
Аналитическая СУБД ClickHouse обрабатывает множество разных строк, потребляя ресурсы. Для ускорения работы системы постоянно добавляются новые оптимизации. Разработчик ClickHouse Николай Кочетов рассказывает о строковом типе данных, в том числе о новом типе, LowCardinality, и объясняет, как можно ускорить работу со строками.
— Сначала давайте разберемся, как можно хранить строки.

У нас есть строковые типы данных. String хорошо подходит по умолчанию, его стоит использовать почти всегда. У него небольшой Overhead — 9 байт на одну строку. Если мы хотим, чтобы размер строк был фиксирован и известен заранее, то лучше использовать FixedString. В нем можно задать нужное нам число байт, он удобен для данных типа IP-адресов или хеш-функций.

Конечно, иногда что-нибудь тормозит. Допустим, вы делаете запрос к таблице. ClickHouse читает довольно большое количество данных, скажем, со скоростью 100 ГБ/с, при этом строк обрабатывается мало. У нас есть две таблицы, которые хранят почти что одинаковые данные. Из второй таблицы ClickHouse читает данные с большей скоростью, но строк в секунду читается в три раза меньше.

Если мы посмотрим на размер сжатых данных, то он окажется почти равный. На самом деле в таблицах записаны одни и те же данные — первый миллиард чисел — только в первом столбце они записаны в виде UInt64, а во втором — в String. Из-за этого второй запрос дольше читает данные с диска и разжимает их.

Вот другой пример. Предположим, что есть заранее известное множество строк, оно ограничено константой 1000 или 10 000 и практически никогда не меняется. Для этого случая нам подходит тип данных Enum, в ClickHouse их два — Enum8 и Enum16. За счет хранения в Enum мы быстро обрабатываем запросы.
В ClickHouse есть ускорения для GROUP BY, IN, DISTINCT и оптимизации для некоторых функций, например для сравнения с константной строкой. Конечно же, числа в строке не преобразуются, а, наоборот, константная строка приводится к значению Enum. После этого все быстро сравнивается.
Но есть и минусы. Даже если мы знаем точное множество строк, иногда оно должно пополняться. Прилетела новая строка — мы должны сделать ALTER.

ALTER для Enum в ClickHouse реализован оптимально. Мы не переписываем данные на диске, но ALTER могут подтормаживать из-за того, что структуры Enum хранятся в схеме самой таблицы. Поэтому мы должны подождать запросов на чтение из таблицы, например.
Возникает вопрос, можно ли сделать лучше? Наверное, да. Можно сохранить структуру Enum не в схеме таблицы, а в ZooKeeper. Однако могут возникнуть проблемы, связанные с синхронизацией. Например, одна реплика получила данные, другая — нет, и если у нее старый Enum, то что-нибудь сломается. (В ClickHouse мы почти доделали неблокирующие ALTER-запросы. Когда доделаем их полностью, не нужно будет ждать запросы на чтение.)

Чтобы не возиться с ALTER Enum, можно использовать внешние словари ClickHouse. Напомню, что это key-value структура данных внутри ClickHouse, с помощью которой можно получать данные с внешних источников, например с таблиц MySQL.
В словаре ClickHouse мы храним множество различных строк, а в таблице — их идентификаторы в виде чисел. Если нужно получить строку, мы вызываем функцию dictGet и работаем с ней. После этого мы не должны делать ALTER. Чтобы что-то добавить в Enum, мы вставляем это в ту же самую таблицу MySQL.
Но тут возникают другие проблемы. Во-первых, неудобный синтаксис. Если мы хотим получить строку, мы должны вызвать dictGet. Во-вторых, отсутствие некоторых оптимизаций. Сравнение с константной строкой для словарей так же быстро не сделать.
Еще могут быть проблемы с обновлением. Предположим, мы запросили строку в кэш-словаре, а в кэш она не попала. Тогда мы должны ждать, пока загрузятся данные из внешнего источника.

Общий недостаток обоих методов — мы храним все ключи в одном месте и их синхронизируем. Так почему бы не хранить словари локально? Нет синхронизации — нет проблем. Можно хранить словарь локально в куске на диске. То есть мы сделали Insert, записали словарь. Если мы работаем с данными в памяти, то можем записать словарь или в блок данных, или в кусочек колонки, или в какой-нибудь кэш, чтобы ускорить вычисления.
Так мы пришли к созданию нового типа данных в ClickHouse — LowCardinality. Это формат хранения данных: как они пишутся на диск и как читаются, как они представлены в памяти и схема их обработки.

