Предлагаю ознакомиться с расшифровкой доклада начала 2016 года Андрея Сальникова "Типовые ошибки в приложениях, которые ведут к bloat в postgresql"
В данном докладе я разберу основные ошибки в приложениях, которые возникают на этапе проектирования и написания кода приложения. И возьму только те ошибки, которые ведут к bloat в Postgresql. Как правило, это начало конца производительности вашей системы в целом, хотя изначально никаких предпосылок к этому не было видно.

Рад всех приветствовать! Этот доклад не такой технический как предыдущий от моего коллеги. Этот доклад ориентирован на разработчиков бэкенд-систем в основном, потому что у нас достаточно большое количество клиентов. И все они совершают одни и те же ошибки. О них я вам расскажу. Объясню к чему фатальному и плохому ведут эти ошибки.

Почему совершаются ошибки? Совершаются они по двум причинам: на авось, может так прокатит и от незнания каких-то механизм, которые происходят на уровне между базой и приложением, а также в самой базе.
Я вам приведу три примера с ужасными картинками того, как все стало плохо. Вкратце расскажу об механизме, который там происходит. И как с ними бороться, когда они случились, и какие превентивные методы использовать для предотвращения ошибок. Расскажу о вспомогательных инструментах и дам полезные ссылки.

Я использовал тестовую базу данных, где у меня было две таблички. Одна табличка со счетами клиентов, другая с операциями по этим счетам. И с какой-то периодичностью мы обновляем остатки на этих счетах.

Исходные данные таблички: она достаточно небольшая, 2 MB. Время ответа по базе и конкретно по табличке тоже очень хорошее. И достаточно хорошая нагрузка – 2 000 операций в секунду по табличке.
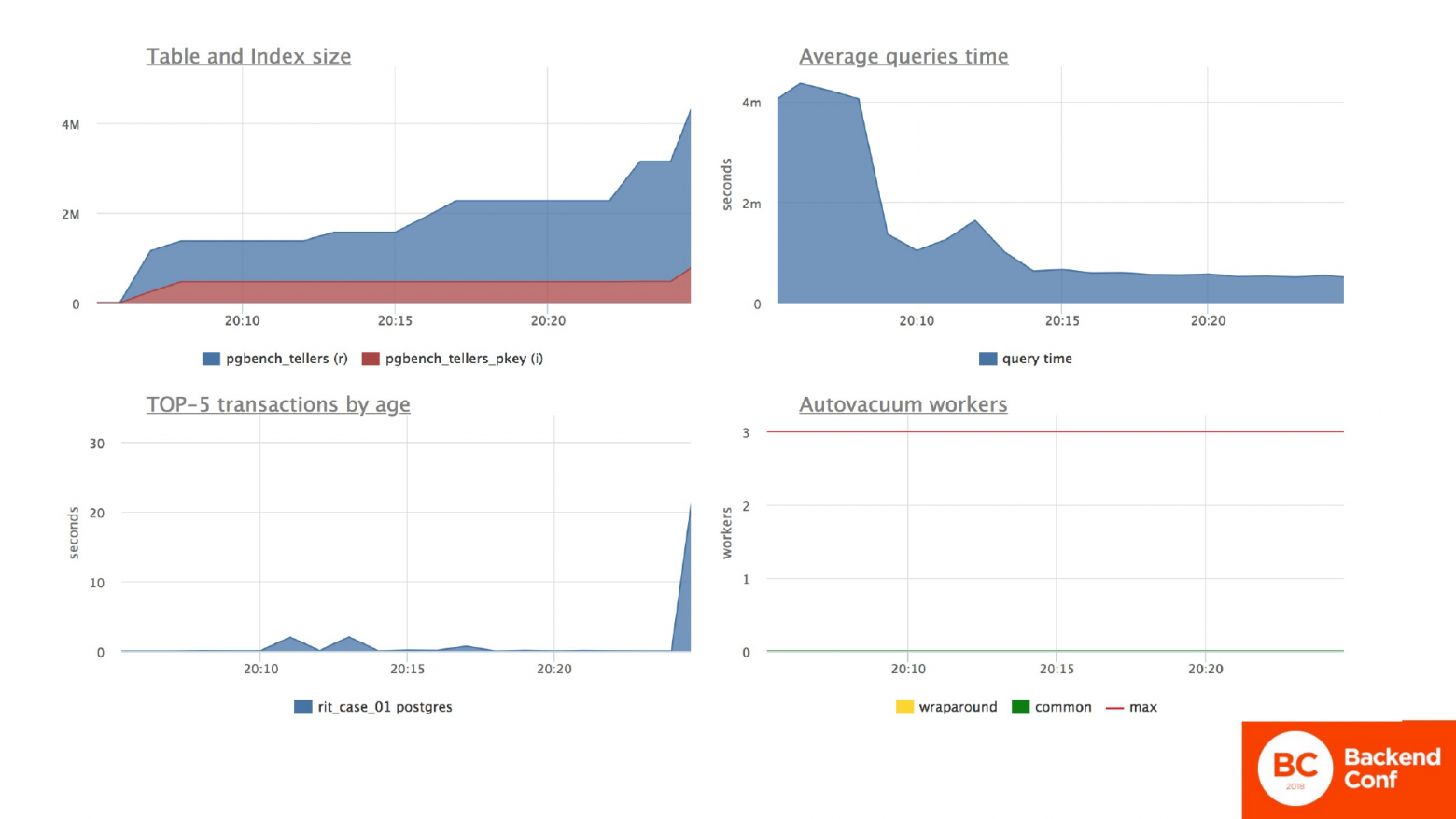
И сквозь этот доклад я вам буду показывать графики, чтобы наглядно было понятно, что происходит. Всегда будет 2 слайда с графиками. Первый слайд – это то, что происходит в общем на сервере.
И в данной ситуации мы видим, что действительно у нас табличка небольшого размера. Индекс небольшой в 2 MB. Это первый слева график.
Среднее время ответа по серверу тоже стабильное, небольшое. Это правый верхний график.
Левый нижний график – это самые длительные транзакции. Мы видим, что транзакции быстро выполняются. И автовакуум тут еще не работает, потому что – это был старт-тест. Дальше он будет работать и будет полезен нам.

Второй слайд всегда будет посвящен испытуемой табличке. В этой ситуации мы обновляем постоянно остатки по счетам у клиента. И мы видим то, что среднее время ответа по операции обновления достаточно хорошее, меньше миллисекунды. Видим, что ресурсы процессора (это правый верхний график) потребляются тоже равномерно и достаточно небольшие.
Правый нижний график показывает, сколько памяти операционной и дисковой мы перебираем в поисках нашей нужной строчки, прежде чем ее обновить. И количество операция по табличке – 2 000 в секунду, как и вначале я говорил.

