
Перед выбором темы диплома я обратил внимание, что широко распространена ситуация, когда при компьютерных атаках человек рассматривается только с одной стороны — того, кого атакуют, в качестве уязвимости.
Во время атаки всем интересны только инструменты и действия нарушителей и только после того как всё случилось — кто стоял за атакой и какие цели они хотели достичь.
Прошли годы (уже почти шесть лет), но эта тема меня до сих пор не оставляет в покое.
При написании диплома стало понятно, что я сильно переоценил свои силы и проект такого масштаба одному человеку за полгода не создать. По крайней мере мне не удалось.
Недостаток опыта работы на реальных системах также оказал свое влияние и некоторые проектные решения были переосмыслены ещё при написании диплома, но до некоторых моментов я дошёл только спустя годы.
Эта статья про эскизный проект и те недочёты и вопросы, которые возникли в ходе проектирования.
Я был бы рад, если бы кого-то заинтересовала эта сторона компьютерных атак и он смог бы использовать мои скромные наработки.
И да, «хакер» в названии статьи используется только в одном, строго определенном значении — нарушитель информационной безопасности.
Тема диплома: проектирование системы динамического определения потенциальной цели нарушителя безопасность компьютерной сети.
Общая идея: когда мы каким-то образом (например, с помощью SIEM) фиксируем атаку, то на основе этих данных предполагаем что хочет нарушитель в итоге сделать.
Когда я писал диплом, то стало понятно, что некоторые моменты в дипломе можно и нужно улучшить.
Я уже рассказывал про часть своего диплома, а точнее об одной из проблем, с которой я столкнулся в процессе написания, здесь. Не самая лучшая моя статья, но кое-что полезное для себя я в комментариях почерпнул, спасибо всем комментаторам.
Про макеты
Первое, на что я бы хотел обратить внимание, в первую очередь дипломников — макетируйте.
Всё и постоянно. Станет понятно где и что пойдёт не так. А если и не понятно, то прокачаете свои навыки. Увы, я не программист или разработчик, да и с администрированием у меня не очень. Мне очень нравится что-нибудь придумывать новое или искать узкие места в идеях. Поэтому макетирование и проведение эксперимента почти целиком легло на моего дипломного руководителя, за что ей огромное спасибо.
Инфраструктуры своей у меня не было.
Вы можете с кем-нибудь объединиться и скинуться железом. Взять, например, несколько ноутбуков, роутер и на этой системе в миниатюре макетировать.
Также вы можете купить на сайтах бесплатных объявлений старое, не очень бодрое, но живое железо. Иногда продают за «1 000₽, но самовывоз».
Ближе к делу
С чего начать прогнозировать?
С того, чтобы понять что происходит в настоящем.
За это отвечала SIEM OSSIM. При этом разработчик заявлял, что может определять атаки и составлять цепочки атак CVE. За это я и зацепился — мне не нужно определять атаки самому и я могу сосредоточиться непосредственно на определении потенциальной цели. Как SIEM OSSIM определяет атаки и присваивает CVE меня не очень интересовало, если честно. Не так давно я попытался разобраться, но конкретики найти не смог.
Кроме того, для прогнозирования можно было использовать CAPEC. Впрочем, мне было намного интереснее использовать CVE/CVSS и CAPEC я не уделил достойное количество внимания.
Но перед этим всем займёмся любимым делом — классификацией нарушителей.
Классификация нарушителей
Эту тему я уже поднимал, но давайте пройдёмся ещё раз, только быстро.
SIEM собирает атаку в цепочку CVE. Из CVE/CVSS мы берём вектор AccessComplexity («Сложность доступа»). Использовалась вторая версия CVSS, поэтому там три градации, а не две, как сейчас.
| Уровень навыков нарушителей безопасности | Сложность доступа |
|---|---|
| Низкий | Low |
| Средний | Medium |
| Высокий | High |
Как-то не впечатляюще, не так ли? Дальше будет интереснее. Тем более, что в прошлой статье этого не было.
Информационная безопасность — это процесс обеспечения доступности, целостности и конфиденциальности информации.
Это одно из общепринятых определений.
А что если мы классифицируем нарушителей по нарушению этих свойств информации?
Так получилась следующая классификация:
- Разведчик
- Разрушитель
- Захватчик

«Разведчик» (Scout) – его основной целью является раскрытие информации о системе, либо получение информации (данных, файлов и т.д.) из неё.
