Будущее наступило, технологии искусственного интеллекта и машинного обучения уже успешно используют ваши любимые магазины, транспортные компании и даже фермы, выращивающие индеек.

А если что-то существует, значит в интернете про это уже есть… открытый проект! Смотрите как Open Data Hub помогает масштабировать новые технологии и избегать трудностей при их внедрении.
При всех плюсах искусственного интеллекта (artificial Intelligence, AI) и машинного обучения (machine learning, ML) у организаций часто возникают трудности с масштабированием этих технологий. Основные проблемы при этом, как правило, следующие:
Оставленные без решения, эти проблемы негативно влияют на скорость, эффективность и продуктивность работы ценных специалистов по обработке и анализу данных. Это приводит к их фрустрации, разочарованию в работе, и в итоге ожидания бизнеса в отношении AI/ML идут прахом.
Ответственность за решение этих проблем возлагается на ИТ-специалистов, которые должны предоставить дата-аналитикам – правильно, нечто вроде облака. Если более развернуто, то нужна такая платформа, которая дает свободу выбора и имеет удобный, простой доступ. При этом она быстрая, легко перенастраивается, масштабируется по требованию и устойчива к отказам. Построение такой платформы на базе технологий с открытым кодом помогает не впасть в зависимость от вендора и сохранить долгосрочное стратегическое преимущество в плане контроля затрат.
Несколько лет назад что-то похожее происходило в разработке приложений и привело к появлению микросервисов, гибридных облачных сред, ИТ-автоматизации и agile-процессов. Чтобы совладать со всем этим, ИТ-специалисты стали использовать контейнеры, Kubernetes и открытые гибридные облака.
Теперь этот опыт применяется для ответа на вызовы Al. Поэтому ИТ-специалисты создают платформы, которые базируются на контейнерах, позволяют создавать AI/ML-сервисы в рамках agile-процессов, ускоряют инновации и строятся с прицелом на гибридное облако.
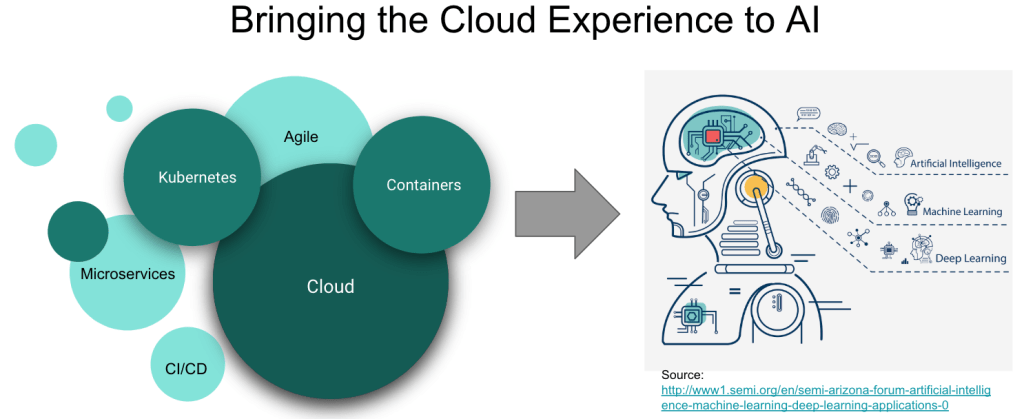
Построение такой платформы мы начнем с Red Hat OpenShift, нашей контейнерной Kubernetes-платформы для гибридного облака, у которой есть быстрорастущая экосистема программных и аппаратных ML-решений (NVIDIA, H2O.ai, Starburst, PerceptiLabs и т.д.). Некоторые из клиентов Red Hat, такие как BMW Group, ExxonMobil и другие, уже развернули контейнеризированные цепочки ML-инструментов и процессы DevOps на базе этой платформы и ее экосистемы, чтобы вывести свои ML-архитектуры на режим промышленной эксплуатации и ускорить работу дата-аналитиков.
Еще одна причина, по которой мы запустили проект Open Data Hub – продемонстрировать пример архитектуры на основе нескольких СПО-проектов и показать, как реализовать весь жизненный цикл ML-решения на базе платформы OpenShift.
Это проект с открытым кодом, который развивается в рамках соответствующего сообщества разработки и реализует полный цикл операций – от загрузки и преобразования начальных данных до формирования, обучения и сопровождения модели – при решении задач AI/ML с помощью контейнеров и Kubernetes на платформе OpenShift. Этот проект можно рассматривать как эталонную реализацию, пример того, как построить открытое решение класса «AI/ML как услуга» на основе OpenShift и соответствующих инструментов с открытым кодом, таких как Tensorflow, JupyterHub, Spark и других. Важно отметить, что Red Hat сама использует этот проект для предоставления своих услуг AI/ML. Кроме того, OpenShift интегрируется с ключевыми программными и аппаратными ML-решениями от NVIDIA, Seldon, Starbust и других вендоров, что облегчает построение и запуск собственных систем машинного обучения.

