Каждый год 21 апреля мы вспоминаем историю Великого падения Dodo IS в 2018 году. Прошлое – жестокий, но справедливый учитель. Стоит помнить о нём, повторять уроки, передавать новым поколениям накопленные знания и с благодарностью относиться к тому, кем мы стали. Под катом мы хотим рассказать вам историю о том, как это было и поделиться выводами. Такую ситуацию не пожелаешь даже врагу.

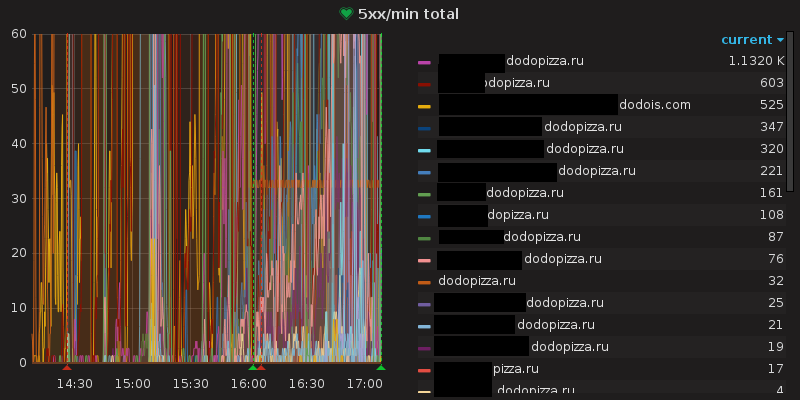
В субботу 21 апреля 2018 года система Dodo IS упала. Упала очень плохо. Несколько часов наши клиенты не могли сделать заказ ни через сайт, ни через мобильное приложение. Очередь звонков в колл-центр выросла до такого состояния, что автоматический голос автоответчика сообщал: «Мы перезвоним через 4 часа».

В тот день мы пережили одно из самых серьёзных падений Dodo IS. Самое ужасное заключалось в том, что накануне мы запустили первую федеральную рекламную кампанию на ТВ с бюджетом 100 млн. рублей. Это было грандиозное событие для Dodo Pizza. IТ-команда тоже хорошо подготовилась к кампании. Мы автоматизировали и упростили деплой – теперь с помощью одной кнопки в TeamCity мы могли развернуть монолит в 12 странах. Мы сделали не всё возможное и поэтому облажались.
Рекламная кампания была потрясающей. Мы получали 100-150 заказов в минуту. Это была хорошая новость. Плохая новость: Dodo IS не выдержала такой нагрузки и умерла. Мы достигли предела вертикального масштабирования и больше не могли обрабатывать заказы. Система была нестабильна в течение примерно трёх часов, периодически восстанавливаясь, но сразу же падала вновь. Каждая минута простоя стоила нам десятки тысяч рублей, не считая потери уважения со стороны разъярённых клиентов. Команда разработки подвела всех: клиентов, партнёров, ребят в пиццериях и колл-центре.
У нас не оставалось выбора, кроме как закатать рукава и сесть за исправление ситуации. С воскресенья (22 апреля) мы работали в жёстком режиме, у нас не было права на ошибку.
Ниже собран наш суммарный опыт о том, как оказаться в такой ситуации и как из неё потом выбираться. Друзья, не допускайте наших ошибок.
Начать стоит с того, как всё началось и где мы облажались.

В субботу 21.04.2018 примерно в 17:00 мы заметили, что начало расти количество локов в базе – предвестник проблем. У нас наготове был runbook для решения, так как мы понимали, откуда эти локи идут.
Всё пошло не так после того, как два раза runbook не сработал. На пару минут база приходила в норму, а потом снова начинала задыхаться от локов. Увы, на мастер-базе rollback_on_timeout был 600 секунд, из-за чего все локи и копились. Это первый важный фейл в этой истории. Простая настройка могла всё спасти.
Дальше были попытки вернуть систему к жизни разными способами, ни один из которых не увенчался успехом. До тех пор пока мы не поняли, что есть разница в схеме приёма заказов в мобильном приложении и на новом сайте. Вырубая их по очереди, мы смогли понять, где дыры у старой схемы приёма заказов.
Система приёма заказа была написана давно. На тот момент она уже была в переработке, и её выкатили на новом сайте dodopizza.ru. В мобильном приложении она не использовалась. Изначально причины создания новой схемы заказов были связаны с чисто бизнесовыми правилами, вопросы производительности даже не стояли на повестке дня. Это второй важный фейл — мы не знали пределов нашей системы.
Реакция команды была очень показательной. Наш СТО написал пост в Slack, и все пришли на следующий день – 22 апреля работа началась в 8:30 утра. Никого не нужно было уговаривать или просить прийти в свой выходной день. Все всё понимали: что нужно поддержать, помочь, руками, головой, в тестировании, оптимизации запросов, инфре. Кое-кто даже приехал со всей семьей! Ребята из соседних команд, не связанных с IT, приезжали в офис с едой, а колл-центр вывел дополнительные силы на всякий случай. Все команды объединились единой целью – подняться!

Новый приём заказа стал основной целью на воскресение, 22 апреля. Мы понимали, что пик заказов будет сравним с субботним. У нас был жесточайший дедлайн — в 17 часов повалит новый шквал заказов.
В этот день мы действовали по плану «сделать, чтобы не упало», который выработали накануне 21 числа поздно вечером, когда уже подняли систему и поняли, что произошло. План условно был разбит на 2 части:
Реализовав эти вещи, мы могли быть уверенными в том, что Dodo IS не упадёт.
Внедрение схемы с новым заказом в мобильное приложение было самой приоритетной задачей. У нас не было точных цифр по всей схеме, но по отдельным частям, количеству и качеству запросов к базе мы экспертно понимали, что он даст прирост в производительности. День в день над задачей работала команда из 15 человек.
Хотя по факту внедрение новой схемы заказа мы начали ещё до падения 21.04., но не довели дело до прода. Ещё оставались активные баги и задача висела в полуактивном состоянии.
Команда разделила регресс на части: регресс с двух мобильных платформ, плюс управление пиццерией. Мы много времени тратили вручную, чтобы подготовить тестовые пиццерии, но чёткое разделение помогало параллелить ручной регресс.
