Прелюдия
Это вторая из четырех статей в серии, которая даст представление о механике и дизайне указателей, стеков, куч, escape analysis и семантики значения/указателя в Go. Этот пост посвящен кучам и escape analysis.
Оглавление цикла статей:
- Language Mechanics On Stacks And Pointers (перевод)
- Language Mechanics On Escape Analysis
- Language Mechanics On Memory Profiling (перевод)
- Design Philosophy On Data And Semantics
Вступление
В первом посте из этой серии я рассказал основы механики указателя на примере, в котором значение распределяется по стеку между горутинами. Я не показывал вам, что происходит, когда вы разделяете значение в стеке. Чтобы понять это, вам нужно узнать о другой области памяти, где могут находиться значения: о «куче». С этим знанием вы можете начать изучать «escape analysis».
Escape analysis — это процесс, который компилятор использует для определения размещения значений, созданных вашей программой. В частности, компилятор выполняет статический анализ кода, чтобы определить, может ли значение быть помещено в стековый фрейм для функции, которая его строит, или значение должно «сбежать» в кучу. В Go нет ни одного ключевого слова или функции, которую вы могли бы использовать, чтобы указать компилятору какое решение ему принять. Только то, как вы пишете свой код, условно позволяет повлиять на это решение.
Кучи
Куча — это вторая область памяти, помимо стека, используемая для хранения значений. Куча не самоочищается, как стеки, поэтому использование этой памяти обходится дороже. Прежде всего, затраты связаны со сборщиком мусора (GC), который должен содержать эту область в чистоте. Когда GC запускается, он будет использовать 25% доступной мощности вашего процессора. Кроме того, он может потенциально создавать микросекунды задержки «stop the world». Преимущество наличия GC заключается в том, что вам не нужно беспокоиться об управлении памятью кучи, которая исторически была сложной и подвержена ошибкам.
Значения в куче провоцируют аллокации памяти в Go. Эти аллокации оказывают давление на GC, потому что каждое значение в куче, на которое больше не ссылается указатель, должно быть удалено. Чем больше значений необходимо проверить и удалить, тем больше работы GC должен выполнять при каждом запуске. Поэтому постоянно работает алгоритм стимуляции для балансировки размера кучи и скорости выполнения.
Совместное использование стека
В языке Go ни одной горутине не разрешено иметь указатель, указывающий на память в стеке другой горутины. Это связано с тем, что память стека для горутины может быть заменена новым блоком памяти, когда стек должен увеличиваться или уменьшаться. Если бы во время выполнения пришлось отслеживать указатели на стек в другой горутине, то пришлось бы слишком многим управлять, а задержка «stop the world» при обновлении указателей на эти стеки была бы ошеломляющей.
Вот пример стека, который несколько раз заменяется из-за роста. Посмотрите на вывод в строках 2 и 6. Вы дважды увидите изменения адресов строкового значения внутри стекового фрейма main.
play.golang.org/p/pxn5u4EBSI
Механика побега
Каждый раз, когда значение разделяется вне области стекового фрейма функции, оно помещается (или аллоцируется) в кучу. Задача алгоритмов escape analysis заключается в том, чтобы находить такие ситуации и поддерживать уровень целостности в программе. Целостность заключается в обеспечении того, чтобы доступ к любому значению всегда был точным, последовательным и эффективным.
Посмотрите на этот пример, чтобы изучить основные механизмы escape analysis.
play.golang.org/p/Y_VZxYteKO
Листинг 1
01 package main 02 03 type user struct { 04 name string 05 email string 06 } 07 08 func main() { 09 u1 := createUserV1() 10 u2 := createUserV2() 11 12 println("u1", &u1, "u2", &u2) 13 } 14 15 //go:noinline 16 func createUserV1() user { 17 u := user{ 18 name: "Bill", 19 email: "bill@ardanlabs.com", 20 } 21 22 println("V1", &u) 23 return u 24 } 25 26 //go:noinline 27 func createUserV2() *user { 28 u := user{ 29 name: "Bill", 30 email: "bill@ardanlabs.com", 31 } 32 33 println("V2", &u) 34 return &u 35 }
Я использую директиву go:noinline, чтобы компилятор не вставлял код для этих функций непосредственно в main. Встраивание приведет к удалению вызовов функций и усложнит этот пример. Я расскажу о побочных эффектах встраивания в следующем посте.