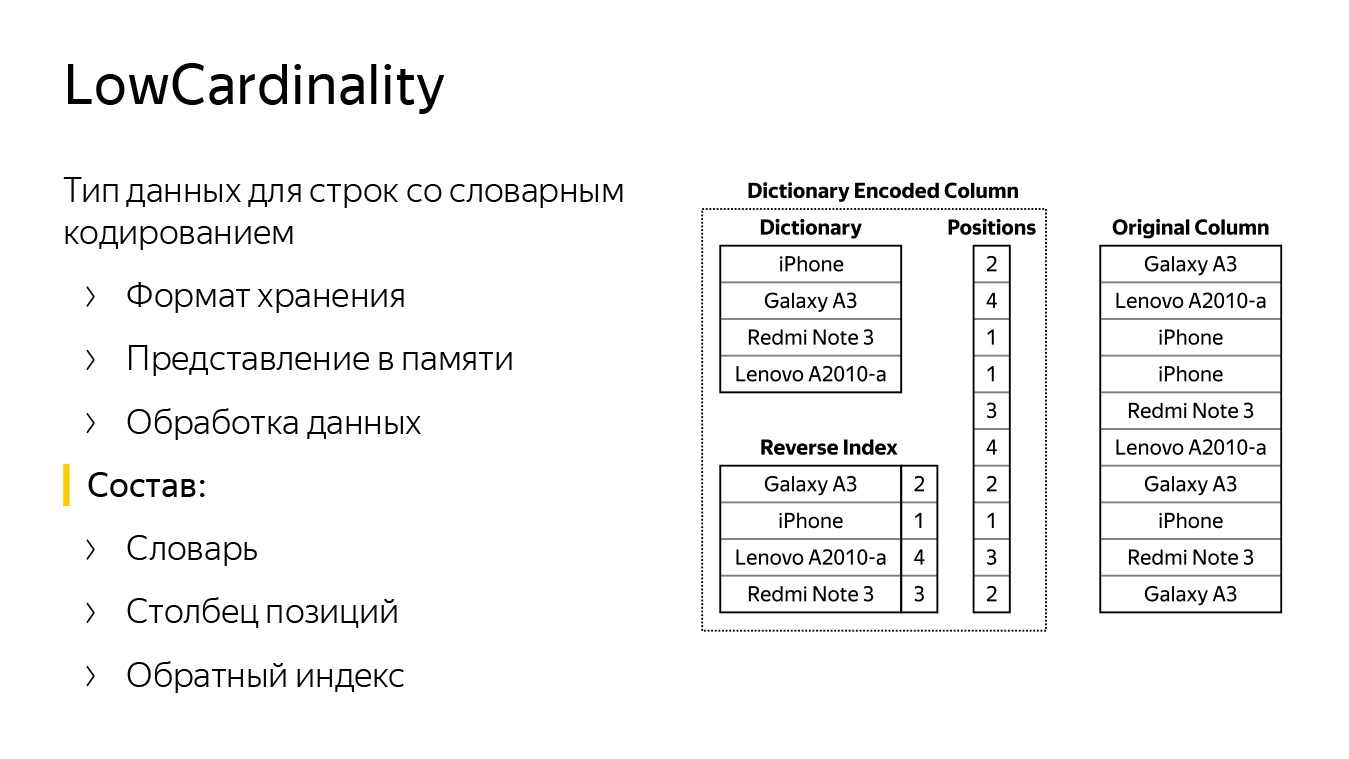
На слайде есть две колонки. Справа строки хранятся стандартно, в типе String. Видно, что это какие-то модели мобильных телефонов. Слева есть точно такая же колонка, только в типе LowCardinality. Она состоит из словаря с множеством разных строк (строки из колонки справа) и списка позиций (номеров строк).
С помощью этих двух структур можно восстановить исходную колонку. Также есть обратный обратный индекс — хеш-таблица, которая помогает по строке найти позицию в словаре. Она нужна для ускорения некоторых запросов. Например, если мы хотим сравнить, поискать строку в нашей колонке или слить их между собой.
LowCardinality — параметрический тип данных. Он может быть либо числом, либо чем-то, что хранится в виде числа, либо строкой, либо Nullable от них.

Особенность LowCardinality в том, что он может сохраняться для некоторых функций. На слайде видно пример запроса. В первой строчке я создал колонку типа LowCardinality от String, назвал ее S. Далее я спросил ее имя — ClickHouse сказал, что это LowCardinality от String. Все верно.
Третья строчка почти такая же, только мы вызвали функцию length. В ClickHouse функция length возвращает тип данных UInt64. Но у нас стало LowCardinality от UInt64. В чем смысл?

В словаре хранились названия мобильных телефонов, мы применили функцию length. Теперь у нас стал аналогичный словарь, состоящий только из чисел, — это длины строк. Столбец с позициями не поменялся. В итоге мы обработали меньше данных, сэкономили на времени запроса.
Могут быть и другие оптимизации, например добавление простого кэша. При вычислении значения функции можно запомнить его и составить такой же, не вычислять заново.
Также может быть сделана оптимизация GROUP BY, потому что наша колонка со словарем уже частично агрегирована — можно быстрее вычислять значение хеш-функций и примерно находить bucket, куда поместить очередную строку. Еще можно специализировать некоторые агрегатные функции, например uniq, ведь в нее можно отправить только словарь, а позиции оставить нетронутыми — так все будет работать быстрее. Первые две оптимизации мы уже добавили в ClickHouse.

