2018 год стал переломной точкой для развития моделей машинного обучения, направленных на решение задач обработки текста (или, что более корректно, обработки естественного языка (Natural Language Processing, NLP)). Быстро растет концептуальное понимание того, как представлять слова и предложения для наиболее точного извлечения их смысловых значений и отношений между ними. Более того, NLP-сообщество продвигает невероятно мощные инструменты, которые можно бесплатно скачать и использовать в своих моделях и пайплайнах. Эту переломную точку также называют NLP’s ImageNet moment, ссылаясь на тот момент несколько лет назад, когда схожие разработки значительно ускорили развитие машинного обучения в области задач компьютерного зрения.
(ULM-FiT не имеет ничего общего с Коржиком, но что-то лучше не пришло в голову)
Одна из последних основополагающих разработок в этой сфере – это релиз BERT'а, событие, которое положило начало новой эре в NLP. BERT – это модель, побившая несколько рекордов по успешности решения ряда NLP-задач. Вскоре после выхода статьи, описывающей модель, команда разработчиков также выложила в открытый доступ код модели и сделала возможным скачивание различных версий BERT'а, которые уже были предобучены на больших наборах данных. Этот знаменательный шаг позволил любому разработчику встраивать в свои модели машинного обучения для обработки естественного языка уже готовый мощный компонент, сохраняя свои время, энергию и ресурсы, необходимые для обучения модели обработки языка с нуля.
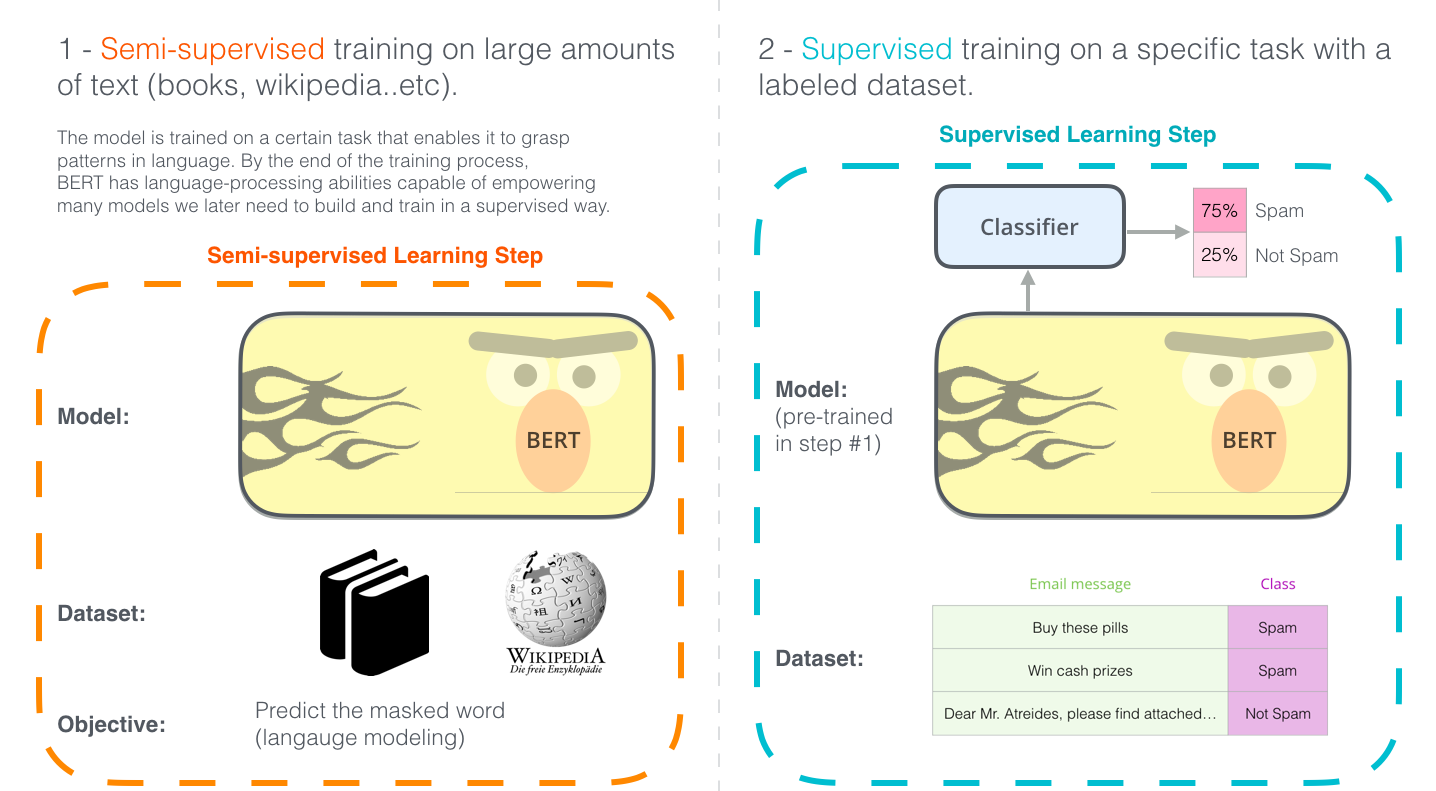
Разработка BERT'а. Шаг 1: скачивание модели (предобученной на неразмеченных данных); Шаг 2: тонкая настройка модели.
BERT построен на целом ряде недавних разработок, предложенных NLP-сообществом, включая, но не ограничиваясь: Semi-supervised Sequence learning (авторы – Andrew Dai и Quoc Le), ELMo (авторы – Matthew Peters и исследователи из AI2 и UW CSE), ULMFiT (авторы – основатель fast.ai Jeremy Howard и Sebastian Ruder), OpenAI Transformer (авторы – исследователи OpenAI Radford, Narasimhan, Salimans, и Sutskever) и Трансформер (Vaswani et al).
Обозначим некоторые понятия, которые необходимо знать для того, чтобы как следует изучить BERT'а. Начнем с понятий, относящихся к применению этой модели, а затем заглянем к ней под капот.
Пример: Классификация предложений
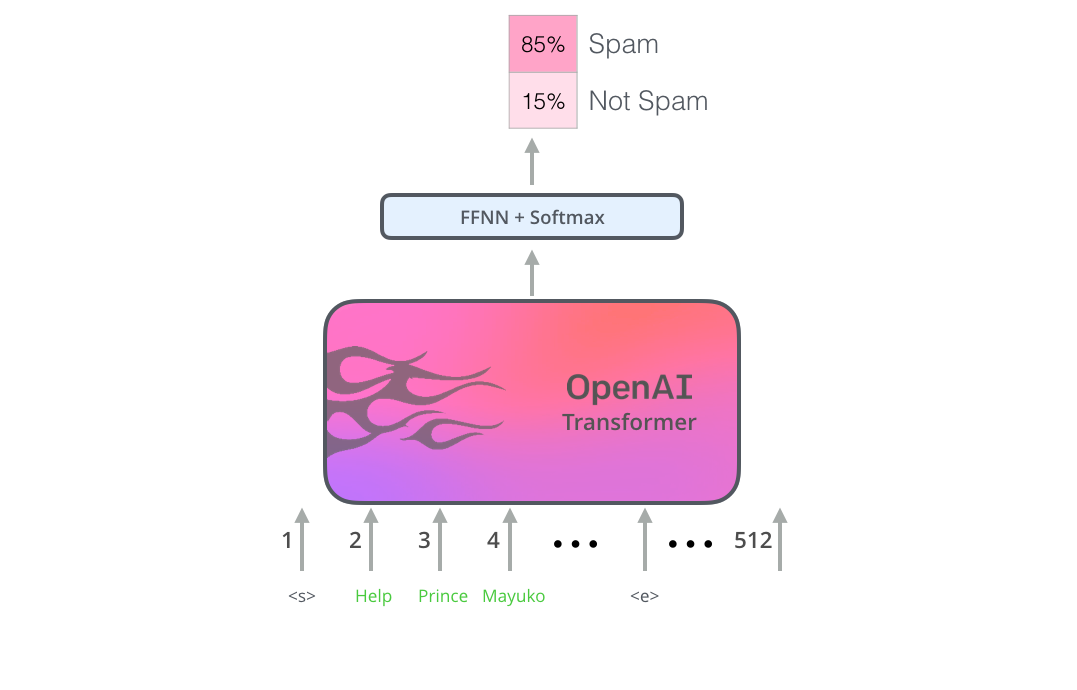
Наиболее очевидный способ использовать BERT – это классификация фрагмента текста. Такая модель может выглядеть следующим образом:
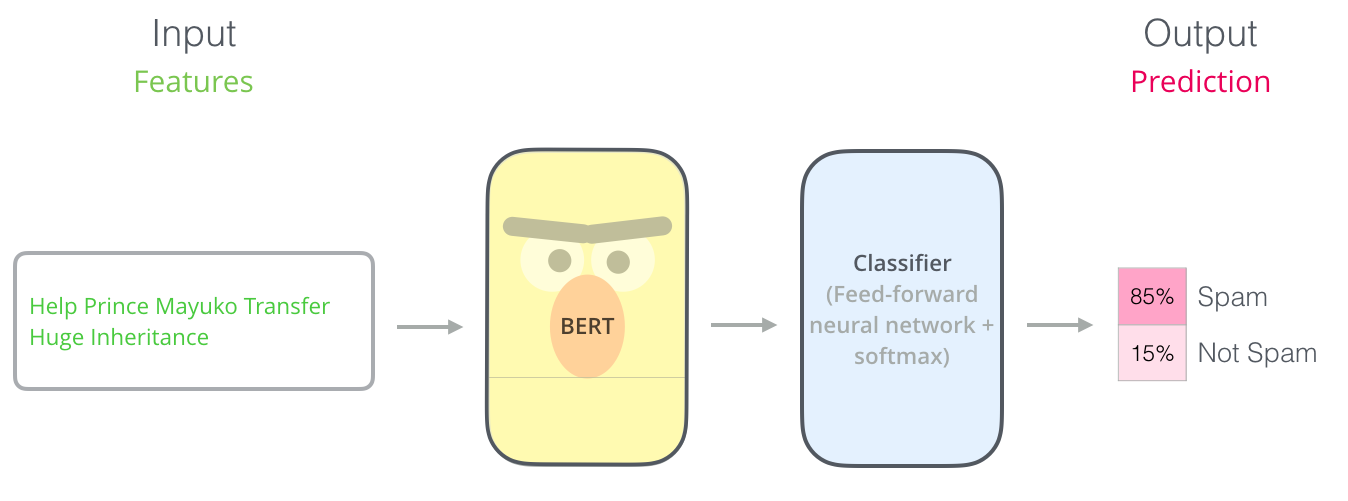
Для обучения модели необходимо, по большей части, только обучить классификатор (classifier) с минимальными изменениями в самой модели BERT'а во время фазы обучения. Такой процесс обучения называется тонкой настройкой (fine-tuning), корни которой лежат в статье Semi-supervised Sequence Learning и модели ULMFiT.
