
Люди пользуются кнопкой возврата на предыдущую страницу в браузере очень часто — возможно, чаще, чем вы думаете. А если так, то зачем сразу выбрасывать страницу из памяти браузера, а спустя секунду тратить время и трафик на её повторное открытие? Чтобы пользователь мог быстро вернуться назад, была придумана технология BFCache, о которой важно помнить при разработке интерфейсов. Виктор Хомяков victor-homyakov разобрался в «кэшировании туда и обратно» и составил таблицу совместимости BFCache с разными API.
— Здравствуйте, меня зовут Виктор. Я работаю в составе довольно большой команды, которая занимается страницей поиска.
Как минимум, такую же или аналогичную страницу в Google вы уже видели. И в частности, я занимаюсь проблемой скорости загрузки этой страницы — чтобы она максимально быстро рендерилась на сервере и максимально быстро скачивалась и показывалась клиентам. Почему это важно? Чем меньше ожидания у клиента, пока загрузится ваша страница, тем меньше шансов, что он не дождется и уйдет от вас. И тем больше шансов, что будет успешная конверсия клиента во что-то еще, тем больше будет net promotion score. То есть клиент будет радостно рассказывать всем знакомым, что здесь офигенно классная страница — очень быстро грузится, очень удобно пользоваться. И в конечном счете, тем больше денег вы сможете заработать. Или ваша компания, тогда она выдаст вам премию.
Приведу ряд примеров от известных компаний. Google провел эксперимент. Они специально встроили задержку на странице поиска и измерили, как это влияет на характеристики. Оказалось, что в среднем стало на полпроцента меньше поисков на одного пользователя. Что такое полпроцента? Посчитайте: полпроцента от сотен миллионов пользователей Google — это довольно большое число.
Bing провел такой же эксперимент. Они не верили Google, решили перепроверить. У них получились аналогичные результаты: заметно меньше доходов на пользователя при замедлении страницы. Почему замедление? Потому что легче замедлить страницу на точное число миллисекунд, чтобы это легко воспроизводилось в продакшене, чем ускорить ее на столько же.
Пример от AliExpress. Они ускорили свой сайт на 36% и получили заметно больше заказов от пользователей. Заказы — это прямые деньги. В общем, всем уже понятно, что скорость довольно важна, влияет через какое-то количество метрик на зарабатываемые деньги.
И еще один фактор. Сегодня уже говорили про оптимизацию картинок. Оптимизируя свой трафик, уменьшая количество загрузок, вы платите меньше денег вашим хостерам за исходящий трафик. Это тоже деньги, которые останутся у вас в кармане. Что если я внезапно предложу вам скидку 10% на трафик у любого хостера без ограничений и условий? А если я предложу сделать так, чтобы доля ваших страниц — например, десять процентов — грузилась у пользователя практически мгновенно? Никто не откажется.
Технология, о которой я попытаюсь рассказать сегодня, — одно из возможных решений, которое налагает мало ограничений на то, в каком стеке вы работаете, с какими технологиями, но при этом обещает дать вам вот такие довольно значимые выигрыши.
Начнем с того, что Google в своих браузерах собирает статистику о том, как эти браузеры используются. И они опубликовали такое число: оказывается, в среднем из всех открытий страниц, из всех навигаций в мобильном Chrome примерно 19% — это перемещение по истории вперед-назад. Подумайте, что это значит? Если округлить, получится, что 20% навигаций — это перемещение на страницу, где пользователь только что был.
Для нас как для авторов страниц это означает: даже если пользователь с нее ушел, есть немалый шанс, что он вот-вот вернется обратно. С одной стороны, это может быть именно проблемой мобилок: там все маленькое, легко промахнуться пальцем, нажать на ссылку и уйти со страницы, потом сказать: «А, черт! Я хочу вернуться». Но на десктопах примерно такая же картина: там число меньше, но все равно есть значительный процент возвратов.
Что мы в это время делаем? Бездарно тратим время пользователя и трафик. То есть мы начинаем обратно перезагружать ту же самую страничку, парсить ее, пересоздавать DOM, перерисовывать все на экране, загружать, выполнять JavaScript.
Браузер — довольно мощная штука. Он пытается использовать кэши везде, где только можно. И большая часть ресурсов, возможно, окажется у него в кэше. Он не будет ждать их из сети, а поднимет прямо из кэша. Например, в движке V8 результат парсинга JavaScript тоже кэшируется. То есть браузер не будет повторно загружать и парсить JS, а в большинстве случаев примется сразу его выполнять. Но все равно пересоздание DOM, перезагрузка не кэшированных ресурсов и выполнение JS занимают заметное время.
Решение напрашивается само собой. Что мы делаем? Мы, когда пользователь выходит с нашей страницы, не вычищаем ее сразу же. Мы просто сохраняем ее состояние и визуально прячем ее от пользователя, чтобы под капотом она оставалась в распоряжении браузера.
Что мы сделаем, если пользователь решит вернуться? Просто покажем ему ту же самую сохраненную страницу. Ее можно показать практически мгновенно.
Эта технология называется back/forward cache, от слов «вперед-назад». Сокращенно — bfcache.
Вот пример того, как один и тот же браузер, одна и та же сборка, ведет себя при выключенном и при включенном bfcache. Первое открытие страницы происходит одинаково медленно и там, и там. Но дальше, когда мы начинаем перемещаться по истории вперед-назад, слева заметна пауза, а справа ее нет. Слева обычное перемещение по истории, занимает заметное время. Справа все происходит очень-очень быстро.
Аналогичный пример из нашего поиска. Слева обычный Safari на macOS при отключенном bfcache, справа тот же самый Safari с настройками «по умолчанию» и включенным bfcache. Это довольно частый случай: человек приходит на поиск, может точно не знать, чего он ищет, может задать несколько вариантов запроса. Первый запрос задал — что-то не то. Второй запрос — кажется, лучше. Третий — нет, хуже, возвращаемся назад к предыдущему запросу. И вот в этот момент очень хорошо бы не заставлять его ждать. Он только что видел этот предыдущий запрос, покажите его сразу же.
Или второй вариант, если у вас есть пагинация и несколько страниц на выдаче. Человек листает выдачу. Перешел на вторую, третью, четвертую страницу, посмотрел — нет, там что-то не то, вернусь обратно. И мы, опять же, можем ему показать предыдущие страницы практически мгновенно.
Важный вопрос — безопасность. Пока страница, на которой был пользователь, не находилась в скрытом состоянии, она могла получить доступ к разным API, которые позволяют считывать состояние железа вашего телефона или компьютера. Вот кратенький список того, что сразу пришло в голову: геолокация, изменение положения вашего устройства в пространстве, доступ к камере, к звуку с микрофона.
Потом, когда страница покажется, важно, чтобы она не получила доступа ко всем событиям, которые произошли за время, пока она была спрятана. Иначе откроется дополнительный канал для шпионажа за пользователями. Важно, чтобы она не получила историю ваших перемещений за все это время и записи микрофона и камеры. Об этом разработчики браузеров тоже не должны забывать.
Ближе к теме. Допустим, я вас уже уговорил, вы такие: «Да, хорошая тема, надо с этим работать». Какие API у нас есть в распоряжении, с чем мы можем работать, если мы согласились принять bfcache во внимание, и как это все поддерживается браузерами?
Где bfcache уже есть, где это можно посмотреть?
— Он давно реализован в браузерах Firefox, Safari (и macOS, и iOS), а также в Internet Explorer 11 (!). Обычно мы ругаем разработчиков Microsoft, но здесь они как раз постарались.
— Он реализован в браузере UC Browser 11/12, версия под Android.
— Внезапно его нет в Chrome. А в Chromium эта фича находится в стадии разработки.

