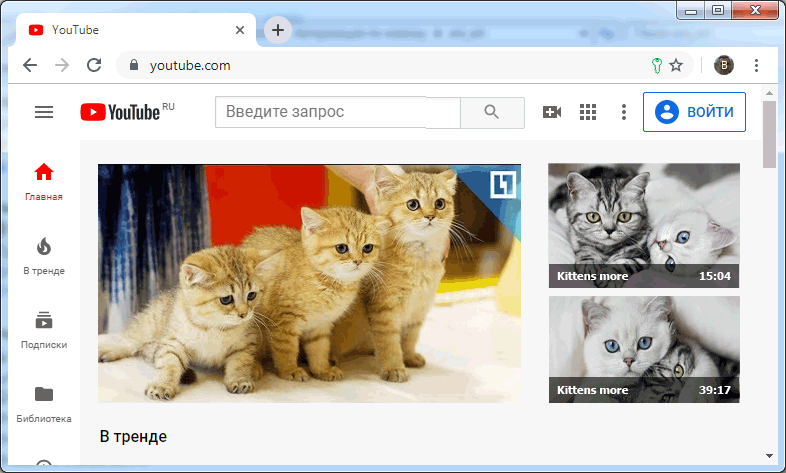
На иллюстрации
Приведет пример данного алгоритма при регистрации на сайте www.youtube.com с использованием кросс-доменной авторизации через accounts.google.com.
Сайт S может принять решение сохранить данные о вас в своей БД или нет. Этот вопрос выходит за рамки предлагаемой схемы авторизации. Но далее, где мы будем рассматривать риски утраты ключа для SSO, сайту рекомендуется сохранять токен пользователя и идентификатор от SSO на своей стороне, а пользователю рекомендует создавать постоянный ключ для S.
Уязвимость: После такой авторизации, сайты S1, S2, S3, … (где вы авторизовались через Google) смогут узнавать вас (по назначенному вам идентификатору от Google), и, как следствие, отслеживать вашу деятельность.
Вариант защиты: не работать одновременно на сайтах, если вы регистрировались через SSO одного и того же поставщика. По возможности, делать логаут из сервера авторизации сразу же после завершения авторизации («автовыход» для домена).
1.10 Как реализовать меж-доменную идентификацию?
Всё это, конечно, хорошо. Пока работа осуществляется на одном браузере – всё отлично. А как быть с современными реалиями, когда у человека два мобильных телефона, один рабочий компьютер и несколько браузеров на нем, домашний компьютер, и ещё ноутбук? Плюс общий планшет жены/детей.
Придется как-то решать вопрос с переносом ключей доменов между браузерами, устройствами. А ещё решить вопрос их правильной синхронизации.
Одним из механизмов решения данной задачи является вычисление различных ключей доменов на базе общего мастер-ключа без возможности обратного восстановления мастер-ключа по известному ключу домена.
Создав при помощи мастер-ключа M персональный ключ K для домена D на одном устройстве, пользователь сможет создать тот же самый ключ K для домена D и на любом другом при помощи всё того же мастер-ключа M и единого алгоритма. Точнее это сделает не пользователь, а его браузер. При таком подходе пользователю достаточно распространить свой мастер ключ между всеми используемыми им браузерами и он разом «переносит все свои ключи» доменов. Заодно делает таким образом резервные копии.
Максимальное удобство для пользователя. Но и максимальный риск в случае компрометации мастер-ключа. Поэтому последний должен защищаться соответствующим образом. О рисках утраты или компрометации мастер-ключа, о способах минимизации таких рисков написано в главе «3 Рекомендации по безопасности».
Использование только одного мастер-ключа для генерации всех ключей для всех доменов не всегда удобный вариант. Во-первых, как быть, если вдруг ключ домена скомпрометирован и его необходимо поменять? Во-вторых, что если нужно поделиться ключом домена с другим человеком? Например, между членами семьи. Или это корпоративная учётная запись на доступ к общей почте. Как затем «забрать» свой ключ (ведь по факту он скомпрометирован)?
Поэтому генерация индивидуальных ключей доменов при помощи биологического датчика случайных чисел должна поддерживаться браузерами. Но тогда мы вновь возвращаемся к вопросу нашей мобильности и вопросам синхронизации, функций экспорта и импорта ключей в браузере, создания резервных копий.
Перенос через физическое отчуждаемое устройство
Смарт-карты и usb-токены могут вполне подойти в качестве защищенного хранилища ключевой информации (ибо для этого и создавались). Двухфакторная аутентификация защищает ключи от НСД при непосредственном доступе к устройству.
Правда для смарт-карт требуются специальные считыватели (не говоря уже про драйвера), что ограничивает их применение только рабочими станциями, оборудованными такими считывателям.
С USB-токенами чуть проще. Требуются только драйвера. Вот только такой токен в телефон не воткнешь. И хотя для мобильных телефонов существуют токены, выполненные в виде SD-карт, не сказать, что данное решение добавляет к мобильности. Попробуй вытяни карту из мобильника, да вставь в другой. И речь не о том, что это невозможно. Речь о том, что это не удобно.
А если токен поломается? Тогда все ваши ключи уйдут к «Великому Ктулху».
Так что появится соблазн при такой схеме использовать несколько устройств-дубликатов. Но тогда ещё необходимо решить вопрос с синхронизацией ключей, если у вас несколько смарт-карт.
Да и, честно говоря, не защищены такие устройства от клавиатурных шпионов. Вот если бы пин-код вводился бы с самой карты/токена. Тогда другое дело. Но я таких в природе не видел.

Плюсы: можно использовать случайный 256-биные ключи; высокая безопасность за счёт использования двухфакторной аутентификации; высочайший уровень защиты от прямого НСД.
Минусы: зависимость от устройств; требует финансовых затрат; низкая мобильность; необходимость резервирования карт и, как следствие, синхронизации данных между ними; уязвимость к клавиатурным шпионам сохраняется.
Синхронизация через онлайн-сервис
«Облачные технологии» сейчас пихаются куда только можно. Похоже они, вкупе с блокчейном, стали заменой «банано-технологиям». Естественно, возникает желание, использовать некую интернет-площадку для обмена ключевой информацией. Этакая смарт-карта «онлайн».
А что? Авторизуешься по нашей схеме анонимно на таком сайте; отправляешь туда свои ключи зашифрованные паролем; заходишь с другого устройства на этот же сайт с тем же ключом/паролем; получаешь от туда ключи; синхронизируешь изменения по дате правки. Аналогично менеджеру паролей, только это онлайн.
Вот только, никто не гарантирует, что онлайн-сервис не будет взломан или не станет сам сливать ваши, пусть и зашифрованные, ключи «куда надо». Кто будет за бесплатно реализовывать такой сервис. То-то и оно.
Хотя, конечно, пароль защищает ключи от прямого использования. Но устойчив ли ваш пароль к брут-форсу «офлайн»? Тот ещё вопрос.
Плюсы:высокая мобильность учетных данных; независимость от устройства и браузера; нужен всего один единственный пароль (хотя от пароля не ушли, но уже лучше).
Недостатки:менее безопасно, чем хранение ключей на отчуждаемом носителе. Фактически безопасность ключей основана на стойкости пароля к подбору.
Можно, конечно, использовать для шифрования других ключей мастер-ключ. Тот самый, при помощи которого вычисляются другие ключи доменов. Как вариант.
2 Техническое описание протокола
2.0 Алгоритм формирования ключа домена
Настоящий протокол определяет только 2 способа формирования ключей домена
- на базе генератора случайных чисел (желательно биологического)
- на базе 256-битного мастер ключа
В последнем случае ключ домена вычисляется как:

 – 256-битный мастер-ключ, Domain – доменное имя, для которого делается ключ.
– 256-битный мастер-ключ, Domain – доменное имя, для которого делается ключ.Здесь и далее HMAC – алгоритм криптографического вычисления хеша на основе 256-битной реализации хеш-функции SHA-2.
Компрометация или добровольное разглашение ключа домена не приводит к компрометации исходного мастер-ключа.
Мастер-ключ обеспечивает механизм мобильности учётных данных пользователей.
На заметку
В первоначальной версии протокола рассматривался вариант генерации ключей домена на базе пароля пользователя, как обеспечивающий мобильность пользователей, и защищающий от компрометации пароля при взломе сайта. Но в главе «3 Рекомендации по безопасности» будут даны пояснения, почему от такой схемы было принято решение отказаться.
Если ключ, созданный на базе «мастера», был скомпрометирован, либо был скомпрометирован токен, вычисленный от такого ключа (в результате взлома сайта), то ключ необходимо поменять. Поменять можно на случайный 256-битный ключ, либо сгенерировать от того же «мастера», с добавлением версии:

 будет использоваться для операции конкатенации строк (массивов байт).
будет использоваться для операции конкатенации строк (массивов байт).2.1 Алгоритм вычисления исходного токена
Идентификационный токен пользователя вычисляется при каждом запросе любого ресурса домена. Для вычисления токена запроса берутся следующие данные:
- Sender – доменное имя инициатора запроса (им может быть страница с iframe или скрипт с чужого домена, выполняющий fetch),
- Recipient – доменное имя получателя (куда отправляется запрос),
- Context – контекст выполнения запроса,
- Protection – случайная последовательность 32-х байт (256-бит), если Context пуст; иначе пусто
Эти данные конкатенируются и подвергаются хэшированию 256-битной SHA-2 на ключе K домена-инициатора запроса:

Валидный токен получается, когда Context не пуст. Для правильной идентификации на целевом сайте необходимо, чтобы выполнялось условие Sender = Recipient = Context.
Поле Context вкупе с Protection используется для защиты от XSS и CSRF-атак, а также от трекинга пользователя.
Более подробные пояснения по правилам определения Sender / Recipient / Context будут даны ниже.
2.2 Алгоритм защиты токена при передаче
Исходный токен клиента передается крайне редко. Только при передаче незарегистрированного токена в момент создания сессии.
Токен считается незарегистрированным, если он: создан на базе случайного (не зафиксированного) ключа; не был принят сервером после отправки ключа Change-To или Permanent. Подробнее см. «Обработка токенов на сервере».
Браузер и сервер совместно вырабатывают пару случайных чисел, т.н. соль (Salt), при помощи которой хешируются младшие 128 бит токена. Оба обмениваются этими числами согласно протоколу. Подробнее см. «Процедура обмена солью между браузером и сервером».
Таким образом, сервер сайта видит следующий токен:

