Это статья перевод моей статьи на medium — Getting Started with Data Lake, которая оказалась довольно популярной, наверное из-за своей простоты. Поэтому я решил написать ее на русском языке и немного дополнить, чтобы простому человеку, который не является специалистом по работе с данными стало понятно, что такое хранилище данных (DW), а что такое озеро данных (Data Lake), и как они вместе уживаются.
Почему я захотел написать про озеро данных? Я работаю с данными и аналитикой больше 10 лет, и сейчас я точно работаю с большими данными в Amazon Alexa AI в Кембридже, который в Бостоне, хотя сам живу в Виктории на острове Ванкувер и часто бываю и в Бостоне, и в Сиэтле, и в Ванкувере, а иногда даже и в Москве выступаю на конференциях. Так же время от времени я пишу, но пишу в основном на английском, и написал уже несколько книг, так же у меня есть потребность делиться трендами аналитики из Северной Америке, и я иногда пишу в телеграмм.
Я всегда работал с хранилищами данных, и с 2015 года стал плотно работать с Amazon Web Services, да и вообще переключился на облачную аналитику (AWS, Azure, GCP). Я наблюдал эволюцию решений для аналитики с 2007 года и сам даже поработал в вендоре хранилищ данных Терадата и внедрял ее в Сбербанке, тогда-то и появилась Big Data с Hadoop. Все стали говорить, что прошла эра хранилищ и теперь все на Hadoop, а потом уже стали говорить про Data Lake, опять же, что теперь уж точно хранилищу данных пришел конец. Но к счастью (может для кого и к несчастью, кто зарабатывал много денег на настройке Hadoop), хранилище данных не ушло.
В этой статье мы и рассмотрим, что такое озеро данных. Статья рассчитана на людей, у которых мало опыта с хранилищами данными или вовсе нет.

На картинке озеро Блед, это одно из моих любимых озер, хотя я там был всего один раз, но запомнил его на всю жизнь. Но мы поговорим о другом типе озера — озеро данных. Возможно многие из вас уже не раз слышали про это этот термин, но еще одно определение никому не повредит.
Прежде всего вот самые популярные определения Озера Данных:
Я часто люблю упрощать вещи, если я могу рассказать сложный термин простыми словами, значит для себя я понял, как это работает и для чего это нужно. Как то, я ковырялся в iPhone в фотогалерее, и меня осенило, так это же настоящее озеро данных, я даже сделал слайд для конференций:
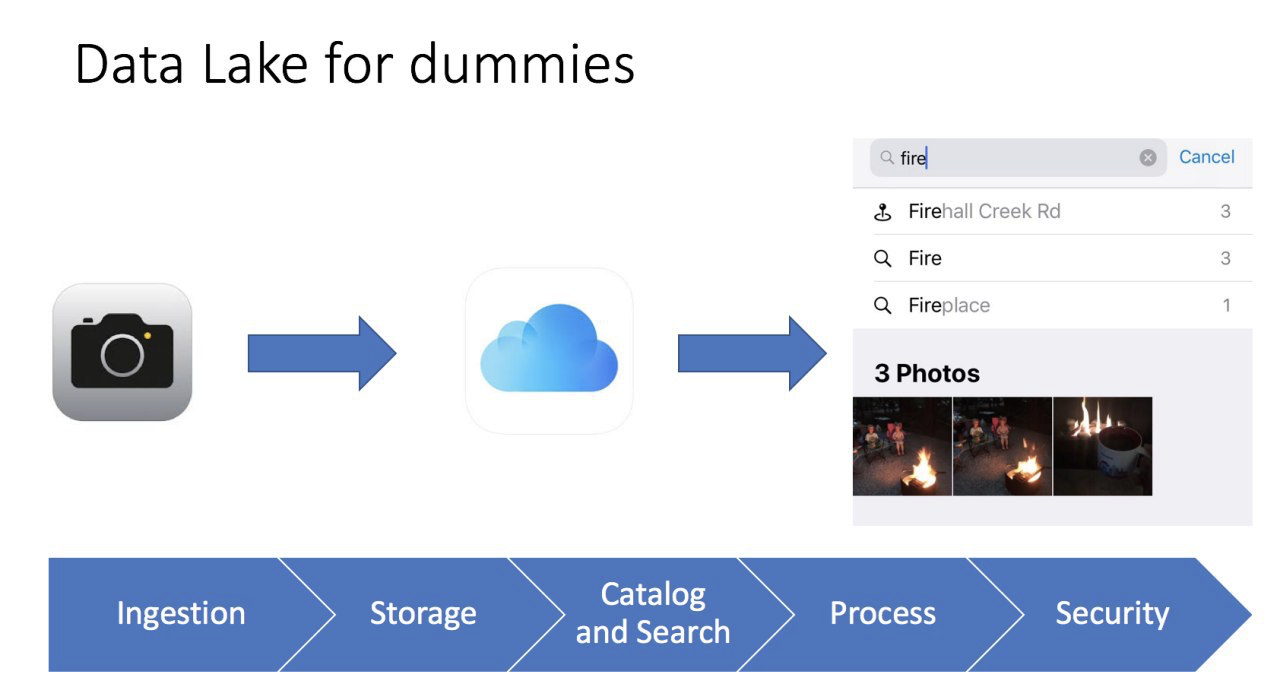
