Это первая статья из небольшого цикла о графическом языке программирования G, который используется в LabVIEW. Язык этот пока не очень популярен — по индексу TIOBE на май 2020 года LabVIEW находится на сороковом месте аккурат между Julia и Haskell. Выпуск LabVIEW Community Edition даёт возможность значительно расширить аудиторию пользователей (раньше можно было пользоваться только триальной версией, а по истечении 45-и дней учиться "вприглядку").
Что ж, как говорили великие Керниган и Ритчи — "единственный способ научиться новому языку программирования — это начать на нём программировать". Этим и займёмся.
В первой части мы разберём основные элементы среды разработки, и нарисуем на блок-диаграмме наш первый "Hello, World!"

Статья-туториал рассчитана на тех, кто видит LabVIEW впервые. Под катом полсотни картинок примерно на семь мегабайт.
Введение
Предполагается, что вы уже справились с установкой и активацией LabVIEW NXG.
Основное отличие от имеющихся учебных материалов будет заключаться в том, что мы будем изучать этот язык с точки зрения средства разработки "общего назначения". В процессе изложения я буду пытаться также проводить параллели с текстовыми языками чтобы показать некоторые отличия от "традиционных" средств разработки. Для иллюстрации я буду использовать C# (в минимальном варианте, доступном и тем, кто понимает базовый синтаксис языка С). Изложение будет настолько подробным, насколько возможно, по мере углубления в дебри LabVIEW степень "подробности" основ будет уменьшаться. Также потребуется минимальное знание английского — русской локализации LabVIEW пока нет.
Итак, LabVIEW программа собирается из отдельных "кирпичиков", которые называются "Виртуальные Инструменты" ("Virtual Instruments") или коротко VI. Первые версии LabVIEW предназначались для превращения ПК в измерительный прибор-инструмент, так что исторически за ними и закрепилось такое вот название. Также как С# программа собирается из отдельных *.cs файлов, также и LabVIEW программа собирается из VI файлов (в классической LabVIEW 2020 у них расширение *.vi, а в NXG — *.gvi). Множественные файлы объединяются в проекты. Единственное отличие — представьте себе, что вы организуете проект таким образом, что в каждом файле лежит только одна функция (ну или метод класса, если будет угодно). В небольшом проекте счёт отдельных виртуальных инструментов может идти на десятки, в проектах средних размеров — на сотни, а в больших проектах — тысячи их (предполагается, что размер кода в каждом отдельном инструменте находится в пределах разумного). Вот сейчас я работаю над проектом, в котором семь с лишним тысяч VI и это довольно большой проект.
При первом запуске LabVIEW NXG покажет нам вот такое окно:
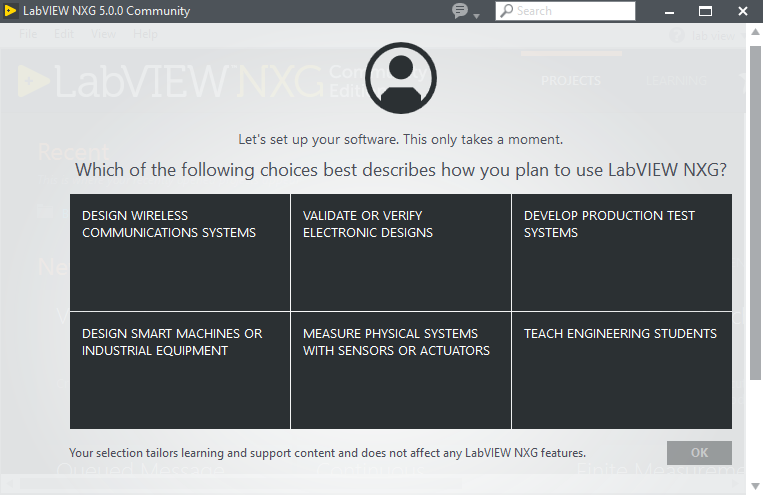
Здесь перечислены шесть основных направлений, в которых применяется LabVIEW. В принципе без разницы, что вы здесь выберете, просто для некоторых направлений разработки или обучения нам рекомендуется "классическая" LabVIEW, а для некоторых — NXG, поскольку функциональность NXG пока проигрывает классической LabVIEW, но команда NI работает в этом направлении, а нам для изучения и NXG хватит с лихвой.

На этот вопрос нужно ответить всего один раз, после этого NXG будет запускаться вот так:

Виртуальный инструмент
Создадим наш первый инструмент, выбрав в меню File->New VI...:

