В этой статье я хотел бы рассказать, как быстро и просто сделать каркас приложения на Java с поддержкой динамической загрузки плагинов. Читателю наверняка сразу в голову придёт, что такая задача уже давно решена, и можно просто использовать готовые фреймворки или написать свой загрузчик классов, но в предлагаемом мною решении ничего этого не потребуется:
Однако всё же есть одно требование — такое решение будет работать только на Java 9 или выше. Потому что оно будет основано на модулях и сервисах.
Итак, начнём. Сформулируем задачу более конкретно:
То есть собранное приложение должно выглядеть примерно так:
Давайте начнём с модуля
Создадим в модуле следующие 4 Java-файла:
Первый файл,
Я дал точке расширения абстрактное имя
Файл
Таким образом,
Также обратите внимание на второй метод
Второй файл,
Для простоты
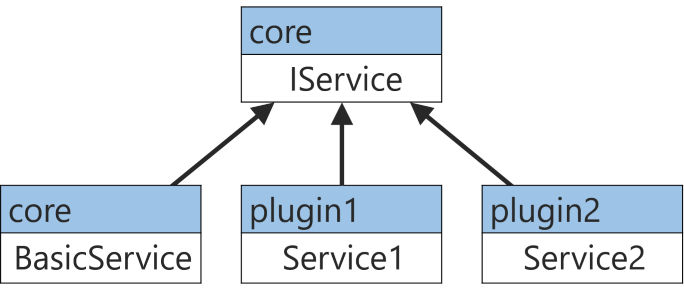
Таким образом, на текущий момент мы имеем следующую картину:

Третий файл,
Когда Java запускает приложение, то все модули платформы + модули, перечисленные в аргументе

Слой
К счастью, решение есть: Java позволяет в рантайме создавать свои собственные слои модулей, которые будут загружать модули из нужного нам места. Для наших целей будет достаточно одного нового слоя для плагинов, который в качестве родителя будет иметь слой

Тот факт, что слой плагинов имеет в качестве родителя слой
Итак, зная теперь, что такое слой модулей, наконец, можно посмотреть на содержимое файла
Если вы первый раз смотрите на этот код, то он может показаться очень сложным, но это ложное ощущение из-за большого количества новых неизвестных классов. Если немного разобраться в смысле классов ModuleFinder, Configuration и ModuleLayer, то всё становится на свои места. И кроме того, здесь всего лишь несколько десятков строк! Это вся логика, которая пишется один раз.
Остался ещё один (четвёртый) файл, который мы не рассмотрели:
Смысл строк этого файла должен быть очевиден:
Так как декларация модуля написана на Java, то мы получаем очень важные преимущества: проверки компилятора и статические гарантии. Например, если бы мы ошиблись в названии типов или указали бы несуществующий пакет, то сразу получили бы по рукам. В случае какого-нибудь OSGi никаких проверок во время компиляции мы бы не имели, поскольку декларация точек расширения была бы написана на XML.
Итак, каркас готов. Давайте попробуем запустить его:
Что произошло?
Написав ядро нашего приложения, теперь самое время попробовать написать к нему плагины. Давайте напишем два плагина
Создадим первый плагин с двумя файлами:
Файл
Файл
Обратите внимание, что
Второй плагин полностью аналогичен первому, поэтому приводить его здесь не буду.
Теперь давайте соберём плагины, положим их в папку
Ура, плагины подхватились! Как это произошло:
Заметьте, что именно потому, что поиск провайдеров сервисов начинается с дочерних слоёв, а потом переходит к родительским, то сначала печатается
Итак, я показал, как можно быстро и эффективно организовать плагинное приложение на Java, которое обладает следующими свойствами:
Повторюсь, я продемонстрировал лишь идею. В настоящем плагинном приложении были бы десятки-сотни модулей и сотни-тысячи точек расширений.
Я решил поднять эту тему, потому что сам последние 7 лет пишу модульное приложение с использованием Eclipse RCP, в котором в качестве плагинной системы используется пресловутый OSGi, а дескрипторы плагинов пишутся на XML. У нас более сотни плагинов и мы пока что ещё сидим на Java 8. Но даже если мы перейдём на новую версию Java, то мы вряд ли будем использовать модули Java, поскольку сильно завязаны на OSGi.
