Этот пост является вторым в серии статей об авто-трекинге — новой системе реактивности в Ember.js. Я также обсуждаю концепцию реактивности в целом, и как она проявляется в JavaScript.
От переводчика: Крис Гарретт — работает в компании LinkedIn и является одним из core-контрибьюторов js-фреймворка Ember. Он принимал активное участие в создании нового издания фреймворка — Ember Octane. Одним из краеугольных камней этой редакции является новая система реактивности на основе автоматического отслеживания (autotracking). Несмотря на то, что его серия написана для Ember-разработчиков в ней затрагиваются концепции, которые полезно знать всем веб-программистам.
- Что такое реактивность?
- Что делает реактивную систему хорошей? ← Этот пост
- Как работает автотрекинг
- Кейс для автотрекинга — TrackedMap
- Кейс для автотрекинга — @localCopy
- Кейс для автотрекинга — RemoteData
- Кейс для автотрекинга — effect()
В предыдущем сообщении в блоге мы обсуждали, что означает реактивность системы. Определение, которое я вывел для этой серии:
Реакционная способность: декларативная программная модель, которая автоматически обновляется в соответствии с изменениями состояния.
Я немного подправил его с прошлого раза, чтобы определение читалось лучше, но фактически текст такой же. В этом посте я расскажу о другом общем аспекте реактивности: что делает хорошую реактивную систему хорошей?
Вместо того, чтобы пытаться определить это теоретически, я начну с рассмотрения реактивности некоторых других языков и структур. Из этих тематических исследований я постараюсь извлечь несколько принципов хорошего реактивного проектирования. Это, как я думаю, поможет сохранить основы и продемонстрирует различные способы достижения одной и той же фундаментальной цели. Как я уже говорил в первом посте этой серии, есть много разных способов сделать реактивность, каждый со своими плюсами и минусами.
Я также хочу сразу сказать, что не являюсь экспертом во всех технологиях, которые мы рассмотрим. Мое понимание их в основном основано на исследованиях, которые я проводил во время моей работы надо автотрекингом, чтобы лучше понять реактивность в целом. Так что я могу ошибаться в некоторых вещах и пропустить некоторые детали! Пожалуйста, дайте мне знать, если вы видите что-то немного некорректное (или полностью неправильное).
HTML
В последнем посте я использовал HTML как пример полностью декларативного языка. Прежде чем мы углубимся в некоторые фреймворки, я хотел бы немного подробнее остановиться на этом, а также обсудить встроенную в язык модель реактивности. HTML (наряду с CSS) на самом деле реагирует сам по себе, без какого-либо JavaScript!
Во-первых, что делает HTML декларативным? И почему так хорошо быть декларативным языком? Давайте рассмотрим пример HTML для страницы входа в систему:
<form action="/my-handling-form-page" method="post"> <label> Email: <input type="email" /> </label> <label> Password: <input type="password" /> </label> <button type="submit">Log in</button> </form>
В этом примере описывается структура формы для браузера. Затем браузер берет ее и предоставляет полностью функциональную форму непосредственно пользователю. Никаких дополнительных шагов настройки не требуется — нам не нужно сообщать браузеру, в каком порядке добавлять элементы, или добавлять обработчик для кнопки для отправки формы или какую-либо дополнительную логику. Мы говорим браузеру, как должна выглядеть форма входа, а не как ее отображать.
В этом смысл декларативного программирования: мы описываем, какой вывод мы хотим, а не то, как мы этого хотим. HTML хорош для того, чтобы быть декларативным, в частности, потому что он очень ограничен — мы на самом деле не можем добавить никаких дополнительных шагов к рендерингу без добавления другого языка (JavaScript). Но если это так, как HTML может быть реактивным? Реакционная способность требует состояния и изменения состояния, а как HTML может изменяться?
Ответ через интерактивные элементы HTML, такие как input и select. Браузер автоматически связывает их, чтобы они были интерактивными, и обновляет их собственное состояние, изменяя значения их атрибутов. Мы можем использовать эту возможность для создания различных компонентов, например, выпадающего меню.
