Два года назад я начал разработку еще одного свободного кодогенератора из OpenAPI Specification v3 в TypeScript (он доступен на Github). Изначально, я задался целью сделать эффективную генерацию примитивных и сложных типов данных в TypeScript, с учетом различных возможностей JSON Schema, таких как oneOf/anyOf/allOf и т.п. (у родного решения от Swagger с этим были некоторые проблемы). Другая идея заключалась в том, чтобы использовать схемы из спецификаций для валидации на фронте, бэке и в других частях системы.

Сейчас кодогенератор относительно готов — он находится на стадии MVP. В нем есть многое из того, что нужно в плане генерации типов данных, а также экспериментальная библиотека для генерации фронтенд-сервисов (пока что для Angular). В этой статье я хочу показать наработки и рассказать как они могут помочь, если вы используете TypeScript и OpenAPI v3. Попутно, я хочу поделиться некоторыми идеями и соображениями, возникшими у меня в процессе работы. Ну и если вам интересно, можете почитать и предысторию, которую я скрыл в спойлер, чтобы не осложнять чтение технической части.
Содержание
- Предыстория
- Описание
- Установка и использование
- Практика использование кодогенератора
- Использование генерируемых типов данных в приложениях
- Декомпозиция схем внутри OAS-спецификации
- Вложенная декомпозиция
- Автогенерация сервисов для работы с REST API
- Вместо послесловия
Предыстория
Все началось два года назад — тогда я работал в компании, разрабатывающей Data Mining платформу и отвечал за фронтенд (в основном, TypeScript + Angular). Особенностями проекта были сложные структуры данных с большим количеством параметров (30 и более) и не всегда очевидные бизнес-связи между ними. Компания росла, и программная конъюнктура переживала довольно частые изменения. Фронтенд должен был быть хорошо осведомлен в нюансах, потому что некоторые расчеты дублировались на фронте и на бэкенде. То есть, это был тот случай, когда использование OpenAPI более чем уместно. Я застал в компании период, когда за считанные месяцы команда разработки обрела единую спецификацию, ставшую общей базой знаний для бэка, фронта и даже Core-отдела, который скрывался за широкой спиной веб-бэкенда. Версия OpenAPI была выбрана “на вырост” — тогда еще совсем молодая v3.0
Это была уже не спецификация в одном или нескольких статичных YML/JSON-файлах, и не результат работы аннотаторов, а целая библиотека компонент, методов, шаблонов и свойств, организованная в соответствии с DDD-концепцией платформы. Библиотека была разбита по директориям и файлам, а специально устроенный сборщик выдавал OAS-документы для каждой предметной области. Экспериментальным путем был выстроен work flow, который можно было охарактеризовать как Design-First.
В блоге компании Яндекс.Деньги есть неплохая статья, в которой рассказывали про Design First
Design First и общая спецификация помогли десакрализировать знания, но стала очевидна новая проблема — поддержка актуальности кода. В спецификации были описаны несколько десятков методов и десятки (а позже — сотни) сущностей. Но код предстояло писать вручную: типы данных, сервисы для работы с REST и т.д. Один-два спринта с параллельными историями сильно меняли картину; добавьте сложности при мерже нескольких историй и человеческий фактор. Рутина грозила быть значительной, и выход казался очевидным — нужна кодогенерация. Ведь в OAS-спецификациях уже содержалось все необходимое, чтобы не перепечатывать это вручную. Но все было не так просто.
Фронтенд находится в самом конце производственного цикла, поэтому ощущал болезненность изменений больше, чем коллеги из других отделов. При проектировании REST API решала конъюнктура бэкенда, и даже после утверждения “Design First” оставалась инерция; для фронтенда все выглядело менее очевидным. На самом деле, я понимал это с самого начала, и начал прощупывать почву заранее — когда разговоры о “всеобщей” спецификации только начинались. Речи о написании собственного кодогенератора не шло; я хотел просто найти что-то готовое.
Меня ждало разочарование. Было две проблемы: OAS версии 3.0, с поддержкой которой, казалось, никто особо не спешил, и качество самих решений — на тот момент (напомню, это было два года назад), мне удалось найти два относительно готовых решения: от Swagger и от Microsoft (кажется, это). В первом поддержка OAS 3.0 была в глубокой бете. Второе работало только с версией 2.x, а однозначных прогнозов не было. К слову, запустить кодогенератор от Microsoft мне так и не удалось даже на тестовом документе формата Swagger 2.0. Решение от Swagger заработало, но более-менее сложная схема с $ref-ссылками превращалась в непонятное “ERROR!”, а рекурсивные зависимости отправляли его в бесконечный цикл. Были и проблемы с примитивными типами. Вдобавок, я не совсем понимал, как мне работать с авто-генерируемыми сервисами — казалось, они сделаны для галочки, а их реальное использование создавало больше проблем, чем решало (на мой взгляд). Ну и наконец, интеграция JAR-файла в NPM-ориентированный CI/CD была неудобной: приходилось руками скачивать нужный снапшот, который весил, кажется, 13 мегабайт, и что-то с ним делать. В общем, я взял паузу и решил понаблюдать что будет дальше.
Примерно через пять месяцев вопрос кодогенерации возник снова. Предстояло переписать и расширить часть Веб-приложения, и я хотел заодно отрефакторить старые сервисы для работы с REST API и типы данных. Но оценка трудоемкости не была оптимистичной: от человеко-недели до двух — и это только на REST-сервисы и описания типов. Не скажу, что это сильно меня угнетало, но все же. С другой стороны, решения для кодогенерации я так и не нашел и не дождался, а его реализация едва заняла бы меньше времени. То есть, об этом не могло идти речи: польза сомнительна, риски велики. Никто не поддержал бы эту идею, да я и не предлагал. Тем временем, приближались майские праздники, а компания “задолжала” мне несколько дней за отработку в выходные. На две недели я сбежал от всех рабочих переживаний в Грузию, в которой когда-то прожил почти год.
