
Добрый день, в прошлых статьях мы познакомились с работой ELK Stack. А теперь обсудим возможности, которые можно реализовать специалисту по ИБ в использовании данных систем. Какие логи можно и нужно завести в elasticsearch. Рассмотрим, какую статистику можно получить, настраивая дашборды и есть ли в этом профит. Каким образом можно внедрить автоматизацию процессов ИБ, используя стек ELK. Составим архитектуру работы системы. В сумме, реализация всего функционала это очень большая и тяжелая задача, поэтому решение выделили в отдельное название — TS Total Sight.
В настоящее время усиленно набирают популярность решения, консолидирующие и анализирующие инциденты ИБ в одном логическом месте, в результате специалист получает статистику и фронт действий для улучшения состояния ИБ в организации. Такую задачу мы себе поставили в использовании стека ELK, в результате выделили основной функционал в 4 раздела:
- Статистика и визуализация;
- Обнаружение инцидентов ИБ;
- Приоритизация инцидентов;
- Автоматизация процессов ИБ.
Далее более подробно рассмотрим по отдельности.
Обнаружение инцидентов ИБ
Главная задача в использовании elasticsearch в нашем случае это сбор только инцидентов ИБ. Собирать инциденты ИБ можно с любых средств защиты, если они поддерживают хоть какие-то режимы пересылки логов, стандартное это syslog или по scp сохранение в файл.
Можно привести стандартные примеры средств защиты и не только, откуда следует настроить пересылку логов:
- Любые средства NGFW (Check Point, Fortinet);
- Любые сканеры уязвимостей (PT Scanner, OpenVas);
- Web Application Firewall (PT AF);
- Анализаторы netflow (Flowmon, Cisco StealthWatch);
- AD сервер.
Посте того, как настроили отправление логов и конфигурационные файлы в Logstash, можно скоррелировать и сравнить с инциденты, поступающие с различных средств безопасности. Для этого удобно использовать индексы, в которых будем хранить все инциденты, относящиеся к конкретному устройству. Другими словами, один индекс — это все инциденты к одному устройству. Реализовать такое распределение возможно 2 способами.
Первый вариант это настроить конфиг Logstash. Для этого необходимо продублировать лог по определенным полям в отдельную единицу с другим типом. И потом в последующем использовать этот тип. В примере клонируются логи по блэйду IPS межсетевого экрана Check Point.
filter { if [product] == "SmartDefense" { clone { clones => ["CloneSmartDefense"] add_field => {"system" => "checkpoint"} } } }
Для того чтобы сохранить в отдельный индекс такие события в зависимости от полей логов, например такой как Destination IP сигнатуры атаки. Можно использовать подобную конструкцию:
output { if [type] == "CloneSmartDefense"{ { elasticsearch { hosts => [",<IP_address_elasticsearch>:9200"] index => "smartdefense-%{dst}" user => "admin" password => "password" } } }
И таким образом можно сделать сохранение в индекс всех инцидентов, например, по IP адресу, или по доменному имени машины. В данном случае сохраняем в индекс «smartdefense-%{dst}», по IP адресу назчения сигнатуры.
Однако, у различных продуктов будут разные поля для логов, что приведет к хаосу, и лишнему употреблению памяти. И здесь надо будет либо внимательно в настройках конфига Logstash заменять поля на заранее задуманные, которые будут одинаковы для всех типов инцидентов, что тоже является сложной задачей.
Второй вариант реализации — это написание скрипта или процесса, которые будут в режиме реального времени обращаться к базе эластика, вырывать нужные инциденты, и сохранять уже в новый индекс, это являются тяжелой задачей, но позволяет работать с логами как душе угодно, и коррелировать напрямую с инцидентами с других средств безопасности. Данный вариант позволяет настроить работу с логами максимально полезно для вашего случая с максимальной гибкостью, но здесь возникает проблема в поиске такого специалиста, который это сможет реализовать.
И разумеется, самый главный вопрос, а что вообще можно скореллировать и обнаружить?
Здесь может быть несколько вариантов, и зависит от того какие средства безопасности используются в вашей инфраструктуре, парочка примеров:
- Самый очевидный и с моей точки зрения самый интересный вариант для тех у кого есть решение NGFW и сканер уязвимостей. Это сравнение логов по IPS и результатов сканирования уязвимостей. Если было задетектирована атака ( не блокирована) системой IPS, и данная уязвимость не закрыта на конечной машине исходя из результатов сканирования — необходимо трубить во все трубы, так как существует большая вероятность того что уязвимость была проэксплуатирована.