Все очень просто. Мы делаем фотографию на телефон, фотография сохраняется на телефон и может быть сохранено в iCloud (файловое хранилище в облаке). Также телефон собирает мета-данные фотографии: что изображено, гео метка, время. Как результат, мы может использовать удобный интерфейс iPhone, чтобы найти нашу фотографию и при этому мы даже видим показатели, например, когда я ищу фотографии со словом огонь (fire), то я нахожу 3 фотографии с изображение костра. Для меня это прям как Business Intelligence инструмент, который работает очень быстро и четко.
И конечно, нам нельзя забывать про безопасность (авторизацию и аутентификацию), иначе наши данных, могут легко попасть в открытый доступ. Очень много новостей, про крупные корпорации и стартапы, у которых данные попали в открытый доступ из-за халатности разработчиков и не соблюдения простых правил.
Даже такая простая картинка, помогает нам представить, что такое озеро данных, его отличия от традиционного хранилища данных и его основные элементы:
С практической точки зрения, мы можем характеризовать озеро данных тремя атрибутами:
Теперь можно поговорить о разнице между хранилищем данных и озером данных. Обычно люди спрашивают:
Если кратко, то четкого ответа нет. Все зависит от конкретной ситуации, навыков в команде и бюджета. Например миграция хранилища данных на Oracle в AWS и создание озера данных дочерней компанией Амазон — Woot — Our data lake story: How Woot.com built a serverless data lake on AWS.
С другой стороны, вендор Snowflake заявляет, что вам больше не нужно думать про озеро данных, так как их платформа данных (до 2020 это было хранилище данных), позволяет вам совместить и озеро данных и хранилище данных. Я работал не много со Snowflake, и это действительно уникальный продукт, который может так делать. Конечно Snowflake стоит денег, но у крупных компаний на западе серьезные бюджеты на аналитику.
В заключении, мое личное мнение, что нам все еще нужно хранилище данных как основной источник данных для нашей отчетности, и все, что не помещается, мы храним в озере данных. Вся роль аналитики — это предоставить удобный доступ бизнесу для принятия решений. Как ни крути, но бизнес пользователи работаю эффективней с хранилищем данных, чем озером данных, например в Amazon — есть Redshift (аналитическое хранилище данных) и есть Redshift Spectrum/Athena (SQL интерфейс для озера данных в S3 на базе Hive/Presto). Тоже самое относится к другим современным аналитическим хранилищам данных.
Давайте рассмотрим типичную архитектура хранилища данных:
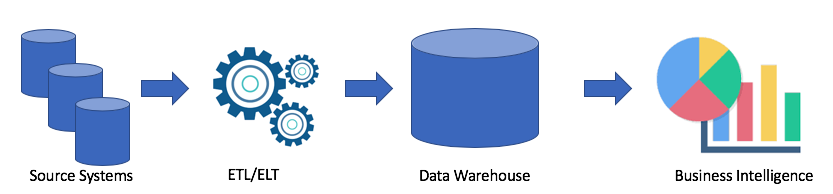
Это классическое решение. У нас есть системы источники, с помощью ETL/ELT мы копируем данные в аналитическое хранилище данных и подключаем к Business Intelligence решению (мое любимое Tableau, а ваше?).