Для людей, не погруженных в тему: использование классификатора означает, что мы находимся в сфере машинного обучения с учителем. Для обучения такой модели необходим размеченный набор данных. В случае классификатора спама размеченным набором данных будет список почтовых сообщений и их классов («спам» или «не спам»).

Другие примеры использования BERT'а:
- Анализ тональности (sentiment analysis)
- Вход: отзыв на фильм/продукт. Выход: положительная/отрицательная тональность
- Пример набора данных: SST
- Проверка фактов (fact-checking):
- Вход: предложение. Выход: «утверждение» (Claim) или «не утверждение» (Not Claim)
- Более амбициозный/футуристичный пример:
- Вход: предложение с утверждением (Claim sentence). Выход: «Правда» или «Ложь»
- Full Fact – организация, разрабатывающая автоматические фактчекеры для общественной пользы. Частью их пайплайна является классификатор, который читает новостные статьи и распознает сомнительные факты, которые затем могут быть проверены (пока человеком, позже, возможно, с помощью машинного обучения)
- Видео: Эмбеддинги предложений для автоматической проверки фактов
Архитектура модели
Теперь, после того как мы познакомились с примерами использования BERT'а, посмотрим, как он работает.

Релизная статья описывает две модели BERT'а разных размеров:
- BERT BASE (Базовая) – сравнимая по размерам и производительностью с OpenAI Transformer;
- BERT LARGE (Расширенная) – поистине громадная модель, которая достигла непревзойденных результатов (state of the art), описанных в статье.
По сути, BERT – это обученный стек энкодеров Трансформера. См. предыдущую статью, описывающую принципы работы модели Трансформера – основополагающего для BERT’а понятия и концептов, о которых мы будем говорить далее.
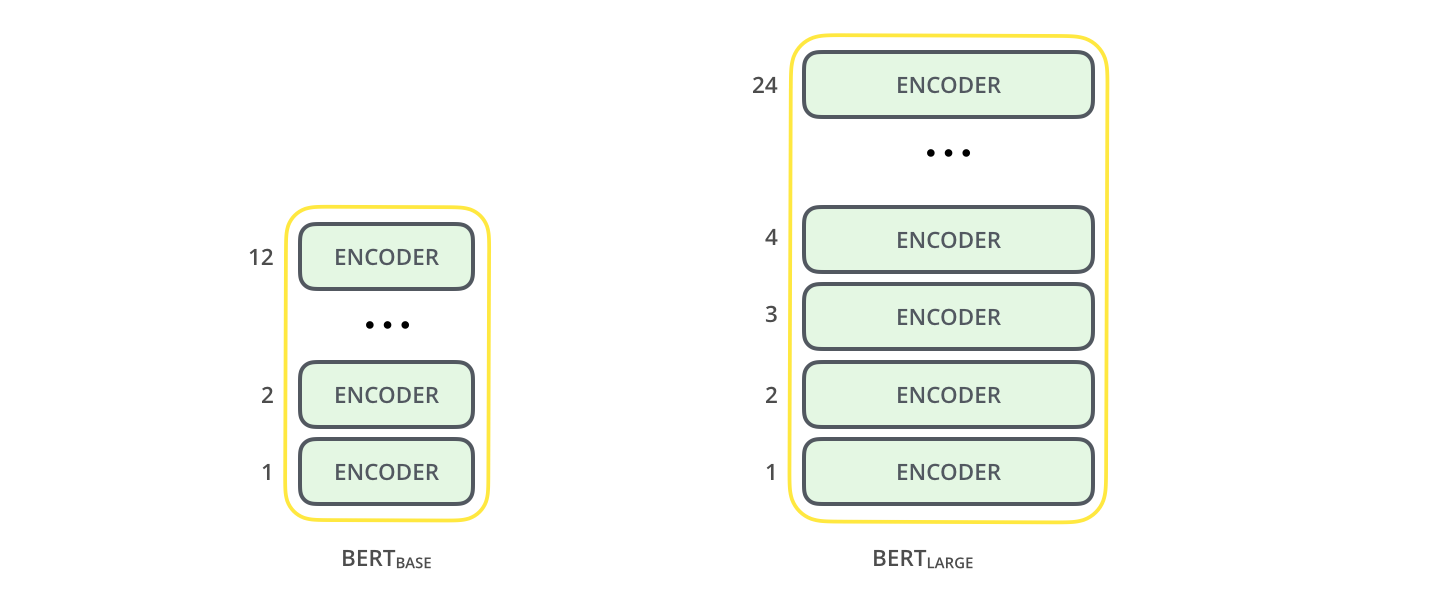
У обеих моделей BERT'а есть большое количество слоев энкодера (которые в статье называются «блоками Трансформера» (Transformer Blocks)): 12 для базовой версии и 24 для расширенной. Они также имеют более крупные слои сети прямого распространения (768 и 1024 скрытых нейронов соответственно) и больше «голов» внимания (attention heads)(12 и 16 соответственно), чем в базовой конфигурации Трансформера, описанной в исходной статье (6 слоев энкодера, 512 скрытых нейронов, 8 «голов» внимания).
Входы модели
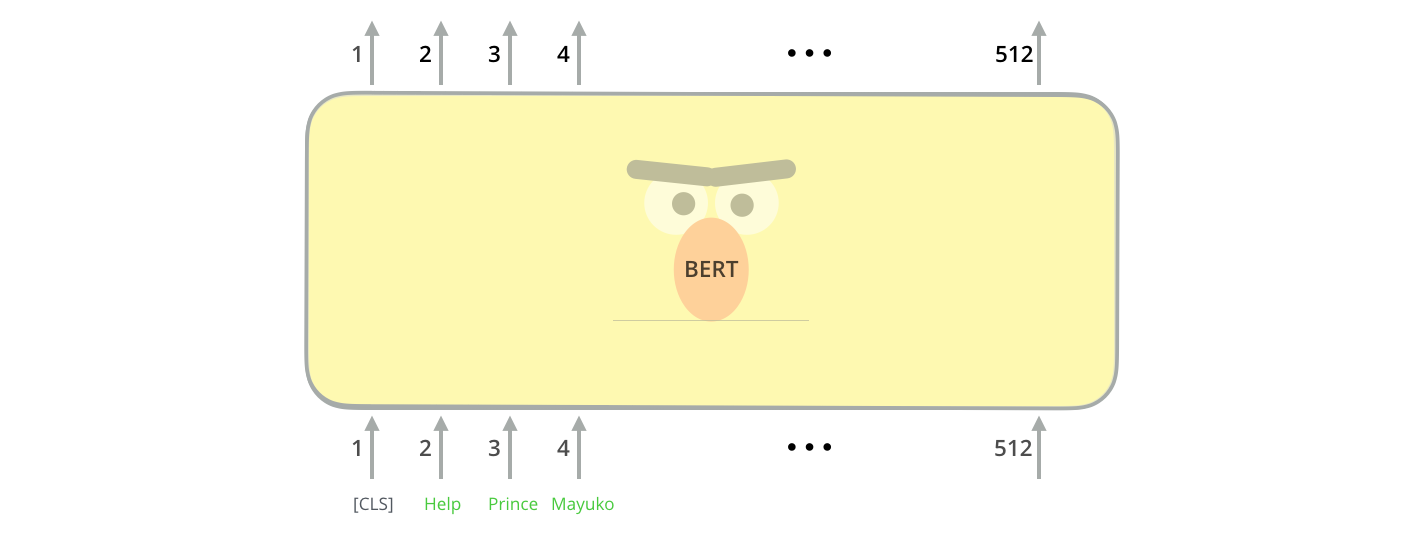
Первый входной токен поступает вместе со специальным токеном [CLS] по причинам, о которых мы скажем позднее. CLS в данном случае означает классификацию.
