
Хабр Курсы для всех
РЕКЛАМА
Практикум, Хекслет, SkyPro, авторские курсы — собрали всех и попросили скидки. Осталось выбрать!
Я тоже когда мне кинули и прочитал заголовок, подумал "опять набрасывают". Но, не имею привычки закрывать статьи только потому, что с ними не согласен.
В итоге дочитам до конца, всё стало достаточно очевидным. Если вас и это не убедило, то в конце есть комментарий на +89 для развеивания последних сомнений.
Статьи которые вы линканули в качестве аргумента "вон фп ругают" это весьма очевидный стёб на уровне ущербно-ориентированного программирования.. Но ни там фп не ругают, ни тут ООП не ругают.
Причем написано достаточно толсто, поэтому если вы приняли это на веру, то вас очень легко задеть любым невосхищением ФП)
def fibonachi2(a, b):
yield a
yield from fibonachi2(b, a+b)
def fibonachi():
yield from fibonachi2(1, 1)
def nfibonachi(n):
result = []
for i, number in enumerate(fibonachi()):
if i == n:
return result
result.append(number)
Некоторое время назад у меня был вот такой код на питоне, где я хотел проверить, что список состоит из уникальных значений, и если это так, то получить его:
fair_id = reduce(lambda a, b: (a if a
== b else raise_(DepersonException('Multiple fairs are not supported'
))), fair_ids)В итоге в питон чате единогласно сказали, что это говнокод, и так не пишут. Как надо писать? Ну, из предложенных вариантов большинство является вариацией на тему:
fair_id = fair_ids[0]
if any(id != fair_id for id in fair_ids):
raise (DepersonException('Multiple fairs are not supported')Такие дела.
Если вдруг вопросы, почему редьюс лучше: если убрать строчку с проверкой, то исчезнет переменная fair_id, и попытка её использовать будет ошибкой инетрпретатора (предпочел бы компиляции, ну ладно уж). А во втором слуачае будет просто иногда неправильно отрабатывать скрипт.
Что до ленивости — то ленивость списков выражается через явную конструкцию, добавленную для этого — итераторы/генераторы. А вот для не-списков (деревьев, например) такого уже нет. А еще лучше: для управления флоу, эти ваши when/until функции.
Если вдруг вопросы, почему редьюс лучше: если убрать строчку с проверкой, то исчезнет переменная fair_id, и попытка её использовать будет ошибкой инетрпретатора (предпочел бы компиляции, ну ладно уж).
Это решается заведением отдельной функции:
def take_any_copy(list):
a = list[0]
if any(a != b for b in list):
raise DepersonException('Multiple items are not supported')
return aА ваш первый вариант — и правда говнокод, потому что не понять что он вообще делает без исполнения всего алгоритма в уме.
Не вижу, чем этот вариант лучше. Чем хуже я уже сказал — у него есть те же проблемы, что ифчик можно закомментить, а узнать об этом через 2 года.
Ну и в любом случае это аргумент к тому, что никакого фп в питоне нет, когда вместо комбинаторов советуют использовать циклы и выносить элементарные однострочники в отдельные функции.
А почему вы рассматриваете только комментирование? Точно так же я могу заменить ваш reduce на что-то ещё и всё поломать. И никакой компилятор мне не помешает...
Я оцениваю количество строк, в которых существует потенциально невалидная переменная. В частности a является невалидной до тех пор, пока она не проверена условием. Количество невалидных строчек одна (та, где мы проверяем на any).
С другой стороны у reduce количества невалидных строчек — ноль, нет никакого значения, которое уже не присвоено, но еще не проверено, что оно валидно.
Поэтому я придерживаюсь того способа, который дает меньше потенциально опасных строчек.
К слову, в идеале я хотел бы написать [fair_id] = set(fair_ids) с возможностью переопределить эксепшн который должен вылететь, тогда и читаемее было, и понятнее, но подходящей функции я не нашел. А трай кетчи очень не люблю.
Осталось понять почему опасной строчкой считается именно та, в которой существует "потенциально невалидная переменная".
Я вот опасной строчкой считаю ту, которая не пойми что делает. Потому что наличие такой строчки ускоряет переход кода в категорию "legacy, наверное для чего-то нужно"
Ну мне лично очевидно, что она делает. "если аргументы это одно значение, верни его, иначе брось исключение", причем по исключению понятно, почему так. Окей, можно вынести в функцию как у вас выше сделано, если возникают затруднения, тогда вообще всё тривиально.
Очевидно? Вы или гений, или обманываете.
Я не гений, но и не обманываю. Давайте еще раз код посмотрим:
fair_id = reduce(lambda a, b: (a if a
== b else raise_(DepersonException('Multiple fairs are not supported'
))), fair_ids)я читаю:
номер ярмарки — ага, новая переменная
равен — ага, щас посмотрим значение
свертке списка fair_ids — ага, значит смотрим на лямбду свертки.
чтобы понять лямбду свертки нам достаточно посмотреть, что происходит с двумя переменными: a и b.
(a if a == b else raise_(DepersonException('Multiple fairs are not supported') — если оба параметра совпадают, то возвращаем один из них, иначе бросаем исключение что параметры не могут различаться.
Какой-то такой процесс прочтения кода. Не очень понимаю, в какой момент тут может возникнуть проблема. С лямбдой вроде всё понятно, не думаю, что какой-то из питонистов бы ругался на код:
foo(a,b):
return a if a
== b else raise Exception('Multiple argument are not supprted')А больше там ничего и нет — присваивание и редьюс.
Перед тем, что вы написали, надо ещё распарсить нетривиально расставленные вложенные скобки, и это в языке где вместо фигурных скобок используются отступы! Один только грустный смайлик ))) в третьей строчке убивает всю читаемость.
А после этого всего надо сделать логический вывод "если исключения не было — значит, все параметры совпадают". Для чего нужно сначала понять, что оба параметра лямбды на каждом шаге являются двумя элементами исходного списка.
В то же время, альтернативный вариант читается безо всяких сложностей, просто как текст.
Перед тем, что вы написали, надо ещё распарсить нетривиально расставленные вложенные скобки, и это в языке где вместо фигурных скобок используются отступы! Один только грустный смайлик ))) в третьей строчке убивает всю читаемость.
Возможно дело в этом, я скобки игнорирую, в процессе парсинга они выступают как пробелы между функциями.
А после этого всего надо сделать логический вывод "если исключения не было — значит, все параметры совпадают". Для чего нужно сначала понять, что оба параметра лямбды на каждом шаге являются двумя элементами исходного списка.
ИМХО это не сложнее чем сделать вывод "если исключения не было — значит, все параметры совпадают с первым".
Ладно, возможно, вы правы. Я хотел написать что-то в таком духе:
var fairId =
fairIds.Distinct().SingleOrDefault()
?? throw new DepersonException("Multiple fairs are not sup");Возможно, действительно с отдельной функцией с валидацией читалось бы лучше. Спасибо!
Возможно дело в этом, я скобки игнорирую, в процессе парсинга они выступают как пробелы между функциями.
Опасная практика когда в языке есть функции с переменным числом элементов или перегрузка функций.
А можно конкретнее пример где это может выстрелить? А то такого, чтобы тайпчекнулось, но неправильно работало трудно представить. Кроме как foo(bar(1,2), 3), где обе функции это варарги, и `bar() еще и число возвращает. Но так просто не стоит писать. А более реалистичного примера в голову что-то не приходит.
В Питоне тайпчекером на пол-ставки, увы, вынужден работать программист. Отсюда и ненависть к неидеоматичному коду.
В C# богатые традиции по созданию перегрузок функций наложены на новейшие возможности компилятора по созданию параметров со значениями по умолчанию. Я просто не хочу задумываться на тему "тайпчекнется или нет в случае ошибки", лучше пересчитаю на всякий случай скобочки :-)
В Питоне тайпчекером на пол-ставки, увы, вынужден работать программист. Отсюда и ненависть к неидеоматичному коду.
Ну, мне тут питонисты недавно продавали mypy, довольно крутая штука. Вот например: https://mypy-play.net/?mypy=latest&python=3.8&gist=6dea37f9f65b88bbb754e2504353e4ea
В C# богатые традиции по созданию перегрузок функций наложены на новейшие возможности компилятора по созданию параметров со значениями по умолчанию. Я просто не хочу задумываться на тему "тайпчекнется или нет в случае ошибки", лучше пересчитаю на всякий случай скобочки :-)
Ну, одна из причин почему я предпочитаю статически типизированные япы — нравится перекладывать работу на машину, пусть думает, она в отличие от меня ошибается куда реже)
Ну, одна из причин почему я предпочитаю статически типизированные япы
Я придерживаюсь более радикального мнения: ДТ была ошибкой и в 2020 в языках общего назначения не нужен. :)
Я предпочитаю не делать резких высказываний насчет "нинужных" языков и людей, которые ничего не понимают.