Значит, когда они это сделают в Chromium, примерно все эти браузеры (и это далеко не полный список) рано или поздно получат эту функциональность — даром, без смс и регистрации.
Есть ли какой-то API? Я хочу управлять bfcache, хочу включать и выключать его прямо из JavaScript, узнавать, есть ли в bfcache какая-то страница или нет. Как насчет такого API? Такой API отсутствует. И это сделано сознательно: страница вообще не должна хотеть включать-выключать bfcache для всех и для себя. Или узнавать, есть ли кто-нибудь в этом bfcache или нет. Это все из-за секьюрности.

Ссылка со слайда
Но что у нас есть? Типы навигации. Есть тип link — link prerender, когда мы хотим заранее отрендерить страницу. Для него есть специальный тип навигации: эта страница будет открыта с NavigationType “prerender”. Если мы просто открываем страницу в браузере, то там будет “navigate”. Если жмем на кнопку «Обновить» — будет “reload”.
Нас здесь интересует тип навигации “back_forward”, это явно говорит о том, что пользователь перемещался по истории вперед-назад. Это именно тот тип навигации, при котором может сработать наш bfcache.

Еще один API — это события pageshow pagehide. Они уже и так существовали в браузерах. Соответственно, pageshow срабатывает, когда ваша страница показывается в браузере пользователю, pagehide — когда страница скрывается по какой-либо причине. И они были дополнены полем persisted. Если страница скрывается и при этом будет помещена в bfcache, то в поле persisted будет true. Если страница показывается при поднятии ее из bfcache, то в поле persisted опять же будет true.
Соответственно, если браузер не собирается кэшировать страницу, то на pagehide будет persisted false. И если браузер показывает страницу при обычной загрузке, или он не использует bfcache, то при pageshow будет тоже persisted false.

Ссылка со слайда
Поддержка события есть практически во всех браузерах, даже в тех, которые пока не поддерживают bfcache.

Ссылка со слайда
То же самое касается поля persisted. Оно уже есть в Chrome, при этом Chrome все еще не поддерживает bfcache. То есть в нем это поле всегда будет, но пока оно будет false.
Когда я столкнулся с этим явлением, bfcache, мне пришлось изучать его, обстукивать со всех сторон, смотреть, как оно работает. Я сразу захотел увидеть у себя на странице при открытии, чему равно значение поля persisted в моих обработчиках.

Казалось бы, все довольно просто. Я написал обработчик и вывел в console.log() то, что мне приходит. Но при открытии DevTools в некоторых браузерах bfcache может внезапно отключиться. То есть я открыл DevTools, хожу по страницам вперед-назад, и у меня persisted всегда false, страница в bfcache не попадает. Окей, у меня есть еще одно мощное средство — alert.
Но нет. Современные браузеры при выгрузке страницы в обработчиках pagehide, beforeunload и unload просто игнорируют alert, он там просто не работает. И я опять не вижу того, чего хочу.

Окей, у меня есть еще более убойное средство. Я в какой-то блок прямо на своей же странице, которую исследую, просто добавляю текстом содержимое моего события и тем самым все логирую. Такой способ сработал.

Все, пожалуйста, можно пользоваться. Я свой код отладил, он у меня работает, я могу с ним дальше продолжать. Конечно, я не забываю, что все-таки лучше подходит внешний статический скрипт, чтобы не грузить на странице в заинлайненном коде все то же самое, а использовать кэширование файлов.
Я вынес во внешний скрипт этот отлаженный код.

Но нет, обработчики pageshow pagehide отвалились в Safari! Из внешнего скрипта они почему-то не работают.
Окей, у меня уже есть рабочий вариант. Мне пришлось оставить его в таком виде.

Вкратце перечислю, на что я успел наступить буквально за один день. Во-первых, DevTools могут отключать кэширование. Вы, наверное, помните, что в DevTools на вкладке Network в Chrome есть галочка «Отключать кэш». Она отключает сетевой кэш, на bfcache она может не влиять, а может и влиять. Аналогия понятна: открыли DevTools — значит, мы разрабатываемся и кэширование нам может быть не нужно. Может, оно нам мешает.

Вторая особенность — alert. Firefox и Safari молча его проигнорируют и продолжат дальше выполнять обработчики, как будто там не было никакого alert. И только один старый-добрый Chrome в консоли напишет красным цветом ошибку — у вас alert, я его заблокировал, знайте об этом!
Еще раз напоминаю, что обработчики из внешнего скрипта в Safari могут не вызываться, это очень странно.
И еще одна важная новость. Если ваша страница ушла в кэш, то есть вы получили событие pagehide, и в нем написано persisted true, а браузер вам говорит: «Да, я положил ее в кэш», — это не дает никаких гарантий, что страница когда-либо потом будет из этого кэша поднята и показана обратно пользователю. Потому что браузер может решить почистить этот кэш, если ему не хватает памяти. Потому что пользователь может закрыть браузер и не навигироваться никуда. Запомните это.
Я стал дальше копаться в документации, исследовать, как мне с этим знанием жить. На удивление, документация была. То есть можно нарыть в интернетах описание, как работает bfcache в браузерах. Но, чем дальше я читал, тем больше накапливалось различий между разными браузерами.
В одном одно работает так, в другом так. В одном одно мешает, другое не мешает. Разработчики не знают, как корректно обработать целый ряд API при помещении страницы в bfcache. Они говорят: окей, если страница использует этот API, то я просто ее игнорирую, не помещаю в кэш никогда ни при каких условиях. И этот список разный в разных браузерах, каждый делает так, как ему удобно.
И тогда я начал сводить то, что я узнавал, в одну таблицу. У меня получилось примерно следующее:

Я читал документацию по браузерам — по Firefox, Safari, семейству Chromium. По IE была доступная документация, хотя и устаревшая. Мы же, программисты, не любим обновлять документацию после изменений в браузере? Когда я понял, что информация устарела, то начал тестировать в браузерах свои маленькие странички и проверять, какое API работает, а какое нет.
Этого тоже оказалось недостаточно: я же не знаю, какие API смотреть в принципе, не перебирать же вообще все-все подряд? И мне пришлось заглянуть в исходные коды самих движков браузеров, то есть код оказался самым точным и достоверным источником знаний. На текущий момент эта табличка (перед вами ее кусочек, вот ссылка на полную версию) — самое полное собрание знаний о том, какие API разрешают или запрещают работу bfcache в браузерах.
Галочкой и зеленым цветом помечены те API, которые не мешают, красным — те, которые однозначно будут мешать попаданию страницы в bfcache. Белые поля — пробелы, которые нигде не описаны.
Вот интересные детали из конкретных браузеров. Начну с Firefox, он первый это все сделал.

