Опубликованная месяц назад статья Алексис Бингесснер «Рендеринг текста вас ненавидит» очень мне близка.
В далёком 2017 году я разрабатывал интерактивный текстовый редактор в браузере. Неудовлетворённый существующими библиотеками на ContentEditable, я подумал: «Эй, да просто заново реализую выделение текста! Разве это сложно?» Я был молод. Наивен. Прикинул, что справлюсь за две недели. На самом деле попытка решить эту проблему отняла несколько лет моей жизни, в том числе год оплачиваемой работы с утра до вечера по разработке текстового редактора для новой ОС.
На работе мне посчастливилось многое узнать у наставников с огромным опытом в этой области. Я слышал много, очень много страшных историй. В том числе об инженере, который поддерживал приложение Windows с кастомной реализацией текстового поля — и хотел перейти с устаревшего API ввода текста на новую версию. Вот список интерфейсов для ввода текста в этой новой версии:

Всё правильно, 128 интерфейсов для ввода текста. Почти уверен, что есть ещё восемь (8!) различных типов блокировок для устранения проблем параллелизма, хотя честно не читал их документацию, поэтому не цитируйте меня по этому поводу. Тот инженер полтора года (полный рабочий день!) дорабатывал свой редактор, но в итоге потерпел неудачу и остался на старом API.
Ввод текста — это сложно.
Алексис местами упоминает про выделение текста, но её личный опыт больше связан с рендерингом. Как человек с той стороны, могу добавить несколько моментов именно про ввод.
Я уже освещал это в предыдущей статье, но можем быстро повторить здесь.

В этом примере, если нажать вверх, курсор уйдёт в начало строки, перед словом hello. Пока всё довольно разумно. Но если нажать вверх, а затем вниз, курсор сначала прыгнет перед hello, а затем встанет после some.
Это может показаться не очень логичным. Вы спросите, почему он прыгает вправо? Ну, при вертикальных перемещениях каждый курсор запоминает позицию x в пикселях, и она обновляется только при нажатии влево или вправо, а не вверх и вниз. То же самое поведение предотвращает перемещение курсоров влево при вертикальном перемещении через короткие строки.
Ладно, теперь мы знаем, что при выделении текста у нас два фрагмента состояния: байтовое смещение внутри строки и координата x в пикселях, упомянутая выше. Проблема решена? Ну, нет.
Рассмотрим две позиции курсора на очень длинной строке:

Поскольку loooooooooong — это одно слово, у двух позиций курсора в точности одинаковое байтовое смещение в строке. Между ними нет символа новой строки, так как строка мягко переносится. Нашим курсорам нужен дополнительный бит, который скажет, на какую строку перенестись. Большинство систем называют этот бит affinity (близость). Он же используется в смешанном двунаправленном тексте, про который мы скоро поговорим.
Допустим, я отправляю другу сообщение. Для выражения своих чувств хочу добавить забавный эмодзи. Ввожу в текстовой области поднятый вверх большой палец, букву

Ой, не хотел писать букву. Устанавливаю курсор после неё и нажимаю Backspace. Что произойдёт? Я видел несколько вариантов, в зависимости от редактора.

Все варианты плохие, поэтому вы можете предположить, что наверное есть какой-то четвёртый вариант. Есть! Многие редакторы, такие как TextEdit, даже не позволяет поставить курсор после буквы, так как модификатор тона кожи рассматривается как единое целое с предыдущим символом. Это имеет смысл в контексте эмодзи и даже хорошо работает в данном случае, но что если модификатор указан первым символом в строке?

