Примеры для двух неблокирующих библиотек доступа к SQL базам данных — Vert.X SQL и R2DBC. Примеры будут основаны на PostgreSQL и реактивных обертках Java.

Начнем с главного: JDBC — это отличный стандарт. Служил и служит верой и правдой.
Но новые веяния просят новых решений. И даже есть смысл иногда потеснить JDBC.
Я предлагаю взглянуть на две альтернативных реализации доступа к SQL базам из JVM приложений и их (реализаций) применимости.
В статье будет теоретическая часть, практические примеры и в конце немного сравнения. Кому интересна практическая часть — просто перематывайте текст, к конкретной реализации теория отношение имеет весьма посредственное.
Пояснения к материалу
Базу данных я взял отсюда. Её я загрузил на отдельный сервер, чтобы сервер БД (PostgreSQL 12) не мешал смотреть на работу клиента. Производительность приложения зависит от версии СУБД, от схемы данных, от количества данных в ответе, от типов данных и, наверное, много чего еще.
Также не стоит забывать, что производительность самого JDK меняется — для потоков OpenJDK 11, который я использовал, не обязательно такая же для Oracle JDK 8, например.
Для эмуляции медленных запросов можно использовать вызов pg_sleep(seconds) из PostgreSQL.
Не стоит экспериментировать с разными библиотеками в одном модуле — могут быть конфликтующие зависимости (netty). Есть различия даже в patch-версиях, которые сломают работу. Это потенциально может стать сильной головной болью, если netty используется в других частях проекта, например, при обработке HTTP-запросов.
В примерах выполняется по одному запросу, без транзакций. Рассмотрение более сложных случаев выходит за рамки статьи. Стоит отметить, что как и в JDBC, транзакции привязываются к соединению. То есть пока соединение полностью не использовано и не возвращено в пул, его использовать для других запросов нельзя, как и в JDBC. Использовать менеджеры транзакций без серьезного изучения не стоит — как правило, они используют ThreadLocal для поддержки транзакций, что для данных библиотек недопустимо.
Полностью код, использованный в качестве примера тут, можно найти у меня на GitHub.
Если разрабатывается конечное приложение, то скорость и производительность имеет смысл мерять в полной связке со всеми частями. Например, если есть веб-фреймворк, то стоит мерять производительность в связке с ним, а не "чистый" доступ к данным. Может оказаться, что какой-то фреймворк лучше работает с какой-то одной библиотекой, даже если "вчистую" выигрывает другая.
Зачем нужны неблокирующие вызовы. Теория.
Неблокирующие вызовы — это про распределение ресурсов, а не про скорость. Скорость иногда приходит, но в целом это больше про масштабирование. Соответственно, лучше всего проявляет это себя при масштабировании.
Вот говорят, что потоки очень "тяжеловесные", что переключение контекста — это накладные расходы. Что-то в этом есть. Проявляется это на тысячах, в лучшем случае, потоках. С десятками тысяч проблемы заметны, с сотнями — их не избежать. Так что первое, о чем стоит подумать при выборе технологии доступа — а нужно ли масштабироваться до таких значений? Иногда это нужно, иногда о таких объемах речи не идет и смысл в использовании более сложного API теряется. Под простым API я подразумеваю не JDBC, а готовые решения, которые работают поверх него — JPA, JOOQ, Hibernate ORM и подобные.
Проблемы с количеством потоков могут возникать не из-за высокой частоты запросов, но и из-за "бутылочных горлышек" — один путь исполнения может задействовать доступ к базе и блокировать поток из пула, который в обычных условиях освободился бы раньше. Например, каждый десятый запрос лезет в базу и виснет. Раньше у нас приложения были глупые и всегда лезли в базу и уж если там заблокировало — пропало все (упрощаю картинку). Сейчас у нас куча интеграций и мы лезем из кода во все стороны, во всякие разные сервисы и базы, а управлять отдельными пулами потоков нам все еще неудобно. Именно такие случаи "бутылочных горлышек" могут доставить гораздо больше проблем, чем много конкурентых запросов — например, фиксированный пул потоков может исчерпаться не по причине недоступности базы, а когда поток "утек" и завис на другой операции.
Пример 1: Если все на пуле пяти потоков, которые привязаны к веб-стеку (а не отдельный для базы — ну сгенерированный костяк приложения, что поделать) то примерно через пятьдесят запросов они все будут заняты и ни один запрос дальше не пройдет. Если доступ неблокирующий, то каждый десятый (после пятидесятого) будет виснуть, а девять будут отрабатывать как надо (например, забирая данные из кэша).
