Примечание переводчика: в текущий момент я подготавливаю материалы для обещанной статьи по монадам. К сожалению, это занимает довольно много времени, не говоря о том, что я всё же должен заниматься основной работой и уделять время семье, но процесс идёт. А пока представляю вам перевод небольшой свежей заметки от замечательного товарища Mark Seemann'а, которая мне показалась любопытной.
Я часто становлюсь участником длительных и жарких дебатов на тему статической типизации против динамической. Сам я определенно отношу себя к сторонникам статической типизации, но эта статья не о достоинствах статической типизации. Цель статьи — устранить распространённое заблуждение насчет статически типизированных языков.
Церемонность
Люди, которые предпочитают динамически типизированные языки статически типизированным, часто подчеркивают тот факт, что отсутствие церемонности делает их продуктивнее. Это звучит логично, однако, это ложная дихотомия.
Церемония — это то, что вы делаете до того, как начнете делать то, что вы действительно собирались сделать.
Venkat Subramaniam
Динамически типизированные языки производят такое впечатление, что им не требуются особые церемонии, но отсюда нельзя сделать вывод что статически типизированные языки их требуют. К сожалению, все мейнстримные статически типизированные языки относятся к одной и той же семье, и они требуют церемонности. Я думаю, что люди экстраполируют то, что они о них знают, ложно заключая что все статически типизированные языки обязательно идут в комплекте с оверхедом церемонности.
Это привело меня к мысли о том, что существует злосчастная Зона Церемонности:
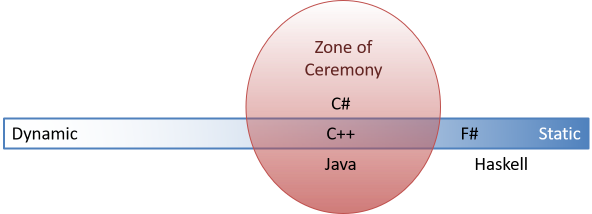
Конечно же, эта диаграмма всего лишь упрощение, но я надеюсь, что она демонстрирует суть. C++, Java и C♯ — языки, которые требуют церемонности. Справа от них находятся языки, которые мы могли бы назвать транс-церемониальными, включая F♯ и Haskell.
Ниже я покажу код на различных языках. Мы рассмотрим церемонность согласно определению выше, обращая внимание на количество подготовительной работы, которую надо сделать, как то: создание новых файлов, объявления классов, объявления типов и так далее. Код, который не имеет отношения к обсуждаемой теме я оставил серым, чтобы подчеркнуть то, что я хочу донести.
Малое количество церемоний в JavaScript
Допустим, у нас есть список чисел, и еще одно некоторое число. Это число показывает, сколько элементов из списка должно быть удалено. Необходимо удалять элементы слева до тех пор, пока сумма удаленных чисел не будет больше этого числа. Результатом будет остаток списка.
> consume ([1,2,3], 1); [ 2, 3 ] > consume ([1,2,3], 2); [ 3 ] > consume ([1,2,3], 3); [ 3 ] > consume ([1,2,3], 4); []
В первом случае мы удалили только первый элемент, тогда как во втором и третьем мы удалили и 1, и 2, потому что сумма этих значений 3, а запрошенный quantity был 2 и 3 соответственно. В четвертом примере мы удалили все элементы, потому что запрошенный quantity был равен 4, и нам нужно просуммировать все числа, чтобы сумма стала достаточно большой. Функция должна работать строго слева направо, поэтому мы не можем взять только 1 и 3.