И теперь у нас происходит трагедия. По какой-то причине возникает длинная забытая транзакция. Причины обычно все банальные:
- Одна из самых распространенных – это то, что мы в коде приложения начали обращаться к внешнему сервису. И этот сервис нам не отвечает. Т. е. мы открыли транзакцию, сделали изменение в базе и пошли из приложения почту почитать или к другому сервису в рамках нашей инфраструктуры, и он по какой-то причине нам не отвечает. И у нас повисла сессия в состоянии – неизвестно, когда разрешится.
- Вторая ситуация, когда у нас в коде по какой-то причине произошел exception. И мы в exception не обработали закрытие транзакции. И у нас получилась висящая сессия с отрытой транзакцией.
- И последний – это тоже довольно частый случай. Это некачественный код. Некоторые фреймворки открывают транзакцию. Она висит, и вы можете не знать в приложении, что она у вас висит.
К чему ведут такие вещи?
К тому, что у нас начинают резко раздуваться таблицы и индексы. Это как раз тот самый эффект bloat. Для базы это будет выражаться в том, что у нас очень резко увеличится время ответа базы данных, увеличится нагрузка на сервер базы данных. И как итог у нас будет страдать приложение. Потому что если вы в коде тратили 10 миллисекунд на запрос в базу, 10 миллисекунд на свою логику, то у вас функция отрабатывала 20 миллисекунд. А сейчас у вас ситуация будет совсем печальная.
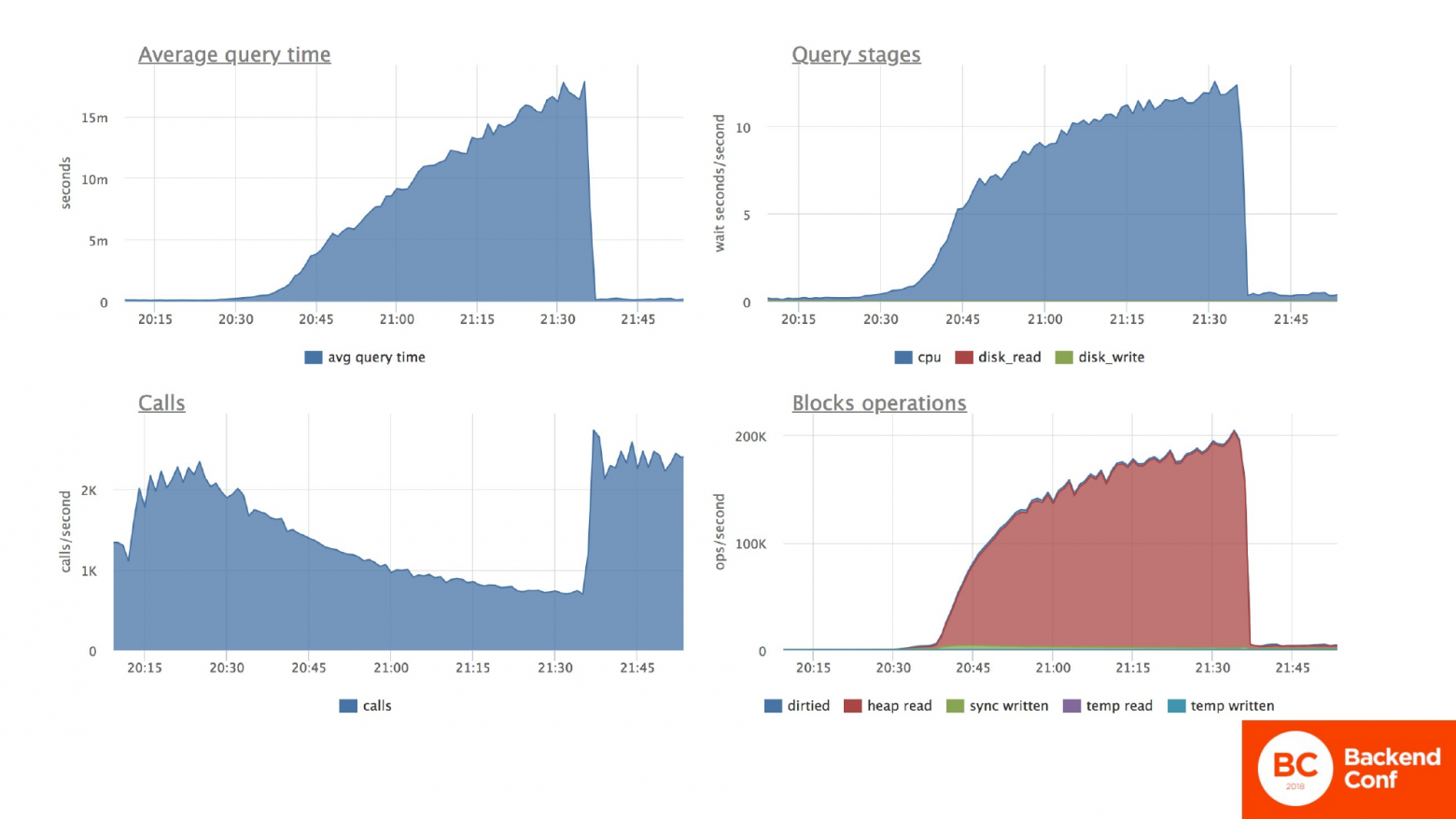
И давайте посмотрим, что происходит. Левый нижний график показывает, что у нас длинная долгая транзакция. И если мы посмотрим на левый верхний график, то мы видим, что размер таблицы с двух мегабайт у нас резко скакнул в 300 мегабайт. При этом количество данных в таблице не изменилось, т. е. там достаточно большое количество мусора.
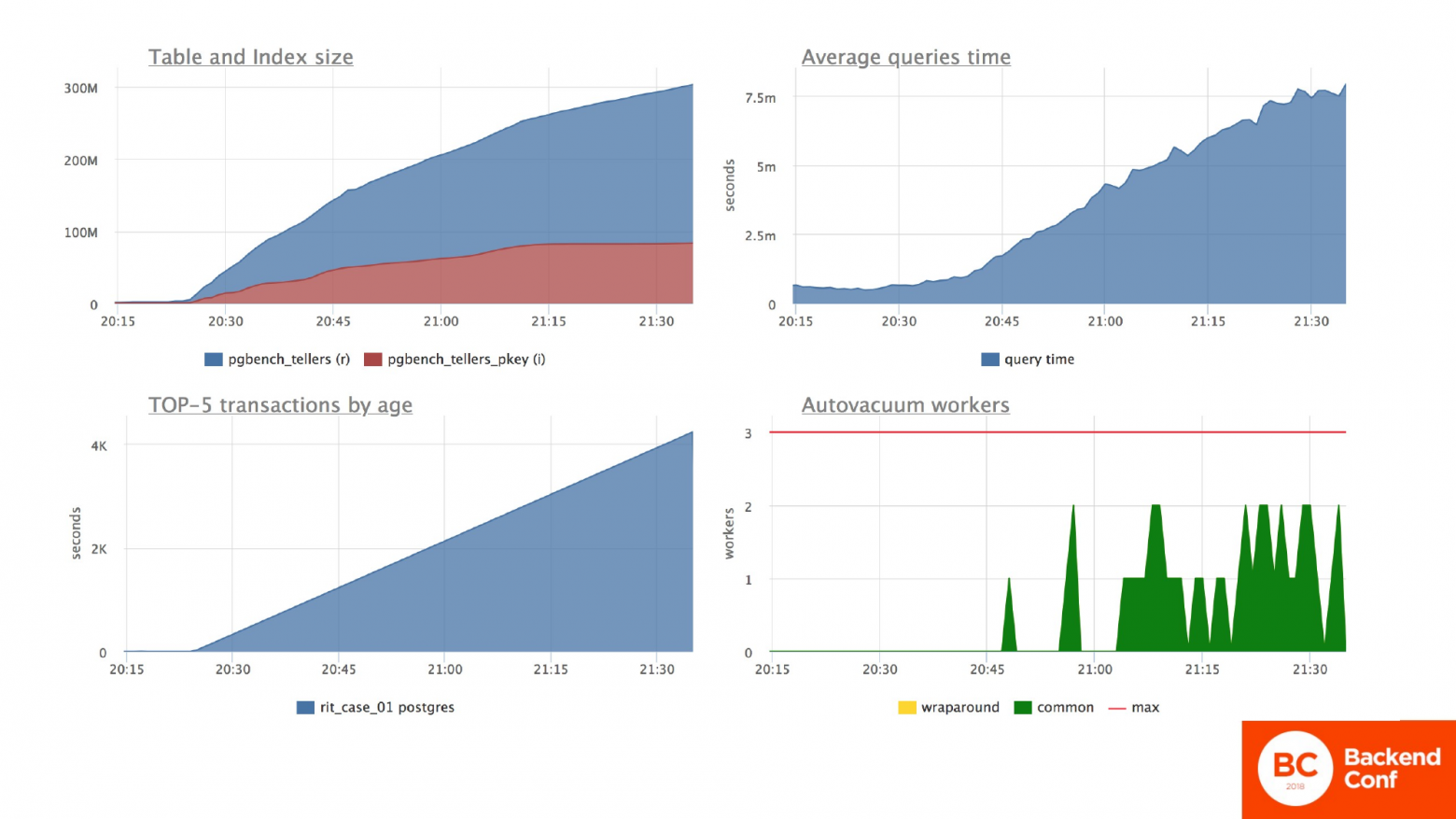
Общая ситуация по среднему времени ответа сервера тоже изменилось на несколько порядков. Т. е. все запросы по серверу начали капитально проседать. И при этом запустились внутренние процессы Postgres в лице автовакуума, которые что-то пытаются делать и потребляют ресурсы.
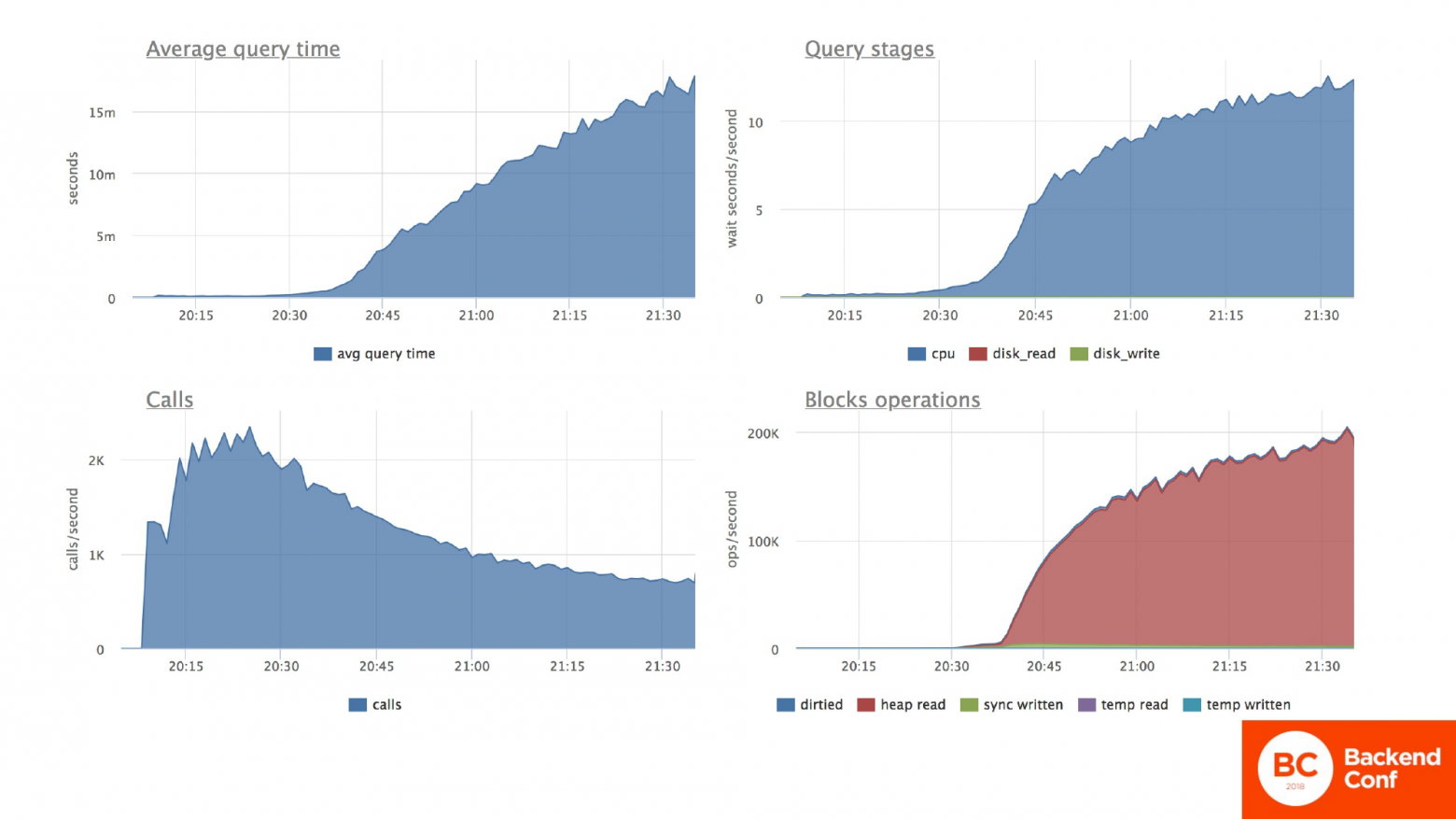
Что же с нашей табличкой происходит? Тоже самое. Среднее время ответа по табличке у нас скакнуло на несколько порядков вверх. Если конкретно по потребляемым ресурсам, то мы видим, что очень сильно увеличилась нагрузка на процессор. Это правый верхний график. И увеличилась она потому что, процессору приходится перебирать кучу бесполезных строчек в поисках одной нужной. Это правый нижний график. И как результат – количество вызовов в секунду у нас начало просаживаться очень сильно, потому что база не успевает обрабатывать то же количество запросов.

Нам надо возвращаться к жизни. Лезем в интернет и узнаем, что длинные транзакции приводят к проблеме. Находим и убиваем эту транзакцию. И у нас все становится нормально. Все работает как надо.
Мы успокоились, но через некоторое время начинаем замечать, что приложение работает не так, как до аварийной ситуации. Запросы обрабатываются все равно медленнее, причем существенно медленнее. В полтора-два раза медленнее конкретно в моем примере. Нагрузка на сервер тоже выше, чем была до аварии.
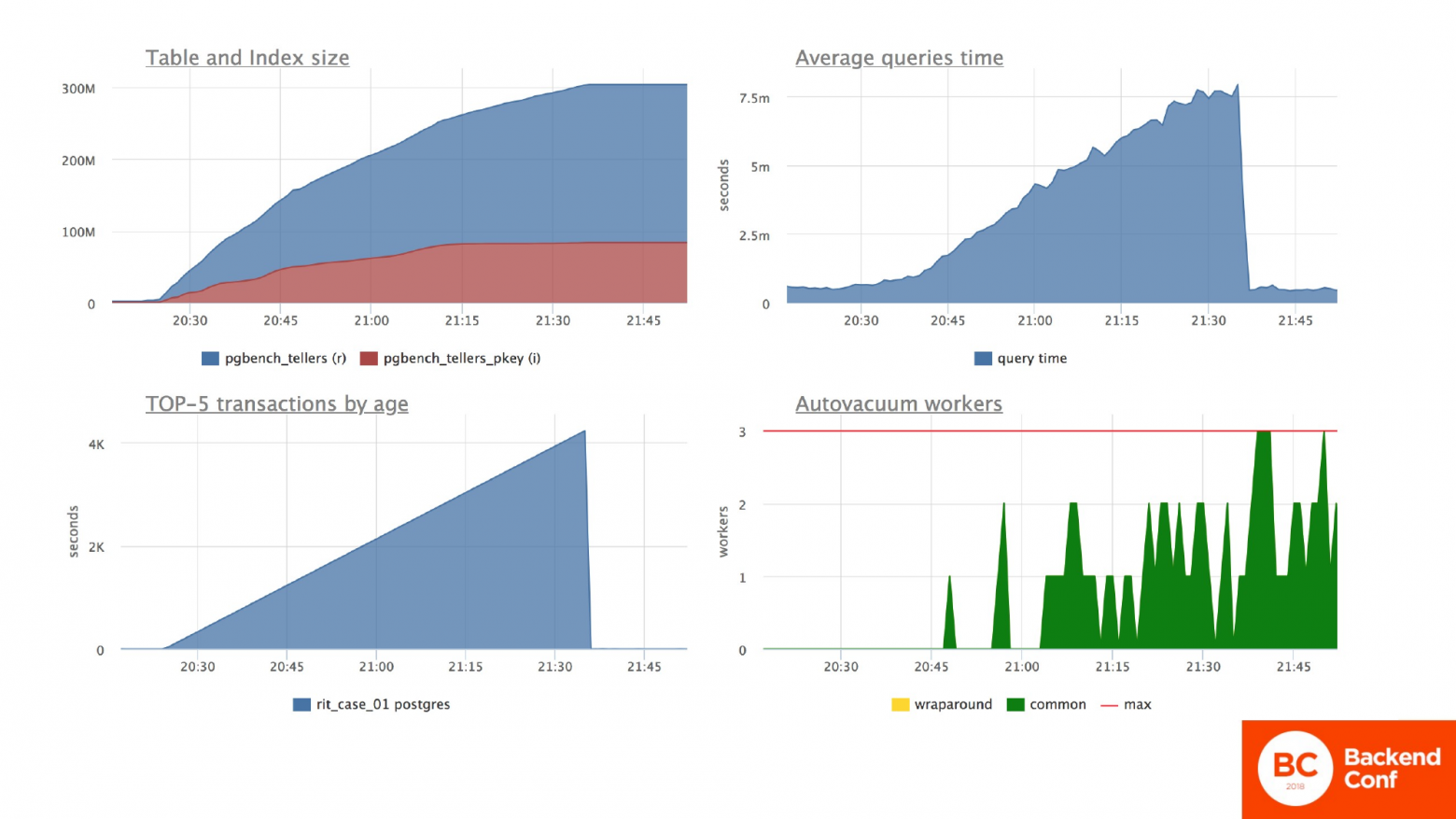
И вопрос: «Что происходит с базой в этот момент?». А с базой происходит следующая ситуация. На графике транзакций вы видите, что она остановилась и там действительно нет длительных транзакций. Но размеры таблички во время аварии у нас фатально выросли. И с тех пор не уменьшились. Среднее время по базе стабилизировалось. И ответы вроде ходят адекватно с приемлемой для нас скоростью. Автовакуум стал более активным и начал что-то делать с табличкой, потому что ему нужно перелопачивать большее количество данных.
Конкретно по испытуемой табличке со счетами, где мы меняем остатки: время ответа по запросу вроде бы вернулось в норму. Но на самом деле оно в полтора раза выше.
И по нагрузке на процессор мы видим, что нагрузка на процессор не вернулась в нужную величину до аварии. И причины там кроются как раз в правом нижнем графике. Видно, что там происходит перебор какого-то количества памяти. Т. е. для поиска нужной строчки мы тратим ресурсы сервера база данных при переборке бесполезных данных. Количество транзакций в секунду стабилизировалось.
В общем хорошо, но ситуация хуже, чем была. Явная деградация базы данных как следствие нашего приложения, которое работает с этой базой данных.

