
Make AI Strong Again!
В последнее время термин «искусственный интеллект» стал чрезвычайно широким. Где только не употребляют его – от «умных» устройств до программ игры в шахматы, Го и пр. При этом собственно интеллекта, сознания в человеческом понимании в этих устройствах нет.
Наиболее хайповые темы — нейросети, глубокое обучение и пр. основаны на концепциях, которые предполагают реализацию, по сути, только одной функции — распознавания образов и не могут привести к созданию полноценной системы искусственного интеллекта.
В этой статье я предлагаю вернуться к изначальному пониманию задачи – созданию систем, обладающих свойствами мыслительной деятельности человека – такими, как понимание смысла, построение плана действий для достижения цели, способность объяснить свои действия, корректировка поведения в зависимости от окружающей среды и т.д.
Уже многие годы предпринимаются попытки создать системы искусственного интеллекта, приближающиеся по свойствам к мозгу человека. Однако до сих пор этого не удалось достичь. Ученые уже достаточно подробно знают функции и строение базовых элементов мозга – специальных клеток, называемых нейронами. Также более-менее изучено общее строение мозга – какие части мозга за какие глобальные функции отвечают. Однако средний уровень — уровень соединений нейронов в более крупные структуры и связь этих структур с сознанием и процессом мышления остается загадкой.
Данная статья является попыткой представить гипотезу способа объединения нейронов в более крупные структуры, описать основные функции и свойства этих структур. Это позволит, по моему мнению, подойти к технической реализации таких понятий, как смысл, внимание, целенаправленное поведение, самосознание и др. Представленные идеи конечно необходимо проверить на практике. Но даже если они не подтвердятся, возможно соображения, изложенные в данной статье, подтолкнут других исследователей к работе в этом направлении, явно испытывающем дефицит конструктивных идей в настоящее время.
Представленную в статье концепцию я назвал — «Динамическая семантическая сеть, основанная на действиях».
1. Исходные положения
Ниже изложены известные факты об устройстве нервной системы, на которых базируется предлагаемая модель:
- Восприятие внешних сигналов в нервной системе происходит специальными структурами, называемыми рецепторами, которые активируются при определенных условиях внешней среды.
- Выполнению элементарных действий (сокращение/расслабление мышц, выделение химических веществ) происходит за счет активизации других элементов, называемых эффекторами.
- Передача активности между рецепторами и эффекторами выполняется специальными элементами, называемыми нейронами.
- Сигнал активности – бинарный. Активность либо есть, либо нет.
- Для возможности обучения в процессе обработки информации необходима способность образовывать новые нейроны и связи между ними.
- В мышцах, сухожилиях и суставах присутствуют рецепторы, то есть выполняемые действия посылают сигналы о своем выполнении — действия ощущаются.
2. Описание модели
2.1 Общая схема
Информация, обрабатываемая в системе, имеет в своей основе ощущения, то есть сигналы от определенных рецепторов — визуальных, слуховых и прочих. На определенном этапе обработки, эта информация становится знанием, а процесс ощущается как мышление. Нет какой-то отдельной сущности для представления мыслей. То, что мы называем мыслью – это обработанные ощущения.
Сигнал от рецепторов (ощущение) может возникать как вследствие внешнего раздражения, так и от сигналов изнутри системы.
Общая схема обработки представлена на Рис. 1.

Рис. 1 Общая схема
В дальнейшем под термином рецепторы будем понимать совместно собственно сенсоры и функциональность переключения, обеспечивающую активацию либо извне системы, либо изнутри.
2.2. Детектор, действие, понятие
Итак, рецепторы регистрируют элементарные сигналы окружающей среды, такие как цвет, яркость точек пространства, амплитуду и частоту колебаний окружающего воздуха, температуру участков тела, положение суставов, состояние мышц, химический состав в определенных точках тела и др. В результате возникают наборы сигналов активности от рецепторов идущие в сеть обработки.