Как только вносилось какое-то изменение, оно тут же деплоилось на pre-production среду и моментально тестировалось. Команда всё время находилась на связи друг с другом, они реально просто сидели в большой комнате с включенным hangouts. Ребята из Нижнего Новгорода и Сыктывкара тоже всегда были на связи. Если возникал затык, он тут же решался.
Обычно мы выводим новый функционал постепенно: 1 пиццерия, 5 пиццерий, 10 пиццерий, 20 пиццерий и так на всю сеть постепенно. В тот раз нам нужно было действовать решительнее. Времени у нас не было – в 17 часов начинался новый пик. Мы просто не могли не успеть.
Примерно в 15:00 обновление было раскатано на половину сети (это около 200 пиццерий). В 15:30 мы убедились, что всё работает нормально и включили на всю сеть. Фича-тоглы, быстрые деплои, разбитый на части регресс и зафиксированный API помогли всё это сделать.
Остальная часть команды занималась разными вариантами оптимизации при создании заказа. Новая схема была не совсем новая, она таки использовала легаси часть. Сохранение адресов, применения промокодов, генерация номера заказа – эти части были и оставались общими. Их оптимизация сводилась либо к переписыванию самих SQL-запросов, либо к избавлению от них в коде, либо к оптимизации их вызовов. Что-то пошло в асинхронном режиме, что-то, как оказалось, вызывалось по несколько раз вместо одного.
Команда инфраструктуры занималась тем, что выделяла часть компонентов на отдельные инстансы просто для того, чтобы не пересекать нагрузку. Нашим основным проблемным компонентом был легаси фасад, ходивший в легаси базу. Ему и были посвящены все работы, в том числе и по разделению инстансов.
Утром мы провели единственный за день синк, разбились на команды и ушли работать.
Сначала весь лог изменений и задач мы вели прямо в Slack, потому что сначала задач было не так много. Но их количество росло, поэтому мы быстро переехали в Trello. Настроенная интеграция между Slack и Trello оповещала о любом изменении статуса в задачке.
Дополнительно нам было важно видеть весь лог изменения продакшена. Электронная версия была в Trello, дублирующая версия была на доске инфраструктуры в виде карточек. В случае, если что-то пойдёт не так, нам нужно было быстро понять, какие изменения откатить. Полноценный регресс был только для схемы с новым заказом, остальные изменения тестировались более лояльно.
Задачи вылетали на продакшн со скоростью пули. Суммарно мы обновили систему 15 раз за тот день. У ребят были развернуты тестовые стенды, по одному на команду. Разработка, быстрая проверка, деплой на продакшн.
Дополнительно к основному процессу CTO Саша Андронов постоянно бегал в команды с вопросом «Чем помочь?». Это помогало перераспределять усилия и не терять времени на то, что кто-то не подумал попросить помощи. Полуручное управление разработкой, минимум отвлечений и работа на пределе возможностей.
После того дня нужно было выйти с ощущением, что мы сделали всё, что могли. И даже больше. И мы это сделали! В 15:30 новая схема приема заказа была раскатана для мобильного приложения на всю сеть. Режим хакатона, под 20 деплоев на продакшн за день!
Вечер 22 апреля прошёл спокойно и чётко. Ни падений, ни единого намека не то, что системе может быть нехорошо.
В районе 22 часов вечера мы собрались ещё раз и набросали план действий на неделю. Лимитирование, перфоманс тесты, асинхронный заказ и много чего ещё. Это был долгий день, а впереди были долгие недели.
Неделя с 23 апреля была адская. После неё мы сказали себе, что выложились на 200% и сделали всё, что могли.
Мы должны были спасать Dodo IS и решили применить некоторую медицинскую аналогию. Вообще это первый реальный случай использования метафоры (как в оригинальном XP), который реально помогал понимать, что происходит:

Первый этап реанимации — стандартные runbook для восстановления системы в случае отказа по каким-то параметрам. Упало одно — делаем это, упало то — делаем это и так далее. В случае падения быстро находим нужный runbook, все они лежат на GitHub и структурированы по проблемам.
Второй этап реанимации — лимитирование заказов. Данную практику мы переняли у своих же пиццерий. Когда на пиццерию сваливается очень много заказов, и они понимают, что не могут быстро их приготовить, то они встают в стоп минут на 5. Просто чтобы разгрести очередь заказов. Мы сделали подобную схему для Dodo IS. Решили, что если станет совсем плохо, включим общий лимит и будет говорить клиентам, мол, ребята, 5 минут и мы примем ваш заказ. Эту меру мы разработали на всякий случай, но в итоге ни разу ей не воспользовались. Не пригодилось. И славно.
Для того, чтобы начать лечить надо поставить диагноз, поэтому мы сфокусировались на performance-тестах. Часть команды пошла собирать реальный профиль нагрузки с продакшена с помощью GoReplay, часть команды сосредоточилась на синтетических тестах на Stage.
Синтетические тесты не отражали реальный профиль нагрузки, но они дали определённую почву для улучшений, показали некоторые слабые места системы. Например, незадолго до этого мы переводили MySQL-коннектор с ораклового на новый. В версии коннектора была бага с pooling sessions, которая приводила к тому, что сервера просто уходили в потолок по CPU и переставали обслуживать запросы. Мы воспроизвели это с тестами на Stage, зачинили и спокойно вышли на продакшн. Подобных кейсов было с десяток.
По мере диагностики и выявления причин проблем, точечно их исправляли. Дополнительно понимали, что наш идеальный путь — это асинхронный приём заказа. Начали работать над тем, чтобы внедрить его в мобильном приложении.
Команда из 40 человек работала над единой большой целью — стабилизация системы. Все команды работали вместе. Не знаешь, чем заняться? Помоги другим командам. Фокус на конкретных целях помог не распыляться и не заниматься ненужной нам ерундой.

Три раза в день была синхронизация, общий стендап, как в классическом скраме. На 40 человек. Лишь дважды за три недели (за почти 90 синков) мы не уложились в 30 минут. Самый долгий синк длился 57 минут. Хотя обычно они занимали 20-30 минут.
Цель синков: понять, где нужна помощь и когда мы выведем те или иные задачи на продакшн. Ребята объединялись в проектные команды, если нужна была помощь инфраструктуры, тут же приходил человек, все вопросы решались быстро, меньше обсуждения больше дела.
