* — сайты и ресурсы, где кандидаты, пользователи сами размещают о себе информацию. Доступ к этим ресурсам не ограничен, в том числе лицензиями и условиями предоставления услуг этих ресурсов (Terms of service).

Задача
Обычно автоматизация означает оптимизацию процесса. В нашем случае цель была сформулирована как повышение эффективности поиска кандидатов. Эффективность в данном случае выражается через нахождение наиболее подходящих вакансии кандидатов с минимальными затратами ресурсов.
Таким образом, система поиска кандидатов должна сопоставлять кандидатов и открытые позиции (вакансии). Очевидно, что и то и другое можно представить в виде набора навыков. Если мы обе эти сущности (вакансии и кандидатов) представляем через навыки, мы можем сравнить, насколько наш кандидат соответствует открытой позиции с точки зрения набора навыков. Именно такой подход применяет и рекрутер на самом первом этапе поиска: у него есть позиция, описанная в виде набора навыков, и он пытается найти такой же набор в кандидатах, используя внутренние базы данных или внешние сервисы. Это та часть процесса отбора кандидатов, которую потенциально можно автоматизировать без существенного ухудшения качества найма.
С точки зрения формулировки задачи всё просто, но возникает много вопросов: каким образом выразить соответствие навыков для кандидата, как оценить, насколько сильно набор навыков соответствует конкретному человеку, где взять этих кандидатов.
Основная задача здесь — найти эффективный способ отображения соответствия кандидатов и навыков. Другими словами, мы должны сделать репрезентацию кандидатов через набор навыков. Соответственно, на выходе мы ожидаем некоторый вектор, который описывает положение кандидата в пространстве навыков.
Теория: Подходы
Задача нахождения соответствия между двумя или более видами сущностей не новая. Разработано, опробовано и успешно внедрено в различных системах уже не малое количество подходов для этой задачи. В целом все эти подходы делают примерно одно и то же: они пытаются создать некоторое многомерное пространство, в котором можно расположить всех кандидатов, вакансии и другие сущности, и где чем более похожие сущности — тем меньше дистанции между ними внутри этого пространства. Таким образом, происходит репрезентация (проекция) из одного пространства в другое.
Метод #1. Кодирование в переменные — One-Hot Encoding (OHE)
Самым простым способом было бы представить кандидатов и их навыки в виде некоторой матрицы, где значение 1 — обладает навыком, 0 — не обладает навыком.
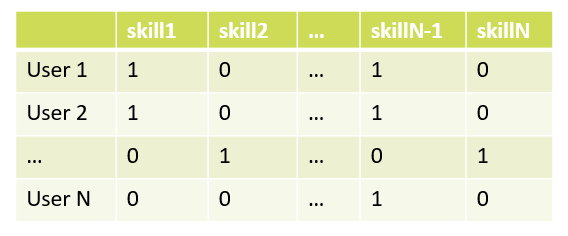
Данный подход простой, но обладает рядом недостатков. Пожалуй, основная проблема данного подхода в том, что навыки в полученном с его помощью пространстве будут ортогональны друг другу, и мы не сможем сравнить их похожесть между собой. Нам, скорее всего, не так важно различать такие навыки, как например Java7 и Java8, при этом хорошо бы отличить их от других навыков, совершенно не связанных с позицией Java-девелопера. При таком подходе Java7 от Java8 будет отличаться также, как Java7 от Python.
Кроме этого, недостатком данного подхода является то, что мы не можем отличить специфические навыки от популярных, которые распространены по всей нашей выборке. Это будет вносить определённый шум в наш поиск и мешать различать кандидатов и выделять похожих.
Простой способ немного скорректировать влияние популярных навыков на поиск — использовать не бинарные оценки, а взвешенные, основанные на частоте встречаемости в выборке в целом и в отдельных документах. Для этого используют метод TF-IDF. Но в этом случае мы по-прежнему не сможем оценить, насколько похожи навыки между собой.
Метод #2. Матричная факторизация
Представление кандидатов в пространстве, где каждый навык — это координата пространства, является избыточным, так как часть навыков почти не отличаются друг от друга. Соответственно, можно схлопнуть похожие навыки в некоторые факторы/компоненты/латентные признаки. Одним из подходов, позволяющих находить такие компоненты, является группа методов матричной факторизации.