Такое решение имеет следующие недостатки:
Конечно, все зависит от ваше кейса. Если у вас нет проблем с вашим хранилищем данных, то вам совершенно не нужно озеро данных. Но когда появляются проблемы с нехваткой места, мощности или цена вопроса имеет ключевую роль, то можно рассмотреть вариант озера данных. Именно поэтому, озеро данных очень популярно. Вот пример архитектуры озера данных:
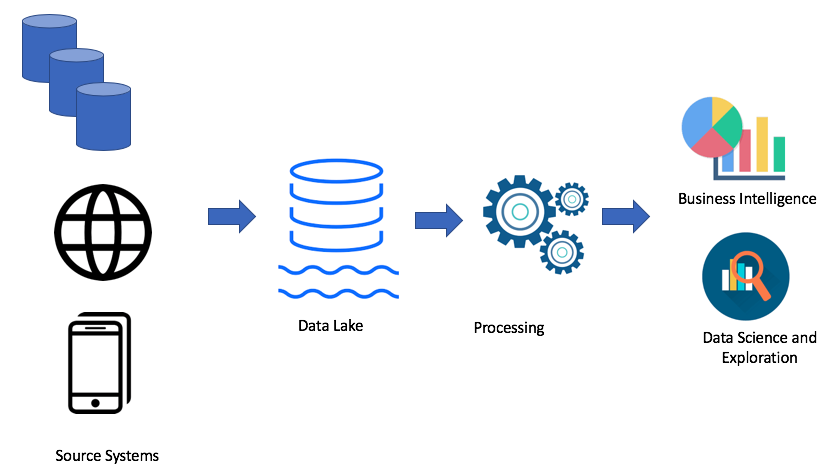
Используя подход озера данных, мы загружаем сырые данные в наше озеро данных (batch или streaming), далее мы обрабатываем данные по необходимости. Озеро данных позволяет бизнес пользователям создавать свои собственные трансформации данных (ETL/ELT) или анализировать данные в решениях Business Intelligence (если есть нужный драйвер).
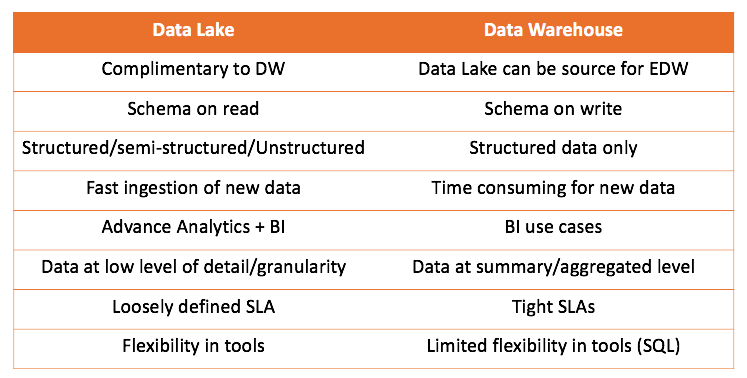
Главный вывод, который можно сделать, что хранилище данных, никак не соревнуется с озером данных, а больше дополняет. Но это вам решать, что подходит для вашего случая. Всегда интересно, попробовать самому, и сделать правильные выводы.
Я хотел бы также рассказать по один из кейсов, когда я стал использовать подход озера данных. Все довольно банально, я попытался использовать инструмент ELT (у нас был Matillion ETL) и Amazon Redshift, мое решение работала, но не укладывалось в требования.
Мне необходимо было взять веб логи, трансформировать их и агрегировать, чтобы предоставить данные для 2х кейсов:
Очень простой, очень простые логи. Вот пример:
Один файл весил 1-4 мегабайта.