И чтобы разобраться, что там происходит, если вы не были на предыдущем докладе, то сейчас немножечко теории. Теория о процессе внутреннем. Зачем автовакуум и что он делает?
Буквально вкратце для понимания. В какой-то момент времени мы имеем таблицу. В таблице у нас находятся строчки. Эти строчки могут быть активные, живые, нужные нам сейчас. На картинке они помечены зеленым цветом. И есть строчки мертвые, которые уже отработали, были обновлены, по ним появились новые записи. И они помечены, что они уже не интересны базе данных. Но лежат в таблице из-за особенности Postgres.
Зачем нужен автовакуум? Автовакуум в какой-то момент приходит, обращается к базе данных и спрашивает ее: «Дай мне, пожалуйста, id самой старой транзакции, которая открыта на данный момент в базе данных». База данных возвращает этот id. И автовакуум опираясь на него перебирает строчки в таблице. И если видит, что какие-то строчки были изменены транзакциями куда более старыми, то он имеет право их пометить как строчки, которые мы можем переиспользовать в будущем, записав туда новые данные. Это фоновый процесс.
Мы в это время продолжаем работать с базой данных, продолжаем производить какие-то изменения в таблице. И на эти строчки, которые мы можем переиспользовать, записываем новые данные. И таким образом у нас получается круговорот, т. е. все время там возникают какие-то мертвые старые строки, вместо них мы записываем новые строки, которые нам нужны. И это нормальное состояние для работы PostgreSQL.
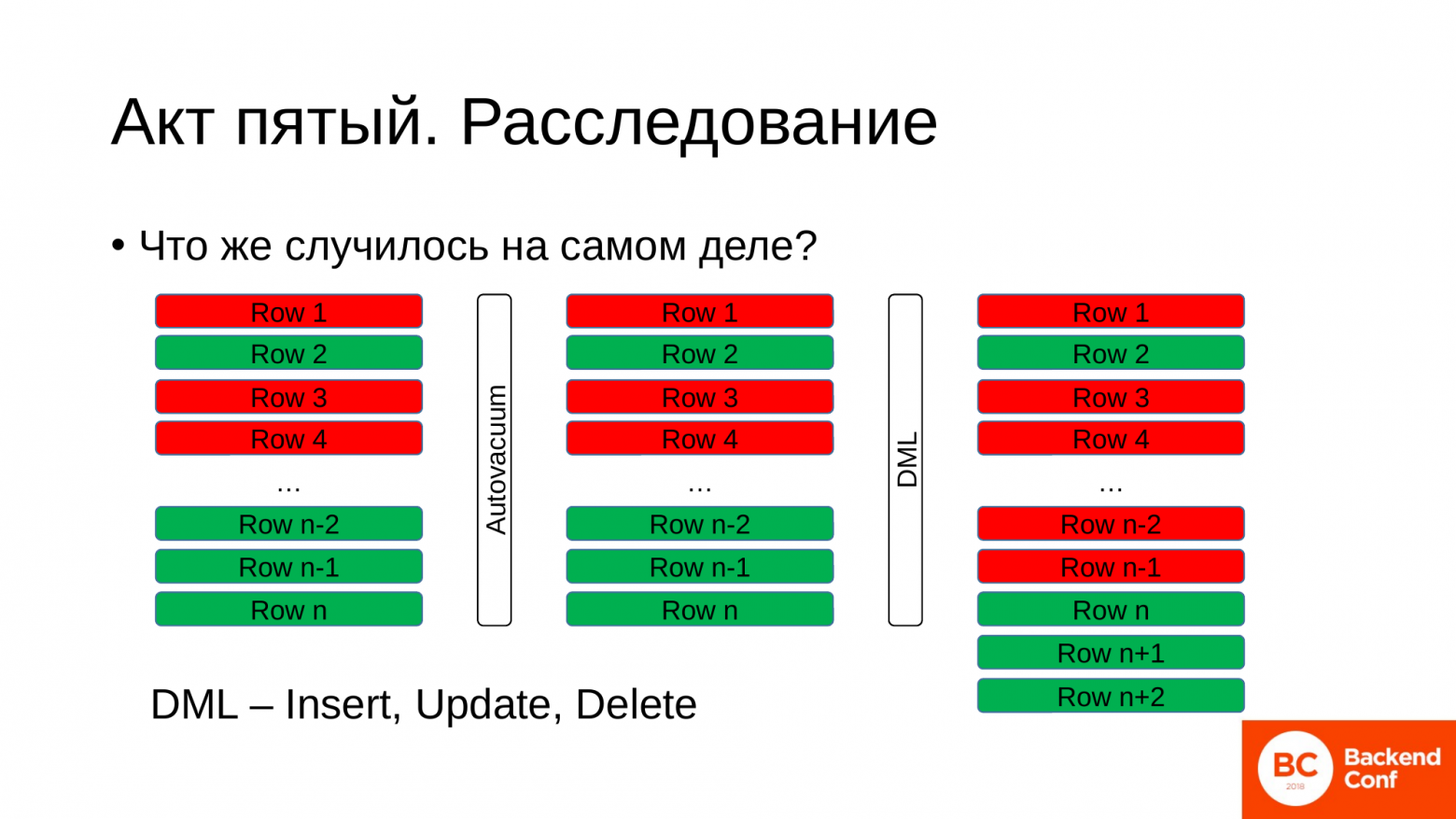
Что произошло во время аварии? Как там происходил этот процесс?
Мы имели табличку в каком-то состоянии, какие-то живые, какие-то мертвые строчки. Пришел автовакуум. Он спросил базу данных о том, какая у нас самая давняя транзакция, какой у нее id. Получил этот id, который может быть многочасовой давности, может десятиминутной. Это зависит от того, насколько сильная нагрузка у вас в базе данных. И пошел искать строчки, которые он может пометить как переиспользуемые. И не нашел таких строчек в нашей таблице.
Но мы в это время продолжаем работать с таблицей. Что-то делаем в ней, обновляем, меняем данные. А что базе данных в это время делать? Ей ничего не остается, как дописывать новые строчки в конец существующей таблицы. И тем самым у нас размер таблицы начинает раздуваться.
Реально нам для работы нужны зеленые строчки. Но во время такой проблемы у нас получается, что процент зеленых строчек крайне низок во всем объеме таблицы.
А когда мы выполняем запрос, базе данных приходится пробегаться по всем строчкам: и красным, и зеленым, чтобы найти нужную строчку. И эффект раздутия таблицы бесполезными данными называется «bloat», который еще и жрет наше дисковое пространство. Помните, было 2 MB, стало 300 MB? А теперь поменяйте мегабайты на гигабайты и вы так достаточно быстро лишитесь всех запасов своих дисковых ресурсов.

Какие последствия могут быть для нас?
- В моем примере таблица и индекс выросли в 150 раз. У некоторых наших клиентов бывали более фатальные случаи, когда просто место на диске начиналось заканчиваться.
- Размер таблиц сам по себе никогда не уменьшится. Автовакуум в некоторых случаях может отрезать хвостик таблицы, если там только мертвые строчки. Но так как происходит постоянная ротация, одна зеленая строчка может в конце зависнуть и не обновляться, а все остальные где-то в начале таблички будут записываться. Но это настолько маловероятное событие, что у вас сама по себе таблица уменьшится в размерах, что не стоит на это надеяться.
- Базе данных нужно перебирать всю кипу бесполезных строчек. И мы тратим дисковые ресурсы, тратим ресурсы процессора и электроэнергию.
- И это непосредственно влияет на наше приложение, потому что если в начале мы тратили 10 миллисекунд на запрос, 10 миллисекунд на наш код, то во время аварии мы стали тратить секунду на запрос и 10 миллисекунд на код, т. е. на порядок производительность приложения снизилась. И когда разрешили аварию у нас стало тратится 20 миллисекунд на запрос, 10 миллисекунд на код. Это значит, что мы все равно просели в полтора раза по производительности. И это все из-за одной транзакции, которая подвисла, причем, возможно, по нашей вине.
- И вопрос: «Как все вернуть назад?», чтобы у нас стало все хорошо и запросы забегали также быстро, как до аварии.