В сети обработки, частично вследствие генетической информации, а в большей степени на основе индивидуального опыта, образуются нейроны, реагирующие только на определенные комбинации входных сигналов. Будем называть данные нейроны детекторами, а комбинацию входных сигналов от рецепторов — образом. То есть детекторы выполняют функцию распознавания образов. Собственно, именно эту функцию и моделируют разнообразные широко известные в настоящий момент нейронные сети. Но их разработчики на этом и останавливаются, а мы пойдем дальше.
Аналогично детекторам, нейроны посылающие сигналы к эффекторам, могут объединяться в более сложные структуры, активация входных связей которых приводит к выполнению комбинаций элементарных действий. Таким образом, возникают структуры, представляющие действия.
Можно представить образование структуры, которая будет выполнять следующие действия:
- Активизацию связей изнутри системы к некоторой комбинации рецепторов
- Установку переключателя (Рис.1) на восприятие сигналов изнутри системы
Таким образом образуется действие по воображению, представлению некоего образа, являющегося набором сигналов от рецепторов. Будем называть такие действия действиями-представлениями некоторого образа.
Комбинация детектора некоторого образа и действия-представления для этого образа образует понятие-образ, с которым система может работать. С помощью детектора система может распознать понятие во входном сигнале, а с помощью действия-представления представить его, даже при отсутствии соответствующих сигналов извне.
2.3. Ассоциативные связи
Между понятиями-образами могут образовываться связи, так что, например, одно понятие может активировать другое. Таким образом активация извне детектора визуального образа может приводить к активации, например, звукового, или другого визуального образа. Пример варианта подобных связей показан на Рис. 2.

Рис. 2 Ассоциативные связи
2.4. Действия-восприятия и действие-внимание
Ранее мы рассмотрели действия-представления, активизация которых приводила к представлению какого-то образа на входе сети обработки. Эти действия устанавливали переключатель рецепторов на прием информации изнутри системы.
В случае установки переключателя на прием информации извне, состояние рецепторов будет определяться состоянием окружающей среды. Назовем такие действия действиями-восприятиями. Это такие знакомые нам понятия, как например смотреть, слушать, читать.
Рецепторы поставляют в сеть обработки данные о большом числе параметров (например, зрительный нерв содержит около миллиона волокон). Если учитывать весь набор входных сигналов, то воспринятые образы были бы для системы всегда новыми, так как окружающая среда никогда не бывает одной и той же до мельчайших деталей. И система в этом случае не могла бы узнавать ранее виденные части новой сцены.
То есть необходима возможность ограничения входных сигналов, фильтрации их. Это приводит нас к необходимости действия — внимания. На пути сигналов от рецепторов должен располагаться некий фильтр, управляемый вниманием и способный отсекать часть информации по определенным признакам. Прошедшие этот фильтр сигналы, либо приведут к активации какого-то детектора (в случае, если ранее он был сформирован в системе), либо должны быть запомнены на случай возможной важности в будущем. Таким образом, помимо фильтрации, внимание должно уметь создать из прошедших фильтр сигналов временное понятие, объединив активные детекторы и сформировав связи к соответствующим действиям-представлениям.
Рис. 3 показывает действия-восприятия и входящее в их состав действие-внимание.
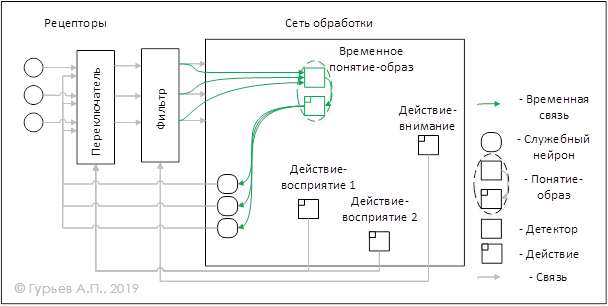 "
"Рис. 3 Действия-восприятия и действие-внимание
Созданные временные понятия и связи через некоторое время могут разрушаться, а могут и становиться постоянными, в случае неоднократного использования.