В листинге 1 представлена программа с двумя разными функциями, которые создают значение типа user и возвращают его обратно вызывающей стороне. Первая версия функция использует семантику значения при возврате.
Листинг 2
16 func createUserV1() user { 17 u := user{ 18 name: "Bill", 19 email: "bill@ardanlabs.com", 20 } 21 22 println("V1", &u) 23 return u 24 }
Я сказал, что функция использует семантику значений при возврате, потому что значение типа user, созданное этой функцией, копируется и передается в стек вызовов. Это означает, что вызывающая функция получает копию самого значения.
Вы можете видеть создание значения типа user, выполняемого в строках с 17 по 20. Затем в строке 23 копия значения передается в стек вызовов и возвращается к вызывающей стороне. После возврата функции стек выглядит следующим образом.
Изображение 1
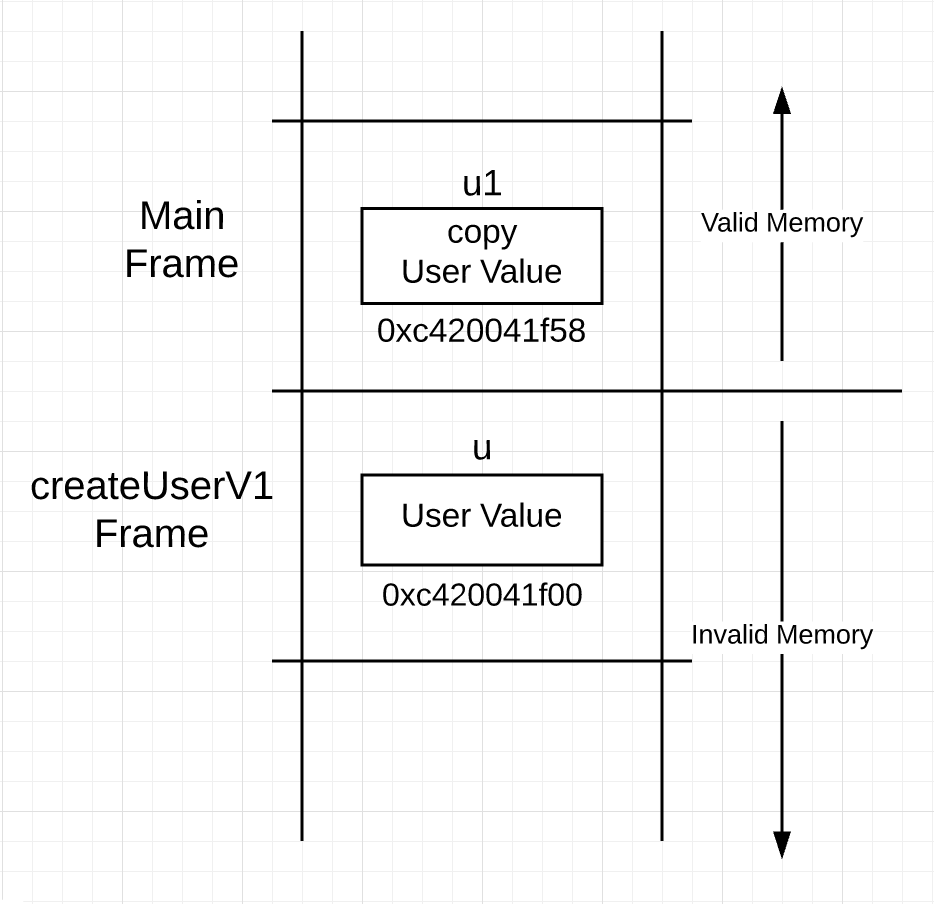
На рисунке 1 вы можете увидеть, что значение типа user существует в обоих фреймах после вызова createUserV1. Во второй версии функции для возврата используется семантика указателя.