 – старшие 128 бит,
– старшие 128 бит,  – младшие 128 бит исходного токена, – конкатенация строк. При этом исходный токен
– младшие 128 бит исходного токена, – конкатенация строк. При этом исходный токен  должен быть уже известен серверу.
должен быть уже известен серверу.В идеале CSI-Salt должен меняться при каждом запросе браузера к серверу. Однако это может быть затратным требованием с точки зрения вычислительных ресурсов. Кроме того, это может «убить» возможность отправки параллельных запросов на сервер.
Поэтому допускается, в целях оптимизации расчетов, сохранение неизменным значения CSI-Salt в разных запросах, но не дольше одного сеанса. Это может быть ограничение по времени (смена CSI-Salt каждые 5 минут), либо реакция на интенсивность запросов (смена CSI-Salt через каждые 100 запросов), либо после каждой серии запросов (в момент паузы клиент-сервер), либо смешанный вариант. Здесь решение оставляется за разработчиками браузеров.
Слишком долгое удержание неизменным CSI-Salt ослабляет защиту передаваемого токена, позволяя злоумышленнику, при перехвате токена, воспользоваться им, пока легальный пользователь не выполнил Logout, и выполнить неавторизованный запрос от имени жертвы.
2.3 Процедура обмена солью между браузером и сервером
2.3.1 Токен на базе случайного или незарегистрированного[1] сервером ключа.
| Браузер | Сервер |
|---|---|
| Первичный запрос (инициализация сессии пользователя) | |
| Браузер отправляет токен как есть. В запросе отсутствует CSI-Salt. |
Сервер впервые видит такой токен. между прочим Сервер может и не впервые видеть такой токен. А браузер его считать незарегистрированным. Это может произойти при пересоздании ключа на базе мастер-ключа на другом устройстве. Поэтому такая ситуация тоже должна учитываться. Воспринимает его как есть (считает его незащищенным). Использует этот токен как идентификатор сессии. Генерирует свою соль Ssalt. Возвращает её в ответе в заголовке CSI-Salt. |
| Второй запрос | |
| Генерирует соль Сsalt. Браузер соединяет[3] свою соль и соль сервера. Браузер отправляет запрос, передавая защищенный совместной солью токен. Посылает CSI-Salt. |
Сервер получает запрос и извлекает CSI-Salt клиента. Сервер соединяет соль браузера со своей и использует для проверки токена. Если валидация токена успешна, предоставляет пользователю контент в соответствии с его правами. При ошибках проверки возвращает клиенту заголовок CSI-Token-Action: invalid. Выдавать контент или возвращать пустой ответ: зависит от сервера. |
| Последующие запросы | |
| Браузер отправляет запрос, передавая защищенный совместной солью токен. В запросе отсутствует CSI-Salt. |
Сервер получает запрос и проверяет его токен. Если валидация токена успешна, предоставляет пользователю контент в соответствии с его правами. При ошибках проверки возвращает клиенту заголовок CSI-Token-Action: invalid. Выдавать контент или возвращать пустой ответ: зависит от сервера. |
| Через некоторое[2] время работы | |
| Генерирует новую соль Сsalt. Соединяет новую соль с солью сервера. Отправляет запрос, передавая защищенный новой совместной солью токен. Посылает CSI-Salt. |
Сервер получает запрос и извлекает новую CSI-Salt клиента. Сервер соединяет соль браузера со своей и использует для проверки токена. Если валидация токена успешна, предоставляет пользователю контент в соответствии с его правами. При ошибках проверки возвращает клиенту заголовок CSI-Token-Action: invalid. Выдавать контент или возвращать пустой ответ: зависит от сервера. |
2.3.2 Токен на базе зарегистрированного[1] сервером ключа.
| Браузер | Сервер |
|---|---|
| Первичный запрос (инициализация сессии пользователя) | |
| Генерирует соль Сsalt. Посылает CSI-Salt. Передает токен в защищенном виде. |
Сервер получает запрос и извлекает CSI-Salt клиента. Читает защищенный токен. Находит полный токен клиента в своей базе (использует для поиска первые 128-бит полученного в запросе токена). Т.к. это первичный запрос, сервер не посылал соль клиенту, то валидация токена на данном этапе производится только солью клиента. При ошибках проверки возвращает клиенту заголовок CSI-Token-Action: invalid. Выдавать контент или возвращать пустой ответ: зависит от сервера. Если валидация токена успешна, предоставляет пользователю контент в соответствии с его правами. Генерирует свою соль Ssalt. Возвращает её в ответе в заголовке CSI-Salt. |
| Последующие запросы | |
| Браузер соединяет свою соль и соль сервера. Браузер отправляет запрос, передавая защищенный совместной солью токен. В запросе отсутствует CSI-Salt. |
Сервер получает запрос и проверяет его токен. Если валидация токена успешна, предоставляет пользователю контент в соответствии с его правами. При ошибках проверки возвращает клиенту заголовок CSI-Token-Action: invalid. Выдавать контент или возвращать пустой ответ: зависит от сервера. |
| Через некоторое[2] время работы | |
| Генерирует новую соль Сsalt. Браузер соединяет новую соль с солью сервера. Браузер отправляет запрос, передавая защищенный новой совместной солью токен. Посылает CSI-Salt. |
Сервер получает запрос и извлекает новую CSI-Salt клиента. Сервер соединяет соль браузера со своей и использует для проверки токена. Если валидация токена успешна, предоставляет пользователю контента в соответствии с его правами. При ошибках проверки возвращает клиенту заголовок CSI-Token-Action: invalid. Выдавать контент или возвращать пустой ответ: зависит от сервера. |
[1] Токен считается незарегистрированным, если он: создан на базе случайного ключа; не был принят сервером после отправки ключа Change-To или Permanent ответом CSI-Token-Action: success.
[2] Время, через которое делается изменение CSI-Salt определяется браузерами самостоятельно. Это может происходить после серии запросов, после таймаута, после определенного числа запроса. Единственное ограничение – использование одного и того же CSI-Salt в разных сессиях запрещено.
[3] Имеется в виду конкатенация 16-ричного представления 128-битных чисел. Первым всегда берется соль клиента, вторым соль сервера: Сsalt || Ssalt. Если у браузера нет соли сервера – он хэширует токен своей солью, передавая её в заголовке. Если у сервера нет соли клиента, то он должен полагать, что токен передается незащищенным.
2.4 Правила формирования поля Context
Дисклеймер о правилах
Правила формирования этого поля довольно запутаны. Вполне допускаю вариант, что где-то допустил ошибку. Такие правила нужны для защиты от возможных атак на предлагаемую схему авторизации.
Чтобы лучше разобраться в возможных сценариях атак, введем несколько определений. И прошу прощения за введение терминов, которые могут отличаться от официальных.
Чтобы лучше разобраться в возможных сценариях атак, введем несколько определений. И прошу прощения за введение терминов, которые могут отличаться от официальных.
Будем называть нашим тот домен, страницу которого мы загружаем (отображается в адресной строке браузера). Остальные домены будем называть внешними. Даже если это дочерние домены данного.
Назовем ресурс внешним, если он был загружен с внешнего домена. Назовем ресурс внутренним, если он был загружен с нашего домена. Ресурсом может быть скрипт, изображение, ajax-запрос и любой другой файл.
Скрипт считается внешним, если он был загружен с внешнего домена. Скрипт, размещенный в созданном теге <script>, созданный внешним скриптом, тоже будет считаться внешним. Скрипт, располагаемый в измененном теге <script>, объявляется внешним, если изменялся внешним скриптом, или внешний скрипт присутствовал в цепочке вызовов при изменении его содержимого. Даже если при этом данный <script> изначально был на странице или был создан внутренним скриптом.
Назовем теги LINK, SCRIPT, IMG, IFAME и другие, которые требуют от браузера догрузить какой-либо ресурс, как только будут встречены парсером DOM – ресурсными тегами.
Назовем теги FORM, A, META и другие, которые могут инициировать загрузку страницы при определенных условиях (submit, click, timeout) – инициирующими тегами.
Назовем тег статическим, если он изначально присутствовал на странице при первичной выдаче сервером. Назовем тег динамическим, если он был создан в процессе работы скриптов.
Тег FORM объявляется динамическим, даже если изменялся не только сам тег, но и значения всех полей INPUT, связанных с этой формой.
Назовем динамический тег собственным, если скрипт его создавший, принадлежит нашему домену, а в цепочке вызовов инструкции, породившей данный тег, не было функции, принадлежащих внешнему скрипту. В противном случае считаем такой динамический тег несобственным.
Загрузка страницы провоцируется инициирующими тегами. Инициирующий тег может быть приведен в действие непосредственно пользователем, либо активирован скриптом, через выполнение команды click (для ссылки), и submit (для формы) или через генерацию скриптом соответствующих событий onclick/onsubmit.
Также инициирующий тег может быть приведен в действие браузером. Пример такого тега – META с параметрами http-equiv=«refresh» content=«0».
Таблица P. Значения Context при разных условиях открытия страницы
| Способ открытия | Кто спровоцировал загрузку страницы? | |||||
|---|---|---|---|---|---|---|
| Пользователь | собств. JS | внеш. JS | браузер | |||
| тег1 | Статический | P1. Referrer | P2. Variant3 | P3. Empty | P4. Inherit | |
| Динамический | Собственный | P5. Inherit | P6. Variant3 | P7. Empty | P8. Inherit | |
| Несобственный | P9. Empty | PA. Empty | PB. Empty | PC. Empty | ||
| Непосредственно | PD. Domain | PE. Variant3 | PF. Empty | PG. Variant4 | ||
та же таблица, только изображением
изображение
Если ресурсный тег был изменен скриптом (например атрибут SRC у IMG), а затем браузером автоматически загрузился ресурс, то считаем, что загрузка контента/ресурса спровоцирована парсером, способ загрузки — тег, но статус этого тега становится «динамическим».
Таблица R. Значения Context при разных условиях загрузки контента/ресурса
| Способ загрузки | Кем вызвана загрузка контента? | ||||
|---|---|---|---|---|---|
| DOM Parser | собств. JS | внеш. JS | |||
| тег2 | Статический | R1. Page | |||
| Динамический | Собственный | R4. Page | |||
| Несобственный | R7. Empty | ||||
| Непосредственно | RA. Referrer | RB. Page | RC. Referrer | ||
та же таблица, только изображением
изображение
[1] Инициирующий тег
[2] Ресурсный тег
[3] Inherit для своих же страниц, Empty при открытии страниц чужих доменов
[4] Inherit при редиректах сервером на свои страницы, Empty при редиректах на чужие домены или открытии страницы от внешних источников (см. разъяснения)
Пояснения к сокращениям
Referrer – значение совпадает с полем Referrer.
Page – домен вкладки (Tab) браузера от имени которой идет запрос.
Empty – пустая строка.
Domain – поле Context равно домену адресной строки
Inherit – значение Context наследуется от породившей страницы
Variant – значение Context зависит от атрибута «свой-чужой» у страницы
Page – домен вкладки (Tab) браузера от имени которой идет запрос.
Empty – пустая строка.
Domain – поле Context равно домену адресной строки
Inherit – значение Context наследуется от породившей страницы
Variant – значение Context зависит от атрибута «свой-чужой» у страницы
Пометки вида P1..PF, R1..RC будут использованы для отсылки к соответствующей ячейке таблицы при разборе конкретных ситуаций.
Обратите внимание на выделенные Referrer и Domain в первой таблице. Авторизованным на сайте вы сможете стать только, когда сами откроете сайт по прямому адресу, либо по ссылке с другого сайта, с последующей перезагрузкой страницы по вашей инициативе.
2.5 Правила определения полей Sender и Recipient
Sender – это домен страницы/скрипта/стиля, от которых идет запрос. Страница запрашивает стили, картинки, скрипты. Скрипты запрашивают контент через ajax. Стили могут подгружать другие стили. Это инициаторы запроса.
Recipient – это домен, на который реально уходит запрос.
Чтобы не осталось вопросов, рассмотрим на конкретных примерах.