По вечерам, чтобы поддержать ребят, в нашей R&D-лаборатории готовили еду для разработчиков на вечер. Пиццы по самым сумасшедшим рецептам, куриные крылья, картошка! Вот это было нереально круто! Такая поддержка мотивировала ребят максимально.

Работать в таком нон-стоп режиме было чертовски сложно. В среду 25 апреля около 5 вечера к CTO подошёл Олег Блохин, один из наших разработчиков, который фигачил с субботы без остановки. В глазах у него была нечеловеческая усталость: «Я пошёл домой, не могу уже». Выспался и на следующий день был бодрячком. Так можно описать общее состояние многих ребят.
В следующую субботу 28 апреля (это была рабочая суббота для всех в России) было поспокойней. Мы уже не могли что-то изменить, наблюдали за системой, ребята немного отдыхали от темпа. Всё прошло спокойно. Нагрузка была, не столь огромная, но была. Выдержали без проблем, и это придало уверенности в том, что мы идём правильным путем.
Вторая и третья недели после падения прошли уже в более спокойном режиме, адского темпа до позднего вечера уже не было, но общий процесс военного положения сохранился.
Следующий день X был на 9 мая! Кто-то сидел дома и мониторил состояние системы. Те из нас, кто пошёл гулять, взяли с собой ноуты, чтобы быть во всеоружии, если что-то пойдет не так. Саша Андронов, наш СТО, ближе к вечернему пику отправился в одну из пиццерий, чтобы в случае проблем, увидеть всё воочию.
В тот день мы получили 91500 заказов в России (на тот момент второй результат за историю Додо). Не было даже малейшего намека на проблемы. 9 мая подтвердило, что мы на правильном пути! Фокус на стабильности, на перфомансе, на качестве. Дальше нас ждала перестройка процесса, но это уже совсем другая история.
В критических ситуациях вырабатываются хорошие практики, которые можно и нужно переносить в спокойное время. Фокусировка, межкомандная помощь, быстрый деплой на продакшн не дожидаясь полного регресса. Мы начали с ретро и дальше вырабатывали каркас процесса.

Первые два дня прошли в обсуждении практик. Мы не ставили себе цель «уложить ретроспективу в 2 часа». После такой ситуации мы готовы были выделить время на то, чтобы детально проработать наши идеи и наш новый процесс. Участвовали все. Все, кто так или иначе был задействован во время работ по восстановлению.

Как итог, получилось 6 важных практик, о которых хочется рассказать чуть подробнее.
История Великого падения
День 1. Авария, которая стоила нам миллионы рублей
В субботу 21 апреля 2018 года система Dodo IS упала. Упала очень плохо. Несколько часов наши клиенты не могли сделать заказ ни через сайт, ни через мобильное приложение. Очередь звонков в колл-центр выросла до такого состояния, что автоматический голос автоответчика сообщал: «Мы перезвоним через 4 часа».
В тот день мы пережили одно из самых серьёзных падений Dodo IS. Самое ужасное заключалось в том, что накануне мы запустили первую федеральную рекламную кампанию на ТВ с бюджетом 100 млн. рублей. Это было грандиозное событие для Dodo Pizza. IТ-команда тоже хорошо подготовилась к кампании. Мы автоматизировали и упростили деплой – теперь с помощью одной кнопки в TeamCity мы могли развернуть монолит в 12 странах. Мы сделали не всё возможное и поэтому облажались.
Рекламная кампания была потрясающей. Мы получали 100-150 заказов в минуту. Это была хорошая новость. Плохая новость: Dodo IS не выдержала такой нагрузки и умерла. Мы достигли предела вертикального масштабирования и больше не могли обрабатывать заказы. Система была нестабильна в течение примерно трёх часов, периодически восстанавливаясь, но сразу же падала вновь. Каждая минута простоя стоила нам десятки тысяч рублей, не считая потери уважения со стороны разъярённых клиентов. Команда разработки подвела всех: клиентов, партнёров, ребят в пиццериях и колл-центре.
У нас не оставалось выбора, кроме как закатать рукава и сесть за исправление ситуации. С воскресенья (22 апреля) мы работали в жёстком режиме, у нас не было права на ошибку.
Ниже собран наш суммарный опыт о том, как оказаться в такой ситуации и как из неё потом выбираться. Друзья, не допускайте наших ошибок.
Два фейла, которые запустили эффект домино
Начать стоит с того, как всё началось и где мы облажались.
В субботу 21.04.2018 примерно в 17:00 мы заметили, что начало расти количество локов в базе – предвестник проблем. У нас наготове был runbook для решения, так как мы понимали, откуда эти локи идут.
Всё пошло не так после того, как два раза runbook не сработал. На пару минут база приходила в норму, а потом снова начинала задыхаться от локов. Увы, на мастер-базе rollback_on_timeout был 600 секунд, из-за чего все локи и копились. Это первый важный фейл в этой истории. Простая настройка могла всё спасти.
Дальше были попытки вернуть систему к жизни разными способами, ни один из которых не увенчался успехом. До тех пор пока мы не поняли, что есть разница в схеме приёма заказов в мобильном приложении и на новом сайте. Вырубая их по очереди, мы смогли понять, где дыры у старой схемы приёма заказов.
Система приёма заказа была написана давно. На тот момент она уже была в переработке, и её выкатили на новом сайте dodopizza.ru. В мобильном приложении она не использовалась. Изначально причины создания новой схемы заказов были связаны с чисто бизнесовыми правилами, вопросы производительности даже не стояли на повестке дня. Это второй важный фейл — мы не знали пределов нашей системы.
День 2. Ликвидации аварии
Реакция команды была очень показательной. Наш СТО написал пост в Slack, и все пришли на следующий день – 22 апреля работа началась в 8:30 утра. Никого не нужно было уговаривать или просить прийти в свой выходной день. Все всё понимали: что нужно поддержать, помочь, руками, головой, в тестировании, оптимизации запросов, инфре. Кое-кто даже приехал со всей семьей! Ребята из соседних команд, не связанных с IT, приезжали в офис с едой, а колл-центр вывел дополнительные силы на всякий случай. Все команды объединились единой целью – подняться!
Новый приём заказа стал основной целью на воскресение, 22 апреля. Мы понимали, что пик заказов будет сравним с субботним. У нас был жесточайший дедлайн — в 17 часов повалит новый шквал заказов.
