В прошлой статье я рассказывал про прерывание DebugMon и регистры с ним связанные.
В этой статье будем писать реализацию отладчика по UART.
Тут и тут есть описание структуры запросов и ответов GDB сервера. Хоть оно и кажется простым, но реализовывать в микроконтроллере его мы не будем по следующим причинам:
Для получения наиболее легкого и быстрого модуля отладки будем использовать бинарный протокол с управляющими последовательностями:
Для обработки этих последовательностей при приеме потребуется автомат с 4мя состояниями:
А вот для отправки состояний потребуется уже 7:
Напишем определение структуры, внутри которой будут находиться все переменные модуля:
Состояния приемного и передающего автоматов объеденены в одну переменную так как работа будет вестись полудуплексном режиме. Теперь можно писать сами автоматы с обработчиком прерываний.
Здесь всё довольно просто. Обработчик прерывания в зависимости от наступившего события вызывает либо автомат приема, либо автомат передачи. Для проверки что всё работает, напишем обработчик пакета, отвечающий одним байтом:
Компилим, зашиваем, запускаем. Результат виден на скрине, оно заработало.
Далее нужно реализовать аналоги команд из протокола GDB сервера:
Команда будет кодироваться первым байтом данных. Коды команд имеют номера в порядке их реализации:
Параметры будут передаваться следующими байтами данных.
Ответ не будет содержать номер команды, т.к. мы и так знаем какую команду отправляли.
Чтобы модуль не вызывал исключения BusFault при операциях чтения/записи, нужно маскировать его при использовании на M3 и выше, либо писать обработчик HardFault для M0.
Установка breakpointа реализуется через поиск первого неактивного регистра FP_COMP.
Очистка реализуется через поиск установленной точки останова. Остановка выполнения устанавливает breakpoint на текущий PC. При выходе из прерывания UART, ядро сразу попадает в DebugMon_Handler.
Сам же обработчик DebugMon выполнен очень просто:
Читать регистры ядра из СИшного когда задача проблематичная, поэтому я переписал часть кода на ASM. В результате получилось что ни DebugMon_Handler, ни обработчик прерывания UART, ни автоматы не используют стек. Благодаря этому упростилось определение значений регистров ядра.
Микроконтроллерная часть отладчика работает, теперь займемся написанием связующего звена между IDE и нашим модулем.
С нуля писать сервер отладки не имеет смысла, поэтому за основу возьмем готовый. Так как больше всего опыта у меня в разработке программ на .net, взял за основу этот проект и переписал под другие требования. Правильнее было бы дописать поддержку нового интерфейса в OpenOCD, но это бы заняло больше времени.
При запуске программа спрашивает с каким COM портом работать, далее запускает на прослушивание TCP порт 3333 и ждет подключения GDB клиента.
Все команды GDB протокола транслируются в бинарный протокол.
В результате вышла работоспособная реализация отладки по UART.
Оказалось что отладка контроллером самого себя не является чем-то сверх сложным.
Теоретически, разместив данный модуль в отдельной секции памяти, его можно использовать и для прошивки контроллера.
Исходники выложил на GitHub для всеобщего изучения
Микроконтроллерная часть
GDB сервер
В этой статье будем писать реализацию отладчика по UART.