Но если вы пишете плагинное приложение с нуля, то модули Java — это один из возможных вариантов его реализации. Помните, что модули — это лишь инструмент, а не цель.
Программирую более 10 лет (из них 8 на Java), отвечаю на StackOverflow и веду свой канал в Telegram, посвящённый Java.
- Нам не понадобятся специальные библиотеки или фреймворки (OSGi, Guice и т.п.)
- Мы не будем использовать парсинг байткода с помощью ASM и подобных библиотек.
- Не будем писать свой загрузчик классов.
- Не будем использовать рефлексию и аннотации.
- Не понадобится возня с classpath для поиска плагинов. Мы вообще не будем трогать classpath.
- Также мы не будем использовать XML, YAML или какие-либо другие декларативные языки для описания точек расширений (extension point’ов в плагинах).
Однако всё же есть одно требование — такое решение будет работать только на Java 9 или выше. Потому что оно будет основано на модулях и сервисах.
Итак, начнём. Сформулируем задачу более конкретно:
Нужно реализовать минимальный каркас приложения, которое при старте будет подгружать пользовательские плагины из папки plugins.То есть собранное приложение должно выглядеть примерно так:
plugin-app/ plugins/ plugin1.jar plugin2.jar ... core.jar …
Давайте начнём с модуля
core. Данный модуль — это ядро нашего приложения, то есть по сути и есть наш каркас.Для тех, кому дорого время, готовый проект выложен на GitHub. Инструкции по сборке.
Ссылка
git clone https://github.com/orionll/plugin-app cd plugin-app mvn verify cd core/target java --module-path core-1.0-SNAPSHOT.jar --module core
Создадим в модуле следующие 4 Java-файла:
core/ src/main/java/ org/example/pluginapp/core/ IService.java BasicService.java Main.java module-info.java
Первый файл,
IService.java — это файл, в котором описана наша точка расширения. В эту точку расширения потом смогут делать вклад («контрибьютить») другие плагины. Это стандартный принцип построения плагинных приложений, который называется принципом инверсии зависимостей (Dependency Inversion). В основе этого принципа лежит то, что ядро зависит не от конкретных классов, а от интерфейсов.Я дал точке расширения абстрактное имя
IService, так как сейчас я демонстрирую исключительно концепцию. В реальности это может быть любая конкретная точка расширения, например, если вы пишете графический редактор, то это может быть эффект обработки изображения, например, IEffectProvider, IEffectContribution или ещё как то иначе в зависимости от того, как вы предпочитаете именовать точки расширения. При этом само приложение будет содержать некоторый базовый набор эффектов, а сторонние разработчики смогут писать дополнительные более изощрённые эффекты и поставлять их в виде плагинов. Пользователю понадобится лишь положить эти эффекты в папку plugins и перезапустить приложение.Файл
IService.java выглядит следующим образом:… public interface IService { void doJob(); static List<IService> getServices(ModuleLayer layer) { return ServiceLoader .load(layer, IService.class) .stream() .map(Provider::get) .collect(Collectors.toList()); } }
Таким образом,
IService — это просто интерфейс, который делают некую абстрактную работу doJob() (повторюсь, детали не важны, в реальности это будет что-то конкретное).Также обратите внимание на второй метод
getServices(). Этот метод возвращает все реализации интерфейса IService, который он нашёл в данном слое модулей и его родителях. Об этом мы поговорим подробнее чуть позже.Второй файл,
BasicService.java — это базовая реализация интерфейса IService. Она будет всегда присутствовать, даже если в приложении не будет ни одного плагина. Другими словами, core — это не только ядро, но ещё и одновременно плагин для самого себя, который будет всегда загружен. Файл BasicService.java выглядит следующим образом:… public class BasicService implements IService { @Override public void doJob() { System.out.println("Basic service"); } }
Для простоты
doJob() просто печатает строку "Basic service" и всё.Таким образом, на текущий момент мы имеем следующую картину:
Третий файл,
Main.java — это то, где реализован метод main(). В нём есть есть немножечко магии, для понимания которой нужно знать, что такое слой модулей (module layer).Про слои модулей
Когда Java запускает приложение, то все модули платформы + модули, перечисленные в аргументе