В перерывах между тусовками и застольями мне нужно было чем-то заниматься, и я решил написать свое решение. Работа в летних кафешках возле парка Ваке была на удивление продуктивна, и в Питер я вернулся с готовым кодогенератором типов данных. Затем еще месяц я “допиливал” сервисы по выходным, прежде чем он был готов к работе.
С самого начала, я сделал кодогенератор открытым, работая над ним в свободное время. Хотя, по-сути, писал под рабочий проект. Я не скажу, что доработка/обкатка прошли совсем без проблем; и не скажу что они были значимыми. Но в какой-то момент я обратил внимание, что перестал пользоваться Redoc/Swagger документацией: навигация по коду оказалась удобнее, при условии, что код всегда актуален и прокомментирован. Вскоре я “забил” на свои наработки, никак не развивая их, пока коллега (теперь уже бывший — полгода назад я ушел в другую компанию) не посоветовал заняться ими серьезней (он же и придумал название).
Свободного времени не хватало, и несколько месяцев у меня ушло на доработку в фоновом режиме: playground, тестовое приложение, реорганизация проекта. Сейчас я готов получить обратную связь.
Описание
На данный момент, решение для кодогенерации включает в себя три NPM-библиотеки, объединенные в скопе @codegena и находящиеся в общем моно-репозитории:
| Библиотека | Описание |
|---|---|
| @codegena/oapi3ts | Базовая библиотека — конвертор из OAS3 в описания типов данных (сейчас поддерживает только TypeScript) |
| @codegena/ng-api-service | Расширение для Angular-сервисов |
| @codegena/oapi3ts-cli | Оболочка для удобного использования в CLI-скриптах |
Установка и использование
Самый практичный вариант — использование в NodeJS-скриптах, запускаемых из CLI. Для начала нужно установить зависимости:
npm i @codegena/oapi3ts, @codegena/ng-api-service, @codegena/oapi3ts-cli
Затем, создать js-файл (например, update-typings.js) с кодом:
"use strict"; var cliLib = require('@codegena/oapi3ts-cli'); var cliApp = new cliLib.CliApplication; cliApp.createTypings(); // cliApp.createServices('angular'); // optional
И запустить его, передав три параметра:
node ./update-typings.js --srcPath ./specs/todo-app-spec.json --destPath ./src/lib --separatedFiles true
В destPath будут сгенерированные файлы и, собственно, содержимое вот этой директории в репозитории проекта создано таким же способом. Вот генерирующий скрипт, и вот так он запускается в NPM-скриптах. Впрочем, при желании вы можете использовать его даже в браузере, как это сделано в Playground.
Практика использование кодогенератора
Далее я хочу рассказать о том, что мы получим в результате: в чем идея, как это поможет нам. Наглядным пособием будет код демо-приложения. Оно состоит из двух частей: бэкенд (на фреймворке NestJS) и фронтенд (на Angular). При желании, вы даже можете запустить его локально.
Даже если вы не знакомы с Angular и/или NestJS, это не должно создать проблем: примеры кода, которые будут приведены, должны быть понятны большинству TypeScript-разработчиков.
Хотя приложение максимально упрощено (например, бэкенд хранит данные в сессии, а не в БД), я постарался воссоздать в нем data flow и особенности иерархии типов данных, которые присущи реальному приложения. Оно готово примерно на 80-85%, но “допиливание” может затянуться, а пока важнее рассказать о том, что уже есть.
Использование генерируемых типов данных в приложениях
Допустим, у нас есть OpenAPI-спецификация (например, вот эта), с которой предстоит работать. Неважно, создаем мы что-либо с нуля, либо занимаемся поддержкой, есть важная вещь, с которой мы скорее всего начнем — типизация. Мы либо начнем описывать основные типы данных, либо вносить в них изменения. Большинство программистов делают это для того, чтобы облегчить себе дальнейшую разработку. Так не придется лишний раз заглядывать в документацию, держать в голове перечисления параметров; и можно быть уверенными, что IDE и/или компилятор заметят опечатку.
В нашей спецификации может быть или отсутствовать раздел components.schemаs. Но в любом случае, в ней будут описаны наборы параметров, запросы и ответы — и мы можем пользоваться этим. Рассмотрим пример:
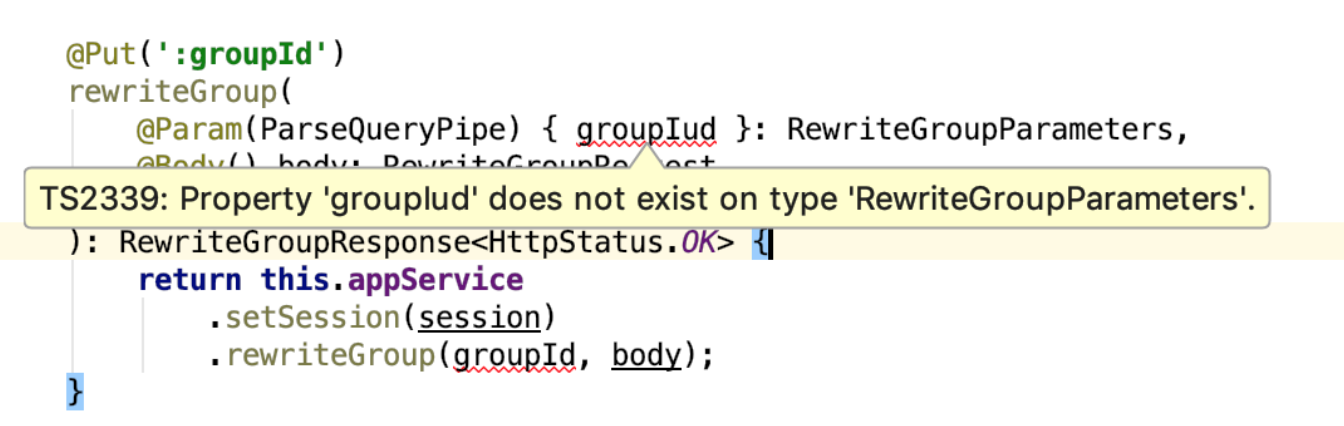
@Controller('group') export class AppController { // ... @Put(':groupId') rewriteGroup( @Param(ParseQueryPipe) { groupId }: RewriteGroupParameters, @Body() body: RewriteGroupRequest, @Session() session ): RewriteGroupResponse<HttpStatus.OK> { return this.appService .setSession(session) .rewriteGroup(groupId, body); } // ... }
Это фрагмент контроллера для фреймворка NestJS, у которого типизированы параметры (RewriteGroupParameters), тело запроса (RewriteGroupRequest) и тело ответа (RewriteGroupResponse<T>). Уже в этом фрагменте кода мы можем усмотреть пользу типизации:
- Если мы перепутаем имя деструктуризованного параметра
groupId, указав вместо негоgroupUid, то сразу получим ошибку в редакторе.
