
Мартин Фаулер в книге «Patterns of Enterprise Application Architecture» описывает «Модель предметной области (Domain Model)» как сложный подход к организации бизнес-логики. Метод заключается в создании классов, соответствующих объектам предметной области из реального мира как с точки зрения структуры данных, так и поведения. При этом технические аспекты, такие как хранение данных, аутентификация и авторизация, управление транзакциями, выносится за пределы слоя бизнес-логики. Паттерн реализуется одним из двух способов:
- Богатая (насыщенная) модель — данные и поведение инкапсулируются внутри объектов предметной области.
- Анемичная модель — в объектах предметной области инкапсулируются только данные, поведение (методы) выносится в отдельный слой сервисов.
Фаулер и Эванс считают анемичную модель анти-паттерном. Однако многие кодовые базы, с которыми мне доводилось работать, реализованы именно в стиле «анемичной» модели. Под катом расшифровка и видео моего доклада с DotNext 2019 Moscow, посвященного сравнению сильных и слабых сторон обоих подходов и не очевидным деталям реализации модели предметной области в парадигме ООП и в функциональном стиле.
Презентация к докладу
Структура поста:
- Историческая справка
— Причины раскола
— Always valid (миф или реальность?) - Паттерны DDD на практике
— DDD-жаргон
— Дизайн на основе типов
— Агрегаты
— Домен и инфраструктура
— Все вместе - По наклонной («плохие» случаи)
— Делаем не SOLIDно
— Lazy Load
— Проектирование — компромисс - Workarounds
— Expressions
— Specification
— Default Interfaces Implementation
— Bulk Extensions
— А может F#? - Bounded Context
— Первый список вопросов (организационный и никак не связан с технологиями)
— Второй список вопросов (технологический)
— Как делить Domain Model на Bounded Context
— Монолит на микросервисы
— Как пересечь границу контекстов - Что выбрать?
- Полезные ссылки

Историческая справка
Впервые я столкнулся с термином «модель предметной области» (Domain Model) читая книгу Patterns Of Enterprise Application Architecture (PoEAA) Мартина Фаулера. Прочитал и немного чего понял. Может быть время было неподходящее, а может у Фаулера было написано уж очень кратко. Так или иначе, после прочтения паттерн был забыт на несколько лет, пока в руки ко мне не попала небезызвестная «синяя книга» Эрика Эванса Domain Driven Design. На этот раз я по настоящему проникся, как в фильме «Матрица», когда Нео смогу наконец освободить свой разум. Не в том смысле, конечно, что начал останавливать пули силой мысли или обрел какие-то иные сверхъестественные способности. Вместо этого в значительной изменились мои взгляды на то, что важно, а что не очень в контексте разработки корпоративного ПО. До прочтения я считал единственно-важным технологический аспект, а после — закрались мысли, что нужно еще заниматься аналитикой, сбором требований и другими немаловажными вещами, а главные сложности в корпоративной сфере вообще связаны с людьми, а не технологиями.

Однако, далеко не все разделяют мой щенячий восторг по поводу Эванса, многим больше нравится «красная» книжка Вернона. На вкус и цвет, как говорится, все фломастеры разные, так что какую из них читать каждый решает сам. Можно читать и обе, но их содержание в значительной степени пересекается. А вот книга Скотта Влашина Domain Modeling Made Functional вышла буквально в прошлом году. Она примечательна тем, что рассматривает типовые проблемы предметно-ориентированного проектирования через призму функционального программирования и дает некоторые неожиданные ответы, недоступные в ООП.
Например, в ООП исторически сложилось два основных подхода к моделированию домена: «богатая» и «бедная или анемичная» модели. В ФП же, этого разделения нет, потому что функциональные языки отличаются по возможностям от классических ООП-языков и потому что в функциональном мире вообще не принято объединять структуру данных и операции над ними (поведение) в объекты. В контексте доклада я буду в основном оставаться в объектно-ориентированной парадигме и лишь пару раз соскользну на кривую тропинку функциональщины.
Богатая

Богатая модель — это способ моделирования, который имели в виду Фаулер и Эванс:
- Структура данных и поведение совмещены в одних и тех же классах.
- Структура программного кода отражает структуру домена, т.е. классы, относящиеся к бизнес-логике должны называться «касса», «проводка», «платежная ведомость», а не «сервис», «репозиторий» или «прокси».