Листинг 3
27 func createUserV2() *user { 28 u := user{ 29 name: "Bill", 30 email: "bill@ardanlabs.com", 31 } 32 33 println("V2", &u) 34 return &u 35 }
Я сказал, что функция использует семантику указателя при возврате, потому что значение типа user, созданное этой функцией, совместно используется стеком вызовов. Это означает, что вызывающая функция получает копию адреса, где находится значения.
Вы можете увидеть тот же структурный литерал, который используется в строках с 28 по 31 для создания значения типа user, но в строке 34 отличается возврат из функции. Вместо передачи копии значения обратно в стек вызовов передается копия адреса для значения. Исходя из этого, вы можете подумать, что после вызова стек выглядит так.
Изображение 2
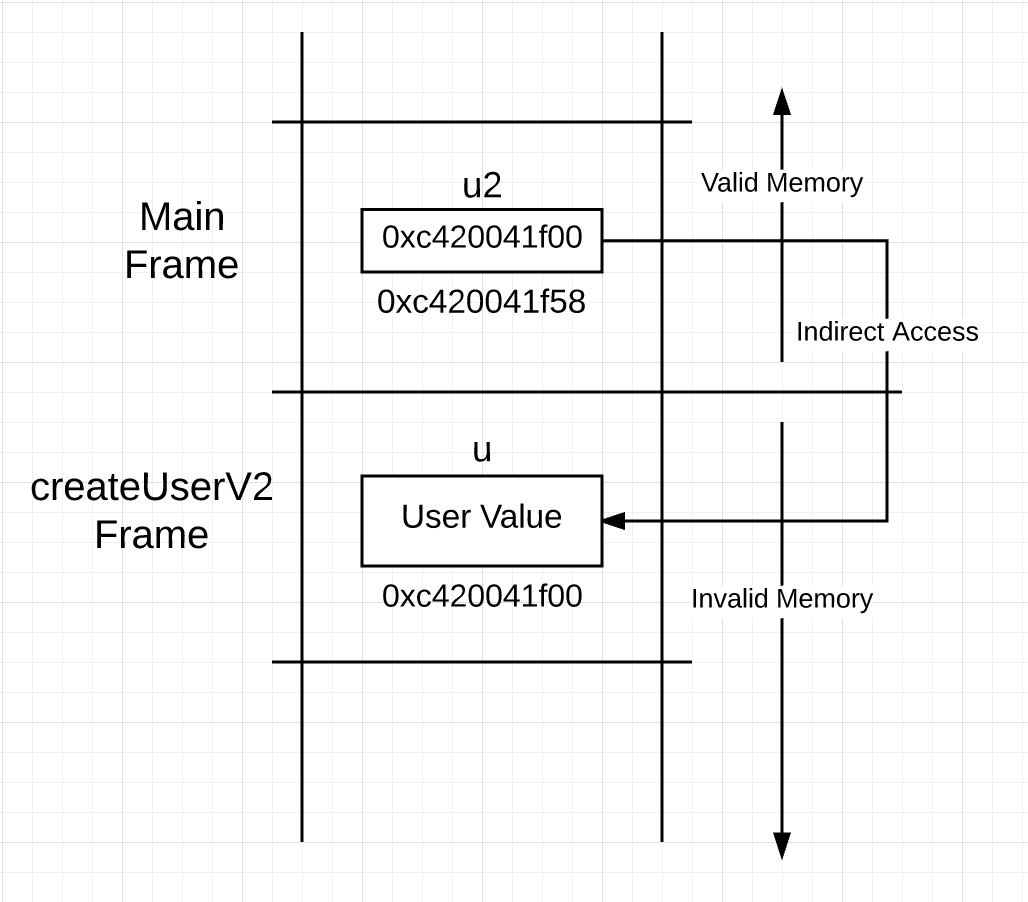
Если то, что вы видите на рисунке 2, действительно происходит, у вас возникнет проблема целостности. Указатель указывает вниз на стек вызовов в память, которая больше не действительна. При следующем вызове функции указанная память будет переформирована и повторно инициализирована.