Но была одна трудность. У нас было 7 доменов по всему миру, и за один день создавалось 7 тысяч файлов. Это не очень больше объем, всего 50 гигабайт. Но размер нашего кластера Redshift был тоже небольшим (4 ноды). Загрузка традиционным способом одного файла занимала около минуты. То есть, в лоб задача не решалась. И это был тот случай, когда я решил использовать подход озера данных. Решение выглядело примерно так:
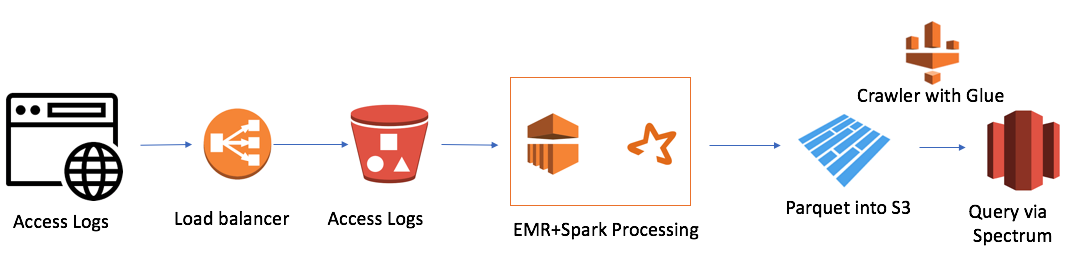
Оно достаточно простое (я хочу заметить, что преимущество работы в облаке это простота). Я использовал:
Самый маленький кластер EMR+Spark обрабатывал все пачку файлов за 30 минут. Есть и другие кейсы для AWS, особенно много связанных с Alexa, где данных очень много.
Совсем недавно я узнал один из недостатков озера данных — это GDPR. Проблема в том, когда клиент просит его удалить, а данные находятся в одном из файлов, мы не можем использовать Data Manipulation Language и операцию DELETE как в базе данных.
Надеюсь, статья прояснила разнице между хранилищем данных и озером данных. Если было интересно, то могу перевести еще свои статьи или статье профессионалов, которых читаю. А также рассказать про решения, с которыми работаю, и их архитектуру.
Почему я захотел написать про озеро данных? Я работаю с данными и аналитикой больше 10 лет, и сейчас я точно работаю с большими данными в Amazon Alexa AI в Кембридже, который в Бостоне, хотя сам живу в Виктории на острове Ванкувер и часто бываю и в Бостоне, и в Сиэтле, и в Ванкувере, а иногда даже и в Москве выступаю на конференциях. Так же время от времени я пишу, но пишу в основном на английском, и написал уже несколько книг, так же у меня есть потребность делиться трендами аналитики из Северной Америке, и я иногда пишу в телеграмм.
Я всегда работал с хранилищами данных, и с 2015 года стал плотно работать с Amazon Web Services, да и вообще переключился на облачную аналитику (AWS, Azure, GCP). Я наблюдал эволюцию решений для аналитики с 2007 года и сам даже поработал в вендоре хранилищ данных Терадата и внедрял ее в Сбербанке, тогда-то и появилась Big Data с Hadoop. Все стали говорить, что прошла эра хранилищ и теперь все на Hadoop, а потом уже стали говорить про Data Lake, опять же, что теперь уж точно хранилищу данных пришел конец. Но к счастью (может для кого и к несчастью, кто зарабатывал много денег на настройке Hadoop), хранилище данных не ушло.
В этой статье мы и рассмотрим, что такое озеро данных. Статья рассчитана на людей, у которых мало опыта с хранилищами данными или вовсе нет.
На картинке озеро Блед, это одно из моих любимых озер, хотя я там был всего один раз, но запомнил его на всю жизнь. Но мы поговорим о другом типе озера — озеро данных. Возможно многие из вас уже не раз слышали про это этот термин, но еще одно определение никому не повредит.
Прежде всего вот самые популярные определения Озера Данных:
«файловое хранилище всех типов сырых данных, которые доступны для анализа кем-угодно в организации» — Мартин Фовлер.
«Если вы думаете, что витрина данных это бутылка воды — очищенной, запакованной и расфасованной для удобного употребления, то озеро данных это у нас огромный резервуар с водой в ее естественном виде. Пользователи, могу набирать воды для себя, нырять на глубину, исследовать» — Джеймс Диксон.Теперь мы точно знаем, что озеро данных это про аналитику, оно позволяет нам хранить большие объемы данных в их первоначальной форме и у нас есть необходимый и удобный доступ к данным.
Я часто люблю упрощать вещи, если я могу рассказать сложный термин простыми словами, значит для себя я понял, как это работает и для чего это нужно. Как то, я ковырялся в iPhone в фотогалерее, и меня осенило, так это же настоящее озеро данных, я даже сделал слайд для конференций:
Все очень просто. Мы делаем фотографию на телефон, фотография сохраняется на телефон и может быть сохранено в iCloud (файловое хранилище в облаке). Также телефон собирает мета-данные фотографии: что изображено, гео метка, время. Как результат, мы может использовать удобный интерфейс iPhone, чтобы найти нашу фотографию и при этому мы даже видим показатели, например, когда я ищу фотографии со словом огонь (fire), то я нахожу 3 фотографии с изображение костра. Для меня это прям как Business Intelligence инструмент, который работает очень быстро и четко.