А что, если мы создадим колонку с нашим типом данных и вставим в нее много плохих разных строк? Не переполнится ли наша память? Нет, для этого в ClickHouse есть две специальные настройки. Первая — low_cardinality_max_dictionary_size. Это максимальный размер словаря, который может быть записан на диск. Вставка происходит следующим образом: когда мы вставляем данные, к нам идет поток строк, из них мы формируем большой общий словарик. Если словарик становится больше, чем значение настройки, мы записываем текущий словарь на диск, а остальные строки — где-нибудь «сбоку», рядом с индексами. В итоге мы никогда не пересчитаем большой словарь и не получим проблем с памятью.
Вторая настройка называется low_cardinality_use_single_dictionary_for_part. Представьте, что в прошлой схеме, когда мы вставляли данные, наш словарь переполнился, и мы записали его на диск. Возникает вопрос, а почему бы теперь не формировать еще один точно такой же словарь?
Когда он переполнится, мы снова запишем его на диск и начнем формировать третий. Эта настройка как раз отключает такую возможность по умолчанию.
На самом деле много словарей могут быть полезны, если мы хотим вставить какое-то множество строк, но случайно вставили «мусор». Скажем, сначала мы вставили плохие строки, а потом вставили хорошие. Тогда словарь разделится на много маленьких словарей. Часть из них будут с «мусором», но последние будут с хорошими строками. И если мы прочитаем, скажем, только последнюю гранулу, то все тоже будет работать быстро.

Прежде чем говорить о преимуществах LowCardinality, сразу скажу, что мы вряд ли добьемся уменьшения данных на диске (хотя это может произойти), потому что ClickHouse сжимает данные. Есть вариант по умолчанию — LZ4. Также можно сделать сжатие с помощью ZSTD. Но оба алгоритма уже реализуют словарное сжатие, поэтому наш внешний словарь ClickHouse не очень поможет.
Чтобы не быть голословным, я взял некоторые данные из метрики — String, LowCardinality(String) и Enum — и сохранил их в разные типы данных. Получилось три столбца, где записан один миллиард строк. В первом столбце, CodePage, всего 62 значения. И видно, что в LowCardinality(String) нам сжали их лучше. String чуть похуже, но это, скорее всего, из-за того, что строки короткие, мы храним их длины, а они занимают много места, плохо сжимаются.
Если взять PhoneModel, их 48 тысяч — уже больше, и различия между String и LowCardinality(String) почти что нет. Для URL мы тоже сэкономили всего лишь 2 ГБ — думаю, не стоит на это полагаться.

Ссылка со слайда
Теперь оценим скорость работы. Чтобы ее оценить, я использовал датасет с описанием поездок такси в Нью-Йорке. Он доступен на GitHub. В нем чуть более чем миллиард поездок. Там отражены локация, время старта и окончания поездки, способ оплаты, число пассажиров и даже вид такси — зеленый, желтый и Uber.

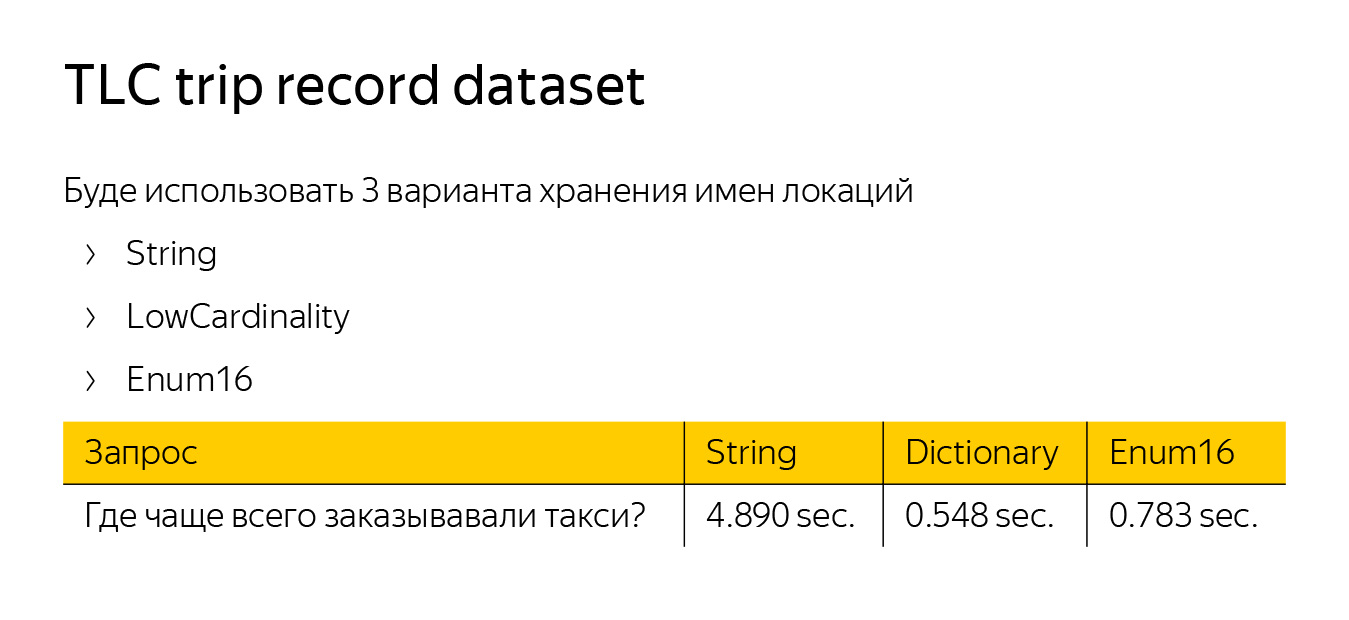
Первый запрос я сделал довольно простым — спросил, где чаще всего заказывают такси. Для этого нужно взять локацию, откуда заказывали, сделать по ней GROUP BY и посчитать функцию count. Вот ClickHouse что-то выдает.

