Десять лет назад у нас был классический LAMP-стек: Linux, Apache, MySQL, и PHP, который работал в медленном режиме mod_php. Мир менялся, а с ним и важность скорости. Появился PHP-FPM, который позволил значительно увеличить производительность решений на PHP, а не срочно переписывать на чем-то побыстрее.
Параллельно велась разработка библиотеки ReactPHP с применением концепции Event Loop для обработки сигналов от ОС и представления результатов для асинхронных операций. Развитие идеи ReactPHP — AMPHP. Эта библиотека использует тот же Event Loop, но поддерживает корутины, в отличие от ReactPHP. Они позволяют писать асинхронный код, который выглядит как синхронный. Возможно, это самый актуальный фреймворк для разработки асинхронных приложений на PHP.

Но скорости требуется всё больше и больше, инструментов уже не хватает, поэтому идея асинхронного программирования в PHP — одна из возможностей ускорить обработку запросов и лучше утилизировать ресурсы.
Об этом и поговорит Антон Шабовта (zloyusr) — разработчик в компании Onliner. Опыт больше 10 лет: начинал с десктопных приложений на С/С++, а потом перешел в веб-разработку на PHP. «Домашние» проекты пишет на C# и Python 3, а в PHP экспериментирует с DDD, CQRS, Event Sourcing, Async Multitasking.
Статья основана на расшифровке доклада Антона на PHP Russia 2019. В ней мы разберемся в блокирующих и неблокирующих операциях в PHP, изучим изнутри структуру Event Loop и асинхронных примитивов, таких как Promise и корутины. Напоследок, узнаем, что нас ждет в ext-async, AMPHP 3 и PHP 8.
Введем пару определений. Я долго пытался найти точное определение асинхронности и асинхронных операций, но не нашел и написал свои.
Вроде бы несложно, но сначала надо понять, какие операции блокируют поток выполнения.
PHP это язык-интерпретатор. Он читает код построчно, переводит в свои инструкции и выполняет. На какой строке из примера ниже код заблокируется?
Если мы подключаемся к БД через PDO, то поток выполнения будет заблокирован на строке запроса к SQL-серверу:
Это происходит потому, что PHP не знает, как долго SQL-сервер будет обрабатывать этот запрос, и выполнится ли он вообще. Он ждет ответа от сервера и все это время программа не выполняется.
Также PHP блокирует поток выполнения на всех I/O операциях.
Кроме того исполнение блокируется на таймерах:
Но современный PHP — это язык общего назначения, а не только для веба как PHP/FI в 1997 году. Поэтому мы можем написать асинхронный SQL-клиент с нуля. Задача не самая тривиальная, но решаемая.
Что делает такой клиент? Подключается к нашему SQL-серверу, переводит работу сокета в неблокирующий режим, пакует запрос в бинарный формат понятный SQL-серверу, записывает данные в сокет.
Так как сокет в неблокирующем режиме, то операция записи со стороны PHP выполняется быстро.
Но что вернется как результат такой операции? Мы не знаем, что ответит SQL-сервер. Он может долго выполнять запрос или не выполнить вообще. Но что-то же надо вернуть? Если мы используем PDO и вызываем
Это концепция из мира асинхронного программирования.
Так как результата еще нет, мы можем установить только какие-то

Когда данные будут доступны, необходимо выполнить колбэк

Если произойдет ошибка, то выполнится колбэк
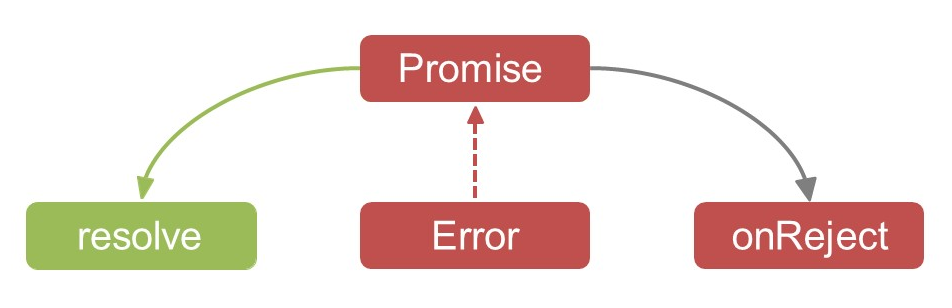
Интерфейс Promise выглядит примерно так.
У Promise есть статус и методы для установки колбэков и заполнения (
Часто методы для заполнения Promise

Как это применить в SQL-клиенте, если мы решим писать его сами?
Сначала мы создали Deferred, выполнили всю работу сокетами, записали данные и вернули Promise — все просто.
Когда у нас есть Promise, мы можем, например:
Остается вопрос: мы поставили колбэк, а кто будет вызывать
Существует концепция Event Loop — цикл событий. Он умеет обрабатывать сообщения в асинхронной среде. Для асинхронного I/O это будут сообщения от ОС о том, что сокет готов к чтению или записи.