«Разрушитель» (Destroyer) – его основной целью является нарушение работы системы или её компонентов, вплоть до выхода из строя.
«Захватчик» (Invader) – его основной целью является получения контроля над системой или её компонентами.
Такое распределение «ролей» мне казалось пять лет назад хорошей идеей. Впрочем, мне многое тогда казалось хорошей идеей.
Чтобы классифицировать нарушителей по этим классам возьмём из CVE/CVSS ConfImpact («Влияние на конфиденциальность»), IntegImpact («Влияние на доступность»), AvailImpact («Влияние на целостность»).
В векторе влияние может принимать следующие значения: нет влияния на ресурс (N), частичное влияние на ресурс (P), полной контроль над ресурсом (C).
| Класс | Влияние на конфиденциальность | Влияние на доступность | Влияние на целостность |
|---|---|---|---|
| Разведчик | N | P/C | N |
| Разрушитель | P/C | N/P | N |
| Захватчик | N/P/C | N/P/C | P/C |
Ну и для завершения мы указываем, что у классов разное влияние на систему: меньше всего у «Разведчика» и больше всего у «Захватчика».
Таким образом получив из SIEM цепочку атак мы можем классифицировать нарушителя. И уже на этом мы можем делать какие-то выводы о целях нарушителя.
Проходя цепочку атак нарушитель может только увеличивать свои навыки и класс, но не снижать их. Низкий → Средний → Высокий и Разведчик → Разрушитель → Захватчик.
Классификация используется в прогнозировании цели нарушителя опосредовано.
Но классифицируя нарушителей можно предполагать к чему они стремятся.
Наверное, можно сказать, что классификация наиболее хорошо работающее место в дипломе.
Все те нюансы, которые меня смущают в общем-то описаны в предыдущей статье.
Архитектура
Давайте сначала обратимся к архитектуре решения.
Основными компонентами подсистемы система динамического определения потенциальной цели нарушителя безопасности являются три модуля, названные по именам трех норн, мифических скандинавских волшебниц, определяющих судьбу человека – Урд, Верданди и Скульд.
Рассказывая про «скандинавских волшебниц» на защите диплома я был уверен, что это отличная идея и поможет как-то «разрядить обстановку». Нет. Кажется, эффект получился обратный. Но почувствовал я это уже после того как всё озвучил. Наверное, такой подход подойдёт, если вы спикер где-нибудь на phdays, но не перед госкомиссией.
Тем не менее дать именно такие имена подсистемам помогло мне понять как же система должна работать.

Система функционально делится на три основные подсистемы:
- База знаний (Урд — Прошлое);
- Система сбора информации (Верданди — Настоящее);
- Система прогнозирования цели (Скульд — Будущее).
Центральное место уделяется СБД — серверной базе данных, входящей в базу знаний.
Предполагалось, что будет некая глобальная база данных, в которую пользователи будут записывать и получать графы атак. Выглядеть они должны как-то так.
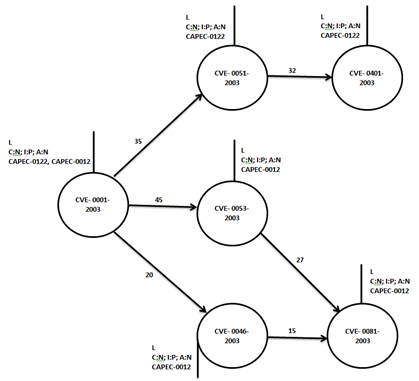
Так как хранить графы в базе данных и работать с ними как с графами? Всё просто — есть графовые базы данных.
Но именно в этот момент я понял, что своими силами я не справляюсь и диплом конкретно так съехал в сторону концепта, нежели реально разработанной и работающей системы.
Мне нужно было найти в БД SIEM где хранятся атаки, а потом написать парсер, который бы перенес эти сведения в графовую базу данных.
Как наполняется база: SIEM детектирует атаку, даёт мне CVE, я добавляю в базу новую вершину или, если такая вершина уже есть, увеличиваю количество переходов между вершинами на одну единицу. Если атака продолжается — я добавляю вершину/переход.