- Если метод this.appService.rewriteGroup(groupId, body) имеет типизированные параметры, мы можем контролировать корректность передаваемого параметра
body. И если изменится формат входящих данных у метода контроллера или у метода сервиса, мы сразу узнаем об этом. Забегая вперед, отмечу, что у метода сервиса входной параметр имеет тип данных, отличный отRewriteGroupRequest, но в нашем случае, они будут тождественны друг другу. Однако, если вдруг метод сервиса будет изменен, и начнет приниматьToDoGroupвместоToDoGroupBlank, IDE и компилятор сразу покажут места расхождений:

- Точно также, мы можем контролировать и соответствие возвращаемого результата. Если вдруг в спецификации поменяется статус успешного ответа, и станет
202вместо200, мы также узнаем об этом, потому чтоRewriteGroupResponse— это дженерик с перечисляемым типом:

Теперь давайте рассмотрим пример из фронтенд-приложения, работающий с другим API-методом:
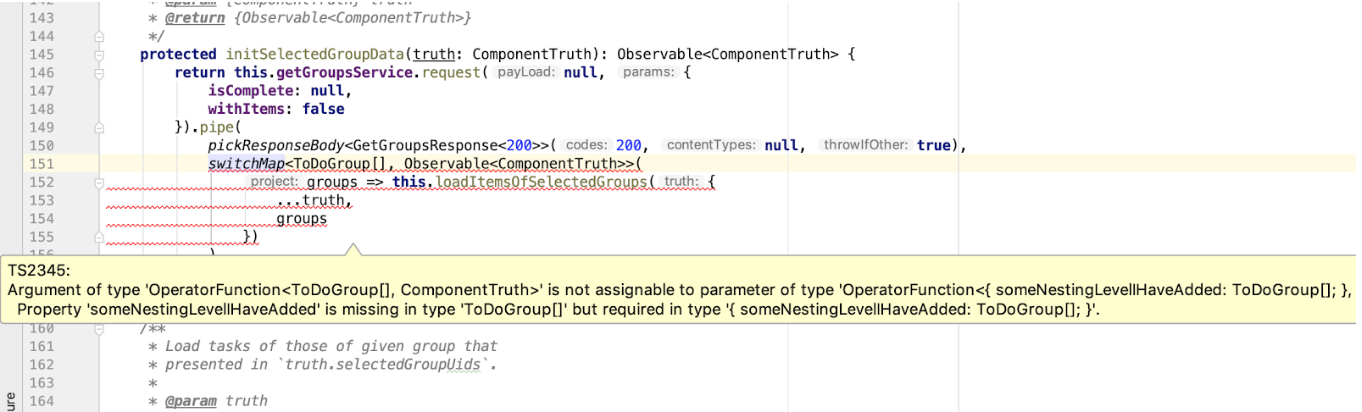
protected initSelectedGroupData(truth: ComponentTruth): Observable<ComponentTruth> { return this.getGroupsService.request(null, { isComplete: null, withItems: false }).pipe( pickResponseBody<GetGroupsResponse<200>>(200, null, true), switchMap<ToDoGroup[], Observable<ComponentTruth>>( groups => this.loadItemsOfSelectedGroups({ ...truth, groups }) ) ); }
Не будем забегать вперед и разбирать кастомный RxJS-оператор pickResponseBody, а заострим внимание на уточнение типа GetGroupsResponse. Мы используем его в цепочке RxJS-операторов, и следующий за ним оператор имеет входное уточнение ToDoGroup[]. Если этот код работает, значит указанные типы данных соответствуют друг другу. Здесь мы также можем контролировать соответствие типов, и если вдруг поменяется формат ответа в нашем API — это не ускользнет от нашего внимания:
Ну и конечно, параметры вызова this.getGroupsService.request тоже типизированы. Но это уже тема генерируемых сервисов.
В приведенных выше примерах мы видим, что типизация запросов, ответов и параметров может использоваться в различных частях системы — фронтенд, бэкенд и т.д. Если бэкенд и фронтенд находятся в одном моно-репозитории и имеют совместимую эко-среду, они могут использовать одну общую библиотеку со сгенерированным кодом. Но даже если бэкенд и фронтенд поддерживаются разными командами, и не имеют ничего общего, кроме публичной OAS-спецификации, им все равно будет легче синхронизировать свой код.