Для этого есть определенный цикл работ, который проводится.
Сначала нам необходимо найти проблемные таблицы, которые раздулись. Мы понимаем, что по каким-то таблицам запись идет более активно, по каким-то менее активно. И для этого используется расширение pgstattuple. Установив это расширение, вы можете написать запросы, которые помогут вам найти таблицы, которые раздулись достаточно сильно.
После того, как вы нашли эти таблицы, их необходимо сжать. Для этого есть уже инструменты. В нашей компании мы используем три инструмента. Первый – встроенный VACUUM FULL. Он жестокий, суровый и беспощадный, но иногда он очень полезен. Pg_repack и pgcompacttable – это сторонние утилиты для сжатия таблиц. И они более бережно относятся к базе данных.
Они используются в зависимости от того, что вам удобнее. Но об этом я расскажу в самом конце. Главное, что есть три инструмента. Есть из чего выбрать.
После того, как мы все поправили, убедились, что все стало хорошо, мы должны знать, как предотвратить эту ситуацию в будущем:
- Предотвращается она достаточно легко. Нужно следить за длительностью сессий на Мастер-сервере. Особенно опасные сессии в состоянии idle in transaction. Это те, которые как раз открыли транзакцию, что-то сделали и ушли или просто повисли, потерялись в коде.
- И для вас, как для разработчиков, важно тестировать код на момент возникновения данных ситуаций. Это не сложно сделать. Это будет полезная проверка. Вы избежите большое количество «детских» проблем, связанных с длительными транзакциями.
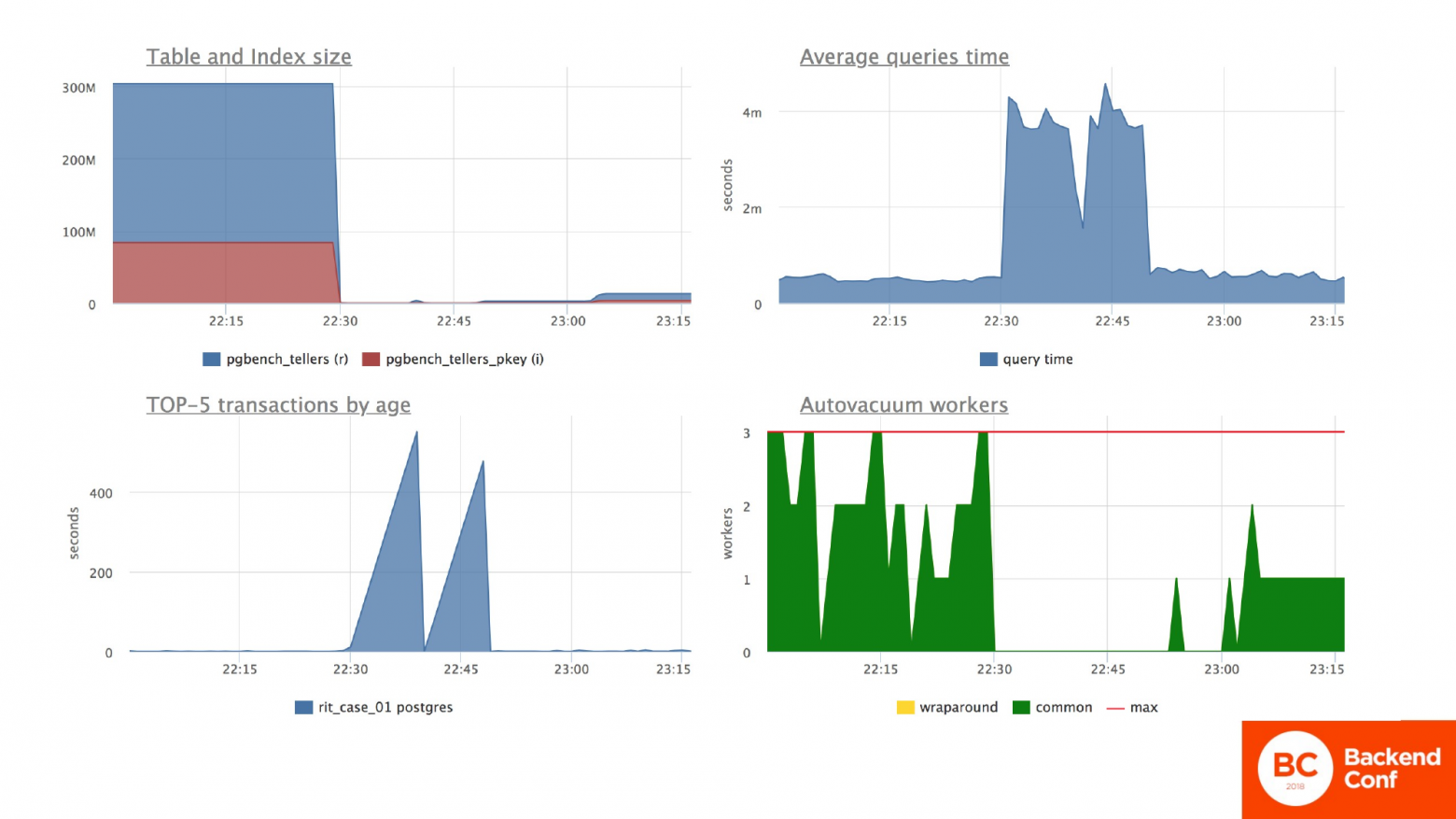
На этих графиках я вам хотел показать, как изменилась табличка и поведение базы данных после того, как я прошел в данном случае VACUUM FULL’ом по табличке. Это у меня не production.
Размер таблицы вернулся сразу в нормальное рабочее состояние в пару мегабайт. На среднее время ответа по серверу это не сильно повлияло.
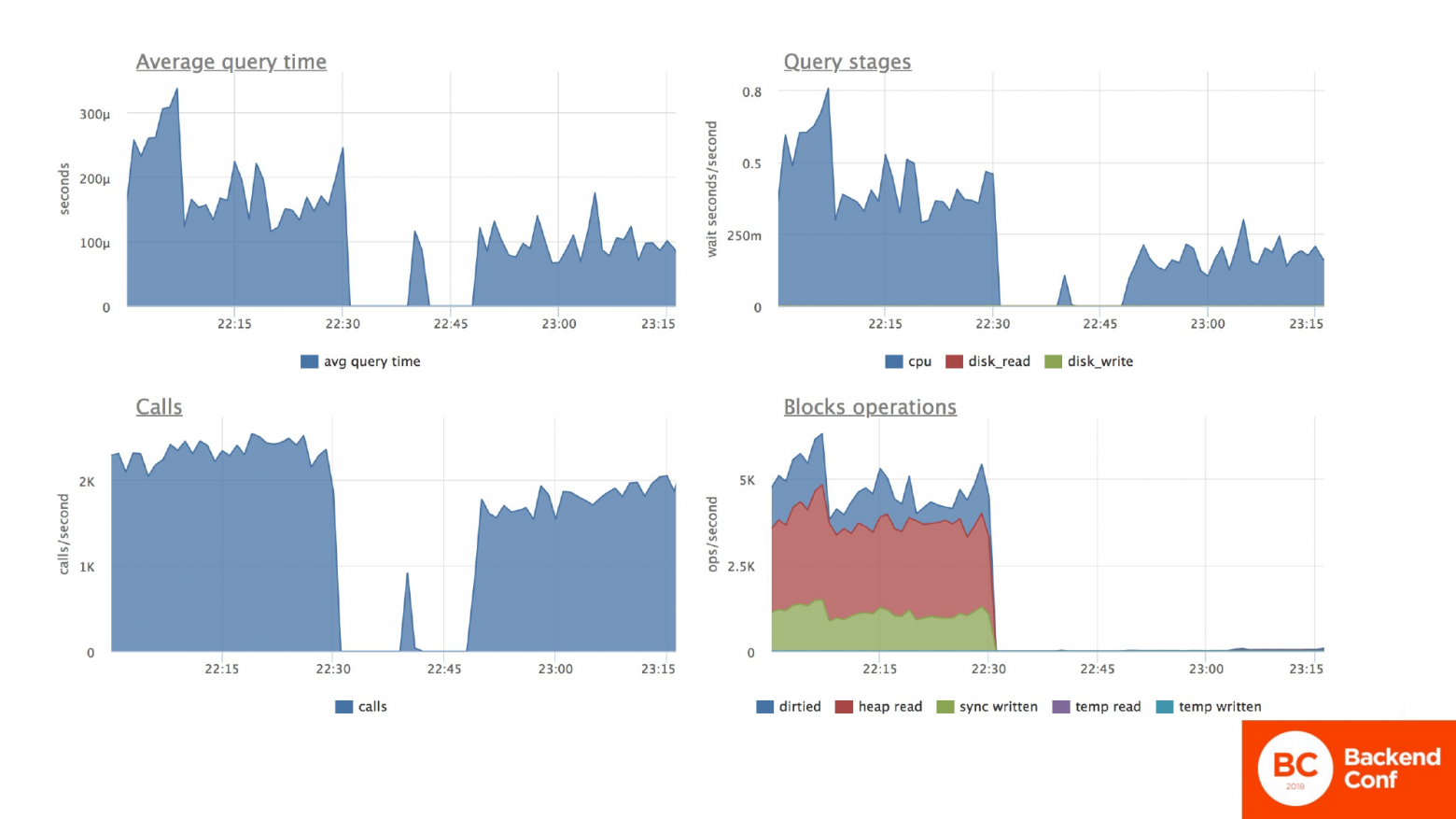
Но конкретно по нашей испытуемой табличке, где мы обновляли остатки на счетах, мы видим, что среднее время ответа по запросу обновления данных в табличке сократилось до доаварийного уровня. Ресурсы, потребляемые процессором на выполнение этого запроса, тоже упали до доаварийного уровня. И правый нижний график показывает, что сейчас мы находим ровно ту строчку, которая нужна нам сразу, не перебирая скоп мертвых строчек, которые были до сжатия таблицы. И среднее время запросов примерно на том же уровне осталось. Но тут у меня, скорее, погрешность моего железа.

На этом первая история закончилась. Она самая распространенная. И случается у всех, независимо от опыта клиента, насколько там квалифицированные программисты. Рано или поздно это происходит.
История вторая, в которой мы распределяем нагрузку и оптимизируем серверные ресурсы

- Мы уже выросли и стали серьезными ребятами. И понимаем, что у нас есть реплика и хорошо бы нам сбалансировать нагрузку: писать на Мастер, а с реплики читать. И обычно эта ситуация возникает, когда мы хотим готовить какие-то отчеты или ETL. И бизнес этому очень радуется. Он очень хочет разнообразных отчетов с кучей аналитики сложной.
- Отчеты многочасовые, потому что сложную аналитику не посчитаешь за миллисекунды. Мы, как бравые ребята, пишем код. Делаем в приложении вставки, что запись мы ведем на Мастер, отчеты выполняем на реплике.
- Распределяем нагрузку.
- Все работает отлично. Мы молодцы.
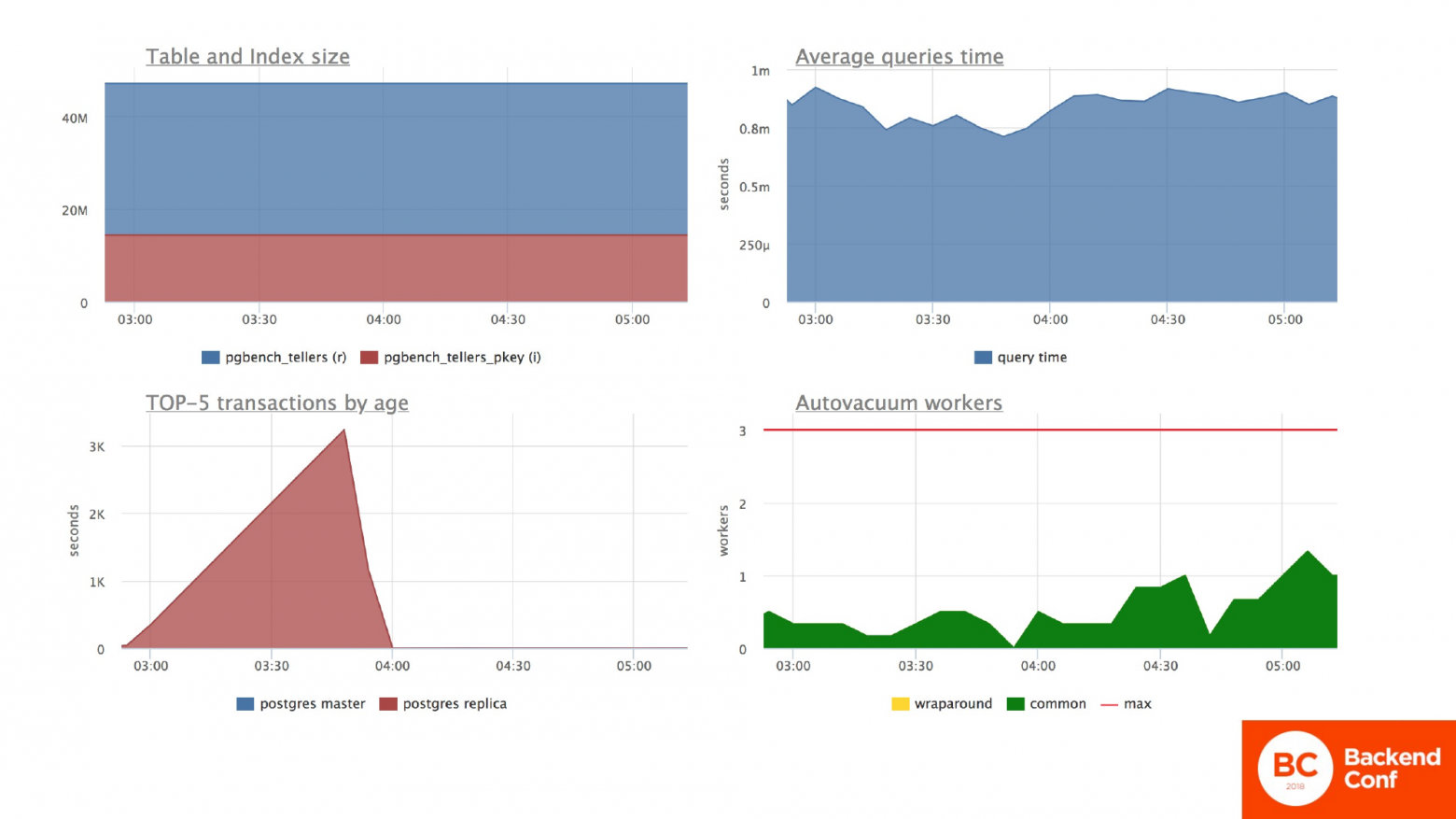
И как это ситуация выглядит? Конкретно на этих графиках я еще для длительности транзакции добавил длительность транзакций с реплики. Все остальные графики относятся только к Мастер-серверу.
Табличка с отчетами к этому моменту у меня подросла. Их стало больше. Мы видим, что среднее время ответа сервера стабильное. Мы видим, что на реплике у нас есть длительная транзакция, которая работает 2 часа. Видим спокойную работу автовакуума, который обрабатывает мертвые строчки. И все у нас хорошо.

