От переводчика: вопросы, поднятые в прошлой моей статье (видимо не слишком удачной) тем не менее вывели меня (огромное спасибо комраду Kilorad за ссылку!) на материал, который я посчитал необходимым перевести и выложить сюда. Да, я, к сожалению, посредственно владею как языком оригинала, так и собственно темой, но… Этот материал должен здесь быть! Готов к всяческим дополнениям/поправкам/критике (перевода, ибо исходная работа не моя) — дабы все было корректно.
Мы исследуем построение моделей популярных сред обучения с подкреплением генеративными нейронными сетями. Наша модель мира может быть быстро обучена (без учителя), чтобы сформировать сжатое пространственное и временное представление окружающей среды. Используя паттерны (features), из модели мира в качестве входных данных для агента, мы можем получить очень компактную и простую стратегию для достижения поставленных целей. Мы даже можем обучить агента полностью в «его воображении» (в среде, воссозданной по его модели мира) и перенести полученную стратегию обратно в реальный исходный мир.

Люди формируют ментальную модель мира, основанную на своем (довольно ограниченном) восприятии. Мы принимаем решения и действуем на основании этой внутренней модели. Джей Райт Форрестер, отец системной динамики, описал ментальную модель так: «Образ окружающего мира в нашей голове — не более чем модель реального мира: никто не держит в уме весь мир, правительство или страну в целом. Мы выбираем только отдельные концепции и их взаимосвязи, дабы использовать их для представления реальной системы.»
Чтобы иметь возможность переработать огромное количество информации, постоянно поступающей извне, наш мозг выработал способность извлекать и запоминать абстрактное представление как пространственных, так и временных аспектов этой информации. Мы можем в реальном времени наблюдать за сценой и запоминать ее абстрактное описание. Также есть данные, говорящие о том, что то, что мы воспринимаем в данный момент основано на предсказании мозга о будущем на основе нашей внутренней модели.

Одна из версий, как бы эта предсказательная модель могла быть реализована в нашем сознании, строится на том, что речь идет не о прогнозировании будущего в целом, а о прогнозировании будущих сенсорных данных с учетом наших текущих действий. Мы способны инстинктивно действовать на основе этой модели и активировать рефлекторные поведенческие механизмы (в момент опасности, например) без необходимости сознательно продумывать стратегию поведения.
Возьмем бейсбол. У бэттера (игрок с битой в бейсболе, задача которого отбить мяч, брошенный питчером противника, прим. переводчика) есть буквально миллисекунды, чтобы определится с ударом — это меньше, чем время, которое затрачивает визуальный сигнал, на то чтобы достигнуть мозга. Единственное объяснение, как человек может «взять мяч» скоростью 100 миль в час — наша способность инстинктивно предсказать где и когда он окажется. Для бейсболистов все происходит подсознательно: их руки рефлекторно выполняют мах (англ: swing the bat) таким образом, чтобы бита оказалась в нужном месте и в нужное время — в соответствии с предсказанием их внутренней модели. Они способны быстро реагировать на собственные прогнозы, без необходимости сознательного перебора вариантов для нахождения лучшей стратегии.
 Для многих актуальных задач обучения с подкреплением (RL) агенту также не помешало бы представление о прошлых и настоящих состояниях системы, а также хорошая прогнозная модель, желательно реализованная на компьютере общего назначения, такая, как рекуррентная нейронная сеть (RNN).
Для многих актуальных задач обучения с подкреплением (RL) агенту также не помешало бы представление о прошлых и настоящих состояниях системы, а также хорошая прогнозная модель, желательно реализованная на компьютере общего назначения, такая, как рекуррентная нейронная сеть (RNN).
Большие RNN — это модели с высокой выразительностью, которые могут работать с пространственными и временными данными. Тем не менее большинство описанных model-free методов в RL используют маленькие сети с небольшим числом параметров. Узким местом алгоритмов RL является проблема распределения подкрепления или проблема обратной связи (англ: CAP, credit assignment problem), что затрудняет применение этих алгоритмов в случае большой сети с миллионами весов, поэтому на практике используются меньшие сети, так как они быстрее достигают хороших стратегий в ходе тренировок.