- Самое важное, соблюдаются инварианты объектов, т.е. их состояние непротиворечиво.
Анемичная
В анемичной, все ровно наоборот.
- Структуры данных и операции над ними (поведение) разделены. Чаще всего структуры данных называют «сущностями», а поведение — «сервисами».
- Структура программного код отражает скорее паттерны и фреймворки.
- Бизнес-правила либо невозможно понять, путем изучения кода, либо это дается с большим трудом.
- И наконец, инварианты не соблюдаются, а зачастую даже отрицается такая необходимость или возможность
Фаулер и Эванс считают, что анемичная модель — это анти-паттерн, свидетельствующий о том, что команды разработки не получилось корректно смоделировать домен в ООП-стиле. Несмотря на это, многие программисты уверены, что анемичная модель — это ровно то, что нужно или даже за ней будущее. Более того, анемичная модель — это строгое следование принципам SOLID.
Причины раскола
Сложно сказать в какой именно момент произошел этот раскол и что стало тому причиной. Лично я считаю, что основных причин две:
Засилье ORM
Давайте посмотрим на статистику скачивания пакетов с nuget.org. Entity Framework скачивают чаще, чем ASP.NET MVC. Можно предположить, что множества скачивающих ASP.NET MVC и Entity Framework в значительной степени пересекаются, и сделать вывод, что многие веб-приложения манипулируют данными посредством ORM. На сколько это действительно нужно делать — вопрос открытый.
Простота реализации
Анемичную модель, наверняка хотя бы раз в жизни реализовывал каждый из читающих этот текст. Как же правильно реализовать богатую модель — вопрос гораздо менее однозначный. Несмотря на обилие теоретического материала как только дело доходит до реализации на практике, появляются вопросы, на некоторые из которых я не нашел внятного ответа до сих пор.
Always valid (миф или реальность?)
 Можно предположить, что проблема кроется исключительно в недостаточной квалификации программистов. Почему же тогда таких «неумех» так много в индустрии? Почему люди отказываются от столь заманчивых идей, как «писать код, из которого понятны бизнес-правила» и «всегда соблюдать инвариант»?
Можно предположить, что проблема кроется исключительно в недостаточной квалификации программистов. Почему же тогда таких «неумех» так много в индустрии? Почему люди отказываются от столь заманчивых идей, как «писать код, из которого понятны бизнес-правила» и «всегда соблюдать инвариант»?Ведь что значит стопроцентное соблюдение всех инвариантов? В пределе — то, что ни один объект вообще нельзя создать в «неправильном состоянии». А это значит, что ошибки будут найдены не на этапе юнит-тестирования, приемочного тестирования или, упаси господи, на продакшене, а в момент компиляции.
Более глубоко тема инвариантов и проектирования, направленного на исключение возможности ошибки во время компиляции программы, а не во время выполнения в статье Скотта Влашина "Making illegal states unrepresentable"
 Кто вообще в здравом уме будет отказываться от такого? Не жизнь, а сказка… или миф… а может быть художественный вымысел?
Кто вообще в здравом уме будет отказываться от такого? Не жизнь, а сказка… или миф… а может быть художественный вымысел? Такая дискуссия состоялась в интернете между Грегом Янгом и Джеффри Палермо. Первый — сторонник концепции Always Valid, а второй утверждал, что этот подход вообще неосуществим в реальности.
Аргументы Джеффри вполне логичны. Для обеспечения корректности состояния любого объекта в изменяемой (mutable) среде нам придется снабдить любой setter защитной конструкцией, например такой.
public string Name { get { return _name; } set { if (string.IsNullOrEmpty(value)) { throw new Exception("Name is required"); } _name = value; } }
Такой подход не только сильно замусоривает и зашумляет код, но и действительно не очень дружит с SOLID, потому что такие классы получают две причины для изменений: хранение данных и валидацию. Чтобы не нарушать принцип единственной ответственности мы могли бы объявить отдельный интерфейс валидатора, реализовать его и перенести логику валидации в соответствующую реализацию.
public interface IValidator<T> { ValidationResult Validate(T obj); }
Давайте оставим пока SOLID в покое и посмотрим на эту аргументацию с другой стороны. В некоторых случаях обеспечить корректное состояние объектов может быть просто невозможно. Коммерсанты давно смекнули, что вероятность покупки в интернет магазине снижается в зависимости от количества необходимых форм для заполнения. В идеале вообще должна быть только одна огромная кнопка «купить» и какой-то способ связаться с пользователем. Остальные «необходимые» поля может заполнить кол-центр после получения оплаты.