В общем случае нашу матрицу User-Skills мы представляем в виде двух матриц, произведение которых будет приближать исходную матрицу. Одна представляет латентные признаки для каждого из кандидатов в сконструированном латентном пространстве. Другая — латентные признаки навыков (skills’ embedding). Для простоты можно это пространство воспринимать, как пространство интересов кандидатов — каждого кандидата можно описать с помощью его соответствия тем или иным интересам, так же и каждый навык можно описать через величину того, насколько он удовлетворяет тот или иной интерес кандидата.
Плюс этого подхода в том, что он более устойчив к популярным навыкам, снижает размерность и позволяет оценивать соответствие между навыками. То есть репрезентации в пространстве уменьшенной размерности сохраняют некоторые зависимости между сущностями, которые наблюдались в исходном пространстве. Минус — обычно нужно довольно много данных, чтобы сделать хорошую репрезентацию. Кроме того, мы не можем отследить сложные зависимости между навыками и кандидатами.
Чтобы выучить более сложные репрезентации кандидатов и навыков, нужны более мощные методы, и группа таких методов может быть основана на глубоком обучении.
Метод #3. Коллаборативная фильтрация с глубоким обучением

Источник
В рекомендательных системах нередко используют коллаборативную фильтрацию, основанную на нейронных сетях. Принцип применения такой же, что и в матричной факторизации — конструирование пространства латентных признаков и помещение в это пространство кандидатов и навыки. Только происходит это уже в ходе обучения модели нейронной сети, которая выучивает латентное представление каждой сущности, решая при этом, например, задачу прогнозирования релевантности навыка для кандидата (в supervised постановке задачи), или итеративно корректируя латентное пространство таким образом, чтобы навыки, часто встречающиеся вместе у кандидатов, находились близко друг к другу в полученном пространстве, а навыки, которые редко вместе описывают одного специалиста, были бы далеки друг от друга в этом пространстве (unsupervised постановка задачи). Полученные представления кандидатов и навыков называют эмбедингами.
Этот метод позволяет решить те задачи, которые раньше не поддавались. Появляется больше возможностей для получения пространства, учитывающего специфику конкретных данных, можно использовать разные архитектуры сетей, что в итоге позволяет отражать более сложные взаимосвязи между навыками и кандидатами.
Но один вопрос остается открытым — нужно довольно много данных, чтобы получить хорошее представление.
Реализация, которая помогла
При создании нашей системы рекомендации кандидатов на позиции мы использовали нейронную сеть — StarSpace. Это довольно мощная и неплохо работающая из «коробки», реализация. Кроме того, имеется фреймворк для этой модели, пользоваться которым довольно просто, достаточно подготовить определенным образом данные, запустить модель, и вы получите репрезентации сущностей.
Плюс в том, что не нужно сильно погружаться в детали, чтобы получить результат. Минус в том, что в реализованном фреймворке для настройки нейронной сети доступен лишь ограниченный набор параметров.
Метод #4. Репрезентация графов
Другая группа методов, позволяющая решать задачи репрезентации сущностей — репрезентация графов.
В целом представление взаимосвязи кандидатов и навыков в виде графа, кажется довольно естественным. Например, можно представить граф, где узлы — кандидаты, а связи — наличие общих навыков у кандидатов. Или граф навыков, где связи — принадлежность навыков к одному кандидату. Другой вариант — граф кандидаты-навыки — двухмодальный граф, где каждый узел принадлежит либо к одной сущности, либо к другой. Но большинство методов графовой репрезентации работает с одномодальными графами, поэтому обычно двухмодальные графы следует трансформировать в граф, где узлы представлены одним видом сущностей.
Особые характеристики графа, важные с точки зрения репрезентации структуры графа — однородность и структурная похожесть узлов.
Узлы — например, кандидаты могут быть чем-то похожи между собой, состоять в одном комьюнити, разделять общие интересы, работать в одной компании или обладать другими одинаковыми характеристиками — за это отвечает характеристика однородности. С другой стороны, узлы разных групп могут быть объединены тем, что играют в своих группах одинаковую роль — лидеры, помощники лидеров, хранители информации, коммуникаторы, аутсайдеры. Если бы мы хотели сравнить два графа, то мы могли бы понять, что лидеры в одном графе играют ту же роль, что и лидеры в другой — это то, что называется структурной похожестью.
Методы графовой репрезентации так или иначе пытаются конструировать пространство с учётом как однородности, так и структурной эквивалентности графа.
Графовая факторизация
В первую очередь рассмотрим метод, основанный на графовой факторизации.

Принцип действия такой же, как и в матричной факторизации: нужно трансформировать граф в матрицу пересечений, т.е. если два кандидата имеют общие навыки — 1, если нет — 0. К сожалению, при использовании подобных моделей мы теряем структурную эквивалентность узлов.