Ссылка со слайда
Самое главное, что я узнал из исходников Firefox, — это то, что он при работе с bfcache может писать в текстовый лог на диске все причины, по которым он не может поместить страницу в кэш.

Ссылка со слайда
И мне даже удалось узнать, как его заставить это сделать. Есть две секретных переменных окружения: в одной мы указываем, что логировать, во второй — в какой файл писать лог. После этого мы запускаем бинарник, и вуаля! Мы увидим примерно то, что на предыдущем слайде, строчки вида «такой html не может быть закэширован по такой причине, такой — по другой причине». Мы это cможем сразу прочитать, очень удобно.

Если вы хотите один раз поэкспериментировать, можно в Firefox открыть страницу about:networking. Там в разделе «Журнал» можно ввести эти же самые поля. Мы можем указать в двух полях, что и куда логировать, и кнопочками начинать и останавливать журнал.

Ссылка со слайда
Когда Firefox отказывается от кэширования страницы? Если у вас есть незавершенные запросы, в том числе AJAX-запросы или запросы за ресурсами типа картинок, то он откажется помещать страницу в bfcache. Он считает, что она не завершена, не закончила загрузку, там есть какая-то подозрительная активность. Но все это не распространяется на favicon. Если вы забыли favicon, если она не грузится, он считает — окей, пойдет, для вашего сайта это нормально.
Если у вас есть долго выполняющийся скрипт, браузер спросит: раз он занимает время, блокирует UI, может, его прибить? И если вы согласились, то такая страница считается битой, неправильной, и мы ее не кэшируем.
Если вы используете IndexedDB… Это поучительная история. Раньше, в первой реализации, они смотрели: если у вас IndexedDB и есть незавершенная транзакция, то такая страница не кэшируется, потому что непонятно, как с ней работать (мы прямо в середине транзакции пытаемся ее спрятать). Но потом они в ходе рефакторинга этот кусок кода просто потеряли. И как вы догадываетесь, тестов на это у них не было. У них в багтрекере даже есть баг. Ему уже два с чем-то года. Люди написали: «У меня bfcache с IndexedDB работает некорректно, что делать?» Разработчики Firefox ответили — действительно ломается, мы этот кусок текста при рефакторинге просто потеряли, окей, пусть так будет и дальше. Мораль: пишите тесты, даже если вы пишете Firefox, иначе все может закончиться печально.
И еще один интересный фактор непопадания в bfcache — если явно разрешен mixed content. Что это такое?

Ссылка со слайда
Предположим, ваша страница открывается через HTTPS, но некоторые ресурсы вы все еще грузите через HTTP, особенно скрипты. То есть у вас несекьюрный скрипт, он может модифицироваться кем угодно.

Ссылка со слайда
По умолчанию Firefox, как и другие браузеры, такой несекьюрный скрипт сейчас не выполняет. Но если вам очень важно, вы залезли в настройки и разрешили его выполнять, то он, соответственно, такую страницу кэшировать не будет. Он скажет — хорошо, ты меня уломал выполнить код, но дальше ни-ни!

Еще одна настройка — это размер самого bfcache. Здесь по умолчанию стоит минус один. Значит, сколько памяти хватает Firefox, столько страниц он и пытается закэшировать. Но мы можем принудительно отключить кэш, проставив ноль, или явно задать число — допустим, запоминай не более пяти страниц.
Предупреждение: следующий слайд содержит пример кода на страшном языке C++, на фронтенд-конференции это может быть опасным. Не пытайтесь это копировать, выполнять в консоли браузера. У вас может отформатироваться диск, взорваться экран, или начнут майниться биткоины. Я вас предупредил.

Ссылка со слайда
Итак, код Gecko. Его можно открыть, прочитать, посмотреть бесплатно в интернете. И я покопался. Там есть самый главный метод — CanSavePresentation(), он отвечает на вопрос: можно ли кэшировать данный документ? То есть это конечный источник правды о том, что прямо сейчас реализовано в Firefox. И еще — именно оттуда я узнал о том, что можно прочитать лог. Есть такая переменная — gPageCacheLog. Это и есть тот лог, в который все пишется. Вот такая интересная история про экскурс в C++.
То есть вы открываете ссылку, смотрите код, ищете (там удобный и притом быстрый поиск) и можете узнавать актуальные детали реализации в последней версии браузера — такие, которые в документации просто отсутствуют.
Самое жестокое, что делает Safari при попадании страницы в bfcache: если у вас есть незавершенные AJAX-запросы, Safari их просто убивает.

Даже если вы обложили их обработками ошибок и пытаетесь все проверять, исправлять — запроса как будто вообще не было в принципе. После восстановления из bfcache у вас не будет ни ошибки, ни «OK», вообще ничего.

Обработчики pageshow pagehide, как я уже говорил, в Safari вызываются, только если они написаны в скрипте, который заинлайнен в страницу. Из внешнего скрипта они могут работать или не работать — как повезет. Но я вас предупредил.

Еще одно интересное отличие: обработчики beforeunload и unload не мешают попаданию страницы в bfcache. При этом beforeunload вызывается всегда, и при попадании в кэш, и при не попадании. А вот unload при попадании страницы в кэш не вызывается. И здесь еще одни грабли расположены: страница может попасть в кэш и из него не показаться уже никогда, и если вы написали в unload какой-то важный код, он может в принципе никогда не вызваться, хотя на странице не произошло ни одной ошибки. То есть она корректно ушла в кэш, а из него в никуда, и вашего unload никогда не будет вызвано.

Еще один интересный момент. Как вы знаете, можно через window.open() открывать несколько окон. И при этом у этих окон друг на друга остаются ссылки. То есть они могут синхронно лазить в window друг друга, читать/писать разные свойства. Такое открытие дочерних окон не мешает bfcache. И здесь, скорее всего, Safari так же жестоко поступает, как и с AJAX-запросами, то есть все по-жесткому рвет, и до свидания. Разработчики Apple любят пожестче.
Снова минутка C++! Исходники WebKit тоже не секретны, их тоже можно открывать, читать и изучать.

Ссылка со слайда
Они лежат на GitHub, там я выделил две важных функции:
— canCacheFrame() — проверка, можно ли кэшировать данный фрейм.
— В разных объектах на странице, типа HTML-элемента или шрифта, есть методы canSuspendForDocumentSuspension(). Этот объект отвечает за то, может ли он закэшироваться, заморозиться, или не может.
И еще один важный аспект: у WebKit есть очень удобные тесты. Там прямо в папке LayoutTests/fast/history в виде маленьких, компактных, лаконичных html лежат тесты на работу разных API, которые реализованы в Safari с bfcache. Это живой пример того, как можно писать код в Safari с этими API и как они влияют или не влияют, разрешают попадание в bfcache или не разрешают. Очень интересно посмотреть.

Оттуда же я узнал, что Safari тоже пишет все свое знание о bfcache, все особенности, в текстовый лог. Но, к сожалению, я так и не раскопал, как включить это логирование или, если оно включено, где найти этот файл на диске. Если кто-то знает, скажите мне, я буду очень благодарен.