С другой стороны, чем больше магазин знает о вас, тем лучше можно настроить маркетинговые кампании, чтобы показать более релевантную рекламу, которая с большей вероятностью заставит вас пойти на сайт магазина покупать что-то снова и снова.
Таким образом, в одних случаях нужно, чтобы обязательных полей было минимум, а в других — максимум. Значит в разных контекстах правила «обязательности» полей класса могут быть разными и экземпляр класс вообще не может всегда находиться в «правильном» состоянии, потому что «правильность» зависит от текущего контекста. Шах и мат, Грег Янг?
Проблема универсалий
Удивительно, что впервые в известной человечеству истории подобными вопросами задались Платон с Аристотелем задолго до становления кибернетики с информатикой и изобретения компьютеров. Я не буду сильно углубляться в онтологию, да просят меня древнегреческие философы за весьма вольное толкование их идей.
Представьте себе единорога. Не конкретного, а единорога в принципе, как абстрактную концепцию. А теперь представьте объект, относящийся к классу «единорогов». Здесь термины объект и класс я трактую широко: не в смысле терминологии ООП, а как категорию, в которую входят всевозможные единороги и одного представителя этой категории. Считаете что на картинке слева единорог? А справа?

Здесь не все так очевидно. Это персонаж мультфильма «Гадкий я 3», на протяжение которого одна маленькая девочка искала живого единорога, потому что единорог слева был ее любимой игрушкой… и в общем и целом она нашла. Какое отношение древнегреческие философы и современные мультфильмы имеют к контекстной валидации? Как ни странно, самое прямое.
Контекстная валидация и инвариант
Давайте разделим валидацию на два подвида:
- Качества, необходимых объекту, чтобы принадлежать определенному классу: единорог — это все-таки лошадь с одним рогом, а не овечка с двумя рогами, один из которых обломился.
- В зависимости от контекста существуют другие типы валидации, работающие в дополнение к инварианту. В контексте продаж пользователю достаточно обладать контактными данными, а в контексте доставки обязательными становятся еще и имя с фамилией и, возможно, другие необходимые поля.
На первый взгляд такое разделение дает возможность всегда держать модель в согласованном состоянии. Значит дело все-таки исключительно в программистах, нежелающих чуть больше подумать, чтобы получить преимущества богатой модели? В теории, да, на практике все не так однозначно.
Дальше я буду сравнивать богатую и анемичную модель и присваивать одно очко богатой, если реализация богатой модели оказалась такой же простой, как и анемичной, и одно очко анемичной, когда реализация богатой модели окажется неудобной или неполной. Простота реализации против надежности удобства сопровождения.
Паттерны DDD на практикеDDD-жаргон
Прежде чем начать соревнование, напомню DDD-жаргон. Модель не монолитна, а разделена на несколько ограниченных контекстов. Вопрос соотношения терминов домен, субдомен и ограниченный контекст я оставляю за скобками, потому что он не важен в рамках доклада. Существование ограниченных контекстов объясняется организационными причинами. Чаще всего невозможно создать единую модель для всего предприятия, потому что такая модель не будет отражать реальную неоднородную структуру компании, разнящейся от отдела к отделу.
Скажем, решили вы заказать изготовление продукции. Пока вы ее не оплатите никто не поднимет пятой точки. Зато после оплаты заявка поступает в отдел производства. Отделу производства в свою очередь не важно оплачена заявка или нет. Для них актуальны сроки выполнения и наличие необходимых материалов на складе. Затем товар отправляется в доставку, которому вообще по барабану что это за товар. Их волнует только расстояние от склада отгрузки до точки доставки.
Таким образом, существует три заявки: на оплату, изготовление и доставку, обладающие разными характеристиками и имеющие смысл только внутри ограниченного контекста, а не всего предприятия. Словарь терминов, понимаемый одинаково в рамках ограниченного контекста называется единым языком. Внутри ограниченного контекста DDD предлагает три основных инструмента моделирования: Value Object, Entity и Aggregate.