<style> input[type='checkbox'] + ul { display: none; } input[type='checkbox']:checked + ul { display: inherit; } </style> <nav> <ul> <li> <label for="dropdown">Dropdown</label> <input id="dropdown" type="checkbox" /> <ul> <li>Item 1</li> <li>Item 2</li> </ul> </li> </ul> </nav>
Мой любимый пример этих возможностей — это превосходная презентация Эстель Вейл «Знаете ли вы, CSS». См. ./index.html для слайд-шоу на чистом HTML / CSS с некоторыми потрясающими примерами нативных функций платформы.
В этой модели реактивности каждое взаимодействие с пользователем отображается непосредственно на изменение в HTML (например, checked атрибут переключается на флажки). Затем этот измененный HTML-код отображается точно так же, как если бы это было начальное состояние. Это важный аспект любой декларативной системы, и первый принцип реактивности, который мы выделим:
1. Для данного состояния, независимо от того, как вы достигли этого состояния, вывод системы всегда одинаков
Независимо от того, попали мы на страницу с уже установленным флажком или обновили ее самостоятельно, HTML-код будет отображаться в браузере одинаково. Он не будет выглядеть по-другому после того, как мы установили флажок 10 раз, и не будет выглядеть иначе, если мы запустили страницу в другом состоянии.
Такая модель реактивности отлично подходит для простых случаев. Однако для многих приложений в какой-то момент ее становится недостаточно. Это момент, когда JS вступает в игру.
Реактивность по методу push
Одним из наиболее фундаментальных типов реактивности является реактивность push. Такая реактивность распространяет изменения в состоянии, когда эти изменения происходят, обычно используя события. Эта модель будет знакома всем, кто много писал на JavaScript, поскольку события это один из самых важных элементов браузера.
Однако сами по себе события не очень декларативны. Они зависят от каждого уровня, вручную распространяющего изменения, а это означает, что есть много маленьких, императивных шагов, где что-то может пойти не так. Например, рассмотрим этот пользовательский веб-компонент <edit-word> :
customElements.define('edit-word', class extends HTMLElement { constructor() { super(); const shadowRoot = this.attachShadow({mode: 'open'}); this.form = document.createElement('form'); this.input = document.createElement('input'); this.span = document.createElement('span'); shadowRoot.appendChild(this.form); shadowRoot.appendChild(this.span); this.isEditing = false; this.input.value = this.textContent; this.form.appendChild(this.input); this.addEventListener('click', () => { this.isEditing = true; this.updateDisplay(); }); this.form.addEventListener('submit', e => { this.isEditing = false; this.updateDisplay(); e.preventDefault(); }); this.input.addEventListener('blur', () => { this.isEditing = false; this.updateDisplay(); }); this.updateDisplay() } updateDisplay() { if (this.isEditing) { this.span.style.display = 'none'; this.form.style.display = 'inline-block'; this.input.focus(); this.input.setSelectionRange(0, this.input.value.length) } else { this.span.style.display = 'inline-block'; this.form.style.display = 'none'; this.span.textContent = this.input.value; this.input.style.width = this.span.clientWidth + 'px'; } } } );
Этот веб-компонент позволяет пользователю кликать на текст, чтобы редактировать его. При нажатии он переключает состояние isEditing, а затем запускает метод updateDisplay чтобы скрыть span и показать элемент form для редактирования. Когда форма подтверждается или уходит фокус, состояние переключается обратно. И что важно, каждый обработчик событий должен вручную вызывать updateDisplay для распространения этого изменения.
Логически, состояние элементов пользовательского интерфейса является производным состоянием, а переменная isEditing является корневым состоянием. Но поскольку события позволяют только запускать императивные команды, мы должны вручную синхронизировать производное состояние. Это подводит нас к нашему второму общему принципу хорошей реактивности:
2. Чтение состояния в системе приводит к реактивному производному состоянию
В идеальной реактивной системе использование состояния isEditing автоматически приведет к тому, что система обеспечит нужные изменения. Это можно сделать разными способами, как мы увидим совсем скоро, но главное — это чтобы наша реактивность всегда обновляла все производные состояния.
Стандартные события не дают нам этого свойства сами по себе, но есть реактивные системы, которые это делают.