Пусть есть сайт site.net. На главной странице сайта находится:
- стиль site.net/css/common.css
- в стилях common.css импортируется стиль fonts.google.com/fonts/Roboto.css
- стиль Roboto.css импортирует шрифт fonts.google.com/fonts/Roboto.ttf
- картинка, ведущая на img.site.net/picture1.jpg
- фрейм, подгружаемый с adriver.ru/frame
- скрипт с adm.site.net/admin.js
Пусть во фрейме (с adriver.ru) подключается:
- стиль с adriver.ru/style.css
- картинка с img.adriver.ru/img/01.png
- скрипт с adriver.ru/libs.js
- скрипт с api.adriver.ru/v1/ad.js
Значения Sender / Recipient при загрузке ресурсов парсером DOM
| Загружаемый ресурс | Значение Sender | Значение Recipient |
|---|---|---|
| site.net/css/common.css | site.net | site.net |
| fonts.google.com/fonts/Roboto.css | site.net | fonts.google.com |
| fonts.google.com/fonts/Roboto.ttf | fonts.google.com | fonts.google.com |
| img.site.net/picture1.jpg | site.net | img.site.net |
| adriver.ru/frame | site.net | adriver.ru |
| adm.site.net/admin.js | site.net | adm.site.net |
| adriver.ru/style.css | adriver.ru | adriver.ru |
| img.adriver.ru/img/01.png | adriver.ru | img.adriver.ru |
| adriver.ru/libs.js | adriver.ru | adriver.ru |
| api.adriver.ru/v1/ad.js | adriver.ru | api.adriver.ru |
Теперь рассмотрим значения Sender / Recipient при загрузке контента скриптами в процессе выполнения ajax-запросов.
Значения Sender / Recipient при загрузке контента скриптами
| Выполняемый скрипт | Куда идет запрос | Sender | Recipient |
|---|---|---|---|
| adm.site.net/admin.js | site.net/api/ | adm.site.net | site.net |
| adriver.ru/libs.js | adriver.ru/api/ | adriver.ru | adriver.ru |
| api.adriver.ru/v1/ad.js | api.2gis.ru/… | api.adriver.ru | api.2gis.ru |
2.6 Подробнее о значениях таблиц определения Context
Рассмотрим подробнее, какие варианты открытия страниц (вкладок в браузере) у нас имеются, и какое значение Context будет при этом получаться.
P1 – пользователь на предыдущей странице щелкнул ссылку или нажал кнопку submit на форме. Стандартный обработчик браузера событий для ссылки/формы перенаправил пользователя на эту страницу. Нормальная ситуация. Безопасный переход между страницами домена или разных доменов.
При переходе на site.net с другого домена google.com, Context будет равен предыдущему домену (google.com). И пользователь на новом домене site.net окажется неавторизованный (даже если открыта соседняя вкладка этого сайта, где пользователь авторизован).
Повторный самостоятельный переход пользователя (без содействия скриптов) по ссылке на этот же сайт приведет снова к ситуации P1, но Context будет уже равен домену site.net, т.к. по правилу Context = Referrer.
Это сделано для защиты от CSRF-атак.
P5 – пользователь на предыдущей странице нажал на ссылку, созданную/измененную скриптом, загруженным с домена предыдущей страницы; или пользователь на предыдущей странице нажал на кнопку submit формы, созданную/измененную скриптом (изменение тега FORM, включая её поля INPUT). Стандартный обработчик браузера событий для ссылки/формы перенаправил пользователя на эту страницу.
P9 – тоже, что и P5, только скрипт был внешним, или в цепочке вызовов присутствует функция из внешнего скрипта (защита от правки сторонним скриптом функций скрипта сайта).
PD – пользователь открыл страницу по прямому адресу. Безопасное открытие.
Пользователь должен открыть страницу путем ввода URL в адресной строке. Либо открыть сайт из закладок браузера.
Открытие ссылки с ярлыка рабочего стола, из другой программы, любая иная ситуация, когда ОС направляет браузеру команду открыть ссылку, должны рассматриваться, как случай PG (открытие ссылки по инициативе браузера). Даже если пользователь нажмет F5, чтобы перезагрузить страницу, это должно рассматриваться как случай PG. Только если пользователь встанет в адресную строку и нажмет Enter будет рассматриваться браузером как PD.
Это сделано для защиты CSRF-атак от других программ.
Переход по ссылке из другой программы приведет пользователя на атакуемый сайт с не валидным токеном и пустым Context, который будет сохраняться, даже если пользователь нажмет F5 (обновить страницу). Авторизоваться не получиться до тех пор, пользователь не откроет какую-нибудь ссылку на страницы сайта (ситуация P1).
Таким образом, если злоумышленник из другой программы решит подсунуть авторизованному пользователю ссылку на страницу сайта site.net, выполняющую какую либо команду, у него не выйдет это сделать так просто. Необходимо будет заставить пользователя нажать на этой странице ещё одну ссылку, потом заставить пользователя аутентифицироваться там, и только потом… Потом, уже пользователь будет, скорее всего, на другой странице сайта site.net.
P2 – на предыдущей странице для ссылки или формы, изначально размещенных на странице, собственный скрипт предыдущей страницы сгенерировал событие click/submit. В цепочке вызовов не было функций, принадлежащих внешнем скриптам. Браузер перенаправил пользователя на эту страницу.
Если новая страница принадлежит этому же домену, Context наследуется от предыдущей страницы. Если новая страница принадлежит чужому домену, Context будет пустым.
P6 – тоже самое, что P2, только ссылка/форма была создана/изменена собственным скриптом.
PA – тоже самое, что P2, только ссылка/форма была создана/изменена внешним скриптом.
PE – скрипт на предыдущей странице спровоцировал открытие этой страницы командой window.location.href или window.open(…).
Если страница site.net скриптом перенаправляет пользователя на страницу этого же домена, поле Context будет наследоваться от порождающей страницы. В этом случае Context = site.net.
Если была открыта страница ya.ru, а скрипт перевел нас на maps.ya.ru, то Context новой страницы будет уже пустым. При последующих действиях пользователя Context будет практически всегда оставаться пустым, что затруднит авторизацию пользователя на сайте.
Протокол подразумевает, что открытие одним сайтом другого – небезопасная операция. Это защищает пользователя от несанкционированного трекинга этими сайтами и от CSRF-атак.
P3 – аналогично P2, только событие click/submit было провоцировано внешним скриптом. Context становится пустым (вместо него посылается случайная последовательность байт), что защищает от трекинга пользователя сторонними сайта (баннерные сети).
P7 – аналогично P6, только ссылка/форма была создана/изменена внешним скриптом.
PB – аналогично PA, только ссылка/форма была создана/изменена внешним скриптом.
PF – аналогично PE, только провоцирующий скрипт был внешним.
P4 – страницу перезагрузил браузер в результате обработки тега <META>. Тег изначально был на странице. Легальный редирект. Context будет сохраняться от первоначальной страницы. Как в случае с PE.
P8 — страницу перезагрузил браузер в результате обработки тега <META>. Но тег был создан/изменен собственным скриптом. Это допустимо, но Context будет сохраняться от первоначальной страницы. Как в случае с PE. Выманить легальный токен пользователя таким образом не удастся.
PC – аналогично P8, только скрипт внешний. Открываемый сайт получит в качестве Context случайное число.
PG – открытие браузером ссылки по команде из ОС. Это может быть, переход вами по ссылке из другой программы, открытие ярлыка на рабочем столе. Это может быть команда, поступившая от другой программы, без вашего ведома. В этом случае источник является не доверенным, и поле Context будет оставаться пустым при любых манипуляциях пользователя.
Это сделано для защиты CSRF-атак от других программ.
Если браузер сам открывает сохраненные ранее вкладки, то Context страницы устанавливается равным значению этой страницы на момент закрытия браузера.
Кроме того, под эту категорию попадают все ситуации, когда браузер перенаправляется сервером на другую страницу (своего домена или чужого) в результате обработки HTTP-заголовка Header. Если перенаправление идет на свою же страницу, то значение Context наследуется. Если перенаправление идет на чужую – обнуляется.
Это сделано для защиты от трекинг-атак веб-серверов.
Кстати, такое правило может вызвать проблемы при текущей реализации кросс-доменной авторизации. Если после прохождения авторизации SSO-сервер редиректом сам перенаправит пользователя обратно на целевой сайт – последний там окажется анонимным.
Чтобы пользователь «не потерял» исходную авторизацию на целевом сайте, необходимо передавать аутентификационную информацию меж-серверным запросом. Алгоритм может быть таким:
- пользователь создает и активирует постоянный ключ для целевого сайта;
- переходит с целевого сайта на SSO-сервер сам, нажимая соответствующую ссылку;
- активирует имеющийся постоянный ключ от SSO-сервера;
- SSO-сервер, получив ключ Changed-To, посылает меж-серверный запрос на целевой сайт;
- пользователь нажимает на странице авторизации кнопку-ссылку «Продолжить», которая возвращает его обратно на целевой сайт;
- чтобы выполнить правило P1, целевой сайт предлагает пользователю ещё раз нажать кнопку-ссылку, ведущую на него же (например, на стартовую страницу авторизованного участника).
- пользователь нажимает кнопку-ссылку, страница перезагружается, и пользователь на целевом сайте уже авторизован.
Описание алгоритма выглядит, на самом деле, сложнее, чем его реализация. А UI-имплементация может выглядеть так:
Повторный вход на целевой сайт уже не требует от пользователя SSO-авторизации. Достаточно только активировать постоянный ключ.
Теперь рассмотрим подробнее, какие варианты загрузки контента имеются у страниц, и какое значение Context будет получаться при запросах.
R1 – ресурс загружается браузером в результате разбора страницы (браузер встретил ресурсный тег). Значение Context при формировании запроса на получение ресурса берется из Context страницы содержащего ресурсный тег.
Например, если на сайте site.net есть фрейм adriver.ru, в котором грузится картинка с сайта img.disk.com, то при формировании HTTP-запроса к img.disk.com браузер в качестве Context возьмёт значение, которое было рассчитано для страницы site.net.
R4 – тоже, что и R1. Только ресурсный тег был создан/изменен собственным скриптом, в результате чего сработал DOM Parser браузера. Например, на странице site.net/index.html собственным скриптом site.net/require.js был вставлен другой собственный скрипт (тег <script src=…>) site.net/min.js, что вынудило браузер сформировать запрос на загрузку файла main.js. Поле Context в данном запросе будет установлено в значение, которое было рассчитано для страницы site.net.
R7 – тоже, что и R1. Но поскольку ресурсный тег был создан/изменен внешним скриптом, при запросе ресурса браузер сформирует токен на основе пустого Context и случайной 256-битной последовательности. Как результат внешний скрипт злоумышленника evil.com/drop.js, внедренный на страницу атакуемого домена site.net, пытающийся выполнить запрос на целевой сайт site.net от имени жертвы потерпит неудачу, т.к. сервер получит запрос со случайным токеном и не сможет идентифицировать отправителя запроса.
RA – загрузка контента осуществляется парсером в результате анализа другого контента. Например, файл стилей site.net/css/common.css, загружаемый для страницы site.net/index.html, импортирует файл стилей fonts.google.com/fonts/Roboto.css, что вынуждает браузер обратиться с запросом к fonts.google.com от имени Referrer = site.net/css/common.css. Значение Context будет в этом случае равно Referrer. Далее файл стилей Roboto.css импортирует шрифт Roboto.ttf, что вынуждает браузер обратиться с запросом к fonts.google.com/fonts/Roboto.ttf от имени Referrer = fonts.google.com/fonts/Roboto.css. Значение Context будет и в этом случае равно Referrer, но уже другое.
Предположим, гипотетически, что файл Roboto.css (внешний ресурс) импортирует не шрифт/стиль, а пытается провести CSRF-атаку такой инструкцией:
в надежде выполнить запрос на сайте site.net от имени авторизованного пользователя. Но проблема для злоумышленника в том, что site.net ожидает получить от пользователя токен:@import "https://site.net/api/payment?victim_params"