Конкретно по испытуемой табличке мы продолжаем там обновлять остатки на счетах. И у нас тоже стабильное время ответа по запросу, стабильное потребление ресурсов. Все у нас хорошо.

Все хорошо до момента, пока у нас эти отчеты не начинают отстреливаться по конфликту с репликацией. И отстреливаются они с постоянной периодичностью.
Мы лезем в интернет и начинаем читать, почему это происходит. И находим решение.
Первое решение – увеличить задержку репликации. Мы знаем, что у нас отчет работает 3 часа. Ставим задержку репликации – 3 часа. Запускаем все, но у нас все равно продолжаются проблемы с тем, что отчеты иногда отстреливаются.
Мы хотим, чтобы у нас все было идеально. Лезем дальше. И находим в интернете классную настройку – hot_standby_feedback. Включаем его. Hot_standby_feedback позволяет нам придержать работу автовакуума на Мастере. Тем самым мы совсем избавляемся от конфликтов репликации. И нас все работает хорошо с отчетами.
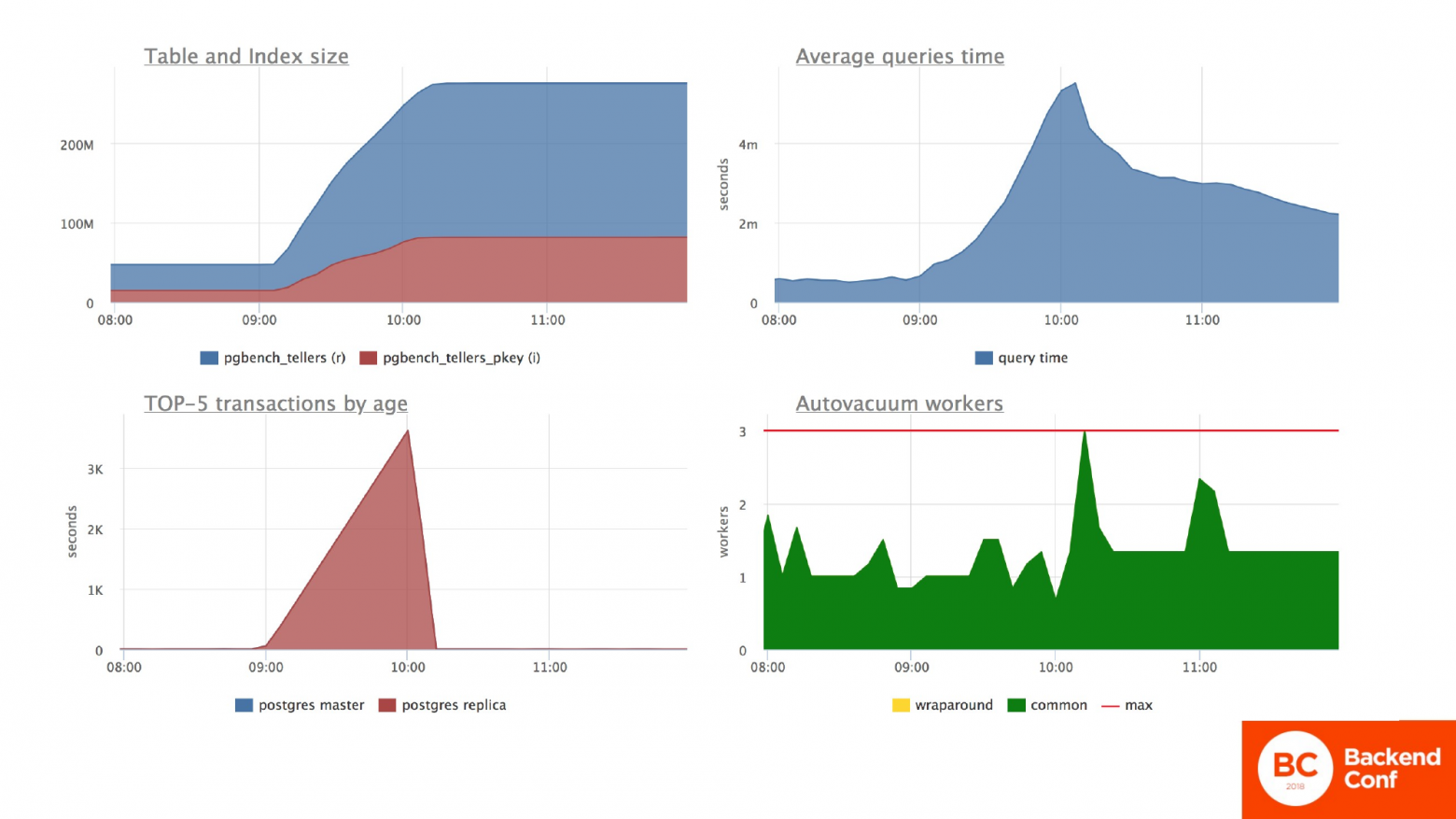
А что в это время у нас происходит с Мастер-сервером? А с Мастер-сервером у нас происходит тотальная беда. Сейчас мы наблюдаем графики, когда я включил обе эти настройки. И мы видим, что сессия на реплике у нас каким-то образом стала влиять на ситуацию на Мастер-сервере. Она действительно влияет, потому что она приостановила автовакуум, который вычищает мертвые строки. У нас размер таблицы снова скакнул в небеса. Среднее время выполнения запросов по всей базе данных тоже скакнуло в небеса. Автовакуумы чуть-чуть поднапряглись.
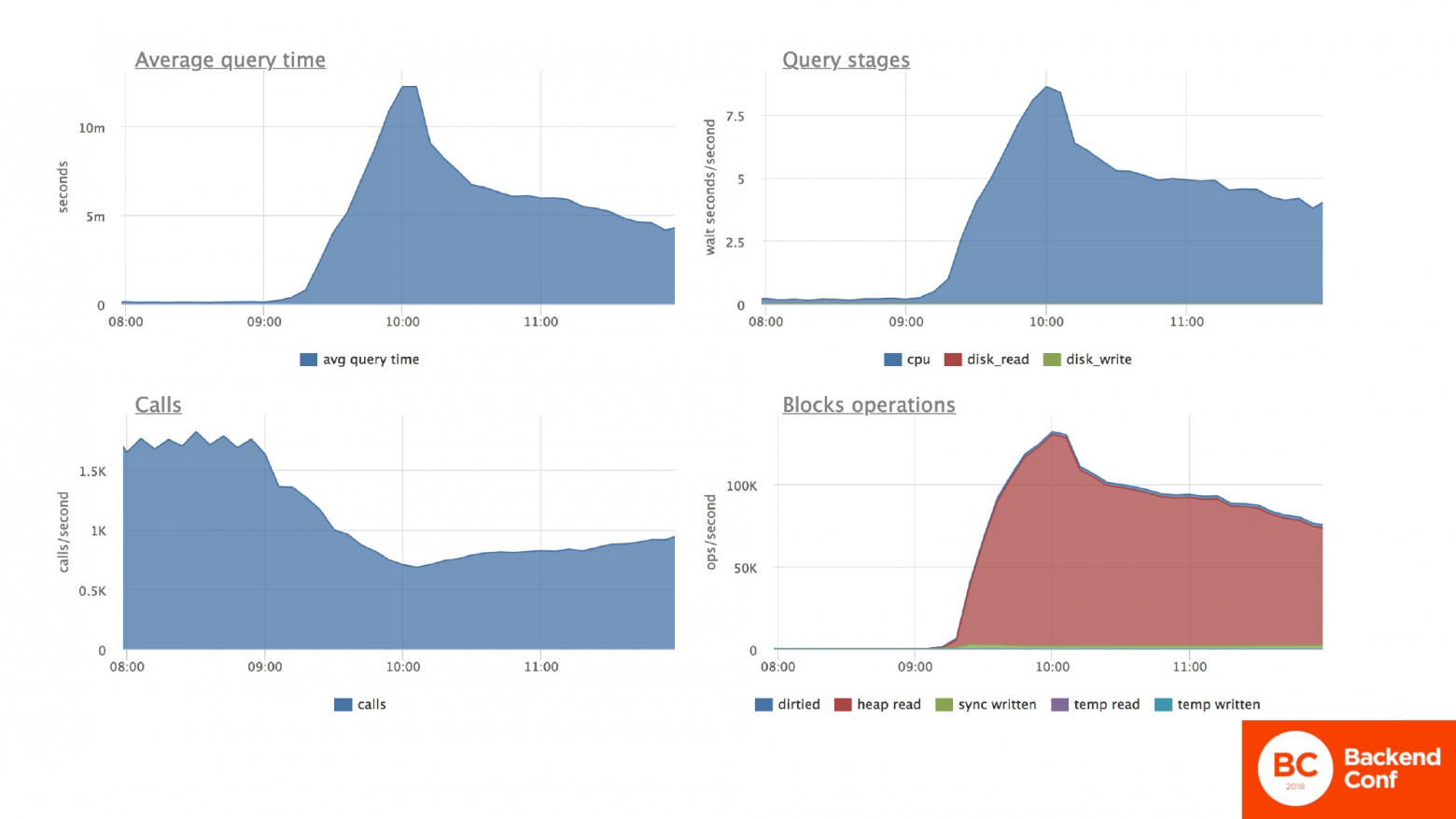
Конкретно по нашей табличке мы видим, что по ней обновление данных тоже скакнуло в небеса. Потребление ресурсов процессора аналогично очень сильно увеличилось. Мы снова перебираем большое количество мертвых бесполезных строчек. И время ответа по этой табличке, количество транзакций упало.

