
Все началось, казалось бы, с простого вопроса, который сначала ввел меня в ступор — "Зачем нужен make? Почему нельзя обойтись bash скриптами?". И я подумал — Действительно, зачем нужен make? (и самое важное) Какие проблемы он решает?
Тут я решил немного подумать — как бы мы собирали свои проекты, если бы у нас не было make. Допустим, мы имеем проект с исходниками. Из них нужно получить исполняемый файл (или библиотеку). На первый взгляд задача вроде простая, но пошли дальше. Пусть на начальном этапе проект состоит из одного файла.

Для его компиляции достаточно выполнить одну команду:
$ gcc main.c -o main
Это было довольно просто. Но проходит некоторое время, проект развивается, в нем появляются некоторые модули и исходных файлов становится больше.
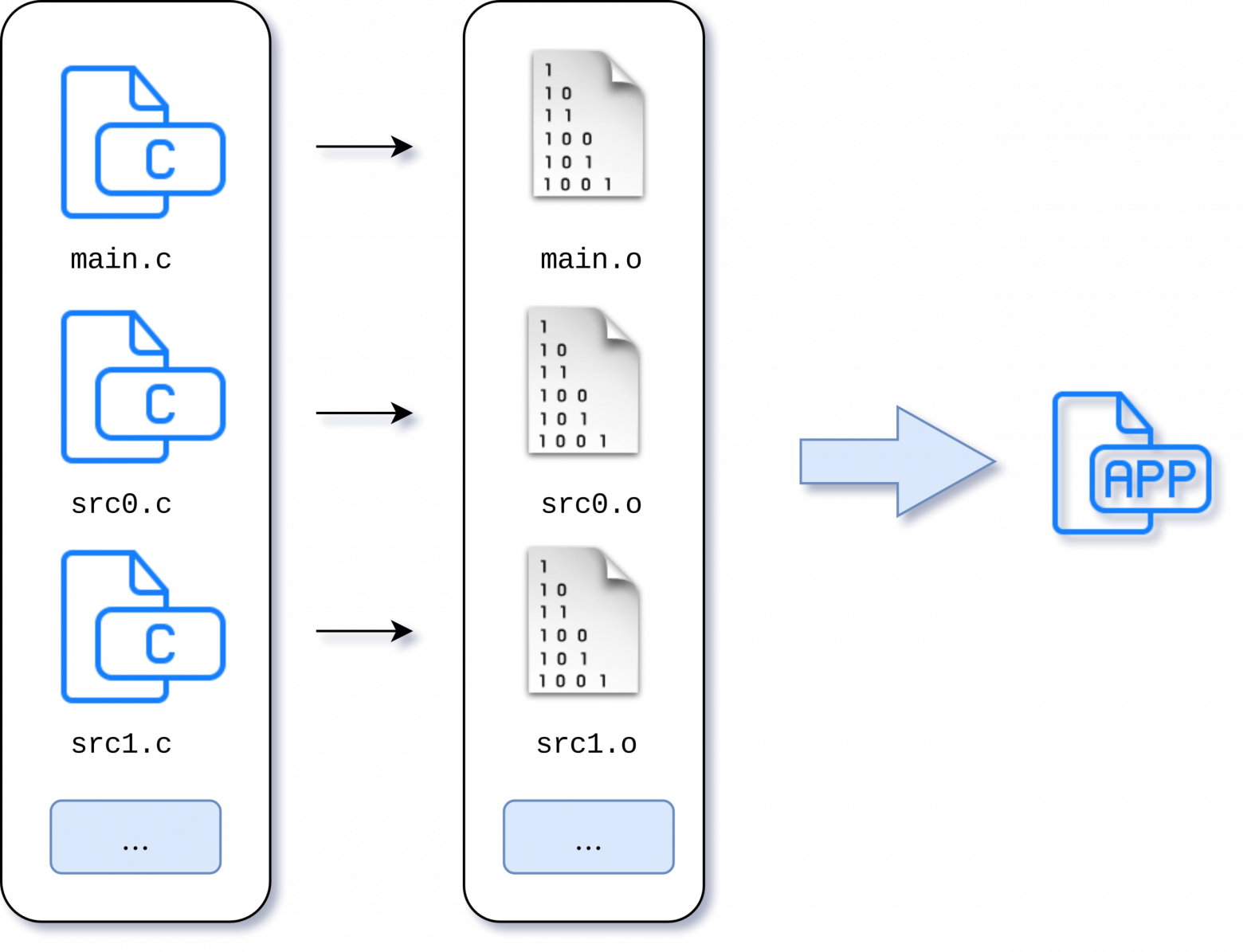
Для компиляции нужно выполнить условно вот такое количество команд:
$ gcc -c src0.c $ gcc -c src1.c $ gcc -c main.c $ gcc -o main main.o src0.o src1.o