В идеале, мы бы хотели тренировать агентов на основе больших рекуррентных сетей. Для их обучения может быть использован механизм обратного распространения ошибки. В этой работе мы рассмотрим обучение большой нейронной сети решать задачи RL, разделив агента на большую модель мира и небольшую модель контроллера. Сначала мы используем большую нейронную сеть (обучение без учителя) для создания модели мира, а затем методами RL обучаем совсем небольшой контроллер выполнять поставленные задачи, используя эту модель. Маленький контроллер позволяет обучающему алгоритму успешно справится с проблемой обратной связи в небольшом пространстве поиска, не жертвуя при этом выразительностью за счет большой модели мира. Обучая агента через призму его модели мира, мы покажем, что он может выработать очень компактную стратегию для достижения поставленной задачи.
В этой статье мы объединили несколько ключевых концепций из множества статей 1990-2015 годов о моделях мира и контроллерах на основе RNN с более поздними инструментами вероятностного моделирования и представим (на упрощенном примере) свой подход для тестирования некоторых из этих ключевых концепций в современных средах RL. Среди прочего наши эксперименты показывают, как данный подход может быть использован для решения достаточно сложной задачи «навигации по пикселям» гоночного автомобиля, которая не была решена ранее с использованием более традиционных методов.
Многие современные model-based подходы формируют модель, но обучаются при этом в реальной среде. Мы же попробуем полностью заменить среду на реконструкцию, воссозданную по его модели мира, обучая контроллер агента только внутри этой реконструкции и попробуем применить полученную стратегию в реальной среде.
Чтобы решить проблему переобучения мы введем в реконструированную модель ряд настраиваемых параметров, чтобы контролировать степень неопределенности реконструкции. Мы тренируем контроллер внутри более шумной и неопределенной версии его модели мира и демонстрируем, что это позволяет предотвратить переобучение. Мы так же коснемся других работ в области model-based RL, разделяющих наши идеи формирования динамической модели и обучения агента с использованием этой модели.
Мы представляем простую модель, вдохновленную нашей собственной когнитивной системой. В этой модели наш агент имеет визуально-сенсорный компонент, который сжимает увиденное в небольшой репрезентативный код. Он также имеет компонент памяти, который делает прогнозы относительно будущих кодов на основе исторической информации. Наконец, наш агент имеет компонент принятия решений, который решает, какие действия предпринять, основываясь только на представлениях, созданных его компонентами восприятия и памяти.

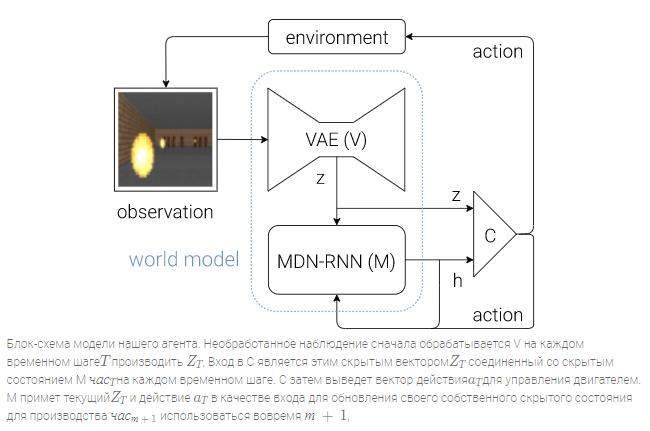
Наш агент состоит из трех компонентов, которые работают в тесном взаимодействии: Vision (V), Memory (M) и Controller ©.
VAE (V) Модель
Окружающая среда предоставляет нашему агенту данные высокой размерности на каждом временном шаге. Этот вход обычно представляет собой 2D-кадр изображения, который является частью видеопоследовательности. Роль V-модели заключается в изучении абстрактного сжатого представления каждого наблюдаемого входного кадра.