Как я уже говорил, там работа пока в процессе, все закрыто под флагом. Вы можете загрузить свеженький Chrome Canary, зайти во флаги. Там спрятана настроечка — можно попробовать ей поиграться. Возможно, вы что-то увидите.

Из интересного — я уже говорил про открытие страницы через window.open(). В Chromium пока что такие страницы не кэшируются. Они не придумали, как корректно все это разрулить, а бессовестно все обрывать, как в Safari, им совесть не позволяет.
Если не наступил DOMContentLoaded, то страница тоже не будет кэшироваться.
Есть много новых API, которые начинаются с «Web» — с ними тоже пока сложно и непонятно, и пока что все они по умолчанию выключают bfcache. То есть если на странице используется что-то модное, новое, типа WebGL, WebVR, WebUSB, WebBluetooth и прочее, — в bfcache такая страница не попадет.
Service Worker. Тоже пока что не кэшируем такую страницу, но планируем ее корректно обрабатывать, прятать от зорких глаз Service Worker.
Если разрешена геолокация — тоже пока не кэшируем. Так проще пока что.
Если за время пребывания страницы в кэше у нее протухли куки, считаем, что у вас истекла какая-то авторизация. Возможно, это был интернет-банкинг или еще что-нибудь. Значит, страница больше не валидна — мы ее вычищаем из кэша.

Ссылка со слайда
Ребята из Google пошли еще дальше. Они предложили все объединить формализовать, унифицировать во всех браузерах, предложили спецификацию page lifecycle по всем стейтам, предложили добавить новых событий на переходы между разными стейтами. Вы можете посмотреть по ссылке, что они там придумали.

Ссылка со слайда
Исходники. Как вы знаете, исходники Chromium тоже доступны. Все это лежит в классе, который называется BackForwardCacheImpl — очень хороший нейминг, почти не пришлось искать. Главный метод, который проверяет, может ли документ сохраниться, называется CanStoreDocument(). Там же есть метод GetDisallowedFeatures(), в котором просто перечислены все новые фичи и API, которые не поддерживаются в bfcache. Очень удобно: в одном месте сосредоточено, прочитал и понял, что на текущий момент можно, а что нельзя использовать.
Экскурс в историю для тех, у кого все еще есть IE 11. Для тех, у кого все плохо.

Там bfcache есть, и это главная проблема, потому что приходится с этим бороться. В документации написано, что bfcache якобы работает только по HTTP. На самом деле в продакшене он еще и по HTTPS почему-то работает. Мораль: если вы разработчики, пожалуйста, уделяйте внимание своей документации. Потом приходится из-за нее страдать.
Если есть обработчик beforeunload, то он помешает попаданию в кэш. Про unload они в документации ничего не сказали — возможно, не знали или забыли про него.
Если не завершилась загрузка страницы, она тоже не кэшируется. Если кто-то использовал ActiveX-компоненты, тоже не кэшируем. И если там открыты DevTools — тоже. Это важный момент.

Как без багов? Добавили поле persisted, но оно иногда не срабатывает. То есть страница реально попадает в кэш, возвращается из него, и при этом persisted не выставлено в true. Что делать?
У нас был красивый код, который определяет, вернулись ли мы из кэша или заново загрузились с сервера.

Теперь его пришлось дополнить костыликом для IE. Мы определяем, что у нас IE, и какими-то обходными путями понимаем — страница все-таки была извлечена из кэша и в то же время у нас была навигация по истории (back_forward).

При этом как узнать, что страница из кэша? Мы считаем время ее загрузки. Если она загрузилась с сервера за 50 миллисекунд или быстрее, то такого в принципе не может быть в IE — значит, она из кэша! :)

Про навигацию по истории я уже упоминал. Если у нас тип навигации back_forward, то мы перешли по истории, и если страница из кэша — значит, это bfcache, других вариантов в IE не дано.
Что же дальше делать с этими знаниями? Не хотелось бы, чтобы вы вышли и все это забыли как страшный сон.
— Во-первых, вот самое ценное, на что я натолкнулся и к чему хочу вас подтолкнуть: пользуйтесь открытыми исходниками браузеров! В открытом доступе в интернете прямо сейчас лежат исходники всех ведущих браузеров, которыми пользуются наши клиенты. И это самая актуальная документация по тому, что и как поддержано, где и как работает. В том числе там есть тесты, которые прямо написаны на HTML и JS. Пользуйтесь, смотрите!
— Во-вторых, учтите в уже существующих приложениях, что они могут наталкиваться на bfcache. Расскажите об этом вашим тестировщикам, чтобы они, проверяя навигацию, знали — страница может при переходе по истории открываться как с сервера, так и из bfcache. Вот видео реального бага, который мы починили, когда у нас заработал bfcache:
Пользователь вводит четыре запроса, видит четыре выдачи. После этого возвращается назад, видит выдачу 3 и запрос 4. Еще одна предыдущая выдача — 2 и запрос 3. То есть у него состояние страницы рассогласовано — содержимое строки поиска и выдачи противоречат друг другу. Учитывайте это у себя в приложениях.
— И в-третьих, если вы пишете новый код, подумайте, нужен ли вам bfcache. Если да — пользуйтесь таблицей совместимости API. Если нет — не пользуйтесь, но при случайном попадании в bfcache учитывайте упомянутые мной особенности Safari и других браузеров. Некоторые вещи могут внаглую рваться, и вы не сможете понять, почему так происходит.
Как и обещал, ссылка на материалы.
— Здравствуйте, меня зовут Виктор. Я работаю в составе довольно большой команды, которая занимается страницей поиска.
Как минимум, такую же или аналогичную страницу в Google вы уже видели. И в частности, я занимаюсь проблемой скорости загрузки этой страницы — чтобы она максимально быстро рендерилась на сервере и максимально быстро скачивалась и показывалась клиентам. Почему это важно? Чем меньше ожидания у клиента, пока загрузится ваша страница, тем меньше шансов, что он не дождется и уйдет от вас. И тем больше шансов, что будет успешная конверсия клиента во что-то еще, тем больше будет net promotion score. То есть клиент будет радостно рассказывать всем знакомым, что здесь офигенно классная страница — очень быстро грузится, очень удобно пользоваться. И в конечном счете, тем больше денег вы сможете заработать. Или ваша компания, тогда она выдаст вам премию.
Приведу ряд примеров от известных компаний. Google провел эксперимент. Они специально встроили задержку на странице поиска и измерили, как это влияет на характеристики. Оказалось, что в среднем стало на полпроцента меньше поисков на одного пользователя. Что такое полпроцента? Посчитайте: полпроцента от сотен миллионов пользователей Google — это довольно большое число.
Bing провел такой же эксперимент. Они не верили Google, решили перепроверить. У них получились аналогичные результаты: заметно меньше доходов на пользователя при замедлении страницы. Почему замедление? Потому что легче замедлить страницу на точное число миллисекунд, чтобы это легко воспроизводилось в продакшене, чем ускорить ее на столько же.
Пример от AliExpress. Они ускорили свой сайт на 36% и получили заметно больше заказов от пользователей. Заказы — это прямые деньги. В общем, всем уже понятно, что скорость довольно важна, влияет через какое-то количество метрик на зарабатываемые деньги.
И еще один фактор. Сегодня уже говорили про оптимизацию картинок. Оптимизируя свой трафик, уменьшая количество загрузок, вы платите меньше денег вашим хостерам за исходящий трафик. Это тоже деньги, которые останутся у вас в кармане. Что если я внезапно предложу вам скидку 10% на трафик у любого хостера без ограничений и условий? А если я предложу сделать так, чтобы доля ваших страниц — например, десять процентов — грузилась у пользователя практически мгновенно? Никто не откажется.
Технология, о которой я попытаюсь рассказать сегодня, — одно из возможных решений, которое налагает мало ограничений на то, в каком стеке вы работаете, с какими технологиями, но при этом обещает дать вам вот такие довольно значимые выигрыши.
Начнем с того, что Google в своих браузерах собирает статистику о том, как эти браузеры используются. И они опубликовали такое число: оказывается, в среднем из всех открытий страниц, из всех навигаций в мобильном Chrome примерно 19% — это перемещение по истории вперед-назад. Подумайте, что это значит? Если округлить, получится, что 20% навигаций — это перемещение на страницу, где пользователь только что был.
Для нас как для авторов страниц это означает: даже если пользователь с нее ушел, есть немалый шанс, что он вот-вот вернется обратно. С одной стороны, это может быть именно проблемой мобилок: там все маленькое, легко промахнуться пальцем, нажать на ссылку и уйти со страницы, потом сказать: «А, черт! Я хочу вернуться». Но на десктопах примерно такая же картина: там число меньше, но все равно есть значительный процент возвратов.
Что мы в это время делаем? Бездарно тратим время пользователя и трафик. То есть мы начинаем обратно перезагружать ту же самую страничку, парсить ее, пересоздавать DOM, перерисовывать все на экране, загружать, выполнять JavaScript.
Браузер — довольно мощная штука. Он пытается использовать кэши везде, где только можно. И большая часть ресурсов, возможно, окажется у него в кэше. Он не будет ждать их из сети, а поднимет прямо из кэша. Например, в движке V8 результат парсинга JavaScript тоже кэшируется. То есть браузер не будет повторно загружать и парсить JS, а в большинстве случаев примется сразу его выполнять. Но все равно пересоздание DOM, перезагрузка не кэшированных ресурсов и выполнение JS занимают заметное время.
Решение напрашивается само собой. Что мы делаем? Мы, когда пользователь выходит с нашей страницы, не вычищаем ее сразу же. Мы просто сохраняем ее состояние и визуально прячем ее от пользователя, чтобы под капотом она оставалась в распоряжении браузера.
Что мы сделаем, если пользователь решит вернуться? Просто покажем ему ту же самую сохраненную страницу. Ее можно показать практически мгновенно.
Эта технология называется back/forward cache, от слов «вперед-назад». Сокращенно — bfcache.
Вот пример того, как один и тот же браузер, одна и та же сборка, ведет себя при выключенном и при включенном bfcache. Первое открытие страницы происходит одинаково медленно и там, и там. Но дальше, когда мы начинаем перемещаться по истории вперед-назад, слева заметна пауза, а справа ее нет. Слева обычное перемещение по истории, занимает заметное время. Справа все происходит очень-очень быстро.
Показать гифку