Здесь escape analysis и начинает поддерживать целостность. В этом случае компилятор определит, что небезопасно создавать значение типа user внутри стекового фрейма createUserV2, поэтому вместо этого он создаст значение в куче. Это произойдет сразу во время конструкции в строке 28.
Читаемость
Как вы узнали из предыдущего поста, функция имеет прямой доступ к памяти внутри своего фрейма через указатель фрейма, но доступ к памяти вне фрейма требует косвенного доступа. Это означает, что доступ к значениям, которые попадают в кучу, также должен осуществляться косвенно через указатель.
Вспомните как выглядит код createUserV2.
Листинг 4
27 func createUserV2() *user { 28 u := user{ 29 name: "Bill", 30 email: "bill@ardanlabs.com", 31 } 32 33 println("V2", &u) 34 return &u 35 }
Синтаксис скрывает то, что действительно происходит в этом коде. Переменная u, объявленная в строке 28, представляет значение типа user. Конструкция в Go не сообщает вам, где именно в памяти хранится значение, поэтому до оператора return в строке 34 вы не знаете, что значение будет сбегать в кучу. Это означает, что, хотя u представляет значение типа user, доступ к этому значению должен осуществляться через указатель.
Вы можете визуализировать стек, который после вызова функции выглядит вот так.
Изображение 3
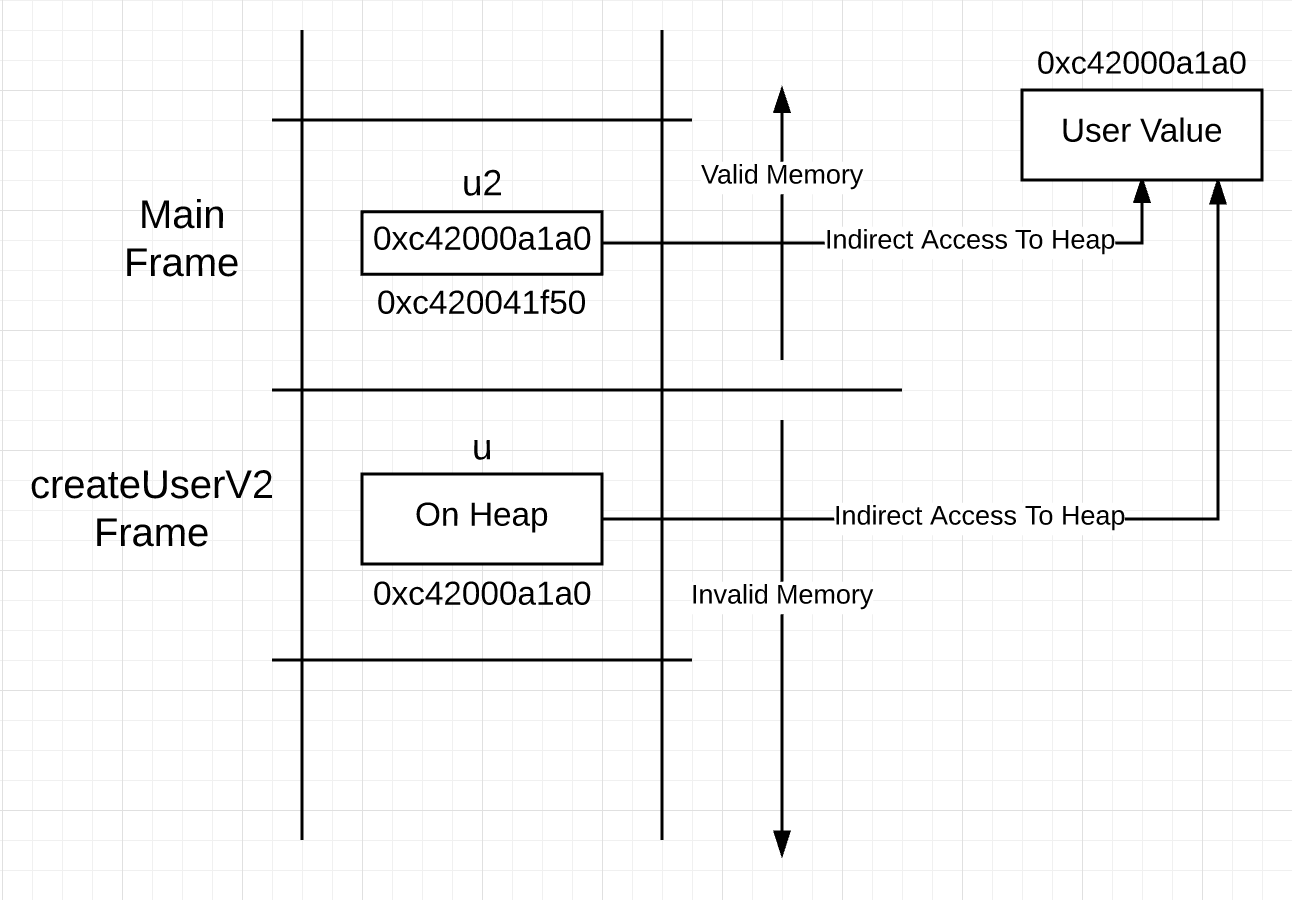
Переменная u в стековом фрейме для createUserV2 представляет значение в куче, а не в стеке. Это означает, что использование u для доступа к значению требует доступа к указателю, а не прямого доступа, предлагаемого синтаксисом. Вы можете подумать, почему бы тогда сразу не сделать указатель, поскольку доступ к значению, которое он представляет, все равно требует использования указателя?
Листинг 5
27 func createUserV2() *user { 28 u := &user{ 29 name: "Bill", 30 email: "bill@ardanlabs.com", 31 } 32 33 println("V2", u) 34 return u 35 }
Если вы так сделаете, то вы потеряете читаемость, которую могли бы в своем коде и не терять. Отойдите подальше от тела функции на секунду и просто сосредоточьтесь на return.