Точно так же, как и в обычном Трансформере, BERT принимает на вход последовательность слов, которая затем продвигается вверх по стеку экодеров. Каждый слой энкодера применяет внутреннее внимание (self-attention) и передает результаты в сеть прямого распространения, после чего направляет его следующему энкодеру.
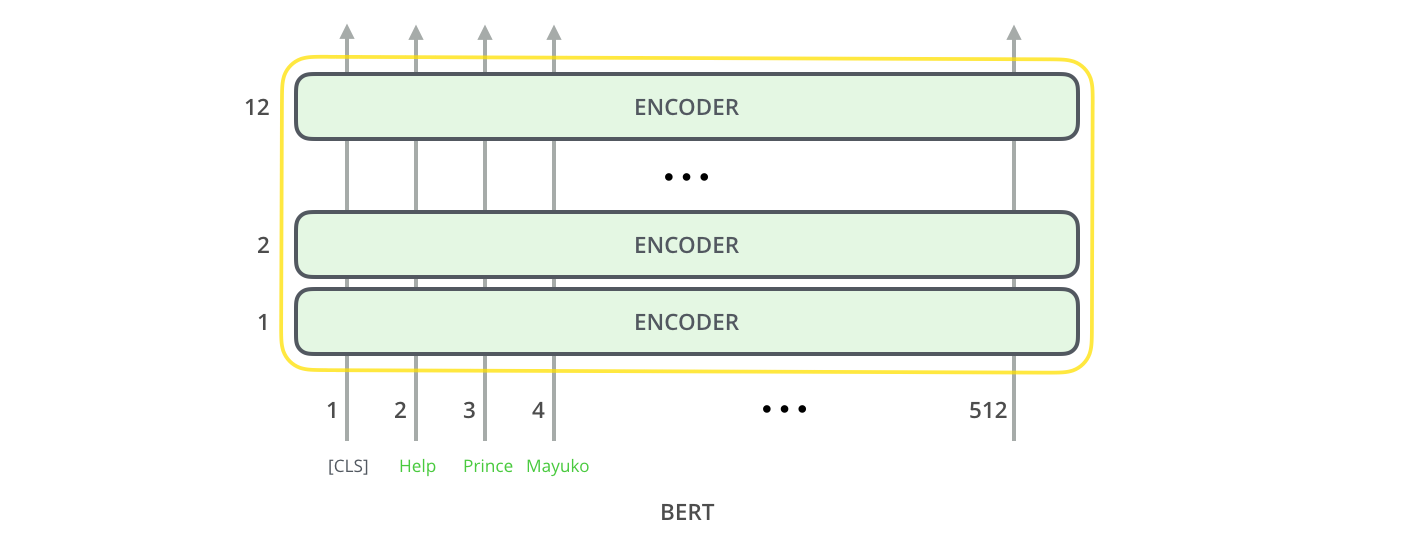
С точки зрения архитектуры, данный процесс идентичен Трансформеру вплоть до следующего этапа (если не учитывать размер, который является настраиваемым параметром). Но относительно выходов эти две модели значительно отличаются.
Выходы модели
Для каждой позиции на выход подается вектор размерностью hidden_size (768 в базовой модели BERT'а). Для примера классификации предложения, который мы рассматривали выше, сфокусируемся на выходе только первой позиции (в которую мы передали специальный токен [CLS]).
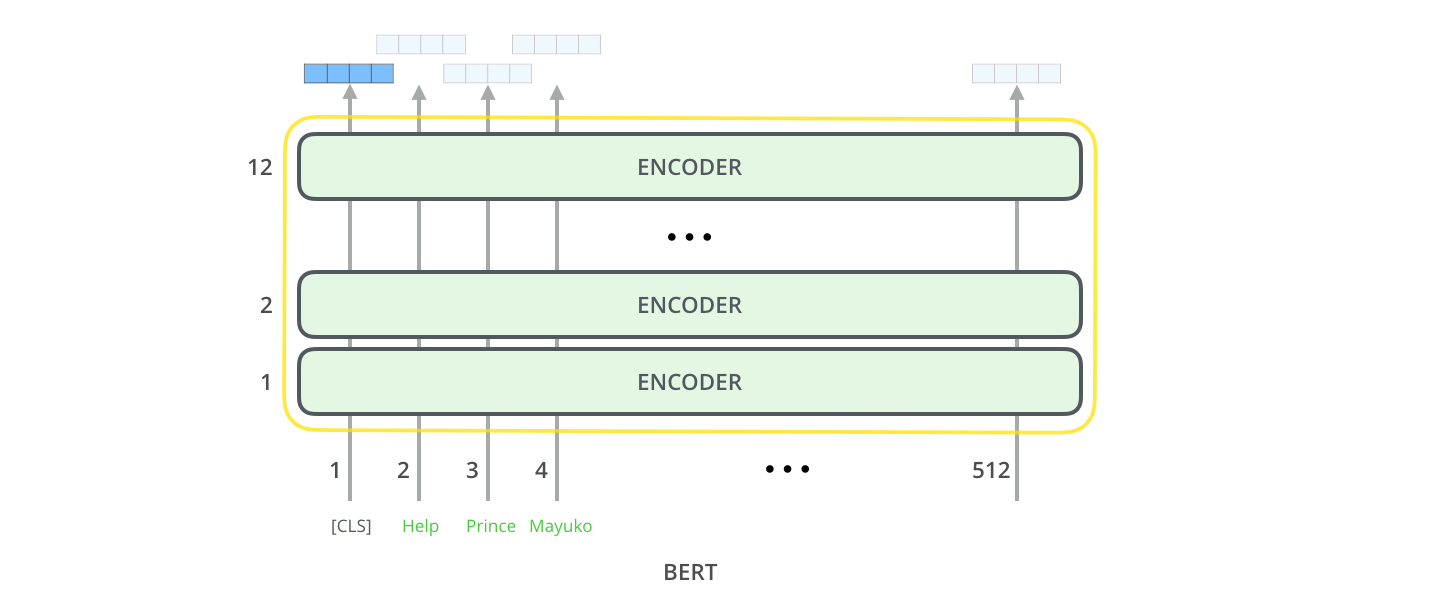
Этот вектор может быть использован как входной вектор для выбранного нами классификатора. Авторы статьи смогли добиться отличных результатов, используя в качестве классификатора нейронную сеть всего с одним слоем.