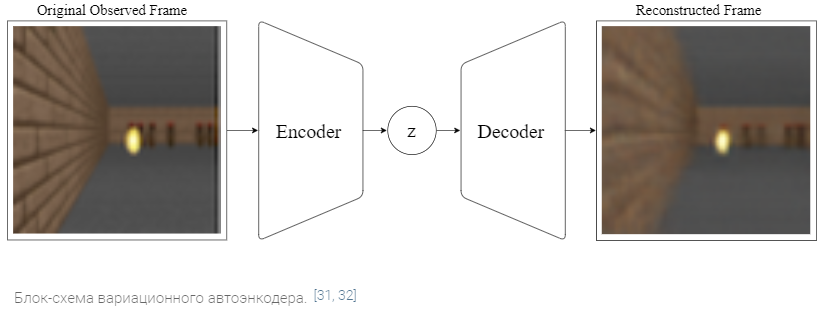
Мы используем Variational Autoencoder (VAE) как модель V в наших экспериментах. В следующей демонстрации мы покажем, как V-модель сжимает каждый кадр, полученный на шаге по времени t в низкоразмерный скрытый вектор z(t). Это сжатое представление может быть использовано для восстановления исходного изображения.

Модель MDN-RNN (M)
Хотя роль модели V состоит в том, чтобы сжимать то, что видит агент в каждый момент времени, мы также хотим сжимать происходящее во времени. Для этой цели роль модели М заключается в прогнозировании будущего. Модель М является прогнозирующей моделью будущего: векторов z , которые V, как ожидается, произведет. Поскольку многие сложные среды имеют стохастическую природу, мы обучаем наш RNN выводить функцию плотности вероятности р(z), вместо детерминированного прогноза Z.

Наш подход заключается в том, что мы аппроксимируем p(z) совокупностью нормальных распределений (mixture of Gaussian distribution) и обучаем RNN выдавать распределение вероятностей следующего скрытого вектора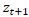 , с учетом текущей и прошлой информации, переданной в качестве входных данных.
, с учетом текущей и прошлой информации, переданной в качестве входных данных.
Конкретнее, RNN будет моделировать P(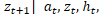 ), где a -действие, предпринятое в момент времени t, a
), где a -действие, предпринятое в момент времени t, a 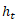 — скрытое состояние RNN в момент время t. Кроме того, добавим «температурный» параметр τ для контролируемой неопределенности модели — нужно подобрать такой τ, чтобы он максимально «подходил» для обучения нашего контроллера позже.
— скрытое состояние RNN в момент время t. Кроме того, добавим «температурный» параметр τ для контролируемой неопределенности модели — нужно подобрать такой τ, чтобы он максимально «подходил» для обучения нашего контроллера позже.
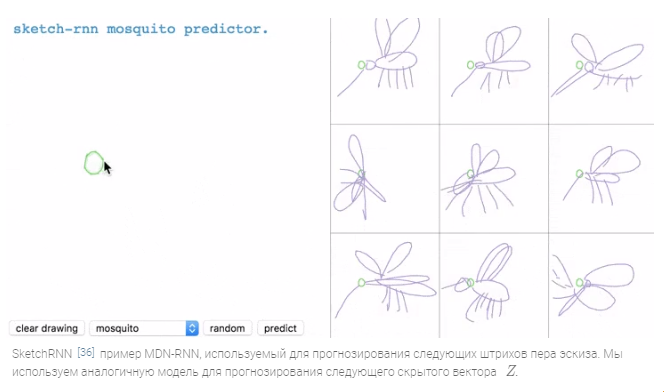
Этот подход известен как Mixture Density Network (MDN) в сочетании с RNN (т.е. MDN-RNN) и успешно использовался в прошлом для решения задач генерации последовательности, таких как воспроизведение рукописного текста и предсказание скетчей (см. картинку выше).