После этого откроется основное окно — это наше рабочее пространство. При первом запуске нам покажут подсказки (если вы их закроете, то для того, чтобы их вызвать снова, надо нажать вопросик в правом верхнем углу).
Элементы рабочего пространства:
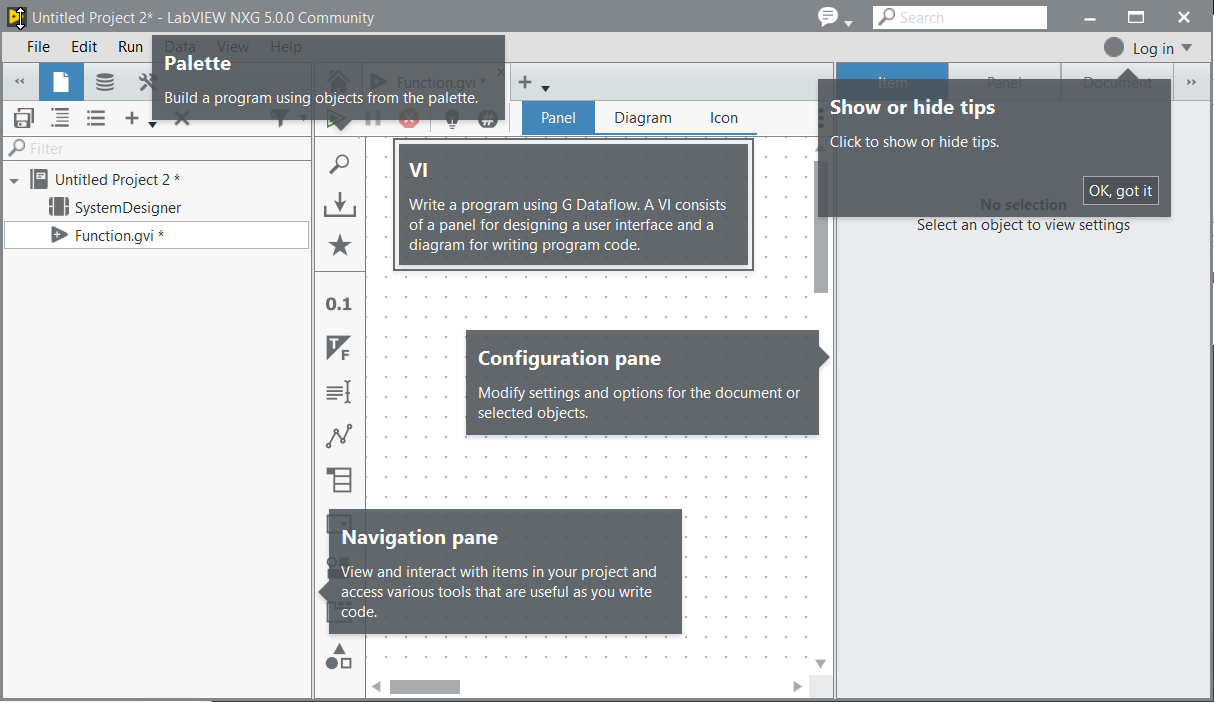
В левой части находится дерево для навигации по файлам проекта (Navigation Pane), в середине — основное пространство для программирования (VI), там же слева палитра инструментов (Palette), а справа — свойства для конфигурирования, вид которых меняется в зависимости от выбранных элементов (Configuration Pane), а снизу будет панель ошибок и предупреждений.
Нас в данный момент интересует средняя панель (VI). Вообще Виртуальный Инструмент VI обычно состоит из двух основных частей — Блок-Диаграммы (Block Diagram) и Передней Панели (Front Panel). Переключатель расположен в верхней части — Panel и Diagram (Icon — это иконка инструмента, мы её разберём попозже).
Блок-Диаграмма
Отложим пока что переднюю панель в сторону и займёмся блок-диаграммой. Очень часто программистам LabVIEW задают вопрос — ну картинки картинками, а код-то где? Вот собственно блок-диаграмма и есть ваш код. Щелкните по вкладке Diagram в верней части. Вот наше рабочее пространство:
Обычно изучение нового языка начинается с "Привет, мир!"-подобной программы, выводящей что-то в консоль, ну как-то вот так:
Console.WriteLine("Hello World!");
Где тут консоль? — этот вопрос возникает у многих программистов, ранее работавших с текстовыми языками. Консоли здесь как таковой нет, так что ниже мы будем выводить модальное диалоговое окошко. Если проводить аналогию с текстовыми языками, то, пожалуй самым ближайшим аналогом будет С# с WPF. Аналогом блок диаграммы у нас является *.cs файл исходного кода, а аналогом передней панели — соответствующий *.xaml файл с разметкой с той разницей, что в LabVIEW обе части находятся в одном *.gvi файле.
Кстати, если вы решили основательно заняться NXG, то есть ещё одна причина для того, чтобы изучить C#/WPF — вы сможете делать сборки, расширяющие интерфейс пользователя и логику (да, свои сборки .net можно подключать к графическому языку, в том числе включающие WPF контролы можно вкорячить в переднюю панель — для этого есть API).
Соответственно вывод диалогового окошка самым простым способом в C# реализуется как-то так:
const string message = "Hello, Habr!"; MessageBox.Show(message);
В принципе даже если вы не знаете C#, тут всё достаточно просто — объявляется строковая константа и выводится диалог. Если уж быть совсем дотошным, то MessageBox — это класс, из которого мы вызываем метод Show (документация для любопытных).
Вот давайте сделаем примерно тоже самое в LabVIEW. Нам понадобится строковая константа и собственно диалог.
Функции работы со строками находятся в палитре DataTypes вот здесь:

А собственно строковая константа находится вот здесь:

Поначалу обилие иконок может смущать, но к ним довольно быстро привыкаешь (кроме того есть и другие способы доступа к функциям, о которых я расскажу ниже).
Перетащим строковую константу мышкой на блок-диаграмму:

Теперь нам ещё диалог потребуется, он находится вот здесь в палитре "User Interface":
Перетащим и его на блок-диаграмму:

Обратите внимание, что при наведении мышки слева у диалога мы видим две малиновые (или пурпурные, в общем цвета "magenta") точки слева и зелёную справа — они называются терминалами. Слева терминалы входные, а справа — выходной. Восклицательный знак у верхнего терминала означает, что этот терминал (message) обязательно должен быть куда-то подключён, а вот второй терминал — не обязательный, и по умолчанию его значение "OK". Разный цвет терминалов связан с типами данных — для строк они малиновые, для чисел — синие для целых или оранжевые для плавающей точки и так далее. Зелёный означает что выход представляет собой логический (булевый) тип данных (в случае однокнопочного диалога возвращаемое значение будет всегда true).
Вот теперь разместим эти два элемента рядышком, наведём мышку на выходной терминал строковой константы — курсор превратится в катушку, щёлкнем по малиновой точке и соединим выход константы со входом диалога (держать постоянно зажатой кнопку можно, но не нужно), завершив создание проводника щелчком по входному терминалу диалога (либо отпустив кнопку мыши, если вы держали её нажатой):

Ну а в самой константе наберём какой-либо текст (указатель мыши "умный", он меняется в зависимости от контекста использования):
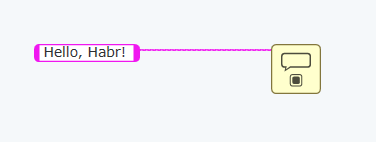
(если у вас возникли сложности — промотайте статью чуть ниже — там есть анимированный gif)
Этот код — суть квинтэссенция графического программирования, основанного на потоках данных (Data Flow).
Константа является источником данных. Диалог является приёмником данных. Соединяющий проводник ("Wire") переносит данные от источника к приёмнику.
Общепринято направление потока данных "слева направо". То есть источники надо располагать левее, а приёмники — правее, так, чтобы поток данных шёл слева направо.
Один источник может быть подключён к нескольким приёмникам, но не наоборот.