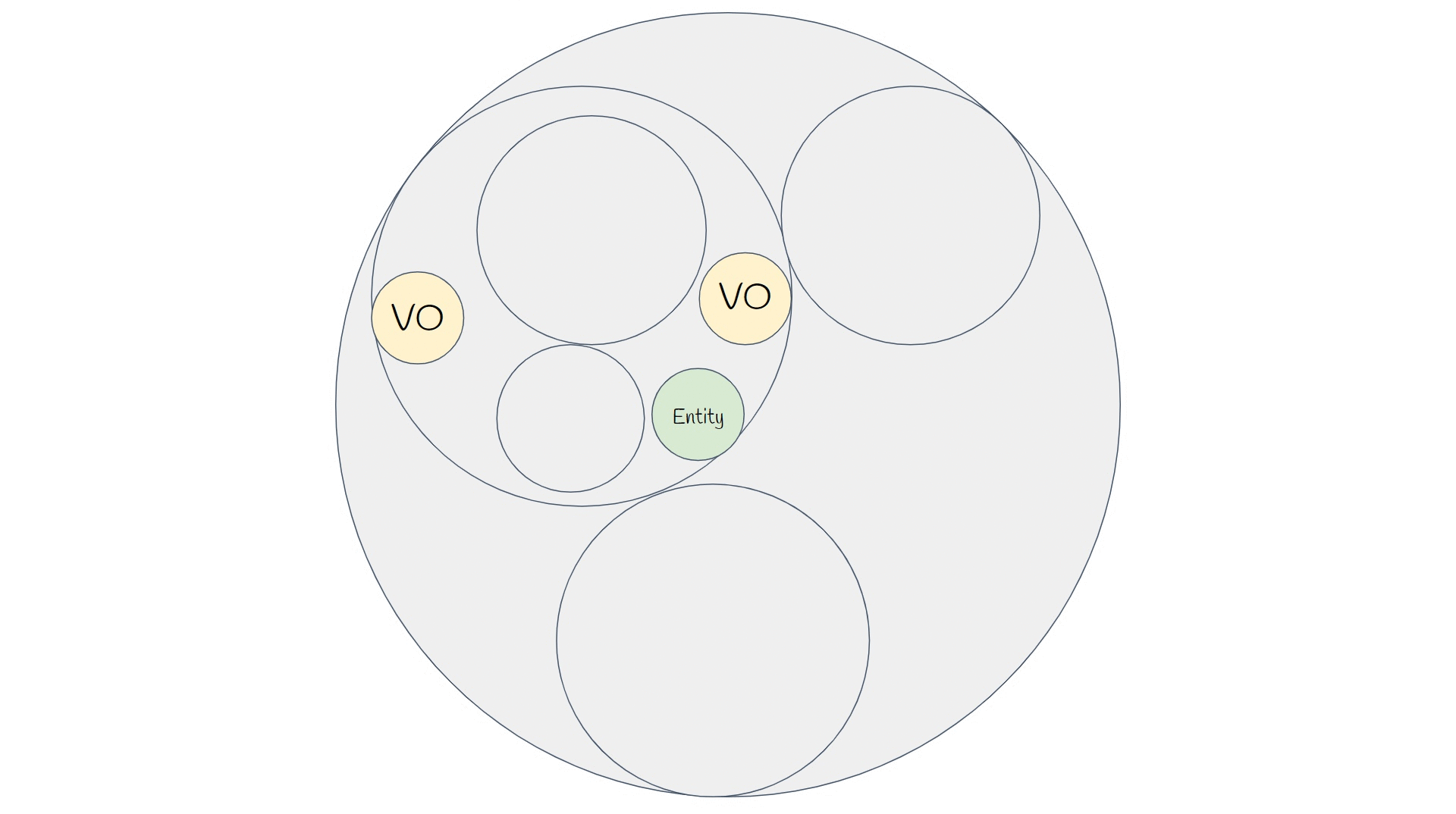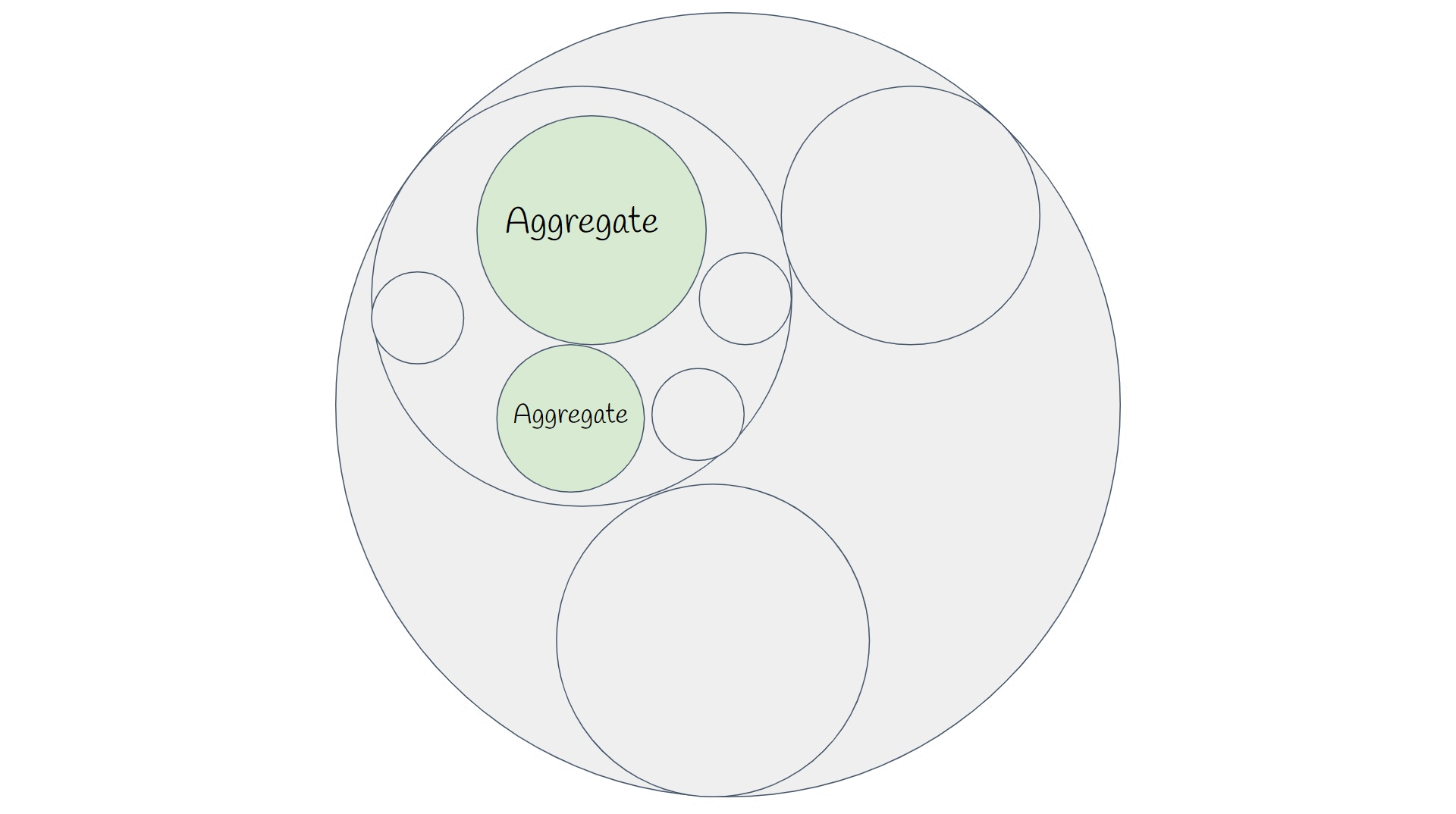
Агрегаты — это деревья объектов, обладающие инвариантом для группы, а не для единичного объекта. Доступ к агрегатам осуществляется через «Корень агрегации» — объект, находящийся в корне дерева. Таким образом, корень обеспечивает инвариант всей группы с помощью инкапсуляции.
Сущности и Value Object — это основные строительные блоки приложения, которые могут как входить в агрегаты, так и не входить. Их основное отличие в том, что у сущностей есть уникальный идентификатор, а у объектов-значений — нет.
Дизайн на основе типов
Вернемся к пользователю интернет магазина. Попробуем смоделировать всего один объект в стиле «богатой» модели. Мы пришли к тому, что валидацию инварианта и контекстную валидацию необходимо разделить. Самый простой способ достижения цели — разделить класс, моделирующий пользователя. Напрашивается два основных подтипа:
- профиль пользователя — персональные данные, которые заставим заполнить позже.
- аккаунт пользователя, содержащий контактную информацию, необходимую для его идентификации и оформления заказа.