--module-path (и ещё classpath, если он есть), попадают в так называемый слой Boot. В нашем случае, если мы соберём модуль core.jar и запустим из командной строки java --module-path core.jar --module core, то в слое Boot будут как минимум модули java.base и core:Слой
Boot всегда присутствует в любом Java-приложении, и это самая минимально возможная конфигурация. Большая часть приложений так и существует в одном единственном слое модулей. Однако в нашем случае мы хотим делать динамическую загрузку плагинов из папки plugins. Мы могли бы просто заставить пользователя исправлять строку запуска приложения, чтобы он сам добавлял в --module-path необходимые плагины, но это будет не самым лучшим решением. Особенно оно не понравится тем людям, которые не являются программистами и не понимают, зачем для такой простой вещи им нужно куда-то лезть и что-то исправлять.К счастью, решение есть: Java позволяет в рантайме создавать свои собственные слои модулей, которые будут загружать модули из нужного нам места. Для наших целей будет достаточно одного нового слоя для плагинов, который в качестве родителя будет иметь слой
Boot (любой слой обязан иметь родителя):Тот факт, что слой плагинов имеет в качестве родителя слой
Boot, означает, что модули из слоя плагинов могут ссылаться на модули из слоя Boot, но не наоборот.Итак, зная теперь, что такое слой модулей, наконец, можно посмотреть на содержимое файла
Main.java:… public final class Main { public static void main(String[] args) { Path pluginsDir = Paths.get("plugins"); // Будем искать плагины в папке plugins ModuleFinder pluginsFinder = ModuleFinder.of(pluginsDir); // Пусть ModuleFinder найдёт все модули в папке plugins и вернёт нам список их имён List<String> plugins = pluginsFinder .findAll() .stream() .map(ModuleReference::descriptor) .map(ModuleDescriptor::name) .collect(Collectors.toList()); // Создадим конфигурацию, которая выполнит резолюцию указанных модулей (проверит корректность графа зависимостей) Configuration pluginsConfiguration = ModuleLayer .boot() .configuration() .resolve(pluginsFinder, ModuleFinder.of(), plugins); // Создадим слой модулей для плагинов ModuleLayer layer = ModuleLayer .boot() .defineModulesWithOneLoader(pluginsConfiguration, ClassLoader.getSystemClassLoader()); // Найдём все реализации сервиса IService в слое плагинов и в слое Boot List<IService> services = IService.getServices(layer); for (IService service : services) { service.doJob(); } } }
Если вы первый раз смотрите на этот код, то он может показаться очень сложным, но это ложное ощущение из-за большого количества новых неизвестных классов. Если немного разобраться в смысле классов ModuleFinder, Configuration и ModuleLayer, то всё становится на свои места. И кроме того, здесь всего лишь несколько десятков строк! Это вся логика, которая пишется один раз.
Дескриптор модуля
Остался ещё один (четвёртый) файл, который мы не рассмотрели:
module-info.java. Это самый короткий файл, в котором содержатся декларация нашего модуля и описание сервисов (точек расширения):… module core { exports org.example.pluginapp.core; uses IService; provides IService with BasicService; }
Смысл строк этого файла должен быть очевиден:
- Во-первых, модуль экспортирует пакет
org.example.pluginapp.core, чтобы плагины могли наследоваться от интерфейсаIService(иначеIServiceне был бы доступен вне модуляcore). - Во-вторых, он объявляет, что использует сервис
IService. - В-третьих, он говорит, что предоставляет реализацию сервиса
IServiceчерез классBasicService.
Так как декларация модуля написана на Java, то мы получаем очень важные преимущества: проверки компилятора и статические гарантии. Например, если бы мы ошиблись в названии типов или указали бы несуществующий пакет, то сразу получили бы по рукам. В случае какого-нибудь OSGi никаких проверок во время компиляции мы бы не имели, поскольку декларация точек расширения была бы написана на XML.
Итак, каркас готов. Давайте попробуем запустить его:
> java --module-path core.jar --module core Basic service
Что произошло?
- Java попыталась найти модули в папке
pluginsи не нашла ни одного. - Создался пустой слой.
- ServiceLoader начал поиск всех реализаций
IService. - В пустом слое он не нашёл ни одной реализации сервиса, поскольку там нет ни одного модуля.