Ограничусь высказыванием, что я один раз брал питон в коммерческом проекте, и то по единственной причине, что нужная мне библиотека была только под него (причем под второй).
При чём тут языки? Я про то, что ДТ не даёт никаких преимуществ, кроме ускорения написания простых скриптов ценой усложнения поддержки кода, снижения его надёжности и скорости работы. В том же питоне ДТ добавляет гораздо больше проблем, чем решает.
А можно поподробнее прот питон? Просто у меня мнение, что проблемы прежде всего доставляет слабая типизация, а в питоне вроде как сильная
Как минимум, появляется забавный класс ошибок: передача в функцию/метод аргумента не того типа. Это звучит не так страшно примерно до того момента, как кодовая база перешагивает за 100 тысяч строк. Единственный выход — обмазываться тестами (большим количеством, чем для статики) и ставить ассерты. Отсюда и легендарное питоновское кидание стектрейсами по любому поводу.
Проверка типов происходит в рантайме и это сильно не бесплатно. И ещё сильнее бьёт по скорости создания объектов: вместо простых vtable'ов приходится хранить кучу данных о методе, вплоть до его имени и заполнять эти данные при создани объекта. Хочется распихать миллион записей по структурам и обрабатывать в памяти? Нет, работай с сырыми данными, энтот ваш ООП не нужен.
Статическая типизация, оказывается, обладет свойством самодокументации: изучаем API библиотеки? Сами по себе возвращаемый тип и типы аргументов говорят об ограничениях на входные/выходные данные, а так же о работе функции. В ДТ приходтся лезть в документацию на каждый чих. И писать её на каждый чих.
Ещё интересное следствие: больший простор творчества для говнокода. Поменять в существующем методе возвращаемый тип? Или поставить возвращаемый тип в зависимость от входных данных? Питон считается языком с низким порогом вхождения, но на деле требует опыта и самодисциплины от разработчика. Плохая репутация питона во многом растёт именно отсюда.
"Фунциональщина" в таком виде в питоне не приветствуется просто потому что почти всегда используется только ради того, чтобы писать плохочитаемый код ради выпендрежа.
В итоге в питон чате единогласно сказали, что это говнокод, и так не пишут.
будет просто иногда неправильно отрабатывать скрипт.
Такие дела.
Покажите в каком моменте это уб. Я вообще не уверен, что в питоне хоть что-то уб.
иногда неправильно отрабатывать
Нет, UB и "неправильно работает" это совершенно разные вещи.
Undefined behavior — это если бы оно "иногда неправильно отрабатывало", потому что один и тот же код превращается в неидентичные результирующие алгоритмы, в зависимости от внешних причин. А тут алгоритм всегда один и тот же — просто в общем случае некорректный, но иногда всё же выдающий правильные значения.
Это будет вполне определенное поведение, которое не является ожидаемым.
В житейском смысле — да. Но в программировании эти слова устоялись в другом значении, как указано в соседней ветке: это случай, когда поведение программы явно указано как неопределённое правилами языка. В данном случае поведение определённое — программа для каждого входа выдаёт соответствующий ему вывод, а соответствует ли он ожиданиям вызывающей стороны — вопрос отдельный.
Надо было залезть не в гугл переводчик, а в документацию, а то вам гугл переводчик напереводит "полено мерзавца", а вы потом пойдете ругаться, какие смухенчики Линус в общеиспользуемый софт подсадил.
Касаемо питона, пункт 6.15 документации:
Python evaluates expressions from left to right. Notice that while evaluating an assignment, the right-hand side is evaluated before the left-hand side.
In the following lines, expressions will be evaluated in the arithmetic order of their suffixes:
expr1, expr2, expr3, expr4 (expr1, expr2, expr3, expr4) {expr1: expr2, expr3: expr4} expr1 + expr2 * (expr3 - expr4) expr1(expr2, expr3, *expr4, **expr5) expr3, expr4 = expr1, expr2
При этом никаких исключений я не нашел. Следовательно, в питоне УБ вообще нет. Впрочем, меня это не удивляет, емнип в джаве его тоже нет. В сишарпе есть, но очень немного.
Почему "имитирующая"-то?
А программы на идрисе — императивные? А то он строгий по умолчанию.
А программы на функциональных языках, для теорий типов которых выполняется strong normalization theorem
А почему вы считаете, что функция-генератор "полностью выполнилась" когда вернула управление, а не когда исполнение кода дошло до её конца?
Из-за этого, в случае работы над чем-либо сложным, такую программу всё-равно в голове приходится транслировать в императивный стиль
Следует ли из этого, что «в случае работы над чем-либо сложным» программист должен в голове транслировать написанную программу в двоичный код?
Императивная программа на высокоуровневом ЯП остаётся императивной и при выполнении в машинных кодах, полностью сохраняя логику, которую в неё явно заложил разработчик.
разработчик при разработке должен держать в голове две модели вычислений вместо одной
Во-первых куче JS-разработчиков незнание нижележащей платформы не мешает работать :dunno:
Например, есть пара небольших задачек про производительность. В каждой из задач два варианта исполнения одного и того же кода, только один из них исполняется сильно медленее другого. Вопрос в том, чтобы обьяснить почему так. Ответ очевиден любому человеку, знакомому с архитектурой процессоров, но большинство JS-разработчиков которым я показывал всё списали в итоге на магию.
Сами задачи на js, чтобы было легко исполнить их в браузере:
https://jsfiddle.net/djth9oq7/
https://jsfiddle.net/3smxuh1o/
Во-вторых возьмем другую парадигму: ООП. Никто вроде не говорит "почему вы выполняете ООП код на императивной машине"? Хотя ООП отличается прям настолько же, в этих ваших процессорах нет никаких менеджеров, адаптеров, визиторов и прочего. Но как-то работает, хотя часть паттернов (например предпочтение AoS нежели SoA) прямо проитиворечит нижележащей архитектуре. И вполне неплохо.
Ну и наконец можно просто пойти на бенчмаркгеймс и посмотреть как там себя хаскель или скала показывают. А показывают на уровне джавы. Что кмк вполне себе приемлемый уровень. Можно поспрашивать знакомых, насколько им сложно оптимизировать ФП код. Судя по моим знакомым — проще, чем плюсовый. Потому что локал ризонинг и ссылочная прозрачность.
Любая программа, реализованная в подходе ФП, выполняется на «императивной» ОС и на «императивном» железе, а может быть и на императивном интерпретаторе. Из-за этого, в случае работы над чем-либо сложным, такую программу всё-равно в голове приходится транслировать в императивный стиль с учётом всех нюансов языка. Для многих ситуаций (не для всех) это выглядит как чистой воды лишняя работа.
Любая программа в итоге превращается в набор инструкций на АЛУ, тем не менее разработчики (особенно, всяких вм вроде джаваскриптов или сишарпа) могут спокойно писать, не думая об этом.
Никогда не мог понять этого возражения. Это как сказать, что типизированные языки компилируются в нетипизированный машинный код, поэтому нужно уметь транслировать в такой нетипизированный код в голове, и это выглядит как лишняя работа.
Спасибо за статью, любопытно. Хотя я не со всем согласен:
Основным отличием функционального программирования от императивного является не свойство чистоты функций, не наличие безымянных функций, функций высших порядков, монад, параметрического полиморфизма или чего-бы то ни было еще. Основным отличием является использование иной модели вычислений. Все остальное — не более чем следствия.
Я остаюсь при своем мнении, что чистота — это основное свойство ФП, а вот модель вычислений — нет. Просто так получилось, что императивный подход больше склоняется с жадной модели (где лучше контроль над использованием ресурсов), а функциональный — к ленивый (где более естественны рекурсивные схемы). Тем не менее, это не является обязательным требованием, и нетрудно привести контрпример строго ФП языка: например, Idris.
Я больше склоняюсь к тому, что есть языки, где ленивость включена/выключена по-умолчанию для всех типов, а для конкретных она включается/выключается: банг операторы, seq, лэзи типы, и вот это всё. То есть вопрос в том, какую парадигму язык по-дефолту рекомендует. Тем не менее, на хаскелле спокойно можно писать строго (особенно этим любит заниматься 0xd34df00d ), а на этих ваших питоношарпах — лениво.
Нужны ли монады в императивном мире? У меня нет устоявшегося мнения по данному вопросу. Автор этого поста уверен, что нужны.
Боюсь, вы совсем не так поняли мой посыл) Я нигде не предлагал писать на императивных япах с монадами и стрелками. Я лишь использовал общеизвестный язык, чтобы более явно донести мысль в понятных людям терминах. Я сам пишу сейчас фуллтайп на сишарпе, в основном, и я не пишу ни монад, ни either'ов — продолжаю плакаться и колоться писать частичные функции с эксепшнами, и никакими монадами не упарываюсь: я прекрасно знаю, в какое нечитаемое месиво это превращается, лучше уж жить с известными недостатками, чем с этим.