- Много попыток логина с одной машины в разные места, может символизировать о зловредной активности.
- Скачивание пользователем вирусных файлов ввиду посещения в огромном количеству потенциально опасных сайтов.
Статистика и визуализация
Самое очевидное и понятное, для чего нужен ELK Stack — это хранение и визуализация логов, в прошлых статьях было показано, каким образом можно завести логи от различных устройств, используя Logstash. После того как логи идут в Elasticsearch, можно настроить дашборды, о которых тоже упоминали в прошлых статьях, с необходимой для вас информацией и статистикой посредством визуализации.
Примеры:
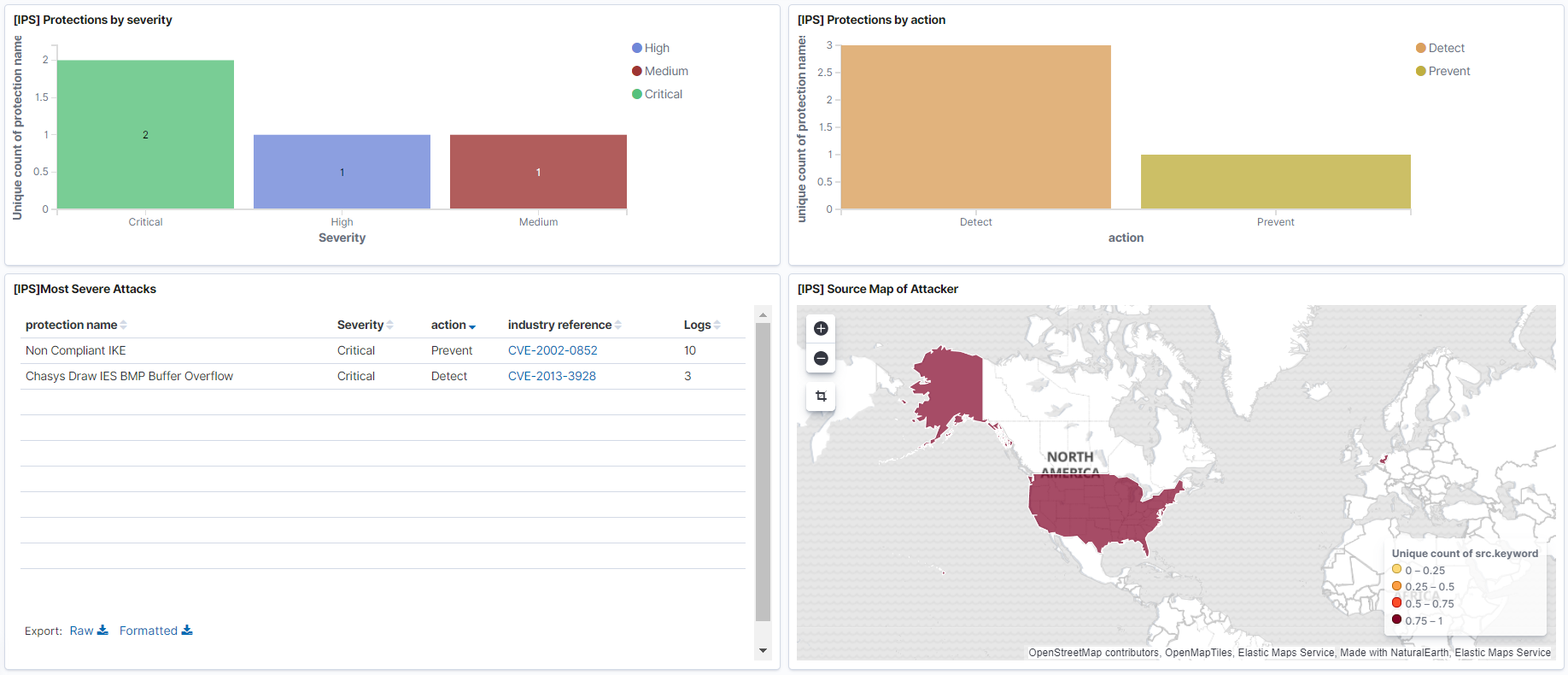
- Дашбоард по событиям Threat Prevention с наиболее критическими событиями. Здесь можно отразить какие сигнатуры IPS были обнаружены, откуда территориально они исходят.