Чтобы измерить скорость обработки запроса, я создал три таблицы с одинаковыми данными, но использовал для нашей стартовой локации три разных типа данных — String, LowCardinality и Enum. LowCardinality и Enum оказались в пять раз быстрее String. Enum быстрее потому, что работает с числами. LowCardinality — потому, что реализована оптимизация GROUP BY.

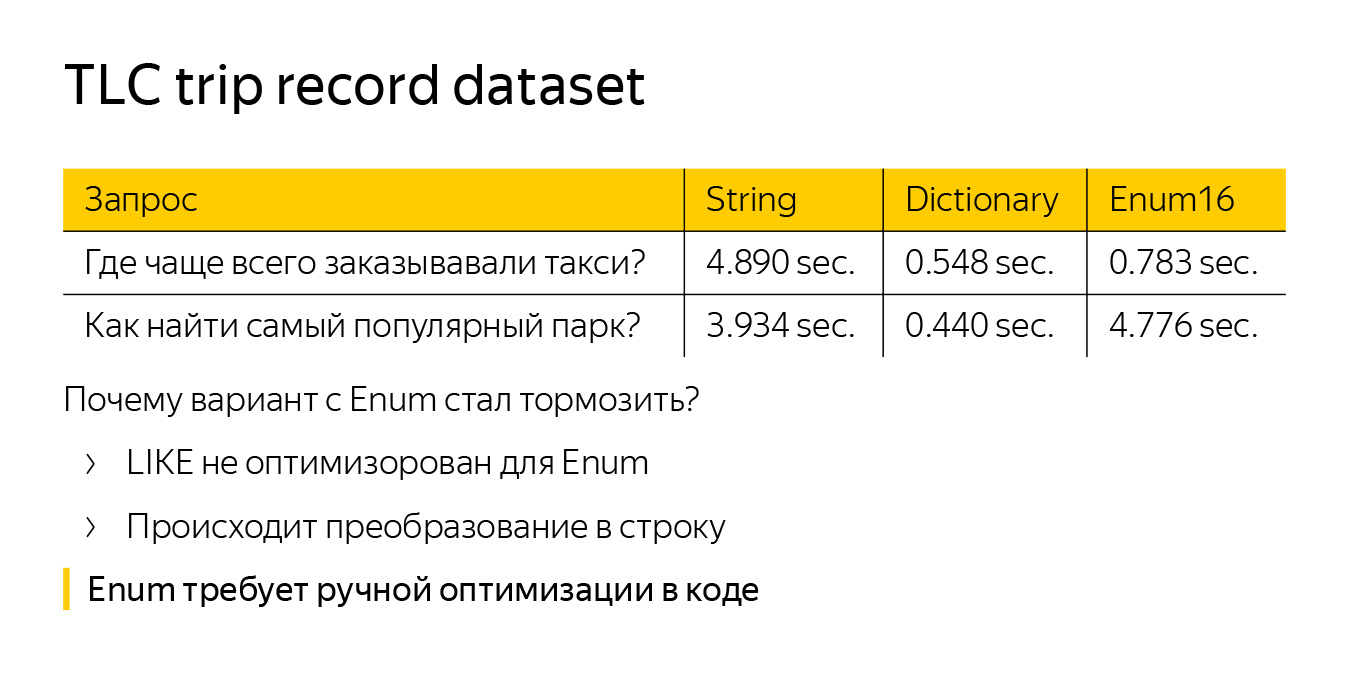
Давайте еще усложним запрос — спросим, где находится самый популярный парк в Нью-Йорке. Опять же мы будем это измерять по тому, где чаще всего заказывают такси, но при этом пофильтруем только те локации, где есть слово «парк». Также добавим функцию like.

Смотрим на время — видим, что Enum внезапно начал тормозить. Причем работает он еще медленнее, чем стандартный тип данных String. Это происходит потому, что функция like совсем не оптимизирована для Enum. Нам приходится преобразовывать наши строки из Enum в обычные строки — мы делаем больше работы. LowCardinality(String) тоже не оптимизирован по умолчанию, но там like работает над словарем, поэтому запрос ускоряется по сравнению со String.
При работе с Enum есть более глобальная проблема. Если мы хотим его оптимизировать, мы должны сделать это в каждом месте кода. Предположим, мы написали новую функцию — нужно обязательно придумать оптимизацию для Enum. А в LowCardinality все оптимизировано по умолчанию.