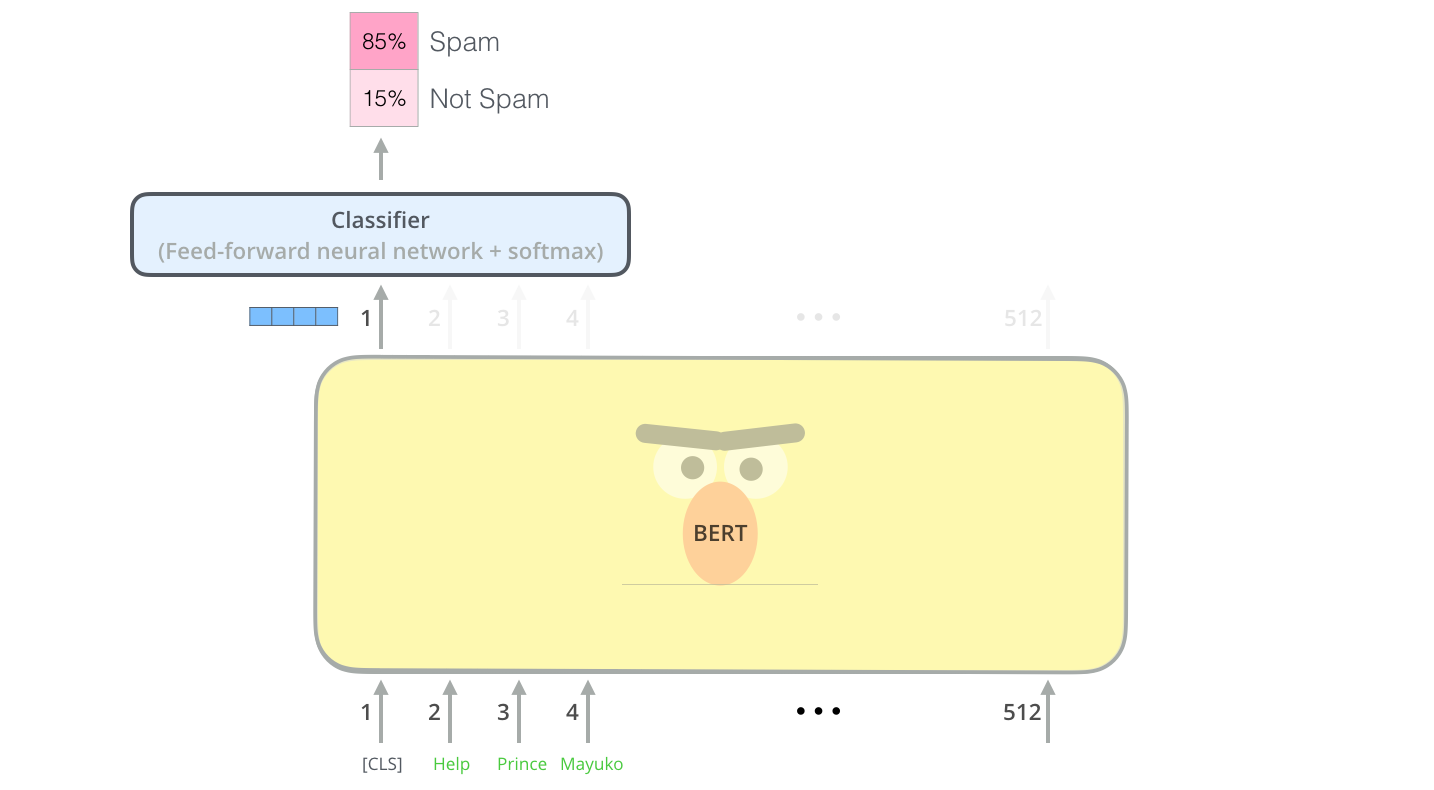
Если у вас больше чем две метки (например, если почтовый клиент сортирует письма на «спам», «не спам», «социальные сети», «предложения» и др.), нужно просто добавить в нейронную сеть классификатора больше выходных нейронов и пропустить их через софтмакс.
Параллели со сверточными сетями
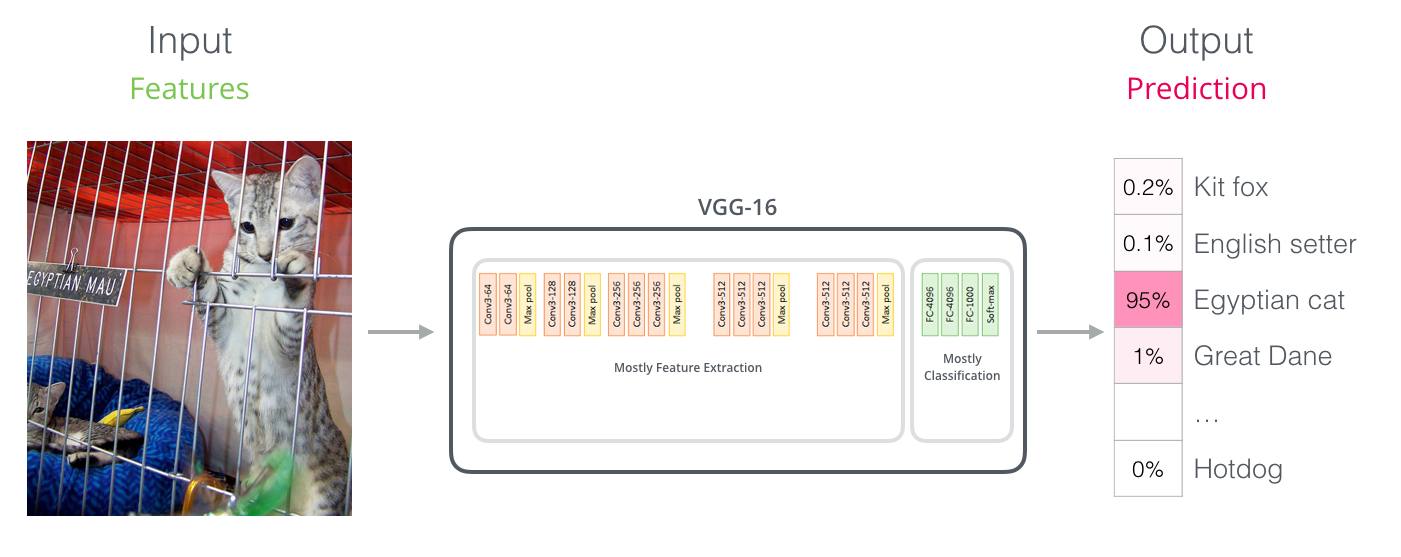
Для тех, кто знаком с компьютерным зрением, эта передача векторов может напоминать то, что происходит между сверточной частью сети типа VGGNet и ее классификационными полносвязными слоями.
Новая эра эмбеддингов
Рассмотренные новые разработки несут с собой переворот в кодировании слов. Ранее основной силой, с помощью которой NLP-модели могли иметь дело с языком, были эмбеддинги слов: широко использовались для подобных задач методы вроде Word2Vec и GloVe. Поэтому для начала поясним, как использовать данные методы, а затем посмотрим на то, что изменилось.
Краткий обзор механизма эмбеддингов слов
Для обработки слов с помощью моделей машинного обучения необходима некая форма числового представления этих слов, которую модели могли бы использовать в своих вычислениях. Word2Vec показал, что мы можем использовать вектор (набор чисел), чтобы представлять слова в виде, который может передавать их семантику или смысловые отношения (т.е. способность различать схожие и противоположные по смыслу слова или находить параллели в отношениях таких словарных пар, как «Стокгольм» – «Швеция» и «Каир» – «Египет»), а также синтаксические или грамматические отношения (например, определять, что отношение между «имел» и «иметь» такое же, как между «был» и «быть»).
Сообщество быстро осознало, что лучше всего использовать эмбеддинги, предобученные на больших объемах текста, чем обучать их вместе с моделью на зачастую достаточно маленьком наборе данных. Стало возможным загружать списки слов и их эмбеддингов, созданных с помощью предварительного обучения Word2Vec или GloVe. Так выглядит пример эмбеддинга в GloVe для слова «stick» (где размерность эмбеддинга – 200):

Эмбеддинг слова «stick» из модели GloVe – вектор из 200 чисел с плавающей точкой (округленных до 2 знака после запятой).
Для удобства в данной статье такие большие вектора будут изображаться схематично в виде нескольких квадратиков одного цвета.
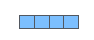
ELMo: контекст имеет значение
Если мы используем представление GloVe, то слово «stick» будет представлено этим вектором вне зависимости от контекста. «Подождите минутку», – сказали некоторые NLP-исследователи (а именно Peters et. al., 2017, McCann et. al., 2017 и снова Peters et. al., 2018 в статье про ELMo). – «Слово «stick» имеет множество значений в зависимости от того, где оно используется. Почему бы не дать ему эмбеддинг на основе контекста, в котором оно стоит – для того, чтобы передавать не только значение слова, но и контекстуальную информацию?». Так появились контекстуализированные эмбеддинги (contextualized word-embeddings).

Контекстуализированные эмбеддинги дают словам разные вектора на основе их семантики в контексте предложения.
Вместо того, чтобы использовать фиксированные эмбеддинги слов, ELMo смотрит на целое предложение, прежде чем присвоить каждому слову его эмбеддинг. Она использует двунаправленную модель долгой краткосрочной памяти (bi-directional LSTM), обученную специально под задачу создания таких эмбеддингов.
ELMo стала значительным шагом к предварительному обучению в области NLP. Если ELMo LSTM обучалась на большом наборе текстов на целевом для нас языке, мы можем использовать ее как компонент других моделей, предназначенных для обработки естественного языка.
В чем секрет ELMo?