Тогда, как при таком CSRF-запросе, браузер создаст токен:

И запрос на сайт придет уже от имени неизвестного сайту анонима, не имеющему прав доступа на совершение указанных операций.
RB – контент загружается собственным скриптом сайта. В этом случае для расчета токена запроса используется Context, равный странице, содержащей скрипт. Для скрипта site.net/1.js со страницы site.net Context будет равен Context самой страницы.
Обратите внимание, что Context самой страницы не всегда равен доменному имени страницы и зависит от того, как она была первоначально открыта.Предположим, что сайт злоумышленника evil.com открывает страницу атакуемого сайта site.net, на которой скрипт site.net/util.js выполняет запрос с параметрами, переданными через URL страницы. Злоумышленник надеется, подсунув «свои параметры» через URL, заставить собственный скрипт site.net/util.js выполнить ajax-запрос на совершение важных действий от имени жертвы.
Предположим, что пользователь сам зашел на evil.com по прямой ссылке. Тогда Context для evil.com будет evil.com. Далее evil.com скриптом открывает site.net/api/payment?victim_params, надеясь провести атаку, но поле Context для site.net будет уже пустым (случай PE/PF). Скрипт site.net/utils.js, выполняя ajax-запрос, заставит браузер взять Context от страницы site.net. А оно у нас пустое. Но тогда site.net получит ajax-запрос с таким токеном:

тогда как для авторизованного пользователя ожидается:

site.net увидит неизвестный токен и не сможет идентифицировать пользователя. Защита сработала.
Кстати, говоря, из-за такой схемы провести кросс-доменную авторизацию через всплывающие окна будет нереально.Для реализации SSO в рамках протокола, необходимо открывать новую вкладку для страницы сервера авторизации. И при этом пользователь должен сам открыть такую вкладку. Наилучший вариант – открытие пользователем соответствующей ссылки с целевого сайта.
RC – контент загружается внешним скриптом сайта. В этом случае для расчета токена запроса используется Context равный полю Referrer запроса.
Не смотря на то, что RA, RB и RC защищают от CSRF-атак, они тем не менее приводят к генерации постоянных токенов. А это позволяет реализовать кросс-доменную аутентификацию и меж-доменную идентификацию пользователя (когда нужно определить, что несколько запросов на разные сервера поступило именно вот от этого пользователя). Что может быть реализовано для предоставления ему равных полномочий на группе связанных доменов.
Если страница сайта открылась автоматически с другого сайта, вы там не сможете авторизоваться, даже если будете самостоятельно перезагружать этот сайт. Поскольку Source будет наследоваться от пустого значения. Браузер должен сигнализировать пользователю о данном факте (Source = Random):