Листинг 6
34 return u 35 }
О чем говорит этот return? Все, что он говорит, это то, что копия u передается в стек вызовов. Тем временем, что говорит вам return, когда вы используете оператор &?
Листинг 7
34 return &u 35 }
Благодаря оператору & return теперь говорит вам, что вы совместно используете стек вызовов и, следовательно, выходите в кучу. Помните, что указатели предназначены для совместного использования и во время чтения кода заменяют оператор & на словосочетание «общий доступ». Это очень мощно с точки зрения читаемости. Это то, чего не хотелось бы потерять.
Вот еще один пример, где построение значений с использованием семантики указателей ухудшает читаемость.
Листинг 8
01 var u *user 02 err := json.Unmarshal([]byte(r), &u) 03 return u, err
Для того, чтобы этот код работал, при вызове json.Unmarshal в строке 02 вы должны передать указатель на переменную указателя. Вызов json.Unmarshal создаст значение типа user и назначит его адрес переменной указателя. play.golang.org/p/koI8EjpeIx
Что говорит этот код:
01: Создать указатель типа user с нулевым значением.
02: Поделиться переменной u с функцией json.Unmarshal.
03: Верните копию переменной u вызывающему.
Не совсем очевидно, что вызывающей стороне передается значение типа user, созданное функцией json.Unmarshal.
Как изменяется читаемость при использовании семантики значений во время объявления переменной?
Листинг 9
01 var u user 02 err := json.Unmarshal([]byte(r), &u) 03 return &u, err
Что говорит этот код:
01: Создать значение типа user с нулевым значением.
02: Поделиться переменной u с функцией json.Unmarshal.
03: Поделиться переменной u с вызывающим.
Все очень понятно. Строка 02 делит значение типа user вниз по стеку вызовов в json.Unmarshal, а строка 03 делит значение по стеку вызовов обратно к вызывающей стороне. Этот общий ресурс приведет к тому, что значение переместится в кучу.
Используйте семантику значений при создания значения и пользуйтесь преимуществом читаемости оператора &, чтобы прояснить, как разделяются значения.
