Иногда возникают ситуации, когда решение задачи выборки данных из реляционной БД не укладывается в возможности используемой в проекте ОРМ, например, либо из-за недостаточной скорости работы самой ОРМ, либо не совсем оптимальных SQL запросов генерируемых ею. В таком случае обычно приходится писать запросы вручную.
Проблема в том, что данные из БД (в т.ч. в ответ на JOIN запрос) возвращаются в виде “плоского” двухмерного массива никак не отражающего сложную “древовидную” структуру данных приложения. Работать с таким массивом дальше крайне неудобно, поэтому требуется более-менее универсальное решение, позволяющее привести этот массив в более подходящий вид по заданному шаблону.
Решение было найдено, удобное и достаточно быстрое.
Для оценки скорости работы библиотеки я собрал небольшой испытательный стенд на котором скорость работы моей библиотеки сравнивается со скоростью работы Eloquent. Для замеров использовался пакет phpbench.
Для того чтобы развернуть стенд у себя:
Здесь я использовал инструмент описанный в моей предыдущей статье.
Затем в меню выбираем: 1 Develop, затем: 1 Build, затем 2 Deploy and Up;
Затем запускаем тесты 5. Run tests
В базе 3000 книг. Результаты получились следующие:
benchEloquent — вытаскивает все книги с авторами с использованием Eloquent
benchEloquentId — вытаскивает определенную книгу с авторами с использованием Eloquent (10 раз)
benchProc — вытаскивает все книги с авторами с использованием библиотеки
benchProcId — вытаскивает определенную книгу с авторами с использованием библиотеки (10 раз)
Возможно приведенные тесты недостаточно репрезентативны, но разница заметна, как по времени выполнения, так и по расходованию памяти.
Устанавливаем:
Далее, для примера (крайне простого), представим, что у нас имеется БД книг и авторов со следующей структурой.
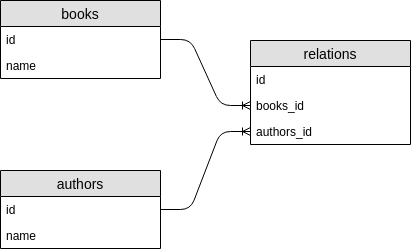
Задача — вытащить все книги с их авторами.
Запрос будет выглядеть как-то так:
В ответ мы получим примерно такой массив данных.
Для этого немного изменим наш запрос:
Здесь мы в секции SELECT задали алиасы: для полей с данными о книгах алиасы с префиксом 'book_', а для полей с информацией об авторах с префиксом 'author'.
Далее преобразуем ответ БД
где:
$rows — ответ БД в виде массива объектов /stdClass()
$config — ассоциативный массив отражающий структуру данных итогового массива
В итоге в $booksData имеем древовидный массив имеющий структуру, описанную в $config, заполненный соответствующими данными.
Как-то так.
Проблема в том, что данные из БД (в т.ч. в ответ на JOIN запрос) возвращаются в виде “плоского” двухмерного массива никак не отражающего сложную “древовидную” структуру данных приложения. Работать с таким массивом дальше крайне неудобно, поэтому требуется более-менее универсальное решение, позволяющее привести этот массив в более подходящий вид по заданному шаблону.
Решение было найдено, удобное и достаточно быстрое.
На сколько быстрое
Для оценки скорости работы библиотеки я собрал небольшой испытательный стенд на котором скорость работы моей библиотеки сравнивается со скоростью работы Eloquent. Для замеров использовался пакет phpbench.
Для того чтобы развернуть стенд у себя:
git clone https://github.com/hrustbb2/env-arrayproc-bench.git cd env-arrayproc-bench ./env
Здесь я использовал инструмент описанный в моей предыдущей статье.
Затем в меню выбираем: 1 Develop, затем: 1 Build, затем 2 Deploy and Up;
Затем запускаем тесты 5. Run tests
В базе 3000 книг. Результаты получились следующие:
+-----------------+-----+------+------+-------------+--------------+ | subject | set | revs | iter | mem_peak | time_rev | +-----------------+-----+------+------+-------------+--------------+ | benchEloquent | 0 | 1 | 0 | 76,442,912b | 12,781.612ms | | benchEloquentId | 0 | 10 | 0 | 5,123,224b | 16.432ms | | benchProc | 0 | 1 | 0 | 36,364,176b | 1,053.937ms | | benchProcId | 0 | 10 | 0 | 4,462,696b | 7.684ms | +-----------------+-----+------+------+-------------+--------------+
benchEloquent — вытаскивает все книги с авторами с использованием Eloquent
benchEloquentId — вытаскивает определенную книгу с авторами с использованием Eloquent (10 раз)
benchProc — вытаскивает все книги с авторами с использованием библиотеки
benchProcId — вытаскивает определенную книгу с авторами с использованием библиотеки (10 раз)
Возможно приведенные тесты недостаточно репрезентативны, но разница заметна, как по времени выполнения, так и по расходованию памяти.
Как это работает
Устанавливаем:
composer require hrustbb2/arrayproc:v1.0.0
Далее, для примера (крайне простого), представим, что у нас имеется БД книг и авторов со следующей структурой.
Задача — вытащить все книги с их авторами.
Запрос будет выглядеть как-то так:
SELECT books.id, books.name, authors.id, authors.name FROM books LEFT JOIN relations ON relations.books_id = books.id LEFT JOIN authors ON authors.id = relations.authors_id
В ответ мы получим примерно такой массив данных.
| book.id | book.name | author.id | author.name |
| 1 | book1 | 2 | author2 |
| 1 | book1 | 4 | author4 |
| 1 | book1 | 6 | author6 |
| 2 | book2 | 2 | author2 |
| 2 | book2 | 3 | author3 |
| 2 | book2 | 6 | author6 |
| 2 | book2 | 7 | author7 |
Массив двумерный, некоторые поля дублируются, для удобства нужно его преобразовать
[ 1 => [ 'id' => 1, 'name' => 'book1', 'authors' => [ 2 => [ 'id' => 2, 'name' => 'author2' ], 4 => [ 'id' => 4, 'name' => 'author4' ], 6 => [ 'id' => 6, 'name' => 'author6' ], ] ], 2 => [ 'id' => 2, 'name' => 'book2', 'authors' => [ 2 => [ 'id' => 2, 'name' => 'author2' ], 3 => [ 'id' => 3, 'name' => 'author3' ], 6 => [ 'id' => 6, 'name' => 'author6' ], 7 => [ 'id' => 7, 'name' => 'author7' ], ] ], ]
Для этого немного изменим наш запрос:
SELECT books.id AS book_id, books.name AS book_name, authors.id AS author_id, authors.name AS author_name FROM books LEFT JOIN relations ON relations.books_id = books.id LEFT JOIN authors ON authors.id = relations.authors_id
Здесь мы в секции SELECT задали алиасы: для полей с данными о книгах алиасы с префиксом 'book_', а для полей с информацией об авторах с префиксом 'author'.
Далее преобразуем ответ БД
use hrustbb2\arrayproc\ArrayProcessor; $arrayProcessor = new ArrayProcessor(); $config = [ 'prefix' => 'book_', 'authors' => [ 'prefix' => 'author_', ] ] $booksData = $arrayProcessor->process($conf, $rows)->resultArray();
где:
$rows — ответ БД в виде массива объектов /stdClass()
$config — ассоциативный массив отражающий структуру данных итогового массива
В итоге в $booksData имеем древовидный массив имеющий структуру, описанную в $config, заполненный соответствующими данными.
Как-то так.