В этот день мы действовали по плану «сделать, чтобы не упало», который выработали накануне 21 числа поздно вечером, когда уже подняли систему и поняли, что произошло. План условно был разбит на 2 части:
- Внедрение схемы с новым заказом в мобильное приложение.
- Оптимизация процесса создания заказа.
Реализовав эти вещи, мы могли быть уверенными в том, что Dodo IS не упадёт.
Определяем фронт работ и работаем
Внедрение схемы с новым заказом в мобильное приложение было самой приоритетной задачей. У нас не было точных цифр по всей схеме, но по отдельным частям, количеству и качеству запросов к базе мы экспертно понимали, что он даст прирост в производительности. День в день над задачей работала команда из 15 человек.
Хотя по факту внедрение новой схемы заказа мы начали ещё до падения 21.04., но не довели дело до прода. Ещё оставались активные баги и задача висела в полуактивном состоянии.
Команда разделила регресс на части: регресс с двух мобильных платформ, плюс управление пиццерией. Мы много времени тратили вручную, чтобы подготовить тестовые пиццерии, но чёткое разделение помогало параллелить ручной регресс.
Как только вносилось какое-то изменение, оно тут же деплоилось на pre-production среду и моментально тестировалось. Команда всё время находилась на связи друг с другом, они реально просто сидели в большой комнате с включенным hangouts. Ребята из Нижнего Новгорода и Сыктывкара тоже всегда были на связи. Если возникал затык, он тут же решался.
Обычно мы выводим новый функционал постепенно: 1 пиццерия, 5 пиццерий, 10 пиццерий, 20 пиццерий и так на всю сеть постепенно. В тот раз нам нужно было действовать решительнее. Времени у нас не было – в 17 часов начинался новый пик. Мы просто не могли не успеть.
Примерно в 15:00 обновление было раскатано на половину сети (это около 200 пиццерий). В 15:30 мы убедились, что всё работает нормально и включили на всю сеть. Фича-тоглы, быстрые деплои, разбитый на части регресс и зафиксированный API помогли всё это сделать.
Остальная часть команды занималась разными вариантами оптимизации при создании заказа. Новая схема была не совсем новая, она таки использовала легаси часть. Сохранение адресов, применения промокодов, генерация номера заказа – эти части были и оставались общими. Их оптимизация сводилась либо к переписыванию самих SQL-запросов, либо к избавлению от них в коде, либо к оптимизации их вызовов. Что-то пошло в асинхронном режиме, что-то, как оказалось, вызывалось по несколько раз вместо одного.
Команда инфраструктуры занималась тем, что выделяла часть компонентов на отдельные инстансы просто для того, чтобы не пересекать нагрузку. Нашим основным проблемным компонентом был легаси фасад, ходивший в легаси базу. Ему и были посвящены все работы, в том числе и по разделению инстансов.
Организуем процесс
Утром мы провели единственный за день синк, разбились на команды и ушли работать.
Сначала весь лог изменений и задач мы вели прямо в Slack, потому что сначала задач было не так много. Но их количество росло, поэтому мы быстро переехали в Trello. Настроенная интеграция между Slack и Trello оповещала о любом изменении статуса в задачке.
Дополнительно нам было важно видеть весь лог изменения продакшена. Электронная версия была в Trello, дублирующая версия была на доске инфраструктуры в виде карточек. В случае, если что-то пойдёт не так, нам нужно было быстро понять, какие изменения откатить. Полноценный регресс был только для схемы с новым заказом, остальные изменения тестировались более лояльно.
Задачи вылетали на продакшн со скоростью пули. Суммарно мы обновили систему 15 раз за тот день. У ребят были развернуты тестовые стенды, по одному на команду. Разработка, быстрая проверка, деплой на продакшн.
Дополнительно к основному процессу CTO Саша Андронов постоянно бегал в команды с вопросом «Чем помочь?». Это помогало перераспределять усилия и не терять времени на то, что кто-то не подумал попросить помощи. Полуручное управление разработкой, минимум отвлечений и работа на пределе возможностей.
После того дня нужно было выйти с ощущением, что мы сделали всё, что могли. И даже больше. И мы это сделали! В 15:30 новая схема приема заказа была раскатана для мобильного приложения на всю сеть. Режим хакатона, под 20 деплоев на продакшн за день!
Вечер 22 апреля прошёл спокойно и чётко. Ни падений, ни единого намека не то, что системе может быть нехорошо.
В районе 22 часов вечера мы собрались ещё раз и набросали план действий на неделю. Лимитирование, перфоманс тесты, асинхронный заказ и много чего ещё. Это был долгий день, а впереди были долгие недели.
Возрождение
Неделя с 23 апреля была адская. После неё мы сказали себе, что выложились на 200% и сделали всё, что могли.
Мы должны были спасать Dodo IS и решили применить некоторую медицинскую аналогию. Вообще это первый реальный случай использования метафоры (как в оригинальном XP), который реально помогал понимать, что происходит:
- Реанимации — когда нужно спасать пациента, который при смерти.
- Лечение — когда есть симптомы, но пациент ещё жив.
Реанимация
Первый этап реанимации — стандартные runbook для восстановления системы в случае отказа по каким-то параметрам. Упало одно — делаем это, упало то — делаем это и так далее. В случае падения быстро находим нужный runbook, все они лежат на GitHub и структурированы по проблемам.
Второй этап реанимации — лимитирование заказов. Данную практику мы переняли у своих же пиццерий. Когда на пиццерию сваливается очень много заказов, и они понимают, что не могут быстро их приготовить, то они встают в стоп минут на 5. Просто чтобы разгрести очередь заказов. Мы сделали подобную схему для Dodo IS. Решили, что если станет совсем плохо, включим общий лимит и будет говорить клиентам, мол, ребята, 5 минут и мы примем ваш заказ. Эту меру мы разработали на всякий случай, но в итоге ни разу ей не воспользовались. Не пригодилось. И славно.
Лечение
Для того, чтобы начать лечить надо поставить диагноз, поэтому мы сфокусировались на performance-тестах. Часть команды пошла собирать реальный профиль нагрузки с продакшена с помощью GoReplay, часть команды сосредоточилась на синтетических тестах на Stage.