В JavaScript эта функция могла бы быть реализована примерно так:
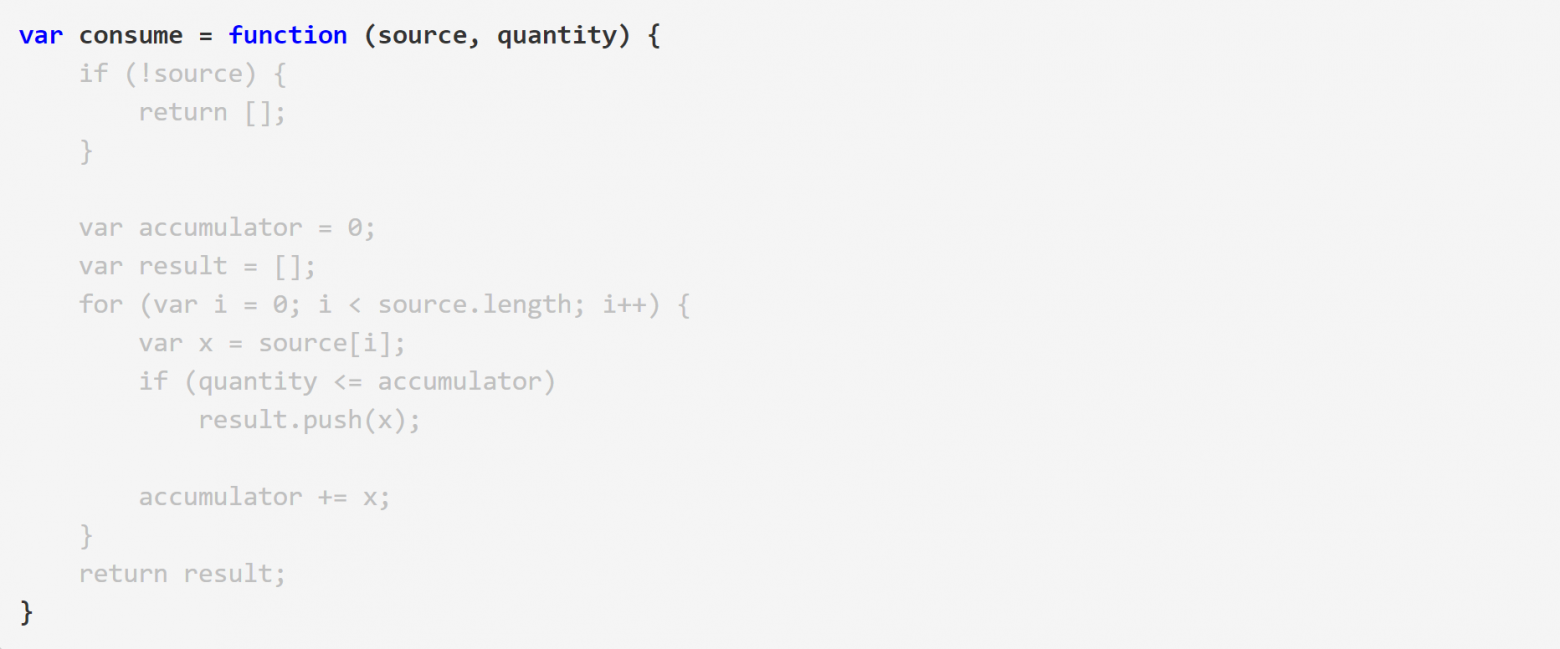
Я ужасный JavaScript-разработчик, так что я уверен, что эту функцию можно было написать более элегантно, но насколько я могу судить, она делает своё дело. Я написал 17 тестов, и все они прошли. Смысл не в том, как вы напишете эту функцию, а в том, сколько церемоний для этого требуется. В JavaScript вам не требуется объявлять никаких типов. Просто напишите имя функции, её аргументы, и вы готовы к тому, чтобы писать тело.
Большое количество церемоний в C♯
Давайте сравним пример на JavaScript с кодом на C♯. Та же самая функция на C♯ могла бы выглядеть так:

Тут нам нужно объявить тип каждого аргумента, равно как и результирующий тип метода. Также вы должны поместить этот метод в класс. На первый взгляд это не кажется серьезным оверхедом, но, если вам в дальнейшем понадобится поменять типы, то их изменение может затронуть зависящий от них код, поэтому простая правка протекает через весь код.
Но на самом деле всё еще хуже. Код выше работает только с int массивами. А что, если мы хотим использовать long?
Нам придется написать еще одну перегрузку:
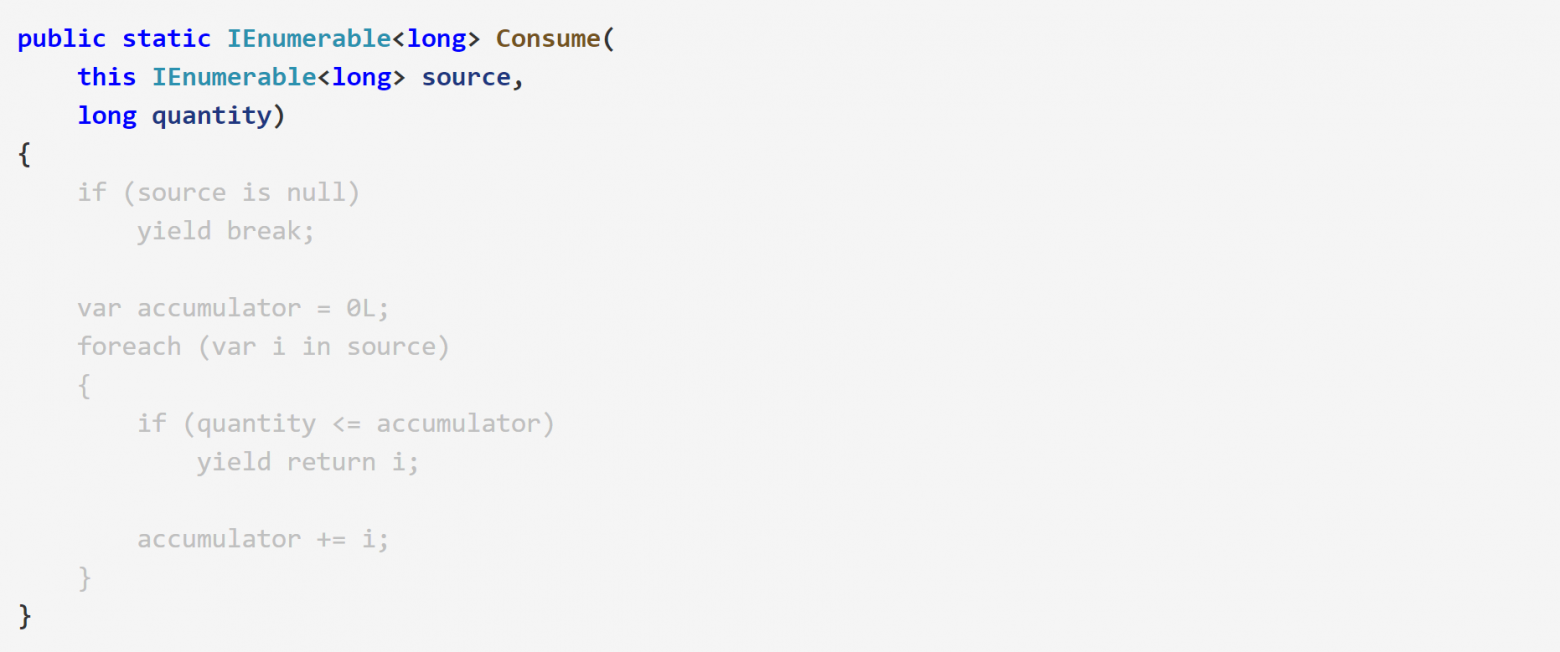
Вам нужна поддержка shortов? Еще одна перегрузка. decimal? Еще одна. byte? Еще одна.
Неудивительно, что сторонникам динамической типизации это кажется неудобным.
Малое количество церемоний в F♯
Ту же самую функцию в F♯ можно написать так:

На первый взгляд здесь нет никаких типов, но тем не менее функция статически типизирована. Правда, у неё достаточно сложный тип:
quantity: ^a -> (seq< ^b> -> seq< ^b>) when ( ^a or ^b) : (static member ( + ) : ^a * ^b -> ^a) and ^a : (static member get_Zero : -> ^a) and ^a : comparison
Хотя это выглядит довольно страшно, на самом деле сигнатура говорит о том, что функция поддерживает последовательности любых чисел, у которых есть ноль, и которые можно складывать и сравнивать. Вы можете её вызывать с целыми числами разной битности, decimalами, и так далее:
> consume 2 [1;2;3];; val it : seq<int> = seq [3] > consume 2m [1m;2m;3m];; val it : seq<decimal> = seq [3M]