Пример 2: Все операции к базе работают как надо, пул потоков к вводу выводу отдельный. Вроде все лучше, чем в прошлом примере. Вдруг кто-то дописал код, не заметив наш отдельный пул, который обагащает каждый десятый запрос данными из стороннего REST сервиса, да еще блокирующе. Вот поток "утек" для доступа к базе и не сможет обслужить вовремя запрос, хотя мог бы.
Еще хотелось бы отметить, что "неблокирующий" относится именно к "потоку", а не к чему-то абстрактному. Используя "неблокирующие" операции мы все равно чего-то будем ждать. Очень просто — у нас ограничено количество соединений к базе данных. Блокирующий или неблокирующий у нас ввод-вывод, а "одновременно" будет выполняться только то, что позволит база данных и пул соединений. Ждать будем все равно, хотя потоки не будем блокировать — что позволит их использовать для работы над чем-то, не требующим доступа к базе.
Второе, о чем стоит подумать — это общий стиль работы приложения. Если приложение основано на неблокирующих операциях, то использование блокирующих вызовов помимо того, что просто некрасиво, может привести к дополнительным ошибкам — как в "Примере 2". Впрочем, об этом твердят на каждом втором митапе о неблокирующих библиотеках и останавливаться на этом не стоит.
Что плохого в неблокирующих библитеках. Теория.
Первое: Плохо, что высокоуровневых библиотек/фреймворков практически нет (только Spring Data R2DBC нашел). Для JDBC есть удобные дополнительные абстракции — JPA, JOOQ, Hibernate ORM, которые здорово облегчают жизнь разработчика. Там и кэш запросов, и метрики, и проверки типов ну и всякое, написанное за много лет. Пулы соединений, менеджеры транзакций — все это либо отсутствует, либо безальтернативно.
Второе: Это не стандартно и пока плохо поддерживается. Под этим нужно понимать как минимум две вещи:
- производители баз данных отдают приоритет JDBC драйверам, так что не пишут или запаздывают с обновлениями, исправлениями и новыми возможностями баз в альтернативные решения.
- не всякую базу данных можно использовать в принципе. Например, Oracle никак не поддерживается.
Vert.X SQL (PG) Client.
Набор библиотек от Eclipse, страница GitHub и документация для Postgres.
Особенности:
- поддерживаются PostgreSQL, MySQL, MSSQL, DB2
- основана на callback, имеет поддержку RxJava2. Не уверен насчет корутин Kotlin, но написать руками несложно.
- Работает на vert.x фреймворке, так что должна естественно вписываться в Quarkus.
- Быстрая.
→ Ссылка к последнему пункту
Не поддерживаются встраиваемые базы данных вроде H2, что затрудняет использование в автоматических тестах. Есть недавняя отличная статья о том, что тестировать надо на той базе, которая в продакшне, но это не абсолютный рецепт успеха и не единственный возможный вариант.
Добавим зависимости для клиента, реактивному (rxjava2) его варианту и сетевой транспорт для моей машины:
<dependency> <groupId>io.vertx</groupId> <artifactId>vertx-pg-client</artifactId> <version>3.9.0</version> </dependency> <dependency> <groupId>io.vertx</groupId> <artifactId>vertx-rx-java2</artifactId> <version>3.9.0</version> </dependency> <dependency> <groupId>io.netty</groupId> <artifactId>netty-transport-native-epoll</artifactId> <version>4.1.15.Final</version> <classifier>linux-x86_64</classifier> </dependency>
Будем использовать пул и реактивный вариант API:
import io.vertx.pgclient.PgConnectOptions; import io.vertx.reactivex.pgclient.PgPool; import io.vertx.reactivex.sqlclient.Pool; import io.vertx.reactivex.sqlclient.Tuple; import io.vertx.sqlclient.PoolOptions;
Настройка соединения. Важно указать, что надо кэшировать prepared statement на уровне пула — это хорошо поднимает производительность.
PgConnectOptions connectOptions = new PgConnectOptions() .setPort(5432) .setHost(host) .setDatabase("postgres") .setCachePreparedStatements(true) .setPreparedStatementCacheMaxSize(1000) .setSsl(false) .setUser(user) .setPassword(password);
И пула с размером pool (например, 50).
PoolOptions poolOptions = new PoolOptions() .setMaxSize(pool); Pool client = PgPool.pool(connectOptions, poolOptions);
Будем называть операции с асинхронным ответом попросили. Процесс вытаскивания данных выглядит примерно так:
- попросили дать соединение из пула
- получили соединение, попросили приготовить запрос
- получили подготовленный запрос, попросили выполнить этот запрос с параметрами в Tuple
- получили RowSet, который является Iterable
- прошлись результатам и вытащили значение по имени колонки.