Низкоуровневая часть
Тут и тут есть описание структуры запросов и ответов GDB сервера. Хоть оно и кажется простым, но реализовывать в микроконтроллере его мы не будем по следующим причинам:
- Большая избыточность данных. Адреса, значения регистров, переменных кодируются в виде hex-строки, что увеличивает объем сообщений в 2 раза
- Парсить и собирать сообщения займет дополнительные ресурсы
- Отслеживать конец пакета требуется либо по таймауту (будет занят таймер), либо сложным автоматом, что увеличит время нахождения в прерывании UART
Для получения наиболее легкого и быстрого модуля отладки будем использовать бинарный протокол с управляющими последовательностями:
- 0хАА 0xFF — Start of frame
- 0xAA 0x00 — End of frame
- 0xAA 0xA5 — Interrupt
- 0xAA 0xAA — Заменяется на 0xAA
Для обработки этих последовательностей при приеме потребуется автомат с 4мя состояниями:
- Ожидание ESC символа
- Ожидание второго символа последовательности Start of frame
- Прием данных
- Прошлый раз был принят Esc символ
А вот для отправки состояний потребуется уже 7:
- Отправка первого байта Start of frame
- Отправка второго байта Start of frame
- Отправка данных
- Отправка End of frame
- Отправка Esc символа замены
- Отправка первого байта Interrupt
- Отправка второго байта Interrupt
Напишем определение структуры, внутри которой будут находиться все переменные модуля:
typedef struct { // disable receive data unsigned tx:1; // program stopped unsigned StopProgramm:1; union { enum rx_state_e { rxWaitS = 0, // wait Esc symbol rxWaitC = 1, // wait Start of frame rxReceive = 2, // receiving rxEsc = 3, // Esc received } rx_state; enum tx_state_e { txSendS = 0, // send first byte of Start of frame txSendC = 1, // send second byte txSendN = 2, // send byte of data txEsc = 3, // send escaped byte of data txEnd = 4, // send End of frame txSendS2 = 5,// send first byte of Interrupt txBrk = 6, // send second byte } tx_state; }; uint8_t pos; // receive/send position uint8_t buf[128]; // offset = 3 uint8_t txCnt; // size of send data } dbg_t; #define dbgG ((dbg_t*)DBG_ADDR) // адрес задан жестко, в настройках линкера эта часть озу убирается из доступной
Состояния приемного и передающего автоматов объеденены в одну переменную так как работа будет вестись полудуплексном режиме. Теперь можно писать сами автоматы с обработчиком прерываний.
Обработчик UART
void USART6_IRQHandler(void) { if (((USART6->ISR & USART_ISR_RXNE) != 0U) && ((USART6->CR1 & USART_CR1_RXNEIE) != 0U)) { rxCb(USART6->RDR); return; } if (((USART6->ISR & USART_ISR_TXE) != 0U) && ((USART6->CR1 & USART_CR1_TXEIE) != 0U)) { txCb(); return; } } void rxCb(uint8_t byte) { dbg_t* dbg = dbgG; // debug vars pointer if (dbg->tx) // use half duplex mode return; switch(dbg->rx_state) { default: case rxWaitS: if (byte==0xAA) dbg->rx_state = rxWaitC; break; case rxWaitC: if (byte == 0xFF) dbg->rx_state = rxReceive; else dbg->rx_state = rxWaitS; dbg->pos = 0; break; case rxReceive: if (byte == 0xAA) dbg->rx_state = rxEsc; else dbg->buf[dbg->pos++] = byte; break; case rxEsc: if (byte == 0xAA) { dbg->buf[dbg->pos++] = byte; dbg->rx_state = rxReceive; } else if (byte == 0x00) { parseAnswer(); } else dbg->rx_state = rxWaitS; } } void txCb() { dbg_t* dbg = dbgG; switch (dbg->tx_state) { case txSendS: USART6->TDR = 0xAA; dbg->tx_state = txSendC; break; case txSendC: USART6->TDR = 0xFF; dbg->tx_state = txSendN; break; case txSendN: if (dbg->txCnt>=dbg->pos) { USART6->TDR = 0xAA; dbg->tx_state = txEnd; break; } if (dbg->buf[dbg->txCnt]==0xAA) { USART6->TDR = 0xAA; dbg->tx_state = txEsc; break; } USART6->TDR = dbg->buf[dbg->txCnt++]; break; case txEsc: USART6->TDR = 0xAA; dbg->txCnt++; dbg->tx_state = txSendN; break; case txEnd: USART6->TDR = 0x00; dbg->rx_state = rxWaitS; dbg->tx = 0; CLEAR_BIT(USART6->CR1, USART_CR1_TXEIE); break; case txSendS2: USART6->TDR = 0xAA; dbg->tx_state = txBrk; break; case txBrk: USART6->TDR = 0xA5; dbg->rx_state = rxWaitS; dbg->tx = 0; CLEAR_BIT(USART6->CR1, USART_CR1_TXEIE); break; } }
Здесь всё довольно просто. Обработчик прерывания в зависимости от наступившего события вызывает либо автомат приема, либо автомат передачи. Для проверки что всё работает, напишем обработчик пакета, отвечающий одним байтом:
void parseAnswer() { dbg_t* dbg = dbgG; dbg->pos = 1; dbg->buf[0] = 0x33; dbg->txCnt = 0; dbg->tx = 1; dbg->tx_state = txSendS; SET_BIT(USART6->CR1, USART_CR1_TXEIE); }
Компилим, зашиваем, запускаем. Результат виден на скрине, оно заработало.