Теперь модификатор изменяет символ новой строки. TextEdit не позволит поместить курсор в начале второй строки! Я лично считаю это решение «тоже плохим».
Возможно, вы также заметили, что большой палец вверх стал большим пальцем вниз. Это я сам сделал, чтобы отразить свои чувства по поводу всей ситуации.
Кстати, TextEdit специально делает курсор на первой строке очень глючным. Например, угадайте, что произойдёт, если я здесь нажму

Угу. Вы также можете подумать, что между цифрами есть пробелы. Их нет.
Алексис упоминает разделённые выделения в смешанном двунаправленном тексте, как в этом примере из TextEdit:

Это действительно имеет смысл, поскольку арабский язык в строках кодируется справа налево, так что выделение кажется разделённым, но по байтам представляет собой непрерывный диапазон.
Поэтому немного удивительно, что мы можем получить такое выделение:

Да, это визуально непрерывное, но разделённое по байтам выделение. Да, плохо. Так делают некоторые редакторы, если выделять текст клавишами со стрелками вместо мыши. Альтернатива — поменять местами клавиши влево/вправо внутри текста с направлением справа налево, что тоже плохо. Здесь нет хороших вариантов.
В качестве бонуса, попробуйте понять, что происходит здесь:
Господи… не хочу это комментировать.
Программное обеспечение, которое переводит нажатия клавиш во ввод, называется «метод ввода» (input method) или «редактор метода ввода» (input method editor). Для латинского алфавита это не очень интересное ПО, так как каждое нажатие клавиши напрямую сопоставляется с вставкой одного символа. Но во многих письменностях символы не помещаются на клавиатуру, поэтому приходится проявлять творческий подход. Например, в некоторых методах ввода для китайского языка пользователь вводит звуки — и получает список похожих по звучанию иероглифов:

Это поле иногда называют композиционной областью (composing region), и она часто появляется над подчёркнутым текстом. Иногда метод ввода должен её стилизовать. Например, метод ввода японского языка на Android использует цвет фона для создания области разделения предложений:

(Спасибо Shae за скриншот!)
Взаимодействуют ли все эти выделения и композиционные области с двунаправленным текстом? Давайте не будем об этом думать.
Методы ввода должны работать везде, даже внутри терминала:

Ничего не отправится в Vim, пока не выбран китайский иероглиф из списка. Вероятно, вы думаете: «Но как это работает в командном режиме Vim?» Не очень хорошо. Вот почему в интернете ввод текста и нажатия клавиш являются отдельными событиями. В консоли они смешиваются, вызывая проблемы.
Это всего лишь один пример из множества различных способов ввода текста. (Не забывайте о методах ввода без клавиатуры, таких как голосовой и рукописный ввод!) К счастью, операционная система предоставляет вам все эти методы. Но, к сожалению, ваше текстовое поле должно говорить на общем протоколе ввода текста, используемом всеми этими методами. Для Windows это те 128 интерфейсов, перечисленные в начале статьи. В других ОС интерфейсы попроще, но их всё равно сложно реализовать.
Вы также могли заметить, что метод ввода — отдельный процесс, так что в состояние текстового поля могут вносить изменения и метод ввода, и приложение. Это фактически параллельный протокол редактирования. Windows решает проблему с помощью восьми (8!) видов блокировки. Хотя удержание блокировки через границы процесса может показаться сомнительным, большинство других платформ для устранения проблем параллелизма пытаются использовать несовершенные эвристики. Или просто надеются, что состояние гонки не произойдёт. По моему опыту, молитва — не очень эффективный примитив параллелизма.
Джонатан Блоу в лекции о деградации софта упоминает текстовый редактор Кена Томпсона, который он написал за неделю. Большая часть кода в этой статье — случайно привнесённая сложность. Действительно ли Windows нужно 128 интерфейсов и 8 видов блокировок для ввода текста? Ни в коем случае. Являются ли ошибки в TextEdit результатом сложной модели редактирования? Да. Является ли россыпь багов в современных программах чем-то, о чём следует беспокоиться? По крайней мере, для меня это так.
Однако редактор Кена Томпсона был и намного, намного проще, чем то, что мы ожидаем от современных текстовых редакторов. Юникод поддерживает почти все живые языки в мире (их около 7000), и ещё много мёртвых. Там разные письменности, направления текста и методы ввода, каждый из которых накладывает сложные (и в некоторых случаях неразрешимые) ограничения на любой редактор. А ведь он должен ещё и поддерживать программы чтения с экрана.
Огромная сложность накапливается неизбежно, а в этой статье мы только слегка её тронули. Это настоящее чудо программирования, что можно просто шлёпнуть
В далёком 2017 году я разрабатывал интерактивный текстовый редактор в браузере. Неудовлетворённый существующими библиотеками на ContentEditable, я подумал: «Эй, да просто заново реализую выделение текста! Разве это сложно?» Я был молод. Наивен. Прикинул, что справлюсь за две недели. На самом деле попытка решить эту проблему отняла несколько лет моей жизни, в том числе год оплачиваемой работы с утра до вечера по разработке текстового редактора для новой ОС.
На работе мне посчастливилось многое узнать у наставников с огромным опытом в этой области. Я слышал много, очень много страшных историй. В том числе об инженере, который поддерживал приложение Windows с кастомной реализацией текстового поля — и хотел перейти с устаревшего API ввода текста на новую версию. Вот список интерфейсов для ввода текста в этой новой версии:
Всё правильно, 128 интерфейсов для ввода текста. Почти уверен, что есть ещё восемь (8!) различных типов блокировок для устранения проблем параллелизма, хотя честно не читал их документацию, поэтому не цитируйте меня по этому поводу. Тот инженер полтора года (полный рабочий день!) дорабатывал свой редактор, но в итоге потерпел неудачу и остался на старом API.
Ввод текста — это сложно.
Алексис местами упоминает про выделение текста, но её личный опыт больше связан с рендерингом. Как человек с той стороны, могу добавить несколько моментов именно про ввод.
Вертикальное перемещение курсора
Я уже освещал это в предыдущей статье, но можем быстро повторить здесь.