Общий процесс восприятия информации от окружающей среды разбивается таким образом на отдельные акты восприятия, завершающиеся либо созданием/модификацией временных понятий (при замечании чего-то нового в окружающей среде) или просто активизацией уже созданных понятий.
Действие-внимания, активирующее при восприятии временные понятия, ведет упорядоченный список этих понятий, глубина которого вероятно и определяет размер кратковременной памяти человека (обычно не более 10 понятий).
2.5. Действие как основа (смысл) понятий
Размышление о разных понятиях с которыми оперирует мозг человека, приводит к наблюдению, что понятие действия является центральным и лежит в основе практически всех понятий и составляет так называемый их смысл.
Рассмотрим понятия, выражающие свойства или характеристики объектов.
2.5.1. Понятия — характеристики
Образы, регистрируемые рецепторами, содержат в себе информацию о разных базовых характеристиках окружающей среды, например, цвете, яркости, форме линий в определенной точке пространства, частоте и силе колебаний воздуха и других параметрах.
Проверяя образ на выполнение некоторых условий, можно активировать понятия, которые будут выражать значения определенных характеристик или признаков, например, «красный», «желтый», «в центре», «круглый», «большой».
Само действие по проверке этих условий можно считать вопросом о чем-либо, а результат работы этого действия ответом на этот вопрос. Например, вопрос – «Дом красный?», ответ — «Красный». Но необходимо как-то обозначать отрицательный результат проверки. Так появляется понятие «Нет», выражающее отрицательный результат любой проверки. Для симметрии и удобства появляется понятие «Да», которое обозначает положительный результат проверки. Ответы «Красный» и «Да» на вышеуказанный вопрос эквивалентны.
Отдельные действия проверки могут группироваться в наборы, которые получают определенное обозначение. Так появляются наборы характеристик «Цвет», «Размер», «Форма» и другие, включающие в себя отдельные проверки, такие как например, «красный», «желтый», «большой», «маленький». В этих общих характеристиках содержится действие, объединяющее в себе проверки отдельных элементов. Результатом этого действия является одно из значений, входящих в это понятие характеристик. Например, «Размер дома?» — «Большой». Ответить «Да», или «Нет» на подобные вопросы нельзя.
В дальнейшем будем называть характеристикой как отдельное понятие (например, «большой»), так и групповое (например, «размер»). При их использовании каких-то существенных отличий не имеется.
Говоря о действиях-характеристиках можно различить четыре варианта их использования:
- Можно говорить об обобщенном действии-характеристике, например, «Цвет чего-то», «Размер чего-то» и др. Эти выражения просто определяют действие, задают какие признаки образа проверяются, и какие возможные значения могут получаться в результате. Аналог описания класса в объектно-ориентированном программировании.
- Можно говорить о характеристике какого-то конкретного объекта, представляемого временным понятием, созданным действием-восприятием. Например, внутрисистемным представлением (смыслом) фразы «Какой цвет у этой книги?» будет новое временное понятие, действие-характеристика созданное на основе обобщенного понятия «Цвет чего-то» (п.1) и временного понятия «Эта книга». У характеристики «Цвет чего-то» параметр объекта действия указывает на «Эта книга». Является аналогом экземпляра класса в объектно-ориентированном программировании с конкретизированным значением объекта действия.
- А можно задать и результат действия. Этот вариант будет внутренним представлением утвердительных фраз, например, «Цвет этой книги красный». Является аналогом экземпляра класса в объектно-ориентированном программировании у которого конкретизированы объект действия и результат.
- И, наконец, может быть задан результат действия, но не задан объект. Этот вариант будет внутренним представлением фраз вида «Что-то красное», «Что-то большое». Является аналогом экземпляра класса в объектно-ориентированном программировании у которого конкретизированы только результат.
Таким образом одна внутренняя структура (действие по проверке определенного признака) лежит в основе таких различных понятий, как 1) обобщенное понятие – характеристика («форма»), 2) вопрос о характеристике конкретного объекта («Какая форма у этого камня?»),
3) утверждение о свойстве конкретного объекта («Камень, лежащий наверху — круглый») и 4) указание на некий объект с определенными свойствами («Что-то круглое»).