Просто туториалов на хаскелле хватает и без меня, а вот так чтобы обычный ООП разраб понял, зачем вся эта машинерия нужна — вот, пожалуйста, статья. Писать так не надо, это просто объяснение. Чтобы писать: велкам ту зе хаскель, ну или скала.
Я сам пишу сейчас фуллтайп на сишарпе, в основном, и я не пишу ни монад, ни either'ов — продолжаю плакаться и колоться писать частичные функции с эксепшнами, и никакими монадами не упарываюсь: я прекрасно знаю, в какое нечитаемое месиво это превращается, лучше уж жить с известными недостатками, чем с этим.
Просто рано или поздно оно превращается в такое:
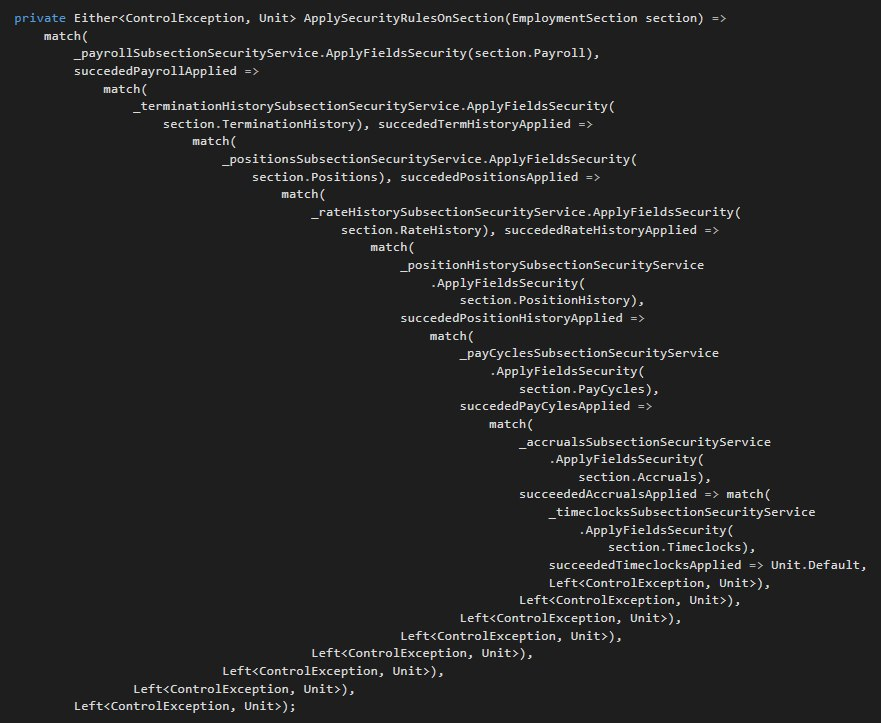
Это можно написать чуть адекватнее, но я всё равно не очень доволен опытом Either'ов в одном из микросервисов, где они есть.
Лучше уж эксепшны, право слово. А еще лучше брать подходящий язык: хотя бы фшарп, где работа с АДТ не вызывает такой боли.
Э-э-э, а там хоть один из возвращенных параметров где-то дальше используется?
Если я ничего не путаю, этот код можно заменить на цикл.
Или это настолько нагруженный микросервис, что виртуальные вызовы в таком количестве тут недопустимы? Тогда надо собрать и по-билдить Expression.
Тут нет никаких циклов, тут просто последовательное выполнение. На обычном дотнете это выглядело бы как огромный трай кетч с упаковыванием значения в Either.
А в каком-нибудь хаскелле это было бы:
applySecurityRulesOnSection section = do
_ <- applyPayrollFieldSecurity (section ^. payroll)
_ <- applyTermFieldSecurity (section ^. terminationHistory)
_ <- applyPositionFieldSecurity (section ^. positions)
_ <- applyRateHistoryFieldSecurity (section ^. rateHistory)
...Если бы from в шарпе был чутка удобнее, то и в нем можно было бы.
ИСЧХ в языке с монадками в языке есть возможность получить бесплатную параллелизацию:
applySecurityRulesOnSection section = liftA4 work a b c d where
a = applyPayrollFieldSecurity (section ^. payroll)
b = applyTermFieldSecurity (section ^. terminationHistory)
c = applyPositionFieldSecurity (section ^. positions)
d = applyRateHistoryFieldSecurity (section ^. rateHistory)
work = ...Не обязательно что оно прям будет исполняться параллельно, но вот то что мы теперь можем получить все ошибки, а не споткнуться на первой попавшейся — неплохой бонус.
Это у вас циклов нету, а я предлагаю добавить:
foreach (var handler in new Func<Either<ControlException, Unit>>[] {
() => _payrollSubsectionSecurityService.ApplyPayrollFieldSecurity(section.Payroll),
// ...
}) {
var result = handler();
if (!result.Succeded) return result;
}После преобразования к такому виду код точно так же можно будет при желании "распараллелить".
Кстати, в функциональных языках подобное преобразование тоже приведёт к упрощению кода.
ну делаете
Either<ControlException, Unit[]> = sections
.Select(section => _payrollSubsectionSecurityService.ApplyPayrollFieldSecurity(section.Payroll))
.Sequence();и всё. Не добавляют циклы тут никакой сложности.
Э-э-э, это вы о чём? Откуда взялись sections во множественном числе?
Я не предлагаю усложнять код, я его упростить предлагаю.
А, понял, не так прочитал.
Да, в данном случае функции друг от друга не зависят, и поэтому можно так переписать. Но если они начинают зависеть, то так сделать уже не получится. К тому же вот этот цикл с проверкой на !result.Success это совершенно механическая работа, хотелось бы её не совершать.
public Either<L,T> Select<T>(Func<R, T> map)
{
if (IsLeft)
return new Either<L, T>(left);
else
return new Either<L, T>(map(right));
}
public Either<L, R3> SelectMany<R2, R3>(Func<R, Either<L,R2>> select, Func<R, R2, R3> project)
{
if (IsLeft) return new Either<L, R3>(left);
var selected = select(right);
return selected.IsLeft ? new Either<L, R3>(selected.left): Select(t => project.Invoke(right, selected.right));
}
var res = from a in applyPayrollFieldSecurity(section.Payroll)
from b in applyTermFieldSecurity(section.TerminationHistory)
from c in applyPositionFieldSecurity(section.Positions)
from d in applyRateHistoryFieldSecurity(section.RateHistory)
select ...
Верно, но работа с Either в дотнете всё же не очень удобна, особенно если типы ошибок вдруг различаются. Но да, с линукшной ду-нотацией выглядет очень схоже. Жалко, сишарп так и не научился в плейсхолдер _ в LINQ. Причем везде в других местах оно работает:
_ = 5;
_ = 10;А вот в LINQ — почему-то нет.
С Idris не знаком, комментировать не могу.
Очень рекомендую познакомиться, во-первых завтипы тащат, а во-вторых это замечательный пример, который опровергает "фп должно быть ленивым". Просто ленивое ФП удобнее и естественнее ложится на рекурсивные функции которые там часто пишут.
Соответственно и все дальнейшие рассуждения следуют из неверной посылки: вот есть идрис, вот он фп, вот он жадный, и вполне себе тьюринг-полный. Более того, ленивость наоборот плохо работает с зависимыми и линейными типами, насколько мне известно.
Это такая же зыбкая почва, как "Что такое ООП". Вот все сходятся, что джава — ооп, а допустим си — нет. Почему? Вон, куча примеров, как люди делают структуры, руками таскают указатели на vtable, вот вам все три кита, под которыми обычно ООП продают. Или это что-то еще?..
Потому что в моем понимании четких критериев парадигм просто нет. То есть ООП язык это тот, в котором удобно работать со всем как с объектами. Причем удобство — вещь довольно субъективная. По нему и получается отличить джаву от си, потому что таскать втейбл руками — неудобно.
Точно так же можно сказать про ФП. Можно ли заэнкодить в тайпскрипте ХКТ, сделать там монады-аппликативы? Да запросто. Будет ли этим удобно пользоваться? Не факт… Вопрос: является ли TS функциональным?
Просто не надо путать корреляцию с казуацией :) Да, ФП часто идут комплектом с ленивостью, мощными системами типов и так далее. Но далеко не факт что что-то из этого является причиной, следствием или они вообще взаимосвязаны. Возможно, так просто получилось. Возможно, они не всегда идут пачкой.
Много разных вариантов.
Вроде автор ООП не считает, что Java ООП :)
Если Ваша задача — донести смысл «функциональных» конструкций до программистов на сишарпах и ему подобных в привычных для них терминах, то с этой задачей Вы по-моему справляетесь отлично. Мои сомнения вызвало то, что код, подобный приведенному Вами, обычно воспринимается с позиций «как я могу это использовать», особенно с учетом сделанных Вами акцентов на полезности функциональных подходов в практике программирования.