Посмотрим на последний запрос, более искусственный. Мы просто посчитаем хеш-функцию от нашей локации. Хеш-функция — довольно медленный запрос, считается долго, поэтому все замедлится раза в три.
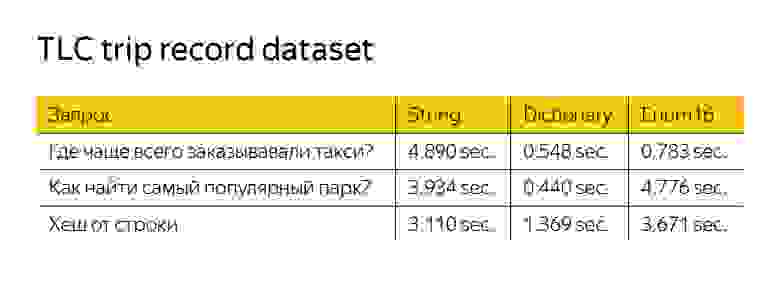
LowCardinality все еще работает быстрее, хотя тут нет фильтрации. Это происходит из-за того, что наши функции работают только над словарем. У функции вычисления хеша один аргумент — он может обрабатывать меньше данных и тоже может вернуть LowCardinality.

Наш глобальный план — добиться скорости работы не ниже, чем у String в любых случаях, и сохранить ускорения. И, может быть, мы когда-нибудь заменим String на LowCardinality, вы обновите ClickHouse, и у вас все заработает немножко быстрее.
— Сначала давайте разберемся, как можно хранить строки.

У нас есть строковые типы данных. String хорошо подходит по умолчанию, его стоит использовать почти всегда. У него небольшой Overhead — 9 байт на одну строку. Если мы хотим, чтобы размер строк был фиксирован и известен заранее, то лучше использовать FixedString. В нем можно задать нужное нам число байт, он удобен для данных типа IP-адресов или хеш-функций.

Конечно, иногда что-нибудь тормозит. Допустим, вы делаете запрос к таблице. ClickHouse читает довольно большое количество данных, скажем, со скоростью 100 ГБ/с, при этом строк обрабатывается мало. У нас есть две таблицы, которые хранят почти что одинаковые данные. Из второй таблицы ClickHouse читает данные с большей скоростью, но строк в секунду читается в три раза меньше.

Если мы посмотрим на размер сжатых данных, то он окажется почти равный. На самом деле в таблицах записаны одни и те же данные — первый миллиард чисел — только в первом столбце они записаны в виде UInt64, а во втором — в String. Из-за этого второй запрос дольше читает данные с диска и разжимает их.

Вот другой пример. Предположим, что есть заранее известное множество строк, оно ограничено константой 1000 или 10 000 и практически никогда не меняется. Для этого случая нам подходит тип данных Enum, в ClickHouse их два — Enum8 и Enum16. За счет хранения в Enum мы быстро обрабатываем запросы.
В ClickHouse есть ускорения для GROUP BY, IN, DISTINCT и оптимизации для некоторых функций, например для сравнения с константной строкой. Конечно же, числа в строке не преобразуются, а, наоборот, константная строка приводится к значению Enum. После этого все быстро сравнивается.
Но есть и минусы. Даже если мы знаем точное множество строк, иногда оно должно пополняться. Прилетела новая строка — мы должны сделать ALTER.

ALTER для Enum в ClickHouse реализован оптимально. Мы не переписываем данные на диске, но ALTER могут подтормаживать из-за того, что структуры Enum хранятся в схеме самой таблицы. Поэтому мы должны подождать запросов на чтение из таблицы, например.
Возникает вопрос, можно ли сделать лучше? Наверное, да. Можно сохранить структуру Enum не в схеме таблицы, а в ZooKeeper. Однако могут возникнуть проблемы, связанные с синхронизацией. Например, одна реплика получила данные, другая — нет, и если у нее старый Enum, то что-нибудь сломается. (В ClickHouse мы почти доделали неблокирующие ALTER-запросы. Когда доделаем их полностью, не нужно будет ждать запросы на чтение.)

Чтобы не возиться с ALTER Enum, можно использовать внешние словари ClickHouse. Напомню, что это key-value структура данных внутри ClickHouse, с помощью которой можно получать данные с внешних источников, например с таблиц MySQL.
В словаре ClickHouse мы храним множество различных строк, а в таблице — их идентификаторы в виде чисел. Если нужно получить строку, мы вызываем функцию dictGet и работаем с ней. После этого мы не должны делать ALTER. Чтобы что-то добавить в Enum, мы вставляем это в ту же самую таблицу MySQL.
Но тут возникают другие проблемы. Во-первых, неудобный синтаксис. Если мы хотим получить строку, мы должны вызвать dictGet. Во-вторых, отсутствие некоторых оптимизаций. Сравнение с константной строкой для словарей так же быстро не сделать.
Еще могут быть проблемы с обновлением. Предположим, мы запросили строку в кэш-словаре, а в кэш она не попала. Тогда мы должны ждать, пока загрузятся данные из внешнего источника.