Как это будет выглядеть, если мы не знаем, о чем я говорил до этого?
- Мы начинаем искать проблемы. Если мы сталкивались с проблемами в первой части, мы знаем, что это может быть причина в длинной транзакции и лезем на Мастер. Проблема у нас на Мастере. Колбасит его. Он греется, у него Load Average под сотню.
- Запросы там тормозят, но мы там не видим никаких длительных транзакций. И не понимаем, в чем дело. Не понимаем, где искать.
- Проверяем серверное оборудование. Может быть у нас развалился raid. Может у нас сгорела планка памяти. Да что угодно может быть. Но нет, сервера новые, все работает отлично.
- Бегают все: администраторы, разработчики и директор. Ничего не помогает.
- И в какой-то момент все неожиданно само начинает исправляться.
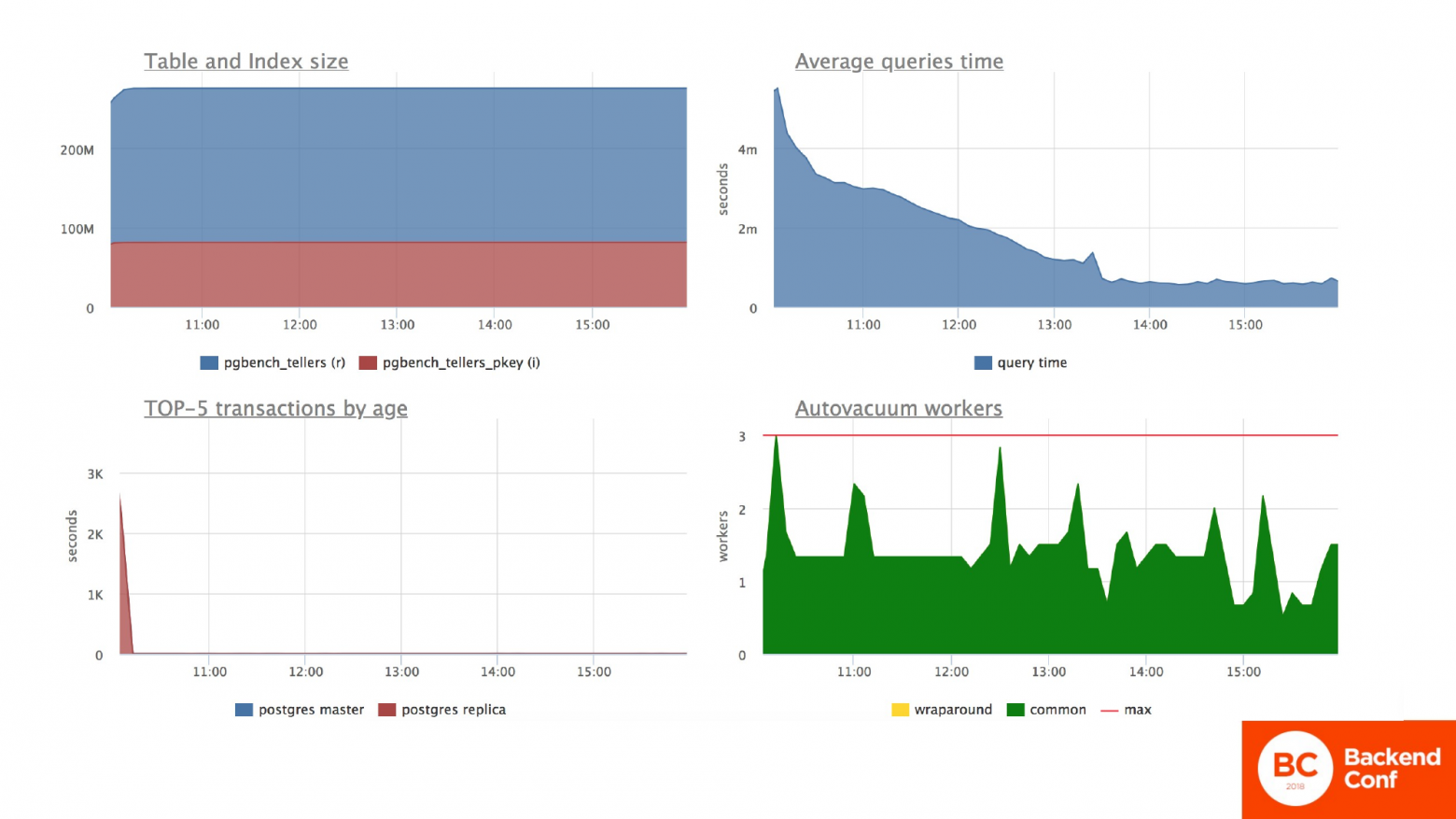
На реплике у нас в это время запрос отработал и ушел. Мы получили отчет. Бизнес все еще довольный. Как видим, табличка у нас выросла снова и не собирается уменьшаться. На графике с сессиями я оставил кусочек вот этой длинной транзакции с реплики, чтобы вы могли оценить, насколько длительное время проходит, пока ситуация стабилизируется.
Сессия ушла. И только через какое-то время сервер приходит более-менее в порядок. И среднее время ответа по запросам на Мастер-сервере приходит в норму. Потому что, наконец-то, автовакуум получил возможность вычищать, помечать эти мертвые строчки. И он начал делать свою работу. И насколько быстро он ее делает, настолько быстро мы придем в порядок.
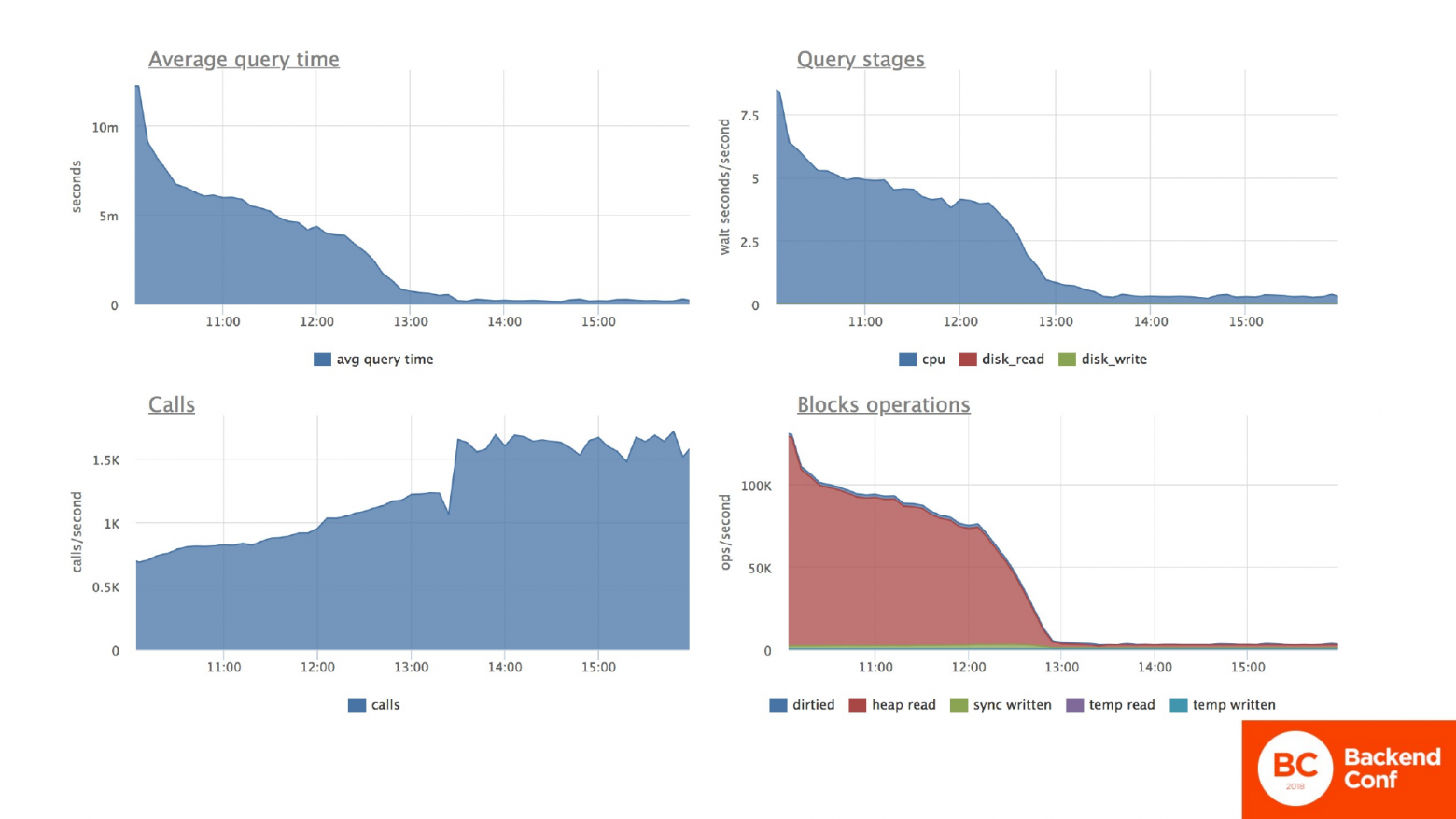
По испытуемой табличке, где мы обновляем остатки по счетам, мы видим точно такую же картину. Среднее время обновления счета тоже нормализуется постепенно. Ресурсы, потребляемые процессором, тоже уменьшаются. И количество транзакций в секунду возвращается в норму. Но снова в норму не в такую, как была у нас до аварии.

Мы в любом случае получаем просадку по производительности как и в первом случае в полтора-два раза, а иногда и больше.
Мы вроде сделали все правильно. Распредели нагрузку. Оборудование не простаивает. По уму разбили запросы, но все равно все плохо получилось.
- Не включать hot_standby_feedback? Да, его без особо сильных причин не рекомендуется включать. Потому что эта крутилка непосредственно влияет на Мастер-сервер и приостанавливает работу автовакуума там. Включив его на какой-то реплике и забыв про это, вы можете убить Мастер и получить большие проблемы с приложением.
- Увеличивать max_standby_streaming_delay? Да, для отчетов – это так. Если у вас трехчасовой отчет и вы не хотите, чтобы он у вас падал из-за конфликтов репликаций, то просто увеличьте задержку. Длительный отчет никогда не требует данных, которые пришли в базу прямо сейчас. Если он у вас трехчасовой, значит, вы его запускаете за какой-то старый период данных. И вам, что три часа задержки, что шесть часов задержки – никакой роли не сыграет, но зато вы будете стабильно получать отчеты и не знать проблем с падением их.
- Естественно, нужно контролировать длительные сессии на репликах, особенно, если вы решили включить hot_standby_feedback на реплике. Потому что может быть что угодно. Дали эту реплику разработчику, чтобы он потестировал запросы. Он написал сумасшедший запрос. Запустил и ушел пить чай, а мы получили сложившийся Мастер. Или мы туда пустили не то приложение. Ситуации разнообразные. Сессии на репликах необходимо контролировать также тчательно, как и на Мастере.
- И если у вас есть быстрые и длительные запросы по репликам, то в данном случае лучше для распределения нагрузки разбить их. Это ссылочка к streaming_delay. Для быстрых иметь одну реплику с небольшой задержкой репликации. Для длительных запросов отчетных иметь реплику, которая может отставать на 6 часов, на сутки. Это вполне нормальная ситуация.
Устраняем последствия все тем же способом:
- Находим раздутые таблицы.
- И сжимаем наиболее удобным инструментом, который нам подходит.
История вторая на этом завершилась. Переходим к истории третьей.

Тоже довольно обычная для нас, в которой мы делаем миграцию.

- Любой программный продукт растет. Меняются к нему требования. Мы в любом случае хотим развиваться. И бывает так, что нам необходимо обновить данные в таблице, именно прогнать апдейт в плане нашей миграции под новый функционал, который мы внедряем в рамках нашего развития.
- Старый формат данных не устраивает. Допустим, мы сейчас обратимся ко второй табличке, где у меня операции по этим счетам. И, допустим, что они были в рублях, а мы решили повысить точность и делать в копейках. И для этого нам нужно сделать апдейт: поле с суммой операции умножить на сто.
- В современном мире мы используем автоматизированные средства контроля версий базы данных. Допустим, Liquibase. Прописываем туда нашу миграцию. Тестируем ее на нашей тестовой базе. Все отлично. Апдейт проходит. Блокирует работу на некоторое время, но зато мы получаем обновленные данные. И можем запускать новый функционал на этом. Все оттестировали, проверили. Все подтвердили.
- Провели плановые работы, провели миграцию.
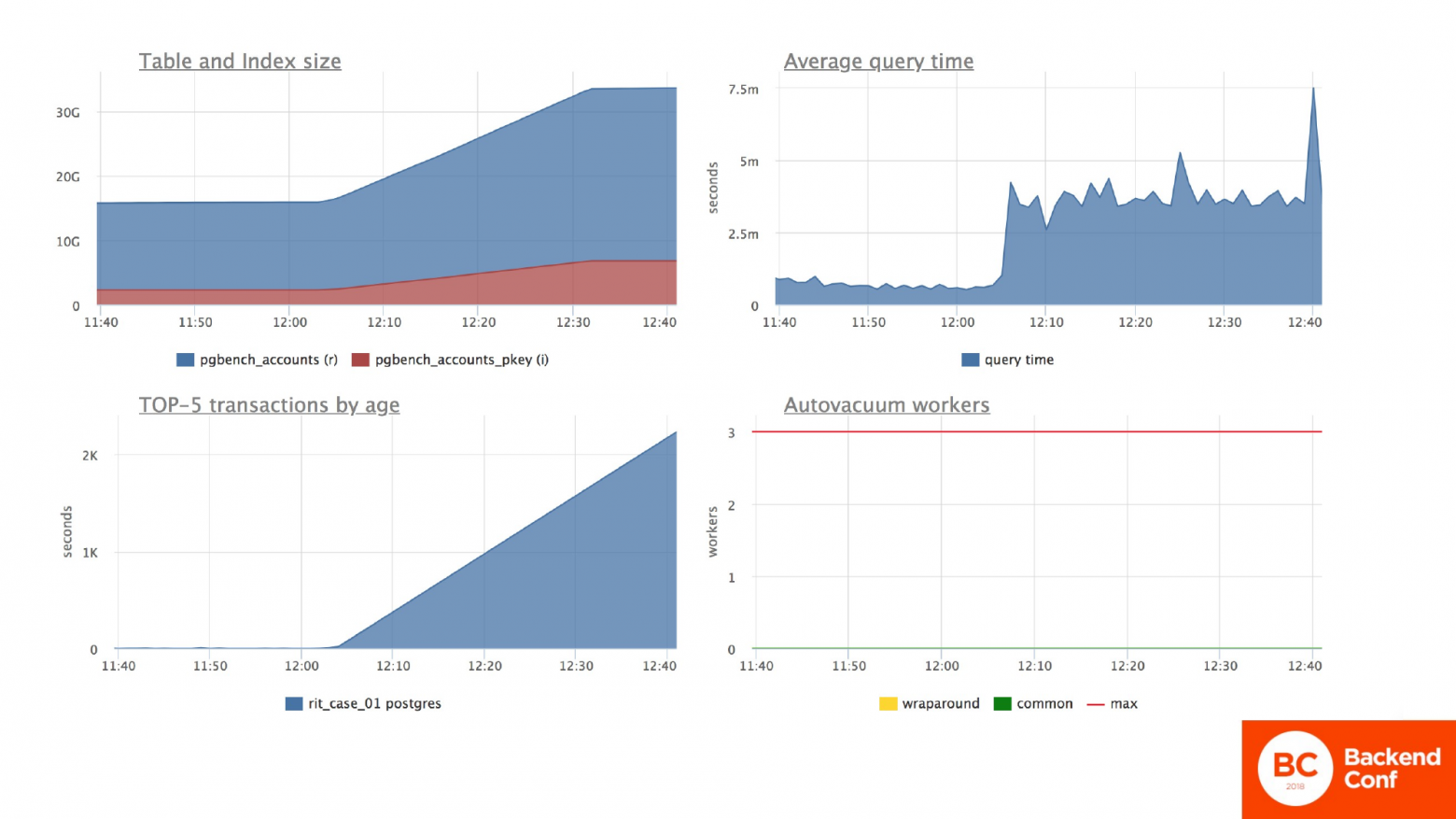
Вот миграция с апдейтом представлена перед вами. Так как это у меня операции по счетам, табличка была в 15 GB. И так как мы обновляем каждую строчку, мы апдейтом раздули табличку в два раза, потому что мы перезаписали каждую строчку.