Синтетические тесты не отражали реальный профиль нагрузки, но они дали определённую почву для улучшений, показали некоторые слабые места системы. Например, незадолго до этого мы переводили MySQL-коннектор с ораклового на новый. В версии коннектора была бага с pooling sessions, которая приводила к тому, что сервера просто уходили в потолок по CPU и переставали обслуживать запросы. Мы воспроизвели это с тестами на Stage, зачинили и спокойно вышли на продакшн. Подобных кейсов было с десяток.
По мере диагностики и выявления причин проблем, точечно их исправляли. Дополнительно понимали, что наш идеальный путь — это асинхронный приём заказа. Начали работать над тем, чтобы внедрить его в мобильном приложении.
Адские недели: организация процесса
Команда из 40 человек работала над единой большой целью — стабилизация системы. Все команды работали вместе. Не знаешь, чем заняться? Помоги другим командам. Фокус на конкретных целях помог не распыляться и не заниматься ненужной нам ерундой.
Три раза в день была синхронизация, общий стендап, как в классическом скраме. На 40 человек. Лишь дважды за три недели (за почти 90 синков) мы не уложились в 30 минут. Самый долгий синк длился 57 минут. Хотя обычно они занимали 20-30 минут.
Цель синков: понять, где нужна помощь и когда мы выведем те или иные задачи на продакшн. Ребята объединялись в проектные команды, если нужна была помощь инфраструктуры, тут же приходил человек, все вопросы решались быстро, меньше обсуждения больше дела.
По вечерам, чтобы поддержать ребят, в нашей R&D-лаборатории готовили еду для разработчиков на вечер. Пиццы по самым сумасшедшим рецептам, куриные крылья, картошка! Вот это было нереально круто! Такая поддержка мотивировала ребят максимально.
Работать в таком нон-стоп режиме было чертовски сложно. В среду 25 апреля около 5 вечера к CTO подошёл Олег Блохин, один из наших разработчиков, который фигачил с субботы без остановки. В глазах у него была нечеловеческая усталость: «Я пошёл домой, не могу уже». Выспался и на следующий день был бодрячком. Так можно описать общее состояние многих ребят.
В следующую субботу 28 апреля (это была рабочая суббота для всех в России) было поспокойней. Мы уже не могли что-то изменить, наблюдали за системой, ребята немного отдыхали от темпа. Всё прошло спокойно. Нагрузка была, не столь огромная, но была. Выдержали без проблем, и это придало уверенности в том, что мы идём правильным путем.
Вторая и третья недели после падения прошли уже в более спокойном режиме, адского темпа до позднего вечера уже не было, но общий процесс военного положения сохранился.
Следующий день Х: проверка на прочность
Следующий день X был на 9 мая! Кто-то сидел дома и мониторил состояние системы. Те из нас, кто пошёл гулять, взяли с собой ноуты, чтобы быть во всеоружии, если что-то пойдет не так. Саша Андронов, наш СТО, ближе к вечернему пику отправился в одну из пиццерий, чтобы в случае проблем, увидеть всё воочию.
В тот день мы получили 91500 заказов в России (на тот момент второй результат за историю Додо). Не было даже малейшего намека на проблемы. 9 мая подтвердило, что мы на правильном пути! Фокус на стабильности, на перфомансе, на качестве. Дальше нас ждала перестройка процесса, но это уже совсем другая история.
Ретро Великого падения и 6 практик
В критических ситуациях вырабатываются хорошие практики, которые можно и нужно переносить в спокойное время. Фокусировка, межкомандная помощь, быстрый деплой на продакшн не дожидаясь полного регресса. Мы начали с ретро и дальше вырабатывали каркас процесса.
Первые два дня прошли в обсуждении практик. Мы не ставили себе цель «уложить ретроспективу в 2 часа». После такой ситуации мы готовы были выделить время на то, чтобы детально проработать наши идеи и наш новый процесс. Участвовали все. Все, кто так или иначе был задействован во время работ по восстановлению.
Как итог, получилось 6 важных практик, о которых хочется рассказать чуть подробнее.
- Top N целей. Это важный момент, объясняющий цели. До военного положения бизнес и Product Owners понимали, какие задачи, какие цели стоят перед нами, но это понимание в командах разработки было несколько размазано. Не было общей картины. Каждая синхронизация работ шла от команд, кто чем занимался. Во время военного положения было не столь принципиально, КТО делает, было важно, ЧТО мы делаем. Вроде очевидная мысль, но мы пришли к такой организации работ только сейчас. Самые важные N целей будут видеть все команды и главная метрика – это Lead Time для каждой из них.
- Проектные команды. Вот это интересный момент. Изначально мы работали как фича-команды, то есть команды с постоянным составом, которые могут решать задачи в любой части системы. Но военное положение показало просто невероятную эффективность проектных команд, когда мы собирали заинтересованных людей над одной задачей, не важно, в какой команде они были. Решили пробовать дальше.
- Внутренние хакатоны. Фокус на единой цели, режим работы «чуть ли не по ночам» дал многим невероятный драйв. Ощущение, что ты вообще можешь сделать всё что угодно. Казалось, ребят невероятно прёт от того, что они делают каждую минуту. Мы подумали, что можем повторить такой формат работы для решения каких-нибудь интересных новых задач. Так в прошлом году мы провели внутренний хакатон в честь первой годовщины падения Dodo IS. В этом году собираемся повторить после отмены режима самоизоляции.
- Маленький Pull Request. Очевидный момент этой практики в том, что мы постоянно минимизировали Pull Request, который в регрессе и который вот-вот выйдет на продакшн. Но надо ещё меньше. Ещё меньше означало, что меньше регресса, меньше шансов сломать, больше шансов откатить, если что-то пошло не так. Мы не хотим тут упарываться и каждую строку кода сразу на продакшн, нет. Разумно, с головой. Но 15 раз обновить нашу систему за день теперь не является преградой.
- Performance-тесты — часть регресса. Отсутствие performance-тестов стало приговором для нашей системы. Мы не понимали, каковы её пределы. Performance-тесты дали почву для улучшений. Мы выработали baseline и были уверены, что каждый следующий PR не ухудшит производительность. Дальше мы двинулись в сторону нагрузочного тестирования, ежедневно и еженедельно.