Подробнее этот подход в докладе Скотта Влашина Domain Modeling Made Functional или нашего с Вагифом Абиловым Жизнь после бизнес-объектов.
Вынести IO на границы (Anticorruption Layer)
Следующим шагом перенесем ввод-вывод на границы приложения. Данные, пришедшие извне по определению могут быть в любом состоянии: как в согласованном, так и нет. DDD даже предлагает специальный паттерн для пограничного контроля ограниченных контекстов — Anticorruption Layer, который, впрочем, отличается от обычного фасада лишь более узкой специализацией.

Все данные из-за пределов контекста сначала попадают в фасад, где происходит проверка. Некорректные данные отвергаются, а данные, прошедшие валидацию идут дальше в слой домена. Над ними выполняются операции бизнес-логики. Результаты покидают пределы слоя домена. Новые входные данные даже на базе результатов «чистого» слоя домена все-равно считаются «грязными» и операция повторяется.
Crud у всего есть начало
Таким образом в домен попадают только корректные данные. Сам же слой домена соблюдает все инварианты, поэтому входные и выходные параметры всех операций должны быть всегда согласованными. Первый рубеж, гарантирующий корректность — конструкторы классов. Конструкторы изначально были задуманы для того, чтобы создавать только согласованные объекты, но долгое время ORM и сериализаторы умели работать только с непараметрическими конструкторами. Кроме того, синтаксис конструкторов в C++ подобных языках оказался чересчур многословным. В итоге, мы можем наблюдать противостояние прививочников и антипрививочников тех, кто считает, что конструкторы нужны и полезны и тех, кто считает, что это слишком многословно.
Проблема инициализации параметров хорошо решена в TypeScript с помощью parameter properties. В C#9 нам обещают records. Эта функциональность планировалась еще в C#8, но разработчики языка решили доработать концепцию и, похоже, что в следующей версии языка мы все-таки их дождемся.
В случае богатой модели выбора нет, конструктор должен быть. Контактные данные сделаем обязательным полем, чтобы использовать их в качестве уникального идентификатора, а профиль пользователя — необязательный параметр конструктора.
public class User : EntityBase
{
public Contact Contact { get; protected set; }
public UserName? UserName { get; protected set; }
public User(Contact contact, UserName? userName = null)
{
Contact = contact;
UserName = userName;
}
}
Контактные данные — это либо email, либо телефон. Необязательно заполнять и то и другое, кол-центр устроит любой способ связи, главное, чтобы он был заполнен верно. Для email — наличие собаки и домена в адресе, а для телефона знака "+" и следующих за ним цифр. Более точные правила валидации email и телефона намеренно опущены, потому что они сейчас не важны.
public class Contact
{
const string PhonePattern = @"\+?\d";
[EmailAddress]
public string? Email { get; }
[RegularExpression(PhonePattern)]
public string? Phone { get; }
private Contact(string? email, string? phone)
{
Email = email;
Phone = phone;
}
}
Мы могли бы использовать вот такой конструктор, но в C# нет способа показать, что один из параметров является обязательным. Сигнатура метода будет сообщать о том, что оба параметра не обязательные. Поэтому сделаем конструктор закрытым, а вместо него предоставим два публичным метода с более говорящими названиями. В C# обычно используется префикс Try для операций, которые могут завершиться ошибкой, но не выбрасывают исключений. Можно реализовать конструктор таким образом.
public class Contact
{
public static bool TryParsePhone(string phone, out Contact c)
{
if (PhoneRegex.IsMatch(phone))
{
c = new Contact(null, phone);
return true;
}
c = null;
return false;
}
}
Если не хотите использовать TryPattern, можете использовать атрибуты. Несмотря на то, что атрибуты — это мета-информация, вообще никак не влияющая на исполнение программы, существует уже готовое вполне удобное API, использовав которое в конструкторе мы заставим пройти все проверки.
public class UserName
{
public UserName(string firstName, string lastName, string? middleName)
{
FirstName = firstName;
LastName = lastName;
MiddleName = middleName;
Validator.ValidateObject(this, new ValidationContext(this));
}
[Required, StringLength(255)]
public string FirstName { get; protected set; }
[Required, StringLength(255)]
public string LastName { get; protected set; }
[StringLength(1)]
public string? MiddleName { get; protected set; }
}
Откуда берутся пользователи
На этом можно было бы остановиться, если бы за пару простых действий нельзя было сделать бизнес-правила более отчетливыми в коде программы. Из сигнатуры конструктора не ясно при каких обстоятельствах пользователи появились в системе. Заменим два параметра на один и дадим ему понятное название.