Как это работает.

Выразим эту концепцию в коде: возьмем простейший случай, уберем обработку ошибок и другие нюансы, чтобы остался один бесконечный цикл. В каждой итерации он будет опрашивать ОС о сокетах, которые готовы к чтению или записи, и вызывать колбэк для конкретного сокета.
Дополним наш SQL-клиент. Мы сообщаем Event Loop, что как только в сокет, с которым мы работаем, придут данные от SQL-сервера, нам надо привести Deferred в состояние «выполнено» и передать данные из сокета в Promise.
Event Loop умеет обрабатывать наши I/O и работает с сокетами. Что еще он может делать?
Написать свой Event Loop не только можно, но и нужно. Если хотите работать с асинхронным PHP, важно написать свою простую реализацию, чтобы понять, как это работает. Но в продакшн мы это, естественно, использовать не будем, а возьмем готовые реализации: стабильные, без ошибок и проверенные в работе.
Существует три основных реализации.
ReactPHP. Самый старый проект, начинался еще с PHP 5.3. Сейчас минимальная требуемая версия PHP 5.3.8. Проект реализует стандарт Promises/A из мира JavaScript.
AMPHP. Именно эту реализацию я предпочитаю использовать. Минимальное требование PHP 7.0, а со следующей версии уже 7.3. Здесь используются корутины поверх Promise.
Swoole. Это интересный китайский фреймворк, в котором разработчики пытаются перенести в PHP некоторые концепции из мира Go. На английском документация неполная, большая часть на GitHub на китайском. Если знаете язык — вперед, но мне пока работать страшно.

Посмотрим как будет выглядеть клиент с использованием ReactPHP для MySQL.
Все почти также, как мы написали: создаем
и колбэк для обработки ошибок:
Из этих колбэков можно строить длинные-длинные цепочки, потому что каждый результат
Это решение проблемы, которая называется «callback hell». К сожалению, в реализации ReactPHP это приводит к проблеме «Promise hell», когда для корректного подключения RabbitMQ, требуется10-11 колбэков. Работать с таким кодом и исправлять его сложно. Я быстро понял, что это не мое и перешел на AMPHP.
Этот проект младше, чем ReactPHP, и продвигает иную концепцию — корутины. Если посмотреть на работу с MySQL в AMPHP, то видно, что это почти аналогично работе с
Здесь мы создаем пул, подключаемся и выполняем запрос. Мы можем обрабатывать ошибки через привычные
Но перед асинхронным вызовом здесь появляется ключевое слово —
Ключевое слово
Как только интерпретатор PHP встречает
Генераторы наследуют интерфейс итератора.
Соответственно, по ним можно пробежаться циклами
Запустим нашу функцию
Как только выполним генератор
Но у генератора есть функция интереснее — мы можем снаружи отправить данные в генератор. В этом случае это уже не совсем генератор, а корутина или сопрограмма.
В данном участке кода интересно, что
Кроме отправки данных в генератор можно отправлять ошибки и обрабатывать их изнутри, что удобно.
Подытожим. Корутина это компонент программы, который поддерживает остановку и продолжение выполнения с сохранением текущего состояния. Корутина помнит свой стек вызовов, данные внутри, и может их использовать в дальнейшем.
Посмотрим на интерфейсы генераторов и Promise.
Они выглядят одинаково, за исключением разных названий методов. Мы можем отправить данные и выкинуть ошибку и в генератор, и в Promise.
Как это можно использовать? Напишем функцию.
Функция берет у генератора текущее значение:
Я немного утрировал. Да, мы должны проверить, что текущее значение, которое нам вернулось это какой-то
То же можно провернуть и с ошибками. Если Promise завершился с ошибкой, например, SQL-сервер сказал: «Too many connections», то можем выкинуть ошибку внутрь генератора и перейти на следующий шаг.
Все это подводит нас к важному понятию кооперативной многозадачности.
Это тип многозадачности, при котором следующая задача выполняется только после того, как текущая задача явно объявит себя готовой отдать процессорное время другим задачам.
Я редко встречаюсь с чем-то простым как, например, работа только с одной БД. Чаще всего в процессе обновления пользователя надо обновить данные в БД, в поисковом индексе, потом почистить или обновить кэш, а после еще отправить 15 сообщений в RabbitMQ. В PHP это все выглядит так.
Мы выполняем операции одну за одной: обновили базу, индекс, потом кэш. Но по умолчанию PHP блокирует на таких операциях (I/O), поэтому, если приглядеться, на самом деле все так.
На темных частях мы заблокировались. Они занимают больше всего времени.
Если мы работаем в асинхронном режиме, то этих частей нет, таймлайн выполнения прерывистый.

Можно все это склеить и выполнять кусочки один за одним.