Тестовый обмен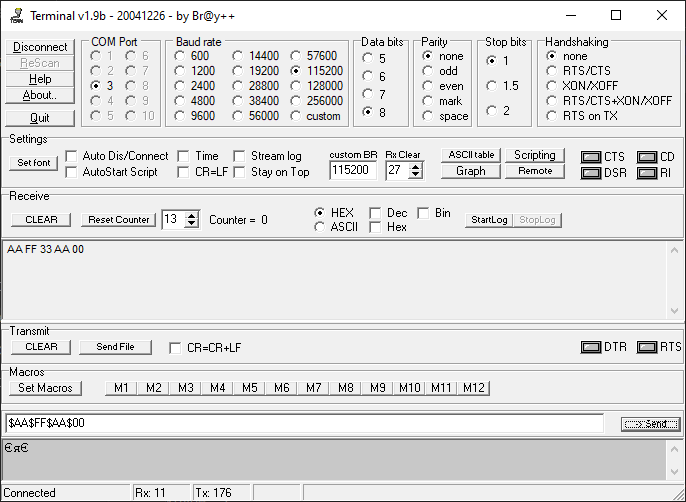
Далее нужно реализовать аналоги команд из протокола GDB сервера:
- чтение памяти
- запись памяти
- останов программы
- продолжение выполнения
- чтение регистра ядра
- запись регистра ядра
- установка точки останова
- удаление точки останова
Команда будет кодироваться первым байтом данных. Коды команд имеют номера в порядке их реализации:
- 2 — чтение памяти
- 3 — запись памяти
- 4 — останов
- 5 — продолжение
- 6 — чтение регистра
- 7 — установка breakpointа
- 8 — очистка breakpointа
- 9 — шаг (не получилось реализовать)
- 10 — запись регистра (не реализовано)
Параметры будут передаваться следующими байтами данных.
Ответ не будет содержать номер команды, т.к. мы и так знаем какую команду отправляли.
Чтобы модуль не вызывал исключения BusFault при операциях чтения/записи, нужно маскировать его при использовании на M3 и выше, либо писать обработчик HardFault для M0.
Безопасный memcpy
int memcpySafe(uint8_t* to,uint8_t* from, int len) { /* Cortex-M3, Cortex-M4, Cortex-M4F, Cortex-M7 are supported */ static const uint32_t BFARVALID_MASK = (0x80 << SCB_CFSR_BUSFAULTSR_Pos); int cnt = 0; /* Clear BFARVALID flag by writing 1 to it */ SCB->CFSR |= BFARVALID_MASK; /* Ignore BusFault by enabling BFHFNMIGN and disabling interrupts */ uint32_t mask = __get_FAULTMASK(); __disable_fault_irq(); SCB->CCR |= SCB_CCR_BFHFNMIGN_Msk; while ((cnt<len)) { *(to++) = *(from++); cnt++; } /* Reenable BusFault by clearing BFHFNMIGN */ SCB->CCR &= ~SCB_CCR_BFHFNMIGN_Msk; __set_FAULTMASK(mask); return cnt; }
Установка breakpointа реализуется через поиск первого неактивного регистра FP_COMP.