Во время миграции мы ничего не могли делать с этой табличкой, потому что все запросы к ней встали в очередь и ждали, пока закончится этот апдейт. Но тут я хочу обратить ваше внимание на цифры, которые на вертикальной оси. Т. е. мы имеем среднее время запроса до миграции в районе 5 миллисекунд и нагрузки на процессор, количество блочных операций по чтению памяти диска меньше, чем в 7,5.

Провели миграцию и получили снова проблемы.
Миграция прошла успешно, но:
- Старый функционал стал выполняться дольше.
- Таблица снова выросла в размерах.
- Нагрузка на сервер снова стала больше, чем была.
- И, естественно, мы пока еще возимся с тем функционалом, который работал хорошо, мы его немножко улучшили.
И это снова bloat, который нам снова портит жизнь.
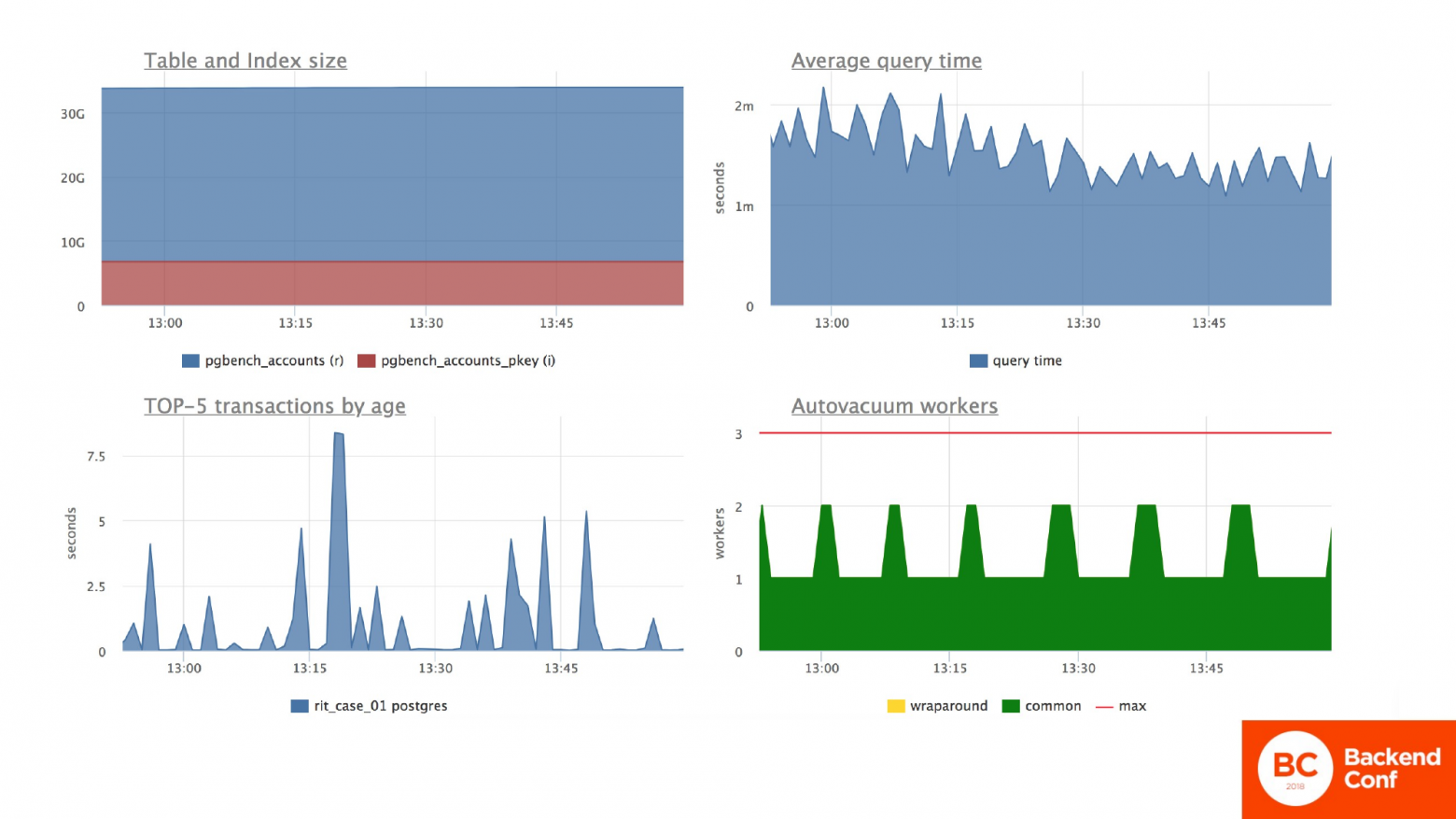
Тут я демонстрирую, что таблица, как и предыдущих двух случаях, не собирается возвращаться к предыдущим размерам. Средняя нагрузка по серверу вроде бы адекватная.
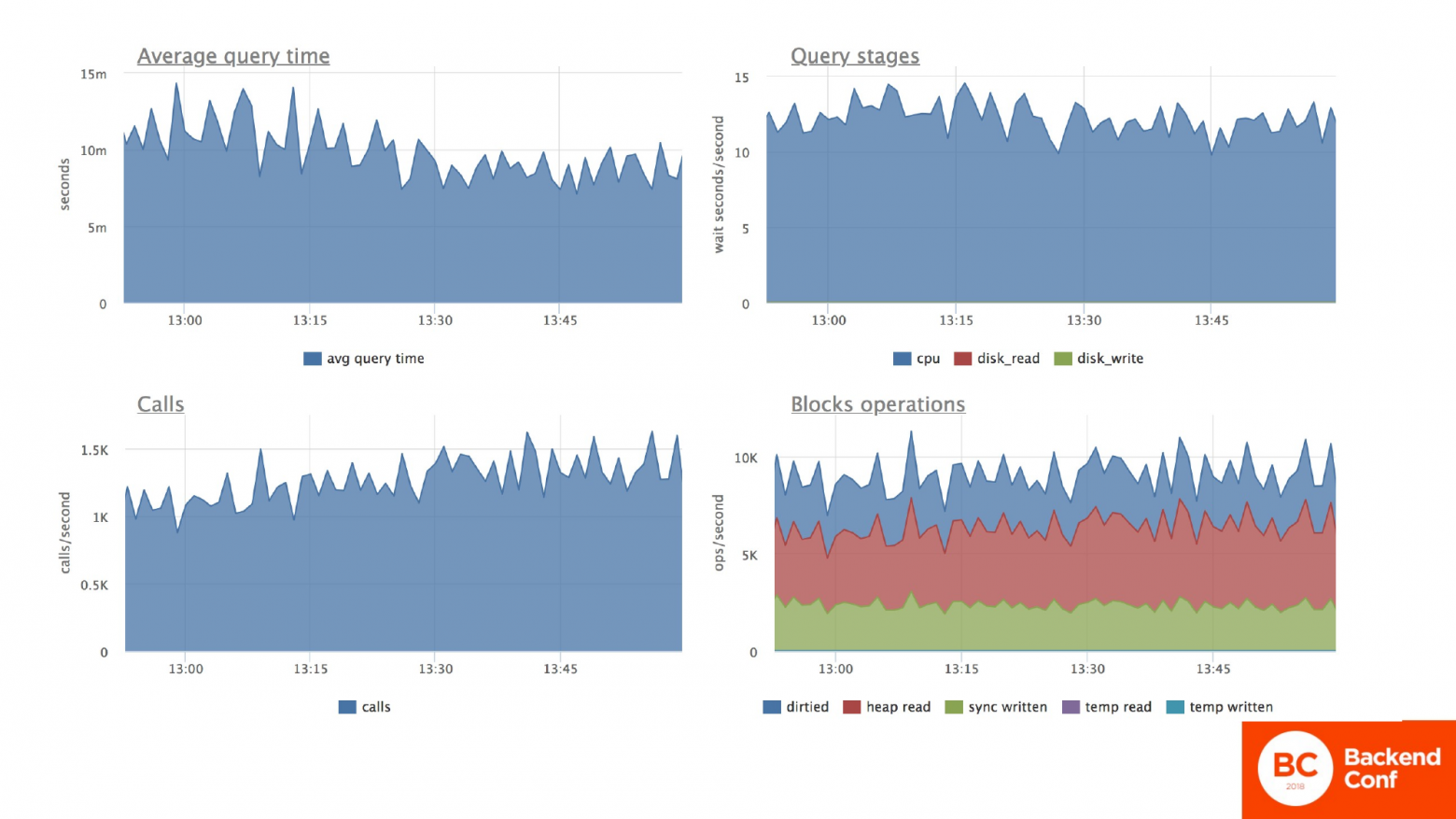
А если мы обратимся к таблице со счетами, то мы увидим, что среднее время запроса у нас выросло в два раза к этой табличке. Нагрузка на процессор и количество перебираемых строчек в памяти скакнуло выше 7,5, а было ниже. И скакнуло в случае процессоров в 2 раза, в случае блочных операций в 1,5 раза, т. е. мы получили деградацию производительности сервера. И как следствие – деградацию производительности нашего приложения. При этом количество вызовов осталось примерно на том же уровне.