Согласитесь, это довольно длительный и кропотливый процесс. Выполнять это вручную я бы не стал. Я бы подумал, что этот процесс можно автоматизировать, просто создав скрипт build.sh, который бы содержал эти команды. Окей, так намного проще:
$ ./build.sh
Погнали дальше! Проект растет, количество файлов с исходниками увеличивается и строк в них тоже становится больше. Мы начинаем замечать, что время компиляции заметно возросло. Тут мы видим существенную недоработку нашего скрипта — он выполняет компиляцию всех наших 50 файлов с исходниками, хотя мы модифицировали только один.
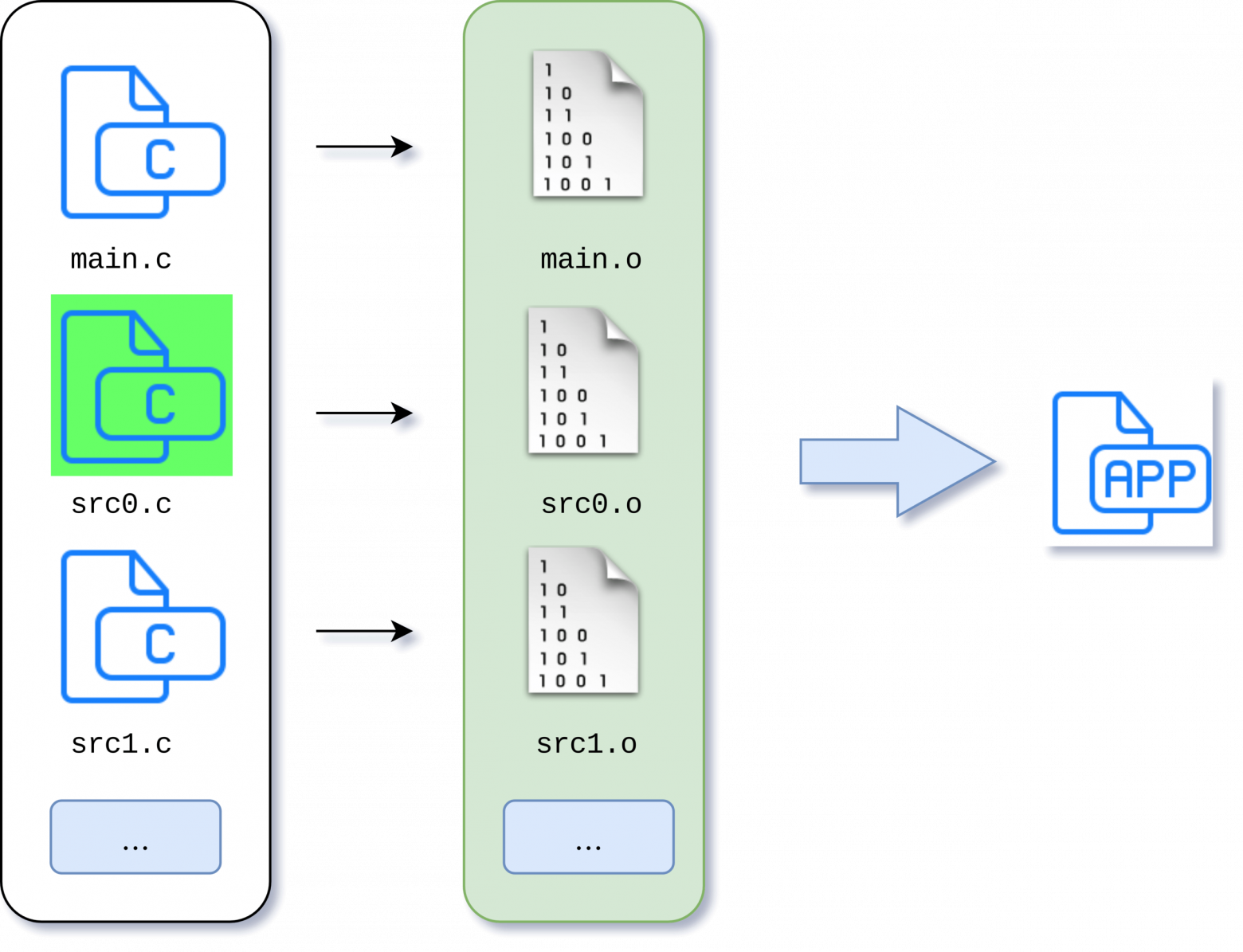
Так не пойдет! Время разработчика слишком ценный ресурс. Что же, мы можем попытаться доработать скрипт сборки таким образом, чтобы перед компиляцией производилась проверка времени модификации исходников и объектных файлов. И компилировать только те исходники, которые были изменены. И условно это может выглядеть как-то так:
#!/bin/bash function modification_time { date -r "$1" '+%s' } function check_time { local name=$1 [ ! -e "$name.o" ] && return $? [ "$(modification_time "$name.c")" -gt "$(modification_time "$name.o")" ] && return $? } check_time src0 && gcc -c src0.c check_time src1 && gcc -c src1.c check_time main && gcc -c main.c gcc -o main main.o src0.o src1.o