public class User : EntityBase
{
public Contact Contact { get; protected set; }
public UserName? UserName { get; protected set; }
public User (SignUp command)
{
Contact = command.Contact;
UserName = command.UserName;
}
}
Теперь стало ясно, что пользователь может зарегистрироваться самостоятельно (SignUp) или зарегистрироваться по приглашению друга (SignUpByInvite). Механизм приглашений может натолкнуть читающего код на мысль о том что в системе существует реферальная программа. У этого изменения есть еще один неожиданный побочный эффект. Представьте, что в логах есть два разных сообщения об ошибке:
- Что-то пошло не так во время регистрации пользователя
- Что-то пошло не так, когда Маша пыталась зарегистрироваться по приглашению Паши
Второе гораздо информативнее. Конкретные Маша и Паша, конкретный процесс регистрации, а не абстрактная ошибка регистрации в вакууме. Таким образом, сопровождать продукт новым разработчикам, не знакомым со всеми требованиями станет несколько проще.
public class User : EntityBase
{
public User? Invitee { get; protected set;}
public Contact Contact { get; protected set; }
public UserName? UserName { get; protected set; }
public User (InviteUser command)
{
Contact = command.Contact;
UserName = command.UserName;
Invitee = command.Invitee;
}
}
Поверья
Я не зря упомянул раньше ORM и сериализацию. Встречаются программисты, считающие, что и сейчас конструкторы с параметрами не поддерживаются. Медленно, но поддержка добавляется. В случаях, когда ORM не справляется с параметрическим конструктором всегда остается план B. Оставить конструктор без параметров приватным или защищенным (в зависимости от того, будете ли вы использовать прокси) и добавить необходимые публичные конструкторы.
public class User : EntityBase
{
public User? Invitee { get; protected set;} // For ORM
public Contact Contact { get; protected set; } // For ORM
public UserName? UserName { get; protected set; } // For ORM
protected User () { } // For ORM
public User (InviteUser command)
public User (SignUp command)
}
ORM будет пользоваться конструктором без параметров несмотря на модификаторы доступа, а в программном коде придется использовать публичные.
public class User : EntityBase
{
public User? Invitee { get; protected set;} // For ORM
public Contact Contact { get; protected set; } // For ORM
public UserName? UserName { get; protected set; } // For ORM
protected User () { } // For ORM
public User (InviteUser command)
public User (SignUp command)
}
К сожалению модификаторы доступа не защищают от коллег, меняющих доступ конструктора без параметров на public. Это вопрос проведения код-ревью, а не архитектуры системы.
Также, конструкторы не поддерживают async/await. Этот вопрос хорошо разобран в статье Марка Симана Asynchronous Injection.
В некоторых случаях вместо публичного конструктора может лучше подойти фабричный метод, реализующий TryPattern. Использовать ли исключения для ошибок бизнес-логики вопрос неоднозначный. Подробнее об этом в статье Об ошибках и исключениях.
Подведем первые итоги. Я считаю, что счет 1:0 в пользу богатой модели. Совершив несколько тривиальных преобразований мы улучшили читаемость кода и сделали бизнес-правила явными повысили надежность и удобство сопровождения программы. Перейдем к более сложным сценариям. Пока мы работали только с сущностями и value object. Как дела обстоят с агрегатами? Как будет обеспечиваться инвариант целой группы объектов?
Агрегаты
Классический пример агрегата — заказ в интернет магазине. Если заказ оплачен и доставлен, поздно добавлять в него новые товары. Поэтому список товаров в заказе не может быть публичным, иначе любой программист сможет воспользоваться этим свойством и добавить товар, несмотря на статус, и будет при этом абсолютно прав, потому что сигнатура класса никак не сообщила ему о зависимости между состоянием заказа и товарами в нем.
public class Order : EntityBase
{
private List<CartItem> _cartItems = new List<CartItem>();
public IReadOnlyList<CartItem> CartItems => _cartItems;
public void Add(Product product)
{
_cartItems.Add(new CartItem(this, product));
}
}
Столь же классическое решение этой проблемы — предоставить во вне readonly-список, а операции записи осуществлять с помощью специализированных методов, содержащих необходимые проверки. И с этого момента начинаются первые проблемы.