Спасибо за замечание, возможно, стоило сделать более явную сноску на какие-нибудь курсы по скале или хаскеле )
У меня имелся опыт, связанный с обучением функциональному подходу. Обычно трудность в том, чтобы заставить перестать проводить ложные параллели со знакомыми конструкциями из структурного и ООП-программирования и переносить привычные подходы на функциональные программы. Похожая ситуация, только с обратным знаком, может (на мой взгляд) иметь место в случае вашего поста про монады: перенос абстракций в парадигму, где им не место. Как я упоминал в статье, монады — естественное для ФП образование, призванное решить ряд его естественных же внутренних проблем. Для языков типа шарпа они выглядят искусственным конструктом с неочевидными преимуществами. Так что само появления кода, реализующего монады и функторы, я воспринял неоднозначно.
Смысл в том, что от наличия или отсутствия тайпкласса Monad они не появляются и не исчезают. Это просто типы с определенным функционалом. По сути это как показать школьнику, что сложение и умножение это на самом деле одна и та же операция, просто над разными моноидами. Просто показать, что операции имеют больше общего, чем кажется на первый взгляд. И понимание монады может пригодиться в любом япе, хотя бы с точки зрения "а вот были бы они, я б щас не пилил этот костыль".
Смысл в том, что от наличия или отсутствия тайпкласса Monad они не появляются и не исчезают. Это просто типы с определенным функционалом.
Но это только мое ощущение. Возможно, кому-то такой подход действительно поможет воспринять эти концепции, хотя по-моему пользуясь конструкциями императивного языка невольно рассуждаешь обо все, что видишь, через призму последовательного исполнения кода.
Даже если таки людей меньшинство — то куча монад-туториалов уже существует (тот же Брагилевский над моей статьей в твиттере уже посмеялся), но для этого меньшинства не написано вообще ничего. Все они начинаются "давайте возьмем хаскель". Собственно, поэтому я статью и писал, потому что общаться надо на том языке, который понимают, а не на том который вы знаете.
Про императивщину и ФПшность неплохо у Бартоша написано, где он сравнивает два различных взгляда на программу.
del
Какой коврик? По-сути ФП программы накладывают одно ограничение "всё взаимодействие с внешним миром должно быть асинхронным". Я бы не сказал что это дофига сложное ограничение, более того, на практике у меня вон в программе всё взаимодействие асинхронное: получение хттп запросов, запросы в БД, запросы в эластик, ...
Выходит, что и ограничений никаких нет.
Если у вас нет способа достать результат "Грязно" (то есть функции Promise -> T или аналога), то вы не сможете написать программу, которая читает или пишет нечисто. У вас просто нет способа пронаблюдать эффект, вы можете только композировать через then что делать. когда действие сделано.
Верно. Именно поэтому в том же хаскелле функция которая приоткрывает шторку называется unsafePerformIO, и против неё целые линты есть.
Но подход работает, и получаем все плюшки прозрачности: композабельность и предсказуемость. А то что оно реально будет в базку ходить и на экран что-то печатать — ну такой уж несовершенный мир, мы ведь хотим всё же результат увидеть.
Не знаю как у вас, а у меня 90% взаимодействие и так асинхронное, потому что по сети: либо с другими сервисами, либо с базой, либо ещё с чем. То что вывод в консоль/чтение из неё становятся асинхронными, ну это вроде не так уж страшно, тем более что асинк-авейт давно везде есть, в хаскелле вообще больше 20 лет уже.
Апи IO совпадает с Async, по сути Async это маркерный ньютайп для IO. Никаких других причин заводить отдельный тип я не нашел (в чате мне тоже не смогли ответить).
Это самая простая и прямая аналогия с ежедневным программированием. ИСЧХ человек выше сразу же уловил суть.
Такие дела)
Зависит от определения асинхронности. В обсуждаемом контексте я имею в виду буквально операция, результат которой будет доступен когда-то в будущем. Точно также можно относиться к результатам чтения/записи IO.
"Часть кода, обернутая в IO" начинает выполняться как только этот IO вернули из main.
Вернули в качестве возвращаемого значения.
Любая IO в программе либо так или иначе оказывается скомбинирована внутрь той, которая вернулась из main; либо оказывается забыта и не выполняется. Ну, ещё есть третий вариант — unsafePerformIO, но он на то и unsafe.
Если написано main = foo >> bar — значит, будет выполнена сначала foo, потом bar.
Что здесь меняет ленивость?
Если написано main = foo >> bar — значит, будет выполнена сначала foo, потом bar.
С того, что смысл операции >> именно в этом.
Чтобы доказать что это не так покажите контрпример, где вычисление будет произведено в обратном порядке. Если же такого контрпримера нет...
Потому что доказывать нужно существование чего-то, а не отсутствие, так что бремя доказательства тут так не работает. Вопрос звучит как "есть ли основания утверждать что определение точки в пространстве такое?". То есть, это как-то считается интуитивно понятным, но доказательства что другого определения точки нет, я не знаю.
Впрочем, как уже выше я написал, контрпример быстро бы расставил всё по своим местам.
foo >> bar — значит, будет выполнена сначала foo, потом bar
Sequentially compose two actions, discarding any value produced by the first, like sequencing operators (such as the semicolon) in imperative languages.
https://hackage.haskell.org/package/base-4.12.0.0/docs/Control-Monad.html#v:-62--62-
"Последовательное выполнение двух действие, где результат первого игнорируется, прямо как в этих императивных языках" как по мне достаточно явно говорит, что происходит и в каком порядке.
Вообще-то гарантирует. Потому что операция >>= тоже обладает нужным свойством.
Мешает. Мешает тот факт, что такое IO никому нахрен не нужно.
Никому не нужен язык, в котором не существует возможности указать порядок выполнения операций над внешними для языка объектами.
seq — это эффект. И unsafeRunIO — тоже эффект. И появились они не из вредности, а потому что нужно на практике. Это я к тому, что не следует идеализировать. Haskell форсирует, конечно, дисциплину, но точности это не добавляет, потому что в библиотеках может быть всякое.Только если у вас есть ⊥. Но хаскелисты прикидываются, что у них его нет.
А при чём тут ⊥?
seq дает наблюдаемую разницу только на боттомах. Собственно, про это есть в вики.
seq. В математической модели языка её необходимо выражать, как эффект. Поэтому всякие разные категорные модели Haskell разваливаются.eval, а в языках программирования так и делается, то это эффект. Вот здесь вычиталПочему все так про этот внешний мир любят говорить.
С внешним миром, внезапно, можно работать чисто. Зачем нужны по-вашему всякие хаскелли и скалы, если в них (если взять вашу точку зрения за истину) нельзя даже ответ, что оно посчитало, вывести на экран?
А вы на прологе что-нибудь писали? Там немного странная парадигма, но для своих задач она куда лучше чем аналоги. По крайней мере я не представляю другого языка, где в 200 строчек студент может написать неплохую экспертную систему.
Ну, вывод в консоль там действительно нетривиальный. Впрочем, он никогда не проектировался под IO, его задача именно что задать правила и базу знаний, и получать результаты. Для своих задач вроде солвинга он более чем хорош. Использовать его как язык общего назначения — наверное, не стоит.
Что до "цены за чистоту" не надо забывать, что в целях оптимизаций всегда можно написать мутабельный грязный код, и скрыть его за чистой абстракцией. Ну прямо как ансейф в расте. Точно так же не надо это делать постоянно, но иметь в голове понимание такой возможности полезно.
Что до обучающих материалов: то что идрис, что агда это максимально маргинальные языки (для идриса плагин 3 года не обновлялся), ну и есть же хаскель, который создавался именно для того, чтобы быть понятным разным людям. Так что возможно за пределами хаскелля и не надо ничего искать, раз есть хаскель.
А курсы по "фп в языке %мейнстрим_ланг_нейм%" мне тоже не очень понравились — много мусора, толку не очень.
Ну и по идрису, и по агде есть весьма годные книжки (Type-driven development with Idris, Verified functional programming in Agda, дальше чуть хардкорнее Programming language foundations in Agda). А что плагин не обновлялся — ну, идрис-плагин для вима тоже примерно столько же не обновлялся, но зачем, если он просто работает?
У кого работет? У меня например — нет, баг что не работает 3 года висит открытый. Так и живем.
У меня есть некая претензия к фанатам "ленивых вычислений".
… Если у вас вычисления, то их надо делать. Иначе, зачем их написали в программе?
Если у вас в программе вычисления, которые появляются как результат пересечения двух абстракций и их быть не может — для этого есть zero cost abstractions и такое должно вычищаться компилятором как dead code.