Классический Ember
Под капотом Ember Classic в сильной степени следовал принципу push. Наблюдатели (observers) и слушатели событий (evert listeners) были примитивами, на которых была построена система, и у них были те же проблемы, что и во встроенной в браузер событийной модели. С другой стороны, система биндинга (binding), которая в конечном итоге стала системой цепочки зависимостей (dependency chaining), была более декларативной.
Мы можем увидеть эту систему в действии на классическом примере fullName:
import { computed, set } from '@ember/object'; class Person { firstName = 'Liz'; lastName = 'Hewell'; @computed('firstName', 'lastName') get fullName() { return `${this.firstName} ${this.lastName}`; } } let liz = new Person(); console.log(liz.fullName); 'Liz Hewell'; set(liz, 'firstName', 'Elizabeth'); console.log(liz.fullName); 'Elizabeth Hewell';
Под капотом в Classic Ember эта система работала через уведомления о свойствах. Всякий раз, когда мы впервые использовали вычисляемое свойство, шаблон или наблюдателя, Ember настраивал цепочки на все свои зависимости. Затем, когда мы обновляли свойство с помощью set(), цепочка уведомляла зависимости.
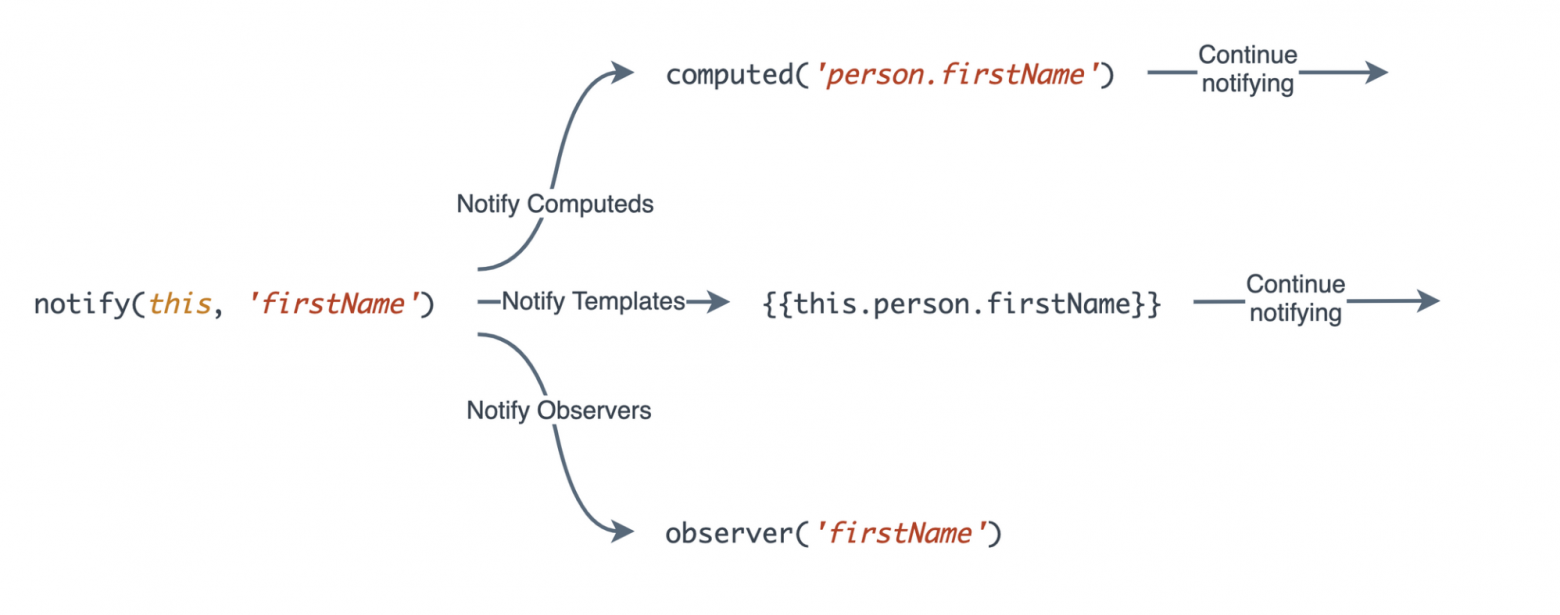
Конечно, наблюдатели (observers) сработают сразу же, но вычисленные свойства (computed) и шаблоны (templates) будут обновляться только при использовании. Это то, что сделало их намного лучше наблюдателей, они выполнили второй принцип реактивности, который мы только что определили. Производное состояние (вычисленные свойства и шаблоны) стало реактивным при использовании автоматически.