- вернули соединение в пул, "закрыв" его.
При необходимости использовать транзакции их можно начать на пуле соединений.
Параметры запроса указываются как $1 $2 $3 и так далее. Методы, начинающиеся с rx — обертки для RxJava2, которые предоставляет vert.x. Без них можно сыграть в callback hell. Если писать на RxJava2 обертке, выйдет вот так:
Flowable<String> titles = client.rxGetConnection() .flatMapPublisher(connection -> connection.rxPrepare("SELECT title FROM nicer_but_slower_film_list WHERE FID = $1") .flatMap(statement -> statement.query().rxExecute(Tuple.of(Math.abs(random.nextInt(990))))) .flattenAsFlowable(Functions.identity()) .map(row -> row.getString("title")) .doOnError(Throwable::printStackTrace) .subscribeOn(Schedulers.computation()) .doFinally(connection::close));
После всего пул можно закрыть
client.close();
R2DBC
Особенности:
- поддерживаются — MariaDB, MySQL, PostgreSQL, MSSQL, H2
- поддержка в Spring Data R2DBC, что упрощает разработку под Spring Boot
- основано на Reactive Streams, поощряет использовние Project Reactor
Для этого возьмем зависимости клиента и пула соединений:
<dependency> <groupId>io.r2dbc</groupId> <artifactId>r2dbc-postgresql</artifactId> <version>0.8.2.RELEASE</version> </dependency> <dependency> <groupId>io.r2dbc</groupId> <artifactId>r2dbc-pool</artifactId> <version>0.8.2.RELEASE</version> </dependency>
Вместе с пулом неявно придет и реактивный Project Reactor.
Нам понадобятся следующие классы:
import io.r2dbc.pool.ConnectionPool; import io.r2dbc.pool.ConnectionPoolConfiguration; import io.r2dbc.spi.ConnectionFactories; import io.r2dbc.spi.ConnectionFactory; import io.r2dbc.spi.ConnectionFactoryOptions; import reactor.core.publisher.Flux; import reactor.core.publisher.Mono;
Строим фабрику соединений и пул. Prepared Statement кэшируются всегда, насколько я понял из исходников.
ConnectionFactory connectionFactory = ConnectionFactories.get(ConnectionFactoryOptions.builder() .option(DRIVER, "postgresql") .option(HOST, host) .option(PORT, 5432) // optional, defaults to 5432 .option(USER, user) .option(PASSWORD, password) .option(DATABASE, "postgres") // optional .option(SSL, false) // optional .build()); ConnectionPoolConfiguration configuration = ConnectionPoolConfiguration.builder(connectionFactory) .maxIdleTime(Duration.ofMillis(1000)) .maxSize(poolSize) .build(); ConnectionPool pool = new ConnectionPool(configuration);
Будем называть операции с асинхронным ответом попросили. Процесс вытаскивания данных выглядит примерно так:
- попросили дать соединение из пула
- получили соединение, подготовили запрос
- задали параметры запроса
- попросили выполнить этот запрос
- получили поток Result
- предоставили mapper-функцию для преобразования результата в объект и попросили дать объекты из результата запроса.
- вернули соединение в пул, попросив "закрыть" его.
Важно соблюдать последний пункт — для возвращения соединения в пул или для закрытия недостаточно вызвать close, надо еще и подписаться на это событие. Параметры запроса указываются как $1 $2 $3 и так далее. В терминах Project Reactor это можно сделать так:
Flux<String> titles = Flux.usingWhen(pool.create(), connection -> Flux.from( connection.createStatement("SELECT title FROM nicer_but_slower_film_list WHERE FID = $1") .bind("$1", Math.abs(random.nextInt(990))) .execute() ).flatMap(result -> result.map(RdbcTest::getTitle)) , Connection::close); private static String getTitle(Row row, RowMetadata meta) { return row.get("title", String.class); }
Ну и не забыть закрыть пул в конце.
pool.close();
Имитация нагрузки
Я считаю, что "вчистую" гонять доступ к базе смысла мало, но все же на начальных этапах знакомства с технологией можно таким образом проверить какие-то специфические гипотезы и отловить какие-то баги. Буду запускать реактивные R2DBC, VertX и JDBC. Executions (скажем, 50 000) запросов, запуская одновременно только concurrency (скажем, 1000) запросов. Хвала backpressure.