Проект Open Data Hub ориентирован на следующие категории пользователей и сценарии использования:
Проект Open Data Hub объединяет в себе целый ряд инструментов с открытым кодом для реализации полного цикла операций AI/ML. В качестве основного рабочего инструмента дата-аналитика здесь используется Jupyter Notebook. Этот инструментарий сегодня пользуется широкой популярностью среди специалистов по обработке и анализу данных, и Open Data Hub позволяет им легко создавать и управлять рабочими областями Jupyter Notebook, используя встроенный JupyterHub. Помимо создания и импорта notebooks Jupyter, проект Open Data Hub также содержит ряд уже готовых notebooks в виде библиотеки AI Library.
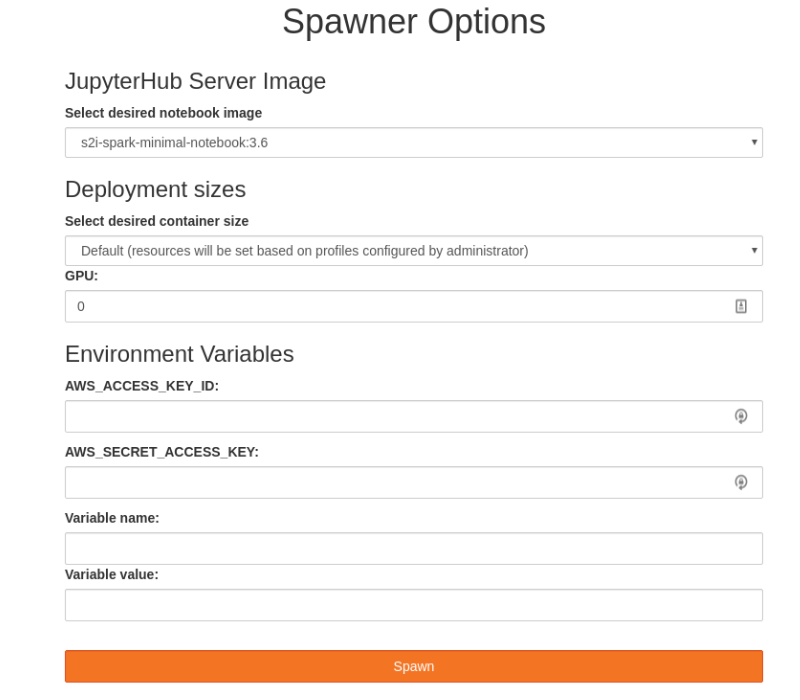
Эта библиотека представляет собой коллекцию open-source компонентов машинного обучения и решений для типовых сценариев, упрощающих быстрое прототипирование. JupyterHub интегрирован с RBAC-моделью доступа OpenShift, что позволяет использовать уже существующие аккаунты OpenShift и реализовать единый вход в систему. Кроме того, JupyterHub предлагает удобный пользовательский интерфейс под названием spawner, с помощью которого пользователь может легко настроить объем вычислительных ресурсов (процессорные ядра, память, GPU) для выбранного Jupyter Notebook.
После того, как дата-аналитик создаст и настроит ноутбук, все остальные заботы о нем берет на себя планировщик Kubernetes, который является частью OpenShift. Пользователям остается лишь выполнять свои эксперименты, сохранять и делиться результатами своей работы. Кроме того, продвинутые пользователи могут напрямую обращаться к CLI-оболочке OpenShift непосредственно из Jupyter notebooks, чтобы задействовать Kubernetes-примитивы, такие как Job, или функционал OpenShift, например Tekton или Knative. Либо для этого можно использовать удобный OpenShift’овский GUI, который называется «веб-консоль OpenShift».

Переходя к следующему этапу, Open Data Hub дает возможность управлять конвейерами данных (data pipelines). Для этого используется Ceph-объект, который предоставляется в виде S3-совместимого объектного хранилища данных. Apache Spark обеспечивает стриминг данных из внешних источников или встроенного хранилища Ceph S3, а также позволяет выполнять предварительные преобразования данных. Apache Kafka обеспечивает расширенное управление конвейерами данных (где можно осуществлять многократную загрузку, а также операции преобразования, анализа и сохранения данных).