Возможность задать результат действия, не выполняя собственно проверку свойств образа, чрезвычайно важна. Она позволяет обрабатывать информацию об объектах в отсутствии собственно образа объекта. Это открывает дорогу к конструированию любых, в том числе абстрактных, понятий, например, «кто-то хороший», «кто-то уважаемый», «функция логарифмическая» и так далее.
Рассмотрим возможную внутреннюю структуру действия-характеристики. Из изложенного выше понятно, что в нем должны присутствовать указатели на объект действия и результат. В рамках действия должны выполняться активности по представлению образа объекта, по проверке определенных свойств этого образа и по формированию результата (активации соответствующего понятия и установлению на него ссылки результата действия). В случае заданного заранее результата, активности по представлению и проверке образа не выполняются.
Схематично это отражено на Рис.4

Рис. 4 Возможное внутреннее устройство действия-характеристики
2.5.2. Сравнительные понятия, понятия отношения
В предыдущем разделе мы говорили о признаках, характеризующих некий образ и выяснили, что смыслом этих понятий было действие сравнения этих признаков с определенными, заранее известными шаблонами. При определении, например, цвета происходило сравнение с шаблонами известных цветов и совпавший считался результатом.
Если же проводить сравнение не с заданным заранее шаблоном, а с признаками другого объекта, то получим сравнительные понятия или понятия-отношения. Например, «что-то больше чего-то», «что-то ярче чего-то», «что-то выше чего-то» и так далее.
Подобно характеристикам, отношения не обязаны базироваться только на признаках, содержащихся в образе, воспринимаемом рецепторами. Вполне возможны понятия, не имеющие явного внешнего представления, например, «Он ее муж», «Он руководитель отдела», «Что-то принадлежит кому-то». Иногда даже затруднительно сформулировать ясные правила проверки какого-то признака, как например для понятия принадлежности.
При отсутствии того или другого объекта отношения, получаются вопросы (например, «Что принадлежит Саше?», «Чья эта ручка?»).
2.5.3. Объект – образ и набор характеристик
Воспринятый рецепторами образ можно представить либо в виде сигналов, составляющих этот образ — «фотографии», либо в виде набора результатов действий по проверке каких-то признаков, то есть набора характеристик, либо и того и другого вместе.
Комбинация образа и/или характеристик, всегда встречающихся вместе удобно представлять понятием объект.
На Рис.5 изображено возможное представление объекта, характеризуемого визуальным образом «Образ 1», ассоциативно связанным с ним звуковым образом «Образ 2» и двумя характеристиками «Цвет» и «Форма».
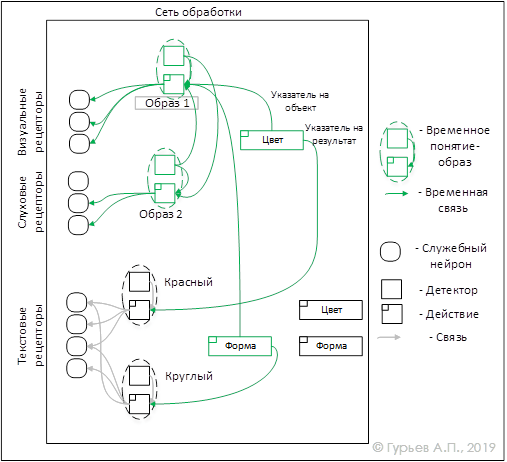
Рис. 5 Возможное представление объекта
Отметим, что значения «Круглый» и «Красный» являются образами «текстовых» рецепторов, то есть словами. «Текстовые рецепторы», реагирующие на символы компьютерной информации отсутствуют конечно у человека и приведены, как возможный пример искусственной системы обработки символьной информации.
2.5.4. Характеристика «быть»
Среди всех возможных характеристик есть одна, которая присутствует всегда и является как бы основой для появления других характеристик. Это характеристика отражающее бытие, наличие чего-то. И уже после этого, это что-то может иметь и другие характеристики.