Декомпозиция схем внутри OAS-спецификации
Вероятно, в предыдущих примерах вы обратили внимание на интерфейсы ToDoGroupBlank, ToDoGroup, с которыми соотносились RewriteGroupResponse и GetGroupsResponse. Собственно, RewriteGroupResponse — это всего-лишь дженерик-алиас для ToDoGroup, HttpErrorBadRequest и т.д. Нетрудно догадаться, что и ToDoGroup, и HttpErrorBadRequest — это схемы из раздела спецификации components.schemаs, на которые ссылается эндпойнт “rewriteGroup” (напрямую или через посредников):
"responses": { "200": { "description": "Todo group saved", "content": { "application/json": { "schema": { "$ref": "#/components/schemas/ToDoGroup" } } } }, "400": { "$ref": "#/components/responses/errorBadRequest" }, "404": { "$ref": "#/components/responses/errorGroupNotFound" }, "409": { "$ref": "#/components/responses/errorConflict" }, "500": { "$ref": "#/components/responses/errorServer" } }
Это обычная декомпозиция структур данных, и ее принцип тот же, что и в других языках программирования. Компоненты, в свою очередь, также могут быть декомпозированы: ссылаться на другие компоненты (в том числе рекурсивно), использовать комбинирование и прочие возможности JSON Schema. Но вне зависимости от сложности, они должны быть корректно превращены в описания типов данных. Я хочу показать как вы можете использовать декомпозицию в OpenAPI, и как будет выглядеть сгенерированный код.
Компоненты в хорошо спроектированной OAS-спецификации будут пересекаться с DDD-моделю использующих ее приложений. Но даже если спецификация неидеальна, вы можете опираться на нее, выстраивая собственную модель данных. Это даст вам больший контроль соответствия ваших типов данных с типами данных интегрируемых подсистем.
Поскольку наше приложение — это список задач, то основная сущность — это Задача. Логично вынести ее в компоненты в первую очередь, т.к. остальные сущности и эндпойнты будут так или иначе связаны с ней. Но перед этим нужно понимать две вещи:
- Мы описываем не только абстракцию, но и правила валидации, и чем они точнее и однозначнее — тем лучше.
- Как любая хранимая в БД сущность, Задача имеет два типа свойств: служебные и вводимые пользователем.
Получается, что в зависимости от сценария использования, мы имеем две структуры данных: Задача, которую только что создал пользователь, и Задача, которая уже хранится в базе. Во втором случае, она имеет уникальный UID, дату создания, изменения и т.д., и эти данные должны назначаться на бэкенде. Я описал две сущности (ToDoTaskBlank и ToDoTask) таким образом, что первая является подмножеством второй:
"components": { "ToDoTaskBlank": { "title": "Base part of data of item in todo's group", "description": "Data about group item needed for creation of it", "properties": { "groupUid": { "description": "An unique id of group that item belongs to", "$ref": "#/components/schemas/Uid" }, "title": { "description": "Short brief of task to be done", "type": "string", "minLength": 3, "maxLength": 64 }, "description": { "description": "Detailed description and context of the task. Allowed using of Common Markdown.", "type": ["string", "null"], "minLength": 10, "maxLength": 1024 }, "isDone": { "description": "Status of task: is done or not", "type": "boolean", "default": "false", "example": false }, "position": { "description": "Position of a task in group. Allows to track changing of state of a concrete item, including changing od position.", "type": "number", "min": 0, "max": 4096, "example": 0 }, "attachments": { "type": "array", "description": "Any material attached to the task: may be screenshots, photos, pdf- or doc- documents on something else", "items": { "$ref": "#/components/schemas/AttachmentMeta" }, "maxItems": 16, "example": [] } }, "required": [ "isDone", "title" ], "example": { "isDone": false, "title": "Book soccer field", "description": "The complainant agreed and recruited more members to play soccer." } }, "ToDoTask": { "title": "Item in todo's group", "description": "Describe data structure of an item in group of tasks", "allOf": [ { "$ref": "#/components/schemas/ToDoTaskBlank" }, { "type": "object", "properties": { "uid": { "description": "An unique id of task", "$ref": "#/components/schemas/Uid", "readOnly": true }, "dateCreated": { "description": "Date/time (ISO) when task was created", "type": "string", "format": "date-time", "readOnly": true, "example": "2019-11-17T11:20:51.555Z" }, "dateChanged": { "description": "Date/time (ISO) when task was changed last time", "type": "string", "format": "date-time", "readOnly": true, "example": "2019-11-17T11:20:51.555Z" } }, "required": [ "dateChanged", "dateCreated", "position", "uid" ] } ] } }