Итак, дата-аналитик получил доступ к данным и построил модель. Теперь у него возникает желание поделиться полученными результатами с коллегами или разработчиками приложений, причем предоставить им свою модель на принципах услуги. Для этого нужен сервер вывода, и Open Data Hub имеет такой сервер, он называется Seldon и позволяет опубликовать модель в виде RESTful-сервиса.
В какой-то момент таких моделей на сервере Seldon становится несколько, и возникает потребность в мониторинге того, как они используются. Для этого Open Data Hub предлагает коллекцию соответствующих метрик и движок отчетов на основе широко распространенных инструментов мониторинга с отрытым кодом Prometheus и Grafana. В результате мы получаем обратную связь для мониторинга использования AI-моделей, в частности в продакшн-среде.

Таким образом, Open Data Hub обеспечивает облакоподобный подход на протяжении всего цикла операций AI/ML, начиная с доступа и подготовки данных и заканчивая обучением и промышленной эксплуатацией модели.
Теперь возникает вопрос, как все это организовать администратору OpenShift. И тут в дело вступает специальный Kubernetes-оператор для проектов Open Data Hub.

Этот оператор управляет установкой, настройкой и жизненным циклом проекта Open Data Hub, включая развертывание таких вышеупомянутых инструментов, как JupyterHub, Ceph, Spark, Kafka, Seldon, Prometheus и Grafana. Проект Open Data Hub можно найти в веб-консоли OpenShift, в разделе community-операторов. Таким образом, администратор OpenShift может задать, что соответствующие проекты OpenShift относятся к категории «проект Open Data Hub». Это делается один раз. После этого дата-аналитик через веб-консоль OpenShift заходит в свои проектные пространство и видит, что для его проектов установлен и доступен соответствующий Kubernetes-оператор. Затем он создает экземпляр проекта Open Data Hub одним щелчком мыши и сразу же получает доступ к вышеописанным инструментам. И все это можно настроить в режиме высокой доступности и отказоустойчивости.

Если вы хотите своими руками попробовать проект Open Data Hub, начните с инструкций по установке и вводного учебника. Технические подробности архитектуры Open Data Hub можно найти здесь, планы развития проекта – здесь. В будущем планируется реализовать дополнительная интеграцию с Kubeflow, решить ряд вопросов с регулированием данных и безопасностью, а также организовать интеграцию с системами на основе правил Drools и Optaplanner. Высказать свое мнение и стать участником проекта Open Data Hub можно на странице сообщества.
Резюмируем: серьезные проблемы с масштабированием мешают организациям в полной мере реализовать потенциал искусственного интеллекта и машинного обучения. Red Hat OpenShift давно и успешно применяется для решения схожих проблем в софтверной отрасли. Проект Open Data Hub, реализованный в рамках сообщества разработки в открытым кодом, предлагает эталонную архитектуру для организации полного цикла операций AI/ML на базе гибридного облака OpenShift. У нас есть четкий и продуманный план развития этого проекта, и мы серьезно настроены создать вокруг него активное и плодотворное сообщество разработки открытых AI-решений на платформе OpenShift.
А если что-то существует, значит в интернете про это уже есть… открытый проект! Смотрите как Open Data Hub помогает масштабировать новые технологии и избегать трудностей при их внедрении.
При всех плюсах искусственного интеллекта (artificial Intelligence, AI) и машинного обучения (machine learning, ML) у организаций часто возникают трудности с масштабированием этих технологий. Основные проблемы при этом, как правило, следующие:
- Обмен информацией и сотрудничество – обмениваться информацией без лишних усилий и сотрудничать в режиме быстрых итераций практически невозможно.
- Доступ к данным – для каждой задачи его нужно строить заново и вручную, что отнимает много времени.
- Доступ по требованию – нет возможности получить on-demand доступ к инструментам и платформе машинного обучения, а также к вычислительной инфраструктуре.
- Продакшн – модели остаются на стадии прототипа и не доводятся до промэксплуатации.
- Отслеживание и объяснение результатов работы AI – воспроизводимость, отслеживание и объяснение результатов AI/ML затруднительны.
Оставленные без решения, эти проблемы негативно влияют на скорость, эффективность и продуктивность работы ценных специалистов по обработке и анализу данных. Это приводит к их фрустрации, разочарованию в работе, и в итоге ожидания бизнеса в отношении AI/ML идут прахом.