В этом примере, если нажать вверх, курсор уйдёт в начало строки, перед словом hello. Пока всё довольно разумно. Но если нажать вверх, а затем вниз, курсор сначала прыгнет перед hello, а затем встанет после some.
Это может показаться не очень логичным. Вы спросите, почему он прыгает вправо? Ну, при вертикальных перемещениях каждый курсор запоминает позицию x в пикселях, и она обновляется только при нажатии влево или вправо, а не вверх и вниз. То же самое поведение предотвращает перемещение курсоров влево при вертикальном перемещении через короткие строки.
Близость
Ладно, теперь мы знаем, что при выделении текста у нас два фрагмента состояния: байтовое смещение внутри строки и координата x в пикселях, упомянутая выше. Проблема решена? Ну, нет.
Рассмотрим две позиции курсора на очень длинной строке:
Поскольку loooooooooong — это одно слово, у двух позиций курсора в точности одинаковое байтовое смещение в строке. Между ними нет символа новой строки, так как строка мягко переносится. Нашим курсорам нужен дополнительный бит, который скажет, на какую строку перенестись. Большинство систем называют этот бит affinity (близость). Он же используется в смешанном двунаправленном тексте, про который мы скоро поговорим.
Модификаторы эмодзи
Допустим, я отправляю другу сообщение. Для выражения своих чувств хочу добавить забавный эмодзи. Ввожу в текстовой области поднятый вверх большой палец, букву
a и модификатор эмодзи для тона кожи. Это выглядит так:Ой, не хотел писать букву. Устанавливаю курсор после неё и нажимаю Backspace. Что произойдёт? Я видел несколько вариантов, в зависимости от редактора.
- Плохо №1 может показаться правильным. Но так работает текстовый редактор с поддержкой устаревшего рендеринга эмодзи, например, Sublime Text. Это плохо, потому что эмодзи светлого пальца кодируется как жёлтый палец, за которым сразу следует модификатор светлого тона кожи. Они не объединяются в один символ, как положено. Даже если я скопирую светлый палец из другого приложения, он всё равно отобразится неправильно, как здесь.
- Плохо №2 — это то, что Chrome 77 делает в адресной строке. Не на веб-страницах, а только в адресной строке. Это не проблема рендеринга, так как копипаст эмодзи с тоном кожи работает. Вместо этого Chrome удаляет букву, а заметив следующий за буквой модификатор, заодно удаляет и его. Упс.
- Плохо №3 соответствует спецификации Юникода, как положено сливать эмодзи. Но это довольно непонятно для пользователей, и, кстати, нужно сдвинуть курсор, чтобы он не застрял на полпути внутри эмодзи.
Все варианты плохие, поэтому вы можете предположить, что наверное есть какой-то четвёртый вариант. Есть! Многие редакторы, такие как TextEdit, даже не позволяет поставить курсор после буквы, так как модификатор тона кожи рассматривается как единое целое с предыдущим символом. Это имеет смысл в контексте эмодзи и даже хорошо работает в данном случае, но что если модификатор указан первым символом в строке?
Теперь модификатор изменяет символ новой строки. TextEdit не позволит поместить курсор в начале второй строки! Я лично считаю это решение «тоже плохим».
Возможно, вы также заметили, что большой палец вверх стал большим пальцем вниз. Это я сам сделал, чтобы отразить свои чувства по поводу всей ситуации.
Кстати, TextEdit специально делает курсор на первой строке очень глючным. Например, угадайте, что произойдёт, если я здесь нажму
4?Угу. Вы также можете подумать, что между цифрами есть пробелы. Их нет.
Двунаправленный текст
Алексис упоминает разделённые выделения в смешанном двунаправленном тексте, как в этом примере из TextEdit:
Это действительно имеет смысл, поскольку арабский язык в строках кодируется справа налево, так что выделение кажется разделённым, но по байтам представляет собой непрерывный диапазон.
Поэтому немного удивительно, что мы можем получить такое выделение:
Да, это визуально непрерывное, но разделённое по байтам выделение. Да, плохо. Так делают некоторые редакторы, если выделять текст клавишами со стрелками вместо мыши. Альтернатива — поменять местами клавиши влево/вправо внутри текста с направлением справа налево, что тоже плохо. Здесь нет хороших вариантов.
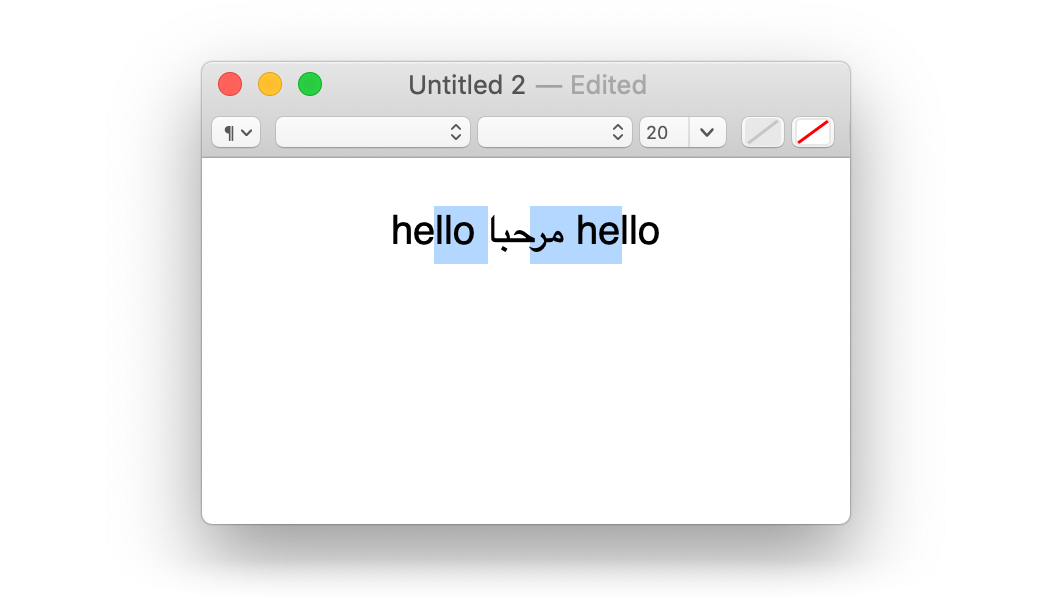
В качестве бонуса, попробуйте понять, что происходит здесь:
Господи… не хочу это комментировать.
Дело в методах ввода
Программное обеспечение, которое переводит нажатия клавиш во ввод, называется «метод ввода» (input method) или «редактор метода ввода» (input method editor). Для латинского алфавита это не очень интересное ПО, так как каждое нажатие клавиши напрямую сопоставляется с вставкой одного символа. Но во многих письменностях символы не помещаются на клавиатуру, поэтому приходится проявлять творческий подход. Например, в некоторых методах ввода для китайского языка пользователь вводит звуки — и получает список похожих по звучанию иероглифов:
Это поле иногда называют композиционной областью (composing region), и она часто появляется над подчёркнутым текстом. Иногда метод ввода должен её стилизовать. Например, метод ввода японского языка на Android использует цвет фона для создания области разделения предложений:
(Спасибо Shae за скриншот!)
Взаимодействуют ли все эти выделения и композиционные области с двунаправленным текстом? Давайте не будем об этом думать.
Методы ввода должны работать везде, даже внутри терминала:
Ничего не отправится в Vim, пока не выбран китайский иероглиф из списка. Вероятно, вы думаете: «Но как это работает в командном режиме Vim?» Не очень хорошо. Вот почему в интернете ввод текста и нажатия клавиш являются отдельными событиями. В консоли они смешиваются, вызывая проблемы.
Это всего лишь один пример из множества различных способов ввода текста. (Не забывайте о методах ввода без клавиатуры, таких как голосовой и рукописный ввод!) К счастью, операционная система предоставляет вам все эти методы. Но, к сожалению, ваше текстовое поле должно говорить на общем протоколе ввода текста, используемом всеми этими методами. Для Windows это те 128 интерфейсов, перечисленные в начале статьи. В других ОС интерфейсы попроще, но их всё равно сложно реализовать.
Вы также могли заметить, что метод ввода — отдельный процесс, так что в состояние текстового поля могут вносить изменения и метод ввода, и приложение. Это фактически параллельный протокол редактирования. Windows решает проблему с помощью восьми (8!) видов блокировки. Хотя удержание блокировки через границы процесса может показаться сомнительным, большинство других платформ для устранения проблем параллелизма пытаются использовать несовершенные эвристики. Или просто надеются, что состояние гонки не произойдёт. По моему опыту, молитва — не очень эффективный примитив параллелизма.
Почему всё так сложно??
Джонатан Блоу в лекции о деградации софта упоминает текстовый редактор Кена Томпсона, который он написал за неделю. Большая часть кода в этой статье — случайно привнесённая сложность. Действительно ли Windows нужно 128 интерфейсов и 8 видов блокировок для ввода текста? Ни в коем случае. Являются ли ошибки в TextEdit результатом сложной модели редактирования? Да. Является ли россыпь багов в современных программах чем-то, о чём следует беспокоиться? По крайней мере, для меня это так.
Однако редактор Кена Томпсона был и намного, намного проще, чем то, что мы ожидаем от современных текстовых редакторов. Юникод поддерживает почти все живые языки в мире (их около 7000), и ещё много мёртвых. Там разные письменности, направления текста и методы ввода, каждый из которых накладывает сложные (и в некоторых случаях неразрешимые) ограничения на любой редактор. А ведь он должен ещё и поддерживать программы чтения с экрана.
Огромная сложность накапливается неизбежно, а в этой статье мы только слегка её тронули. Это настоящее чудо программирования, что можно просто шлёпнуть
<textarea> на веб-странице — и мгновенно обеспечить ввод текста для каждого пользователя интернета по всему миру.