Модель контроллера (С)
Модель Controller © отвечает за определение порядка действий, которые необходимо предпринять, чтобы максимизировать ожидаемое совокупное вознаграждение агента во время запуска окружения. В наших экспериментах мы сознательно делаем C как можно более простым и небольшим, и обучаемся отдельно от V и M, так что большая часть сложности нашего агента находится в модели мира (V и M).
C — простая однослойная линейная модель, отображающая z и h непосредственно к действию a на каждом временном шаге:
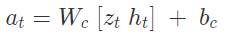
В этой линейной модели W и b являются весовой матрицей и вектором смещения, который отображает каскадный входной вектор [z; h] к выходному вектору действия a.
Следующая схема показывает, как V, M и C взаимодействуют с окружающей средой:
Ниже приведен псевдокод того, как наша модель агента используется в OpenAI Gym окружении. Выполнение этой функции для данного контроллера C вернет совокупное вознаграждение за один прогон.

Этот минимальный дизайн для C также предлагает важные практические преимущества. Достижения в области глубокого обучения предоставили нам инструменты для эффективного обучения больших и сложных моделей, при условии, что мы можем определить хорошо дифференцируемую функцию потерь. Наши модели V и M разработаны для эффективного обучения с использованием алгоритма обратного распространения с использованием современных ускорителей графического процессора, поэтому мы хотели бы, чтобы большая часть сложности модели и параметры модели находились в V и M. Число параметров линейной модели C, при этом — минимален. Этот выбор позволяет нам исследовать более нетрадиционные способы обучения C (как вариант — используя эволюционные алгоритмы), решать более сложные задачи RL, где проблема с присвоением награды является нетривиальной.
Для оптимизации параметров C мы выбрали Covariance-Matrix Adaptation Evolution Strategy (CMA-ES), как наш алгоритм оптимизации, поскольку он хорошо работает для пространств решений с несколькими тысячами параметров. Мы развиваем параметры C на одной машине с несколькими ядрами ЦП, выполняющими несколько прогонов среды параллельно.
От переводчика: это только первая часть оригинальной работы, и я думаю на этом стоит остановиться. Кому интересно — обязательно нужно ознакомиться с оригиналом, т.к. там полно интерактива и приводятся данные по реальным испытаниям на нескольких искусственных средах (Doom, Car Racing и другие).
Аннотация
Мы исследуем построение моделей популярных сред обучения с подкреплением генеративными нейронными сетями. Наша модель мира может быть быстро обучена (без учителя), чтобы сформировать сжатое пространственное и временное представление окружающей среды. Используя паттерны (features), из модели мира в качестве входных данных для агента, мы можем получить очень компактную и простую стратегию для достижения поставленных целей. Мы даже можем обучить агента полностью в «его воображении» (в среде, воссозданной по его модели мира) и перенести полученную стратегию обратно в реальный исходный мир.
Вступление
Люди формируют ментальную модель мира, основанную на своем (довольно ограниченном) восприятии. Мы принимаем решения и действуем на основании этой внутренней модели. Джей Райт Форрестер, отец системной динамики, описал ментальную модель так: «Образ окружающего мира в нашей голове — не более чем модель реального мира: никто не держит в уме весь мир, правительство или страну в целом. Мы выбираем только отдельные концепции и их взаимосвязи, дабы использовать их для представления реальной системы.»
Чтобы иметь возможность переработать огромное количество информации, постоянно поступающей извне, наш мозг выработал способность извлекать и запоминать абстрактное представление как пространственных, так и временных аспектов этой информации. Мы можем в реальном времени наблюдать за сценой и запоминать ее абстрактное описание. Также есть данные, говорящие о том, что то, что мы воспринимаем в данный момент основано на предсказании мозга о будущем на основе нашей внутренней модели.
Одна из версий, как бы эта предсказательная модель могла быть реализована в нашем сознании, строится на том, что речь идет не о прогнозировании будущего в целом, а о прогнозировании будущих сенсорных данных с учетом наших текущих действий. Мы способны инстинктивно действовать на основе этой модели и активировать рефлекторные поведенческие механизмы (в момент опасности, например) без необходимости сознательно продумывать стратегию поведения.