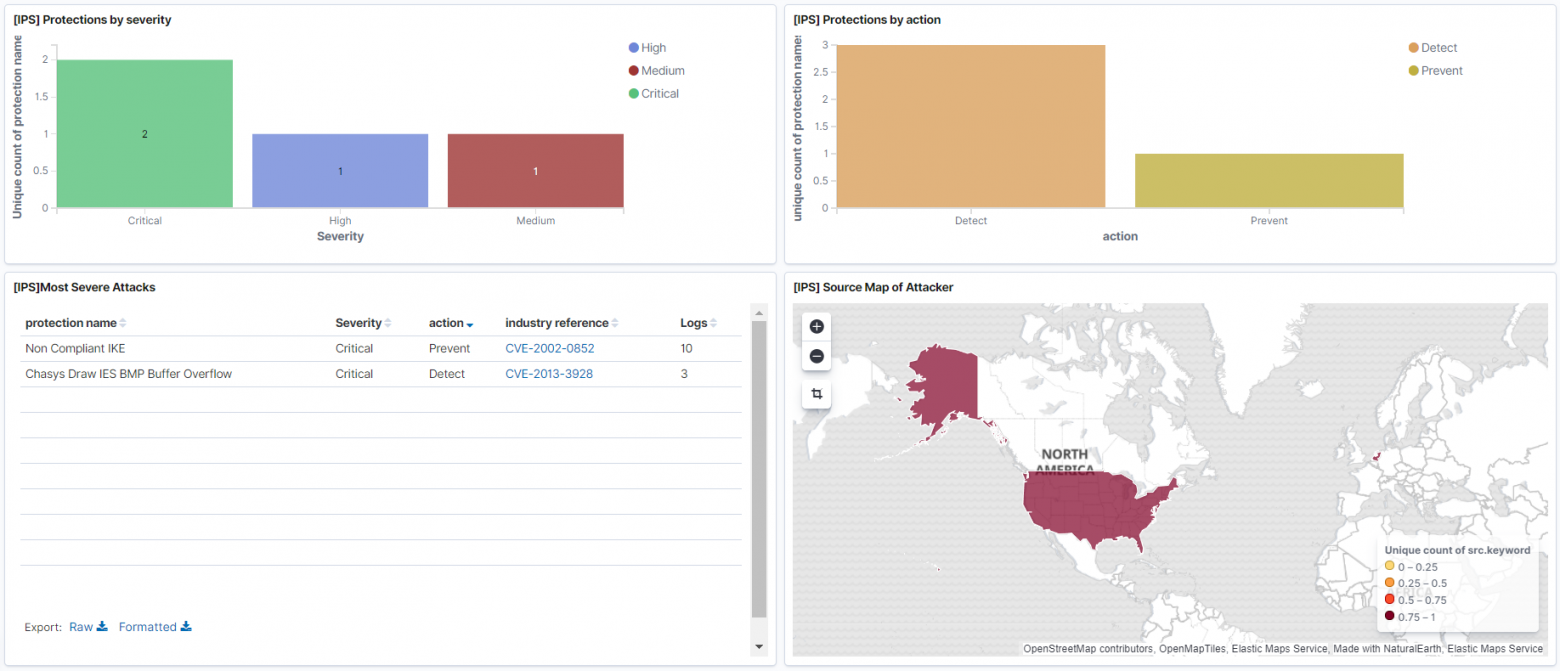
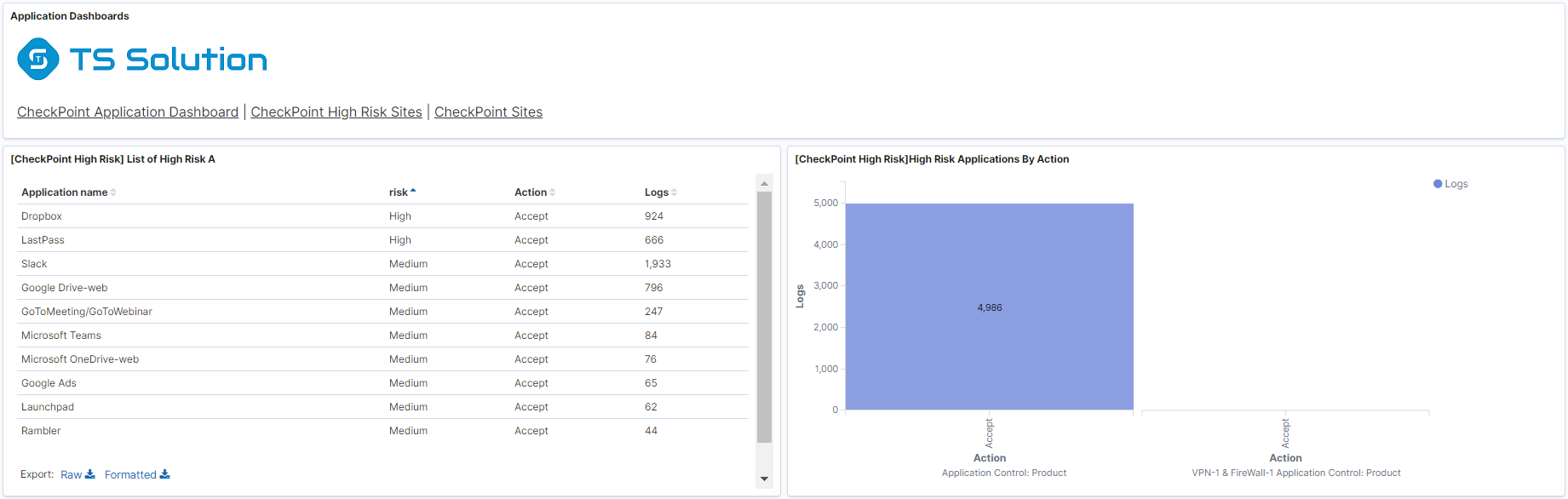
- Дашбоард по использованию наиболее критических приложений, по которым может сливаться информация.