Общий недостаток обоих методов — мы храним все ключи в одном месте и их синхронизируем. Так почему бы не хранить словари локально? Нет синхронизации — нет проблем. Можно хранить словарь локально в куске на диске. То есть мы сделали Insert, записали словарь. Если мы работаем с данными в памяти, то можем записать словарь или в блок данных, или в кусочек колонки, или в какой-нибудь кэш, чтобы ускорить вычисления.
Словарное кодирование строк
Так мы пришли к созданию нового типа данных в ClickHouse — LowCardinality. Это формат хранения данных: как они пишутся на диск и как читаются, как они представлены в памяти и схема их обработки.
На слайде есть две колонки. Справа строки хранятся стандартно, в типе String. Видно, что это какие-то модели мобильных телефонов. Слева есть точно такая же колонка, только в типе LowCardinality. Она состоит из словаря с множеством разных строк (строки из колонки справа) и списка позиций (номеров строк).
С помощью этих двух структур можно восстановить исходную колонку. Также есть обратный обратный индекс — хеш-таблица, которая помогает по строке найти позицию в словаре. Она нужна для ускорения некоторых запросов. Например, если мы хотим сравнить, поискать строку в нашей колонке или слить их между собой.
LowCardinality — параметрический тип данных. Он может быть либо числом, либо чем-то, что хранится в виде числа, либо строкой, либо Nullable от них.