Возьмем бейсбол. У бэттера (игрок с битой в бейсболе, задача которого отбить мяч, брошенный питчером противника, прим. переводчика) есть буквально миллисекунды, чтобы определится с ударом — это меньше, чем время, которое затрачивает визуальный сигнал, на то чтобы достигнуть мозга. Единственное объяснение, как человек может «взять мяч» скоростью 100 миль в час — наша способность инстинктивно предсказать где и когда он окажется. Для бейсболистов все происходит подсознательно: их руки рефлекторно выполняют мах (англ: swing the bat) таким образом, чтобы бита оказалась в нужном месте и в нужное время — в соответствии с предсказанием их внутренней модели. Они способны быстро реагировать на собственные прогнозы, без необходимости сознательного перебора вариантов для нахождения лучшей стратегии.
Большие RNN — это модели с высокой выразительностью, которые могут работать с пространственными и временными данными. Тем не менее большинство описанных model-free методов в RL используют маленькие сети с небольшим числом параметров. Узким местом алгоритмов RL является проблема распределения подкрепления или проблема обратной связи (англ: CAP, credit assignment problem), что затрудняет применение этих алгоритмов в случае большой сети с миллионами весов, поэтому на практике используются меньшие сети, так как они быстрее достигают хороших стратегий в ходе тренировок.
В идеале, мы бы хотели тренировать агентов на основе больших рекуррентных сетей. Для их обучения может быть использован механизм обратного распространения ошибки. В этой работе мы рассмотрим обучение большой нейронной сети решать задачи RL, разделив агента на большую модель мира и небольшую модель контроллера. Сначала мы используем большую нейронную сеть (обучение без учителя) для создания модели мира, а затем методами RL обучаем совсем небольшой контроллер выполнять поставленные задачи, используя эту модель. Маленький контроллер позволяет обучающему алгоритму успешно справится с проблемой обратной связи в небольшом пространстве поиска, не жертвуя при этом выразительностью за счет большой модели мира. Обучая агента через призму его модели мира, мы покажем, что он может выработать очень компактную стратегию для достижения поставленной задачи.
В этой статье мы объединили несколько ключевых концепций из множества статей 1990-2015 годов о моделях мира и контроллерах на основе RNN с более поздними инструментами вероятностного моделирования и представим (на упрощенном примере) свой подход для тестирования некоторых из этих ключевых концепций в современных средах RL. Среди прочего наши эксперименты показывают, как данный подход может быть использован для решения достаточно сложной задачи «навигации по пикселям» гоночного автомобиля, которая не была решена ранее с использованием более традиционных методов.
Многие современные model-based подходы формируют модель, но обучаются при этом в реальной среде. Мы же попробуем полностью заменить среду на реконструкцию, воссозданную по его модели мира, обучая контроллер агента только внутри этой реконструкции и попробуем применить полученную стратегию в реальной среде.
Чтобы решить проблему переобучения мы введем в реконструированную модель ряд настраиваемых параметров, чтобы контролировать степень неопределенности реконструкции. Мы тренируем контроллер внутри более шумной и неопределенной версии его модели мира и демонстрируем, что это позволяет предотвратить переобучение. Мы так же коснемся других работ в области model-based RL, разделяющих наши идеи формирования динамической модели и обучения агента с использованием этой модели.
Модель агента
Мы представляем простую модель, вдохновленную нашей собственной когнитивной системой. В этой модели наш агент имеет визуально-сенсорный компонент, который сжимает увиденное в небольшой репрезентативный код. Он также имеет компонент памяти, который делает прогнозы относительно будущих кодов на основе исторической информации. Наконец, наш агент имеет компонент принятия решений, который решает, какие действия предпринять, основываясь только на представлениях, созданных его компонентами восприятия и памяти.
Наш агент состоит из трех компонентов, которые работают в тесном взаимодействии: Vision (V), Memory (M) и Controller ©.