На выходе мы получим два TypeScript-интерфейса, и первый будет наследоваться вторым:
/** * ## Base part of data of item in todo's group * Data about group item needed for creation of it */ export interface ToDoTaskBlank { // ... imagine there are ToDoTaskBlank properties } /** * ## Item in todo's group * Describe data structure of an item in group of tasks */ export interface ToDoTask extends ToDoTaskBlank { /** * ## UID of element * An unique id of task */ readonly uid: string; /** * Date/time (ISO) when task was created */ readonly dateCreated: string; /** * Date/time (ISO) when task was changed last time */ readonly dateChanged: string; // ... imagine there are ToDoTaskBlank properties }
Теперь у нас есть базовые описания сущности Задача, и мы ссылаться на них в коде своего приложения так, как это сделано в демо-приложении:
import { ToDoTask, ToDoTaskBlank, } from '@our-npm-scope/our-generated-lib'; export interface ToDoTaskTeaser extends ToDoTask { isInvalid?: boolean; /** * Means this task just created, has temporary uid * and not saved yet. */ isJustCreated?: boolean; /** * Means this task is saving now. */ isPending?: boolean; /** * Previous uid of task temporary assigned until * it gets saved and gets new UID from backend. */ prevTempUid?: string; }
В этом примере мы описали новую сущность, добавив к ToDoTask те свойства, которых нам не хватает на стороне фронтенд-приложения. То есть, по-сути, мы расширили полученную модель данных с учетом локальной специфики. Вокруг этой модели постепенно вырастает набор локальных инструментов и что-то типа примитивного DTO:
export function downgradeTeaserToTask( taskTeaser: ToDoTaskTeaser ): ToDoTask { const task = { ...taskTeaser }; if (!task.description || !task.description.trim()) { delete task.description; } else { task.description = task.description.trim(); } delete task.isJustCreated; delete task.isPending; delete task.prevTempUid; return task; } export function downgradeTeaserToTaskBlank( taskTeaser: ToDoTaskTeaser ): ToDoTaskBlank { const task = downgradeTeaserToTask(taskTeaser) as any; delete task.dateChanged; delete task.dateCreated; delete task.uid; return task; }
export class ToDoTaskTeaser implements ToDoTask { // … imagine, definitions from ToDoTask are here constructor( task: ToDoTask, public isInvalid?: boolean, public isJustCreated?: boolean, public isPending?: boolean, public prevTempUid?: string ) { Object.assign(this, task); } downgradeTeaserToTask(): ToDoTask { const task = {...this}; if (!task.description || !task.description.trim()) { delete task.description; } else { task.description = task.description.trim(); } delete task.isJustCreated; delete task.isPending; delete task.prevTempUid; return task; } downgradeTeaserToTaskBlank(): ToDoTaskBlank { // … some code } }
Но это вопрос стиля, целесообразности и того, каким путем будет развиваться архитектура приложения. В целом же, вне зависимости от подхода, мы можем опираться на базовую модель данных и иметь больший контроль за соответствием типизации. Так, если вдруг по какой-либо причине uid у ToDoTask станет числом, мы будем знать обо всех участках кода, требующих обновления:
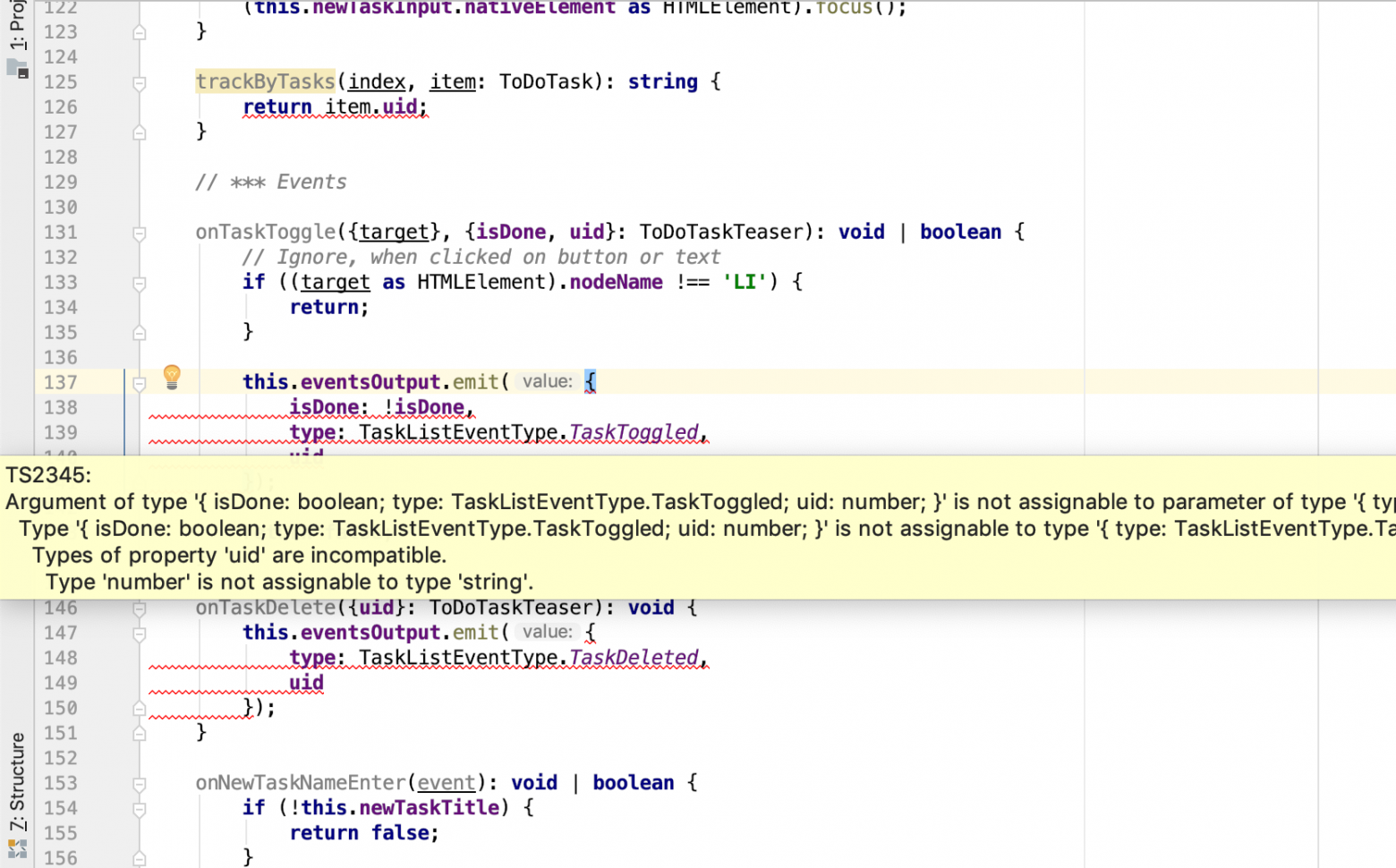
Вложенная декомпозиция
Итак, теперь у нас есть интерфейс ToDoTask, и мы можем ссылаться на него. Схожим образом мы опишем ToDoTaskGroup и ToDoTaskGroupBlank, и они будут содержать в себе свойства с типом ToDoTask и ToDoTaskBlank, соответственно. Но теперь разобьем “Группу задач” не на два, а на три компонента: для наглядности мы опишем дельту в ToDoGroupExtendedData. Так я хочу продемонстрировать подход, при котором один компонент создается из двух других:
"ToDoGroup": { "allOf": [ { "$ref": "#/components/schemas/ToDoGroupBlank" }, { "$ref": "#/components/schemas/ToDoGroupExtendedData" } ] }
После запуска генерации кода, мы получим несколько иную TypeScript-конструкцию:
export type ToDoGroup = ToDoGroupBlank & // Data needed for group creation ToDoGroupExtendedData; // Extended data has to be obtained after first save
Поскольку у ToDoGroup нет своего “тела”, кодогенератор предпочел превратить его в объединение интерфейсов. Впрочем, если добавить третью часть с собственной (анонимной) схемой, то результатом станет интерфейс с двумя предками (но лучше так не делать). И давайте обратим внимание, что свойство items интерфейса ToDoGroupBlank типизировано как массив ToDoTaskBlank, и переопределено в ToDoGroupBlank на ToDoTask. Таким образом, кодогенератор в состоянии переносить довольно сложные нюансы декомпозиции из JSON Schema в TypeScipt.