- Результаты сканирования с любого сканера безопасности.

- Логи с Active Directory по пользователям.
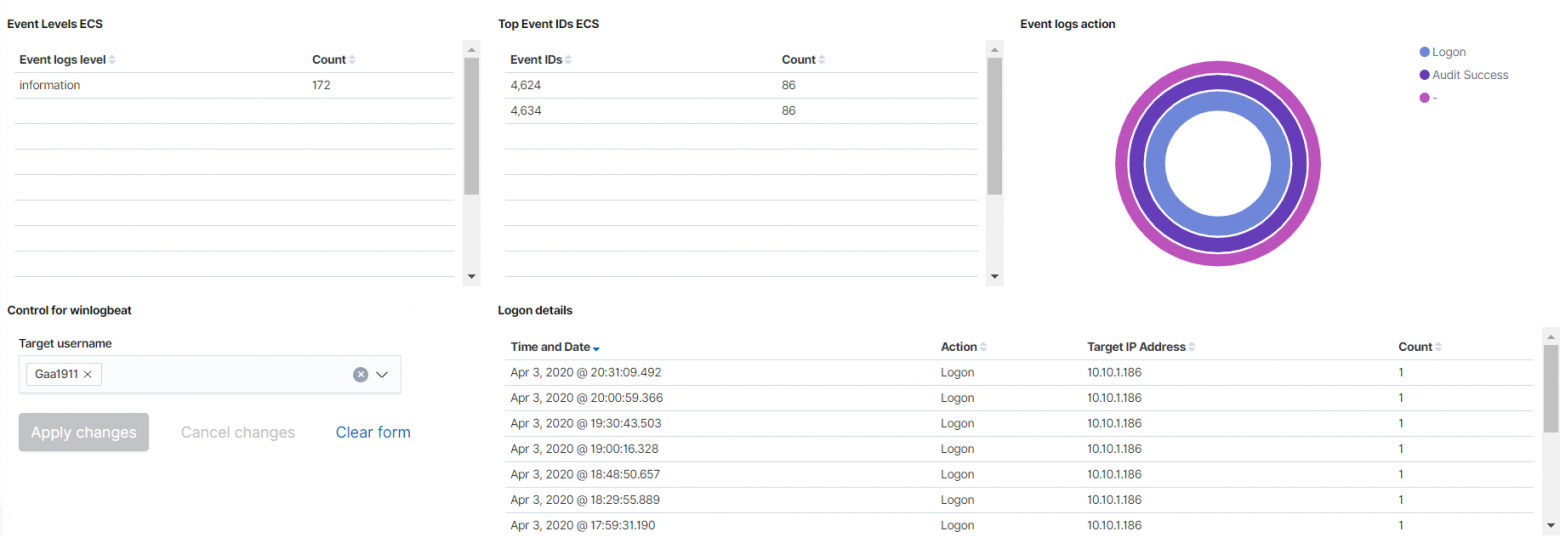
- Дашбоард по подключение VPN.