Почему нельзя — объясняется в окне предупреждений и ошибок в нижней части экрана. Когда ошибок много — двойной щелчок подсветит место ошибки.
И вот так делать не стоит (хотя код этот вполне работоспособен, так как простое перемещение элементов на диаграмме суть косметическое изменение, не влияющее на логику потоков данных):

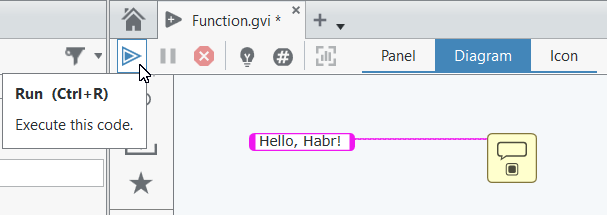
Как это запустить? Очень просто — надо нажать зелёную стрелочку вот здесь — Run Execute this code:
Результатом будет диалог:

Обратите внимание на сочетание клавиш "Ctrl+R" для запуска VI. Запомните его, оно будет использоваться очень часто.
Также обратите внимание, что нам не пришлось компилировать программу, мы просто запустили её. Идеология LabVIEW заключается в том, что программа всегда находится в памяти в уже скомпилированном виде. В сложных случаях, при первом запуске инструмента с большим количеством кода, когда компиляция будет занимать ощутимое время, вам будет показано окошко, примерно вот такое:
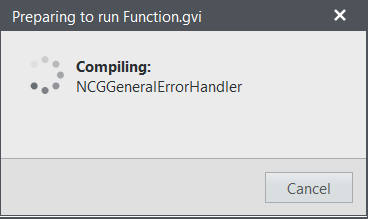
"Принудительная перекомпиляция" возможна, для этого надо щёлкнуть по кнопке Run, удерживая нажатой клавишу "Контрол".
Вы можете визуализировать потоки данных, передающихся по проводникам, включив режим подсветки выполнения, это делается вот здесь:
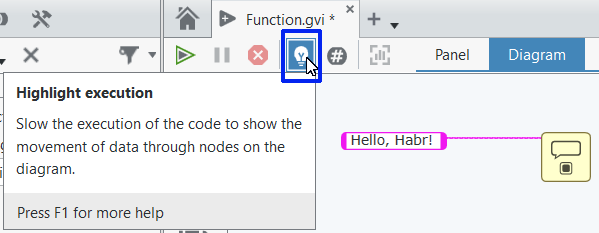
Вот как это выглядит всё вместе:

Теперь мне хотелось бы подчеркнуть очень важный для понимания идеологии потоков данных момент.
Давайте сделаем пару копий нашего кода.
Лайфхак: копипастить код в LabVIEW можно традиционным способом, нажимая клавиши Ctrl+C/Ctrl+V (нужно выделить код, нажать Ctrl+C, затем щёлкнуть мышкой там, где хотим вставить и нажать Ctrl+V), но есть способ чуть проще — нужно выделить код, затем просто нажать клавишу Ctrl и удерживая её (возле курсора появится плюсик), перетащить копию на новое место. При этом если ещё и клавишу Shift зажать, то перемещение будет происходить строго по вертикали или горизонтали — так вы будете копипастить аккуратнее. Вот так (первую копию я сделал традиционным способом, а вторую — удерживая клавишу Ctrl):
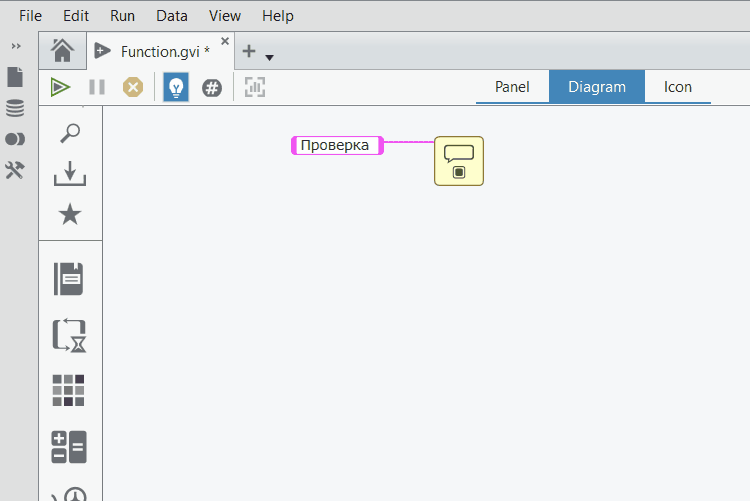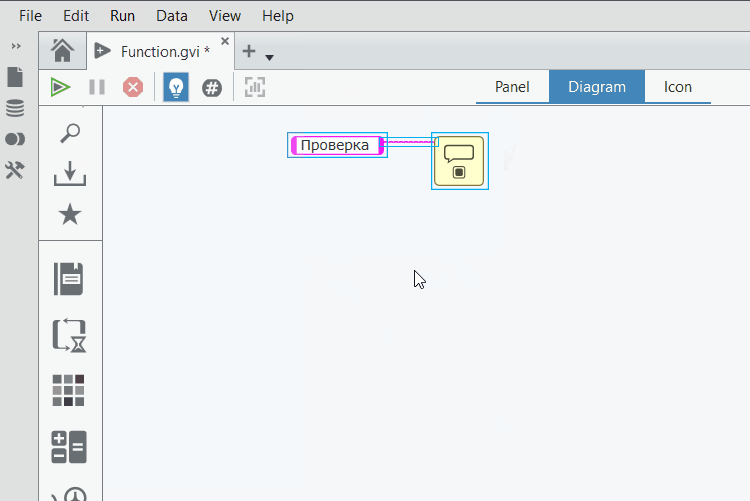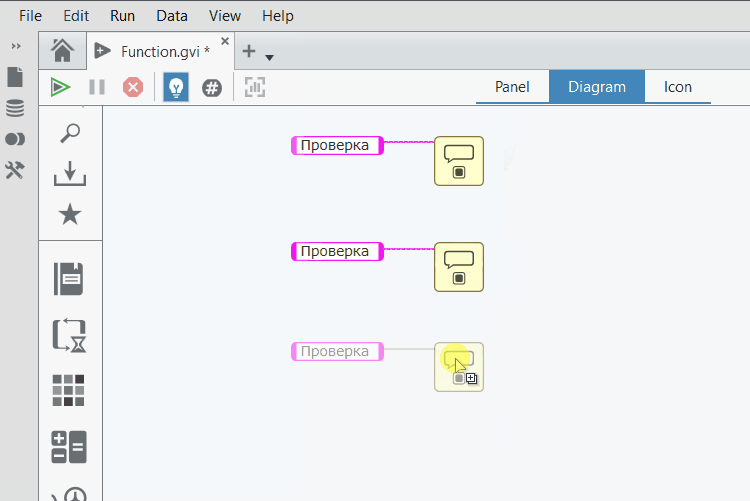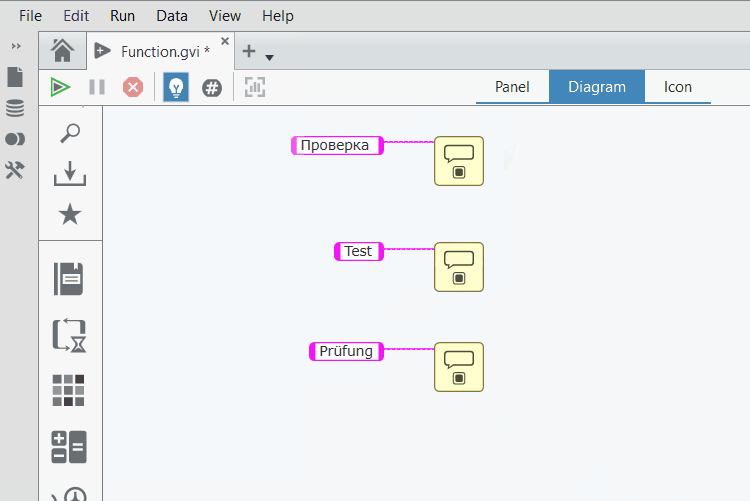
Получилось вот что:
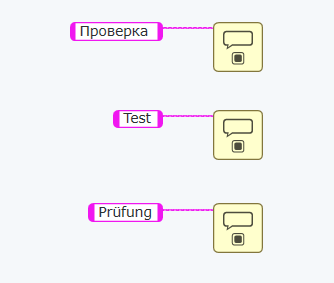
И вот дело в том, что глядя на этот код вы не можете утверждать в каком порядке появятся эти три диалога. В этом смысле мы имеем неопределённое поведение. В этом заключается кардинальное отличие графического программирования от текстового, в котором операторы выполняются последовательно и у вас не возникает сомнений в каком порядке будут выведены три диалоговых окна:
MessageBox.Show("Проверка"); MessageBox.Show("Test"); MessageBox.Show("Prüfung");
вот смотрите, кто бы сомневался (совместно с кириллическими символами я использую немецкое слово с умляутом, чтобы уж заодно проверить код на "юникодность"):
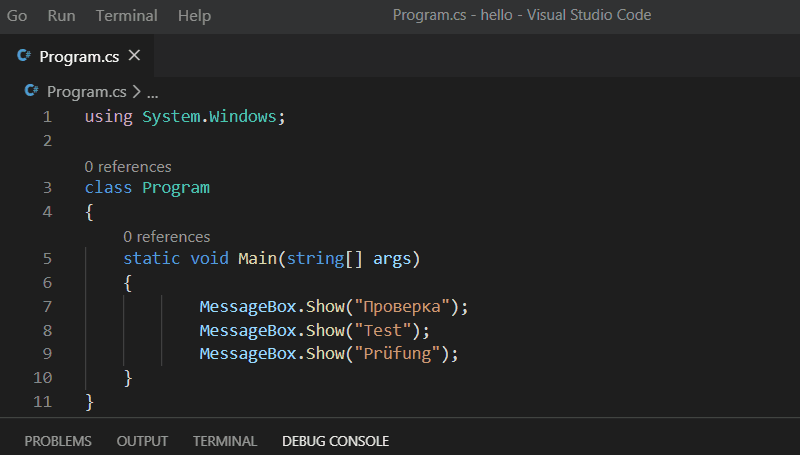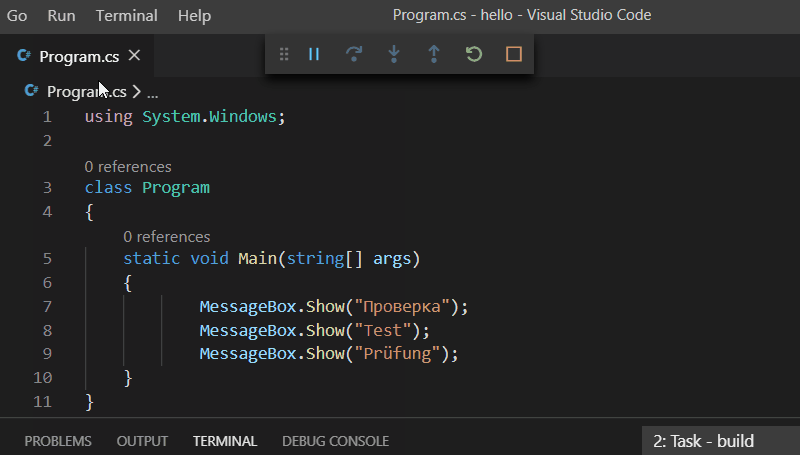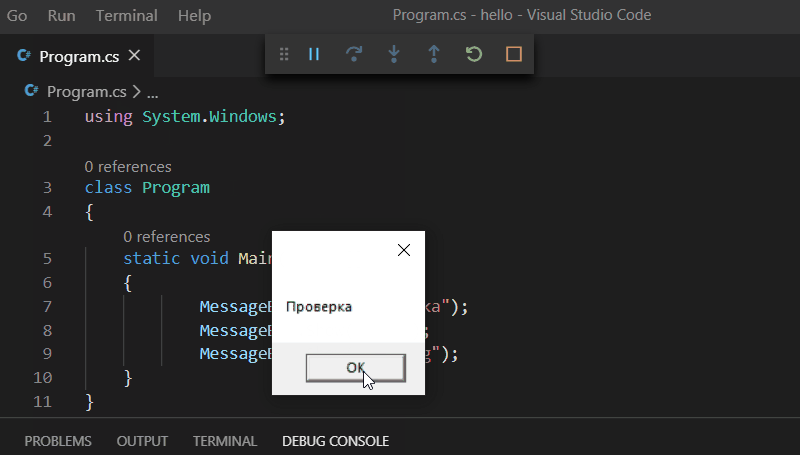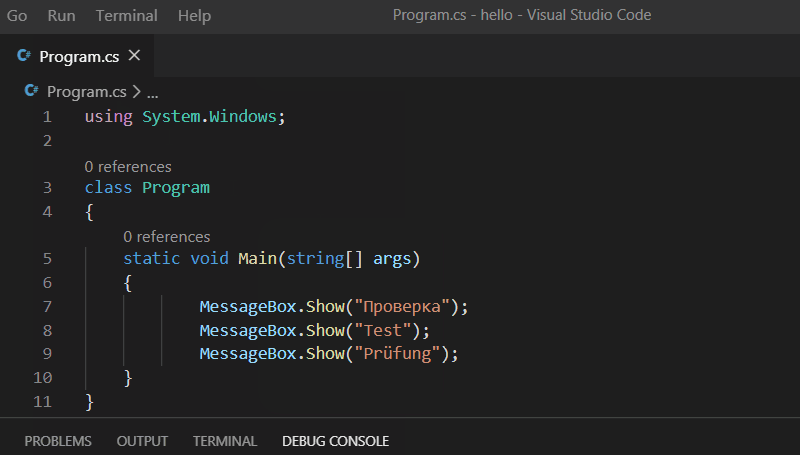
Ну а в LabVIEW вот так:

Для упрощения можно считать, что несвязанный потоками данных код просто выполняется параллельно (хотя это строго говоря и не совсем так), факт в том, что порядок выполнения не определён.
Можно ли явно задать порядок выполнения кода? Да, можно, для этого существует управляющая структура.
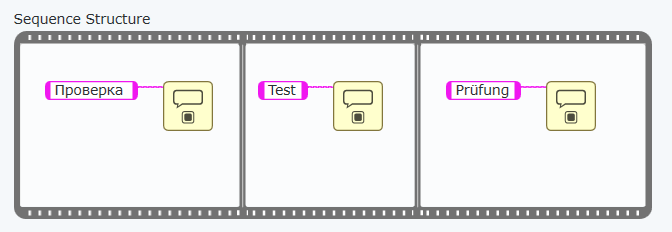
Однако избыточное использование этой структуры считается "плохим тоном" (я на данном этапе даже не буду показывать где она находится). В некоторых случаях её применение оправдано, но каждый раз, когда вы будете использовать эту структуру, есть повод спросить себя "а не стоит ли сделать рефакторинг кода и избавиться от структуры последовательности?"
Аксиома: От любой структуры последовательности всегда можно избавиться. Любой код, содержащий эту структуру, можно изменить таким образом, что порядок выполнения будет задан потоками данных и никак иначе.
На этом можно было бы и остановиться для начала, но давайте рассмотрим среду разработки чуть повнимательнее.
Эффективная работа в LabVIEW
Перетаскивание примитивов из палитр на диаграмму и панель не является самым эффективным способом. Палитры нужны в том числе для того, чтобы понять какие функции есть в нашем распоряжении, но если вы точно знаете, какой элемент вам нужен, то его название можно начать вводить в строке поиска, вот здесь:

Если вы внимательно посмотрите на это окно, то увидите справа сочетания 1dg, 2dg и так далее. Это — короткие сочетания, то есть вместо "One Button Dialog" или "Dialog" можно сразу написать "1dg" и нажать клавишу "Ввод". Если в списке присутствует несколько элементов, то между ними можно перемещаться стрелочками, и выбрав нужный, нажать Enter.
Окно поиска также не требует клика мышкой — для этого есть сочетание клавиш Ctrl+Space (удерживая контрол надо нажать пробел). Это сочетание называется "Quick Drop" и этот метод реально ускоряет работу. Конечно, вы не выучите сразу все сочетания-шорткаты, это придёт постепенно, но этим надо пользоваться.
В том случае если вы забыли и хотите посмотреть, в какой палитре находится тот или иной элемент, надо просто навести указатель мыши на правую часть окошка — появится кнопка "Show in Palette"

При щелчке по этой кнопке откроется соответствующая палитра, где элемент будет подсвечен.
Вам также не всегда нужно открывать основную палитру — щелчок правой кнопкой мышки в свободной области диаграммы откроет компактное окно, в котором прямо под курсором мыши будет доступ ко всем палитрам. Наиболее часто используемые элементы можно добавить в фавориты, также тут есть доступ к ещё неразмещённым "Unplaced" элементам (об этом в следующей части). В целом это даже удобнее чем в "классической" LabVIEW (хотя Quick Drop есть и там).