Для чего все это? Если посмотреть на размер таймлайна, то сначала он занимает много времени, но как только мы склеиваем — приложение ускоряется.
Сама концепция Event Loop и кооперативной многозадачности давно применяется в различных приложениях: Nginx, Node.js, Memcached, Redis. Все они используют внутри Event Loop и построены на этом же принципе.
Раз уж мы начали говорить о веб-серверах Nginx и Node.js, давайте вспомним, как происходит обработка запросов в PHP.
Браузер отправляет запрос, он попадает на HTTP-сервер за которым стоит пул FPM-потоков. Один из потоков берет в работу этот запрос, подключает наш код и начинает его выполнять.

Когда приходит следующий запрос, другой FPM-поток его заберет, подключит код и он будет выполняться.
В этой схеме работы есть плюсы.
Это крутая схема, которая работала в PHP с самого начала и до сих пор работает успешно. Но в ней есть и минусы.
Подойдем к вопросу иначе — напишем HTTP-сервер на самом PHP.

Это можно сделать. Мы уже научились работать с сокетами в неблокирующем режиме, а HTTP-соединение это такой же сокет. Как он будет выглядеть и работать?
Это пример старта HTTP-серверов в фреймворке AMPHP.
Все достаточно просто: загружаем
Дальше запускаем наш сервер, устанавливаем
Последнее, что надо сделать — запустить сервер —
В ReactPHP это будет выглядеть приблизительно также, но только там будет 150 колбэков на разные варианты, что не очень удобно.
С асинхронностью в PHP есть несколько проблем.
Отсутствие стандартов. Каждый фреймворк: Swoole, ReactPHP или AMPHP, реализует свой интерфейс Promise, и они несовместимы.
AMPHP теоретически может взаимодействовать с Promise от ReactPHP, но есть нюанс. Если код для ReactPHP написан не очень грамотно, и где-то неявно вызывает или создает Event Loop, то получится так, что внутри будут крутиться два Event Loop.
Есть относительно хороший стандарт Promises/A+ у JavaScript, который реализует Guzzle. Было бы хорошо, если фреймворки будут ему следовать. Но пока этого нет.
Утечки памяти. Когда мы работаем в PHP в обычном FPM-режиме, то про память можем не думать. Даже если разработчики какого-то расширения забыли написать хороший код, забыли прогнать через Valgrind, и где-то внутри память течет, то ничего страшного — на следующем запросе очистится и начнется заново. Но в асинхронном режиме такое себе позволить нельзя, потому что рано или поздно мы просто упадем с
Чинить это возможно, но сложно и больно. В одних случаях помогает Xdebug, в других strace для разбора ошибок, которые вызвал
Блокирующие операции. Жизненно важно не блокировать Event Loop когда мы пишем асинхронный код. Приложение замедляется как только мы блокируем поток выполнения, каждая из наших корутин начинает работать медленней.
Найти такие операции для AMPHP поможет пакет kelunik/loop-block. Он выставляет таймер на очень маленький интервал. Если таймер не срабатывает, значит мы где-то заблокировались. Пакет помогает в поиске блокирующих мест, но не всегда: блокировки в некоторых расширениях может не заметить.
Поддержка библиотек: Cassandra, Influx, ClickHouse. Основная проблема всего асинхронного PHP это поддержка библиотек. Мы не можем использовать всем привычные
Самый странный опыт я получил с драйвером для БД Cassandra. Они предоставляют операции
Указание типа. Это проблема AMPHP и корутин.
Если в функции встречается
Что нас ждет в PHP 8? Расскажу о своих предположениях или, скорее, желаниях (прим. ред.: Дмитрий Стогов знает, что на самом деле появится в PHP 8).
Event Loop. Есть шанс, что он появится, потому что ведется работа над тем, чтобы внести Event Loop в каком-то виде в ядро. Если это произойдет, у нас появится функция
Generics. В Go ждут Generics, мы ждем Generics, все ждут Generics.
Но мы ждем Generics не для коллекций, а чтобы указать, что результатом выполнения Promise будет именно объект User.
Параллельно велась разработка библиотеки ReactPHP с применением концепции Event Loop для обработки сигналов от ОС и представления результатов для асинхронных операций. Развитие идеи ReactPHP — AMPHP. Эта библиотека использует тот же Event Loop, но поддерживает корутины, в отличие от ReactPHP. Они позволяют писать асинхронный код, который выглядит как синхронный. Возможно, это самый актуальный фреймворк для разработки асинхронных приложений на PHP.
Но скорости требуется всё больше и больше, инструментов уже не хватает, поэтому идея асинхронного программирования в PHP — одна из возможностей ускорить обработку запросов и лучше утилизировать ресурсы.