И конечно, нам нельзя забывать про безопасность (авторизацию и аутентификацию), иначе наши данных, могут легко попасть в открытый доступ. Очень много новостей, про крупные корпорации и стартапы, у которых данные попали в открытый доступ из-за халатности разработчиков и не соблюдения простых правил.
Даже такая простая картинка, помогает нам представить, что такое озеро данных, его отличия от традиционного хранилища данных и его основные элементы:
- Загрузка данных (Ingestion) — ключевой компонент озера данных. Данные могут попадать в хранилище данных двумя способами — batch (загрузка с интервалами) и streaming (поток данных).
- Файловое хранилище (Storage) — главный компонент Озера Данных. Нам необходимо, что хранилище было легко масштабируемое, чрезвычайно надежное и обладало низкой стоимостью. Например, в AWS это S3.
- Каталог и Поиск (Catalog and Search) — для того чтобы нам избежать Болота Данных (это когда мы сваливаем все данные в одну кучу, и потом невозможно с ними работать), нам необходимо создать слой мета-данных для классификации данных, чтобы пользователи легко могли найти данные, которые им необходимы для анализа. Дополнительно, можно использовать дополнительные решения для поиска, например ElasticSearch. Поиск помогает пользователю искать нужные данные через удобные интерфейс.
- Обработка (Process) — это шаг отвечает за обработку и трансформацию данных. Мы можем трансформировать данные, изменять их структуры, очищать и много другое.
- Безопасность (Security) — важно потратить время на дизайн безопасности решения. Например, шифрование данных во время хранения, обработки и загрузки. Важно использовать методы аутентификации и авторизации. В заключение, нужен инструмент аудита.
С практической точки зрения, мы можем характеризовать озеро данных тремя атрибутами:
- Собирайте и храните все что угодно — озеро данных содержит все данные, как сырые необработанные данные за любой период времени, так и обработанных/очищенные данные.
- Глубокий анализ — озеро данных позволяет пользователям исследовать и анализировать данные.
- Гибкий доступ — озеро данных обеспечивает гибкий доступ для различных данных и различных сценариев.
Теперь можно поговорить о разнице между хранилищем данных и озером данных. Обычно люди спрашивают:
- А как же хранилище данных?
- Мы заменяем хранилище данных на озеро данных или мы его расширяем?
- Можно ли все таки обойтись без озера данных?
Если кратко, то четкого ответа нет. Все зависит от конкретной ситуации, навыков в команде и бюджета. Например миграция хранилища данных на Oracle в AWS и создание озера данных дочерней компанией Амазон — Woot — Our data lake story: How Woot.com built a serverless data lake on AWS.
С другой стороны, вендор Snowflake заявляет, что вам больше не нужно думать про озеро данных, так как их платформа данных (до 2020 это было хранилище данных), позволяет вам совместить и озеро данных и хранилище данных. Я работал не много со Snowflake, и это действительно уникальный продукт, который может так делать. Конечно Snowflake стоит денег, но у крупных компаний на западе серьезные бюджеты на аналитику.
В заключении, мое личное мнение, что нам все еще нужно хранилище данных как основной источник данных для нашей отчетности, и все, что не помещается, мы храним в озере данных. Вся роль аналитики — это предоставить удобный доступ бизнесу для принятия решений. Как ни крути, но бизнес пользователи работаю эффективней с хранилищем данных, чем озером данных, например в Amazon — есть Redshift (аналитическое хранилище данных) и есть Redshift Spectrum/Athena (SQL интерфейс для озера данных в S3 на базе Hive/Presto). Тоже самое относится к другим современным аналитическим хранилищам данных.
Давайте рассмотрим типичную архитектура хранилища данных:
Это классическое решение. У нас есть системы источники, с помощью ETL/ELT мы копируем данные в аналитическое хранилище данных и подключаем к Business Intelligence решению (мое любимое Tableau, а ваше?).
Такое решение имеет следующие недостатки:
- ETL/ELT операции требуют время и ресурсов.
- Как правило память для хранения данных в аналитическом хранилище данных не дешевая (например Redshift, BigQuery, Teradata), так как нам надо покупать целый кластер.