Это было в сердце реакционной способности Ember в течение очень долгого времени, и оно вытеснило большую часть экосистемы, так что наблюдатели вышли из общего пользования. Но в этой системе были и слабости. В частности, это была очень объектно-ориентированная система. По сути, для определения цепочек зависимостей требовалось определить объекты и классы, подталкивая разработчиков в этом направлении. Объектно-ориентированное программирование (ООП) — неплохая вещь, но оно может быть ограничительным, если это единственно доступная модель программирования.
Кроме того, хотя вычисленные свойства были в среднем лучше в плане производительности, чем наблюдатели и слушатели событий, но цепочки зависимостей и уведомления о событиях все еще были дорогостоящими. Настройка системы зависимостей должна была выполняться при запуске, и каждое изменение свойства вызывало события, пробегающее по всей системе. Хотя это было неплохо, но жизнь показала, что можно сделать лучше.
Observables, Streams и Rx.js
Другой подход к модели на основе push, которая делает вещи более декларативными, — это модель Observable. Он был популяризирован в JavaScript библиотекой RxJS и используется Angular в качестве основы для его реактивности.
Эта модель организует события в потоки, которые похожи на ленивый массив событий. Каждый раз, когда вы помещаете событие в один конец потока, оно будет проходить через различные преобразования, пока не достигнет подписчиков на другом конце.
// Чистый JS let count = 0; document.addEventListener( 'click', () => console.log(`Clicked ${++count} times`) );
// Используя потоки (Streams) import { fromEvent } from 'rxjs'; import { scan } from 'rxjs/operators'; fromEvent(document, 'click') .pipe(scan(count => count + 1, 0)) .subscribe(count => console.log(`Clicked ${count} times`));
На первый взгляд это может показаться похожим на наблюдателей в Ember, но имеется ключевое отличие — в потоки передаются значения, которые они наблюдают напрямую и возвращают новые значения на их основе. Это означает, что они удовлетворяют второму принципу хорошей реакционной способности, поскольку производное состояние является обязательно реактивным.
Недостатком потоков является то, что они по умолчанию всегда выполняются. Всякий раз, когда событие запускается с одного конца, оно немедленно запускает все преобразования, которые наблюдают за этим потоком. По умолчанию, мы можем проделывать большую работу для каждого изменения состояния.

Существуют методы для снижения этой стоимости, такие как дебаунсинг (debounce), но они требуют, чтобы программист внимательно думал о состоянии потока. И это подводит нас к нашему третьему принципу:
3. Система по умолчанию минимизирует лишнюю работу
Если мы обновим два значения в ответ на одно событие, мы не должны пересчитывать дважды. Если мы обновляем зависимость вычисляемого свойства, но никогда не используем это свойство, нам не следует с нетерпением перезапускать код его вычисления. В общем, если мы можем избежать работы, мы должны избегать, и хорошая реактивность должна быть разработана, чтобы помочь нам сделать это.
К сожалению, реактивность, основанная на push, может в этом отношении не слишком далеко нас продвинуть. Даже если мы будем использовать ленивые (lazy) вычисления, таких как, например, вычисляемые свойства Ember Classic, мы все равно будем выполнять большую работу для каждого изменения. Это связано с тем, что по своей сути системы, основанные на push, предназначены для распространения изменений, когда они происходят.
На другом конце спектра есть реактивные системы, которые распространяют изменения, когда обновляется сама система. Это реактивность на основе pull.
Реактивность на основе pull
Мне кажется, что самый простой способ объяснить реактивность, основанную на pull, — это следующий мысленный эксперимент. Допустим, у нас был невероятно быстрый компьютер, который мог отображать наше приложение практически мгновенно. Вместо того, чтобы пытаться синхронизировать все вручную, мы можем перерисовывать все приложение каждый раз, когда что-то меняется, и начинать заново. Нам не нужно было бы беспокоиться о распространении изменений через приложение, когда они произошли, потому что эти изменения отобразятся, когда мы перерисовываем все.