У данного подхода есть преимущества, такие как:
- самонаполняемость, т.е. не нужно делать дополнительных действия для создания новых графов атак, поскольку это делают сами злоумышленники;
- малая избыточность, т.е. в графе находятся только те графы атак, которыми действительно пользуются злоумышленники.
Главным недостатком подхода является то, что если злоумышленник использует атаку, ранее неиспользуемую, то предсказать его действия невозможно.
Данный метод можно улучшить, добавляя в базу смоделированные другими способами графы атак, назначая для переходов значение «0».
Ещё у данного метода с использованием графовой БД есть две чисто практические сложности:
- Писать в базу данных.
- Читать из базы данных.
Проблема с записью заключается в детектировании атак. В какой момент нужно писать атаку в базу?
Когда атака завершена? Атака может быть долгой. В какой момент понять, что она завершена? Вдруг нарушитель не обладает нужными навыками и бросил развивать атаку? Да и если атака завершена, то инфраструктуры, чтобы отправить данные об атаке, уже может и не быть.
В процессе? Писать каждый переход по CVE? Ну, не самый плохой выбор, но, мне кажется, что и тут будут подводные камни.
Проблема с чтением заключается в предполагаемых объёмах деревьев, которые нужно забирать с сервера. Кажется, с точки зрения ресурсов и времени выполнения эта операция будет катастрофой.
Можно попробовать не делать выборку для каждого обнаружения перехода по графу атак (об этом чуть позже), а синхронизировать всю базу целиком. Но я даже примерно не могу представить какой объём будет занимать база в тот момент, когда начнёт набираться реальными данными.
Помимо серверной БД я использовал локальную — ту, которая будет собирать статистику по атакам на конкретную систему.
Ещё можно сказать о том, что в базу нельзя внести офлайновые атаки. Фишинг, да и вообще вся социнженерия пройдёт мимо нас. Определить как далеко продвинулся по kill chain нарушитель мы сможем только в тот момент, когда он уже будет пытаться нас kill.
Magic
Теперь осталось перейти к самом главному и интересному. К прогнозированию.
Алгоритм исторического прогнозирования
Теперь мне кажется, что более адекватным названием было бы «статистический алгоритм». Но тогда я расценил, что лучше в дипломе не использовать слово «статистика».
Алгоритм, который был придуман, наверное, самое ценное в моём дипломе (за запись в псевдокоде опять-таки спасибо моему дипломному руководителю).
1. Получить CVE_ID, HOST_ID из события безопасности
2. Dgraph=DirectedGraph(CVE_ID)
if DirectedGraph==0 return
3. Set_Edges:=DirectedGraph.getOutEdges(CVE_ID, HOST_ID, DirectedGraph.getRoot())
4. Set_Edges:=MAX_EXPLOIT_FREQUENCY(SET_EDGES)
If (SET_EDGES)==null return
if (SET_EDGES.SIZE()>1)
SET_EDGES:=MIN_ACCESS.COMPLEXITY(SET_EDGES)
if(SET_EDGES.SIZE()>1)
SET_EDGES:=MIN_IMPACT_GOAL(SET_EDGES)
for each EDGES ∈ SET_EDGES
edge.Exploit_Probability==((edge.AttackFrequency)/(1+∑edge.AttackFrequency))
5. Перейти на шаг 3.
По прошествии лет мне самому не так просто прочесть этот алгоритм, поэтому давайте немного попроще.
Мы из события безопасности, которое нам даёт SIEM, получаем наименование хоста, CVE-id и из базы данных выбираем поддерево, которое начинается с уязвимости, CVE-id которой мы получили.
Среди ближайших уязвимостей мы выбираем такую, у которой бы частота использования была бы максимальной.
Если есть несколько уязвимостей с одинаковой частотой, то мы берём ту, у которой меньше сложность доступа.
Если есть несколько уязвимостей с одинаковой сложностью доступа, то берётся уязвимость с меньшим влиянием ImpactGoal (из классификации).
Если и в этом случае будет несколько уязвимостей, то эти уязвимости признаются равновероятными и в определении потенциальной цели используются несколько путей.
Для каждой уязвимости высчитывается вероятность использования уязвимости: частоту использования пути до уязвимости, которую мы считаем вероятной, мы делим на сумму частот использования всех исходящих граней из данного узла.
После выполнения этих шагов мы снова просматриваем окружающие нас уязвимости, т.е. обходим дерево до конца.