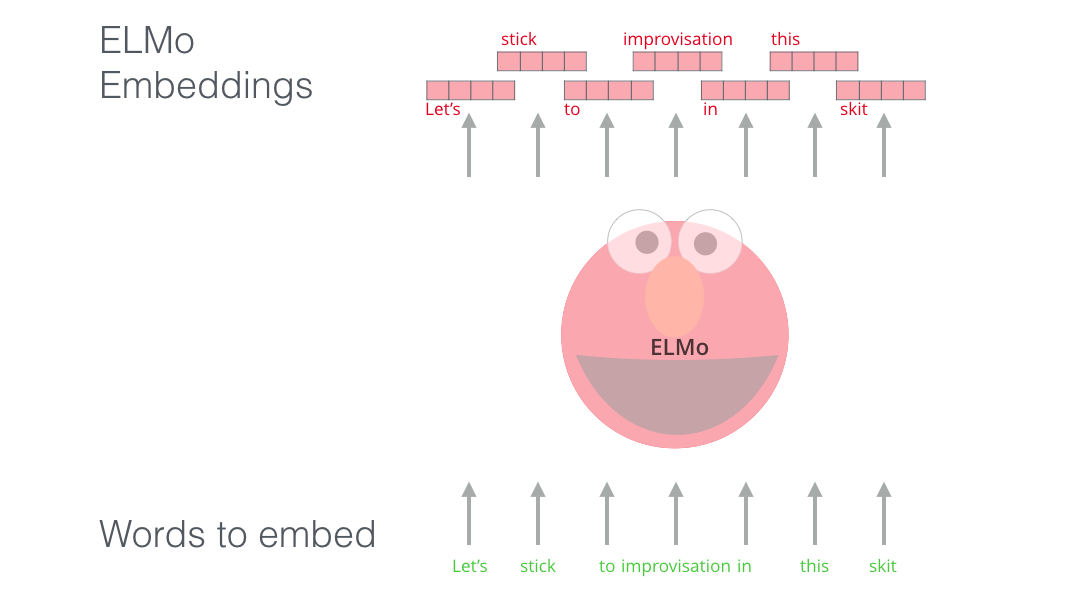
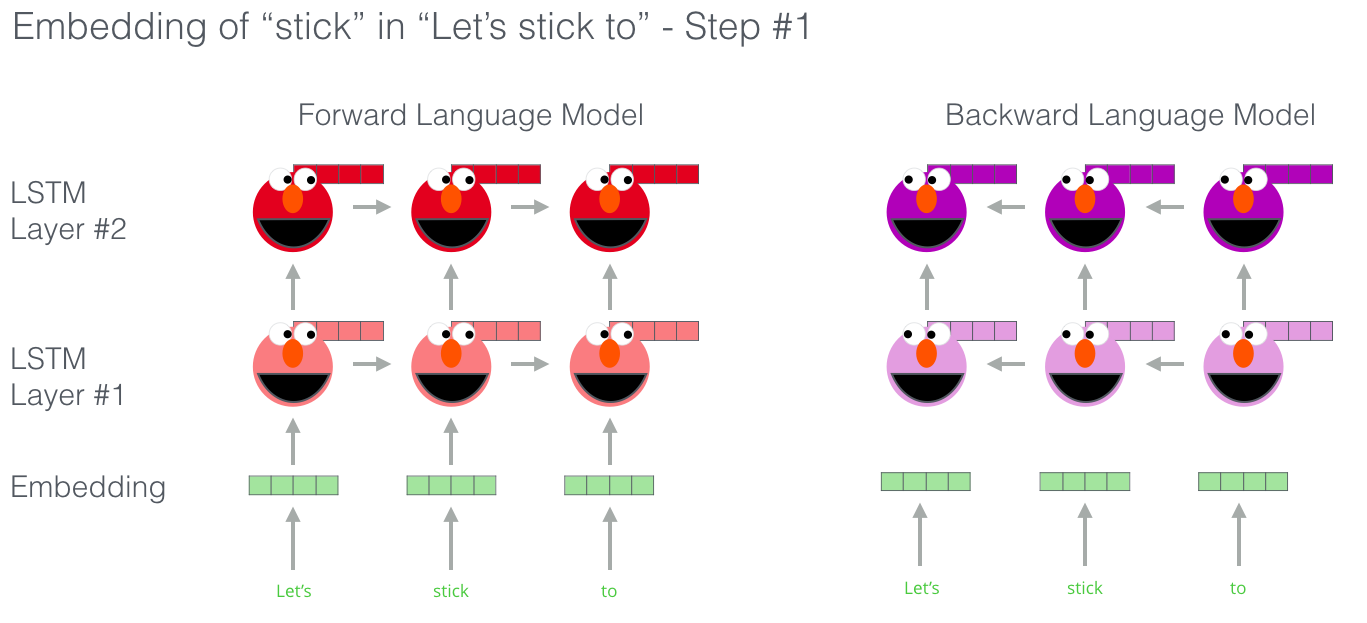
Способность понимать язык ELMo получила после обучения предсказыванию нового слова в последовательности слов – задача, называющаяся языковым моделированием (language modeling). Это удобно, потому что мы располагаем большими объемами текстовых данных, на которых модель может учиться без необходимости их разметки.
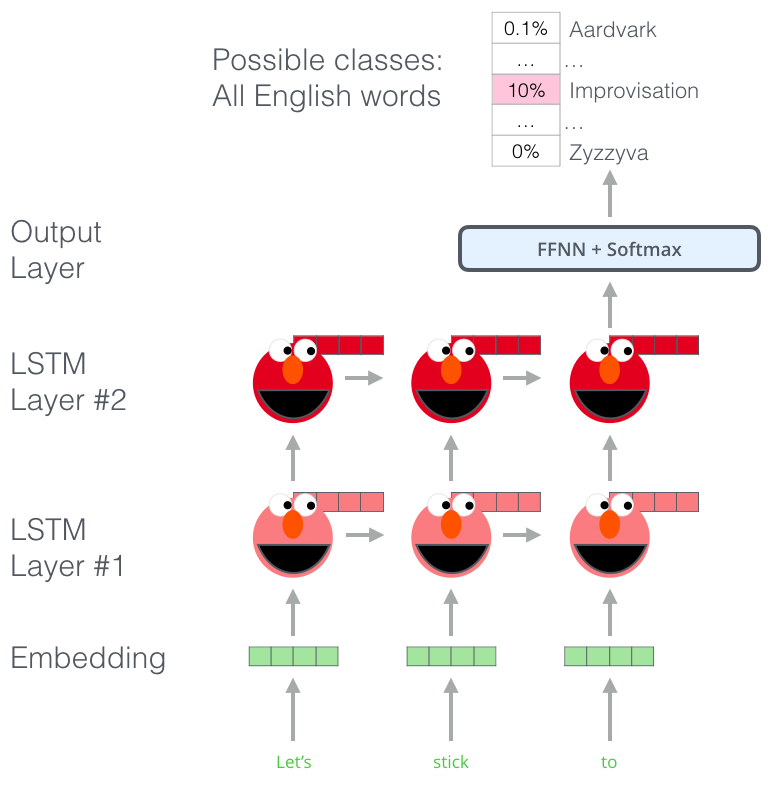
Этап в предварительном обучении ELMo: имея на входе последовательность «Let's stick to», мы должны предсказать следующее наиболее вероятное слово – задача языкового моделирования. Во время обучения на большом наборе данных модель начинает усваивать языковые конструкции. Маловероятно, что она верно отгадает следующее слово в данном примере. Более реалистично, что после такого слова, как, например, «hang», модель присвоит большую вероятность слову вроде «out» (для получения словосочетания «hang out»), чем слову «camera».
На изображении видно, как скрытые состояния каждого слоя LSTM выглядывают из-за головы ELMo. Они пригодятся далее в процессе создания эмбеддингов, после того как будет завершено предварительное обучение.
На самом деле, ELMo идет на шаг дальше и обучает двунаправленную LSTM – так, что языковая модель «чувствует» не только следующее слово, но также и предыдущее.