Ответственность за решение этих проблем возлагается на ИТ-специалистов, которые должны предоставить дата-аналитикам – правильно, нечто вроде облака. Если более развернуто, то нужна такая платформа, которая дает свободу выбора и имеет удобный, простой доступ. При этом она быстрая, легко перенастраивается, масштабируется по требованию и устойчива к отказам. Построение такой платформы на базе технологий с открытым кодом помогает не впасть в зависимость от вендора и сохранить долгосрочное стратегическое преимущество в плане контроля затрат.
Несколько лет назад что-то похожее происходило в разработке приложений и привело к появлению микросервисов, гибридных облачных сред, ИТ-автоматизации и agile-процессов. Чтобы совладать со всем этим, ИТ-специалисты стали использовать контейнеры, Kubernetes и открытые гибридные облака.
Теперь этот опыт применяется для ответа на вызовы Al. Поэтому ИТ-специалисты создают платформы, которые базируются на контейнерах, позволяют создавать AI/ML-сервисы в рамках agile-процессов, ускоряют инновации и строятся с прицелом на гибридное облако.
Построение такой платформы мы начнем с Red Hat OpenShift, нашей контейнерной Kubernetes-платформы для гибридного облака, у которой есть быстрорастущая экосистема программных и аппаратных ML-решений (NVIDIA, H2O.ai, Starburst, PerceptiLabs и т.д.). Некоторые из клиентов Red Hat, такие как BMW Group, ExxonMobil и другие, уже развернули контейнеризированные цепочки ML-инструментов и процессы DevOps на базе этой платформы и ее экосистемы, чтобы вывести свои ML-архитектуры на режим промышленной эксплуатации и ускорить работу дата-аналитиков.
Еще одна причина, по которой мы запустили проект Open Data Hub – продемонстрировать пример архитектуры на основе нескольких СПО-проектов и показать, как реализовать весь жизненный цикл ML-решения на базе платформы OpenShift.
Проект Open Data Hub
Это проект с открытым кодом, который развивается в рамках соответствующего сообщества разработки и реализует полный цикл операций – от загрузки и преобразования начальных данных до формирования, обучения и сопровождения модели – при решении задач AI/ML с помощью контейнеров и Kubernetes на платформе OpenShift. Этот проект можно рассматривать как эталонную реализацию, пример того, как построить открытое решение класса «AI/ML как услуга» на основе OpenShift и соответствующих инструментов с открытым кодом, таких как Tensorflow, JupyterHub, Spark и других. Важно отметить, что Red Hat сама использует этот проект для предоставления своих услуг AI/ML. Кроме того, OpenShift интегрируется с ключевыми программными и аппаратными ML-решениями от NVIDIA, Seldon, Starbust и других вендоров, что облегчает построение и запуск собственных систем машинного обучения.
Проект Open Data Hub ориентирован на следующие категории пользователей и сценарии использования:
- Дата-аналитик, которому нужно решение для реализации ML-проектов, организованное по типу облака с функциями самообслуживания.
- Дата-аналитик, которому нужен максимальный выбор из всего разнообразия новейших инструментов и платформ AI/ML с открытым кодом.
- Дата-аналитик, которому нужен доступ к источникам данным при обучении моделей.
- Дата-аналитик, которому нужен доступ к вычислительным ресурсам (CPU, GPU, память).
- Дата аналитик, которому требуется возможность сотрудничать и обмениваться результатами работы с коллегами, получать обратную связь и вводить улучшения методом быстрых итераций.
- Дата-аналитик, который хочет взаимодействовать с разработчиками (и командами devops), чтобы его ML-модели и результаты работы шли в продакшн.
- Инженер по данным, которому требуется предоставить дата-аналитику доступ к разнообразным источникам данных с соблюдением норм и требований безопасности.
- Администратор/оператор ИТ-систем, которому требуется возможность без лишних усилий контролировать жизненный цикл (установка, настройка, обновление) компонентов и технологий с открытым кодом. А также нужны соответствующие инструменты управления и квотирования.
Проект Open Data Hub объединяет в себе целый ряд инструментов с открытым кодом для реализации полного цикла операций AI/ML. В качестве основного рабочего инструмента дата-аналитика здесь используется Jupyter Notebook. Этот инструментарий сегодня пользуется широкой популярностью среди специалистов по обработке и анализу данных, и Open Data Hub позволяет им легко создавать и управлять рабочими областями Jupyter Notebook, используя встроенный JupyterHub. Помимо создания и импорта notebooks Jupyter, проект Open Data Hub также содержит ряд уже готовых notebooks в виде библиотеки AI Library.