Это характеристика выражается словами «быть», «есть». Действие, лежащее в ее основе, проверяет наличие какого-то сигнала или набора сигналов.

Рис. 6 Характеристика есть/быть
Рис.6 показывает, что существует разница между ассоциативной связью между объектами Образ1 и Образ2 и связью через понятие Есть. В первом случае при восприятии одного образа в системе «всплывает» второй образ, а во втором случае возникает знание об объекте.
Ассоциативные связи могут приводить к появлению бессмысленных и не связанных образов и быть в общем случае случайными, а вот образы, связанные через понятия-характеристики, уже несут смысл, так как содержат в себе определенную проверку и сообщают нам о положительном результате этой проверки. Отсюда возникают понятие об истине и лжи, а также логика, как набор правил работы с понятиями-характеристиками, позволяющий из одних истинных понятий порождать другие, которые также будут истинными.
Внешнее представление понятий-характеристик осуществляется действием-представлением, которое конструирует внешнюю форму объединяя представления самой характеристики, объекта и результата. На Рис.6 оно показано внутри понятия-характеристики Есть.
Итак, мы увидели, что определенное действие лежит в основе следующих понятий:
- Характеристика (действие проверки)
- Отношение (действие проверки)
- Объект (набор характеристик)
Если сюда добавить понятия, представляющие собственно действия или процессы, и связанные с ними понятия (например, сомнение, вероятность и др.), то представляется, что все знание можно описать такими структурами, основанными на действиях, и связями между ними.
Таким образом становится ясно, что ключевым вопросом становится вопрос об управлении действиями, то есть о том, какое действие выполняется в данный момент времени и какое будет выполняться следующим. Рассмотрим это в следующем разделе.
2.6. Управление действиями
2.6.1. Рецепторы действий
В начале мы упоминали что выполняемые действия ощущаются, а значит у действий присутствуют определенные рецепторы. Представляется что система должна уметь различать следующие ситуации:
- Действие в процессе выполнения
- Действие только что завершилось успешно
- Действие только что завершилось неуспешно
То есть внутренняя структура действия должна включать рецепторы этих ситуаций. Наличие рецепторов действия позволяет корректно трактовать сигналы с обычных рецепторов (визуальных, слуховых и т.д.). Например, становится возможным различать ситуацию, когда мы реально видим какой-то объект и когда только представляем его.

Рис. 7 Уточнение образов рецепторами действий
В предыдущих разделах мы говорили и обозначали на рисунках связи между различными элементами. Эти связи передавали сигнал активности от одного элемента к другому. Например, определенный набор связей от рецепторов может формировать некоторый детектор. Связь от детектора может идти к более сложному детектору, или к эффектору, вызывая какое-либо действие. В целом всю активность системы можно представить, как выбор определенных действий в зависимости от различных сигналов на рецепторах.
Рассмотрим возможные варианты активации определенного действия, изображенные на Рис.8.
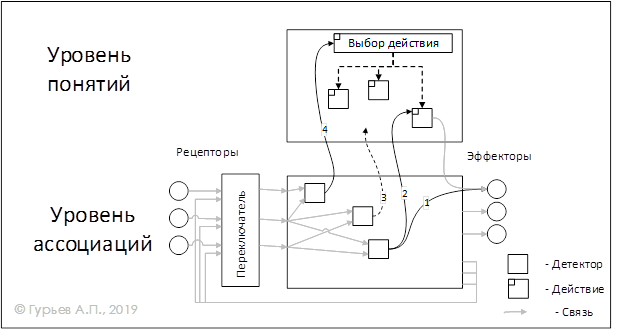
Рис. 8 Варианты выполнения действий
Вариант 1. В системе может сформироваться связь между детектором и непосредственно эффектором или группой эффекторов (на Рис.8 обозначена цифрой 1). В этом случае, при возникновении определенной ситуации будет срабатывать определенный эффектор. Так образуется то, что называется рефлексами.