- Performance тесты обязательны для критических участков. Для нас критические участки — это приём заказа и его обработка. Мобильное приложение, сайт, колл-центр, касса ресторана, трекер, касса доставки и система оповещения в пиццериях. Всё это должно работать без сбоев и выдерживать рост. Тут нам предстояло много работы по расширению сценариев, росту экспертизы в нагрузке.
Бонусы
1. Интервью с участниками событий
 Олег Блохин (Site Reliability Engineering): Шла первая или вторая неделя ФРК. Всё горело, никто ничего не понимал.
Олег Блохин (Site Reliability Engineering): Шла первая или вторая неделя ФРК. Всё горело, никто ничего не понимал.
 Паша Притчин (Site Reliability Engineering, Product Owner продукта Платформа Dodo IS): Сам момент падения я помню плохо. Помню, что это была суббота, был тёплый день.
Паша Притчин (Site Reliability Engineering, Product Owner продукта Платформа Dodo IS): Сам момент падения я помню плохо. Помню, что это была суббота, был тёплый день.
На тот момент я занимался auth’ом, а это было далеко от больного бэкэнда. Поэтому непосредственно участия в момент падения я не принимал. Тогда мы делали свой бэклог независимо, не особо следя за происходящим в мобильном приложении.
Осознание происходящего пришло вечером, когда Саша Андронов (СТО) написал вот такое:
Для меня история падения началась именно с этого поста. В этот момент стало понятно, что всё действительно серьёзно.
На следующее утро я поехал в офис. Накануне я не участвовал в поднятии прода, поэтому контекста у меня не было. Но я не мог сидеть спокойно дома. Мне хотелось помочь хоть чем-то. Быстро выяснилось, что есть задача по снижению импакта от вчерашнего сбоя, а конкретно с поиском пострадавших клиентов. Кто-то делал заказ, деньги списались, а заказ не создался. Нужно было найти этих клиентов, вытащить их номера телефонов и передать в колл-центр, чтобы те обзвонили людей, извинились и сгладили негатив.
Со своей стороны мы отменяли эти транзакции в ручном режиме. Данные о корзинах с мобильного приложения и сайта хранились в redis, откуда их и надо было вытащить. Этим я и занялся. Если бы надо было делать что-то другое, я бы взялся. Ощущение тревоги и серьёзности происходящего не покидало.
В то утро все разработчики Dodo IS пришли в офис. За день мы сделали кучу задач по стабильности. Начиная от простого удаления мешающих эксепшенов, заканчивая переписыванием запросов в базу. Интересно, что в этот момент мы отбросили все структуры, команды, цели, продукты и прочее. Все стали одной командой разработки, цель у всех была одна — любой ценой не упасть вечером.
Утром в понедельник всё началось заново. Этот день и несколько последующих недель работ по стабилизации бэклога мы не зря назвали потом «Военным положением». Лозунг «Всё для фронта, всё для победы» весьма точно описывает происходящее.
Олег Блохин:
Основная причина падения – блокирующие запросы к базе. Старый механизм заказа очень сильно нагружал базу. Проблема частично решилась установкой ограничения на время выполнения запроса. Хорошо, что дальнозоркие ребята из клиентских сервисов уже заканчивали делать новый механизм приёма заказа. Спасибо Диме Новосёлову и Ане Морозовой. Отдельное спасибо Дамиру.
Паша Притчин:
Система не выдержала нагрузки и упала. Сервисы не смогли подняться сами, пришлось их долго и мучительно поднимать руками. Нагрузилась база (единая точка отказа), из-за чего вся сеть не могла нормально работать. Заказы не принимались.
Для меня сам момент падения не так интересен. Гораздо интереснее:
Олег Блохин:
То, что во время инцидента никто ничего не понимал, а те, кто понимал не знал что делать.
Паша Притчин:
Понимание того, что мы могли бы всё исправить заранее и не допустить такой ситуации, но ничего не сделали. Надо помнить о таких событиях, чтобы не допустить их вновь.
Олег Блохин: Самое важное, что появилось после того случая – нагрузочное тестирование.
Паша Притчин:
Олег Блохин:
Паша Притчин:
Олег Блохин:
Не откладывайте «технические» проблемы на потом, чтобы решить «бизнесовые». Лучше, когда у бизнеса нет одной фичи, чем когда лежит вся система. За собой надо прибираться.
Паша Притчин:
Надо всегда помнить, что мы все в одной лодке. Нам помогла взаимовыручка, гибкость, высокий уровень профессионализма и небезразличия. Эти качества нужны и сейчас.
21.04.2018 – памятная дата для Dodo IS. Каким запомнился этот день тебе?
Олег Блохин (Site Reliability Engineering): Шла первая или вторая неделя ФРК. Всё горело, никто ничего не понимал. Паша Притчин (Site Reliability Engineering, Product Owner продукта Платформа Dodo IS): Сам момент падения я помню плохо. Помню, что это была суббота, был тёплый день. На тот момент я занимался auth’ом, а это было далеко от больного бэкэнда. Поэтому непосредственно участия в момент падения я не принимал. Тогда мы делали свой бэклог независимо, не особо следя за происходящим в мобильном приложении.
Осознание происходящего пришло вечером, когда Саша Андронов (СТО) написал вот такое:
Для меня история падения началась именно с этого поста. В этот момент стало понятно, что всё действительно серьёзно.
На следующее утро я поехал в офис. Накануне я не участвовал в поднятии прода, поэтому контекста у меня не было. Но я не мог сидеть спокойно дома. Мне хотелось помочь хоть чем-то. Быстро выяснилось, что есть задача по снижению импакта от вчерашнего сбоя, а конкретно с поиском пострадавших клиентов. Кто-то делал заказ, деньги списались, а заказ не создался. Нужно было найти этих клиентов, вытащить их номера телефонов и передать в колл-центр, чтобы те обзвонили людей, извинились и сгладили негатив.
Со своей стороны мы отменяли эти транзакции в ручном режиме. Данные о корзинах с мобильного приложения и сайта хранились в redis, откуда их и надо было вытащить. Этим я и занялся. Если бы надо было делать что-то другое, я бы взялся. Ощущение тревоги и серьёзности происходящего не покидало.