Эта библиотека представляет собой коллекцию open-source компонентов машинного обучения и решений для типовых сценариев, упрощающих быстрое прототипирование. JupyterHub интегрирован с RBAC-моделью доступа OpenShift, что позволяет использовать уже существующие аккаунты OpenShift и реализовать единый вход в систему. Кроме того, JupyterHub предлагает удобный пользовательский интерфейс под названием spawner, с помощью которого пользователь может легко настроить объем вычислительных ресурсов (процессорные ядра, память, GPU) для выбранного Jupyter Notebook.
После того, как дата-аналитик создаст и настроит ноутбук, все остальные заботы о нем берет на себя планировщик Kubernetes, который является частью OpenShift. Пользователям остается лишь выполнять свои эксперименты, сохранять и делиться результатами своей работы. Кроме того, продвинутые пользователи могут напрямую обращаться к CLI-оболочке OpenShift непосредственно из Jupyter notebooks, чтобы задействовать Kubernetes-примитивы, такие как Job, или функционал OpenShift, например Tekton или Knative. Либо для этого можно использовать удобный OpenShift’овский GUI, который называется «веб-консоль OpenShift».
Переходя к следующему этапу, Open Data Hub дает возможность управлять конвейерами данных (data pipelines). Для этого используется Ceph-объект, который предоставляется в виде S3-совместимого объектного хранилища данных. Apache Spark обеспечивает стриминг данных из внешних источников или встроенного хранилища Ceph S3, а также позволяет выполнять предварительные преобразования данных. Apache Kafka обеспечивает расширенное управление конвейерами данных (где можно осуществлять многократную загрузку, а также операции преобразования, анализа и сохранения данных).
Итак, дата-аналитик получил доступ к данным и построил модель. Теперь у него возникает желание поделиться полученными результатами с коллегами или разработчиками приложений, причем предоставить им свою модель на принципах услуги. Для этого нужен сервер вывода, и Open Data Hub имеет такой сервер, он называется Seldon и позволяет опубликовать модель в виде RESTful-сервиса.
В какой-то момент таких моделей на сервере Seldon становится несколько, и возникает потребность в мониторинге того, как они используются. Для этого Open Data Hub предлагает коллекцию соответствующих метрик и движок отчетов на основе широко распространенных инструментов мониторинга с отрытым кодом Prometheus и Grafana. В результате мы получаем обратную связь для мониторинга использования AI-моделей, в частности в продакшн-среде.
Таким образом, Open Data Hub обеспечивает облакоподобный подход на протяжении всего цикла операций AI/ML, начиная с доступа и подготовки данных и заканчивая обучением и промышленной эксплуатацией модели.
Собираем все воедино
Теперь возникает вопрос, как все это организовать администратору OpenShift. И тут в дело вступает специальный Kubernetes-оператор для проектов Open Data Hub.
Этот оператор управляет установкой, настройкой и жизненным циклом проекта Open Data Hub, включая развертывание таких вышеупомянутых инструментов, как JupyterHub, Ceph, Spark, Kafka, Seldon, Prometheus и Grafana. Проект Open Data Hub можно найти в веб-консоли OpenShift, в разделе community-операторов. Таким образом, администратор OpenShift может задать, что соответствующие проекты OpenShift относятся к категории «проект Open Data Hub». Это делается один раз. После этого дата-аналитик через веб-консоль OpenShift заходит в свои проектные пространство и видит, что для его проектов установлен и доступен соответствующий Kubernetes-оператор. Затем он создает экземпляр проекта Open Data Hub одним щелчком мыши и сразу же получает доступ к вышеописанным инструментам. И все это можно настроить в режиме высокой доступности и отказоустойчивости.
Если вы хотите своими руками попробовать проект Open Data Hub, начните с инструкций по установке и вводного учебника. Технические подробности архитектуры Open Data Hub можно найти здесь, планы развития проекта – здесь. В будущем планируется реализовать дополнительная интеграцию с Kubeflow, решить ряд вопросов с регулированием данных и безопасностью, а также организовать интеграцию с системами на основе правил Drools и Optaplanner. Высказать свое мнение и стать участником проекта Open Data Hub можно на странице сообщества.
Резюмируем: серьезные проблемы с масштабированием мешают организациям в полной мере реализовать потенциал искусственного интеллекта и машинного обучения. Red Hat OpenShift давно и успешно применяется для решения схожих проблем в софтверной отрасли. Проект Open Data Hub, реализованный в рамках сообщества разработки в открытым кодом, предлагает эталонную архитектуру для организации полного цикла операций AI/ML на базе гибридного облака OpenShift. У нас есть четкий и продуманный план развития этого проекта, и мы серьезно настроены создать вокруг него активное и плодотворное сообщество разработки открытых AI-решений на платформе OpenShift.