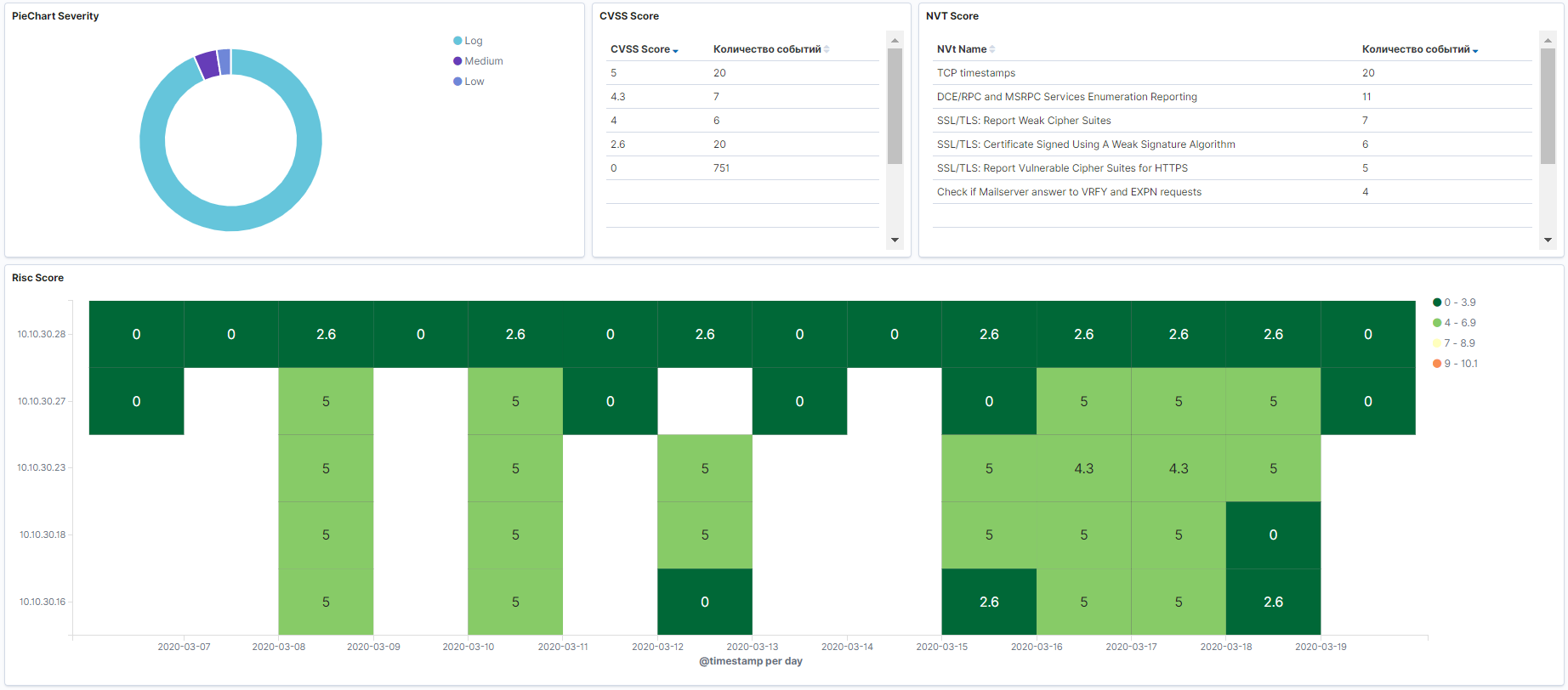

В данном случае, если настроить дашбоарды на обновление каждые несколько секунд, можно получить довольно удобную систему для мониторинга событий в реальном времени, которую далее можно использовать для наиболее быстрого реагирования на инциденты ИБ, если поставить дашборды отдельным экраном.
Приоритизация инцидентов
В условиях большой инфраструктуры количество инцидентов может зашкаливать, и специалисты не будут успевать вовремя разбирать все инциденты. В данном случае, необходимо в первую очередь выделять только те инциденты, которые несут большую угрозу. Поэтому система должна приоритизировать инциденты по их опасности по отношению к вашей инфраструктуре. Желательно настроить оповещение в почту или телеграмм данных событий. Приоритизацию можно реализовать штатными средствами Kibana, путем настройки визуализации. А вот с оповещением тяжелее, по умолчанию данный функционал не включен в базовую версию Elasticsearch, только в платной. Поэтому либо покупать платную версию, либо опять-таки, самому написать процесс который будет в режиме реального времени уведомлять специалистов на почту или в телеграмм.