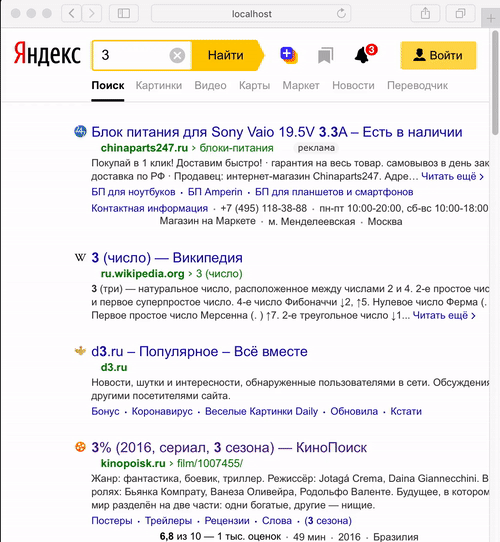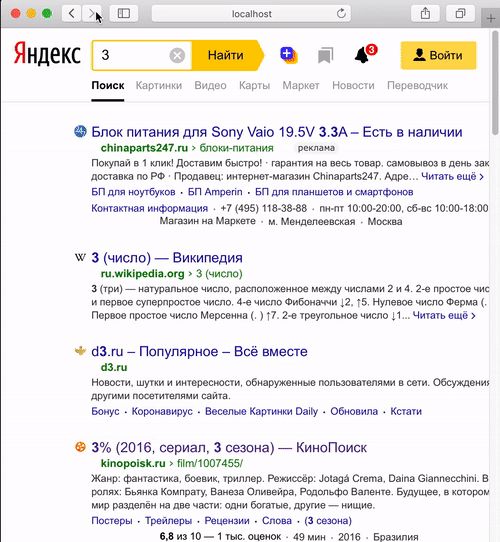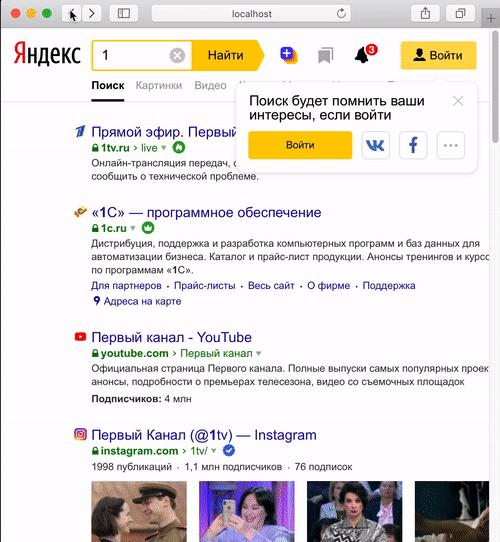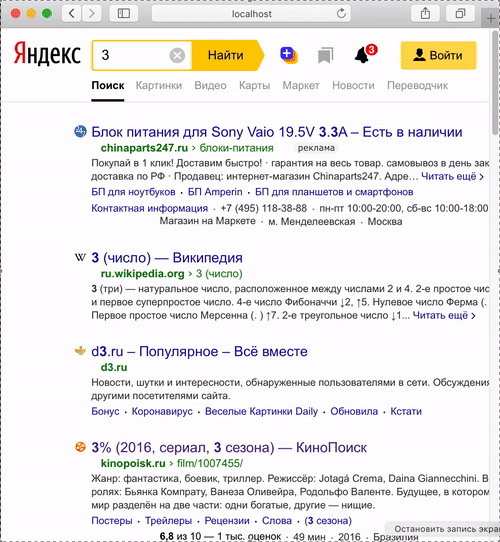
Аналогичный пример из нашего поиска. Слева обычный Safari на macOS при отключенном bfcache, справа тот же самый Safari с настройками «по умолчанию» и включенным bfcache. Это довольно частый случай: человек приходит на поиск, может точно не знать, чего он ищет, может задать несколько вариантов запроса. Первый запрос задал — что-то не то. Второй запрос — кажется, лучше. Третий — нет, хуже, возвращаемся назад к предыдущему запросу. И вот в этот момент очень хорошо бы не заставлять его ждать. Он только что видел этот предыдущий запрос, покажите его сразу же.
Или второй вариант, если у вас есть пагинация и несколько страниц на выдаче. Человек листает выдачу. Перешел на вторую, третью, четвертую страницу, посмотрел — нет, там что-то не то, вернусь обратно. И мы, опять же, можем ему показать предыдущие страницы практически мгновенно.
Важный вопрос — безопасность. Пока страница, на которой был пользователь, не находилась в скрытом состоянии, она могла получить доступ к разным API, которые позволяют считывать состояние железа вашего телефона или компьютера. Вот кратенький список того, что сразу пришло в голову: геолокация, изменение положения вашего устройства в пространстве, доступ к камере, к звуку с микрофона.
Потом, когда страница покажется, важно, чтобы она не получила доступа ко всем событиям, которые произошли за время, пока она была спрятана. Иначе откроется дополнительный канал для шпионажа за пользователями. Важно, чтобы она не получила историю ваших перемещений за все это время и записи микрофона и камеры. Об этом разработчики браузеров тоже не должны забывать.
API и поддержка браузерами
Ближе к теме. Допустим, я вас уже уговорил, вы такие: «Да, хорошая тема, надо с этим работать». Какие API у нас есть в распоряжении, с чем мы можем работать, если мы согласились принять bfcache во внимание, и как это все поддерживается браузерами?
Где bfcache уже есть, где это можно посмотреть?
— Он давно реализован в браузерах Firefox, Safari (и macOS, и iOS), а также в Internet Explorer 11 (!). Обычно мы ругаем разработчиков Microsoft, но здесь они как раз постарались.
— Он реализован в браузере UC Browser 11/12, версия под Android.
— Внезапно его нет в Chrome. А в Chromium эта фича находится в стадии разработки.
Значит, когда они это сделают в Chromium, примерно все эти браузеры (и это далеко не полный список) рано или поздно получат эту функциональность — даром, без смс и регистрации.
Есть ли какой-то API? Я хочу управлять bfcache, хочу включать и выключать его прямо из JavaScript, узнавать, есть ли в bfcache какая-то страница или нет. Как насчет такого API? Такой API отсутствует. И это сделано сознательно: страница вообще не должна хотеть включать-выключать bfcache для всех и для себя. Или узнавать, есть ли кто-нибудь в этом bfcache или нет. Это все из-за секьюрности.
Ссылка со слайда
Но что у нас есть? Типы навигации. Есть тип link — link prerender, когда мы хотим заранее отрендерить страницу. Для него есть специальный тип навигации: эта страница будет открыта с NavigationType “prerender”. Если мы просто открываем страницу в браузере, то там будет “navigate”. Если жмем на кнопку «Обновить» — будет “reload”.
Нас здесь интересует тип навигации “back_forward”, это явно говорит о том, что пользователь перемещался по истории вперед-назад. Это именно тот тип навигации, при котором может сработать наш bfcache.
Еще один API — это события pageshow pagehide. Они уже и так существовали в браузерах. Соответственно, pageshow срабатывает, когда ваша страница показывается в браузере пользователю, pagehide — когда страница скрывается по какой-либо причине. И они были дополнены полем persisted. Если страница скрывается и при этом будет помещена в bfcache, то в поле persisted будет true. Если страница показывается при поднятии ее из bfcache, то в поле persisted опять же будет true.
Соответственно, если браузер не собирается кэшировать страницу, то на pagehide будет persisted false. И если браузер показывает страницу при обычной загрузке, или он не использует bfcache, то при pageshow будет тоже persisted false.
Ссылка со слайда
Поддержка события есть практически во всех браузерах, даже в тех, которые пока не поддерживают bfcache.
Ссылка со слайда
То же самое касается поля persisted. Оно уже есть в Chrome, при этом Chrome все еще не поддерживает bfcache. То есть в нем это поле всегда будет, но пока оно будет false.
Когда я столкнулся с этим явлением, bfcache, мне пришлось изучать его, обстукивать со всех сторон, смотреть, как оно работает. Я сразу захотел увидеть у себя на странице при открытии, чему равно значение поля persisted в моих обработчиках.
Казалось бы, все довольно просто. Я написал обработчик и вывел в console.log() то, что мне приходит. Но при открытии DevTools в некоторых браузерах bfcache может внезапно отключиться. То есть я открыл DevTools, хожу по страницам вперед-назад, и у меня persisted всегда false, страница в bfcache не попадает. Окей, у меня есть еще одно мощное средство — alert.
Но нет. Современные браузеры при выгрузке страницы в обработчиках pagehide, beforeunload и unload просто игнорируют alert, он там просто не работает. И я опять не вижу того, чего хочу.