Вариант 2. Связь от детектора идет не непосредственно к эффекторам, а к специальной структуре, действию (на Рис.8 обозначена цифрой 2). Чтобы действие выполнилось и послало сигнал к соответствующему эффектору нужно разрешение от специального действия, обозначенного на рисунке действием «Выбор действия». То есть, связь 2 не запускает выполнение действия, а только как-бы подсказывает действию «Выбор действия» что делать. Действие «Выбор действия» работает автоматически. Действию «Выбор действия» в этом случае не нужно искать что делать, ему просто надо согласиться с предложенным выбором. Так возникают автоматизмы, когда вследствие опыта или обучения, система привыкает в определенной ситуации выполнять определенные действия. При этом остается возможность изменить поведение, так как действие «Выбор действия» может не согласиться с предложенным вариантом и несмотря на активность связи 2 выбрать другое действие к выполнению.
Вариант 3. В этом случае нет связи от активных детекторов к какому-либо действию, либо предложенные связи (типа 2) не устроили действие «Выбор действия». В этом случае выполняется сложная логика по выбору действия для выполнения (система «думает»). На процесс выбора действия могут влиять внешние сигналы (показаны на Рис.8 связью 4). Таким образом, например, выполнение действий может прерываться при появлении новых сигналов. Подобное поведение известно в нейрофизиологии как ориентировочный рефлекс – переключение внимания на новый раздражитель.
2.6.2. Процесс выбора действия
В данном разделе опишем процесс происходящий в рамках действия «Выбор действия» на Рис.8. Это действие автоматически выполняется если не возникло рефлекторных активностей (тип 1 предыдущего раздела).
В процессе жизни системы, алгоритм заложенный в это действие может изменяться, совершенствоваться. Но представляется, что он должен обладать как минимумом следующими свойствами:
- Выбор следующего действия не должен быть случайным, а должен быть целенаправленным;
- Выполненное действия должно получать оценку – успех/неуспех. Неуспех действия должен учитываться при следующем выборе;
- При выборе действия должны учитываться подсказывающие сигналы с уровня ассоциаций (связи типа 2 предыдущего раздела).
Для реализации первого свойства в системе должна иметься информация, во-первых, о целях, потребностях системы в данный момент времени, во-вторых об ожидаемых результатах каждого известного системе действия, и в-третьих об условиях успешного выполнения действия.
Большим плюсом предлагаемого подхода является то, что все три типа информации (цели, ожидаемые результаты действия и необходимые условия для действия) могут быть представлены одной сущностью – понятием-характеристикой, описанной в разделе 2.5.1. Например, характеристика «что-то рядом» может присутствовать в ожидаемых результатах действия «Подойти к чему-то», в необходимых условиях действия «Взять что-то», а также быть целью в какой-то момент времени.
Покажем эти элементы на Рис.9.

Рис. 9 Выбор действий
В системе присутствует перечень целей, состоящий из указателей на понятия-характеристики (также хранится и значимость данной цели). С данным списком, а также со списком действий с активными ассоциативными связями («подсказки», связи типа 2) и работает действие «Выбор действия». Также каждое известное системе действие включает два списка указателей – один на обязательные условия для выполнения действия, а другой на характеристики результата. Основываясь на этой информации алгоритм действия «Выбор действия» и определяет какое действие выбрать, при необходимости конструируя новое составное действие из отдельных известных действий.
В целом мы видим, как понятие действия, которое берет начало от элементарного эффектора, обрастает вспомогательными структурами (рецепторами, понятиями-характеристиками). Эти структуры формируют некую модель действия, которая позволяет оценивать результат действия до реального выполнения, что дает возможность планировать действия для достижения необходимого результата.
Помимо целенаправленного поведения, необходима реакция на не успешную попытку выполнить действие. Под неуспехом понимаем неспособность завершить (или даже начать) действие в принципе, например, вследствие отсутствия необходимых условий (попытка пить при отсутствии воды или попытка взять что-то очень тяжелое).