Статическая типизация означает только то, что вы не можете вызвать её с произвольными значениями. Выражение вроде consume "foo" [true;false;true] просто не скомпилируется.
Вы можете объявлять типы явно в F♯ (так же, как вы делаете это в C♯), но по моему опыту обычно этого делать не надо: типы склонны протекать через вашу кодовую базу. Измените тип функции, и вызывающий код как правило сам "поймет что к чему". Если вы подумаете о функциях, вызывающих друг друга, как о графе, то зачастую вы можете просто поправить листовые узлы, даже если вы поменяли типы где-то в глубине кодовой базы.
Малое количество церемоний в Haskell
Аналогично вы можете написать эту функцию в Haskell:

И снова вам не нужно указывать никаких типов. Компилятор просто их выведет. Вы даже можете спросить у GHCi о типе функции, и он вам выдаст:
> :t consume consume :: (Foldable t, Ord a, Num a) => a -> t a -> [a]
Оно выглядит чуть более компактно чем выведенный в F♯ тип, но суть остается той же. Оно скомпилируется для любого Foldable контейнера (В том числе и об этом в следующей статье, прим. пер), и для любого типа, принадлежащему тайпклассам Ord и Num. Num поддерживает сложение, а Ord — сравнение.
Как вы можете видеть, в F♯ и Haskell требуется довольно мало церемоний, однако оба языка остаются статически типизированными. Более того, их система типов мощнее, чем у C♯ или Java. Они могут выражать такие взаимоотношения между типами, которые эти языки не могут.
Резюмируя
В спорах о статической типизации против динамической, участники обычно обобщают их опыт с C++, Java или C♯. Им не нравится количество церемоний, требуемое в этих языках, но они ложно считают, что отсюда следует, что не бывает статически типизированных языков без церемоний.
Но дело лишь в том, что мейнстримные статически типизированные языки просто занимают Зону Церемонности.
Статическая типизация без церемоний существует, как было показано на примерах F♯ и Haskell. Вы можете называть эти языки транс-церемониальными. Они предлагают лучшее из двух миров: проверки времени компиляции и небольшое количество церемоний.