/* tslint:disable */ import { ToDoTaskBlank } from './to-do-task-blank'; /** * ## Base part of data of group * Data needed for group creation */ export interface ToDoGroupBlank { // ... items?: Array<ToDoTaskBlank>; // ... }
/* tslint:disable */ import { ToDoTask } from './to-do-task'; /** * ## Extended data of group * Extended data has to be obtained after first save */ export interface ToDoGroupExtendedData { // ... items: Array<ToDoTask>; }
Ну и разумеется, в ToDoTask / ToDoTaskBlank мы также можем использовать декомпозицию. Возможно, вы обратили внимание на то, что свойство attachments описано как массив элементов типа AttachmentMeta. И этот компонент описан следующим образом:
"AttachmentMeta": { "description": "Common meta data model of any type of attachment", "oneOf": [ {"$ref": "#/components/schemas/AttachmentMetaImage"}, {"$ref": "#/components/schemas/AttachmentMetaDocument"}, {"$ref": "#/components/schemas/ExternalResource"} ] }
То есть, этот компонент ссылается на другие компоненты. Поскольку, он не имеет собственной схемы, кодогенератор не выносит его в отдельный тип данных, чтобы не множить сущности, а превращает анонимное описание перечисляемого типа:
/** * Any material attached to the task: may be screenshots, photos, pdf- or doc- * documents on something else */ attachments?: Array< | AttachmentMetaImage // Meta data of image attached to task | AttachmentMetaDocument // Meta data of document attached to task | string // Link to any external resource >;
При этом, для компонент AttachmentMetaImage и AttachmentMetaDocument описываются неанонимные интерфейсы, которые импортируются в использующих их файлах:
import { AttachmentMetaDocument } from './attachment-meta-document'; import { AttachmentMetaImage } from './attachment-meta-image';
Но даже в AttachmentMetaImage мы можем обнаружить ссылку на еще один вынесенный интерфейс ImageOptions, который используется дважды, в том числе, внутри анонимного интерфейса (результат превращения из additionalProperties):
/* tslint:disable */ import { ImageOptions } from './image-options'; /** * Meta data of image attached to task */ export interface AttachmentMetaImage { // ... /** * Possible thumbnails of uploaded image */ thumbs?: { [key: string]: { /** * Link to any external resource */ url?: string; imageOptions?: ImageOptions; }; }; // ... imageOptions: ImageOptions; }
Таким образом базируясь на интерфейсах ToDoTask или ToDoGroup, мы на самом деле интегрируем в наш код код несколько сущностей и цепочку их бизнес-связей, что дает нам больший контроль за изменениями в над-системе, выходящими за пределы нашего кода. Разумеется, это имеет смысл далеко не во всех случаях. Но если вы используете OpenAPI, то у вас может быть еще один небольшой бонус, помимо актуальной документации.
Автогенерация сервисов для работы с REST API
Зачем это нужно?
Если мы возьмём средне-статистическое фронтенд-приложение, работающее с более-менее сложным REST API, то немаленькую часть его кода будут составлять сервисы (или просто функции) для обращения к API. Они будут включать в себя:
- Мапинги URL и параметров
- Валидацию параметров, запроса и ответа
- Извлечение данных и обработка внештатных ситуаций
Неприятно то, что во многом это носит типовой характер и не содержит никакой уникальной логики. Давайте предположим некоторый пример — как в общих чертах, может строиться работа с API:
import _ from 'lodash'; import { Observable, fromFetch, throwError } from 'rxjs'; import { switchMap } from 'rxjs/operators'; // Definitions const URLS = { 'getTasksOfGroup': `${env.REST_API_BASE_URL}/tasks/\${groupId}`, // ... other urls ... }; const URL_TEMPLATES = _.mapValues(urls, url => _.template(url)); interface GetTaskConditions { isDone?: true | false; offset?: number; limit?: number; } interface ErrorReponse { error: boolean; message?: string; } // Helpers // I taken this snippet from StackOverflow only for example function encodeData(data) { return Object.keys(data).map(function(key) { return [key, data[key]].map(encodeURIComponent).join("="); }).join("&"); } // REST API functions // our REST API working function example function getTasksFromServer(groupUid: string, conditions: GetTaskConditions = {}): Observable<Response> { if (!groupUid) { return throwError(new Error('You should specify "groupUid"!')); } if (!_.isString(groupUid)) { return throwError(new Error('`groupUid` should be string!')); } if (_.isBoolean(conditions.isDone)) { // ... applying of conditions.isDone } else if (conditions.isDone !== undefined) { return throwError(new Error('`isDone` should be "true", "false" or should\'t be set!'!)); } if (offset) { // ... check of `offset` and applying or error throwing } if (limit) { // ... check of `limit` and applying or error throwing } const url = [ URL_TEMPLATES['getTasksOfGroup']({groupUid}), ...(conditions ? [encodeData(conditions)] : []) ]; return fromFetch(url); } // Using of REST API working functions function getRemainedTasks(groupUid: number): Observable<ToDoTask[] | ErrorReponse> { return getTasksFromServer(groupUid, {isDone: false}).pipe( switchMap(response => { if (response.ok) { // OK return data return response.json(); } else { // Server is returning a status requiring the client to try something else. return of({ error: true, message: `Error ${response.status}` }); } }), catchError(err => { // Network or other error, handle appropriately console.error(err); return of({ error: true, message: err.message }) }) ); }
Вы можете использовать высокоуровневую абстракцию для работы с REST — в зависимости от используемого стека, это могут быть: Axios, Angular HttpClient, или любое другое подобное решение. Но вероятней всего, принципиально ваш код будет совпадать с этим примером. Почти наверняка, в нем будут:
- Сервисы или функции для обращения к определенным эндпойнтам (функция
getTasksFromServerв нашем примере) - Участки кода, которые обрабатывают результат (функция
getRemainedTasks)
В приложении из реального мира, этот код будет сложнее: в спецификации демо-приложения описывается по 5-6 вариантов ответа. Часто, REST API проектируется таким образом, что каждый статус ответа от сервера должен быть обработан соответствующим образом. Но даже и проверка входных данных имеет тенденцию становиться сложнее в процессе развития приложения: чем больше времени уходит на поддержку и обработку отзывов об ошибках, тем больше желание знать об узких местах циркуляции данных в приложении.