О наличие такой ситуации сообщает рецептор не успешности действия (раздел 2.6.1). В этом случае, перед тем как искать следующее для выполнения действие, необходимо провести анализ причины неуспеха предыдущего действия. Этот анализ включает сравнение ситуации перед выполнением действия с прошлыми ситуациями, когда выполнение было успешным, выделение отличий (в виде понятий-характеристик) и корректировку моделей известных действий (например, добавление необходимых условий).
2.6.3. Формирование перечня целей
Рассмотрим процесс формирования перечня целей. Как уже упоминалось, это список желаемых в данный момент времени характеристик вместе с их значимостью. Этот список динамический – элементы могут добавляться и удаляться в результате выполнения действий и достижения цели. Добавление данных в него возможно автоматически («бессознательно») от сигналов определенных рецепторов, активирующих эффекторы, которые и добавляют цель в перечень. Либо добавление цели возможно целенаправленно («сознательно») путем выбора для выполнения специального действия «Добавить цель».
Удаление цели из перечня также возможно на двух уровнях – на уровне эффекторов, когда сигналы от рецепторов сигнализируют о прекращении нужды в чем-то, и на «сознательном» уровне, проверяя удовлетворение целевой характеристики после выполнения действия, призванного ее удовлетворить. Эта проверка и удаление достигнутых целей выполняется в рамках первых шагов действия «Выбор действия». Удаление цели на этом уровне может выполниться и без достижения целевой характеристики, путем выбора для выполнения специального действия «Удалить цель».
Это показано на Рис.10
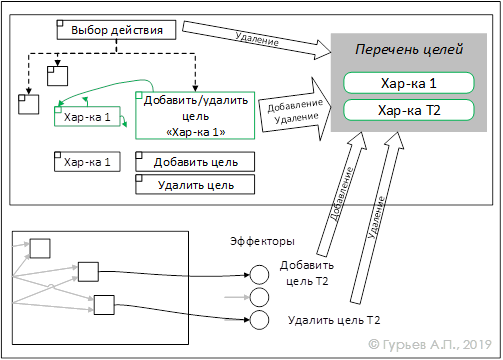
Рис. 10 Формирование перечня целей
2.6.4. Оценка последствий действия
В предыдущих разделах мы рассмотрели структуры необходимые для планирования поведения – перечень текущих целей системы и модели известных системе действий, включающие перечни необходимых для выполнения действия условий, и свойств, получаемых по результатам выполнения действия. Эти данные позволяют подбирать действия для достижения целей. Этим занимается специальное действие «Выбор действий».
Возможны ситуации, когда цель может быть достигнута в результате различных действий. Например, чтобы утолить голод можно съесть имеющуюся на кухне еду, можно купить еду в магазине, можно отобрать еду у кого-то, можно ее украсть где-то. Допустим, что все эти действия теоретически возможны (в холодильнике имеется еда, магазин расположен недалеко и имеются деньги, а по улице идет человек и несет покупки). В этом случае системе надо выбрать из четырех равно возможных действий. Нужен какой-то механизм для оценки предпочтительности возможных действий. Для каждого действия он должен учитывать конкретную текущую ситуацию и выдавать некую оценку на шкале от плохо до хорошо. Чтобы воспринять эту оценку, необходимы рецепторы. А выполнение оценки может выполняться в виде специального действия, входящего в состав модели действия и активирующего, в зависимости от состояния других рецепторов, рецепторы оценки.