- Бизнес пользователи имеют доступ к очищенным и часто агрегированным данным и у них нет возможность получить сырые данные.
Конечно, все зависит от ваше кейса. Если у вас нет проблем с вашим хранилищем данных, то вам совершенно не нужно озеро данных. Но когда появляются проблемы с нехваткой места, мощности или цена вопроса имеет ключевую роль, то можно рассмотреть вариант озера данных. Именно поэтому, озеро данных очень популярно. Вот пример архитектуры озера данных:
Используя подход озера данных, мы загружаем сырые данные в наше озеро данных (batch или streaming), далее мы обрабатываем данные по необходимости. Озеро данных позволяет бизнес пользователям создавать свои собственные трансформации данных (ETL/ELT) или анализировать данные в решениях Business Intelligence (если есть нужный драйвер).
Цель любого аналитического решения — служить бизнес пользователям. Поэтому мы всегда должны работать от требований бизнеса. (В Амазон это один из принципов — working backwards).Работая и с хранилищем данных и с озером данных, мы можем сравнить оба решения:
Главный вывод, который можно сделать, что хранилище данных, никак не соревнуется с озером данных, а больше дополняет. Но это вам решать, что подходит для вашего случая. Всегда интересно, попробовать самому, и сделать правильные выводы.
Я хотел бы также рассказать по один из кейсов, когда я стал использовать подход озера данных. Все довольно банально, я попытался использовать инструмент ELT (у нас был Matillion ETL) и Amazon Redshift, мое решение работала, но не укладывалось в требования.
Мне необходимо было взять веб логи, трансформировать их и агрегировать, чтобы предоставить данные для 2х кейсов:
- Команда маркетинга хотела анализировать активность ботов для SEO
- IT хотело смотреть метрики по работе сайтов
Очень простой, очень простые логи. Вот пример:
https 2018-07-02T22:23:00.186641Z app/my-loadbalancer/50dc6c495c0c9188 192.168.131.39:2817 10.0.0.1:80 0.086 0.048 0.037 200 200 0 57 "GET https://www.example.com:443/ HTTP/1.1" "curl/7.46.0" ECDHE-RSA-AES128-GCM-SHA256 TLSv1.2 arn:aws:elasticloadbalancing:us-east-2:123456789012:targetgroup/my-targets/73e2d6bc24d8a067 "Root=1-58337281-1d84f3d73c47ec4e58577259" "www.example.com" "arn:aws:acm:us-east-2:123456789012:certificate/12345678-1234-1234-1234-123456789012" 1 2018-07-02T22:22:48.364000Z "authenticate,forward" "-" "-"
Один файл весил 1-4 мегабайта.
Но была одна трудность. У нас было 7 доменов по всему миру, и за один день создавалось 7 тысяч файлов. Это не очень больше объем, всего 50 гигабайт. Но размер нашего кластера Redshift был тоже небольшим (4 ноды). Загрузка традиционным способом одного файла занимала около минуты. То есть, в лоб задача не решалась. И это был тот случай, когда я решил использовать подход озера данных. Решение выглядело примерно так:
Оно достаточно простое (я хочу заметить, что преимущество работы в облаке это простота). Я использовал:
- AWS Elastic Map Reduce (Hadoop) как вычислительную мощность
- AWS S3 как файловой хранилище с возможность шифрования данных и разограничения доступа
- Spark как InMemory вычислительную мощность и PySpark для логики и трансформации данных
- Parquet как результат работы Spark
- AWS Glue Crawler как сборщик метаданных о новых данных и партициях
- Redshift Spectrum как SQL интерфейс к озеру данных для существующих пользователей Redshift
Самый маленький кластер EMR+Spark обрабатывал все пачку файлов за 30 минут. Есть и другие кейсы для AWS, особенно много связанных с Alexa, где данных очень много.
Совсем недавно я узнал один из недостатков озера данных — это GDPR. Проблема в том, когда клиент просит его удалить, а данные находятся в одном из файлов, мы не можем использовать Data Manipulation Language и операцию DELETE как в базе данных.
Надеюсь, статья прояснила разнице между хранилищем данных и озером данных. Если было интересно, то могу перевести еще свои статьи или статье профессионалов, которых читаю. А также рассказать про решения, с которыми работаю, и их архитектуру.