Отличная презентация про ELMo
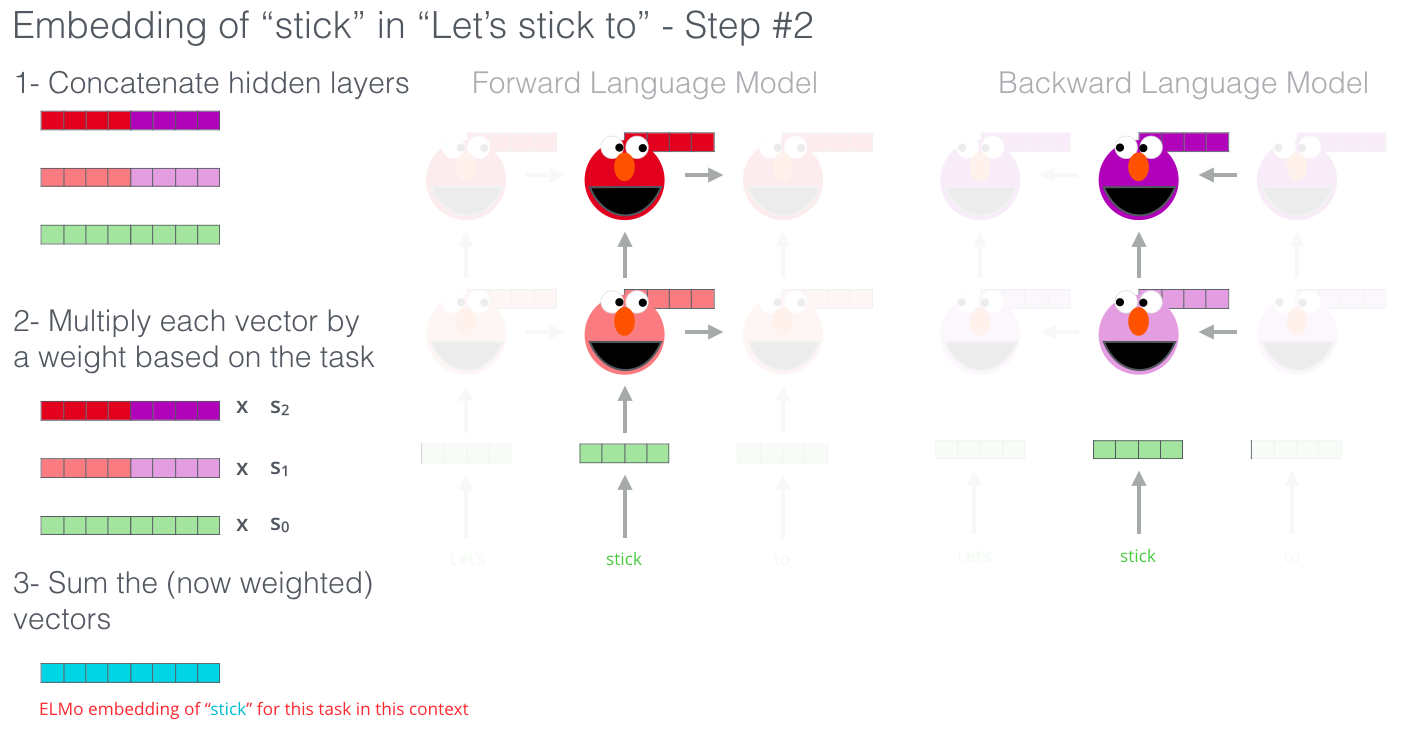
ELMo создает контекстуализированный эмбеддинг посредством группировки скрытых состояний (и начального эмбеддинга) определенным образом (конкатенация следует за взвешенным сложением).
ULM-FiT: внедряя трансферное обучение в NLP
ULM-FiT предоставил методы для эффективного использования того, чему модель учится во время предварительного обучения – больше чем просто эмбеддинги или контекстуализованные эмбеддинги. ULM-FiT представил языковую модель и процесс для эффективной тонкой настройки этой модели для различных задач.
NLP наконец получил способ осуществлять трансферное обучение, возможно, столь же успешно, как оно применяется для задач компьютерного зрения.
Трансформер: выходя за пределы LSTM сетей
Релиз статьи и кода, знакомящих общественность с Трансформером, а также результаты, которых ему удалось достичь в задачах машинного перевода, заставили некоторых людей из NLP-сообщества задуматься над заменой LSTM. Основным аргументом стала способность Трансформеров лучше справляться с долгосрочными зависимостями.
Структура энкодер-декодер Трансформера идеально подходит для задач машинного перевода. Но чем она может помочь в задачах классификации предложений? И как ее использовать для предварительного обучения языковой модели, которую можно настроить на другие прикладные задачи (т.е. задачи для обучения с учителем, использующие предобученные модели или компоненты)?
OpenAI Transformer: предварительное обучение декодера Трансформера для языкового моделирования
Как оказалось, нам не нужен целый Трансформер, чтобы применить трансферное обучение и настраиваемую языковую модель для NLP-задач. Мы можем сделать это лишь на декодере Трансформера. Это не случайный выбор: декодер маскирует будущие токены, что отлично подходит для задачи языкового моделирования (предсказывания следующего слова).

OpenAI Transformer состоит из стека декодеров Трансформера
Модель состоит из 12 слоев декодера. В отсутствии энкодеров эти декодирующие слои не будут иметь энкодер-декодер подслой внимания, который использует обычный декодер Трансформера. Однако, они все еще будут иметь слой внутреннего внимания (с маскированными будущими токенами).
С помощью подобной структуры мы можем переходить к обучению модели для все той же задачи языкового моделирования: предсказать следующее слово, используя большой неразмеченный набор данных. Достаточно просто загрузить 7 тысяч книг и обучить на них модель. Книги для данного рода задач подходят отлично, т.к. они позволяют модели научиться находить связанные по смыслу фрагменты текста, даже если они значительно отстоят друг от друга – то, чего нельзя достигнуть, если обучать модель на твитах или новостных заметках.
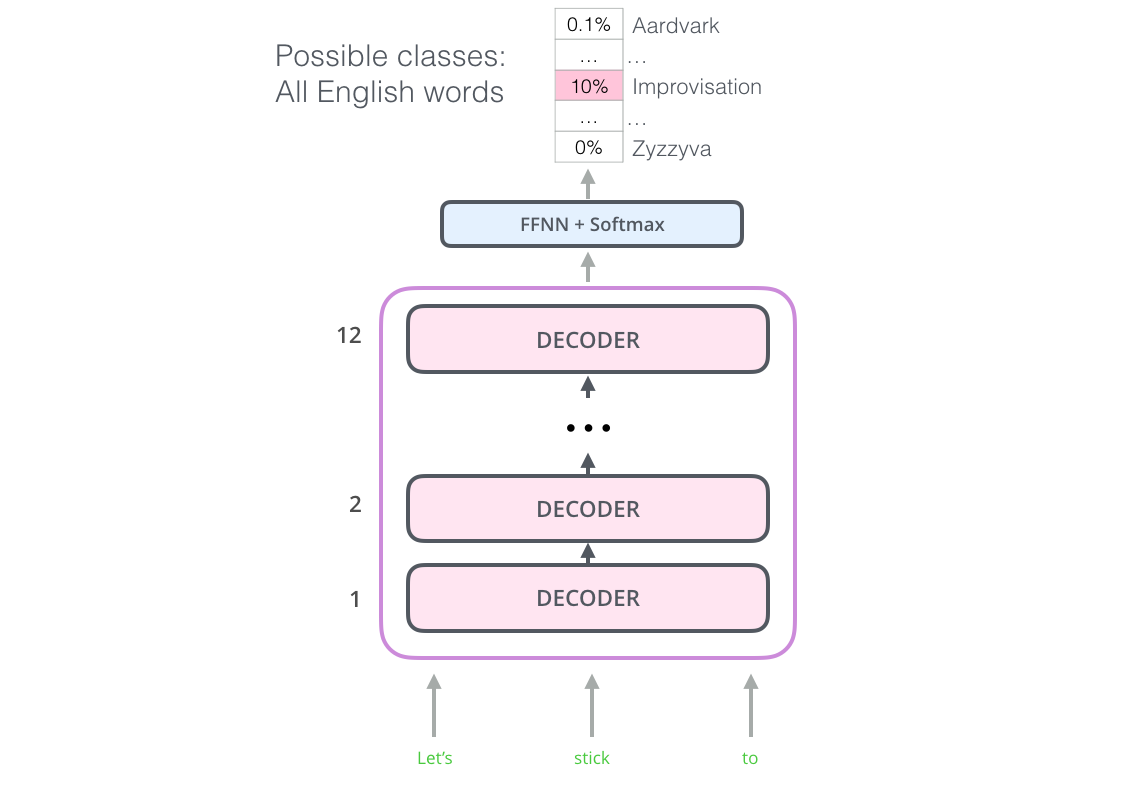
OpenAI Transformer готов к обучению для предсказания следующего слова на наборе данных объемом в 7000 книг
Трансферное обучение в прикладных задачах
Теперь, когда OpenAI Transformer предварительно обучен и его слои были настроены на обработку естественного языка, мы можем начать использовать его для решения прикладных задач. Для начала рассмотрим классификацию предложений (отнесение электронного письма к «спаму» или к «не спаму»):
Статья от OpenAI указывает на ряд трансформаций, делающих возможным обработку входов при решении разнообразных задач. Следующее изображение из этой статьи демонстрирует структуры моделей и входных трансформаций в зависимости от задач:
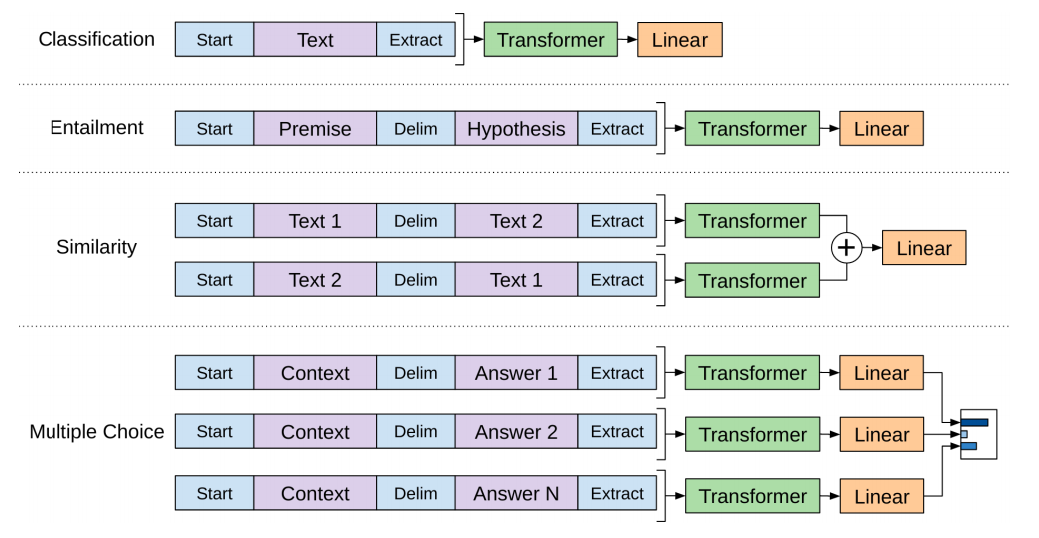
Умно, не правда ли?