Теперь по поводу констант. Их тоже можно "доставать" из быстрого доступа (попробуйте нажать клавиши Ctrl+Space, затем sc — это строковая константа):
Но если константа, скажем, нужна для подключения к терминалу диалога, то значение можно ввести в свойствах вот здесь:
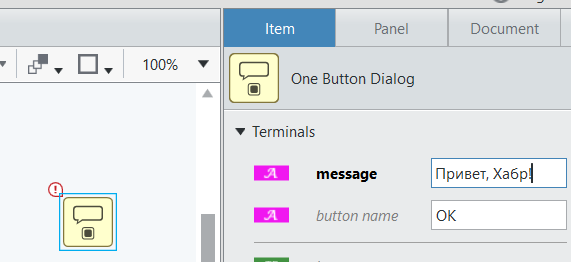
Соответственно один из самых быстрых способов "наброса" кода на диаграмму выглядит примерно вот так:

Здесь я нажал последовательно: <Ctrl+пробел>, затем набрал "1dg", затем <Ввод>, щелкнул на диалоге, ввёл "Hello, Habr" и нажал <Ctrl+R>.
Если вам нужно добавить собственные заметки на диаграмму, то достаточно дважды щёлкнуть в свободном месте и начать вводить текст:

Если полёт вашей мысли заполнил весь экран и вам нужно больше свободного места, то его легко добавить, нажав на клавиатуре клавишу Контрол и очертив область для расширения, вот так:

Как видите, это работает "в обе стороны" — можно не только добавлять свободное пространство но и "убирать" его, делая диаграмму более компактной.
Да, кстати, хорошим тоном считается не превышать размер экрана, чтобы при просмотре диаграммы вообще не пользоваться скроллингом. Это не всегда будет получаться на первых порах, но если размер диаграммы растёт, то лучше делать это только в одном направлении — вертикальном или горизонтальном.
Последнее, о чём хотелось бы рассказать сегодня — контекстные меню и свойства. В LabVIEW довольно много функций доступно через контекстные меню, вызываемые правой кнопкой мыши.
У нас три элемента всего — константа, соединительный проводник и диалог, посмотрите на их контекстные меню:

Некоторый пункты требуют более глубоких знаний (всему своё время), но часть из них уже можно прокомментировать:
Константа:
Dock to node — "прилепит" константу к терминалу, что даст боле компактное представление на диаграмме. Ровно тоже самое произойдёт, если в контекстном меню диалога выбрать Terminals->Dock constants, с тем лишь исключением, что это будет относиться к нескольким константам подключённым к диалогу, если таковые имеются:

Обратите внимание на маленькие приятные детали — если значение константы совпадает со значением терминала по умолчанию (в нашем случае "ОК" — это текст, который будет на кнопке), то терминал будет не закрашен. А вот если я изменю значение по умолчанию, то он будет залит (сравните вид второго и третьего диалогов).
Show in Palette в меню константы и диалога откроет соответствующую палитру и покажет вам, откуда был взят элемент.
Clean up wire в меню проводника "почистит" проводник если вы сделали "спагетти":

Create branch — создаст новую ветку для проводника. Допустим вам одну константу надо в двух диалогах использовать:
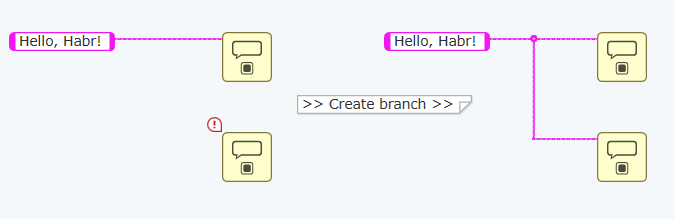
Delete Branch — пояснений не требует. Удалять проводники можно и наживая клавишу "Del", при этом обратите внимание как происходит выделение:

При первом щелчке по вертикальному сегменту выделится только один сегмент, при втором щелчке — дополнительно горизонтальный, а при третьем — весь проводник, включая все ответвления. Так что для эффективной работы надо овладеть искусством тройного щелчка. Собственно во многих текстовых редакторах это работает похожим образом — при щелчке ставится курсор, двойной щелчок выделяет слово, тройной — строку ну и так далее.
Create wire comment позволяет добавить комментарий проводнику — это удобно в случае длинных проводников:

В верхней части контекстных меню находятся кнопки Insert или Replace. Это позволяет заменять элементы, либо вставлять какую-либо функцию прямо в проводник, не требуя возни с удалением проводника и последующим пересоединением. Вот как это работает — я заменю диалог на двухкнопочный и вставлю функцию конвертации строки в верхний регистр:
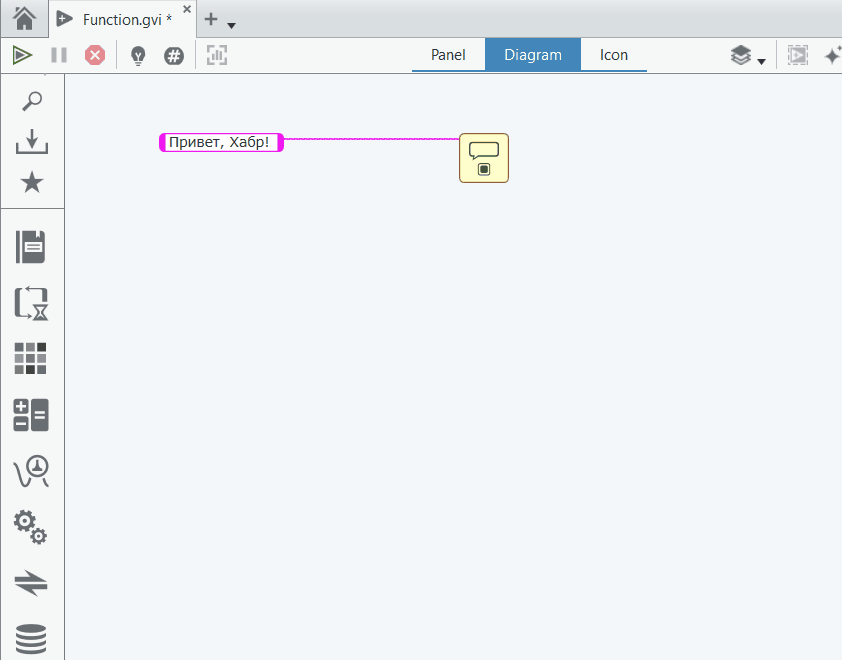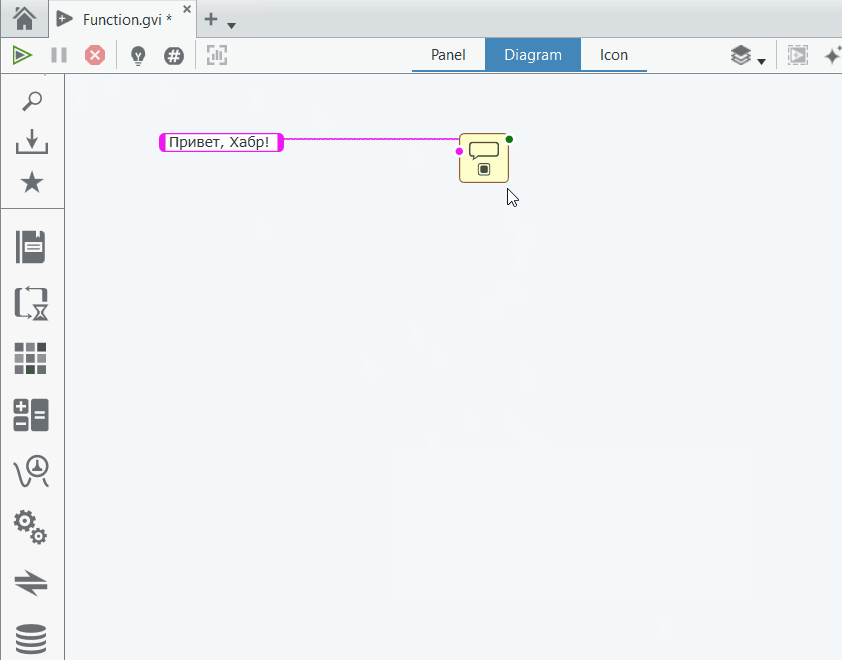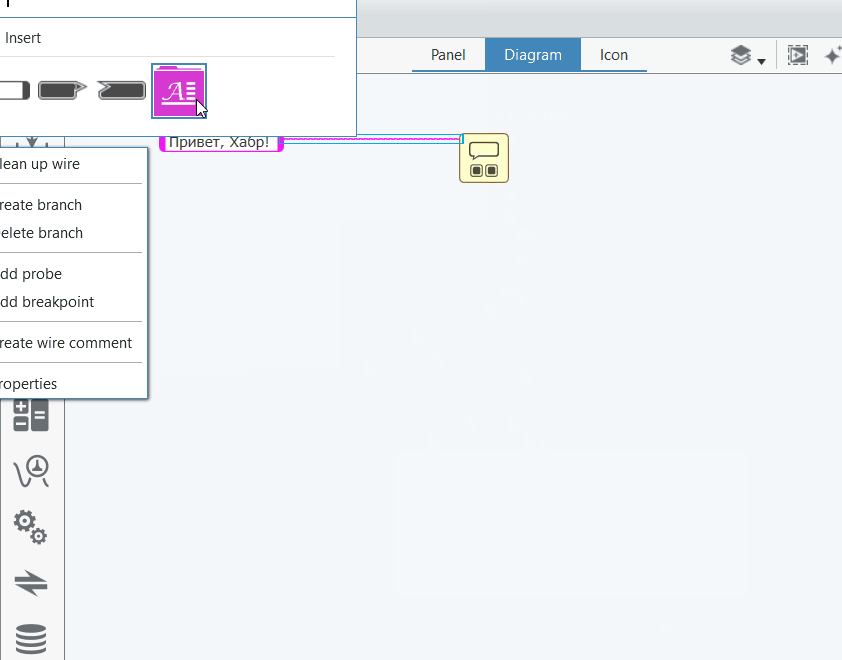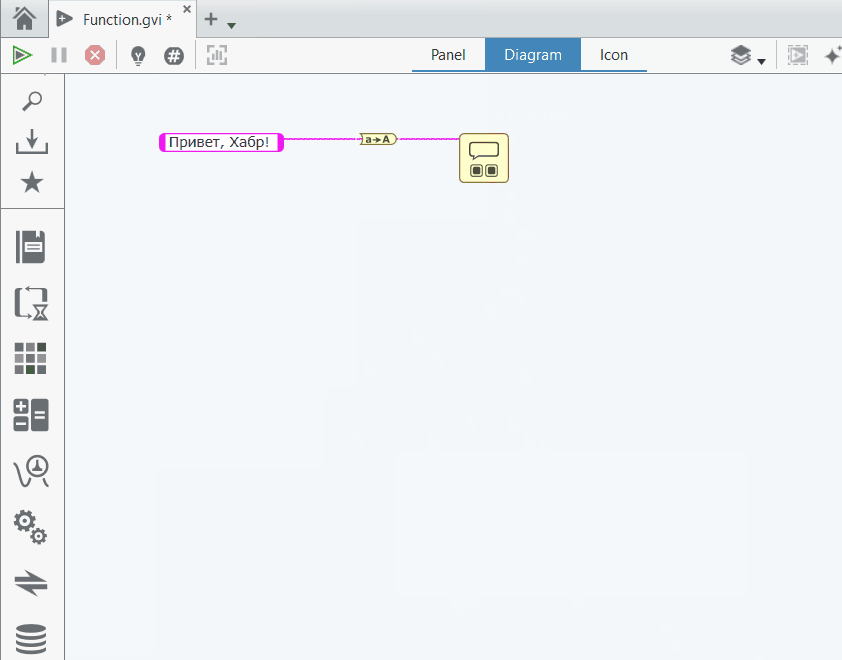
Properties — откроет панель свойств в правой части. Вот как она выглядит для всех трёх элементов (слева направо — строковая константа, проводник и диалог соответственно):