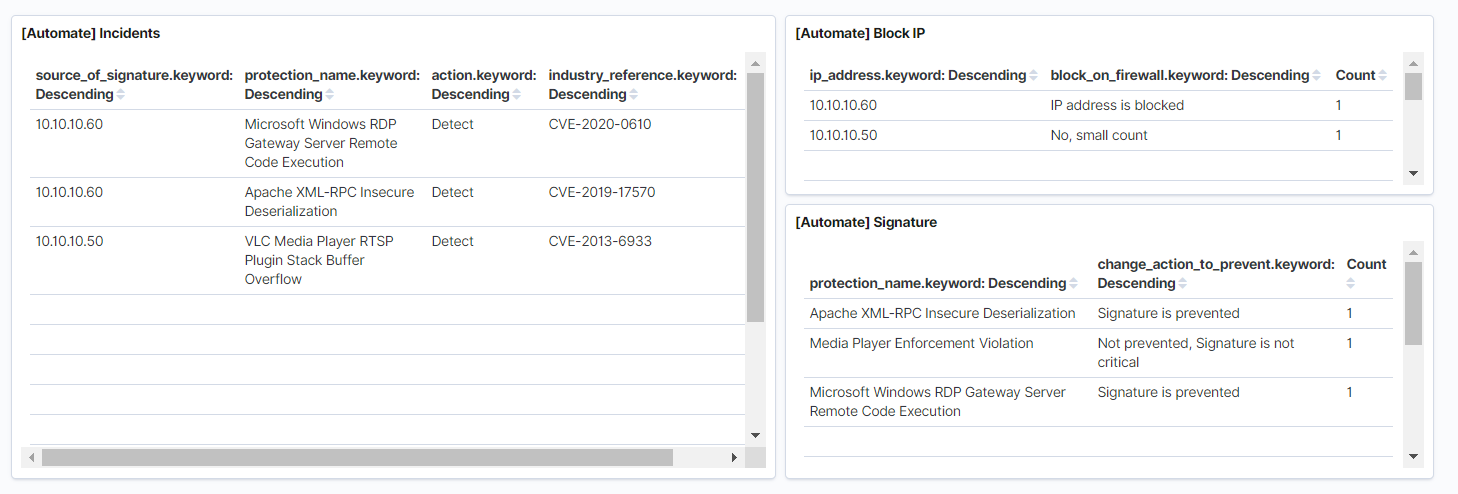
Автоматизация процессов ИБ
И одной из самых интересных частей является автоматизация действий на инциденты ИБ. Ранее данный функционал мы реализовывали для Splunk, чуть подробнее, можете прочитать в этой статье. Основная идея в том, что политика IPS никогда не проверяется и не оптимизируется, хотя в некоторых случаях является важнейшей частью процессов информационной безопасности. К примеру через год после внедрения NGFW и отсутствия действий по оптимизации IPS, у вас скопится большое количество сигнатур с действием Detect, которые не будут блокироваться, что сильно снижает состояние ИБ в организации. Далее некоторые примеры того, что можно автоматизировать:
- Перевод сигнатуры IPS с Detect на Prevent. Если на критические сигнатуры не работает Prevent, то это не порядок, и серьезная брешь в системе защиты. Меняем действие в политике на такие сигнатуры. Реализовать данный функционал можно, если устройство NGFW обладает функционалом REST API. Это возможно только обладая навыками программирования, надо выдергивать нужную информацию из Elastcisearch и выполнить API запросы на сервер управления NGFW.
- Если с одного IP адреса в сетевом трафике обнаружилось или заблокировалось множество сигнатур, то имеет смысл заблокировать на некоторое время данный IP адрес в политике Firewall. Реализация также состоит из использования REST API.
- Запускать проверку хоста сканером уязвимостей, если на этот хост приходится большое количество сигнатур по IPS или других средств безопасности, в случае если это OpenVas, то можно написать скрипт, который будет подключаться по ssh на сканер безопасности и запускать сканирование.
TS Total Sight
В сумме реализация всего функционала это очень большая и тяжелая задача. Не обладая навыками программирования, можно настроить минимальный функционал, которого может быть достаточно для использования в продуктиве. Но если вас интересует весь функционал, вы можете обратить внимание на TS Total Sight. Более подробно вы можете ознакомиться на нашем сайте. В результате вся схема работы и архитектура будет выглядеть подобным образом:

Заключение
Мы рассмотрели, что можно реализовать, используя ELK Stack. В последующих статьях отдельно рассмотрим более детально функционал TS Total Sight!
Так что следите за обновлениями (Telegram, Facebook, VK, TS Solution Blog), Яндекс.Дзен.