BERT: от декодеров к энкодерам
OpenAI Transformer дал нам легко настраиваемую предобученную модель, основанную на архитектуре Трансформер. Но кое-что осталось не охваченным в переходе от LSTM к Трансформерам. Языковая модель ELMo была двунаправленная, но OpenAI Transformer обучает только однонаправленную модель. Можем ли мы сделать на основе Трансформера такую модель, которая могла бы смотреть как вперед, так и назад (технически – «быть обусловлена как левым, так и правым контекстом»)?
«Подержи мое пиво», – сказал Берт из фильмов для взрослых.
Маскированная языковая модель (masked language model)
«Мы будем использовать энкодеры Трансформера», – сказал Берт.
«Это безумие!» – ответил Эрни. – «Все знают, что двунаправленное обусловливание позволит каждому слову непоследовательно видеть себя в многослойном контексте.»
«Мы будем использовать маски», – уверенно заявил Берт.
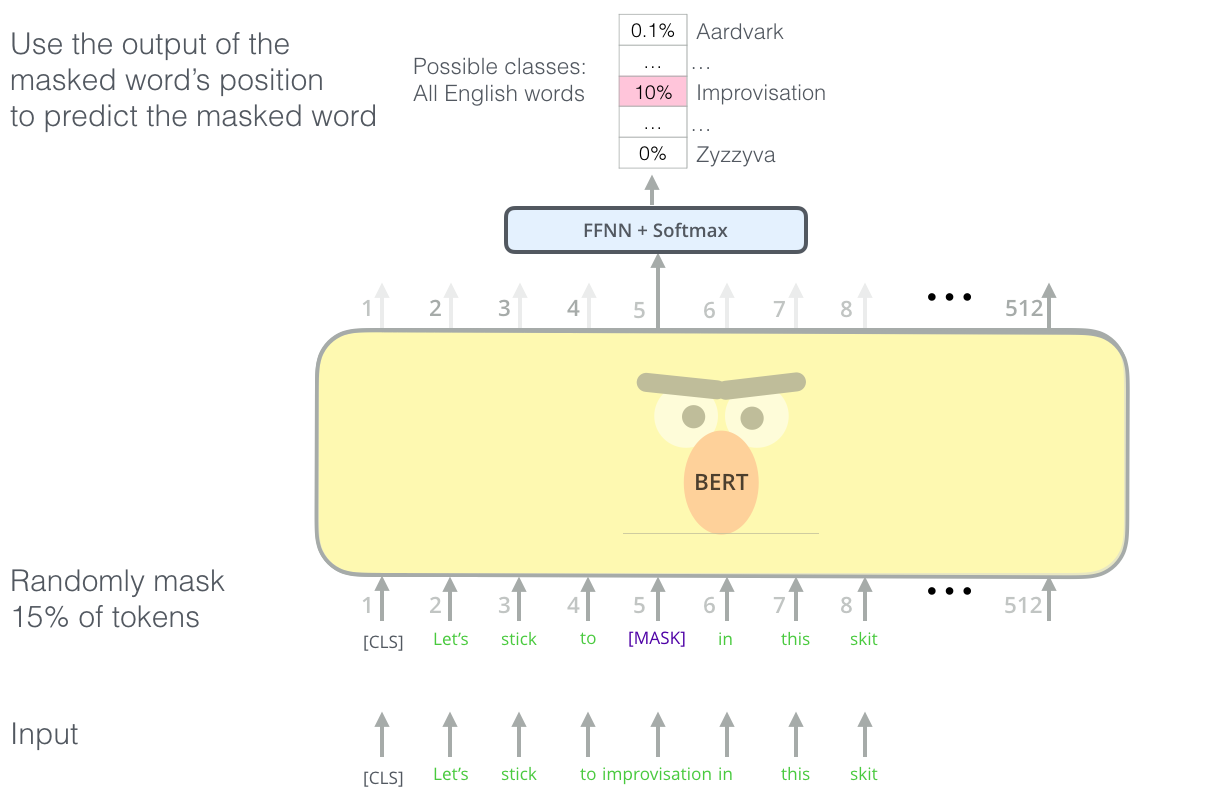
Для задач языкового моделирования BERT использует «умные» маски для 15% слов во входном предложении и просит модель предсказать пропущенное слово.
Нахождение правильной задачи для обучения стека энкодеров Трансформера – это сложное препятствие, которое BERT преодолевает, прибегая к понятию «маскированной языковой модели» (masked language model) из более ранних исследований (известному также как «клоуз-тест»).
Помимо маскирования 15% входного предложения, BERT также немного перемешивает слова для того, чтобы улучшить последующую тонкую настройку модели. Иногда он случайно переставляет слова местами и просит модель предсказать правильную позицию слова.
Задачи двух предложений
Если вернуться к входным трансформациям OpenAI Transformer, то можно заметить, что некоторые задачи требуют от модели выдать что-то осмысленное в отношении двух предложений (например, являются ли они просто парафразом друг друга? Используя в качестве входного предложения статью Википедии и вопрос относительно этой статьи как другое входное предложение, можем ли мы ответить на этот вопрос?).
Для того, чтобы BERT мог лучше справляться с определением связей в нескольких предложениях, предварительное обучение включает дополнительную задачу: дано два предложения (А и В); какова вероятность, что В будет следовать после А?

Вторая задача, на которой BERT проходит предварительное обучение – это задача классификации двух предложений. Токенизация на этой картинке упрощена, т.к. BERT использует WordPieces, а не слова в качестве токенов – поэтому некоторые слова разбиваются на более мелкие кусочки.
Модели для конкретных задач
В статье о BERT'е перечислен ряд способов его использования для различных задач.
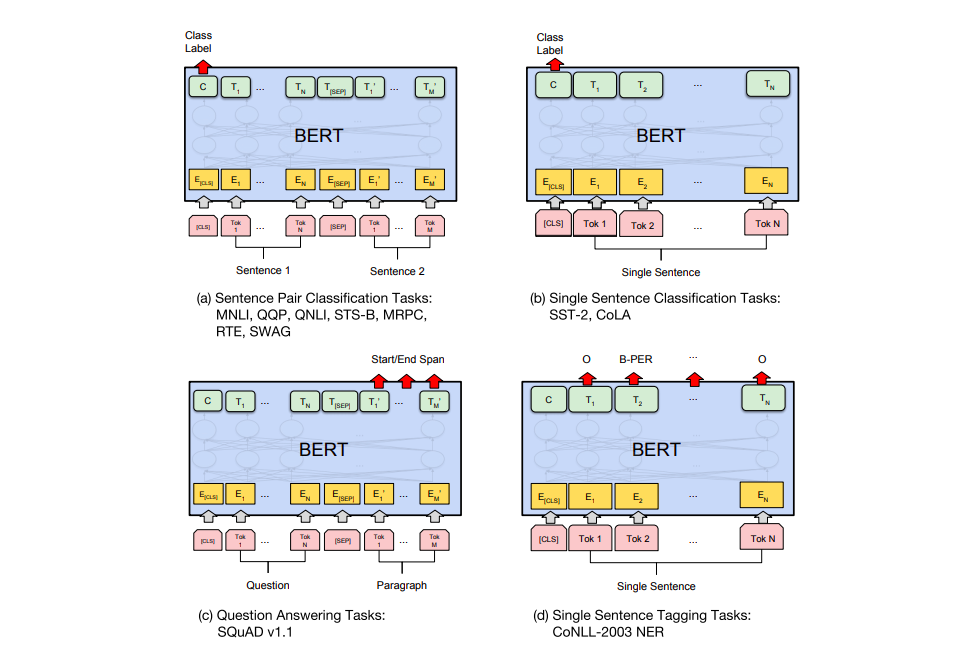
a) Задачи классификации двух предложений: MNLI, QQP, QNLI, STS-B, MRPC, RTE, SWAG; b) задачи классификации одного предложения: SST-2, CoLA; c) вопросно-ответные задачи: SQuAD v1.1; d) задачи разметки одного предложения: CoNLL-2003 NER.