Прошу не воспринимать это как реальный тест, лишь как концепцию. Количество вариаций экспериментов и тюнинга огромное. Подобные тесты производительности лучше тащить у тех, кто этим занимается профессионально (возможно, пристрастно) или писать самим под конкретные условия эксплуатации.
Flowable.range(1, executions) .doOnNext(i -> { if (i % chunk == 0) LOGGER.info("Process {}", i);}) .flatMap(i -> client.preparedQuery( "SELECT title FROM nicer_but_slower_film_list WHERE FID = $1") .rxExecute(Tuple.of(Math.abs(random.nextInt(990)))) .doOnError(Throwable::printStackTrace) .flattenAsFlowable(Functions.identity()) .map(row -> row.getString("title").length()) .doOnError(Throwable::printStackTrace) .subscribeOn(Schedulers.computation()), false, concurrency) .doOnComplete(() -> LOGGER.info("Done with VertX")) .blockingSubscribe(unused -> { }, Throwable::printStackTrace);
Flux.range(1, executions) .doOnNext(i -> { if (i % chunk == 0) LOGGER.info("Processing {}", i);}) .flatMap(i -> Flux.usingWhen(pool.create(), connection -> Flux.from( connection.createStatement("SELECT title FROM nicer_but_slower_film_list WHERE FID = $1") .bind("$1", Math.abs(random.nextInt(990))) .execute() ) .flatMap(result -> Flux.from(result.map(RdbcTest::getTitle))), Connection::close) .subscribeOn(Schedulers.parallel()) .doOnError(Throwable::printStackTrace) , concurrency) .doOnError(Throwable::printStackTrace) .doOnComplete(() -> LOGGER.info("Done with R2DBC")) .blockLast();
HikariConfig config = new HikariConfig(); config.setJdbcUrl("jdbc:postgresql://" + host + "/postgres"); config.setMaximumPoolSize(poolSize); config.setIsolateInternalQueries(false); HikariDataSource ds = new HikariDataSource(config); Flux.range(1, executions) .flatMap(Mono::just) .flatMap(index -> Mono.fromCallable(ds::getConnection) .doOnNext(i -> { if (index % chunk == 0) LOGGER.info("Process {}", index);}) .map(this::request).subscribeOn(Schedulers.elastic()) , concurrency ) .subscribeOn(Schedulers.elastic()) .doOnError(Throwable::printStackTrace) .doOnComplete( ()->LOGGER.info("Done with JDBC")) .blockLast(); private Integer request(Connection connection) { try { var s = connection.prepareStatement( "SELECT title FROM nicer_but_slower_film_list WHERE FID = ?" ); s.setInt(1, Math.abs(random.nextInt(990))); var results = s.executeQuery(); int counter = 0; while (results.next()) { counter += results.getString("title").length(); } results.close(); s.close(); connection.close(); return counter; } catch (RuntimeException e) { e.printStackTrace(); throw e; } catch (Exception e) { e.printStackTrace(); throw new IllegalStateException(e); } }
Хочу выполнить и посмотреть на использованные ресурсы c помощью команды time:
/usr/bin/time --verbose java ...
и посмотреть результаты в Java Mission Control — для этого запущу Java Flight Recorder.
java -XX:StartFlightRecording=disk=true,dumponexit=true,filename=/tmp/r2dbc.jfr,settings=profile,path-to-gc-roots=false,delay=1s,name=R2DBC ...
Результаты time показывают время в userspace и в system, переключения контекста и еще несколько параметров. На моих запусках VertX вырывается далеко вперед, R2DBC и JDBC примерно одинаковы по времени выполнения, чаще переключает контекст. Это все сильно зависит от количества конкурентных "запросов" и размера пула (это самый главный фактор оказался у меня). Получалось, что временами R2DBC проводит в system больше времени, иногда в userspace. В рамках эксперимента я не стал копать глубже, почему так и почему vertx гораздо быстрее на этих прогонах.