Так, с некоторыми упрощениями, работают модели на основе pull. И, конечно же, возможным недостатком здесь является производительность. У нас нет бесконечно мощных компьютеров, и мы не можем перерисовывать целые приложения для каждого изменения на ноутбуках и смартфонах.
Чтобы обойти это, у каждой модели реактивности на основе pull есть свои хитрости, позволяющие снизить стоимость обновления. Например, «Virtual DOM».
React и VirtualDOM
Virtual DOM, вероятно, является одной из самых известных функций React.js и была одним из ключей к его успеху. Концепция предполагает, что добавление HTML в браузер является самой дорогой частью. Вместо того, чтобы делать это напрямую, приложение создает модель, которая представляет HTML, а React переводит части, которые изменились, в настоящий HTML.
При первоначальном рендеринге все заканчивается отрисовкой HTML-кода. Но при повторном рендеринге обновляются только те части, которые были изменены. Это минимизирует одну из самых дорогих частей веб-приложения.

Второй способ, которым оптимизируется модель реактивности React, заключается в повторном запуске только той части, в которой что-то точно изменилось. Это частично то, о чем setState API (и сеттер в хуке useState ).
class Toggle extends React.Component { state = { isToggleOn: true }; handleClick = () => { this.setState(state => ({ isToggleOn: !state.isToggleOn })); } render() { return ( <button onClick={this.handleClick}> {this.state.isToggleOn ? 'ON' : 'OFF'} </button> ); } }
Когда пользователь изменяет состояние в компоненте, только этот компонент (и его подкомпоненты) перерисовываются во время следующего прохода.
Один интересный выбор, который был сделан для поддержания цельности (consistency), заключается в том, что setState и useState не обновляются немедленно после вызова. Вместо этого они ждут для обновления следующего рендера, так как логически новое состояние является новыми входными данными для приложения (и требует повторного рендеринга). Для многих пользователей это контр-интуитивно пока они не изучат React лучше, но это подводит нас к нашему последнему принципу хорошей реактивности:
4. Система предотвращает противоречивое производное состояние
React занимает здесь решительную позицию именно потому, что он не может знать, использовали ли вы уже состояние в другом месте. Представьте себе, если бы в компоненте React мы могли изменить состояние в середине рендера:
class Example extends React.Component { state = { value: 123; }; render() { let part1 = <div>{this.state.value}</div> this.setState({ value: 456 }); let part2 = <div>{this.state.value}</div> return ( <div> {part1} {part2} </div> ); } }
Если бы изменение состояния было применено немедленно, это привело бы к тому, что part1 шаблона компонента будет видеть состояние до изменения, а part2 увидит его после. Хотя иногда это может быть тем поведением, которое хочет пользователь, часто это происходит из-за более глубоких несоответствий, которые приводят к ошибкам. Например, вы можете отображать электронную почту пользователя в одной части приложения, только чтобы обновить ее и отрисовать совершенно другую электронную почту в другой части. React превентивно предотвращает появление этого несоответствия, но требует от разработчика более высоких когнитивных затрат.
В целом, двусторонний подход React к реактивности довольно эффективен до определенного момента, но также имеет свои ограничения. Вот почему существуют такие API, как shouldComponentUpdate() и useMemo(), поскольку они позволяют пользователям React вручную оптимизировать свои приложения.
Эти API работают, но они также перемещают систему в целом к менее декларативному подходу. Если пользователи вручную добавляют код для оптимизации своих приложений, у них есть много возможностей ошибиться.
Vue: гибридный подход
Vue также является фреймворком на основе Virtual DOM, но он использует дополнительную хитрость. Vue включает свойство реактивных data в каждый компонент:
const vm = new Vue({ data: { a: 1 } });
Это свойство используется Vue как замена setState или useState (по крайней мере, для текущего API), и в этом их особенность. На значения объекта data подписываются, когда к ним обращаются, и запускают события для этих подписок при обновлении. Под капотом это делается с помощью observables.