Особенность LowCardinality в том, что он может сохраняться для некоторых функций. На слайде видно пример запроса. В первой строчке я создал колонку типа LowCardinality от String, назвал ее S. Далее я спросил ее имя — ClickHouse сказал, что это LowCardinality от String. Все верно.
Третья строчка почти такая же, только мы вызвали функцию length. В ClickHouse функция length возвращает тип данных UInt64. Но у нас стало LowCardinality от UInt64. В чем смысл?
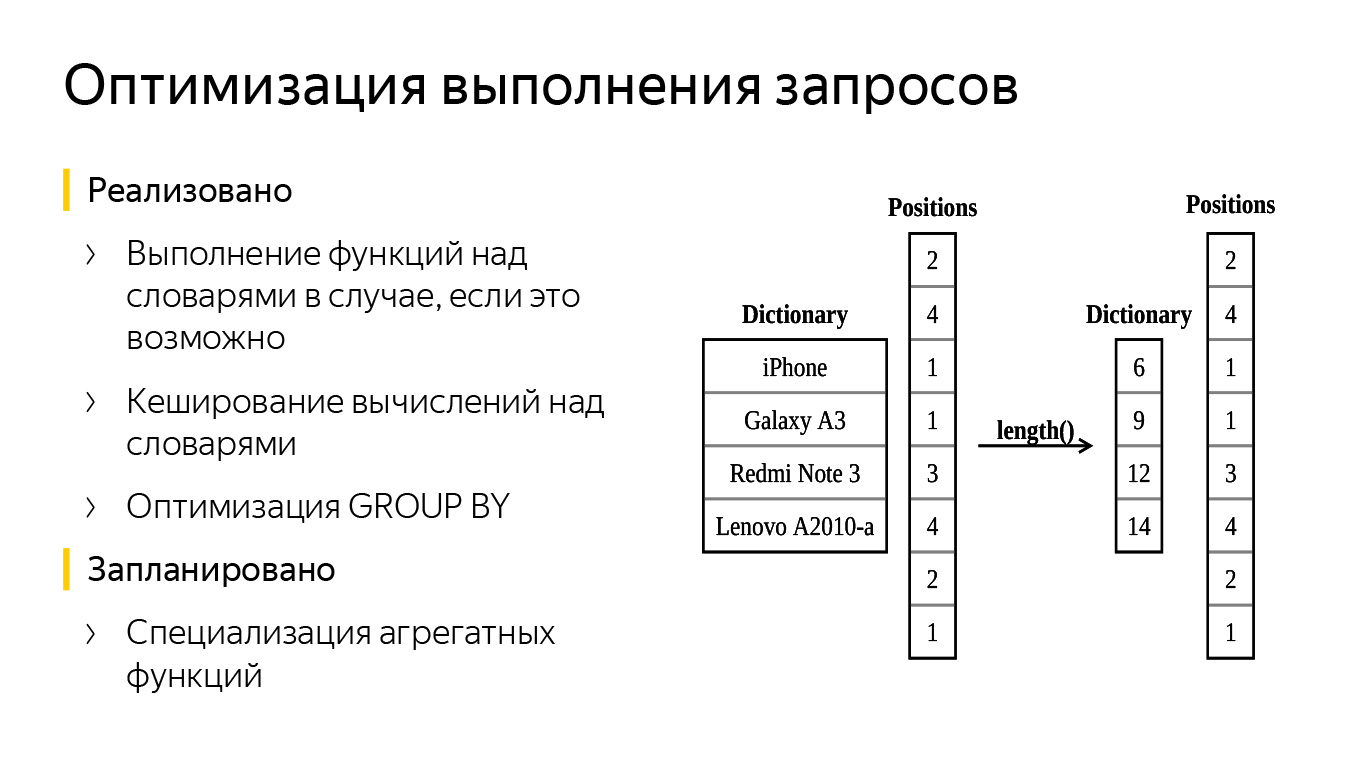
В словаре хранились названия мобильных телефонов, мы применили функцию length. Теперь у нас стал аналогичный словарь, состоящий только из чисел, — это длины строк. Столбец с позициями не поменялся. В итоге мы обработали меньше данных, сэкономили на времени запроса.
Могут быть и другие оптимизации, например добавление простого кэша. При вычислении значения функции можно запомнить его и составить такой же, не вычислять заново.
Также может быть сделана оптимизация GROUP BY, потому что наша колонка со словарем уже частично агрегирована — можно быстрее вычислять значение хеш-функций и примерно находить bucket, куда поместить очередную строку. Еще можно специализировать некоторые агрегатные функции, например uniq, ведь в нее можно отправить только словарь, а позиции оставить нетронутыми — так все будет работать быстрее. Первые две оптимизации мы уже добавили в ClickHouse.
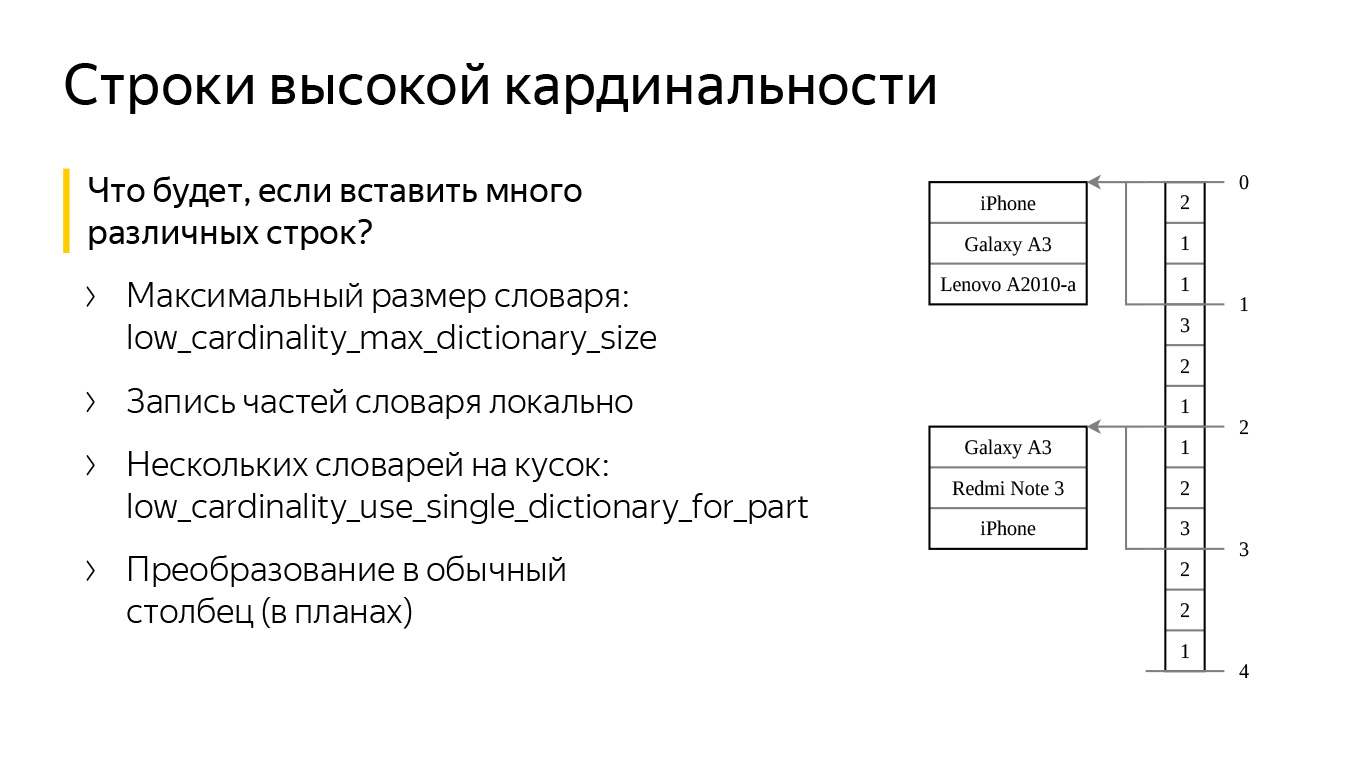
А что, если мы создадим колонку с нашим типом данных и вставим в нее много плохих разных строк? Не переполнится ли наша память? Нет, для этого в ClickHouse есть две специальные настройки. Первая — low_cardinality_max_dictionary_size. Это максимальный размер словаря, который может быть записан на диск. Вставка происходит следующим образом: когда мы вставляем данные, к нам идет поток строк, из них мы формируем большой общий словарик. Если словарик становится больше, чем значение настройки, мы записываем текущий словарь на диск, а остальные строки — где-нибудь «сбоку», рядом с индексами. В итоге мы никогда не пересчитаем большой словарь и не получим проблем с памятью.
Вторая настройка называется low_cardinality_use_single_dictionary_for_part. Представьте, что в прошлой схеме, когда мы вставляли данные, наш словарь переполнился, и мы записали его на диск. Возникает вопрос, а почему бы теперь не формировать еще один точно такой же словарь?
Когда он переполнится, мы снова запишем его на диск и начнем формировать третий. Эта настройка как раз отключает такую возможность по умолчанию.
На самом деле много словарей могут быть полезны, если мы хотим вставить какое-то множество строк, но случайно вставили «мусор». Скажем, сначала мы вставили плохие строки, а потом вставили хорошие. Тогда словарь разделится на много маленьких словарей. Часть из них будут с «мусором», но последние будут с хорошими строками. И если мы прочитаем, скажем, только последнюю гранулу, то все тоже будет работать быстро.