В то утро все разработчики Dodo IS пришли в офис. За день мы сделали кучу задач по стабильности. Начиная от простого удаления мешающих эксепшенов, заканчивая переписыванием запросов в базу. Интересно, что в этот момент мы отбросили все структуры, команды, цели, продукты и прочее. Все стали одной командой разработки, цель у всех была одна — любой ценой не упасть вечером.
Утром в понедельник всё началось заново. Этот день и несколько последующих недель работ по стабилизации бэклога мы не зря назвали потом «Военным положением». Лозунг «Всё для фронта, всё для победы» весьма точно описывает происходящее.
Что всё-таки пошло не так?
Олег Блохин:Основная причина падения – блокирующие запросы к базе. Старый механизм заказа очень сильно нагружал базу. Проблема частично решилась установкой ограничения на время выполнения запроса. Хорошо, что дальнозоркие ребята из клиентских сервисов уже заканчивали делать новый механизм приёма заказа. Спасибо Диме Новосёлову и Ане Морозовой. Отдельное спасибо Дамиру.
Паша Притчин:Система не выдержала нагрузки и упала. Сервисы не смогли подняться сами, пришлось их долго и мучительно поднимать руками. Нагрузилась база (единая точка отказа), из-за чего вся сеть не могла нормально работать. Заказы не принимались.
Для меня сам момент падения не так интересен. Гораздо интереснее:
- Что мы делали неправильно ДО этого падения.
- Что мы сделали СРАЗУ ПОСЛЕ падения.
- Как мы потом учли это и что сделали, чтобы не допустить подобного впредь.
Что было самым ужасным в той ситуации?
Олег Блохин:То, что во время инцидента никто ничего не понимал, а те, кто понимал не знал что делать.
Паша Притчин:Понимание того, что мы могли бы всё исправить заранее и не допустить такой ситуации, но ничего не сделали. Надо помнить о таких событиях, чтобы не допустить их вновь.
Как это повлияло на нас? Какие принципы и подходы появились в тот момент и сохранились с тех пор в разработке?
Олег Блохин: Самое важное, что появилось после того случая – нагрузочное тестирование. Паша Притчин:- Главное — это появление системы нагрузочного тестирования. Почему-то мы задумались об этом по-настоящему только после падения.
До всей этой истории бэкэнд мобильного приложения проходил нагрузку перед запуском, но делали мы это тогда весьма неумело. Осенью 2018 года началась полноценная работа по этой теме, мы пригласили ребят из PerformanceLab, а позже сделали свою команду Нагрузки. - После окончания активных событий стало ясно, что предыдущая организация структуры разработки не отвечает на все запросы. Так у нас начался период Less-трансформации.
- Именно в то время появилось понимание важности работы над стабильностью. В конце 2018 года мы провернули апрельский сценарий ещё раз в мини-режиме, сделав так называемый новогодний бэклог. Все команды уже в спокойном режиме, делали задачи по стабильности. Наработки и опыт апреля-мая 2018 был весьма кстати.
- Активное использование async в коде. Удивительно, но до 21.04.2018 мы не задумывались об этом. А сейчас у нас, да и везде это повсеместно. Все либы пишутся с async.
- Асинхронный заказ. Нет, это не метод SaveOrder на async-await. Это несколько иное, и появилось оно именно тогда. Раньше путь сохранения заказа был такой: с мобильного приложения на клиенте совершался вызов бэкэнда мобильного приложения, оттуда в том же запросе вызывался LF, далее открывалась транзакция в базе и выполнялось порядка 20 действий над таблицами. По окончанию транзакции в случае её успеха, это проходило по цепочке до клиентского приложения. Долгий процесс, в котором мы зависели от надежности каждого из компонентов. А они были ненадёжны!
Даже если они не падали, а просто тормозили, это всё равно могло вызывать каскадный сбой на более высоких уровнях, где замедление воспринималось как ошибка.
Сначала асинхронный заказ был сделан в приёме заказа с мобилки, а позже на сайте, кассах ресторана. Не так давно практика дошла до последнего источника заказа — колл-центра. Теперь все заказы мы принимаем именно так. - Лимиты на уровне базы и балкхэды. До этих событий мы не придавали значения такому понятию, как ограничения (лимиты, балкхэды). Одной из причин падения было то, что при росте нагрузки не было сдерживающих факторов. Все «вентили» были раскручены на полную. Таймаут на nginx был несколько минут, ограничения на стороне веб-приложений не было, в базе лимиты были выставлены от балды.
Мы выставили несколько ограничивающих настроек: innodb_lock_wait_timeout = 5; innodb_rollback_on_timeout = ON. Потом мы уже внимательно следили за ограничениями в базе. Не сказал бы, что после этого легендарного падения, все настройки были приведены в идеальное состояние, но другие падения показывают, что теперь мы умеем манипулировать такими настройками.
Назови три главных вывода, которые лично ты сделал из сложившейся ситуации?
Олег Блохин:- Надо очень хорошо разбираться, как работает то, чем ты пользуешься и то, что ты пишешь. Иначе всё сломается, а ты не сможешь починить.
- Иногда люди просто делают вид, что понимают всё происходящее вокруг.
- За ключевые компоненты должны быть ответственные люди, которые хорошо понимают, как этот компонент работает, и делают вещи наперёд. Если бы не был готов новый флоу заказа – мы бы пошли нафиг.
Паша Притчин:- У нас хорошие разработчики.
- Структура и процессы очень важны. Один и те же люди в разных ситуациях, структурах, процессах действуют совершенно по-разному. И прыгнуть выше головы можно только учитывая все эти связи.
- Необходимо постоянно заниматься техническими работами. Если их нет, то до какого-то времени все будет работать, а потом опять разрушится.
Что можно посоветовать другим, чтобы они не оказались в такой ситуации?
Олег Блохин:Не откладывайте «технические» проблемы на потом, чтобы решить «бизнесовые». Лучше, когда у бизнеса нет одной фичи, чем когда лежит вся система. За собой надо прибираться.
Паша Притчин:Надо всегда помнить, что мы все в одной лодке. Нам помогла взаимовыручка, гибкость, высокий уровень профессионализма и небезразличия. Эти качества нужны и сейчас.
2. Краткий, но увлекательный пересказ истории от Андрея Моревского (Dodo IS Architect)
 Два года назад вся Додо готовилась к первой рекламной кампании на федеральных каналах — ФРК, как мы ласково её называли. Первой она была не только для нас, но и для всей страны — ещё никогда ни одна сеть пиццерий не запускала рекламу на первых кнопках телевизора.