Отчетность компилятора
Чтобы увидеть решения, принимаемые компилятором, вы можете попросить компилятор предоставить отчет. Все, что вам нужно сделать, это использовать ключ -gcflags с опцией -m при вызове go build.
На самом деле вы можете использовать 4 уровня -m, но после 2 уровня информации становится слишком много. Я буду использовать 2 уровня -m.
Листинг 10
$ go build -gcflags "-m -m" ./main.go:16: cannot inline createUserV1: marked go:noinline ./main.go:27: cannot inline createUserV2: marked go:noinline ./main.go:8: cannot inline main: non-leaf function ./main.go:22: createUserV1 &u does not escape ./main.go:34: &u escapes to heap ./main.go:34: from ~r0 (return) at ./main.go:34 ./main.go:31: moved to heap: u ./main.go:33: createUserV2 &u does not escape ./main.go:12: main &u1 does not escape ./main.go:12: main &u2 does not escape
Вы можете видеть, что компилятор сообщает о решениях сбросить значение в кучу. Что говорит компилятор? Сначала снова посмотрите на функции createUserV1 и createUserV2 для освежения их в памяти.
Листинг 13
16 func createUserV1() user { 17 u := user{ 18 name: "Bill", 19 email: "bill@ardanlabs.com", 20 } 21 22 println("V1", &u) 23 return u 24 } 27 func createUserV2() *user { 28 u := user{ 29 name: "Bill", 30 email: "bill@ardanlabs.com", 31 } 32 33 println("V2", &u) 34 return &u 35 }
Начнем с этой строки в отчете.
Листинг 14
./main.go:22: createUserV1 &u does not escape
Это говорит о том, что вызов функции println внутри функции createUserV1 не вызывает сброса значения типа user в кучу. Это случай нужно было проверять, потому что оно используется совместно с функцией println.
Далее посмотрите на эти строки в отчете.
Листинг 15
./main.go:34: &u escapes to heap ./main.go:34: from ~r0 (return) at ./main.go:34 ./main.go:31: moved to heap: u ./main.go:33: createUserV2 &u does not escape
Эти строки говорят, что значение типа user, связанное с переменной u, которое имеет именованный тип user и создано в строке 31, сбрасывается в кучу из-за возврата в строке 34. Последняя строка говорит то же, что и раньше, println вызов в строке 33 не вызывает сброса значения типа user.
Чтение этих отчетов может запутывать и может немного изменяться в зависимости от того, основан ли тип рассматриваемой переменной на именованном или литеральном типе.
Измените переменную u, чтобы она была литерального типа *user вместо именованного типа user, каким она был раньше.
Листинг 16
27 func createUserV2() *user { 28 u := &user{ 29 name: "Bill", 30 email: "bill@ardanlabs.com", 31 } 32 33 println("V2", u) 34 return u 35 }
Запустите отчет еще раз.
Листинг 17
./main.go:30: &user literal escapes to heap ./main.go:30: from u (assigned) at ./main.go:28 ./main.go:30: from ~r0 (return) at ./main.go:34
Теперь в отчете говорится, что значение типа user, на которое ссылается переменная u, имеющее литеральный тип *user и созданное в строке 28, сбрасывается в кучу из-за возврата в строке 34.
Заключение
Создание значения не определяет, где оно находится. Только то, как значение разделяется, будет определять, что компилятор будет делать с этим значением. Каждый раз, когда вы делитесь значением в стеке вызовов, оно сбрасывается в кучу. Существуют и другие причины, по которым значение может сбежать из стека. О них я расскажу в следующем посте.
Целью этих постов является предоставление руководства по выбору использования семантики значения или семантики указателя для любого заданного типа. Каждая семантика идет в паре с выгодой и стоимостью. Семантика значений сохраняет значения в стеке, что снижает нагрузку на GC. Тем не менее, существуют разные копии одного и того же значения, которые должны храниться, отслеживаться и поддерживаться. Семантика указателя помещает значения в кучу, что может оказать давление на GC. Однако они эффективны, потому что существует только одно значение, которое необходимо хранить, отслеживать и поддерживать. Ключевым моментом является использование каждой семантики правильно, последовательно и сбалансировано.