Об этом и поговорит Антон Шабовта (zloyusr) — разработчик в компании Onliner. Опыт больше 10 лет: начинал с десктопных приложений на С/С++, а потом перешел в веб-разработку на PHP. «Домашние» проекты пишет на C# и Python 3, а в PHP экспериментирует с DDD, CQRS, Event Sourcing, Async Multitasking.
Статья основана на расшифровке доклада Антона на PHP Russia 2019. В ней мы разберемся в блокирующих и неблокирующих операциях в PHP, изучим изнутри структуру Event Loop и асинхронных примитивов, таких как Promise и корутины. Напоследок, узнаем, что нас ждет в ext-async, AMPHP 3 и PHP 8.
Введем пару определений. Я долго пытался найти точное определение асинхронности и асинхронных операций, но не нашел и написал свои.
Асинхронность — это способность программной системы не блокировать основной поток выполнения.
Асинхронная операция — это операция, которая не блокирует поток выполнения программы до своего завершения.
Вроде бы несложно, но сначала надо понять, какие операции блокируют поток выполнения.
Блокирующие операции
PHP это язык-интерпретатор. Он читает код построчно, переводит в свои инструкции и выполняет. На какой строке из примера ниже код заблокируется?
public function update(User $user) { try { $sql = 'UPDATE users SET ...'; return $this->connection->execute($sql, $user->data()); } catch (\PDOException $error) { log($error->getMessage()); } return 0; }
Если мы подключаемся к БД через PDO, то поток выполнения будет заблокирован на строке запроса к SQL-серверу:
return $this->connection->execute($sql, $user->data());.Это происходит потому, что PHP не знает, как долго SQL-сервер будет обрабатывать этот запрос, и выполнится ли он вообще. Он ждет ответа от сервера и все это время программа не выполняется.
Также PHP блокирует поток выполнения на всех I/O операциях.
- Файловая система:
fwrite,file_get_contents. - Базы данных:
PDOConnection,RedisClient. Почти все расширения для подключения БД работают в блокирующем режиме по умолчанию. - Процессы:
exec,system,proc_open. Это блокирующие операции, так как вся работа с процессами построена через системные вызовы. - Работа с stdin/stdout:
readline,echo,print.
Кроме того исполнение блокируется на таймерах:
sleep, usleep. Это операции, в которых мы явно указываем потоку уснуть на некоторое время. Все это время PHP будет простаивать.Асинхронный SQL-клиент
Но современный PHP — это язык общего назначения, а не только для веба как PHP/FI в 1997 году. Поэтому мы можем написать асинхронный SQL-клиент с нуля. Задача не самая тривиальная, но решаемая.
public function execAsync(string $query, array $params = []) { $socket = stream_socket_client('127.0.0.1:3306', ...); stream_set_blocking($socket, false); $data = $this->packBinarySQL($query, $params); socket_write($socket, $data, strlen($data)); }
Что делает такой клиент? Подключается к нашему SQL-серверу, переводит работу сокета в неблокирующий режим, пакует запрос в бинарный формат понятный SQL-серверу, записывает данные в сокет.
Так как сокет в неблокирующем режиме, то операция записи со стороны PHP выполняется быстро.
Но что вернется как результат такой операции? Мы не знаем, что ответит SQL-сервер. Он может долго выполнять запрос или не выполнить вообще. Но что-то же надо вернуть? Если мы используем PDO и вызываем
update запроса на SQL-сервере, нам возвращается affected rows — количество строк измененных этим запросом. Это мы вернуть пока не можем, поэтому только обещаем возврат.Promise
Это концепция из мира асинхронного программирования.
Promise — это объект-обертка над результатом асинхронной операции. При этом результат операции нам пока неизвестен.К сожалению, нет единого стандарта Promise, а перенести стандарты из мира JavaScript в PHP напрямую не получается.
Как работает Promise
Так как результата еще нет, мы можем установить только какие-то
callbacks.Когда данные будут доступны, необходимо выполнить колбэк
onResolve.Если произойдет ошибка, то выполнится колбэк
onReject для обработки ошибки.Интерфейс Promise выглядит примерно так.
interface Promise { const STATUS_PENDING = 0, STATUS_RESOLVED = 1, STATUS_REJECTED = 2 ; public function onResolve(callable $callback); public function onReject(callable $callback); public function resolve($data); public function reject(\Throwable $error); }
У Promise есть статус и методы для установки колбэков и заполнения (
resolve) Promise данными или ошибкой (reject). Но есть отличия и вариации. Методы могут называться иначе, либо вместо отдельных методов для установления колбэков, resolve и reject может быть какой-то один, как в AMPHP, например.Часто методы для заполнения Promise
resolve и reject выносят в отдельный объект Deferred — хранилище состояния асинхронной функции. Его можно рассматривать, как некую фабрику для Promise. Он одноразовый: из одного Deferred получается один Promise.Как это применить в SQL-клиенте, если мы решим писать его сами?