И тут главное понимать, как правильно делать такие миграции. А их необходимо делать. Мы довольно постоянно делаем эти миграции.
- Такие большие миграции не делают автоматически. Они всегда должны быть подконтрольные.
- Необходим контроль со стороны знающего человека. Если у вас есть DBA в команде, то пускай это делает DBA. Это его работа. Если нет, то наиболее опытный человек пусть это делает, который знает, как работать с базами данными.
- Новая схема базы данных, даже в случае, если мы обновляем один столбец, мы всегда подготавливаем этапами, т. е. заранее до того, как выкатится новая версия приложения:
- Добавляются новые поля, в которые будем записывать как раз обновленные данные.
- Переносим данные из старого поля в новое поле небольшими частями. Почему мы это делаем? Во-первых, мы всегда контролируем процесс этого процесса. Мы знаем, что мы перенесли уже столько-то батчей и нам осталось столько-то.
- А второй положительный эффект в том, что между каждым таким батчем мы закрываем транзакцию, открываем новую и это дает возможность автовакууму отработать по табличке, пометить мертвые строчки к переиспользованию.
- Для строчек, которые будут появляться в процессе работы приложения (у нас еще работает старое приложение) добавляем триггер, который записывает новые значения в новые поля. В нашем случае – это умноженние на сто старого значения.
- Если мы совсем упертые и хотим то же самое поле, то по завершению всех миграций и перед накатом новой версии приложения, мы просто переименовываем поля. Старые в какое-нибудь придуманное название, а новые поля переименовываем в старые.
- И только после этого запускаем новую версию приложения.
И при этом мы не получим bloat и не просядем по производительности.
На этом третья история закончилась.

https://github.com/dataegret/pg-utils/blob/master/sql/table_bloat.sql
https://github.com/dataegret/pg-utils/blob/master/sql/table_bloat_approx.sql
И сейчас немножко более подробно об инструментах, которые я упоминал в самой первой истории.
До того, как искать bloat, нужно обязательно поставить расширение pgstattuple.
Чтобы вам не придумывать запросы, мы в своей работе уже написали эти запросы. Вы можете их использовать. Тут представлено два запросы.
- Первый довольно длительно работает, но зато он вам покажет точные значения bloat по таблице.
- Второй работает побыстрее и очень эффективен, когда нужно быстро оценить – есть bloat или нет bloat по таблице. И еще вы должны понимать, что bloat в таблице Postgres есть всегда. Это особенность его модели MVCC.
- И 20 % bloat – это нормально для таблиц в большинстве случаев. Т. е. вам не стоит переживать и сжимать эту таблицу.
Как выявлять таблицы, которые у нас распухли, мы разобрались, причем, когда распухли бесполезными данными.
Теперь о том, как исправлять bloat:
- Если у нас небольшая табличка и хорошие диски, т. е. на табличке до гигабайта вполне возможно использовать VACUUM FULL. Возьмет он у вас блокировку на таблицу эксклюзивную на несколько секунд и ладно, зато быстро и жестко все сделает. Что делает VACUUM FULL? Он берет эксклюзивную блокировку на таблицу и из старых таблиц переписывает живые строки в новую таблицу. И в конце подменяет их местами. Старые файлы удаляет, новые подставляет вместо старых. Но на время своей работы он берет эксклюзивную блокировку таблицы. Это означает, что вы с этой таблицей ничего не сможете сделать: ни писать в нее, ни читать в нее, ни модифицировать ее. И VACUUM FULL требует дополнительное место на диске, чтобы записать данные.
- Следующий инструмент pg_repack. По своему принципу он очень похож на VACUUM FULL, потому что он тоже переписывает данные из старых файлов в новые и подменяет их в таблице. Но при этом не берет эксклюзивную блокировку на таблицу в самого начала своей работы, а берет только в момент, когда у него уже готовые данные для того, чтобы подменить файлики. Требования по дисковым ресурсам у него аналогичные как у VACUUM FULL. Вам нужно дополнительное место на диске, а это иногда бывает критично, если у вас терабайтные таблицы. И он довольно прожорлив по процессору, потому что ведет активную работу с вводом-выводом.
- Третья утилита – это pgcompacttable. Она более бережно относится к ресурсам, потому что работает немного по другим принципам. Основная суть у pgcompacttable в том, что она апдейтами в таблице переносит все живые строки в начало таблицы. И потом запускает вакуум по этой таблице, потому что мы знаем, что у нас в начале живые, а в конце мертвые строки. И вакуум уже сам отрезает этот хвостик, т. е. дополнительного дискового пространства он не сильно требует. И при этом его еще можно по ресурсам ужимать.
С инструментами все.

Если вам тема с bloat покажется интересной в плане покопаться дальше вовнутрь, то вот вам некоторые полезные ссылки:
- https://www.slideshare.net/alexius2Mb/where-is-the-space-postgres – это доклад моего коллеги. Он общий о том, куда девается место у Postgres в процессе его работы и жизни. И там очень большой и подробный кусок технический для администраторов баз данных о bloat.
- https://github.com/dataegret/pg-utils – это ссылка на наш репозиторий, где мы храним кучу полезных скриптов на проверку состояния базы данных. Там вы можете найти скрипты по поиску bloat.
- Третья и четвертая ссылки на инструменты, которые вам помогут ужимать таблички.
- http://blog.dataegret.com/2Mb018/03/postgresql-bloatbusters.html – это пост моего коллеги. Там он довольно серьезно и подробно технически разбирает bloat именно уже на уровне близкому к администраторам.
Я тут больше постарался показать страшилку для девелоперов, потому что они являются непосредственными нашими клиентами баз данных и должны понимать, к чему и какие действия ведут. Надеюсь у меня это получилось. Спасибо за внимание!
Вопросы
Спасибо за доклад! Вы говорили о том, как можно выявлять проблемы. А как их можно предупреждать? Т. е. у меня была ситуация, когда запросы висели не только по причине того, что они обращались к каким-то внешним сервисам. Это были просто какие-то дикие joins. Были какие-то малюсенькие запросы безобидные, которые сутки висели, а потом начинали творить какую-то ерунду. Т. е. очень похоже на то, что вы описываете. Как это отслеживать? Сидеть и постоянно смотреть, какой запрос завис? Как можно это предупредить?
В данном случае – это задача для администраторов вашей компании, необязательно для DBA.
Я администратор.
В PostgreSQL есть такое представление, как pg_stat_activity, в котором показаны висящие запросы. И вы можете увидеть, насколько долго он там висит.
Я должна каждые 5 минут заходить и смотреть?
Настройте cron и проверяйте. Если у вас возник длительный запрос, пишите письмо и все. Т. е. вам не нужно глазами смотреть, это можно автоматизировать. Вам придет письмо, вы на него реагируете. А можете автоматически отстреливать.
Есть явные причины, почему это происходит?
Я некоторые перечислил. Другие более сложные примеры. И там разговор надолго может быть.
Спасибо за доклад! Про утилиту pg_repack хотел уточнить. Если она не делает эксклюзивную блокировку, то…
Она делает эксклюзивную блокировку.
… то я потенциально могу потерять данные. Мое приложение ничего не должно записывать в это время?
Нет, оно спокойно работает с таблицей, т. е. pg_repack переносит сначала все живые строчки, которые есть. Естественно, там какая-то запись в таблицу происходит. Он просто этот хвостик докидывает.
Т. е. он в конце все-таки делает?
В конце он берет эксклюзивную блокировку на то, чтобы подменять местами эти файлы.
Это будет быстрее, чем VACUUM FULL?
VACUUM FULL, как стартанул, сразу взял эксклюзивную блокировку. И пока он все не сделает, он ее не отпустит. А pg_repack берет эксклюзивную блокировку только на момент замены файлов. В этот момент вы туда не запишите, но данные не потеряются, все будет в порядке.
Здравствуйте! Вы рассказывали про работу автовакуума. Там был график с красными, желтыми и зелеными ячейками записи. Т. е. желтые – он пометил как удаленные. И в следствие в них можно что-то записать новое?
Да. Postgres не удаляет строчки. У него такая специфика. Если мы обновили строчку, мы старую пометили как удаленную. Там встает id транзакции, который изменил эту строчку, и записываем новую строчку. И у нас есть сессии, которые потенциально могут их читать. В какой-то момент они уже совсем старыми становятся. И суть работы автовакуума в том, что он пробегается по этим строчкам и помечает их как ненужные. И туда можно перезаписать данные.
Я понял. Но вопрос немножко не об этом. Я не договорил. Предположим, что у нас есть таблица. В ней есть поля переменного размера. И если я попытаюсь что-то вставить новое, то это может в старую ячейку просто не влезть.
Нет, там в любом случае вся строчка обновляется. В Postgres есть две модели хранения данных. Он выбирает от типа данных. Есть данные, которые хранятся непосредственно в таблице, а есть еще tos-данные. Это большие объемы данных: текст, json. Они хранятся в отдельных табличках. И по этим табличкам происходит та же история с bloat, т. е. все тоже самое. Просто отдельно они вынесены.
Спасибо за доклад! Насколько приемлемо использовать для ограничения длительности запросы statement timeout?
Очень приемлемо. Мы везде это используем. И т. к. у нас своих сервисов нет, мы оказываем удаленную поддержку, то довольно разнообразные клиенты есть. И всех вполне удовлетворяет это. Т. е. у нас есть задания в cron, которые проверяют. Просто с клиентом оговаривается длительность сессий, раньше которой мы не прибиваем. Это может быть минута, это может быть 10 минут. Это зависит от нагрузки на базу и ее цели. Но у всех мы используем pg_stat_activity.
Спасибо за доклад! Пытаюсь примерить ваш доклад к своим приложениям. И вроде бы мы везде стартуем транзакцию, везде явно ее завершаем. Если какой-то exception, то все равно rollback происходит. И тут я задумался. Ведь может транзакция стартануть не явно. Это подсказка девушке, наверное. Если я просто делаю обновление записи, транзакция стартанет в PostgreSQL и завершится она только тогда, когда произойдет отключение соединения?
Если вы говорите сейчас об уровне приложения, то это зависит от того драйвера, который вы используете, от того ORM, который используется. Там очень много настроек. Если у вас включен auto commit on, то там стартует транзакция, тут же закрывается.
Т. е. закрывается она сразу после апдейта?
Это зависит от настроек. Одну настройку я назвал. Это auto commit on. Она довольно распространенная. Если она включена, то открылась-закрылась транзакция. Если вы явно не сказали «start transaction» и «end transaction», а просто запустили в сессию запрос.
Здравствуйте! Спасибо за доклад! Представим, что у нас есть база, которая пухнет-пухнет и тут на сервере кончается место. Есть какие-то инструменты, чтобы исправить эту ситуацию?
Место на сервере по-хорошему нужно мониторить.
Например, DBA пошел пить чай, был на курорте и т. д.
Когда создается файловая система, то там как минимум какое-то резервное место создается, куда не пишутся данные.
А если совсем под ноль?
Там так и называется reserved space, т. е. его можно освободить и в зависимости от того, насколько большим его создали, вы получили свободное место. По умолчанию я не знаю, сколько там. А в другом случае – доставлять диски, чтобы у вас было место провести операцию восстановительную. Можно удалить какую-то таблицу, которая вам гарантированно не нужна.
Других инструментов нет?
Это всегда ручная работа. И по месту выявляется, что там лучше сделать, потому что есть данные критичные, есть некритичные. И для каждой базы и приложения, которое с ней работает, это зависит от бизнеса. Всегда по месту решается.
Спасибо за доклад! У меня два вопроса. Во-первых, вы демонстрировали слайды, где показывалось, что в случае зависших транзакций растет как и объем табличного пространства, так и размер индекса. И дальше по докладу была куча утилит, которые пакуют табличку. А что с индексом?
Они тоже пакуют их.
Но вакуум не затрагивает индекс?
Некоторые работают с индексом. Например, pg_repack, pgcompacttable. Вакуум пересоздает индексы, затрагивает их. У VACUUM FULL суть в том, чтобы все перезаписать, т. е. он со всеми работает.
И второй вопрос. Я не понял, почему отчеты на репликах так сильно зависят от самой репликации. Мне казалось, что отчеты – это чтение, а репликация – это запись.
В чем возникает конфликт репликации? У нас есть Мастер, на котором происходят процессы. У нас происходит автовакуум. Автовакуум по факту, что делает? Он выпиливает какие-то старые строчки. Если у нас в это время на реплике идет запрос, которые читает эти старые строчки, а на Мастере произошла ситуация, что автовакуум пометил эти строчки как возможные для перезаписи, то мы их перезаписали. И у нас пришел пакет данных, когда мы должны перезаписать те строчки, которые нужны запросу на реплике, то процесс репликации подождет тот тайм аут, который вы настроили. И потом PostgreSQL будет решать, что важнее для него. А репликация для него важнее, чем запрос и он отстрелит запрос, чтобы выполнить эти изменения на реплике.
Андрей, есть вопрос. Вот эти замечательные графики, которые вы показывали во время презентации, это результат работ, какой-то вашей утилиты? Чем строили графики?
Это сервис Okmeter.
Это коммерческий продукт?
Да. Это коммерческий продукт.