Если у вас вычисления определяются внешними событиями (скроллингом пользователя, прерываниями, etc), то вы можете откладывать вычисления на момент происхождения события без использования ленивых вычислений (event driven, futures и т.д.)
Для меня ленивые вычисления — это такой оверкоммит по процессору. Типа, нам тут сложно разобраться что считаться будет, что нет, так что мы обещаем что считать будем всё, но на самом деле будем считать только то, что понадобится. А если понадобится считать до конца (например, узнать len() у ленивого бесконечного списка), то ой. Прийдёт местный полицай и устроит bottom (аналог oom'а для вычислений).
У меня есть некая претензия к фанатам "ленивых вычислений".
… Если у вас вычисления, то их надо делать. Иначе, зачем их написали в программе?
если у вас написано if (a == 3 && b == 5) и a оказалось равно трем, зачем вы писали b == 5? Ведь оператор && в си-подобных языках как раз ленивый, как и ||.
Если обобщить это с булевых операций на все остальные, и получим хаскельную ленивость. Тем не менее, про булевы оператор никто не спрашивает "а зачем вы их пишете", почему тогда в общем случае такой вопрос возникает?
Лень помогает писать эффективные рекурсивные данные, бесконечные данные, или управлять флоу снаружи: все эти императивный while/break/early return в ленивом языке появляются просто сами по себе, без необходимости заранее об этом думать.
На самом деле лень — это оптимизация best case. При этом, когда приходит worst case, мы получаем tail latency от которой индустрия уже лет 5 пытается избавиться и не может. Это когда быстрый код почему-то иногда делает медленно.
Пример (того же уровня): if (fast_ok() && slow_second_guess()), и у вас fast_ok() выполняется в 99.995% случаев за 30μs, а slow_second_guess вычисляется 20 секунд, и вы пытаетесь понять, что не так.
Вопрос не в оптимизациях наносекунд, а в более удобных алгоритмах. Ну скажем, я хочу получить самое большое число в списке, но не больше чем заданное. Беру и пишу
const int myTreshold = 100;
var max = foos.Fold((acc, x) => Max(acc, x, myTreshold));Так вот в в строгом языке мы будем проходить весь итератор (из миллиона допустим элементов), хотя из первых 10 мы упёрлись в 100 и результат уже дальше не поменяется.
Какой выход в энергичных языках? Ну, костылить такой же фолд, но "с вывертом", чтобы возвращать флаг, продолжать ли вычисления дальше или нет:
const int myTreshold = 100;
var max = foos.FoldEarlyReturn((acc, x) =>
acc >= myTreshold ? (myTreshold, finished: true) : (Max(acc, x), finished: false));В лениовм языке самая первая версия работает ожидаемым образом, и дублировать апи для "Ранних выходов" не надо.
Собственно на примере итераторов никто ведь не удивляется, что мы можем сформировать список из миллиарда элементов, который отработает за долю секунды, потому что нам понадобились только первые 100 элементов. Непонятно, почему люди решили, что на булевых операциях и итераторах польза ленивости закончилась.
Простите, но зачем итератор исчерпывать полностью? Обычный if решает проблему.
Иф на чем? У вас ведь нет элементов. Или вы предлагаете откатиться к циклам? Ну да, там и брейки, и continue есть. Только фишка в том, что с ленью break и continue могут быть функциями, а не захардкоженными в язык конструкциями.
И когда у вас есть супер-хороший комбинатор MyUsefulCombinator, который всем хорош, но только он исчерпывает все элементы, то либо идти и писать руками (то, что за вас уже написано, в целом), или идти заводить issue "пожалуйста, сделайте такой же комбинатор, но другой". Как видите, в расте идут по обоим путям сразу.
Пример (того же уровня): if (fast_ok() && slow_second_guess()), и у вас fast_ok() выполняется в 99.995% случаев за 30μs, а slow_second_guess вычисляется 20 секунд, и вы пытаетесь понять, что не так.
Вы что, пытаетесь сказать что если бы код работал за 20 секунд во всех случаях — было бы лучше?
Да. Тогда бы было известно, что это медленное место, которое бы починили.
Представьте себе, что slow_second_guess не тупит 20 секунд, а роняет программу. На тестах до этой ветки код не доходит и хорошо, а в продакшене раз в 0.05% случаев — роняет.
Деградация производительности тут ничем не отличается от падения. Внезапно, редко, и "скрывается" ленивыми вычислениями.
Вполне возможно, что это и без того известно, и именно потому проверка fask_ok() была в принципе добавлена.
Это как раз и вызывает tail latency.
Как нас учит Великий Тьюринг и его последователи, не важно за какое время аккерман вычисляется. Мы знаем, что он вычисляется, а значит, тип не ⊥. С практической же точки зрения, функция, которая вычисляется больше, чем за предельное время — это ⊥, потому что ETIMEOUT.
Т.е. код, который есть, но 99.995% случаев не выполняется — это не очень хороший код. Его трудно проверить, в нём могут быть логические ошибки, или, ещё хуже, предположения, которые уже давно не правда (но никто код не менял, потому что он обычно не выполняется).
В этом смысле правильный код должен выполняться всегда. В идеале — за одинаковое время, зависящее только от размера входных данных (и то, не всегда — крипто обычно требует фиксированного времени no matter what).
Скажите, а если я напишу вот так:
if (fask_ok()) {
slow_second_guess();
}Это ваш tail latency не вызовет?
Если нет, то в чём разница?
Если да, то почему вы не предлагаете запретить условные операторы?
Если вы так напишите, проблему быстро поймают (if fast_ok() будет часто).
В целом, если у вас будет 20 вложенных if'ов в функции, то её завернут за цикломатическую сложность (или пропустят — но тут уж sky is the limit). А вот ленивые вычисления этот if прячут.
Во, правильный аргумент: ленивые вычисления прячут if от программиста, скрывая истинную цикломатическую сложность кода.
Странный какой-то аргумент.
Цикломатическая сложность — это метрика, которая отражает сложность восприятия программы программистом.
Если эту самую сложность от программиста "успешно скрыли" — это всего лишь означает, что она перестала отражать что бы то ни было.
Смотрите, есть два вида скрытия.
Вы можете прятать сложность реализации от потребителя. Это хорошо.
Вы можете прятать нетривиальность происходящего от читающего код. Это плохо.
Почему? Потому что потребителю не важно знать, как оно работает. Пищущему очень важно знать как оно работает и как оно не работает, чтобы делать его рабочим.
Когда у вас if good() && bad() в неявном виде, это прячет сложность от того, кому её надо видеть. Вместо того, чтобы увидеть, что bad() будет вызван только если good() не удался, человек видит, что условие выполняется.
Это нарушение дзена (питона) — "явное лучше неявного".
Всё программирование заключается в том, чтобы прятать сложность. Если это получилось — то говорят про крутую библиотеку и удобную абстракцию, а не ругают.
Окей, давайте я вам покажу офигенный пример абстракции, которая скрывает то, что не надо скрывать.
class mydict(dict):
def items():
yield {'a': 1} # etc
if not time.time() % 1337:
repeat = False
while repeat:
try:
with file('/etc/foobar.conf') as f:
yield from yaml.load(f).items()
repeat = False
except:
passИ вот вы юзаете mydict, и он выглядит как mydict, крякает как mydict, только раз в иногда делает какую-то фигню.
Скажите, что я скрыл от программиста тут? Гигантский толстый wtf, который чёрти как отладить, и который спрятал сайд-эффекты в чистом коде.
Это пример плохого дизайна, в котором скрыта сложность (допустим, этот файл реально надо читать в тот момент, когда число секунд кратно 1337)/
Да ничего вы тут не скрыли. Тем более, что в приличном языке у вас items() возвращает IO (Map String Int), и можно сразу подумать, что программист который эту функцию писал не очень хорошо перед этим подумал.
Функция fibonachi (а это именно функция) порождает бесконечный список чисел
Разница в том, что в рамках функционального подхода подобная организация программы естественна и навязывается самим способом ее выполнения, в то время как в рамках императивного она требует дополнительной творческой работы
Тезис: Функциональная программа — программа, состоящая из чистых функций
Здесь неопытнй читатель наверняка подумает, что функциональные языки «лучше», раз автор так уверенно говорит про «требует дополнительной творческой работы». Но на самом деле ФП тоже «требует дополнительной творческой работы» во всех случаях, когда нужно просто последовательно (в императивном стиле) изложить алгоритм.
Да нет, если вам нужно изложить императивный алгоритм — берете и прямым текстом его излагает. Например, вот мутабельный инплейс квиксорт на этом вашем хаскелле, прям как на си:
qsort :: (V.Vector v a, Ord a) => v a -> v a
qsort = V.modify go where
go xs | M.length xs < 2 = return ()
| otherwise = do
p <- M.read xs (M.length xs `div` 2)
j <- M.unstablePartition (< p) xs
let (l, pr) = M.splitAt j xs
k <- M.unstablePartition (== p) pr
go l; go $ M.drop k prМожно не включая мозг просто переписать алгоритм 1в1.