Асинхронный SQL-клиент
Сначала мы создали Deferred, выполнили всю работу сокетами, записали данные и вернули Promise — все просто.
public function execAsync(string $query, array $params = []) { $deferred = new Deferred; $socket = stream_socket_client('127.0.0.1:3306', ...); stream_set_blocking($socket, false); $data = $this->packBinarySQL($query, $params); socket_write($socket, $data, strlen($data)); return $deferred->promise(); }
Когда у нас есть Promise, мы можем, например:
- установить колбэк и получить те же
affected rows, которые нам возвращаетPDOConnection; - обработать ошибку, добавить в лог;
- попытаться заново выполнить запрос, если SQL-сервер ответил ошибкой.
$promise = $this->execAsync($sql, $user->data()); $promise->onResolve(function (int $rows) { echo "Affected rows: {$rows}"; }); $promise->onReject(function (\Throwable $error) { log($error->getMessage()); });
Остается вопрос: мы поставили колбэк, а кто будет вызывать
resolve и reject?Event Loop
Существует концепция Event Loop — цикл событий. Он умеет обрабатывать сообщения в асинхронной среде. Для асинхронного I/O это будут сообщения от ОС о том, что сокет готов к чтению или записи.
Как это работает.
- Клиент сообщает Event Loop, что его интересует какой-то сокет.
- Event Loop опрашивает ОС через системный вызов
stream_select: готов ли сокет, все ли данные записались, пришли ли данные с другой стороны. - Если ОС сообщает, что сокет не готов, заблокирован, то Event Loop повторяет цикл.
- Когда ОС оповещает о готовности сокета, Event Loop возвращает управление в клиент и разрешает (
resolveилиreject) Promise.
Выразим эту концепцию в коде: возьмем простейший случай, уберем обработку ошибок и другие нюансы, чтобы остался один бесконечный цикл. В каждой итерации он будет опрашивать ОС о сокетах, которые готовы к чтению или записи, и вызывать колбэк для конкретного сокета.
public static function run() { while (true) { stream_select($readSockets, $writeSockets, null, 0); foreach ($readSockets as $i => $socket) { call_user_func(self::readCallbacks[$i], $socket); } // Do same for write sockets } }
Дополним наш SQL-клиент. Мы сообщаем Event Loop, что как только в сокет, с которым мы работаем, придут данные от SQL-сервера, нам надо привести Deferred в состояние «выполнено» и передать данные из сокета в Promise.
public function execAsync(string $query, array $params = []) { $deferred = new Deferred; ... Loop::onReadable($socket, function ($socket) use ($deferred) { $deferred->resolve(socket_read($socket)); }); return $deferred->promise(); }
Event Loop умеет обрабатывать наши I/O и работает с сокетами. Что еще он может делать?
- В JavaScript есть методы
setTimeoutиsetInterval— таймеры. Они могут выполнять код через определенное время или повторять его через каждые N секунд. Event Loop может отслеживать таймеры и вызывать их. - Event Loop часто обрабатывает сигналы от ОС. Это наши любимые
process control, их тоже можно использовать в асинхронном режиме.
Реализации Event Loop
Написать свой Event Loop не только можно, но и нужно. Если хотите работать с асинхронным PHP, важно написать свою простую реализацию, чтобы понять, как это работает. Но в продакшн мы это, естественно, использовать не будем, а возьмем готовые реализации: стабильные, без ошибок и проверенные в работе.
Существует три основных реализации.
ReactPHP. Самый старый проект, начинался еще с PHP 5.3. Сейчас минимальная требуемая версия PHP 5.3.8. Проект реализует стандарт Promises/A из мира JavaScript.
AMPHP. Именно эту реализацию я предпочитаю использовать. Минимальное требование PHP 7.0, а со следующей версии уже 7.3. Здесь используются корутины поверх Promise.
Swoole. Это интересный китайский фреймворк, в котором разработчики пытаются перенести в PHP некоторые концепции из мира Go. На английском документация неполная, большая часть на GitHub на китайском. Если знаете язык — вперед, но мне пока работать страшно.
ReactPHP
Посмотрим как будет выглядеть клиент с использованием ReactPHP для MySQL.
$connection = (new ConnectionFactory)->createLazyConnection(); $promise = $connection->query('UPDATE users SET ...'); $promise->then( function (QueryResult $command) { echo count($command->resultRows) . ' row(s) in set.'; }, function (Exception $error) { echo 'Error: ' . $error->getMessage(); });
Все почти также, как мы написали: создаем
Сonnection и выполняем запрос. Можем установить колбэк для обработки результатов (вернуть affected rows):function (QueryResult $command) { echo count($command->resultRows) . ' row(s) in set.'; },
и колбэк для обработки ошибок:
function (Exception $error) { echo 'Error: ' . $error->getMessage(); });
Из этих колбэков можно строить длинные-длинные цепочки, потому что каждый результат
then в ReactPHP также возвращает Promise.$promise ->then(function ($data) { return new Promise(...); }) ->then(function ($data) { ... }, function ($error) { log($error); }) ...