На каждом узле стыковки программных частей могут возникать ошибки, несвоевременное обнаружение которых (равно как и поиск трудно-диагностируемых проблем) может обойтись бизнесу очень дорого. Поэтому там будут возникать дополнительные уточняющие проверки. По мере роста кодовой базы, и количества покрываемых кейсов, растет и сложность внесения изменений. Но бизнес — это постоянные изменения, и от этого никуда не деться. Поэтому нам стоит озаботиться тем, как мы будем вносить изменения заранее.
Возвращаясь к теме OpenAPI, заметим, что в OAS-спецификациях может быть достаточно информации, чтобы:
- Описать все необходимые энд-пойнты в виде функций или сервисов
- Ассоциировать их с нужными типами данных
- Подставлять необходимые URL и включать в них параметры
- Производить валидацию перед отправкой и при получении данных
Есть еще один аспект использования кодогенерации для сервисов — централизация. Я говорю о том, что вне зависимости от того, сколько у нас функций / сервисов — 5, 10 или 200, мы можем менять их в один момент и проектировать по одной схеме. А значит, мы можем упростить работу с ними, создав универсальные хелперы: такие, как, например, RxJS-оператор pickResponseBody, который позволяет экономить нам по несколько строк одинаковых проверок в каждом месте, где делаем запрос к автоматически-сгенерированному сервису; или tapResponse, который декларативно определяет side-effect (tap) для разных HTTP-статусов. Это не такое большое упрощение, если мы говорим об одно-двух местах в коде. Но если их сотни, и речь идет об удобстве внесения изменений, польза будет более ощутима.
Возможно, это покажется сомнительным достижением — сделать некоторую функцию-хэлпер, которая позволит сэкономить несколько строк кода. В реальной разработке часто оказывается так, что столь скромное нововведение стоит гораздо дороже, чем кажется, потому что "парк" сервисов / функций для обращения к API представлен разношерстной ордой из "исторически-сложившихся" и "временных" решений. Прежде чем ввести что-то одно и общее, нужно найти и отрефакторить всех потребителей этого "общего" (и связанных с ними мест), что часто оказывается очень затратно.
В качестве эксперимента, я решил проработать схему кодогенерации сервисов для работы с REST API в экосреде Angular. Если бы эта модель оказалась жизнеспособной и вызвала интерес, можно было бы заняться дальнейшим улучшением, и задуматься о генерации сервисов для других фреймворков/экосистем. Но пока что эти мысли преждевременны. Далее, я хочу вкратце рассказать о том, что у меня получилось. К сожалению, я не смогу рассказать всех нюансов, т.к. статья уже итак получилась очень большой.
Генерация сервисов
В разделе "Установка и использование" я рассказывал как генерировать типы данных. Чтобы сгенерировать Angular-сервисы, достаточно добавить одну строчку к нашему update-typings.js:
"use strict"; var cliLib = require('@codegena/oapi3ts-cli'); var cliApp = new cliLib.CliApplication; cliApp.createTypings(); cliApp.createServices('angular');
После запуска этого скрипта в нашей директории будут созданы не только типы данных, но и Angular-сервисы для работы с API из нашей спецификации. Как вы уже поняли, демо-приложение тоже использует автоматически-генерируемые сервисы, и вы можете ознакомиться с ними. Давайте рассмотрим один из них, уже знакомый нам RewriteGroupService. Это потомок класса ApiService, и у них указаны типы данных для ответа, запроса и параметров, а также мета-данные:
// Typings for this API method import { RewriteGroupParameters, RewriteGroupResponse, RewriteGroupRequest } from '../typings'; // Schemas import { schema as domainSchema } from './schema.b4c655ec1635af1be28bd6'; /** * Service for angular based on ApiAgent solution. * Provides assured request to API method with implicit * validation and common errors handling scheme. */ @Injectable() export class RewriteGroupService extends ApiService< RewriteGroupResponse, RewriteGroupRequest, RewriteGroupParameters > { protected get method(): 'PUT' { return 'PUT'; } /** * Path template, example: `/some/path/{id}`. */ protected get pathTemplate(): string { return '/group/{groupId}'; } /** * Parameters in a query. */ protected get queryParams(): string[] { return ['forceSave']; } // ... }
Также, в сервис встроена JSON Schema для параметров, запроса и ответа. Она ссылается на импортированный файл, который используется в качестве библиотеки для общих схем, на которые ссылаются сервисы из исходной спецификации:
import { schema as domainSchema } from './schema.b4c655ec1635af1be28bd6';
Схема, которая содержится в файле schema.b4c655ec1635af1be28bd6.ts может быть импортирована в других частях приложения, и использоваться для валидации таких сущностей, как Задача.Использование генерируемых сервисов
Мы не будем заострять внимание о том, как использовать Angular-сервисы.