Визуализация алгоритма исторического прогнозирования
У нас есть некая уже сформированная база атак.
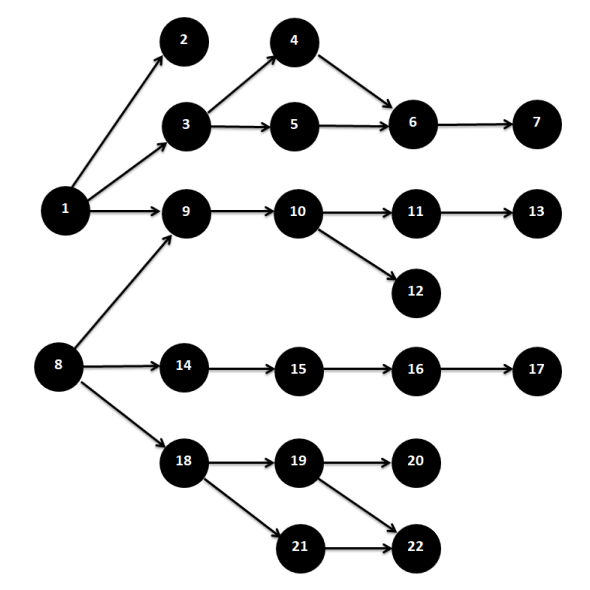
Получаем от SIEM атаку и первую CVE.
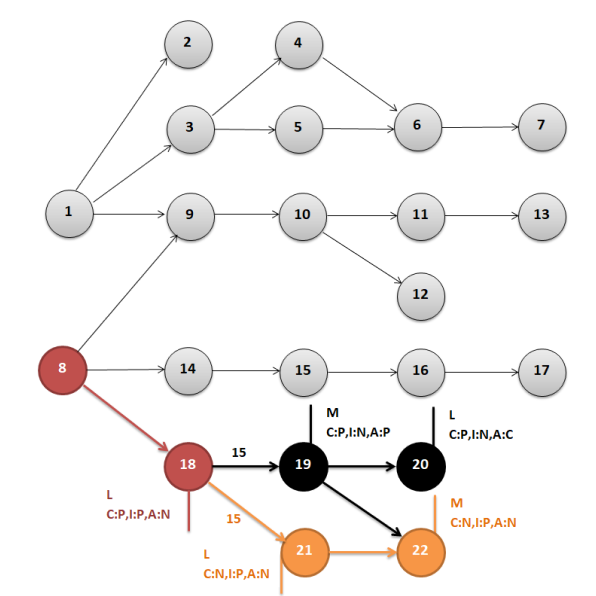
Красным показаны уязвимости, полученные от SIEM. Серым – уязвимости, отброшенные в ходе алгоритма, поскольку к ним больше не существует пути. Чёрным – уязвимости и частоты использования путей, всё ещё считающимися возможными путями в дереве атак. Оранжевым – уязвимости и частоты использования путей, определённые алгоритмом как наиболее вероятные.
В данном случае получаем следующую потенциальную CVE по количеству переходов.

Получаем следующую CVE от SIEM.
Не угадали. Да ещё и на следующем этапе только два пути и у них одинаковое количество переходов. Смотрим на сложность эксплуатации.
Снова не угадали. Снова переходы одинаковые. Да ещё и сложность эксплуатации совпала. Смотрим на векторы влияния.

Проблемы алгоритма исторического прогнозирования
Это такой подход «в лоб». Не очень элегантно. Но без реального опыта расследования компьютерных атак это максимум, который я мог выжать.
Также следует упомянуть, что в реальности скорее всего будет использоваться только условие по количеству переходов, потому что вероятность того, что количество переходов будет совпадать скорее всего очень мала.
А ещё начинаются сложности с тем, что, например, есть атака Разрушителя и атака Захватчика. Они пересекаются в одной CVE. Если чаще идут по пути Разрушителя, то атака Захватчика после перехода на эту CVE будет предсказываться не корректно.
Есть ещё один нюанс, что в описании алгоритма было сказано, что вычисляется вероятность для конечной цели. Но предложенная мной формула сильно так ломалась при вот таких вот пересечениях. Вычисление вероятности осталось, но стало проще, но и так вряд ли будет работать корректно.
И самое главное, что… Я, конечно, не специалист по расследованию компьютерных атак (о чём я уже говорил и не раз), но что-то мне подсказывает, что в реальности моя база данных выглядела бы как-то так.