Никогда не интересовался алгоритмами на графах, но вот например несколько реализаций, включая мутабельную: https://github.com/hcrudolph/haskell-dijkstra
Ну, за экспертным мнением это скорее к 0xd34df00d и подобным товарищам, я пока в прод массово на хаскелле не писал, у нас только небольшой скала сервис.
Реализация на плюсах выглядит проще в плане нагруженности синтаксиса, но понятнее мне разбитая на куски хаскельная версия (особенно самая простая через фолд). Хотя, мне кажется, можно написать попроще.
По строчкам кода если посчитать то одинаково выходит: и там и там 60, не считая импорты и комментарии.
Что до асимптотики то по крайней мере для мутабельного варианта на IORef она совпадает с таковой у С++.
За IO на каждый чих — ещё как надают. А вот какой-нибудь ST или что-то более специализированное уже можно использовать.
Ну в том варианте что я на гитхабе нашел — понять что-то трудно, и тут плюсовый код однозанчно выигрывает в читаемости. Ну и странный он, местами возможно не особо оптимальный. Но если посмотреть по вашей ссылке реализацию как там сделали, то она куда лучше, и мне её читать чутка проще. Хотя примерно так же, как и сишная. Во многом потому, что там буквально runST и всё то же самое :)
Прочитал внимательнее хаскель вариант, они буквально пишут
Translation of: C++
Translation of the C++ solution, and all the complexities are the same as in the C++ solution. In particular, we again use a self-balancing binary search tree (Data.Set) to implement the priority queue, which results in an optimal complexity.
Это не эмуляция, а собственно эмбеддинг императивного кода в ФП язык. Для того ST и придумали.
Что до "проще не стало", лично я разницы в сложности между двумя версиями не ощущаю, это буквально один и тот же код, только записанный в ML-синтаксисе и сишном. Оба языка я знаю примерно на одном уровне (семестр лаб по плюсам в универе и полгода ковыряния пет проекта на хаскелле), поэтому можно наверное эту информацию считать сравнительно заслуживающей доверия.
Почему на понимание такого алгоритма должно уйти больше чем в плюсах, где написан ровно этот же алгоритм — для меня загадка.
Ну синтаксис дело наживное, как говорил один мой товарищ по хабру, "я не знаю албанский, что-либо понять в нем решительно невозможно" (с)
Если просто сесть и 1 раз разобраться в синтаксисе, то польза будет на всю жизнь. А то что ни пейпер интересный в меня кидают, про новинки в области теории типов или там просто крутой паттерн какой-нибудь придумали (вроде таглес файнала того же) — то везде код на хаскелле. Полезно понимать.
Дело не столько в синтаксисе, сколько в количестве мыслетоплива, которое нужно потратить для решения данной задачи.
Да сколько мыслетоплива? Тут буквально 1в1 написано то же самое, плюсовику с опытом дай, скажи "вместо присваивания пиши <-, в конце не забудь написать freeze. В начале напиши магическую фразу runST". Ну чутка вербознее чем плюсы, но это ведь понятно, потому что мутабельность в языке немного сбоку прикручена. Тем более что такое делать надо нечасто — многие вещи и в чистом коде отлично выражаются без оверхеда (как 0xd34df00d показывает в своих статьях), а это фоллбек для случая, когда чистого подходящего алгоритма не нашлось + нам не пофиг на перфоманс в этом месте.
Вербозно? Да, ощутимо больше писать чем в коде на плюсах. Стоит ли того? Чтобы писать только такой алгоритм — конечно нет, лучше взять более подходящий язык. Но если у вас 99% остальной программы написано в "нормальном" стиле, то ради них написать с некоторым количеством церемоний и плясок вокруг мутабельности — наверное нормально.
А в фп же нету паттернов :)
Ну как нет — конечно есть)
https://youtu.be/kR4mCDIHrac
Тем более что такое делать надо нечасто — многие вещи и в чистом коде отлично выражаются без оверхеда
Для этого надо свободно владеть соответствующими примитивами и конструкциями. Когда не владеешь — это как пытаться говорить на языке, который плохо знаешь. Тратится мыслетопливо :)
Ну что поделать, чтобы учиться — надо думать. Зато когда выучился — можно пользоваться тем, что знаешь. И мне кажется, что потратить на какие-нибудь монадки или стандартные комбинаторы траверсаблов/фолдаблов пару дней стоит того, чтобы потом 20+ лет карьерной жизни пользоваться тем, что это знание даёт. Почему-то не все с этим согласны, ну да ладно.
Всё-таки это константа, хоть и имеющая значение, порождаемое функцией.
Здесь неопытнй читатель наверняка подумает...
И здесь важно сказать явно — императивный и функциональный — это лишь стили
Все-таки нет, это функция
Есть алгоритмы, которые естественным образом появляются в рамках одной либо другой концепции.
Тем, что это не присвоение, а определение функции.
Присвоения в ленивых языках как такового нет, поскольку это чистой воды побочный эффект.
И в этой строчке она не вызывается.
Или вы считаете, что функции вообще не вызываются
В ведь понимаете разницу между константой и функцией без аргументов?
С функциональной точки зрения программа — не последовательность вызовов функций, а одна большая функция, которую нужно не «вычислить» в привычном нам понимании, а «упростить» с учетом того, какие значения получили ее переменные.
Вы предлагаете смотреть на код как на пример лямбда-исчисления
абстракция «частичного вычисления» внутри компилятора применима редко из-за сложности такого вычисления
а потому можно ошибиться, если начинать продумывать, до какого момента что-то там частично вычислено
Под константой я понимаю выражение, определение значения которого не требует вычислений. В данном случае определение значения fibonachi вычислений требует и потому константой не является.
Я как раз и оперирую только абстрактными понятиями.
Так в том и прикол, что если интересует только конечный результат, то вам этот порядок до фонаря.
мне кажется, все таки употреблять термин «константа» (лат. constans, родительный падеж constantis — постоянный, неизменный) в таком смысле не правильно. В таком случае main в хаскелле тоже константа. То есть любая программа — константа.
Но ведь и ваше «императивное» понимание в определенной мере иллюзорно
При программировании в императивном стиле тоже сколько угодно случаев, когда понимание того, как сделать правильно/эффективно подводит.
Что насчёт SQL? Там оптимизатор додумывает куда больше, чем любой ФП компилятор, тем не менее более удобного способа работать с массивами данных популярных я не знаю. Даже NoSQL базы предоставляют все те же, только в жс обертке.
Абстракции бывают разные. Абстракция SQL, как минимум для меня, очень понятна и я хорошо понимаю, как она ложится на императивно выражаемые алгоритмы. А вот абстракции из хаскеля я не все до такой степени понимаю. Возможно, это следствие отсутствия длительного периода использования хаскеля, ведь я с ним познакомился, поигрался, да и забыл о нём.
Каким образом она понятно ложиться на императивщину? У нас написано SELECT * FROM A JOIN B ON A.Id = B.EntityId, а там то ли цикл, то ли хэшмапа создалась, то ли сортировка началась. А может и еще что-то, при чем один и тот же код может по-разному работать даже на одной и той же версии БД, просто на основании статистики, не говоря о том, что можно накатить минорный патч и запрос совсем по-другому будет работать. Если это "хорошо ложиться на императивщину" — то хаскель с его монадами и подавно.
Но тем не менее, вспоминая те времена, когда я впервые знакомился с SQL, я отлично помню, что базовые абстракции там дались мне сразу и легко, а вот ту же абстракцию монад мне пришлось штурмовать гораздо дольше.
Не знаю, что там штурмовать: сказали в курсе, что есть функция a -> m b, и если у тебя есть f a то можешь получить f b. Показали пример со списком, опциональным значением и футурой, всё стало понятно. После пары лет работы в сишарпе с LINQ у меня возникло ровно 0 сложностей с этим. Как и у среднестатистического джава-разработчика, который работал со стримами, и пользовался flatMap и thenCompose.
В общем, в последней статье я и писал про это. Как раз потому, что каждый раз люди говорят что "сложно", но что именно "сложно" не говорят, просто обводят руками всё и говорят "ну вот!". Правда, все мои знакомые, которые не поверили устовяшемуся мнению и попробовали хотя бы начать курс на степике ни с какими проблемами не столкнулись.
Ну и если посмотреть на других, то по ним видно, что оптимизацию запросов SQL осиливают далеко не все, что означает и в данном случае наличие заметной сложности.
оптимизацию осваивают все, кто изучал этот вопрос. У большинства людей просто БД и так пережевывает безо всяких оптимизаций, поэтому им просто это не нужно. Когда нужно — быстренько выучивают все, что надо. Ну или увольняются, что бывает реже.