Command being timed: "java -jar r2dbc-1.0-SNAPSHOT-jar-with-dependencies.jar -iterations 50000 -concurrent 1000 -pool 50 -user anonymous -password 12345678 -host pg12.local" User time (seconds): 34.28 System time (seconds): 5.55 Percent of CPU this job got: 10% Maximum resident set size (kbytes): 307004 Minor (reclaiming a frame) page faults: 76835 Voluntary context switches: 121789 Involuntary context switches: 9670
Command being timed: "java -jar jdbc-1.0-SNAPSHOT-jar-with-dependencies.jar -iterations 50000 -concurrent 1000 -pool 50 -user anonymous -password 12345678 -host pg12.local" User time (seconds): 38.72 System time (seconds): 5.80 Percent of CPU this job got: 76% Maximum resident set size (kbytes): 459688 Minor (reclaiming a frame) page faults: 125453 Voluntary context switches: 187752 Involuntary context switches: 14221
Command being timed: "java -jar vertx-1.0-SNAPSHOT-jar-with-dependencies.jar -iterations 50000 -concurrent 1000 -pool 50-user anonymous -password 12345678 -host pg12.local" User time (seconds): 19.06 System time (seconds): 2.02 Percent of CPU this job got: 20% Maximum resident set size (kbytes): 178516 Minor (reclaiming a frame) page faults: 43054 Voluntary context switches: 109914 Involuntary context switches: 4691
Что показывает Java Mission Control? JDBC требует больше памяти и чаще делает GC. Зато есть впечатляющие картинки для презентаций в разделе Threads.
Прекрасные неблокирующие
R2DBC:

VertX:
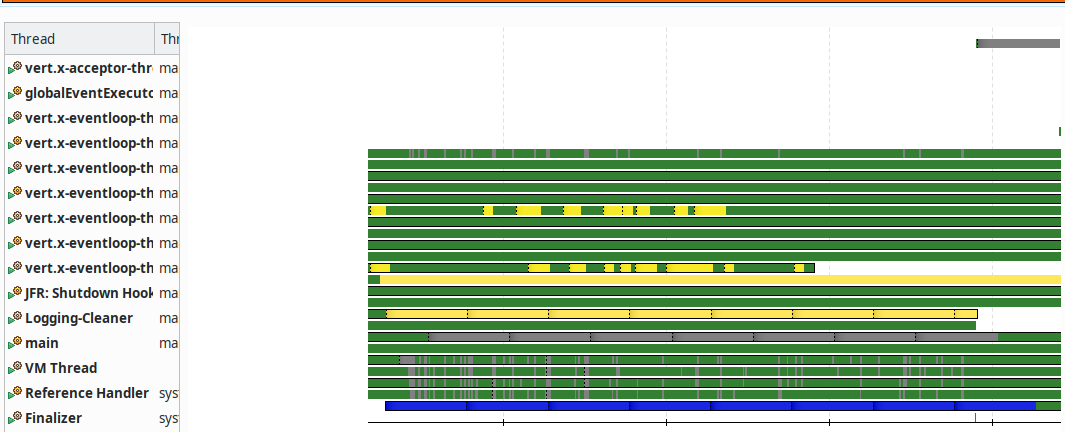
И "жуткий" JDBC:
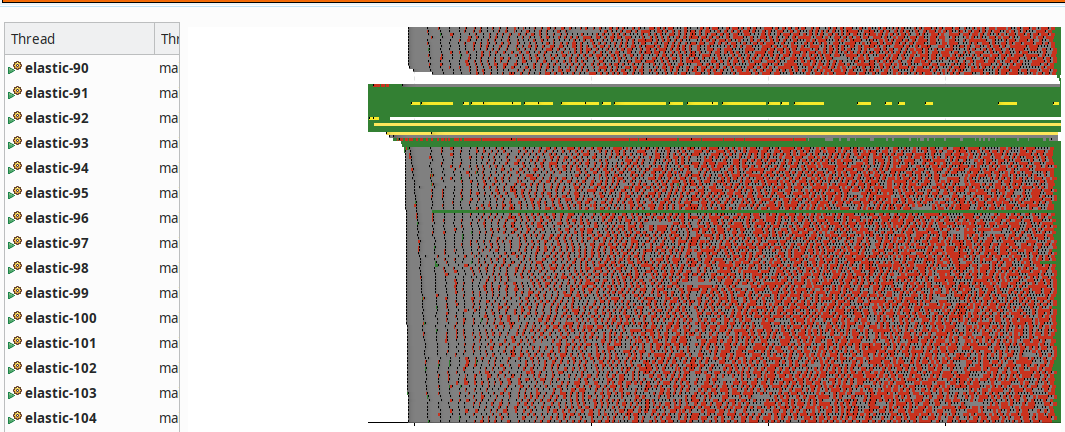
Все красное, все блокировано. Ужас вроде бы. Ну на это можно спросить "и что?". Сами по себе красные черточки ничего не значат и сами по себе проблемой не являются. Проблема, когда они мешают другим действиям приложения. Вот это очень вероятно, но это нужно доказывать в каждом случае отдельно.
Надеюсь, что статья была полезна!