Это решение проблемы, которая называется «callback hell». К сожалению, в реализации ReactPHP это приводит к проблеме «Promise hell», когда для корректного подключения RabbitMQ, требуется10-11 колбэков. Работать с таким кодом и исправлять его сложно. Я быстро понял, что это не мое и перешел на AMPHP.
AMPHP
Этот проект младше, чем ReactPHP, и продвигает иную концепцию — корутины. Если посмотреть на работу с MySQL в AMPHP, то видно, что это почти аналогично работе с
PDOConnection в PHP.$pool = Mysql\pool("host=127.0.0.1 port=3306 db=test"); try { $result = yield $pool->query("UPDATE users SET ..."); echo $result->affectedRows . ' row(s) in set.'; } catch (\Throwable $error) { echo 'Error: ' . $error->getMessage(); }
Здесь мы создаем пул, подключаемся и выполняем запрос. Мы можем обрабатывать ошибки через привычные
try...catch, нам не нужны колбэки.Но перед асинхронным вызовом здесь появляется ключевое слово —
yield.Генераторы
Ключевое слово
yield превращает нашу функцию в генератор.function generator($counter = 1) { yield $counter++; echo "A"; yield $counter; echo "B"; yield ++$counter; }
Как только интерпретатор PHP встречает
yield в теле функции, он понимает, что это функция-генератор. Вместо выполнения при вызове создается объект класса Generator.Генераторы наследуют интерфейс итератора.
$generator = generator(1); foreach ($generator as $value) { echo $value; } while ($generator->valid()) { echo $generator->current(); $generator->next(); }
Соответственно, по ним можно пробежаться циклами
foreach и while и другими. Но, что интереснее, в итераторе есть методы current и next. Пройдемся по ним пошагово. Запустим нашу функцию
generator($counter = 1). Вызовем у генератора метод current(). Вернется значение переменной $counter++.Как только выполним генератор
next(), внутри генератора код перейдет к следующему вызову yield. Весь участок кода между двумя yield выполнится, и это круто. Продолжая раскручивать генератор, получим результат.Корутины
Но у генератора есть функция интереснее — мы можем снаружи отправить данные в генератор. В этом случае это уже не совсем генератор, а корутина или сопрограмма.
function printer() { while (true) { echo yield; } } $print = printer(); $print->send('Hello'); $print->send(' PHPRussia'); $print->send(' 2019'); $print->send('!');
В данном участке кода интересно, что
while (true) не заблокирует поток выполнения, а выполнится один раз. Мы отправили данные в корутину и получили 'Hello'. Отправили еще — получили 'PHPRussia'. Принцип понятен.Кроме отправки данных в генератор можно отправлять ошибки и обрабатывать их изнутри, что удобно.
function printer() { try { echo yield; } catch (\Throwable $e) { echo $e->getMessage(); } } printer()->throw(new \Exception('Ooops...'));
Подытожим. Корутина это компонент программы, который поддерживает остановку и продолжение выполнения с сохранением текущего состояния. Корутина помнит свой стек вызовов, данные внутри, и может их использовать в дальнейшем.
Генераторы и Promise
Посмотрим на интерфейсы генераторов и Promise.
class Generator { public function send($data); public function throw(\Throwable $error); } class Promise { public function resolve($data); public function reject(\Throwable $error); }
Они выглядят одинаково, за исключением разных названий методов. Мы можем отправить данные и выкинуть ошибку и в генератор, и в Promise.
Как это можно использовать? Напишем функцию.
function recoil(\Generator $generator) { $promise = $generator->current(); $promise->onResolve(function($data) use ($generator) { $generator->send($data); recoil($generator); }; $promise->onReject(function ($error) use ($generator) { $generator->throw($error); recoil($generator); }); }
Функция берет у генератора текущее значение:
$promise = $generator->current();.Я немного утрировал. Да, мы должны проверить, что текущее значение, которое нам вернулось это какой-то
instanceof Promise. Если это так, то мы можем ему задать колбэк. Он внутри отправит данные обратно в генератор, когда Promise успешно выполнится и рекурсивно запустит функцию recoil.$promise->onResolve(function($data) use ($generator) { $generator->send($data); recoil($generator); };
То же можно провернуть и с ошибками. Если Promise завершился с ошибкой, например, SQL-сервер сказал: «Too many connections», то можем выкинуть ошибку внутрь генератора и перейти на следующий шаг.
Все это подводит нас к важному понятию кооперативной многозадачности.
Кооперативная многозадачность
Это тип многозадачности, при котором следующая задача выполняется только после того, как текущая задача явно объявит себя готовой отдать процессорное время другим задачам.