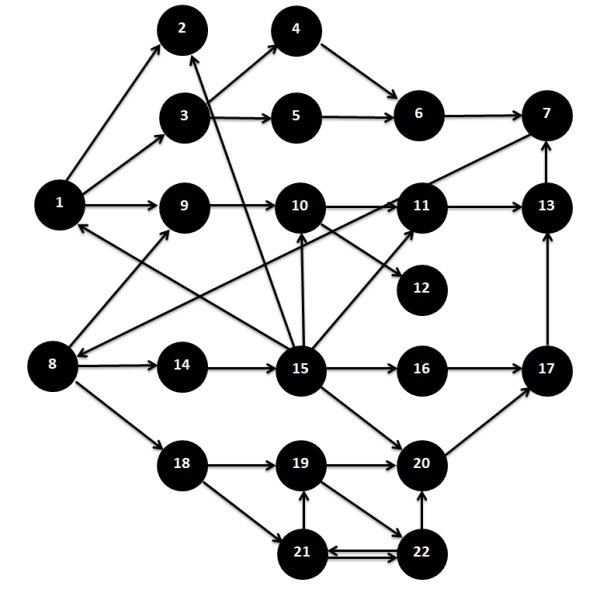
Т.е. немного хаоса. И это ещё более-менее хороший вариант, как мне кажется.
Такая база будет более-менее хорошо работать в пределах одного хоста (и то, CVE в прикладном ПО могут неправильно обсчитываться). Но как правильно предсказывать перемещение нарушителя между станциями? Нужно фильтровать CVE из базы на основе аудита защищённости.
Аналитический алгоритм
Смысл был в том, чтобы по CAPEC/CWE строить базу атак по CVE. Только по переходам информации не будет.
Получаем из SIEM CVE, по ней делаем классификацию нарушителя, а потом выбираем в базе CVE, которые наиболее соответствуют классу и навыкам нарушителя.
К сожалению, это одна из наименее проработанных частей в моём дипломе.
Тезисы по итогам проектирования
Сложно оценить какие ресурсы необходимы для поддержания базы данных. По крайней мере это сложно мне.
Есть определенные сложности как с записью новых данных в базу, так и с выгрузкой данных из неё.
Система не была реализована хоть в каком-то виде, кроме как на бумаге, а проводить эксперимент пришлось «руками». Я даже не могу представить сколько времени мне бы потребовалось, чтобы реализовать какую-нибудь демку. Наверное, если бы начал реализацию ещё при написании диплома, то как раз сейчас бы закончил.
Классификация нарушителей служит дополнительным инструментом в определении целей.
Сама система может выступать в качестве источника данных для какой-нибудь СППР. Например, если происходили попытки атак от Захватчика, а потом резко прекратились, то СППР может порекомендовать провести аудит, потому что Захватчик мог достичь своей цели.
Также, если научиться определять кто производит атаку, можно попробовать определять цели конкретного нарушителя. Также можно попробовать сделать обратное — по атаке говорить кто проводит атаку.
Систему нужно интегрировать не только с SIEM, но и с системами анализа защищенности.
«Исторический алгоритм» работающий инструмент, с помощью которого можно определять цели, но очень много оговорок. Это не самое элегантное решение, но пока что так. Нужно продолжать думать, дорабатывать. Либо отказываться и брать совершенно другой алгоритм.
Использование CAPEC имеет свои преимущества и недостатки, но требует дополнительной проработки.
Самое, наверное, обидное для этой системы с концептуальной точки зрения может быть в том случае, если нарушитель… не имеет цели. Он получает доступ к системе, потому что просто смог это сделать. Быть может, он и не планировал этот взлом. А потом просто не знает что делать дальше. Либо начинает вести себя как лиса в курятнике.
Система очень сильно завязана на возможности SIEM обнаруживать атаки, а также определять с помощью какой CVE атака проводится. Столкнувшись с 0-day система слепнет по всем трём методам прогнозирования. И с этим придётся жить, но никогда не забывать.
Система позволяет получать дополнительную информацию о нарушителе, поскольку большинство систем предоставляют только техническую информацию об атаке, в то время как информация об мотивах, целях и уровне навыков нарушителя тоже является важной и именно их моя система старается получить.
Спасибо за внимание.