Рассмотрим группу методов, основанных на нейронных сетях.
Методы a-like word2vec*
Это группа методов основана на случайном выделении подграфов (частей графа, которые сами рассматриваются как отдельные графы) и обучении способности предсказывать окуржение узлов в подграфе. Иными словами, мы выделяем некоторые кусочки графа и пытаемся выучить модель предсказывать по узлу подграфа то, что будет вокруг него, какие связи у него с другими узлами. Способов выделять подграфы в большом графе тоже может быть много. Такая модель позволяет делать репрезентацию, как информации о структурной эквивалентности узлов, так и их принадлежности к некоторым общим группам. Это группа методов очень похожа на методы, применяемые для репрезентации текстов — w2v(skip-gram), doc2vec. (Подробнее про word2vec).
Почитать подробнее про подобные методы графовой репрезентации можно, например, тут — DeepWalk, Node2vec, Graph2vec.

Источник
Сверточные сети на графах (Graph Convolutional Networks)
Здесь похожая на предыдущий метод идея: мы проходимся по графу и используем для репрезентации отдельного узла информацию о его соседях. Кроме того, в обучении репрезентации участвует информация об общей структуре графа и характеристики узла. Основным нововведением данных методов является то, что модель нормализует значения каждого узла таким образом, чтобы позиция в латентном пространстве двух узлов была бы тем ближе, чем более похожи структурные роли этих узлов в подграфе.
Такая процедура называется свертыванием графов.

Подробнее можно почитать тут:
- Semi-Supervised Classification with Graph Convolutional Networks
- FastGCN: Fast Learning with Graph Convolutional Networks via Importance Sampling
- N-GCN: Multi-scale Graph Convolution for Semi-supervised Node Classification
Реализация, которая помогла
Для задачи репрезентации графов связей между сущностями мы использовали фреймворк PyTorch BigGraph — это ещё один фреймворк от Facebook Research. Относительно новый и довольно мощный метод, позволяющий работать с большими графами. У нас был большой граф и традиционные методы не справлялись или приходилось много сил тратить на то, чтобы сделать так, чтобы они справлялись.
Практика: Реализованная система поиска кандидатов
Вернёмся к задаче: у нас есть некоторая система поиска кандидатов — как чёрный ящик, который мы хотим наполнить. Мы разобрали методы, которыми можно наполнить, осталось решить, откуда брать данные и кто наши кандидаты.
Все вакансии, на которые мы хотели бы рассматривать кандидатов — это IT-вакансии. Следовательно, нам нужен источник данных, где много информации об IT-специалистах, эти данные можно было бы использовать с юридической точки зрения (т.е. мы бы не нарушали закон используя эти данные для нужд системы), также доступ к этим данным был бы дешёвый, желательно бесплатный.
Всем этим требованиям соответствует GitHub (github.com, Terms of Service), который мы и решили попробовать в качестве источника данных. Приятным моментом является и то, что для получения данных можно воспользоваться GitHub API и GitHub Archive, с помощью которых GitHub облегчает доступ к данным для разработчиков, и нет необходимости парсить страницы ресурса.
GitHub можно назвать социальной сетью для обмена кода и знаниями. Тут есть всё необходимые для нашей системы данные: данные о пользователе (не много, но есть), данные о репозиториях, с принадлежностью их к определённым пользователям, языкам, на которых они написаны, текстовым описанием и тегами (топиками), указывающими на направление, технологии репозитория, также есть связь между участниками в виде подписки друг на друга, подписки пользователей на репозитории, других участников, и много другой информации.
Для использования данных GitHub мы сделали предположение, что репозиторий отражает навыки пользователя, создавшего его. Если человек написал какой-то код, значит он обладает необходимыми навыками; если другой человек подписался на данный репозиторий (код), значит он интересуется теми технологиями, с помощью которых написан этот код. Таким образом, можно предположить, что подписка на репозиторий означает наличие определённых навыков.