VAE (V) Модель
Окружающая среда предоставляет нашему агенту данные высокой размерности на каждом временном шаге. Этот вход обычно представляет собой 2D-кадр изображения, который является частью видеопоследовательности. Роль V-модели заключается в изучении абстрактного сжатого представления каждого наблюдаемого входного кадра.
Мы используем Variational Autoencoder (VAE) как модель V в наших экспериментах. В следующей демонстрации мы покажем, как V-модель сжимает каждый кадр, полученный на шаге по времени t в низкоразмерный скрытый вектор z(t). Это сжатое представление может быть использовано для восстановления исходного изображения.
Модель MDN-RNN (M)
Хотя роль модели V состоит в том, чтобы сжимать то, что видит агент в каждый момент времени, мы также хотим сжимать происходящее во времени. Для этой цели роль модели М заключается в прогнозировании будущего. Модель М является прогнозирующей моделью будущего: векторов z , которые V, как ожидается, произведет. Поскольку многие сложные среды имеют стохастическую природу, мы обучаем наш RNN выводить функцию плотности вероятности р(z), вместо детерминированного прогноза Z.
Наш подход заключается в том, что мы аппроксимируем p(z) совокупностью нормальных распределений (mixture of Gaussian distribution) и обучаем RNN выдавать распределение вероятностей следующего скрытого вектора
Конкретнее, RNN будет моделировать P(
Этот подход известен как Mixture Density Network (MDN) в сочетании с RNN (т.е. MDN-RNN) и успешно использовался в прошлом для решения задач генерации последовательности, таких как воспроизведение рукописного текста и предсказание скетчей (см. картинку выше).
Модель контроллера (С)
Модель Controller © отвечает за определение порядка действий, которые необходимо предпринять, чтобы максимизировать ожидаемое совокупное вознаграждение агента во время запуска окружения. В наших экспериментах мы сознательно делаем C как можно более простым и небольшим, и обучаемся отдельно от V и M, так что большая часть сложности нашего агента находится в модели мира (V и M).
C — простая однослойная линейная модель, отображающая z и h непосредственно к действию a на каждом временном шаге:
В этой линейной модели W и b являются весовой матрицей и вектором смещения, который отображает каскадный входной вектор [z; h] к выходному вектору действия a.
Собираем все вместе
Следующая схема показывает, как V, M и C взаимодействуют с окружающей средой:
Ниже приведен псевдокод того, как наша модель агента используется в OpenAI Gym окружении. Выполнение этой функции для данного контроллера C вернет совокупное вознаграждение за один прогон.
Этот минимальный дизайн для C также предлагает важные практические преимущества. Достижения в области глубокого обучения предоставили нам инструменты для эффективного обучения больших и сложных моделей, при условии, что мы можем определить хорошо дифференцируемую функцию потерь. Наши модели V и M разработаны для эффективного обучения с использованием алгоритма обратного распространения с использованием современных ускорителей графического процессора, поэтому мы хотели бы, чтобы большая часть сложности модели и параметры модели находились в V и M. Число параметров линейной модели C, при этом — минимален. Этот выбор позволяет нам исследовать более нетрадиционные способы обучения C (как вариант — используя эволюционные алгоритмы), решать более сложные задачи RL, где проблема с присвоением награды является нетривиальной.
Для оптимизации параметров C мы выбрали Covariance-Matrix Adaptation Evolution Strategy (CMA-ES), как наш алгоритм оптимизации, поскольку он хорошо работает для пространств решений с несколькими тысячами параметров. Мы развиваем параметры C на одной машине с несколькими ядрами ЦП, выполняющими несколько прогонов среды параллельно.
От переводчика: это только первая часть оригинальной работы, и я думаю на этом стоит остановиться. Кому интересно — обязательно нужно ознакомиться с оригиналом, т.к. там полно интерактива и приводятся данные по реальным испытаниям на нескольких искусственных средах (Doom, Car Racing и другие).