Например, в этом примере компонента:
const vm = new Vue({ el: '#example', data: { message: 'Hello' }, computed: { reversedMessage() { return this.message.split('').reverse().join('') } } })
Свойство reversedMessage будет автоматически подписываться на изменения message при его запуске, и любые будущие изменения свойства message будут обновлять его.
Этот гибридный подход позволяет Vue быть более производительным по умолчанию, чем React, поскольку различные вычисления могут автоматически кэшироваться. Это также означает, что мемоизация (memoization) сама по себе является более декларативной, поскольку пользователям не нужно добавлять какие-либо шаги вручную, чтобы указать на необходимость обновления. Но под капотом подход основан на методе push, и поэтому имеет дополнительные расходы, связанные с данным видом реактивности.
Elm
Последняя модель реактивности, которую я хочу обсудить в этом посте, на самом деле не является моделью на основе JavaScript. Для меня, однако, концептуально она наиболее похожа на автоматическое отслеживание (autotracking) по ряду причин, в частности, из-за простоты.
Elm — это язык программирования, который за последние несколько лет произвел сенсацию в сообществе функционального программирования. Это язык, разработанный с учетом реактивности и созданный специально для браузера (он компилируется в HTML + JS). Это также чисто функциональный язык, поскольку он вообще не допускает какого-либо императивного кода.
Таким образом, Elm следует чисто-функциональной модели реактивности, которую я обсуждал в своем последнем посте. Все состояния в приложении полностью экстернализуются, и при каждом изменении Elm перезапускает функцию приложения для получения нового вывода.
Из-за этого Elm может использовать технику кеширования, известную как мемоизация (memoization). Функция приложения по мере выполнения разбивает модель на более мелкие фрагменты для каждой подфункции, которые по сути являются компонентами. Если аргументы этой функции/компонента не изменились, то вместо пересчитывания используется последний результат.
// начальный уровень мемоизации в JS let lastArgs; let lastResult; function memoizedRender(...args) { if (deepEqual(lastArgs, args)) { // Args return lastResult; } lastResult = render(...args); lastArgs = args; return lastResult; }
Поскольку функция «чистая» и переданные ей аргументы одинаковы, нет никаких шансов что результат изменится, поэтому Elm может полностью ее пропустить.
Это огромное подспорье для производительности. Ненужная работа сведена к минимуму, поскольку код для создания нового HTML даже не выполняется, в отличие от React / Vue / других платформ на основе Virtual DOM.
Суть в том, что для того, чтобы извлечь из этого пользу, вам нужно выучить новый язык. И хотя есть много потенциальных плюсов в изучении Elm, и это прекрасный язык, не всегда практично переключаться на что-то менее известное и широко используемое.
Аналогично, попытки привнести чисто функциональный подход Elm в JavaScript обычно имеют разную степень успеха. JavaScript, к лучшему или худшему, является мультипарадигменным языком. Модель экстернализации всего состояния имеет свои проблемы, от концептуальных накладных расходов до проблем с масштабированием. Redux — это библиотека, построенная вокруг этой концепции, но даже апологеты этого сообщества не всегда рекомендуют ее по этим причинам.
Что мы действительно хотим, так это преимущества запоминания, но с возможностью сохранять наше состояние внутри функции приложения — в компонентах, рядом с местами, где это состояние используется. И мы хотим выполнить все другие принципы, которые мы обсуждали.
Но это тема для следующего поста!
Выводы
Итак, в этом посте мы рассмотрели ряд различных моделей реактивности, в том числе:
- HTML / CSS
- Реактивность на основе push
- Чистый JavaScript
— Классический Ember
— Observables / Rx.js - Реактивность на основе pull
— React.js
— Vue.js
— Elm
Мы также извлекли несколько общих принципов проектирования хорошей реактивной системы:
- Для данного состояния, независимо от того, как вы достигли этого состояния, вывод системы всегда одинаков
- Чтение состояния в системе приводит к реактивному производному состоянию
- Система по умолчанию минимизирует лишнюю работу
- Система предотвращает противоречивое производное состояние
Я не утверждаю, что этот список является исчерпывающим, но он охватывает многое из того, что делает реактивные системы надежными и пригодными для использования. В следующем посте мы углубимся в автотрекинг и узнаем, как он реализует эти принципы.