Как работает система
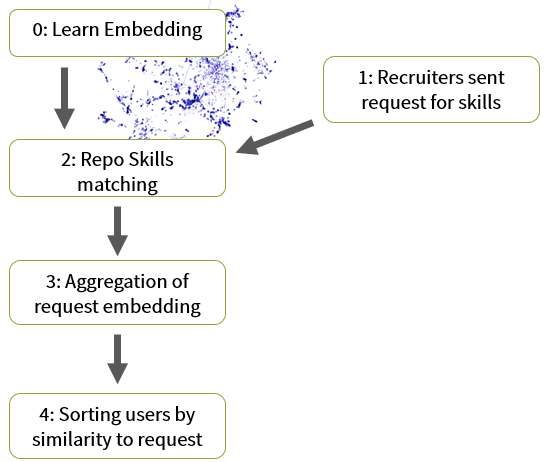
Сначала мы берём все подписки пользователей с GitHub, и для всех подписок выучиваем embedding, т.е. представление в пространстве латентных признаков. Для всех кандидатов находим их положение в полученном латентном пространстве, путём агрегации ембедингов их подписок в один вектор.
Шаг первый
Рекрутеры формируют запрос на поиск кандидатов на определённую позицию в виде набора навыков.
Шаг второй
Находится соответствие между навыками и репозиториями, у которых есть embedding.
Шаг третий
Агрегация embedding репозиториев, соотнесённых с запросом, в один вектор запроса — положение запроса в полученном латентном пространстве.
Шаг четвертый
Далее происходит измерение расстояния от запроса до кандидатов и сортировка. Получаем отсортированный список наиболее подходящих запросу кандидатов.
Полученный список кандидатов обрабатывают рекрутеры, просматривая профили каждого кандидата на GitHub и в других ресурсах, если возможно получить соответствующие профили. С кандидатами, которые кажутся наиболее подходящими, уже происходит традиционный процесс, начинающийся с приглашения к общению.
Результаты
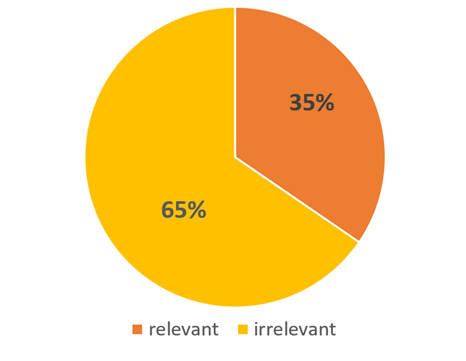
За первые 4 месяца, которые мы работали над проектом, было обработано 5 технологий. Это значит, что с помощью разработанной системы, мы сгенерировали списки кандидатов, ранжированных по релевантности, по пяти направлениям: Java, JavaScript, Python, DevOps, Data Science. В сумме получилось более 3500 человек. Из них, по оценкам рекрутеров, 35% кандидатов было отмечено как релевантные, остальные 65% — как нерелевантные. Тут следует уточнить, что релевантность сильно менялась от одного направления к другому. Так, для таких направлений, как Java Developer релевантность выше — 60%, потому что технологии и навыки, которыми пользуются эти специалисты, достаточно специфические именно для них. И наоборот, для такого направления как DevOps, которое находится на стыке технологий, список требуемых навыков обширен и может меняться от проекта к проекту. Для такого направления поиск через подобную систему осуществлять сложнее, соответственно и релевантность рекомендованных кандидатов ниже средней — около 25,5% релевантных.
Чего мы достигли
- Процент релевантных кандидатов, рекомендованных моделью, сопоставим с процентом из других систем, в том числе с ресурсами по поиску работы.
- Удалось увеличить внутреннюю базу кандидатов на несколько сотен, добавив источник, который ранее не был задействован.
- На 29% сократилось время, затрачиваемое на поиск 1 кандидата, в сравнении с остальными «холодными» источниками поиска (т.е. источниками, которые не используются для прямого поиска работы).
- Нам удалось более эффективно обрабатывать запросы с редкими навыками.
- И нанять несколько senior-инженеров, которые не находились в активном поиске работы.
Что хотелось бы улучшить
Полученное решение обладает недостатками, которые мы пока не смогли решить:
- Всё ещё нет хорошего решения для оценки уровня владения навыками кандидатов.
- Далеко не все пользователи GitHub указывают контактные данные, что снижает вероятность связаться с кандидатом и найти его профиль в других системах.
- Не получается стабильно находить хороших кандидатов для направлений, которые не связаны напрямую с написанием кода, и соответственно с репозиториями на GitHub.
- Также нет стабильно хороших результатов в поиске кандидатов, чьи навыки находятся на стыке технологий.
Осталось отметить, что описанное здесь решении не финальное, мы продолжаем эксперименты по улучшению качества рекомендаций кандидатов, внедрению новые технологий, функциональных элементов в систему.
Надеюсь, что статья была вам полезна, как с точки зрения обзора подходов, так и с точки зрения описания решения конкретной бизнес задачи.