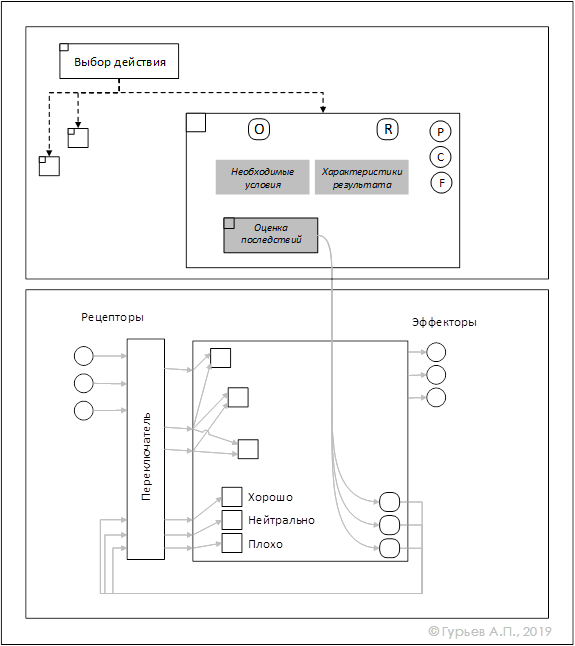
Рис. 11 Оценка последствий
На Рис.11 выполнение действия «Оценка последствий» выполняется действием «Выбор действия» на этапе выбора из теоретически возможных действий. Эти возможные действия сравниваются по значениям рецепторов плохо-хорошо.
Действие «Оценка последствий» не является статичным, формируется и модифицируется в процессе обучения и реальных действий.
Рецепторы оценки «Плохо-хорошо» могут активироваться не только при оценке последствий действий, но и в ходе выполнения действий восприятия сигналов окружающей среды. Они как бы дополняют, «эмоционально» окрашивают все другие сигналы. Как и на базе других сигналов, на их основе могут быть образовываться понятия-характеристики (п.2.5.1) – «Хороший», «Плохой», которые могут включаться в модель действий и учитываться на этапе выбора действий.
2.6.5. Возможный алгоритм выбора действия
Ранее мы упоминали разные функции выполняемые в рамках действия «Выбор действия». Попробуем объединить их в рамках одной блок-схемы. Приведенный на Рис.12 алгоритм не является единственно возможным и не отражает всех особенностей, а служит исключительно для систематизации и осмысления выполняемых функций.
Среди функций этого алгоритма есть функция, которую мы не обсуждали ранее – это так называемое углубление целей, когда перечень целей дополняется новыми целями, создаваемыми на базе необходимых условий из модели некоторого действия. Например, при наличии цели «Отсутствие голода», из модели действия «Съесть еду» (в необходимых условиях которого присутствует понятие-характеристика «Еда рядом») будет добавлена цель «Еда рядом», а для ее выполнения создано действие «Подойти к еде».

Рис. 12 Возможный алгоритм выбора действий
3. Заключение
Итак, в данной статье дана попытка описать концепцию представления и обработки информации, которую я назвал — «Динамическая семантическая сеть, основанная на действиях».
Семантическая сеть – потому что знания представляются в виде связей понятий и образов. Динамическая – так как действия-восприятия порождают временные образы и понятия, с которыми и ведется работа. Основанная на действиях – так как, в основе понятия лежит действие, вокруг которого формируются все более сложные структуры, приводящие к усложнению поведения системы.
За основу при ее разработке брались известные факты о работе нервной системы человека, но, учитывая ограниченность знаний в этой области, в значительной степени данная концепция является гипотезой и требует проверки путем создания прототипов систем для обработки разного типа информации – текстовой, визуальной и пр.
В случае верности изложенных в статье идей, системы на ее основе будут обладать следующими свойствами:
- Понимание смысла воспринятой информации – смысл заключен в стоящих за образами действиях;
- Выполняемые действия могут быть объяснены – в системе есть перечень целей, а выполняемые действия выбираются на основе модели действия, содержащей условия и ожидаемые результаты;
- Способность планирования цепочек действий – наличие модели действия позволяет строить цепочки действий с определенным ожидаемым результатом;
- Способность к обучению на собственном опыте – наличие рецепторов действий позволяет «ощущать» выполняемые действия, оценивать их результат, корректировать модели действий при несовпадении ожиданий и реальности.
Многие вопросы не были освещены в рамках этой статьи, например, понятие времени и представление последовательностей действий, анализ собственных действий (рефлексия), особенности обработки визуальной информации и другие. Возможно в следующих статьях я попытаюсь дать соображения по этим вопросам.