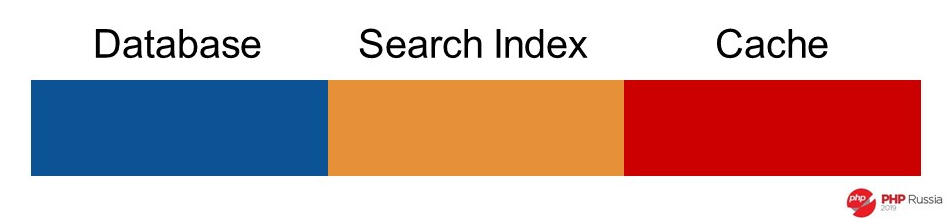
Я редко встречаюсь с чем-то простым как, например, работа только с одной БД. Чаще всего в процессе обновления пользователя надо обновить данные в БД, в поисковом индексе, потом почистить или обновить кэш, а после еще отправить 15 сообщений в RabbitMQ. В PHP это все выглядит так.
Мы выполняем операции одну за одной: обновили базу, индекс, потом кэш. Но по умолчанию PHP блокирует на таких операциях (I/O), поэтому, если приглядеться, на самом деле все так.
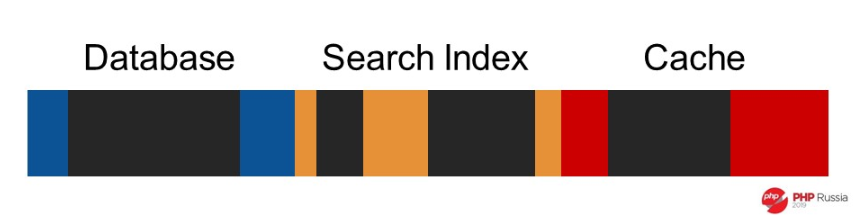
На темных частях мы заблокировались. Они занимают больше всего времени.
Если мы работаем в асинхронном режиме, то этих частей нет, таймлайн выполнения прерывистый.
Можно все это склеить и выполнять кусочки один за одним.
Для чего все это? Если посмотреть на размер таймлайна, то сначала он занимает много времени, но как только мы склеиваем — приложение ускоряется.
Сама концепция Event Loop и кооперативной многозадачности давно применяется в различных приложениях: Nginx, Node.js, Memcached, Redis. Все они используют внутри Event Loop и построены на этом же принципе.
Раз уж мы начали говорить о веб-серверах Nginx и Node.js, давайте вспомним, как происходит обработка запросов в PHP.
Обработка запроса в PHP
Браузер отправляет запрос, он попадает на HTTP-сервер за которым стоит пул FPM-потоков. Один из потоков берет в работу этот запрос, подключает наш код и начинает его выполнять.
Когда приходит следующий запрос, другой FPM-поток его заберет, подключит код и он будет выполняться.
В этой схеме работы есть плюсы.
- Простая обработка ошибок. Если что-то пошло не так и один из запросов упал, нам не нужно ничего делать — придет следующий, и это никак не повлияет на его работу.
- Не думаем о памяти. Нам не нужно чистить память или следить за ней. На следующем запросе вся память очистится.
Это крутая схема, которая работала в PHP с самого начала и до сих пор работает успешно. Но в ней есть и минусы.
- Ограничение количества процессов. Если у нас 50 FPM-потоков на сервере, то как только придет 51-й запрос, он будет ждать, пока один из потоков освободится.
- Затраты на Context Switch. ОС переключает запросы между FPM-потоками. Эта операция на уровне процессора называется Context Switch. Она дорогая и выполняется огромное количество тактов. Надо сохранить все регистры, стек вызовов, все, что есть в процессоре, потом переключиться на другой процесс, загрузить его регистры и его стек вызовов, опять там что-то выполнить, опять переключиться, опять сохранить… Долго.
Подойдем к вопросу иначе — напишем HTTP-сервер на самом PHP.
Асинхронный HTTP-сервер
Это можно сделать. Мы уже научились работать с сокетами в неблокирующем режиме, а HTTP-соединение это такой же сокет. Как он будет выглядеть и работать?
Это пример старта HTTP-серверов в фреймворке AMPHP.
Loop::run(function () { $app = new Application(); $app->bootstrap(); $sockets = [Socket\listen('0.0.0.0:80')]; $server = new Server($sockets, new CallableRequestHandler( function (Request $request) use ($app) { $response = yield $app->dispatch($request); return new Response(Status::OK, [], $response); }) ); yield $server->start(); });
Все достаточно просто: загружаем
Application и создаем пул сокетов (один или несколько).Дальше запускаем наш сервер, устанавливаем
Handler, который будет выполняться на каждый запрос и передавать запрос нашему Application, чтобы получить ответ.Последнее, что надо сделать — запустить сервер —
yield $server->start();.В ReactPHP это будет выглядеть приблизительно также, но только там будет 150 колбэков на разные варианты, что не очень удобно.