И теперь компилироваться будут только те исходники, которые были модифицированы.
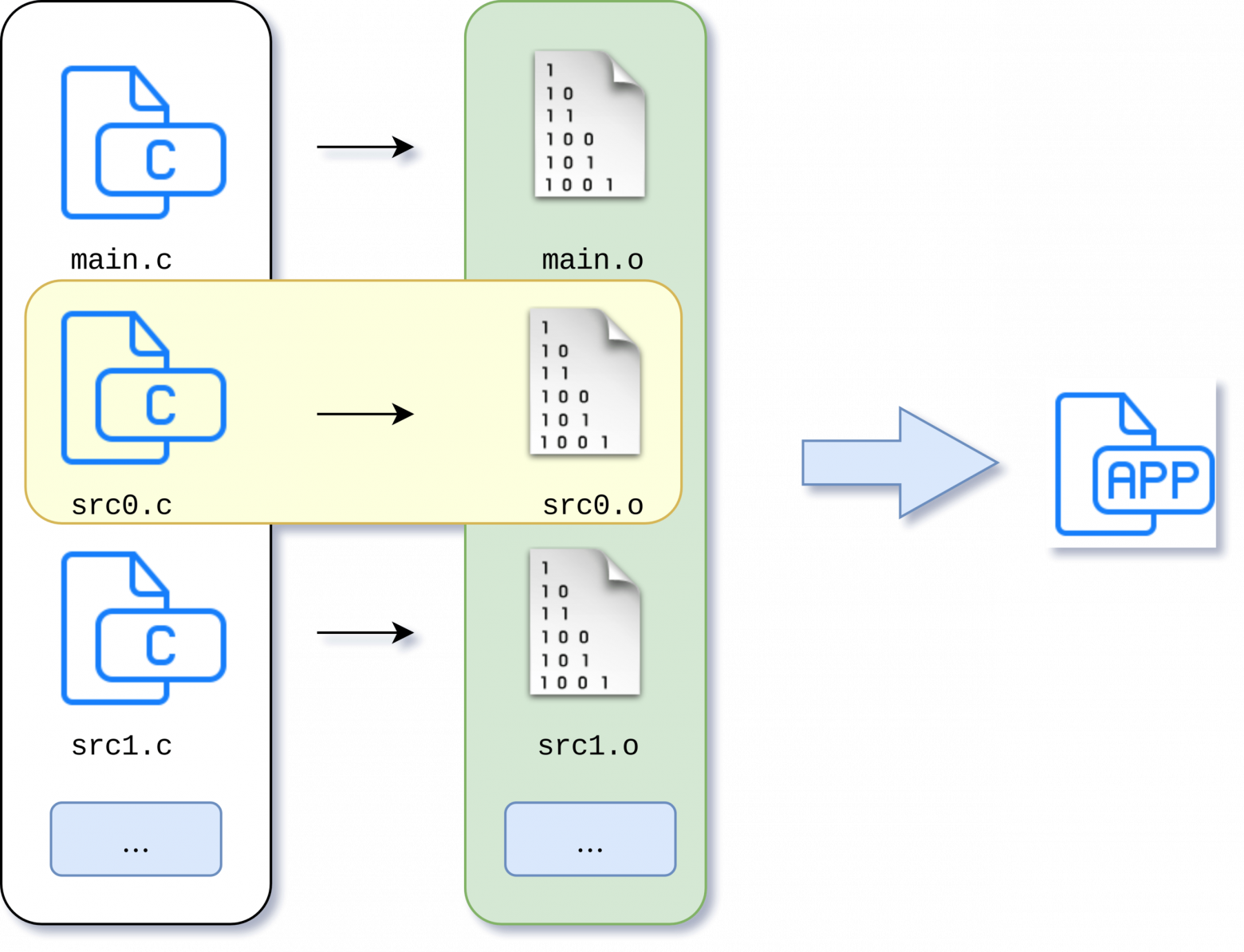
Но что произойдет, когда проект превратится во что-нибудь подобное:
Рано или поздно наступит такой момент, когда в проекте будет очень сложно разобраться и сама по себе поддержка подобных скриптов станет трудоемким процессом. И не факт, что этот скрипт будет производить адекватную проверку всех зависимостей. К тому же, у нас может быть несколько проектов и у каждого будет свой скрипт для сборки.
Само собой мы видим, что напрашивается какое то общее решение этой проблемы. Инструмент, который бы предоставил механизм для проверки зависимостей. И вот тут мы потихоньку подобрались к изобретению make. И теперь, зная с какими проблемами мы столкнемся в процессе сборки проекта, в конце концов я бы сформулировал следующие требования к make:
- анализ временных меток зависимостей и целей
- выполнение минимального объема работы, необходимого для того, чтобы гарантировать актуальность производных файлов
- (ну и + параллельное выполнение команд)
Makefile
Для описания правил сборки проекта используются Makefile'ы. Создавая Makefile, мы декларативно описываем определенное состояние отношений между файлами. Декларативный характер определения состояния удобен тем, что мы говорим, что у нас есть некоторый список файлов и из них нужно получить новый файл, выполнив некоторый список команд. В случае использования какого-либо императивного языка (например, shell) нам приходилось бы выполнять большое количество различных проверок, получая на выходе сложный и запутанный код, тогда как make делает это за нас. Главное построить правильное дерево зависимостей.
< цель > : < зависимости ... > < команда > ... ...
Не буду рассказывать про то, как писать Makefile'ы. В интернете очень много мануалов на эту тему и при желании можно обратиться к ним. И к тому же, мало кто пишет Makefile'ы вручную. А очень сложные Makefile'ы могут стать источником осложнений вместо того, чтобы упростить процесс сборки.