Окей, у меня есть еще более убойное средство. Я в какой-то блок прямо на своей же странице, которую исследую, просто добавляю текстом содержимое моего события и тем самым все логирую. Такой способ сработал.
Все, пожалуйста, можно пользоваться. Я свой код отладил, он у меня работает, я могу с ним дальше продолжать. Конечно, я не забываю, что все-таки лучше подходит внешний статический скрипт, чтобы не грузить на странице в заинлайненном коде все то же самое, а использовать кэширование файлов.
Я вынес во внешний скрипт этот отлаженный код.
Но нет, обработчики pageshow pagehide отвалились в Safari! Из внешнего скрипта они почему-то не работают.
Окей, у меня уже есть рабочий вариант. Мне пришлось оставить его в таком виде.
Вкратце перечислю, на что я успел наступить буквально за один день. Во-первых, DevTools могут отключать кэширование. Вы, наверное, помните, что в DevTools на вкладке Network в Chrome есть галочка «Отключать кэш». Она отключает сетевой кэш, на bfcache она может не влиять, а может и влиять. Аналогия понятна: открыли DevTools — значит, мы разрабатываемся и кэширование нам может быть не нужно. Может, оно нам мешает.
Вторая особенность — alert. Firefox и Safari молча его проигнорируют и продолжат дальше выполнять обработчики, как будто там не было никакого alert. И только один старый-добрый Chrome в консоли напишет красным цветом ошибку — у вас alert, я его заблокировал, знайте об этом!
Еще раз напоминаю, что обработчики из внешнего скрипта в Safari могут не вызываться, это очень странно.
И еще одна важная новость. Если ваша страница ушла в кэш, то есть вы получили событие pagehide, и в нем написано persisted true, а браузер вам говорит: «Да, я положил ее в кэш», — это не дает никаких гарантий, что страница когда-либо потом будет из этого кэша поднята и показана обратно пользователю. Потому что браузер может решить почистить этот кэш, если ему не хватает памяти. Потому что пользователь может закрыть браузер и не навигироваться никуда. Запомните это.
Особенности реализации
Я стал дальше копаться в документации, исследовать, как мне с этим знанием жить. На удивление, документация была. То есть можно нарыть в интернетах описание, как работает bfcache в браузерах. Но, чем дальше я читал, тем больше накапливалось различий между разными браузерами.
В одном одно работает так, в другом так. В одном одно мешает, другое не мешает. Разработчики не знают, как корректно обработать целый ряд API при помещении страницы в bfcache. Они говорят: окей, если страница использует этот API, то я просто ее игнорирую, не помещаю в кэш никогда ни при каких условиях. И этот список разный в разных браузерах, каждый делает так, как ему удобно.
И тогда я начал сводить то, что я узнавал, в одну таблицу. У меня получилось примерно следующее:
Я читал документацию по браузерам — по Firefox, Safari, семейству Chromium. По IE была доступная документация, хотя и устаревшая. Мы же, программисты, не любим обновлять документацию после изменений в браузере? Когда я понял, что информация устарела, то начал тестировать в браузерах свои маленькие странички и проверять, какое API работает, а какое нет.
Этого тоже оказалось недостаточно: я же не знаю, какие API смотреть в принципе, не перебирать же вообще все-все подряд? И мне пришлось заглянуть в исходные коды самих движков браузеров, то есть код оказался самым точным и достоверным источником знаний. На текущий момент эта табличка (перед вами ее кусочек, вот ссылка на полную версию) — самое полное собрание знаний о том, какие API разрешают или запрещают работу bfcache в браузерах.
Галочкой и зеленым цветом помечены те API, которые не мешают, красным — те, которые однозначно будут мешать попаданию страницы в bfcache. Белые поля — пробелы, которые нигде не описаны.
Firefox
Вот интересные детали из конкретных браузеров. Начну с Firefox, он первый это все сделал.
Ссылка со слайда
Самое главное, что я узнал из исходников Firefox, — это то, что он при работе с bfcache может писать в текстовый лог на диске все причины, по которым он не может поместить страницу в кэш.
Ссылка со слайда
И мне даже удалось узнать, как его заставить это сделать. Есть две секретных переменных окружения: в одной мы указываем, что логировать, во второй — в какой файл писать лог. После этого мы запускаем бинарник, и вуаля! Мы увидим примерно то, что на предыдущем слайде, строчки вида «такой html не может быть закэширован по такой причине, такой — по другой причине». Мы это cможем сразу прочитать, очень удобно.
Если вы хотите один раз поэкспериментировать, можно в Firefox открыть страницу about:networking. Там в разделе «Журнал» можно ввести эти же самые поля. Мы можем указать в двух полях, что и куда логировать, и кнопочками начинать и останавливать журнал.
Ссылка со слайда
Когда Firefox отказывается от кэширования страницы? Если у вас есть незавершенные запросы, в том числе AJAX-запросы или запросы за ресурсами типа картинок, то он откажется помещать страницу в bfcache. Он считает, что она не завершена, не закончила загрузку, там есть какая-то подозрительная активность. Но все это не распространяется на favicon. Если вы забыли favicon, если она не грузится, он считает — окей, пойдет, для вашего сайта это нормально.
Если у вас есть долго выполняющийся скрипт, браузер спросит: раз он занимает время, блокирует UI, может, его прибить? И если вы согласились, то такая страница считается битой, неправильной, и мы ее не кэшируем.