Проблемы
С асинхронностью в PHP есть несколько проблем.
Отсутствие стандартов. Каждый фреймворк: Swoole, ReactPHP или AMPHP, реализует свой интерфейс Promise, и они несовместимы.
AMPHP теоретически может взаимодействовать с Promise от ReactPHP, но есть нюанс. Если код для ReactPHP написан не очень грамотно, и где-то неявно вызывает или создает Event Loop, то получится так, что внутри будут крутиться два Event Loop.
Есть относительно хороший стандарт Promises/A+ у JavaScript, который реализует Guzzle. Было бы хорошо, если фреймворки будут ему следовать. Но пока этого нет.
Утечки памяти. Когда мы работаем в PHP в обычном FPM-режиме, то про память можем не думать. Даже если разработчики какого-то расширения забыли написать хороший код, забыли прогнать через Valgrind, и где-то внутри память течет, то ничего страшного — на следующем запросе очистится и начнется заново. Но в асинхронном режиме такое себе позволить нельзя, потому что рано или поздно мы просто упадем с
OutOfMemoryException.Чинить это возможно, но сложно и больно. В одних случаях помогает Xdebug, в других strace для разбора ошибок, которые вызвал
OutOfMemoryException.Блокирующие операции. Жизненно важно не блокировать Event Loop когда мы пишем асинхронный код. Приложение замедляется как только мы блокируем поток выполнения, каждая из наших корутин начинает работать медленней.
Найти такие операции для AMPHP поможет пакет kelunik/loop-block. Он выставляет таймер на очень маленький интервал. Если таймер не срабатывает, значит мы где-то заблокировались. Пакет помогает в поиске блокирующих мест, но не всегда: блокировки в некоторых расширениях может не заметить.
Поддержка библиотек: Cassandra, Influx, ClickHouse. Основная проблема всего асинхронного PHP это поддержка библиотек. Мы не можем использовать всем привычные
PDOConnection, RedisClient, другие драйверы — нам нужны неблокирующие реализации. Писать их надо тоже на PHP в неблокирующем режиме, потому что драйверы на C редко предоставляют интерфейсы, которые можно интегрировать в асинхронный код.Самый странный опыт я получил с драйвером для БД Cassandra. Они предоставляют операции
ExecuteAsync, GetAsync и прочие, но при этом возвращают объект Future с единственным методом get, который блокирует. Возможность что-то получить асинхронно есть, но, чтобы дождаться результата, мы все равно заблокируем весь наш Loop. Сделать это как-то иначе, например, через колбэки, не получается. Я даже написал свой клиент для Cassandra, потому что мы ее используем в работе.Указание типа. Это проблема AMPHP и корутин.
class UserRepository { public function find(int $id): \Generator { $data = yield $this->db->query('SELECT ...', $id); return User::fill($data); } }
Если в функции встречается
yield, то она становится генератором. В этот момент мы уже никак не можем указать правильные возвращаемые типы данных.PHP 8
Что нас ждет в PHP 8? Расскажу о своих предположениях или, скорее, желаниях (прим. ред.: Дмитрий Стогов знает, что на самом деле появится в PHP 8).
Event Loop. Есть шанс, что он появится, потому что ведется работа над тем, чтобы внести Event Loop в каком-то виде в ядро. Если это произойдет, у нас появится функция
await, как в JavaScript или C#, которая позволит дождаться результата асинхронной операции в определенном месте. При этом нам будут не нужны никакие расширения, все будет асинхронно работать на уровне ядра.class UserRepository { public function find(int $id): Promise<User> { $data = await $this->db->query('SELECT ...', $id); return User::fill($data); } }
Generics. В Go ждут Generics, мы ждем Generics, все ждут Generics.
class UserRepository { public function find(int $id): Promise<User> { $data = yield $this->db->query('SELECT ...', $id); return User::fill($data); } }
Но мы ждем Generics не для коллекций, а чтобы указать, что результатом выполнения Promise будет именно объект User.
Зачем все это?
Ради скорости и производительности.PHP — это язык, в котором большая часть операций это I/O bound. Мы редко пишем код, который значительно завязан на вычислениях в процессоре. Скорее всего, у нас это работа с сокетами: надо сделать запрос в базу, что-то прочитать, вернуть ответ, отправить файл. Асинхронность позволяет ускорить такой код. Если посмотреть среднее время ответов на 1000 запросов, мы можем ускориться примерно в 8 раз, а на 10 000 запросов почти в 6!
13 мая 2020 года мы во второй раз соберемся на PHP Russia, чтобы обсудить язык, библиотеки и фреймворки, способы увеличения производительности и подводные камни хайповых решений. Мы приняли первых 4 доклада, но Call for Papers еще идет. Подавайте заявки, если хотите поделиться с сообществом своим опытом.