Прежде чем говорить о преимуществах LowCardinality, сразу скажу, что мы вряд ли добьемся уменьшения данных на диске (хотя это может произойти), потому что ClickHouse сжимает данные. Есть вариант по умолчанию — LZ4. Также можно сделать сжатие с помощью ZSTD. Но оба алгоритма уже реализуют словарное сжатие, поэтому наш внешний словарь ClickHouse не очень поможет.
Чтобы не быть голословным, я взял некоторые данные из метрики — String, LowCardinality(String) и Enum — и сохранил их в разные типы данных. Получилось три столбца, где записан один миллиард строк. В первом столбце, CodePage, всего 62 значения. И видно, что в LowCardinality(String) нам сжали их лучше. String чуть похуже, но это, скорее всего, из-за того, что строки короткие, мы храним их длины, а они занимают много места, плохо сжимаются.
Если взять PhoneModel, их 48 тысяч — уже больше, и различия между String и LowCardinality(String) почти что нет. Для URL мы тоже сэкономили всего лишь 2 ГБ — думаю, не стоит на это полагаться.
Оценка скорости работы

Ссылка со слайда
Теперь оценим скорость работы. Чтобы ее оценить, я использовал датасет с описанием поездок такси в Нью-Йорке. Он доступен на GitHub. В нем чуть более чем миллиард поездок. Там отражены локация, время старта и окончания поездки, способ оплаты, число пассажиров и даже вид такси — зеленый, желтый и Uber.

Первый запрос я сделал довольно простым — спросил, где чаще всего заказывают такси. Для этого нужно взять локацию, откуда заказывали, сделать по ней GROUP BY и посчитать функцию count. Вот ClickHouse что-то выдает.
Чтобы измерить скорость обработки запроса, я создал три таблицы с одинаковыми данными, но использовал для нашей стартовой локации три разных типа данных — String, LowCardinality и Enum. LowCardinality и Enum оказались в пять раз быстрее String. Enum быстрее потому, что работает с числами. LowCardinality — потому, что реализована оптимизация GROUP BY.

Давайте еще усложним запрос — спросим, где находится самый популярный парк в Нью-Йорке. Опять же мы будем это измерять по тому, где чаще всего заказывают такси, но при этом пофильтруем только те локации, где есть слово «парк». Также добавим функцию like.
Смотрим на время — видим, что Enum внезапно начал тормозить. Причем работает он еще медленнее, чем стандартный тип данных String. Это происходит потому, что функция like совсем не оптимизирована для Enum. Нам приходится преобразовывать наши строки из Enum в обычные строки — мы делаем больше работы. LowCardinality(String) тоже не оптимизирован по умолчанию, но там like работает над словарем, поэтому запрос ускоряется по сравнению со String.
При работе с Enum есть более глобальная проблема. Если мы хотим его оптимизировать, мы должны сделать это в каждом месте кода. Предположим, мы написали новую функцию — нужно обязательно придумать оптимизацию для Enum. А в LowCardinality все оптимизировано по умолчанию.

Посмотрим на последний запрос, более искусственный. Мы просто посчитаем хеш-функцию от нашей локации. Хеш-функция — довольно медленный запрос, считается долго, поэтому все замедлится раза в три.

LowCardinality все еще работает быстрее, хотя тут нет фильтрации. Это происходит из-за того, что наши функции работают только над словарем. У функции вычисления хеша один аргумент — он может обрабатывать меньше данных и тоже может вернуть LowCardinality.

Наш глобальный план — добиться скорости работы не ниже, чем у String в любых случаях, и сохранить ускорения. И, может быть, мы когда-нибудь заменим String на LowCardinality, вы обновите ClickHouse, и у вас все заработает немножко быстрее.