Правда моя статистика, понятно, субъективна. Но можно спросить на любом форуме по базам данных — кто из вас вообще знает про хаскель? А кто понимает вот этот код… и привести что-то с монадами. Ответ, мне кажется, будет соответствовать моей статистике.
И что это докажет? Что люди не знающие хаскелля не могу читать хаскель? А можно показать людям не знающих плюсов — код на плюсах. А не знающим эрланга — на эрланге. Не знающим J — на J…
У нас написано SELECT * FROM A JOIN B ON A.Id = B.EntityId, а там то ли цикл, то ли хэшмапа создалась, то ли сортировка началась.
Не знаю, что там штурмовать: сказали в курсе, что есть функция a -> m b, и если у тебя есть f a то можешь получить f b. Показали пример со списком, опциональным значением и футурой, всё стало понятно.
Когда нужно — быстренько выучивают все, что надо
И что это докажет?
Цикл или сортировка — внутренние сложности алгоритма нахождения соответствия записей из А и В. Абстрактный же алгоритм очень прост. Но если мне надо, то я легко найду внутренние детали реализации. Вот в этом простота.
Если это считать деталями алгоритма, то любой фпшный fmap это тоже "детали алгоритма", которые можно так же посмотреть.
Тогда непонятна граница, как отличать одно от другого. А то википедия почему-то считает что SQL это декларативный язык, а не императивный (это взаимо исключающие категории, если что).
У меня был очень простой вопрос — а зачем так? Вы же целую статью на эту тему написали, объясняя зачем. И там много комментариев со спорами.
Ну, иногда нужно. Зачем банда четырёх целую книжку с паттернами написали? И в обсуждении этой книжки споры про то, Как разные паттерны с SOLID/KISS и законом Деметры дружат.
В случае с БД — да, там всё просто. А в случае с хаскелем — я бы так не сказал.
Не вижу принципиальной разницы. Смотреть план запроса или в вывод гхц. Знать про все 547 видов индексов, разные режимы блокировок, сплиты страниц и всё остальное или знать про 547 монад, режимы жадного и ленивого выполнения, и всё остальное.
Докажет разницу в сложности. Большинство знающих хаскель легко разберутся с SQL, но большинству знающих SQL придётся нелегко, когда нужно будет разбираться с хаскелем.
Это не так.
Если это считать деталями алгоритма, то любой фпшный fmap это тоже «детали алгоритма», которые можно так же посмотреть.
Не вижу принципиальной разницы. Смотреть план запроса или в вывод гхц.
А где вы смотрите детали? По БД есть очень хорошая документация, а вот по хаскелю — надо всё искать (если что-то сложнее основ). Вплоть до изучения кода компилятора.
А где вы смотрите детали? По хаскеллю есть очень хорошая документация, а вот по БД — надо всё искать (если что-то сложнее основ). Вплоть до изучения кода компилятора.
Как работает ленивость? Автор статьи упомянул ленивое вычисление списка чисел Фибоначчи — как этот список получается (императивно)? Где искать?
Например на официальной вики? Про то как работает непосредственно вычисление можно почитать по ссылке WFNF.
Но в обычной программе (императивной) вообще нет необходимости смотреть какие-то планы/выводы. Точнее в большинстве случаев достаточно просто подумать.
В императивной программе точно так же надо смотреть на ассемблерные листинги и что там получилось. Мы ведь про оптимизацию говорим, да? Потому что если нет, то никуда смотреть не надо — пиши себе, а оно будет работать.
А где вы смотрите детали?
Например на официальной вики? Про то как работает непосредственно вычисление можно почитать по ссылке WFNF.
В императивной программе точно так же надо смотреть на ассемблерные листинги и что там получилось.
Я его вынес вне цикла, и код ускорился условно с 260 мс до 255 мс.
Пришлось консультироваться с DBA.
А вы целиком понимаете, как ваш код на вашем любимом императивном языке программирования исполняется на процессоре?
Так в том и прикол, что если интересует только конечный результат, то вам этот порядок до фонаря. Получение результата вам гарантирует формальная корректность программы.
Если бы это действительно было так, то в Base не было бы отдельно foldl и foldl'.
В ведь понимаете разницу между константой и функцией без аргументов?
Я вот лично не понимаю. Расскажите, пожалуйста, а то у нас пару недель назад было обсуждение в чате, мы не нашли никаких отличий. Для аналогии: википедия по хаскеллю говорит что Well-formed types (то есть инты там и стринги) можно рассматривать как нульарные тайп конструкторы.
Разница всё-таки есть, хоть и ненаблюдаема средствами языка. Производительность, как всегда, портит красивые модели :-)
К примеру, вот в этой программе
fibs = 0 : 1 : zipWith (+) fibs (tail fibs)константный список будет вычисляться за O(1) на каждом шаге, а вот "функция 0 аргументов" экспоненциально взорвется (если только оптимизатор не догадается заменить её на константу).
Не взорвётся при call by need стратегии.
А что помешает?
В смысле что? При call by need fibs вычислится только раз. Объявление переменной это же связывание, а связанный терм при call by need вычисляется лишь однажды.
Только если это константа, а не "функция 0 аргументов".
Только если это константа, а не "функция 0 аргументов".
С чего вдруг?
Вообще, довольно бессмысленный спор, потому что:
В ведь понимаете разницу между константой и функцией без аргументов?
В ленивых языках её нет. Но только тссс, я этого не говорил, можете спорить дальше
Если бы мы имели дело с действительно функциональной программой, то при вызове partial произошло бы вычисление всего того, для чего нужно значение первого аргумента.
Это неверно.
А обоснование прилагается?
Охренеть! Оно еще имеет наглость обоснования требовать!
Окей, так уж и быть, дам подсказку, вот есть функции g y = g y, f x y = g x, тогда если я выполню f x, ака вызову partial, то что там при вызове произойдет, вычисление чего, а? Небось g x аж до константы свернется?
Если Вам не понятно, я при изложении вполне сознательно упрощал и утрировал, чтобы не засорять внимание деталями, не имеющими прямого отношения к сути рассматриваемого вопроса.
Речь не об утрировании и упрощении, а о том, что вы написали полную чушь. Не какую-то неточность, а просто бред, не имеющий никакого отношения к действительности. Непонятно откуда вообще вы вытащили это утверждение, его же еще придумать надо было!
Делаете замечание — потрудитесь написать по существу в чем автор ошибается и как это влияет на полученные выводы.
Ну так вы попытайтесь ответить на вопрос:
"вот есть функции g y = g y, f x y = g x, тогда если я выполню f x, ака вызову partial, то что там при вызове произойдет, вычисление чего, а?"
и поймете
и как это влияет на полученные выводы.
На выводы это влияет очень просто — у нас есть человек, который зачем-то написал статью, чуть менее чем полностью посвященную ленивой стратегии вычислений, даже на базовом уровне не понимая при этом, как эта стратегия вычислений работает.
Ну если вы дуб дубом в теме, зачем вы по этой теме пишете статью?
Ох лол, да у тебя в голове ещё большая каша чем я думал!
Офкос эти ребята хорошо разбираются в вопросе! Достаточно хорошо, чтобы, в отличии от одного безграмотного скомороха, понимать разницу между частичным применением и частичным вычислением.
А у самого скомороха остаётся на выбор два варианта:
Вы успешно продемонстрировали, что я имею дело с обычным трамвайным хамом со жгучим желанием поумничать и не способным ни на диалог, ни на аргументацию, отличную от "это неправильно, потому что автор ничего не понимает". Если бы вы владели вопросом, то были бы в курсе, что частичные вычисления прямо связаны с нормализацией и вполне могут служить механизмом реализации частичного применения.
Свою задачу рассмотрите сами, если считаете ее чем-то стоящим. Я так не считаю. И вести предметную дискуссию с вами я смогу только если вы пройдете хотя бы ускоренные курсы культуры поведения. А я уж, так и быть, потешу публику.
А если сказать так — "при вызове partial может быть вычислено всё то, для чего достаточно только первого аргумента"? (Но может быть и не вычислено, если компилятор/оптимизатор не сможет доказать это "достаточно")
Основным отличием является использование иной модели вычислений. Все остальное — не более чем следствия.:-) Формулировка, как говориться, «истинного математика»… А *иной*, я извиняюсь, это какой? Если речь исключительно о «ленивости вычислений» (а такой вывод вполне можно сделать из статьи), то к ФП оно имеет весьма опосредованное отношение. Можно подумать, что функциональных языков с «энергичной» моделью вычислений у нас нет. Или, что — как я понимаю — ещё «страшнее», невозможен императивный ЯП с «ленивой» моделью вычислений. :-)
«чистота» — следствие как раз декларативности
В данном случае да, иной — это «ленивой», поскольку из ленивости вытекают многие из тех свойств, которые присущи функциональным языкам и воспринимаются как своеобразные маркеры «функциональности».Вообще-то говоря, с точностью до наоборот. В том смысле, что «многие из тех свойств, которые присущи функциональным языкам и воспринимаются как своеобразные маркеры» замечательно укладываются в «ленивость вычислений»… и с этим-то никто не спорит. Важно то, что все эти «свойства» и «маркеры» ей — т.е. «ленивостью» вычислений — отнюдь не определяются. Вы, грубо говоря, на полном серьезе утверждаете ФЯП => «ленивые вычисления». Что, мягко говоря, не так.