Если вы используете IndexedDB… Это поучительная история. Раньше, в первой реализации, они смотрели: если у вас IndexedDB и есть незавершенная транзакция, то такая страница не кэшируется, потому что непонятно, как с ней работать (мы прямо в середине транзакции пытаемся ее спрятать). Но потом они в ходе рефакторинга этот кусок кода просто потеряли. И как вы догадываетесь, тестов на это у них не было. У них в багтрекере даже есть баг. Ему уже два с чем-то года. Люди написали: «У меня bfcache с IndexedDB работает некорректно, что делать?» Разработчики Firefox ответили — действительно ломается, мы этот кусок текста при рефакторинге просто потеряли, окей, пусть так будет и дальше. Мораль: пишите тесты, даже если вы пишете Firefox, иначе все может закончиться печально.
И еще один интересный фактор непопадания в bfcache — если явно разрешен mixed content. Что это такое?
Ссылка со слайда
Предположим, ваша страница открывается через HTTPS, но некоторые ресурсы вы все еще грузите через HTTP, особенно скрипты. То есть у вас несекьюрный скрипт, он может модифицироваться кем угодно.
Ссылка со слайда
По умолчанию Firefox, как и другие браузеры, такой несекьюрный скрипт сейчас не выполняет. Но если вам очень важно, вы залезли в настройки и разрешили его выполнять, то он, соответственно, такую страницу кэшировать не будет. Он скажет — хорошо, ты меня уломал выполнить код, но дальше ни-ни!
Еще одна настройка — это размер самого bfcache. Здесь по умолчанию стоит минус один. Значит, сколько памяти хватает Firefox, столько страниц он и пытается закэшировать. Но мы можем принудительно отключить кэш, проставив ноль, или явно задать число — допустим, запоминай не более пяти страниц.
Предупреждение: следующий слайд содержит пример кода на страшном языке C++, на фронтенд-конференции это может быть опасным. Не пытайтесь это копировать, выполнять в консоли браузера. У вас может отформатироваться диск, взорваться экран, или начнут майниться биткоины. Я вас предупредил.
Ссылка со слайда
Итак, код Gecko. Его можно открыть, прочитать, посмотреть бесплатно в интернете. И я покопался. Там есть самый главный метод — CanSavePresentation(), он отвечает на вопрос: можно ли кэшировать данный документ? То есть это конечный источник правды о том, что прямо сейчас реализовано в Firefox. И еще — именно оттуда я узнал о том, что можно прочитать лог. Есть такая переменная — gPageCacheLog. Это и есть тот лог, в который все пишется. Вот такая интересная история про экскурс в C++.
То есть вы открываете ссылку, смотрите код, ищете (там удобный и притом быстрый поиск) и можете узнавать актуальные детали реализации в последней версии браузера — такие, которые в документации просто отсутствуют.
Safari
Самое жестокое, что делает Safari при попадании страницы в bfcache: если у вас есть незавершенные AJAX-запросы, Safari их просто убивает.
Даже если вы обложили их обработками ошибок и пытаетесь все проверять, исправлять — запроса как будто вообще не было в принципе. После восстановления из bfcache у вас не будет ни ошибки, ни «OK», вообще ничего.
Обработчики pageshow pagehide, как я уже говорил, в Safari вызываются, только если они написаны в скрипте, который заинлайнен в страницу. Из внешнего скрипта они могут работать или не работать — как повезет. Но я вас предупредил.
Еще одно интересное отличие: обработчики beforeunload и unload не мешают попаданию страницы в bfcache. При этом beforeunload вызывается всегда, и при попадании в кэш, и при не попадании. А вот unload при попадании страницы в кэш не вызывается. И здесь еще одни грабли расположены: страница может попасть в кэш и из него не показаться уже никогда, и если вы написали в unload какой-то важный код, он может в принципе никогда не вызваться, хотя на странице не произошло ни одной ошибки. То есть она корректно ушла в кэш, а из него в никуда, и вашего unload никогда не будет вызвано.
Еще один интересный момент. Как вы знаете, можно через window.open() открывать несколько окон. И при этом у этих окон друг на друга остаются ссылки. То есть они могут синхронно лазить в window друг друга, читать/писать разные свойства. Такое открытие дочерних окон не мешает bfcache. И здесь, скорее всего, Safari так же жестоко поступает, как и с AJAX-запросами, то есть все по-жесткому рвет, и до свидания. Разработчики Apple любят пожестче.
Снова минутка C++! Исходники WebKit тоже не секретны, их тоже можно открывать, читать и изучать.
Ссылка со слайда
Они лежат на GitHub, там я выделил две важных функции:
— canCacheFrame() — проверка, можно ли кэшировать данный фрейм.
— В разных объектах на странице, типа HTML-элемента или шрифта, есть методы canSuspendForDocumentSuspension(). Этот объект отвечает за то, может ли он закэшироваться, заморозиться, или не может.
И еще один важный аспект: у WebKit есть очень удобные тесты. Там прямо в папке LayoutTests/fast/history в виде маленьких, компактных, лаконичных html лежат тесты на работу разных API, которые реализованы в Safari с bfcache. Это живой пример того, как можно писать код в Safari с этими API и как они влияют или не влияют, разрешают попадание в bfcache или не разрешают. Очень интересно посмотреть.
Оттуда же я узнал, что Safari тоже пишет все свое знание о bfcache, все особенности, в текстовый лог. Но, к сожалению, я так и не раскопал, как включить это логирование или, если оно включено, где найти этот файл на диске. Если кто-то знает, скажите мне, я буду очень благодарен.