Для этого достаточно импортировать модуль ApiModule и указать в провайдерах нужные нам сервисы:
import { ApiModule, API_ERROR_HANDLER } from '@codegena/ng-api-service'; import { CreateGroupItemService, GetGroupsService, GetGroupItemsService, UpdateFewItemsService } from '@codegena/todo-app-scheme'; @NgModule({ imports: [ ApiModule, // ... ], providers: [ RewriteGroupService, { provide: API_ERROR_HANDLER, useClass: ApiErrorHandlerService }, // ... ], // ... }) export class TodoAppModule { }
После подключения в модуль, они будут доступны для [инжектирования])(https://angular.io/guide/dependency-injection):
@Injectable() export class TodoTasksStore { constructor( protected createGroupItemService: CreateGroupItemService, protected getGroupsService: GetGroupsService, protected getGroupItemsService: GetGroupItemsService, protected updateFewItemsService: UpdateFewItemsService ) {} }
Все что нам нужно знать об этих сервисах — это то, что у них есть наследуемый метод request, в который мы можем отправить запрос и параметры:
return this.getGroupsService.request(null, { isComplete: null, withItems: false }).pipe( pickResponseBody<GetGroupsResponse<200>>(200, null, true), switchMap<ToDoGroup[], Observable<ComponentTruth>>( groups => this.loadItemsOfSelectedGroups({ ...truth, groups }) ) );
Метод request возвращает тип Observable<HttpResponse<R> | HttpEvent<R>>, и при необходимости, мы можем отслеживать все приходящие от сервера события. Например, если мы реализуем загрузку файлов, то мы сможем отслеживать прогресс загрузки. Однако, чаще всего, мы ожидаем получить определенный тип ответа, а в остальных выкидываем исключение. По этому принципу работает RxJS-оператор pickResponseBody.
И запрос, и объект с параметрами, должны соответствовать валидационной схеме, указанной в сервисе. Перед каждым запросом и после каждого обращения к API, будет производиться проверка данных. Это избавит нас от необходимости писать рутинные проверки. Как мы помним, для параметров производится проверка типизации:
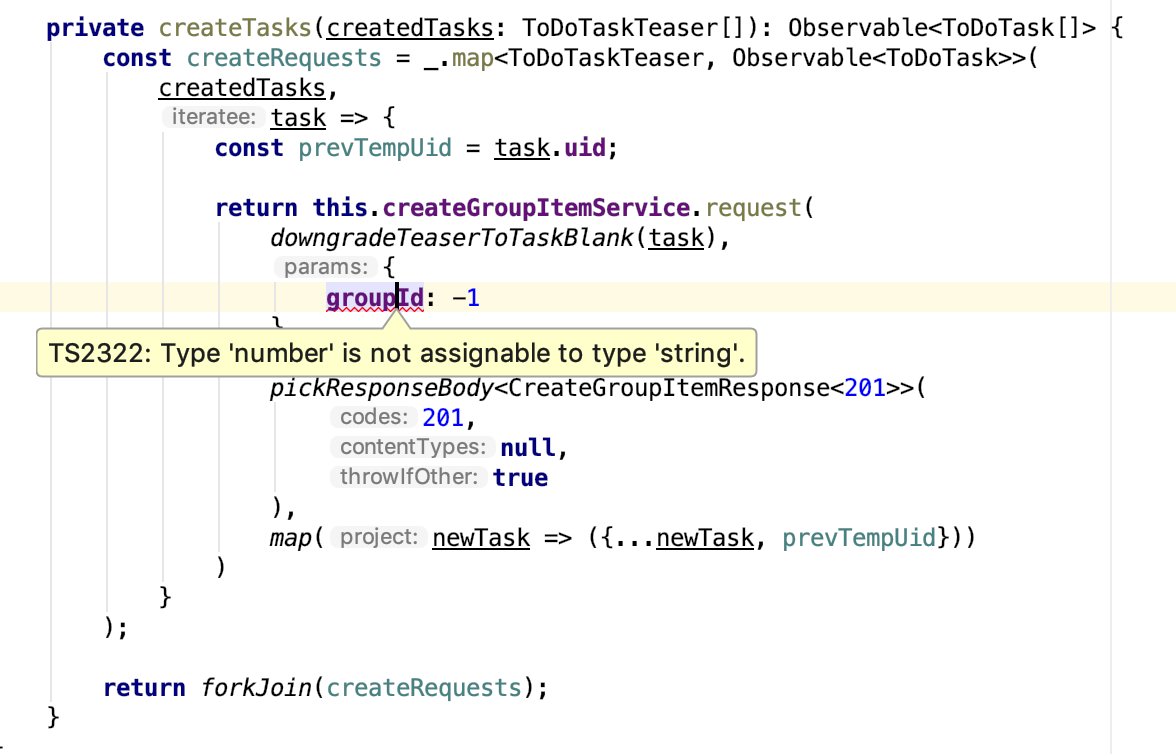
Но это не самая надежная проверка. Валидация по JSON Schema даст нам более надежный контроль. Мы можем настроить обработчик ошибок валидации так, чтобы он "ронял" приложение при каждой попытке сделать что-то недопустимое. Но скорее всего, он будет тихо оповещать наш Sentry или Kibana, и продолжать работу. Это очень важная информация о здоровье системы. При желании, мы можем и вовсе отключить валидацию, включая ее только в режиме отладки.
К сожалению, я не смогу рассказать обо всех нюансах настройки обработчика ошибок в этой статье. Дайте знать, если вам интересна эта тема :)
Вместо послесловия
Есть ощущение того, что в конце эта статья оказалась скомканной. Но я выхожу за пределы своего тайм-бокса, и строки "трудно высказать и не высказать" из нестареющей песни — это про меня. Все же, я думаю, что рассказал достаточно, чтобы сложилась картина.
Что касается самого кодогенератора — его дальнейшая судьба неопределена, и каких-либо планов/амбиций на него нет (и быть не может). Сейчас я хочу получить обратную связь, любая — будет очень интересна.
Спасибо за прочтение.

