
JavaScript язык особенный. Сколько его не изучай, всегда найдутся моменты, которые заставят даже матёрого профессионала начать чесать репу.
В этой статье приводятся несколько задачек на JavaScript, связанных с необычным поведением языка. Кому-то они помогут узнать что-нибудь новое, а кто-то просто сможет освежить знания.
Задачка 1 — «BANANA»
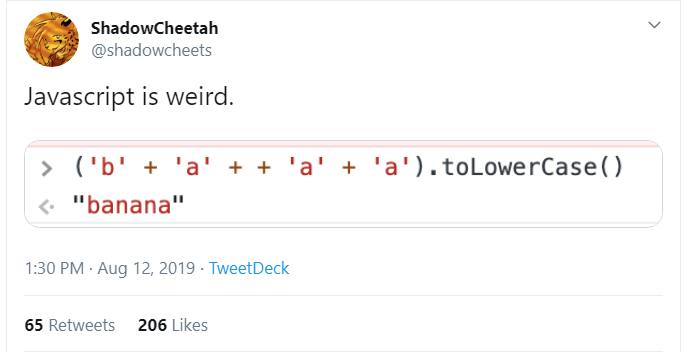
Этот твит в своё время приобрёл определённую популярность в англоязычном сегменте твиттера, посвящённом JavaScript. Не в последнюю очередь потому, что совсем неочевидно, что здесь происходит.
«b» и «a» в начале — это просто строки, результатом сложения которых будет «ba». После «а» вы видите два знака плюс (+). Первый из них предназначен для сложения, зато второй — унарный оператор, который преобразует следующую за ним строку в число. Поскольку вторая «а» не может быть преобразована в число, она преобразуется в «NaN».
Таким образом имеем: «ba» + «NaN» + «a» — «baNaNa». toLowerCase коварно выдаёт нам конечный результат — «banana».
Задачка 2 — Сложение массивов

Это простая задачка, но человека незнакомого с тем, как работает JavaScript, она может поставить в тупик.
Сначала массивы преобразуются в строки — «1,2,3» и «4,5,6». Результатом конкатенации этих строк и будет конечный ответ — строка «1,2,34,5,6».
Задачка 3 — функция parseInt( )
Из всех задачек по JavaScript именно эта для меня оказалась самой сложной.

Если с parseInt в JavaScript так или иначе сталкивались, наверное, все, то о существовании второго опционального параметра «radix» знает уже меньшее количество людей. Это основание системы счисления первого аргумента.
Первый аргумент «null» конвертируется в строку. Первый символ этой строки «n» конвертируется в число в системе счисления с основанием 24. Результат этого преобразования — 23.
parseInt продолжает парсить строку посимвольно, пока не столкнётся с символом, который преобразовать в число не сможет. Это второй символ строки — «u», так как такой цифры нет в системе счисления с основанием 24.
Таким образом:
parseInt(null, 24) === parseInt("null", 24) parseInt("null", 24) === parseInt("n", 24) parseInt("n", 24) === 23
Задачка 4 — точность чисел с плавающей точкой

Выглядит ужасно, но справедливости ради, в той или иной степени с подобным можно столкнуться в любом языке, использующим вычисления с плавающей точкой.
console.log(0.1 + 0.2); // 0.30000000000000004
Константы «0.2» и «0.3» в программе будут аппроксимированы до их «настоящих» значений в машинном представлении. И так уж получилось, что ближайшее double до «0.2» больше, чем рациональное число «0.2». С другой стороны, ближайшее double до «0.3» меньше рационального «0.3».
Таким образом, сумма «0.1» и «0.2» в коде оказывается больше рационального «0.3», а константа «0.3» в коде меньше рационального «0.3».
Хозяйке на заметку: никогда не используйте "===" или "==" для работы с числами с плавающей точкой. Вместо этого используйте
if (abs(x - y) < toleranceValue) { ... }
Заключение
Да, при работе с JavaScript возникает немало WTF моментов. С другой стороны, какой ещё язык может подарить столько незабываемых ощущений?
Ниже список ссылок (на английском языке) для углублённого изучения задачек из этого поста (и не только):