Код, устанавливающий breakpointы
dbg->pos = 0; // установим кол-во байт ответа в 0 addr = ((*(uint32_t*)(&dbg->buf[1])))|1; // требуемое значение регистра FP_COMP for (tmp = 0;tmp<8;tmp++) // ищем не был ли установлен breakpoint уже if (FP->FP_COMP[tmp] == addr) break; if (tmp!=8) // если был, выходим break; for (tmp=0;tmp<NUMOFBKPTS;tmp++) // ищем свободный регистр if (FP->FP_COMP[tmp]==0) // нашли? { FP->FP_COMP[tmp] = addr; // устанавливаем break; // и выходим } break;
Очистка реализуется через поиск установленной точки останова. Остановка выполнения устанавливает breakpoint на текущий PC. При выходе из прерывания UART, ядро сразу попадает в DebugMon_Handler.
Сам же обработчик DebugMon выполнен очень просто:
- 1. Устанавливается флаг остановки выполнения.
- 2. Очищаются все установленные точки останова.
- 3. Ожидается завершение отправки ответа на команду в uart (если он не успел отправиться)
- 4. Начинается отправка последовательности Interrupt
- 5. В цикле вызываются обработчики автоматов приема и передачи пока не опустится флаг останова
Код обработчика DebugMon
void DebugMon_Handler(void) { dbgG->StopProgramm = 1; // устанавливаем флаг остановки for (int i=0;i<NUMOFBKPTS;i++) // очищаем breakpointы FP->FP_COMP[i] = 0; while (USART6->CR1 & USART_CR1_TXEIE) // ждем пока отправится ответ if ((USART6->ISR & USART_ISR_TXE) != 0U) txCb(); dbgG->tx_state = txSendS2; // начинаем отправку Interrupt последовательности dbgG->tx = 1; SET_BIT(USART6->CR1, USART_CR1_TXEIE); while (dbgG->StopProgramm) // пока флаг не сбросится командой продолжения выполнения { // вызываем автоматы UARTа в цикле if (((USART6->ISR & USART_ISR_RXNE) != 0U) && ((USART6->CR1 & USART_CR1_RXNEIE) != 0U)) rxCb(USART6->RDR); if (((USART6->ISR & USART_ISR_TXE) != 0U) && ((USART6->CR1 & USART_CR1_TXEIE) != 0U)) txCb(); } }
Читать регистры ядра из СИшного когда задача проблематичная, поэтому я переписал часть кода на ASM. В результате получилось что ни DebugMon_Handler, ни обработчик прерывания UART, ни автоматы не используют стек. Благодаря этому упростилось определение значений регистров ядра.
GDB server
Микроконтроллерная часть отладчика работает, теперь займемся написанием связующего звена между IDE и нашим модулем.
С нуля писать сервер отладки не имеет смысла, поэтому за основу возьмем готовый. Так как больше всего опыта у меня в разработке программ на .net, взял за основу этот проект и переписал под другие требования. Правильнее было бы дописать поддержку нового интерфейса в OpenOCD, но это бы заняло больше времени.
При запуске программа спрашивает с каким COM портом работать, далее запускает на прослушивание TCP порт 3333 и ждет подключения GDB клиента.
Все команды GDB протокола транслируются в бинарный протокол.
В результате вышла работоспособная реализация отладки по UART.