BERT для извлечения признаков
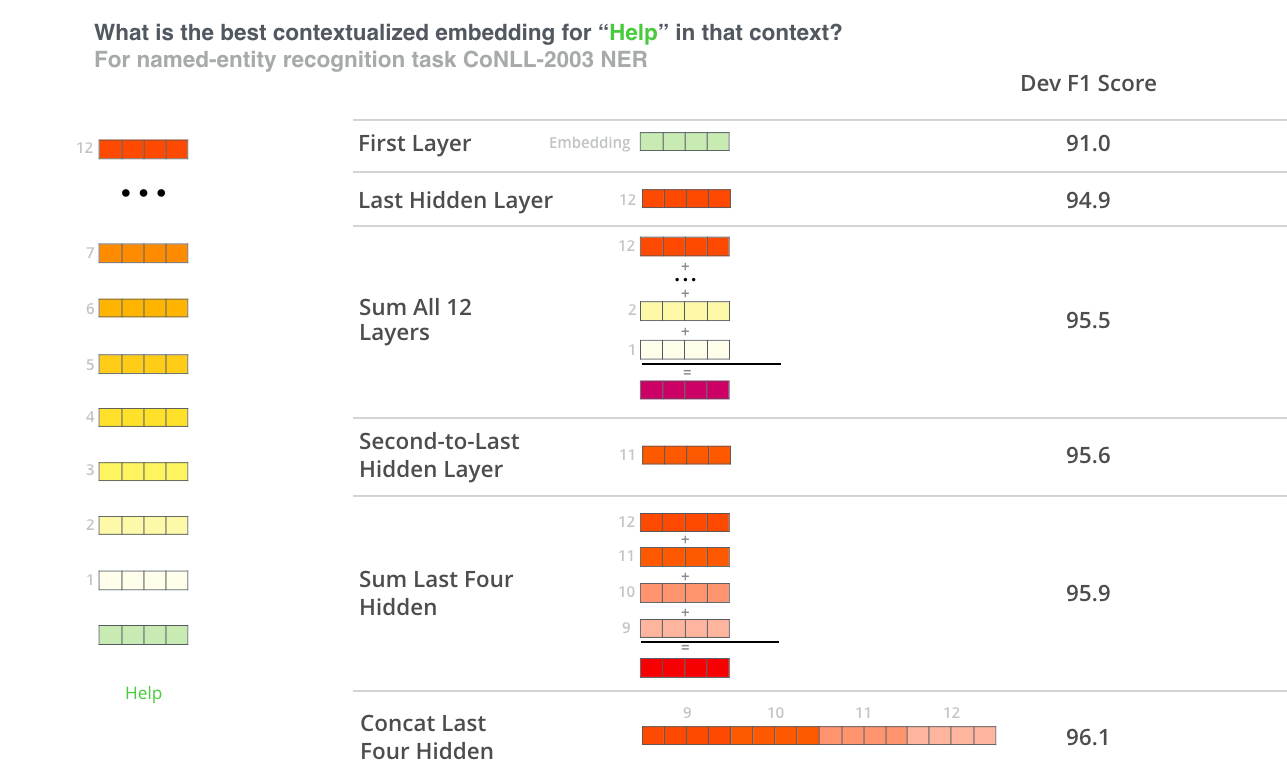
Подход тонкой настройки – не единственный способ использовать BERT. Как и в случае с ELMo, мы можем использовать предобученного BERT'а для создания контекстуализированных эмбеддингов. Далее эти эмбеддинги можно передавать в существующую модель – процесс, который показывает сравнимые с тонкой настройкой результаты на таких задачах, как, например, распознавание именованных сущностей (named-entity recognition).
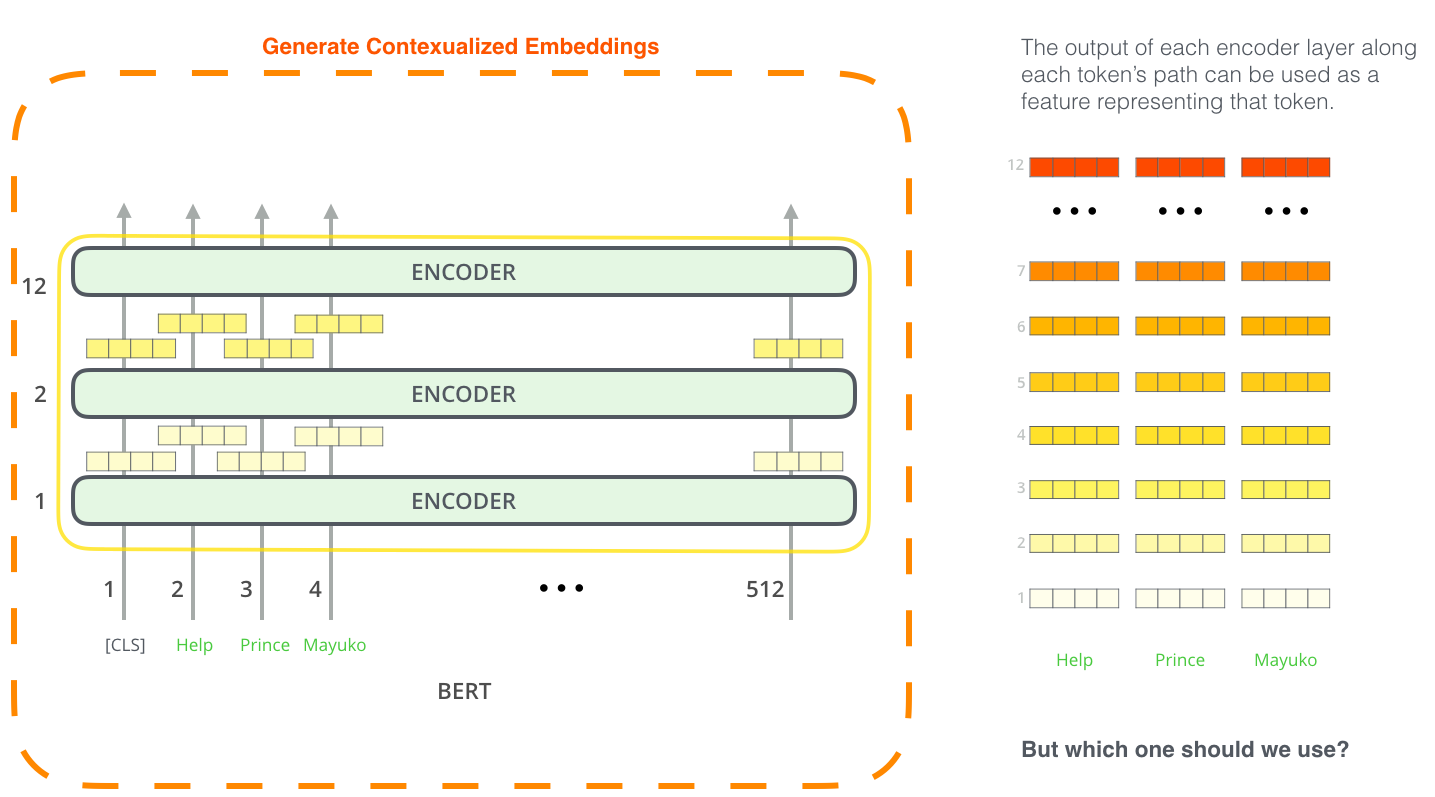
Какой вектор больше подходит в качестве контекстуализированного эмбеддинга? Это зависит от задачи. В статье представлено 6 вариантов (в сравнении с настроенной моделью, достигшей результата 96,4):
Тест-драйв BERT'а
Лучший способ попробовать BERT в действии – запустить ноутбук BERT FineTuning with Cloud TPUs, размещенный на Google Colab. Если вы никогда раньше не пользовались Cloud TPU, это отличная возможность попробовать, т.к. код BERT'а хорошо работает как на TPU, так и на CPU и GPU.
Следующий шаг – посмотреть на код в репозитории BERT'а:
- Модель строится в modeling.py (class BertModel) и практически идентична обычному энкодеру Трансформера.
- run_classifier.py – пример процесса тонкой настройки. Он также строит слой классификации для модели с учителем. Если вы хотите создать свой собственный классификатор, см. метод create_model() в этом файле.
- Несколько предобученных моделей доступны для скачивания, включая базового и расширенного BERT'а для английского и китайского языков, а также мультиязычной модели, обученной на Википедии и охватывающей 102 языка.
- BERT не рассматривает слова как токены. Вместо этого он работает с WordPieces. tokenization.py – токенизатор, который преобразует слова в WordPieces, подходящие для BERT'а.
Вы также можете посмотреть PyTorch-реализацию BERT'а. Библиотека AllenNLP использует ее для применения эмбеддингов BERT'a в любой модели.
Авторы
- Автор оригинала — Jay Alammar
- Перевод — Смирнова Екатерина
- Редактирование и вёрстка — Шкарин Сергей