- После этого слоя он продолжил поиск в родительском слое (т.е. слое
Boot) и нашёл одну реализациюBasicServiceв модулеcore. - У всех найденных реализаций был вызван метод
doJob(). Поскольку найдена только одна реализация, то было напечатано только"Basic service".
Пишем плагин
Написав ядро нашего приложения, теперь самое время попробовать написать к нему плагины. Давайте напишем два плагина
plugin1 и plugin2: пусть первый печатает "Service 1", второй — "Service 2". Чтобы это сделать, нужно предоставить ещё две реализации IService в plugin1 и plugin2 соответственно:Создадим первый плагин с двумя файлами:
plugin1/ src/main/java/ org/example/pluginapp/plugin1/ Service1.java module-info.java
Файл
Service1.java:… public class Service1 implements IService { @Override public void doJob() { System.out.println("Service 1"); } }
Файл
module-info.java:… module plugin1 { requires core; provides IService with Service1; }
Обратите внимание, что
plugin1 зависит от core. Это упоминаемый мною ранее принцип инверсии зависимостей: не ядро зависит от плагинов, а наоборот.Второй плагин полностью аналогичен первому, поэтому приводить его здесь не буду.
Теперь давайте соберём плагины, положим их в папку
plugins и запустим приложение:> java --module-path core.jar --module core Service 1 Service 2 Basic service
Ура, плагины подхватились! Как это произошло:
- Java нашла два модуля в папке
plugins. - Создался слой с двумя модулями
plugins1иplugins2. - ServiceLoader начал поиск всех реализаций
IService. - В слое плагинов он нашёл две реализации сервиса
IService. - После этого он продолжил поиск в родительском слое (т.е. слое
Boot) и нашёл одну реализациюBasicServiceв модулеcore. - У всех найденных реализаций был вызван метод
doJob().
Заметьте, что именно потому, что поиск провайдеров сервисов начинается с дочерних слоёв, а потом переходит к родительским, то сначала печатается
"Service 1" и "Service 2", а потом "Basic Service". Если хочется, чтобы сервисы были отсортированы так, чтобы сначала шли базовые сервисы, а потом плагины, то можно подправить метод IService.getServices(), добавив туда сортировку (возможно для этого придётся добавить метод int getOrdering() в интерфейс IService).Итоги
Итак, я показал, как можно быстро и эффективно организовать плагинное приложение на Java, которое обладает следующими свойствами:
- Простота: для точек расширения и их связывания используются только базовые возможности Java (интерфейсы, классы и ServiceLoader), без фреймворков, рефлексии, аннотаций и загрузчиков классов.
- Декларативность: точки расширения описываются в дескрипторах модулей. Достаточно взглянуть на
module-info.javaи понять, какие существуют точки расширения и какие плагины делают вклад в эти точки. - Статические гарантии: в случае ошибок в дескрипторах модулей программа не скомпилируется. Также в качестве бонуса, если вы используете IntelliJ IDEA, то получаете дополнительные предупреждения (например, если забыли написать
usesи при этом используетеServiceLoader.load()) - Безопасность: модульная система Java проверяет во время старта, что конфигурация модулей является корректной, и в случае ошибок отказывается выполнять программу.
Повторюсь, я продемонстрировал лишь идею. В настоящем плагинном приложении были бы десятки-сотни модулей и сотни-тысячи точек расширений.
Я решил поднять эту тему, потому что сам последние 7 лет пишу модульное приложение с использованием Eclipse RCP, в котором в качестве плагинной системы используется пресловутый OSGi, а дескрипторы плагинов пишутся на XML. У нас более сотни плагинов и мы пока что ещё сидим на Java 8. Но даже если мы перейдём на новую версию Java, то мы вряд ли будем использовать модули Java, поскольку сильно завязаны на OSGi.
Но если вы пишете плагинное приложение с нуля, то модули Java — это один из возможных вариантов его реализации. Помните, что модули — это лишь инструмент, а не цель.
Коротко обо мне
Программирую более 10 лет (из них 8 на Java), отвечаю на StackOverflow и веду свой канал в Telegram, посвящённый Java.
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
Какую версию Java используете?
3.77%Java 6 или более старая версия4
7.55%Java 78
75.47%Java 880
1.89%Java 92
0%Java 100
30.19%Java 1132
11.32%Java 12+12
Проголосовали 106 пользователей. Воздержались 8 пользователей.