Итоговый результат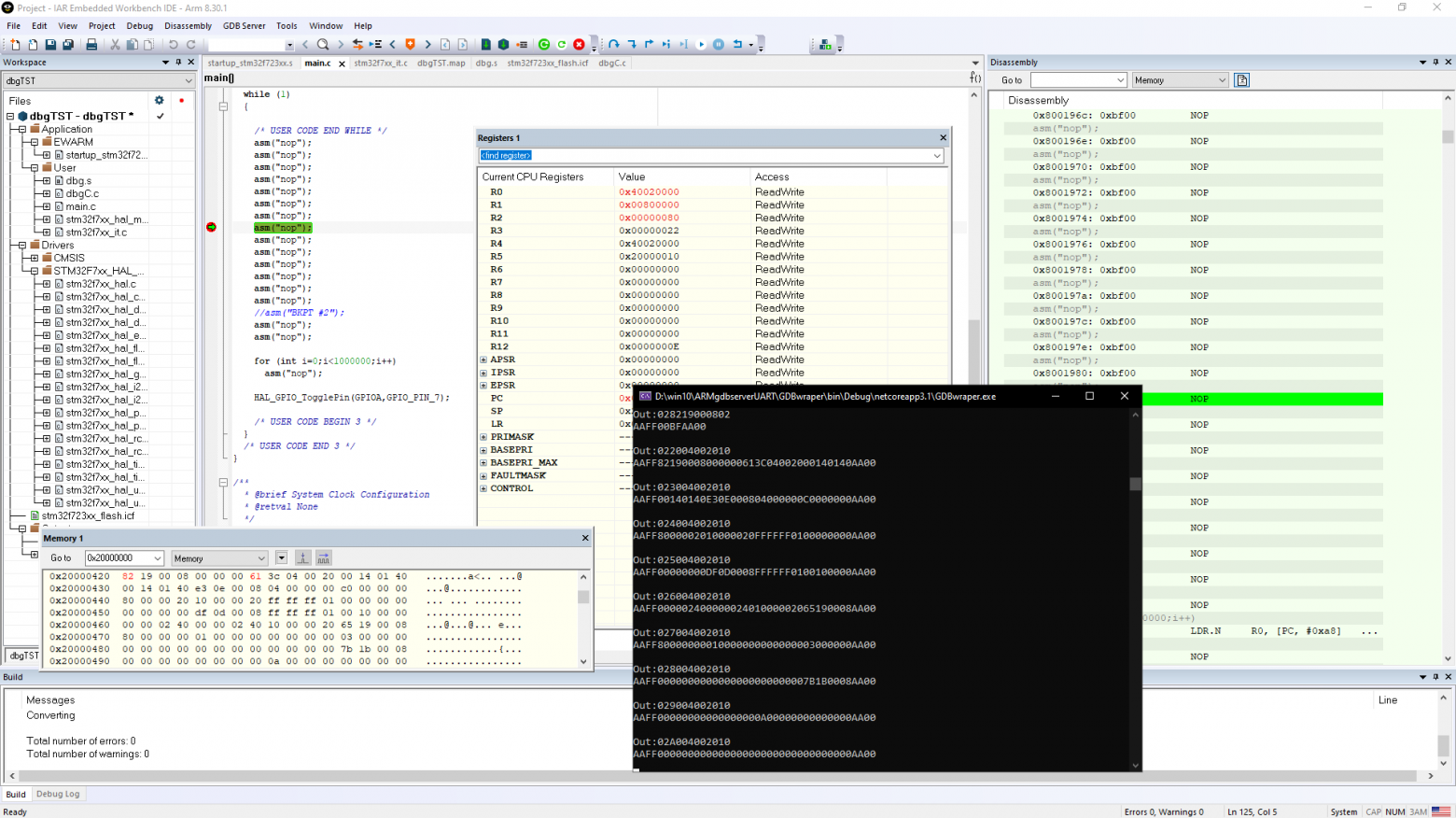
Заключение
Оказалось что отладка контроллером самого себя не является чем-то сверх сложным.
Теоретически, разместив данный модуль в отдельной секции памяти, его можно использовать и для прошивки контроллера.
Исходники выложил на GitHub для всеобщего изучения
Микроконтроллерная часть
GDB сервер