Ленивые вычисления имеют к ФП непосредственное отношение. Если вам известен императивный язык, целиком и полностью основанный на концепции ленивых вычислений — буду рад, если Вы расширите мой кругозор.
… но Пролог «чистоты» не предполагает.Да ладно?! «Чистоты» он «не предполагает» только в, скажем так, «процедурной» своей части. А она, как раз не декларативна.
Вы, грубо говоря, на полном серьезе утверждаете ФЯП => «ленивые вычисления»
«Чистоты» он «не предполагает» только в, скажем так, «процедурной» своей части
Но давайте таки «про чистоту»
В том смысле, что «ленивость» не означает *произвольности*
Но все это следствия как раз императивности/декларативности, а не «ленивости» самой по себе.
И в первую очередь, это модель с *произвольным* порядком вычислений.
Но утверждение «декларативность» => «чистота» все еще требует доказательства. Что предполагает наличия определения термина «декларативность». Мы пока с ФП толком не разобрались.?! Хорошо вам… я-то вообще не могу себе представить, как можно начать разбираться с ФП, не разобравшись *сначала* с декларативностью :-) И определение «декларативности» с т.з. вычислений я уже давал. Если вы с ним не согласны — ваше право… дайте другое :-)
Выражение «произвольный порядок вычислений» как минимум предполагает указание модели вычислений. Что я и сделал. И вывел чистоту как следствие этого самого произвольного порядка. В другой модели вычислений это утверждение снова потребует обоснования.При всем моем уважении, я вот этого в статье не увидел вообще… хотя специально сейчас перечитал её ещё раз. Вы можете указать конкретно, где вы вывели «чистоту как следствие этого самого произвольного порядка»?
Зависит от определения. Если использовать правило «call-by-need» — то это уже в достаточной мере определяет порядок вычислений. Я использовал термин в более широком смысле: ленивый порядок — любой, не предполагающий вычисление значения всех аргументов функции до вычисления самой функции.Угу… «от определения» :-) С чего вы вообще решили, что «не предполагающий вычисление значения всех аргументов функции» — это только к модели Черча относится?! Какие-нибудь short-circuit, call-by-name и т.п. evaluation они в модели Тьюринга нормально себе живут. И тоже «не предполагают» ничего такого. Да даже call-by-need, он не про *порядок*, а про «чистоту». Т.е. императивность тут нисколько не мешает. А вот отсутствие ссылочной прозрачности — очень даже. Т.е. — при условии соблюдения ссылочной прозрачности — call-by-need стратегия возможна и в модели Тьюринга. Вот только декларативной эта модель от этого не становится :-)
Полностью произвольного порядка вычислений быть не может, вы так алгоритм, используемый для вычисления определить не сможете.Смотрите… отличие модели Черча от модели Тьюринга онож не в том, что тут у нас "β-редукция", а там её нет. Её отличие как раз в том, что от порядка выбора редексов результат *не зависит*. Таки да — это тот самый «произвольный порядок вычислений». Которого нет в модели Тьюринга. Внезапно выясняется, что алгоритм в модели Черча описывает все что угодно, но не *порядок* вычислений. Он — что называется — декларативный.
Ленивость и энергичность — часть модели вычислений. В некоторых случаях определяющая, в некоторых нет. О ее первичности, вторичности или n-ричности в общем случае, думаю, утверждать не стоит.«Ленивость и энергичность» — это то, что — «по канону» — называется стратегия (в смысле, конкретный способ) вычислений. И применена эта стратегия может быть к любой модели… хоть к Тьюрингу, хоть к Черчу. То, что некоторые из конкретных стратегий для работы требуют некоторого, скажем так, «окружения» — ничего не меняет. И то, что выгода (те самые «плюшки») от применения этих стратегий в разных моделях разная — это, в рамках дискуссии, действительно «дело десятое», имхо. Принципиальна — сама возможность применения.
я вот этого в статье не увидел вообще
А я — ещё раз — попытаюсь объяснить что увидел я
отличие модели Черча от модели Тьюринга онож не в том..
Принципиальна — сама возможность применения
Функциональные языки декларативны. Логические языки декларативны. Языки запросов декларативны. Языки продукционных экспертных систем декларативны. Что это меняет? Отличий между ними больше, чем сходств.И? Всё их различие объясняется разными моделями. Согласитесь, что λ-исчисление и, какое-нибудь, исчисление предикатов — это таки «немножко разные» вещи. Хотя и то и другое — декларативно.
В ФП «чистота» приводит к появлению монад, в ЛП — к предикатом для работы с базой утверждений.Да не приводит «чистота» к монадам. С чего вы вообще так думаете?! Монады — с т.з. вычислений — это вообще, если хотите, эдакое средство «линеаризации» этих самых вычислений. В смысле, способ их упорядочить. Причем, один из. И все… Если что к ним и «приводит», то это как раз «ленивость» вычислений… по той простой причине, что создает предпосылки к необходимости (порой) упорядочивать эту самую «ленивость».
Сама по себе «чистота» не приводит ни к каким значимым следствиям.Само собой. Но «чистота» таки это необходимое условие для них.
А применение редукции в качестве механизма построения вычислительного процесса — приводит, ...К каким, например? Я вот знаю один ФП, в котором не то, что «вычислительный процесс», в нем его квантование на редукциях основано. Но, в нем нет ни «ленивости», ни — тем более — модан и т.п. :-)
Вы пытаетесь исходить из того, что «ленивость» в том определении, которое применяется в практике программирования и действительно может быть отнесена и к функциональным, и к императивным языкам, «чистота», «функции высших порядков» и прочее — основы.?! Это вы точно про меня? Я-то — как мне казалось — вам талдычу, что, как минимум, «чистота» — это не какие-то там «основы», а следствие декларативности. И моя, скажем так, претензия — она в том, что вы часть свойств приписываете ФП, выведя их *напрямую* из модели Черча. А они — *напрямую* — из неё не выводятся. Если хотите, из того, что вы перечислили в статье, *напрямую* выводится только «все есть ф-ция» aka «функции высшего порядка». Остальное, это не свойства, модели Черча как таковой… это либо, как например «ленивость» — просто опция, которая непосредственно к ФП вообще никакого отношения не имеет, либо, как например «чистота» — следствие декларативности модели. И, лично с моей т.з., все это важно понимать. Я уже говорил, что мне сложно представить, как можно «разбираться с ФП», сначала не разобравшись с декларативностью.
И именно эти первопричинные основы достойны того, чтобы их изучать в рамках курсов функционального программирования.Я тут уже запутался в ваших тезисах. Но если вы к «первопричинным основам» относите «ленивость», то, лично для меня, это, мягко говоря, странно. Мне сложно представить, что вы на полном серьезе считаете, что, тот же Haskell функциональный, потому что он «ленивый» и там есть «монады» :-)
Её отличие как раз в том, что от порядка выбора редексов результат не зависит.
Ну, вообще-то зависит — в нетипизированной лямбде есть термы, которые нормализуются в нормальном порядке, но виснут в энергичном.
Да. Но просто более точно здесь сказать не то, что от порядка результат не зависит, а то, что мы можем вставить любое конечное число редукций в любом порядке и потом в нормальном порядке довести терм до нормальной формы (если он доводится). Т. Е здесь важны скорее особые свойства нормального порядка.
Как пример можно кстати на скалу посмотреть. Она и императивная, и функциональная, и ленивая, и неленивая. Например:
Строгий императивный:
def print_name(name: String, shouldPrintName: Bool) {
if (shouldPrintName) {
println("Your name is: " + name)
}
} Ленивый императивный:
def print_name(name: => String, shouldPrintName: => Bool) {
if (shouldPrintName) {
println("Your name is: " + name)
}
} Строгий функциональный:
def print_name(name: String, shouldPrintName: Bool) : IO[Unit] {
if (shouldPrintName) {
cats.effect.IO.println("Your name is: " + name)
} else {
IO.pure(())
}
} Ленивый функциональный:
def print_name(name: => String, shouldPrintName: => Bool) : IO[Unit] {
if (shouldPrintName) {
cats.effect.IO.println("Your name is: " + name)
} else {
IO.pure(())
}
} Здесь особенно рьяный императивно настроенный читатель
Функциональное программирование — то, что вам (наверно) рассказывали. Если вы слушали