Два года назад вся Додо готовилась к первой рекламной кампании на федеральных каналах — ФРК, как мы ласково её называли. Первой она была не только для нас, но и для всей страны — ещё никогда ни одна сеть пиццерий не запускала рекламу на первых кнопках телевизора.
В кампанию были заложены серьезные бюджеты и высокие ожидания, мы давали бесплатную пиццу за установку мобильного приложения, что должно было привести к лавинообразному росту заказов и новых клиентов. Пожалуй, лишь сравнением с первым запуском человека в космос (который, кстати, тоже случился в апреле) можно описать всю серьёзность отношения бизнеса к ФРК.
Вместе со всеми к рекламной кампании готовился и IT-отдел. Мы оценили потенциальный рост нагрузки на Dodo IS, и по нашим теоретическим выкладкам система должна была выстоять. Мы были достаточно самонадеянны и не проверили эти предположения хотя бы на тестовых окружениях…
Час X настал, ФРК стартанула. Гром грянул в первые же дни. Dodo IS начала падать, мы начали терять тысячи заказов и сотни новых клиентов, начали терять всё, во что вложили так много сил и денег. Трудно описать словами жгучее чувство стыда, который мы, разработчики, испытывали в тот момент. Это был оглушительный факап. Наши коллеги выложились на 146%, чтобы эта кампания стала возможной. И всё это для того, чтобы на старте Dodo IS тупо упала?
Позор решили смывать не кровью, но потом. Собравшись на экстренный брейншторм, мы выработали план действий, который позволил бы в самые кратчайшие сроки остановить падение. В этом плане было и создание нагрузочных стендов и асинхронный заказ и лимитирование запросов и многие другие оптимизации, которые мы постоянно откладывали в долгий ящик. Теперь же времени на раскачку не было, пришла пора действовать здесь и сейчас!
План спасения требовалось реализовать настолько быстро, насколько это возможно. Мы объявили «военное положение»: 11-часовой рабочий день, без выходных, на 2 недели. Переговорка «Сыктывкар» закрылась для бронирования и превратилась в штаб. Каждые 3-4 часа мы собирались в штабе, чтобы синхронизироваться по текущему прогрессу и при необходимости корректировали план. В те дни мы принимали решения с невиданной ранее скоростью, а воплощали их ещё быстрее. Золотые были времена.
Благодаря чёткой координации, мотивации, сфокусированности и ударным темпам работы уже через неделю ситуация стала существенно лучше. А ещё через неделю проблемы исчезли как страшный сон. Dodo IS смогла обслуживать вдвое больше заказов, чем до «военного положения». Нам удалось спасти первую ФРК! (правда от нас самих же).
С тех пор много воды утекло, и за эти годы Dodo IS пришлось столкнуться с куда большими нагрузками, чем в ту самую первую ФРК. Но теперь Dodo IS справляется. В том числе благодаря решениям из «военного времени», например, таким как асинхронный заказ. Ну а мы больше не факапим и регулярно проводим нагрузочное тестирование системы (особенно перед рекламными кампаниями), а наши тестовые пиццерии все так же называются loadtest, совсем как тогда, два года назад.
Два года назад вся Додо готовилась к первой рекламной кампании на федеральных каналах — ФРК, как мы ласково её называли. Первой она была не только для нас, но и для всей страны — ещё никогда ни одна сеть пиццерий не запускала рекламу на первых кнопках телевизора. В кампанию были заложены серьезные бюджеты и высокие ожидания, мы давали бесплатную пиццу за установку мобильного приложения, что должно было привести к лавинообразному росту заказов и новых клиентов. Пожалуй, лишь сравнением с первым запуском человека в космос (который, кстати, тоже случился в апреле) можно описать всю серьёзность отношения бизнеса к ФРК.
Вместе со всеми к рекламной кампании готовился и IT-отдел. Мы оценили потенциальный рост нагрузки на Dodo IS, и по нашим теоретическим выкладкам система должна была выстоять. Мы были достаточно самонадеянны и не проверили эти предположения хотя бы на тестовых окружениях…
Час X настал, ФРК стартанула. Гром грянул в первые же дни. Dodo IS начала падать, мы начали терять тысячи заказов и сотни новых клиентов, начали терять всё, во что вложили так много сил и денег. Трудно описать словами жгучее чувство стыда, который мы, разработчики, испытывали в тот момент. Это был оглушительный факап. Наши коллеги выложились на 146%, чтобы эта кампания стала возможной. И всё это для того, чтобы на старте Dodo IS тупо упала?
Позор решили смывать не кровью, но потом. Собравшись на экстренный брейншторм, мы выработали план действий, который позволил бы в самые кратчайшие сроки остановить падение. В этом плане было и создание нагрузочных стендов и асинхронный заказ и лимитирование запросов и многие другие оптимизации, которые мы постоянно откладывали в долгий ящик. Теперь же времени на раскачку не было, пришла пора действовать здесь и сейчас!
План спасения требовалось реализовать настолько быстро, насколько это возможно. Мы объявили «военное положение»: 11-часовой рабочий день, без выходных, на 2 недели. Переговорка «Сыктывкар» закрылась для бронирования и превратилась в штаб. Каждые 3-4 часа мы собирались в штабе, чтобы синхронизироваться по текущему прогрессу и при необходимости корректировали план. В те дни мы принимали решения с невиданной ранее скоростью, а воплощали их ещё быстрее. Золотые были времена.
Благодаря чёткой координации, мотивации, сфокусированности и ударным темпам работы уже через неделю ситуация стала существенно лучше. А ещё через неделю проблемы исчезли как страшный сон. Dodo IS смогла обслуживать вдвое больше заказов, чем до «военного положения». Нам удалось спасти первую ФРК! (правда от нас самих же).
С тех пор много воды утекло, и за эти годы Dodo IS пришлось столкнуться с куда большими нагрузками, чем в ту самую первую ФРК. Но теперь Dodo IS справляется. В том числе благодаря решениям из «военного времени», например, таким как асинхронный заказ. Ну а мы больше не факапим и регулярно проводим нагрузочное тестирование системы (особенно перед рекламными кампаниями), а наши тестовые пиццерии все так же называются loadtest, совсем как тогда, два года назад.