Для строки:
Constant configuration используется если вам нужна определённая константа, типа табуляции или пробела — для них есть наглядное визуальное представление, кроме того это защитит вас от случайного изменения такой константы.
Display Format -> Show escape sequences позволяет вам переключиться на вот такое представление:

Используется если вам надо чётко видеть все символы в строке.
Visual style -> Show Label позволяет включить подписи:

У константы подпись можно изменить, равно как и размещение слева/внизу/вверху, у диалога — нельзя. Кстати, подпись у константы — это всего лишь метка для вашего удобства, а не её имя. Ну то есть вы можете иметь две константы с одинаковой подписью, и это — две разные константы:

Если вам нужно использовать одну константу в нескольких местах, то единственно правильный способ вот такой:

Layout -> Size to content можно отключить, если вам нужно ввести много текста:
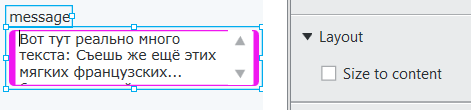
У проводника в окне свойств вы видите тип и можете изменить комментарий, если надо.
Что касается окна свойств диалога, то тут вы можете "прилепить" константы к диалогу как это было показано выше, а также изменить визуальное представление:
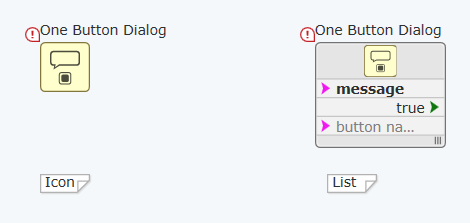
Иконка более компактна, зато список позволяет видеть все терминалы, обязательные к подключению отображаются при этом жирным шрифтом, кроме того порядок их можно поменять, если нужно (это не меняет функциональность, лишь позволяет лучше разместить проводники, чтобы избежать пересечений:

Если вы выделяете несколько однотипных элементов (это делается удерживая клавишу Shift), то общие для всех свойства также отображаются (ну то есть можно включить отображение меток сразу для всех выделенных элементов).
В нашем случае окошки свойств были очень простые, но в зависимости от сложности используемых элементов их вид будет меняться и может быть гораздо сложнее.
Ну и напоследок по окошкам свойств — здесь можно включить контекстную помощь:

Окошко это всегда можно вызвать нажав Ctrl+H. Вид его меняется в зависимости от выделенного элемента и это удобно (также используется, чтобы посмотреть документацию к библиотекам, тип данных на проводниках и так далее).
В конце настало время сохранить наш "Hello, Habr!". Тут всё просто:

Для нас был создан проект, по умолчанию всё сохраняется в "Мои документы" — там будет создана папка "LabVIEW Projects".
Любопытные могут заглянуть внутрь файла — там обычный XML, в котором можно разглядеть нашу диаграмму.
<BlockDiagram Id="a44ad16c1aa64eb9940a6db1357f6f34"> <OneButtonDialog Bounds="230 236 40 40" Id="abd1e9094fb74fe3ae59249f61acaa0b" /> <Literal Bounds="100 236 100 15" DataType="String" Id="99b8849aac10420386a3c64b659755e8" Label="e03893aa5f6948b4b8f028ffff4aaa45" xmlns="http://www.ni.com/MocCommon"> <p.Data>Привет, Хабр!</p.Data> <StringBehavior TextDisplayMode="Default" /> </Literal> <NodeLabel AttachedTo="99b8849aac10420386a3c64b659755e8" Bounds="100 234 30 15" Id="e03893aa5f6948b4b8f028ffff4aaa45" Visible="False" xmlns="http://www.ni.com/PlatformFramework"> <p.Text>message</p.Text> </NodeLabel> <Wire Id="4e45a6a724704c38b808a29f3417ce9b" Joints="N(99b8849aac10420386a3c64b659755e8:Out)|(200,237) N(abd1e9094fb74fe3ae59249f61acaa0b:message)|(230,237)" xmlns="http://www.ni.com/PlatformFramework" /> </BlockDiagram>
В "классической" LabVIEW эти файлы были двоичные, что сводило с ума системы контроля версий, теперь стало чуть лучше. Можно увидеть наш диалог, константу, и проводник, их соединяющий, причём все атрибуты и координаты хранятся тут же.
Вот, собственно и всё на сегодня. Мы рассмотрели блок-диаграмму, сделали простую программку, разучили сочетания клавиш Ctrl+R, Ctrl+H, Ctrl+Пробел и освоились в среде разработки.
На следующем занятии мы потрогаем переднюю панель и сделаем что-нибудь чуть более полезное — Основы работы с Передней Панелью — Контролы и Индикаторы