Это сделано для защиты от сайтов, которые принудительно открывают другие попап-окна (сами или их внешние скрипты), а на открывающихся сайтах будут делать перезагрузку или создадут поддельные кнопки «закрыть» на весь экран, ведущие на эти же сайты. Т.е. здесь предотвращается попытка отследить вас, в надежде получить валидный токен.
Любая попытка сайта сымитировать ваши действия внешним скриптом, либо попытка внешнего скрипта прямо или косвенно создать инициирующий тег и подсунуть его вам, приведет к пустому Source и добавке случайных байт в момент вычисления хэша токена.
Не поможет внешнему скрипту и трюк с созданием или изменением в DOM атакуемой страницы тега <script>. Поле Source будет оставаться пустым.
Но в тех же условиях внутренние скрипты приведут к запросам с Source, равному предыдущему его значению. И если исходная страница имела Source = Domain, всё будет хорошо. Пользователь останется авторизованным при таких запросах.
А вот со скриптами, загруженными со сторонних ресурсов (CDN), могут возникнуть, в некоторых случаях, проблемы. И это правильно, т.к. целостность кода CDN не гарантируется. Хотите не терять авторизацию пользователя – храните скрипты у себя и загружайте их со своего домена. Это что-то вроде аналога запрета использования ссылок http на https-страницах.
Опишем ситуацию, в которую может попасть разработчик. Ваш сценарий в результате действий пользователя выполняет перенаправление авторизованного пользователя на одну из страниц сайта (например, это делает форма), требующих, чтобы пользователь оставался авторизован. Ваш сценарий вызывает, например, $(form).submit() при помощи скрипта jQuery, загруженного с CDN. В этом случае браузер видит, что в стеке вызовов, инициировавших событие submit формы, присутствует функция из внешнего скрипта. Для предотвращения XSS/CSRF-атак браузер делает поле Source пустым, а к генерации токена добавляет случайные байты (случай P9). Как результат, пользователь на новой странице внезапно оказывается неавторизованным и не сможет выполнить операцию. Это может сбивать с толку разработчиков, привыкших использовать CDN.
2.7 Сценарии работы протокола
Приведем основные вероятные сценарии работы пользователя с сайтом, затрагивающие все возможные ситуации и этапы их выполнения (анонимный вход, «запомнить меня», «забыть меня», перейти на использование постоянного ключа, авторизация и выход, регистрация и двух-факторная аутентификация, экспорт/импорт ключа, замена ключа и т.п.)
| 1 Форум, Блог, Википедия | ||
|---|---|---|
| Пользователь | Браузер | Сервер сайта |
| 1.1 Впервые входит на данный сайт. | Генерирует случайный ключ. Посылает незащищенный токен от случайного ключа. | Считаем пользователя анонимом. Используем этот токен в качестве идентификатора сессии пользователя. |
| 1.2 Просматривает страницы. | Посылает защищенный токен от случайного ключа. | Выдает публичный контент. Проверяет младшие 128-бит бит токена. |
| 1.3 Пытается делать действия (добавление комментариев и т.п.) | Посылает защищенный токен от случайного ключа. | Говорит пользователю, что необходимо представиться системе. На данном этапе сайт уверен, что ключ – случайный. |
| 1.4 Говорит браузеру, чтобы сайт запомнил его. | Фиксирует текущий ключ. Посылает ключ Permanent. Токен как и ранее передается в защищенном виде. Посылает этот ключ до тех пор, пока не получит от сервера success. | Теперь сайт знает, что ключ фиксированный. Посылает CSI-Token-Action: success. Может применить технику запоминания пользователя на длительное время: либо сохраняет токен в базе, для будущего восстановления сессии с пользователем. Либо удерживает сессию в течении более длительного времени (сохраняем в файл). |
| 1.5 Выполняет действия (добавление постов, голосования и т.п.) | Посылает защищенный CSI-Token от фиксированного ключа. | Фиксирует действия от этого пользователя. |
| 1.6 Закрывает вкладку браузера. | Ничего. | Находится в ожидании поступления следующих запросов пользователя. |
| 1.7 Снова заходит на сайт. | Посылает защищенный фиксированный ключ. | Продолжает работать с пользователем. Данные сессии берутся из БД или временного файла по токену. |
| 1.8 Отменяет фиксацию ключа (забыть меня на этом сайте) | Посылает ключ Logout | Удаляет данные пользователя в БД, т.к. это был фиксированный ключ, и пользователь больше никогда его не сможет восстановить. Завершает сессию. Браузер больше никогда не пошлет такой токен. |
| 1.9 При первом обращении к сайту после Logout. | Генерирует случайный ключ. Посылает незащищенный токен от случайного ключа. | Для сайта это уже новый пользователь. Считаем пользователя анонимом. Используем токен в качестве идентификатора сессии пользователя. |
| 1.10 Просматривает страницы. | Посылает защищенный токен от случайного ключа. | Выдает публичный контент. Проверяет младшие 128-бит бит токена. |
| 1.11 Закрывает вкладку браузера. | Ничего. | Разрывает сессию после таймаута. |
| 1.12 Снова заходит на сайт. | Генерирует случайный ключ. Посылает незащищенный токен от случайного ключа. | Считаем пользователя анонимом. Используем этот токен в качестве идентификатора сессии пользователя. |
| 1.13 Создает постоянный ключ сайта. | Ничего. | |
| 1.14 Активация постоянного ключа. | Спрашивает пользователя: вы действительно хотите, чтобы сайт запомнил ваш ключ? Убедитесь, что этот сайт является тем, за кого себя выдает. Посылает Change-To. Только в это момент браузер передает токен незащищенным. Во все следующие разы браузер будет всегда при логине передавать защищенный токен. Но для этого сайт должен подтвердить смену токенов через CSI-Token-Action: success. |
Запоминает в БД новый токен пользователя. Меняет ID сессии. Продолжает ожидать запросы от нового токена. Отправляет CSI-Token-Action: success. |
| 1.15 Выполняет действия (добавление постов, голосования и т.п.) | Посылает защищенный Token от постоянного ключа | Фиксирует действия от этого пользователя. Проверяет младшие 128-бит токена. |
| 1.16 Делает «Выход». | Посылает ключ Logout | Разрывает сессию |
| 1.17 Снова заходит на сайт. | Генерирует случайный ключ. Посылает незащищенный токен от случайного ключа. | Считаем пользователя анонимом. Используем токен в качестве идентификатора сессии пользователя. |
| 1.18 Активация постоянного ключа. | Посылает Change-To. Токен уже защищенный, т.к. в прошлый раз сайт ответил нам CSI-Token-Action: success. | Подгружаем сохраненный данные пользователя из базы. Меняет ID сессии. Работаем с сохраненным токеном. Мы знаем, что токен на базе постоянного ключа. |
| 1.19 Закрывает вкладку браузера. | Ничего. Либо ключ Logout, если настроен «автовыход» при закрытии вкладки. | Разрывает сессию после таймаута, либо при получении ключа Logout. |
| 2 Интернет-магазин или сайт объявлений | ||
| Пользователь | Браузер | Сервер сайта |
| 2.1 Впервые входит на данный сайт. | Генерирует случайный ключ. Посылает незащищенный токен от случайного ключа. | Считаем пользователя анонимом. Используем этот токен в качестве идентификатора сессии пользователя. |
| 2.2 Просматривает страницы. | Посылает защищенный токен от случайного ключа. | Выдает публичный контент. Проверяет младшие 128-бит бит токена. |
| 2.3 Пытается делать действия (добавление объявлений, покупки и т.п.) | Посылает защищенный токен от случайного ключа. | Говорит пользователю, что необходимо представиться системе. На данном этапе сайт уверен, что ключ – случайный. |
| 2.4 Говорит браузеру, чтобы сайт запомнил его. | Фиксирует текущий ключ. Пре первом же запросе посылает защищенный CSI-Token с ключом Permanent. После получения success, перестает посылать этот ключ. | Теперь сайт знает, что ключ фиксированный. Может применить технику запоминания пользователя на длительное время: либо сохраняет токен в базе, для будущего восстановления сессии с пользователем. Либо удерживает сессию в течении более длительного времени (несколько суток). |
| 2.5 Выполняет действия (добавление объявлений, покупки и т.п.) | Посылает защищенный CSI-Token от фиксированного ключа. | Фиксирует действия от этого пользователя. Проверяет токен. |
| 2.6 Закрывает вкладку браузера. | Ничего. | Удерживает сессию. При длительной неактивности сохраняет данные сессии из оперативной памяти в файл или базу. |
| 2.7 Снова заходит на сайт. | Посылает защищенный фиксированный ключ. | Сессия продолжается. Работаем с пользователем, как ни в чём не бывало. |
| 2.8 Создает или импортирует постоянный ключ сайта. | Ничего. | |
| 2.9 Активация постоянного ключа. Здесь фактически происходит переход от использования фиксированного ключа к постоянному. | Посылает ключ Change-To. Токен передается незащищенным для вновь созданного ключа и незарегистрированного на сервере токена. Токен передается защищенным для импортированного ключа. | 2.9.А. Токен на базе нового ключа. Если старый токен был сохранен в БД – просто меняем токен в БД. 2.9.В. Токен на базе импортируемого ключа. Если старый токен был сохранен в БД – удаляем его. Выполняя слияние двух профилей одного пользователя (об о чём можно спросить у него самого) – т.к. по факту у пользователя сохранено в БД два токена: от фиксированного ключа и от импортированного. Меняет ID сессии. Отправляет CSI-Token-Action: success. Продолжает ожидать запросы уже от нового токена. |
| 2.10 Выполняет действия (покупки, размещения объявлений, корзина, избранное, отзывы, сравнения) | Посылает защищенный Token от постоянного ключа | Фиксирует действия от этого пользователя. Проверяет младшие 128-бит токена. |
| 2.11 Закрывает вкладку браузера. | Ничего. Либо ключ Logout, если настроен «автовыход» при закрытии вкладки. | Разрывает сессию после таймаута, либо при получении ключа Logout. |
| 3 Сайты с обязательной предварительной регистрацией (соц. сети) | ||
| Пользователь | Браузер | Сервер сайта |
| 3.1 Входит на данный сайт. | Генерирует случайный ключ. Посылает незащищенный токен от случайного ключа. | Считаем пользователя анонимом. Используем этот токен в качестве идентификатора сессии пользователя. Пускаем только в публичные разделы. При попытке доступа к закрытому контенту переводим на форму авторизации. |
| 3.2 Создает постоянный ключ сайта | Ничего | |
| 3.3 Активация постоянного ключа. | Спрашивает пользователя: вы действительно хотите, чтобы сайт запомнил ваш ключ? Убедитесь, что этот сайт является тем, за кого себя выдает. Посылает Change-To. Токен передается в открытом виде. |
Запоминаем новый токен. Не спешим сохранять в БД, пока регистрация ещё не пройдена. Держим пользователя на форме «Регистрация», пока не будет проведено подтверждение обладания (телефоном, почтой). Отправляет CSI-Token-Action: registration |
| 3.4 Вводит свои контактные данные. | Отправляет ajax-запросы. Посылает Change-To. Старый токен на том же случайном ключе. Новый токен уже передается в защищенном виде. Как только получает success, переходит к использованию нового токена (постоянного ключа). |
Проверяет контактные данные. Если всё успешно, отправляет CSI-Token-Action: success. Иначе: CSI-Token-Action: registration. Если отправляется CSI-Token-Action: abort, то регистрация не успешна. Браузер должен вернуться к использованию случайного числа (отмена входа). И сообщить об этом пользователю. |
| 3.5 Переходит к закрытому разделу сайта | Посылает защищенный Token от постоянного ключа. | Предоставляет доступ, проверяя младшие 128-бит токена. |
| 3.6 Выполняет действия (покупки, размещения объявлений, корзина, избранное, отзывы, сравнения) | Посылает защищенный Token от постоянного ключа. | Фиксирует действия от этого пользователя. Проверяет младшие 128-бит токена. |
| 3.7 Закрывает вкладку браузера. | Ничего. Либо ключ Logout, если настроен «автовыход» при закрытии вкладки. | Разрывает сессию после таймаута, либо при получении ключа Logout. |
| 3.8 Входит на данный сайт. | Генерирует случайный ключ. Посылает незащищенный токен от случайного ключа. | Считаем пользователя анонимом. Используем этот токен в качестве идентификатора сессии пользователя. Пускаем только в публичные разделы. При попытке доступа к закрытому контенту сообщаем пользователю, что он аноним. |
| 3.9 Активация постоянного ключа. | Посылает Change-To. Оба токена передаются защищенным образом. | Подгружаем данные пользователя из БД по токену (старшие 128-бит). Теперь сайт знает, кто этот пользователь. |
| 3.10 Меняет постоянный ключ домена (на другой постоянный) | Спрашивает пользователя: вы действительно хотите, чтобы сайт запомнил ваш новый ключ? Убедитесь, что этот сайт является тем, за кого себя выдает. Посылает Change-To. Новый токен передается в открытом виде; старый – в защищенном |
Меняет в БД токен на новый. Подгружает данные профиля. Использует новый токен со следующих запросов. Отправляет CSI-Token-Action: success |
| 3.11 Выполняет действия (добавление постов, голосования и т.п.) | Посылает защищенный Token от нового ключа | Фиксирует действия от этого пользователя. Проверяет младшие 128-бит токена. |
| 3.12 Делает «Выход». | Посылает ключ Logout | Разрывает сессию |
| 3.13 Входит на данный сайт. | Генерирует случайный ключ. Посылает незащищенный токен от случайного ключа. | Считаем пользователя анонимом. Используем этот токен в качестве идентификатора сессии пользователя. Переводим на форму авторизации. |
| 3.14 Активация постоянного ключа | Посылает Change-To. Оба токена передаются защищенным образом. | Подгружаем данные пользователя из БД по токену (старшие 128-бит). |
| 3.15 Импортирует другой ключ для этого домена. Важно: импортируемый ключ должен быть зарегистрирован на сервере. |
Посылает ключ Logout Переходит на использование случайного ключа. | Разрывает сессию |
| 3.16 Активирует новый ключ | Посылает Change-To. Оба токена передаются в защищенном виде. Обратите внимание, что в качестве «предыдущего» используется уже случайный ключ (см. 3.15). |
Этот ключ должен быть известен БД. Экспорт ключа из браузера разрешается только для зарегистрированных токенов. Таким образом браузер уверен, что импортируемый ключ известен серверу и передает его защищенным. В противном случае – сервер не сможет опознать токен пользователя и не сможет его авторизовать. |
| 3.17 Выполняет действия (добавление постов, голосования и т.п.) | Посылает защищенный Token от нового ключа | Фиксирует действия от этого пользователя. Проверяет младшие 128-бит токена. |
| 3.18 Выходит | Посылает ключ Logout | Разрывает сессию |
| 4 Сайты с двух-факторной авторизацией (Сбербанк Онлайн) | ||
| Пользователь | Браузер | Сервер сайта |
| 4.1 Входит на данный сайт. | Генерирует случайный ключ. Посылает незащищенный токен от случайного ключа. | Считаем пользователя анонимом. Используем этот токен в качестве идентификатора сессии пользователя. Переводим на форму авторизации. |
| 4.2 Создает постоянный ключ сайта | Ничего | |
| 4.3 Активация постоянного ключа. | Спрашивает пользователя: вы действительно хотите, чтобы сайт запомнил ваш ключ? Убедитесь, что этот сайт является тем, за кого себя выдает. Посылает Change-To. Токен передается в открытом виде. |
Токен сайту не известен. Запоминает новый токен. Переводит на форму регистрации пользователя. Посылает CSI-Token-Action: registration. |
| 4.4 Вводит в форму свой телефон. Нажимает «продолжить» | Посылает Change-To в каждом запросе до получения success. Старый токен на том же случайном ключе. Новый токен уже передается в защищенном виде. |
Валидирует телефон пользователя. Посылает СМС с кодом. |
| 4.5 Вводит в поле код из СМС. | Делает ajax-запрос. В нем все тот же Change-To. Как только получает success, переходит к использованию нового токена (постоянного ключа). |
Проверяет СМС код. Сохраняет новый токен в базе (проверяя его). Посылает CSI-Token-Action: success Переводит пользователя на главную страницу личного кабинета. Если СМС код неверен, посылает CSI-Token-Action: registration. При ошибке валидации токена посылает CSI-Token-Action: abort. Браузер может сменить соль, но предложить пользователю повторить последнюю операцию. |
| 4.6 Работает с личным кабинетом. | Посылает защищенный Token от постоянного ключа | Предоставляет пользователю доступ в соответствии с его полномочиями. |
| 4.7 Делает «Выход» с сайта | Посылает ключ Logout | Завершает сессию |
| 4.8 Входит на данный сайт. | Генерирует случайный ключ. Посылает незащищенный токен от случайного ключа. | Считаем пользователя анонимом. Используем этот токен в качестве идентификатора сессии пользователя. Переводим на форму авторизации или стартовую страницу с кнопкой «Войти». |
| 4.9 Активация постоянного ключа. | Посылает Change-To. Токен передается в защищенном виде (т.к. известен уже сайту; мы проходили регистрацию ранее). |
Подгружаем данные пользователя из БД по токену (старшие 128-бит). Опознаем пользователя, посылаем СМС с кодом подтверждения на его телефон. На этом этапе мы уже знаем, что за пользователь. Требуем подтвердить свою личность. Отвечаем браузеру CSI-Token-Action: success |
| 4.10 Вводит в поле код из СМС. | Делает ajax-запрос. В заголовке запроса передается защищенный токен на постоянном ключе. | Валидирует токен. Проверяет код. Авторизует пользователя. Переводит пользователя на главную страницу личного кабинета. |
| 4.11 Работает с личным кабинетом. | Посылает защищенный Token от постоянного ключа. | Предоставляет пользователю доступ в соответствии с его полномочиями. |
| 4.12а Делает «Выход» с сайта | Посылает ключ Logout | Завершает сессию |
| 4.12б Или просто закрывает вкладку (небезопасно). | Браузер посылает ключ Logout, если настроен «автовыход» при закрытии вкладки. Либо ничего. | Завершает сессию, если пришел запрос с Logout. Либо по таймауту. |
| 5 Корпоративный сегмент: консоль управления ESXi | ||
| Пользователь | Браузер | Сервер сайта |
| 5.1 Входит на данный сайт. | Генерирует случайный ключ. Посылает незащищенный токен от случайного ключа. | Считает пользователя анонимом. Используем этот токен в качестве идентификатора сессии пользователя. Рисует стартовую страницу. |
| 5.2 Создает постоянный ключ сайта. | ||
| 5.3 Экспортирует ключ в файл (как есть, без защиты паролем). Браузер помечает, что это экспортированный ключ. | ||
| 5.4 Подключается по иным протоколам (SSH, RDP). Записывает ключ в конфигурацию системы (например секция .htaccess – см. пример ниже) | ||
| 5.5 Закрывает вкладку | Ничего | Разрывает сессию по таймауту |
| 5.6 Входит на данный сайт. | Генерирует случайный ключ. Посылает незащищенный токен от случайного ключа. | Считает пользователя анонимом. Используем этот токен в качестве идентификатора сессии пользователя. Рисует стартовую страницу. |
| 5.7 Активация постоянного ключа. | Посылает Change-To. Токен передается в защищенном виде (т.к. браузер уверен, что мы сообщили сайту наш ключ по другому каналу; мы ведь пометили ключ экспортируемым). |
Рассчитывает возможные значения токенов для своих страниц (см. далее). Определяет пользователя по токену (старшие 128-бит). Проверяем защищенные младшие 128-бит. Создаем сессию на этом токене. Отвечаем браузеру CSI-Token-Action: success. Либо отвечаем CSI-Token-Action: abort (если ключа нет в конфиге), а заодно 403 – Forbidden. Перенаправляем на стартовую страницу консоли. |
| 5.8 Работаем в консоли | Посылаем защищенный токен на постоянном ключе. | Предоставляет пользователю доступ в соответствии с его полномочиями. |
| 5.9 Закрывает вкладку | Браузер посылает ключ Logout, если настроен «автовыход» при закрытии вкладки. Либо ничего. | Завершает сессию, если пришел запрос с Logout. Либо по таймауту. |
| 6 Домашний сегмент: управление роутером | ||
| Пользователь | Браузер | Сервер сайта |
| 6.1 Входит на страницу устройства. | Генерирует случайный ключ. Посылает незащищенный токен от случайного ключа. | Считает пользователя анонимом. Используем этот токен в качестве идентификатора сессии пользователя.Выдает обычную страницу логина.Посылает браузеру CSI-Support: yes; |
| 6.2 Создает постоянный ключ. | ||
| 6.3 Активация постоянного ключа. | Спрашивает пользователя: вы действительно хотите, чтобы сайт запомнил ваш ключ? Убедитесь, что этот сайт является тем, за кого себя выдает. Посылает Change-To. Токен передается в открытом виде. |
Запоминает токен, но возвращает CSI-Token-Action: registration, т.к. пользователь не аутентифицирован. |
| 6.4 Вводит логин/пароль администратора «по умолчанию» | Передает логин/пароль POST-запросом с формы. В запросе все тот же Change-To, но только уже защищенный. | Проверяет логин/пароль. Сохраняет токен у себя. Применяет права к пользователю. Возвращает CSI-Token-Action: success |
| 6.5 Деактивирует стандартного пользователя администратора в консоли управления устройства в разделе «Безопасность» | Серия запросов с защищенным Token от постоянного ключа | Запрещает вход под логином/паролем. Сохраняет конфигурацию. |
| 6.6 Выходит | Посылает ключ Logout | Разрывает сессию |
| 6.7 Входит на страницу устройства. | Генерирует случайный ключ. Посылает незащищенный токен от случайного ключа. | Считает пользователя анонимом. Выводит сообщение «Доступ запрещен» |
| 6.8 Активация постоянного ключа. | Посылает Change-To.Токен передается в защищенном виде (т.к. уже известен устройству; мы проходили регистрацию ранее). | Идентифицирует пользователя по старшим 128-битам токена. Проверяет младшие биты. |
| 6.9 Выполняет привилегированные действия | Посылает защищенный Token от постоянного ключа | Выполняет действия в соответствии с полномочиями пользователя. |
| 6.10 Выходит | Посылает ключ Logout | Разрывает сессию |
Пример конфигурации доступа по токенам на базе файла .htaccess.
<Directory "/var/www/html"> AuthType CSI AuthName "Restricted Content" AuthTokensFile /etc/apache2/.csi_keys Require valid-user </Directory>
cat /etc/apache2/.csi_keys
# # Client Self Identification tokens file # # CSI-Domain-Key UserName Role 84bc3da1b3e33a18e8d5e1bdd7a18d7a166d77ac1b46a1ec38aa35ab7e628ab5 MelnikovIN admin 6d7fce9fee471194aa8b5b6e47267f0348a24b70a0b376535542b996af517398 BoshirovAM user
2.7.1 Алгоритм расчета сайтом возможных токенов пользователя по известному ключу
Если нам известен ключ K домена, мы легко можем рассчитать возможный «валидный» токен T пользователя, который придет с его запросами. Для этого необходимо, чтобы было выполнено условие: инициатор запросов, получатель запросов и контекст выполнения должен совпадать и быть равен домену. Иными словами, если у нас доменное имя vsphere.local, то:
Sender = Recipient = Context = vsphere.local
Отсюда исходный (сырой) токен рассчитывается, как:

При передаче, исходный токен будет дополнительно защищен. Младшие 128 бит токена будут хешированы солью, передаваемой в заголовке запроса CSI-Salt*. Таким образом, сайт увидит следующий токен:
Где Hi – старшие 128 бит, Lo – младшие 128 бит исходного токена.
Обычно, для закрытых консолей управления в корпоративной сети, веб-консоли не подгружают внешних скриптов, фреймов и т.п. Поэтому это условие будет в большинстве случае выполнено.
*Способ формирования соли см. в разделе «Процедура обмена солью между браузером и сервером».
2.8 Обработка токенов на сервере
Отправка токена серверу (без ключей)
| Статус токена Т в сессии сайта | Действия на стороне сервера сайта |
|---|---|
| Неизвестный | Это возможно только при первом входе браузера на сайт, либо при срабатывании защиты протокола и генерации браузером неверного токена на базе случайного числа. Считаем пользователя анонимом. Создаем новую сессию. Используем первые 128 бит Т в качестве идентификатора сессии пользователя. Генерируем соль для защиты токена. Возвращаем браузеру нашу соль в CSI-Salt. |
| Известный (первые 128 бит) | Подгружаем данные сессии. Если браузер послал свою соль CSI-Salt – соединяем со своей. Валидируем хеш по алгоритму. Сравниваем с полученными от клиента в CSI-Token. Если хеш неверный, возвращаем CSI-Token-Action: invalid. Можно вернуть код 400. Если всё хорошо – ответ 200. |
Отправка токена с ключом Permanent
Браузер фиксирует ключ клиента. Пользователь хочет, чтобы сайт запомнил клиента дольше, чем на одну сессию. Сохранять ли токен пользователя в своей базе – решение принимает сервер. Возвращаем клиенту CSI-Token-Action: success или CSI-Token-Action: abort.
Отправка токена с ключом Logout
Указывает на то, что текущий токен больше не будет использоваться браузером. Отправляется когда пользователь нажал «Выход» в браузере, или закрыл вкладку и настроена опция (автовыход при закрытии вкладки), или отказался от использования фиксированного ключа («забыть меня на этом сайте»).
Автологина, кстати, быть не должно. По соображениям безопасности.
Отправка токена с ключом Change-To
Назовем старый токен T, новый – Т'.
ВАЖНО: в качестве нового токена T' посылается реальное значение токена (в первый раз, для незарегистрированных), тогда как старый токен посылается хешированный (младшие 128 бит).
| Статус токена в базе сервера* | Действия на стороне сервера сайта | |
| T | T' | |
| нет | нет | Причина: легальная регистрация пользователя. Меняем идентификатор сессии пользователя на T' Отправляем клиенту CSI-Token-Action: success. Пользователь сделал постоянный ключ для сайта и выполнил «Вход». Сервер может сохранить такой токен на своей стороне. А перед этим предложить заполнить регистрационную форму (если это так необходимо). Сервер может послать CSI-Token-Action: registration, чтобы сказать браузеру, что регистрацию необходимо продолжить (пользователь должен выполнить ряд дополнительных действий по подтверждению личности). Тогда браузер будет слать токен с ключом Change-To (ключ уже будет защищенный) до тех пор, пока не будет получен success или abort. В первом случае, браузер считает, что регистрация нового токена завершена. В последнем – что стоит отменить смену токенов (работать на старом). |
| нет | есть | Причина: легальный Login. Подгружаем полный токен T' из базы. Подгружаем профиль пользователя. Меняем идентификатор сессии. Отправляем клиенту CSI-Token-Action: success. ВАЖНО. Если новый токен хотя бы раз передавался через Change-To в открытом виде, и сервер ответил CSI-Token-Action: success, в следующие разы браузер в ключе Change-To будет передавать уже защищенный токен. Защищенным токен передается также, если он сформирован на базе импортированного ключа. Экспорт постоянных ключей возможен только после их регистрации на сервере. Однако сервер при валидации токена должен учитывать, что он может быть передан в «сыром» виде. Это может произойти при первом входе пользователя с другого устройства, когда ключ домена создается на базе мастер-ключа. Т.к. браузер на устройстве «не в курсе», что ключ уже зарегистрирован. |
| есть | нет | Причина: легальная смена ключа по инициативе пользователя. Меняем старый токен T в базе на новый T'. Меняем идентификатор сессии. Отправляем клиенту CSI-Token-Action: success. |
| есть, ключ фикс |
есть | Причина: переход с временного ключа на постоянный Возможная ситуация, когда пользователь переходит от использования фиксированного ключа к постоянному, а последний формируется на базе мастер-ключа. При этом пользователь на другом устройстве уже делал постоянный ключ для этого сайта на базе того же мастер-ключа и зарегистрировался там под ним. В данном случае придется сделать слияние двух существующих учетных записей пользователя (с его согласия). Учетную запись от фиксированного токена – удалить. Меняем идентификатор сессии. Отправляем клиенту CSI-Token-Action: success |
| есть, ключ не фикс. |
есть | Ошибочная ситуация. Попытка заменить существующий в БД токен на другой существующий не разрывая сессии. Должна быть отвергнута. Отправляем CSI-Token-Action: abort. Не меняем сессию. Коллизии 256-битных токенов маловероятны в случае использования честной SHA-2. Возможно нарушение работы хеширующей функции (искусственное ослабление) на стороне браузера или недостаточно хороший генератор случайных чисел. Следующие вероятные причины возможны только по причине нарушения протокола браузером:
Если оба токена известны сайту, значит это постоянные или фиксированные ключи. В таких ситуациях браузер делает в начале Logout для старого ключа. А затем Login для нового. Никак иначе. |
*Имеется в виду сохранен ли в базе данный токен, а не в сессии.
2.9 Меж-доменная идентификация
Как уже говорилось ранее, сайты могут взаимодействовать с другими сайтами-партнерами или своими под-доменами, чтобы предоставлять пользователю некую часть функционала. Самый распространенный пример, когда на сайте site.ru часть ресурсов грузится с поддоменов img.site.ru, часть download.site.ru, а ещё часть с других.
В этом случае сайту site.ru необходимо иметь возможность сообщить своим доменам-партнерам, от кого именно приходят к ним запросы. Ведь, если вы авторизовались на site.ru, это не делает вас автоматически авторизованным на других сайтах, включая под-домены сайта. Они будут видеть от вас иные токены.
Давайте посмотрим, как вычисляется токен и чем нам это может помочь.
Пусть пользователь авторизовался на сайте site.ru постоянным ключом и имеет там токен:

Все запросы, идущие со страницы сайта site.ru на домен site.ru и вызванные:
- ресурсными тегами страницы (статическими или собственными динамическими)
- собственными скриптами
Теперь пусть клиент скачивает файл ограниченного доступа со страницы site.ru, но ссылка ведет на download.site.ru. В этом случае поддомен получит следующий токен (правила R1, R4):

Ровно тот же самый токен download.site.ru получит, если на него будет выполнен ajax-запрос со страницы сайта site.ru (правила RB, RC).
Другой домен domain получит уже токен:

Но, обратите внимание, если условия выполнения запросов не меняются, то для данной связки доменов A, B, C браузер всегда будет генерировать постоянный токен. Значит мы можем провести меж-доменную идентификацию. Например, так.
С сайта site.ru делаем ajax-запросы на поддомены. Передаем идентификатор ID != T1 пользователя, выданный ему сайтом site.ru. Поддомены получат для этого же пользователя ID токены Tx. Каждый из поддоменов сделает связку своего токена с ID пользователя. Информацией о пользователе ID и его правах поддомены уже поделятся межсерверными запросами.
Связка делается однократно. В последствии, поддомены будут ориентироваться на собственные токены, т.к. они для постоянного ключа site.ru тоже будут постоянными.
3 Рекомендации по безопасности
Примечание
Данный раздел не является частью протокола. Здесь идут общие рассуждения о возможных рисках и методах защиты.
3.1 Защита ключевой информации от НСД
Предлагаемый протокол авторизации защищает пользователя от клавиатурных шпионов, крадущих ваши пароли, поскольку в предлагаемой схеме пароли не используются вообще.
А вот способы защиты ключей от компрометации необходимо рассмотреть подробнее.
Ключи могут быть скомпрометированы путем:
- копирования ключевой информации вредоносной программой (удаленный доступ)
- непосредственного доступа к файлу с ключевой информацией «офлайн» (прямой доступ)
- в момент распространения между устройствами
Если допустить, что ключевая информация сохраняется на смарт-карте (мы рассматривали данный вариант в разделе «Мобильность учетных записей»), то задача защиты ключевой информации перекладывается на плечи чипа. Правда появляется уязвимость к клавиатурным шпионам, которые могут перехватить вводимый PIN-код; ну и неудобность в использовании.
Помимо смарт-карт для защиты от прямого доступа к ключевой информации можно использовать симметричное шифрование. Но вопрос: какой ключ взять для шифрования?
Если этот ключ генерировать на базе пароля пользователя, то во-первых, получаем уязвимость к подбору пароля «офлайн», во-вторых, собственно, от чего ушли, к тому и пришли: «опять какие-то пароли».
Более правильный вариант зашивать особым образом* такой ключ в сборку браузера (или одной из его специализированных библиотек). При каждом обновлении браузера меняется и ключ, и место его расположения в скомпилированном файле. Такой подход не даст 100% гарантии защиты, но серьезно усложнит задачу по расшифровке. Вначале злоумышленнику необходимо будет выяснить точную версию сборки, затем найти её, провести дизассемблирование, и выяснить как собирается ключ.
Также сами ключи доменов непосредственно должны храниться в отдельном файле, а не совместно с конфигурацией по их использованию (т.е. только ключи и ничего более). Тогда их расшифровка методом подбора ключа (из известных сборок) будет невозможна, ибо отличить правильно расшифрованный ключ от случайной последовательности байт – невозможно. Тогда попытки подобрать мастер-ключ без знания точной версии сборки браузера и прямого дизассемблирования его кода вообще станут невозможны.
Можно применить комбинированный вариант: шифрование ключом от браузера + шифрование паролем пользователя от учетной записи ОС (если это позволяет API ОС). Причем ключ всегда генерируется «на лету». Тогда офлайновый брутфорс станет ещё затратнее.
Кроме того, после смены пароля пользователя в ОС, ключ тоже изменится. И если не сделать предварительную расшифровку на старом ключе, то это защитит от ситуаций, когда администратор компьютера меняет вам пароль, чтобы получить доступ к вашей учетной записи и выполнять действия от вашего имени. Ситуации вида: уволился с работы.
Вы же предварительно сделаете резервную копию ключей (экспортируете ключи в файл). Если, конечно, уже не сделали этого ранее при распространении ключей на другие устройства.
*Например, 32-байтный ключ распределен случайным образом в 64К-секции исполнимого файла. И только исходный код знает как собрать из этих байт заветный ключ.
3.2 О паролях в качестве ключей доменов
В одной из первоначальных версий протокола ключ домена мог формироваться на базе пароля пользователя. Алгоритм был хитрым, исключавшим повторение ключей у разных доменов для одного и того же пароля.
Это позиционировалось как удобный способ мобильности учетных записей. Ввел один пароль и не переживаешь ни о чём. Но потом оказалось следующее:
- Если сайт знает свой токен, то сайт может восстановить «брутфорсом» пароль, который был положен в основу формирования ключа домена, формирующий этот токен. А если предположить, что этот пароль пользователь использовал ещё где-либо, то мы получим ключи доменов и от других сайтов пользователя.
Допустим (гипотетически), что вы используете сложный 8-ми символьный пароль, состоящий из символов латинского алфавита разного регистра, цифр и таких спец.символов: ~!@#$%^&. Общий алфавит составит: 26 + 26 + 10 + 8 = 70 символов. 8-символьный пароль на таком алфавите имеет ёмкость 708 вариантов.
Представим, что злоумышленник имеет специализированный кластер, способный вычислять наши токены из пароля со скоростью 1012 вариантов в секунду. Тогда для взлома ему потребуется 708 / 1012 = ~576 сек. Т.е. ваш пароль будет гарантировано подобран за ~10 минут. А в среднем такой системе будет достаточно потратить лишь 5 минут на подбор пароля от известного токена. 10-символьный пароль потребует уже в среднем 15 суток. Но повысив производительность системы в 10 раз, мы сократим это время до 1-2 суток.
А такая производительность теперь есть и легко доступна благодаря облачным сервисам, распределенным вычислениям и всего того наследия майнинговых фрем. - Такой пароль уязвим не только к брутфорсу, но и к клавиатурным шпионам.
- Если два незнакомых друг другу пользователя придумают для одного и того же популярного сайта одинаковый пароль, то они получат одинаковый токен. Т.е. пароли могут вызвать конфликт токенов (несмотря на длину хеша и всю мощь SHA-2).
- Ну и, наконец, создавая протокол, я хотел вообще уйти от паролей. А на самом деле лишь похитрее их спрятал.
3.3 Риски потери/компрометации ключей и их минимизация
А что если я потеряю мастер-ключ?
Такое может произойти, если вы поменяли пароль или переустановили ОС. Какие риски?
Ну вы не попадете на сайты, где были раньше. Потеряете историю покупок на интернет-магазинах, свои объявления на интернет-площадках, карму на форумах. Не беда.
Хотя, кто мешает сделать процедуру перерегистрации с новым токеном и подтверждением его через телефон, указанный в том же объявлении? Получается, что сайту необходимо делать форму перерегистрации токена (аналог «восстановления пароля»)? Где же обещанное отсутствие «всяких таких» форм?
На самом деле сайту, которому необходимо не просто идентифицировать посетителя, а ещё и знать кто это на самом деле, придется делать форму регистрации. Собственно, эта форма может использоваться для повторной регистрации. Вы указываете ровно те же данные, что и ранее (email, mobile). Подтверждаете, что обладаете этими данными (письмо, СМС). Система видит, что такая учётка уже есть, данные 100% ваши, но токен другой – перезаписывает токен.
Но всё-таки, лучше не терять мастер-ключ.
Как предотвратить потерю? Создавать резервную копию, защищать её паролем и хранить на отчуждаемых носителях. Так же, собственно, как это делается с ключами для bitcoin. В принципе, можно переводить мастер-ключи в печатный вид и сохранять на бумажке. Если на то пошло. А потом восстанавливать ручным вводом. Но это уже для совсем «параноиков», вроде меня.
А что если у меня угонят мастер-ключ?
Это уже серьезно. Хотя описываемые здесь рекомендации по хранению мастер-ключа (не входят в протокол) защищают их от прямого НСД, клавиатурных шпионов и троянов, тем не менее, риск компрометации мастер-ключа сохраняется. К сожалению, идеальной защиты не существует. Ключ может быть угнан прямо из памяти браузера через уязвимость движка javascript. Как пример. Или вы теряете мобильник…
Так какие риски угона мастер-ключа?
Существенные для получения сведений о вас и даже для совершения действий от вашего имени. Получение возможности злоумышленнику авторизовываться под вами и в режиме чтения получать доступ к закрытой информации. Тихо и незаметно. Или разом выкачать все ваши приватные видео из одноклассников. Вам неприятно. Любители котиков ликуют.
Здесь необходимо быстро перерегистрироваться с новым ключом на важных сайтах. И, если случилось страшное, регистрация вашего нового токена в БД поставщика услуг официальным способом, – единственный правильный вариант. Способов регистрации можно придумать множество: от бумажной фиксации в официальном письме, до заявки через службу техподдержки сайта с подтверждением личности приемлемыми способами. Но это только для серьезных сайтов, вроде онлайн-банка.
Способы минимизации рисков. Использование индивидуальных ключей для доменов (но это понижает мобильность учёток). Двухфакторная аутентификация по независимым каналам. Показ сайтом IP-адресов и устройств, откуда было подключение в последний раз, чтобы вы хотя бы вовремя заметили компрометацию.
4 Атаки на схему авторизации
4.1 Трекинг пользователя
Сайт, которому вы доверяете, может беззастенчиво сливать о вас информацию другим сайтам. В интернете существуют сайты-коллекторы, которые агрегируют такую информацию и продают её желающим. Яндекс-метрика, гугл-аналитика – редкий сайт обходится без них.
Чтобы два разных сайта могли определить, что работают с одним и тем же клиентом, применяются две техники:
- Выполнение одного сайта в контексте другого и взаимный обмен собственно сгенерированными идентификаторами пользователей (в качестве идентификатора может использоваться всё, что угодно из вашего профиля).
- Формирование отпечатка браузера по единому алгоритму (формирование уникального набора атрибутов браузера) и косвенная идентификация клиента по этому отпечатку.
В схеме 2 есть небольшой недостаток: идентифицируется не пользователь, а браузер. Но зачастую браузер == клиент.
Кажется, токен лучшим образом подходит к использованию в схеме № 2. Ведь если пользователь разрешил «запомнить» себя двум сайтам (действующим в паре), наш постоянный токен может выступить в роли такого «отпечатка», только уже не браузера, а самого пользователя. Проблема для сайтов здесь в том, что они получат разные токены.
Но ведь сайты могут попробовать применить ещё и схему № 1. Тогда получится следующее.
Сайт 1 получит от браузера код H1, а сайт 2, выполняемый в контексте сайта 1 – код H2. Кажется, теперь сайты могут сформировать пару (H1, H2) и даже передать это некому сайту-агрегатору.
Пусть есть ещё один сайт 3, который работает в паре с сайтом 2, пытаясь вас отследить. Сайт 3 получит от браузера токен H3, а сайт 2, выполняемый в контексте сайта 3 – токен H2' != H2 (см. как формируется токены). Как результат, объединение полученных данных невозможно, т.к. у них нет пересекающихся частей.
Но это не значит, что сайты не смогут использовать для слежки fingerprint браузера. Здесь утверждается только то, что схема генерации токенов сама по себе достаточно надежна и защищает от трекинга.
Вариант защиты: выходить из сайтов, с которыми вы закончили работу. Браузер может делать это автоматически при закрытии вкладки.
4.2 Атака вида XSS
XSS – тип атаки, заключающейся во внедрении в страницу атакуемого сайта victim.com вредоносного кода. Например, через партнерский скрипт или взломанный CDN популярного фреймворка.
Вредоносный код может использовать авторизацию пользователя на сайте для получения к нему авторизованного доступа или для кражи аутентификационных данных пользователя. Вредоносный код может быть вставлен в страницу через уязвимость в веб-сервере (банальный взлом), через партнерские сети (ненадежные источники), через уязвимость на компьютере пользователя (проскирующий троян).
Основная защита от такого рода атак для нашей схемы авторизации – это особые правила генерации поля Source при вычислении токенов.
Уязвимость: для хранимых XSS (когда скрипт в результате взлома сервера непосредственно вставлен на атакуемый сайт и грузится с него), защита не сработает. Поскольку браузер не сможет идентифицировать такой скрипт как «внешний». Эта же проблема возникнет при проксировании злоумышленником трафика клиент-сервер.
4.3 Атака вида СSRF
Жертва заходит на сайт evil.com, созданный злоумышленником. От её лица выполняется запрос (GET/POST/HEAD/PUT/DELETE) на сайт, где пользователь уже авторизован (например, на сервер платёжной системы). Сам запрос осуществляет некую вредоносную операцию (например, перевод денег на счёт злоумышленника). По недосмотру разработчиков, сайт не проверяет поля Referer и не запрашивает дополнительной проверочной информации от пользователя. Как результат, атака проходит успешно.
Предлагаемая схема авторизации на сайтах подавляет большинство сценариев атак CSRF, за счет алгоритма генерации токенов. Любой межсайтовый запрос приведет к получению атакуемым сайтом не валидного токена от пользователя. Как результат, в такой ситуации пользователь для атакуемого сайта будет неизвестным анонимном. Даже попытка выполнить безобидный GET-запрос с атакующего сайта на атакуемый (загрузка картинки) приведет к получению последним невалидного токена.
Это существенно должно упростить жизнь разработчикам сайтов.
4.4 Трекинг с использованием схемы SSO
Два сайта S1 и S2, которым пользователь доверяет и имеет для них ключи, решают применить технологию, аналогичную SSO, для трекинга пользователя. Но т.к. внедрить один сайт в другой нельзя (кто-то из них получит невалидный токен), открыть сайт партнера скриптом тоже нельзя (по этой же причине), то сайт S1 решает применить хитрый прием.
На одной из страниц он размещает полупрозрачный тег A, перекрывающий всё окно. Ссылка ведет на сайт S2, а в адресе передается идентификатор пользователя (от S1) и токен H1. Пользователь не видит ссылку. Нажимая на любую область сайта S1, он инициирует открытие новой вкладки сайта S2.
В данный момент S2 не получит валидный токен. Не поможет ему и самоперезагрузка при помощи тега
или скриптом.<meta http-equiv="refresh" content="0">
Зато S2 может сделать тег A на всю свою страницу в виде поддельной кнопки «Закрыть»:

Эта ссылка вначале перезагрузит сайт, затем закроет его. В момент перезагрузки браузер пошлет на сайт S2 уже валидный токен H2 (т.к. выполнились правило 2.4 P1: пользователь обе ссылки открыл сам лично).
Как результат S2 получит информацию о действиях своего пользователя на сайте S1, свяжет токен H1 со своим H2, и пошлет H2 межсерверным запросом на S1. В дальнейшем сайты S1 и S2 смогут обмениваться любой информацией о пользователе межсерверным обменом, т.к. теперь могут однозначно его взаимно идентифицировать раздельно друг от друга.
Особо уязвимы к этой атаке мобильные пользователи, т.к. пытаясь закрыть ненужную страницу могут случайно нажать на поддельную ссылку, занимающую весь мобильный экран.Способ защиты: автоматически разрывать сессию при закрытии вкладки. Тогда сайт S2 не смог бы получить валидный токен до тех пор, пока пользователь сам не авторизовался бы на нем. Правда это не защитит от ситуаций, когда пользователь сам открыл вкладки и авторизовался на S1 и S2. А уже потом сайты провели такую атаку.
4.5 Компрометация ключа для SSO
Пусть учетная запись пользователя на сервере аутентификации, поддерживающим SSO, компрометирована. Оценим возможные риски при нашей схеме аутентификации.
Токены для каждого сайта рассчитываются индивидуально на базе ключей доменов.
Компрометация одного ключа домена не ведет к автоматической компрометации всех остальных.Большинство сайтов, где вы уже авторизовывались ранее при помощи SSO, наверняка сохранят в своей базе ваш токен с вашим профилем с сервера SSO. В нашей схеме, сайт просто будет подтягивать токен из БД и опознавать вас. Т.е. на таких сайтах сервер SSO уже не нужен – он выполнил свою функцию на этапе регистрации.
Иными словами вы не теряете автоматически разом все свои доступы. Злоумышленник при этом будет идентифицироваться на этих же сайтах как другой человек.
Не поможет злоумышленнику и попытка провести заново кросс-доменную аутентификацию: сайт должен блокировать попытки создания новой учетной записи со старым Id-пользователя SSO и новым токеном сайта. Либо попытки перезаписи токена пользователя для существующего Id в процессе SSO должны блокироваться. Сам факт этого, должен вызвать обоснованные подозрения на стороне сайта.
Токен пользователя может быть легально изменен только одним способом (см. «Сценарии работы протокола»).
Риск. Если сайт, не сохраняет в своей базе ваш токен и профиль, а целиком полагается на механизм SSO, тогда злоумышленнику достаточно провести кросс-доменную аутентификацию, чтобы авторизоваться под вашем именем.
Минимизация рисков при компрометации. Как ни странно, но это – сохранение сайтами токенов и профилей пользователей на своей стороне. Попытка злоумышленником провести кросс-доменную аутентификацию может вызвать конфликт между старым Id-пользователя и новым его токеном. Сама ситуация, когда у пользователя поменялся токен любым способом, кроме установленного в протоколе, должна восприниматься подозрительно или вовсе отвергаться.
Максимальный риск: авторизация от вашего имени на других сайтах (где вы ещё не были). Доступ к данным вашего профиля. Совершение незаконных действий от вашего имени. А чтобы законный владелец не смог ничего вернуть, злоумышленник может поменять на сервере авторизации свой токен легальным способом. Этот риск, впрочем, совпадает с рисками, при использовании традиционных схем авторизации.
Способы защиты. Отказ от использования SSO (тем более, что предлагаемая схема и задумывалась как способ уйти от централизованных схем аутентификации). Использование нескольких SSO (не храните все яйца в одной корзине!).
Если SSO поддерживает двухфакторную аутентификацию с подтверждением личности по иным атрибутам (почта, телефон), то существует возможность восстановления контроля над учёткой сервера авторизации.
4.6 Компрометация токена при передаче
Понятно, что предложенный механизм хеширования токенов при передаче не дает 100% гарантии их защиты. Злоумышленник может перехватить трафик жертвы в момент передачи незащищенного токена (в момент первичной регистрации постоянного ключа), как пример. И потом использовать его.
Поэтому использование SSL приветствуется. Но не стоит воспринимать HTTPS как панацею. Это протокол также вскрывается, как и HTTP. Только чуть сложнее.
Правда столь редкая передача открытого токена, а также использование индивидуального токена для каждого домена снижает риск эксплуатации уязвимости. Тем не менее.
Еще одна опасность – перехват и повторное использование токена в рамках текущей сессии пользователя. Как я говорил ранее, в идеале токен должен хешироваться новой солью при каждом запросе клиента. Однако это убьёт возможность параллельной обработки запросов на сервере и сделает невозможной отправку параллельных запросов от клиента. Вычисление и проверка хэшей вообще-то дорогостоящая операция, снижающая производительность.
Кроме того, токен, передаваемый в заголовке, не должен быть доступен из Javascript никогда. Аналогично Cookie с флагом HttpOnly. Даже при получении ajax-запросов скриптами.Способ эксплуатации: перехват запроса пользователя, извлечение текущего значения токена, отправка иной операции с тем же токеном (как от имени того же пользователя). Правда и классическая система на базе сессионного cookie тоже уязвима к данному типу атаки.
Способ защиты: подтверждение значимых операций по иным каналам связи, например, через СМС или почту; предварительная регистрация токена по другим каналам связи (бумажный сертификат, как пример).
4.7 Взлом сайта и компрометация токенов
Взломы сайтов происходят постоянно. Ломают даже крупные и хорошо защищенные сайты. Путей взлома много: от банальной инъекции, до инсайдерского «слива». Поэтому компрометация вашего токена на каком-либо сайте – событие весьма вероятное.
Но предлагаемый протокол, как раз-таки, делает событие взлома сайта наименее болезненным для вас.
Компрометация токена не ведет к компрометации ключа домена, на базе которого он был вычислен. Также это событие не ведет к компрометации других ваших токенов. А раз так, то доступы к другим сайтам остаются неприступными.Особенно это приятно, когда к большинству сайтов ключи сделаны при помощи мастер-ключа: его восстановить реверс-инжинирингом невозможно.
Но при этом использовать ключ домена, чей токен был скомпрометировать, уже, по понятным причинам, нельзя. Придется менять ключ.
Ключ для домена, где произошла официальная утечка, можно сделать либо на базе случайного числа, либо на базе мастер-ключа, с добавлением номера версии:

Заключение
Несколько моих знакомых, которым я показал статью, задавали мне по сути один и тот же вопрос: «А в чем здесь главная фишка?»
Если смотреть с высока
И действительно, поверхностный обзор протокола оставляет о нем впечатление (особенно с точки зрения конечного пользователя), как об ещё одном (очередном?) парольном менеджере, встроенном в браузер.
Ну, если сравнивать с парольными менеджерами, то всё-таки разница есть. Не уверен, что существует единый менеджер, реализованный в виде плагина для всех браузеров, работающий на всех платформах и умеющий синхронизировать ваши пароли между устройствами. Да ещё и бесплатный и открытый (чтобы из исходников собрать, в случае чего). Да и не факт, что разработчик такого менеджера не решит сделать «тихий слив» ваших учёток под благим предлогом «онлайн-синхронизации».
Серверы кросс-доменной авторизации тоже решение «так себе».Те же яйца Тот же парольный менеджер, только сбоку «онлайн». Тут вы доверяете владельцу сервера, а не разработчику менеджера. Но сервер могут взломать (и не важно Google это, или Facebook – утечки происходят рано или поздно у всех). Сервер может быть недоступен (вдруг его DDOS-ят или там просто тех.работы – ЕСИА в пример) или заблокирован каким-либо органом. Да и вообще, такие серверы под маской SSO любят собирать о вас слишком много информации, и нередко становятся целью хакеров со всего мира. Вам это нужно?
К тому же, мне, например, не прельщает перспектива регистрироваться в хомячковых соц.сетях только затем, чтобы авторизоваться на очередной интернет-барахолке и разместить там объявление купи-продай. Тем более, что регистрация в таких соц.сетях, становится всё строже и строже. Раньше требовался лишь подтвержденный email, потом телефон. Сейчас в наглую требуют реальную фотографию. Не удивлюсь, если скоро от нас будут требовать сдать отпечатки пальцев и кровь на анализ. Вам точно это нужно?
Я хочу интернет-независимости. А вы? SSO – не делает на свободными.
Наконец, есть же во многих браузерах встроенная фишка «запомнить пароль». Правда эта фишка исчезает при первой же переустановке ОС. Да и с мобильностью тут неважно. Даже между браузерами в пределах одного устройства. Фактически проблема с хранением паролей и их синхронизацией отдана на откуп самому пользователю. Крутись как можешь, чувак.
Некоторые хитрые браузеры предлагают войти куда-то там в облако и хранить «безопасно» пароли там. Но мы уже знаем, чем пахнет такое «безопасное облако». К тому же ставят вас в зависимоть от конкретного браузера, что уже не хорошо.
Так всё-таки, неужели в предлагаемом протоколе нет ни какой особой фишки?
Ну, если сравнивать с парольными менеджерами, то всё-таки разница есть. Не уверен, что существует единый менеджер, реализованный в виде плагина для всех браузеров, работающий на всех платформах и умеющий синхронизировать ваши пароли между устройствами. Да ещё и бесплатный и открытый (чтобы из исходников собрать, в случае чего). Да и не факт, что разработчик такого менеджера не решит сделать «тихий слив» ваших учёток под благим предлогом «онлайн-синхронизации».
Серверы кросс-доменной авторизации тоже решение «так себе».
К тому же, мне, например, не прельщает перспектива регистрироваться в хомячковых соц.сетях только затем, чтобы авторизоваться на очередной интернет-барахолке и разместить там объявление купи-продай. Тем более, что регистрация в таких соц.сетях, становится всё строже и строже. Раньше требовался лишь подтвержденный email, потом телефон. Сейчас в наглую требуют реальную фотографию. Не удивлюсь, если скоро от нас будут требовать сдать отпечатки пальцев и кровь на анализ. Вам точно это нужно?
Я хочу интернет-независимости. А вы? SSO – не делает на свободными.
Наконец, есть же во многих браузерах встроенная фишка «запомнить пароль». Правда эта фишка исчезает при первой же переустановке ОС. Да и с мобильностью тут неважно. Даже между браузерами в пределах одного устройства. Фактически проблема с хранением паролей и их синхронизацией отдана на откуп самому пользователю. Крутись как можешь, чувак.
Некоторые хитрые браузеры предлагают войти куда-то там в облако и хранить «безопасно» пароли там. Но мы уже знаем, чем пахнет такое «безопасное облако». К тому же ставят вас в зависимоть от конкретного браузера, что уже не хорошо.
Так всё-таки, неужели в предлагаемом протоколе нет ни какой особой фишки?
О вот нет главной фишки! Увы. Но есть ряд деталей, делающих протокол выгоднее традиционной схемы «логин/пароль».
1. Вы, наверное, замечали на многих сайтах этот надоедливый popup
«Наш сайт сохраняет cookie! Наденьте каску и будьте бдительны, ведь большой брат следит за вами! Нажмите «Да», ибо выбора у вас всё равно нет».Это ещё один popup к куче других таких же назойливых и очень нужных. А всё это благодаря европейскому GDPR (аналог нашего закона ПДн).
Так вот. В нашей схеме, cookie для целей идентификации больше не нужны! От слова «совсем». Пользовать сам решает позволить ли сайту идентифицировать его, и когда и как долго это делать. Минус один назойливый попап, +1 в карму протокола.
2. Разработчику не нужно больше делать формы авторизации и восстановления пароля. Нет необходимости реализовывать непростые алгоритмы SSO и осваивать непростые библиотеки: OAuth, SAML, Kerberos и т.п., проходить процедуру регистрации своего сайта, менять ключи авторизации, следить за их безопасность; а если что-то пошло в друг не так с SSO, в срочном порядке разбираться: «что пошло не так, и почему». Да ещё и сервер авторизации может заблокировать ваш сайт по неизвестным причинам. Пойди разберись. Вчера всё работало, а сегодня… А тут достаточно просто прочитать токен из заголовка и проверить, нет ли такого в нашей базе. Просто = надежно.
просто говоришь...
На самом деле автор тут лукавит. Протокол не такой уж простой. Особенно для разработчиков браузеров и разрабочиков сайтов, которым нужны кросс-доменная и меж-доменная идентификация пользователя. И отсутствие форм регистрации я тоже обещал. Знаю. Но увы.
Но для всяких интернет-магазинов, интернет-барахолок, функция «запомнить пользователя» реализуется крайне легко.
Но для всяких интернет-магазинов, интернет-барахолок, функция «запомнить пользователя» реализуется крайне легко.
3. Пользователю нет необходимости заводить и помнить кучу паролей. Пользоваться услугами сторонних сайтов или неизвестно кем и как написанных программ. Можно не бояться доступа к компьютеру сторонних лиц, клавиатурных шпионов и троянов. Достаточно сделать резервную копию мастер-ключа, защитить её паролем и хранить где-нибудь на флешке. Как биткоин-кошелек. Чем не фича?
4. Если сайт взломают, вы ничем не рискуете. Ну перегенерируете заново ключ. Тогда как утекший к взломщикам сайта пароль может доставить много неприятностей.
5. Протокол создавался с учетом опыта известных сетевых атак. В его архитектуру уже встроена базовая защита от XSS, CSRF. Опять же веб-мастерам будет проще в разработке сайтов. А их пользователям — спокойнее.
6. Независимость протокола от конкретного поставщика услуг и его прихотей. Протокол делает вас свободным.
7. Наконец, предлагаемый протокол претендует на будущий открытый стандарт. А стандарт, в случае его принятия участниками, накладывает обязательства реализовывать функционал согласно спецификации, а не городить колхоз из собственных решений по авторизации, изобретая в очередной раз форму логина, регистрации, восстановления пароля, логаута. И не накосячить с хэшированием паролей или SQL-инъекцией.
А самое главное, как и любой открытый стандарт, он может быть и должен быть проверен независимыми экспертами. Даже если автор изначальной версии протокола «накосячил» в деталях, интернет-сообщество может своевременно это выявить исправить. Ну или отправить мой протокол в утиль. Увы для меня, и «фух-пронесло» для всех остальных.
– Думаю, мне следует на этом остановиться
Э. Уайлс
PS
Вы можете ознакомиться с вариантом полноформатной статьи в оффлайновом формате. При верстке материала на Habr я мог допустить опечатки. Если у вас есть серьезные замечания, лучше сверяйтесь с оригиналом и оставляйте постатейные комментарии (рецензии) именно в этом файле. Свои правки высылайте мне на почту sergey201991[]гмайл. Я не осьминог, но постараюсь ответить. Многократное совпавшие / интересные замечания добавлю в эту статью. Вместе с ответами на них. Не исключен вариант отдельной статьи-комментариев.
Да, я знаю, что у протокола могут быть проблемы:
- нет возможности автозоваться под своей учёткой на чужом девайсе, если у тебя нет ключа под рукой, а нужно срочно; пароли тут удобнее
- не совсем понятен алгоритм использования пользователям; могут возникнут сложности с управлением ключами при авторизации на сложных сайтах, особенно SSO
- если вдруг мою идею и правда «заценят», веб-мастеры меня проклянут: какое-то время будут использоваться обе системы (а возможно и пожизненно)
- я мог упустить что-то важное
По поводу п. 1 — я уже всерьез раздумывал вернуться к идее генерации ключа домена на базе пароля, сделав защиту от брутфорса путем усложнения процесса генерации ключа: скажем, увеличив число раундов хэширования до 1000. Но проблема с возможной коллизией паролей у разных пользователей на одном сайте не дает мне покоя.
По поводу п. 2 — это лечится временем. К новым интерфейсам нужно привыкать. Сначала будет не понятно, потом будет просто. Дай человеку 80-х годов современный смартфон, он тоже бы не догадался как им управлять.
Огромное спасибо, если дочитали это до конца!