Chromium.
Как я уже говорил, там работа пока в процессе, все закрыто под флагом. Вы можете загрузить свеженький Chrome Canary, зайти во флаги. Там спрятана настроечка — можно попробовать ей поиграться. Возможно, вы что-то увидите.
Из интересного — я уже говорил про открытие страницы через window.open(). В Chromium пока что такие страницы не кэшируются. Они не придумали, как корректно все это разрулить, а бессовестно все обрывать, как в Safari, им совесть не позволяет.
Если не наступил DOMContentLoaded, то страница тоже не будет кэшироваться.
Есть много новых API, которые начинаются с «Web» — с ними тоже пока сложно и непонятно, и пока что все они по умолчанию выключают bfcache. То есть если на странице используется что-то модное, новое, типа WebGL, WebVR, WebUSB, WebBluetooth и прочее, — в bfcache такая страница не попадет.
Service Worker. Тоже пока что не кэшируем такую страницу, но планируем ее корректно обрабатывать, прятать от зорких глаз Service Worker.
Если разрешена геолокация — тоже пока не кэшируем. Так проще пока что.
Если за время пребывания страницы в кэше у нее протухли куки, считаем, что у вас истекла какая-то авторизация. Возможно, это был интернет-банкинг или еще что-нибудь. Значит, страница больше не валидна — мы ее вычищаем из кэша.
Ссылка со слайда
Ребята из Google пошли еще дальше. Они предложили все объединить формализовать, унифицировать во всех браузерах, предложили спецификацию page lifecycle по всем стейтам, предложили добавить новых событий на переходы между разными стейтами. Вы можете посмотреть по ссылке, что они там придумали.
Ссылка со слайда
Исходники. Как вы знаете, исходники Chromium тоже доступны. Все это лежит в классе, который называется BackForwardCacheImpl — очень хороший нейминг, почти не пришлось искать. Главный метод, который проверяет, может ли документ сохраниться, называется CanStoreDocument(). Там же есть метод GetDisallowedFeatures(), в котором просто перечислены все новые фичи и API, которые не поддерживаются в bfcache. Очень удобно: в одном месте сосредоточено, прочитал и понял, что на текущий момент можно, а что нельзя использовать.
Internet Explorer 11
Экскурс в историю для тех, у кого все еще есть IE 11. Для тех, у кого все плохо.
Там bfcache есть, и это главная проблема, потому что приходится с этим бороться. В документации написано, что bfcache якобы работает только по HTTP. На самом деле в продакшене он еще и по HTTPS почему-то работает. Мораль: если вы разработчики, пожалуйста, уделяйте внимание своей документации. Потом приходится из-за нее страдать.
Если есть обработчик beforeunload, то он помешает попаданию в кэш. Про unload они в документации ничего не сказали — возможно, не знали или забыли про него.
Если не завершилась загрузка страницы, она тоже не кэшируется. Если кто-то использовал ActiveX-компоненты, тоже не кэшируем. И если там открыты DevTools — тоже. Это важный момент.
Как без багов? Добавили поле persisted, но оно иногда не срабатывает. То есть страница реально попадает в кэш, возвращается из него, и при этом persisted не выставлено в true. Что делать?
У нас был красивый код, который определяет, вернулись ли мы из кэша или заново загрузились с сервера.
Теперь его пришлось дополнить костыликом для IE. Мы определяем, что у нас IE, и какими-то обходными путями понимаем — страница все-таки была извлечена из кэша и в то же время у нас была навигация по истории (back_forward).
При этом как узнать, что страница из кэша? Мы считаем время ее загрузки. Если она загрузилась с сервера за 50 миллисекунд или быстрее, то такого в принципе не может быть в IE — значит, она из кэша! :)
Про навигацию по истории я уже упоминал. Если у нас тип навигации back_forward, то мы перешли по истории, и если страница из кэша — значит, это bfcache, других вариантов в IE не дано.
Что дальше?
Что же дальше делать с этими знаниями? Не хотелось бы, чтобы вы вышли и все это забыли как страшный сон.
— Во-первых, вот самое ценное, на что я натолкнулся и к чему хочу вас подтолкнуть: пользуйтесь открытыми исходниками браузеров! В открытом доступе в интернете прямо сейчас лежат исходники всех ведущих браузеров, которыми пользуются наши клиенты. И это самая актуальная документация по тому, что и как поддержано, где и как работает. В том числе там есть тесты, которые прямо написаны на HTML и JS. Пользуйтесь, смотрите!
— Во-вторых, учтите в уже существующих приложениях, что они могут наталкиваться на bfcache. Расскажите об этом вашим тестировщикам, чтобы они, проверяя навигацию, знали — страница может при переходе по истории открываться как с сервера, так и из bfcache. Вот видео реального бага, который мы починили, когда у нас заработал bfcache:
Открыть гифку

Пользователь вводит четыре запроса, видит четыре выдачи. После этого возвращается назад, видит выдачу 3 и запрос 4. Еще одна предыдущая выдача — 2 и запрос 3. То есть у него состояние страницы рассогласовано — содержимое строки поиска и выдачи противоречат друг другу. Учитывайте это у себя в приложениях.
— И в-третьих, если вы пишете новый код, подумайте, нужен ли вам bfcache. Если да — пользуйтесь таблицей совместимости API. Если нет — не пользуйтесь, но при случайном попадании в bfcache учитывайте упомянутые мной особенности Safari и других браузеров. Некоторые вещи могут внаглую рваться, и вы не сможете понять, почему так происходит.
Как и обещал, ссылка на материалы.