Паттерн Агрегат — очень хорошо выглядит на бумаге, но оказывается весьма неуклюжим, когда дело доходит до практики. Агрегаты по своей природе сложнее чем сущности или объекты-значения, потому что представляют собой не один объект, а целое дерево. Поэтому проблемы, которые казались на уровне сущностей незначительными, становятся весьма неприятными по мере роста дерева объектов и возможных комбинаций состояний. Рассмотрим типовой сценарий работы с заказом: проверка наличия на складе, отправка, отмена. 
Нужно ли проверять наличие на складе до оплаты? Зависит от требований. Можно ли отправлять заказ до оплаты? Некоторые магазины разрешают оплачивать при получении курьером, правда чаще всего только если доставка осуществляется внутри города. Можно ли отменить заказ, удачно поставленный покупателю. Скорее всего в нашем дизайне не хватает статусов и лучше подойдет не «отменен», а новый статус «разбирательство», открывающий целый новый процесс: то ли мы разбили товар во время доставки, то ли на складе что-то перепутали, то ли покупатель что-то напутал и ему привезли ровно то что он заказывал.
Данные и методы, связанные с соответствующими состояниями заказа имеют смысл, только в рамках одного состояния. Мы же снова объединили все в одном классе и получили пусть и вкусный, но все-таки винегрет. Поэтому счет сравнялся — 1:1. Напоминаю, анемичная модель никогда не утверждала, что будет соблюдаться инвариант, тем более для группы объектов и не обещала того, что из программного кода будут понятны бизнес-правила, поэтому в рамках анемичной модели претензий к дизайну нет, а к богатой появились вопросы. Где выразительность? Где статический анализ для бизнес-правил? Его нет, по крайней мере в классических объектно-ориентированных языках. Зато такая возможность есть в функциональных ЯП с более сильной системой типов.
В F# все иначе
В F# существуют так-называемые алгебраические типы данных: records (да-да, те самые, что завезут в C#9) и discriminated union. 
Поддержки discriminated union в C# в ближайшее время не планируется. Можно воспринимать их как enum на стероидах. В отличие от классического enum-а в перечислении discriminated union могут входить другие типы, в т.ч. и records. Именно поэтому, такая система типов называется «алгебраической». Record — это тип «и &», а discriminated union 0 это тип «или |». Таким образом все приложение может быть построено за счет комбинирования маленьких типов одним из способом. В отличие, от привычного в ООП control flow, основанного на полиморфизме, в ФП часто используется передача управления с помощью pattern matching. Для каждого подтипа в discriminated union необходимо написать свою ветку выполнения, в которой будут доступны только данные и поведение, имеющее смысл в рамках в данного состояния объекта.
В отличие, от привычного в ООП control flow, основанного на полиморфизме, в ФП часто используется передача управления с помощью pattern matching. Для каждого подтипа в discriminated union необходимо написать свою ветку выполнения, в которой будут доступны только данные и поведение, имеющее смысл в рамках в данного состояния объекта.
Эта проблема решается и без применения F#, однако в C# решение выглядит менее элегантным. В статье Шаблон проектирования «состояние» двадцать лет спустя имитируется функциональный подход на основе классического ООП-паттерна с применением современных языковых конструкций C#. На момент написания статьи switch expression еще не зарелизили. С ним pattern matching выглядит лучше. Проконтролировать разбор всех наследников можно написав свой анализатор Roslyn.
 Несмотря на то что мне пришлось сменить язык программирования, я считаю что можно выдать богатой модели еще одно очко. Счет становится 2:1. F# совместим с C# и поддерживает объектно-ориентированную парадигму, поэтому используя только F# или F# в сочетание с C# можно решить проблему разного поведения в разных состояниях. К сожалению, радоваться еще рано. У меня в запасе есть еще несколько сценариев проблематичных сценариев.
Несмотря на то что мне пришлось сменить язык программирования, я считаю что можно выдать богатой модели еще одно очко. Счет становится 2:1. F# совместим с C# и поддерживает объектно-ориентированную парадигму, поэтому используя только F# или F# в сочетание с C# можно решить проблему разного поведения в разных состояниях. К сожалению, радоваться еще рано. У меня в запасе есть еще несколько сценариев проблематичных сценариев.
Домен и инфраструктура
Распределенные транзакции
«Классическое фаулеро-эвансвое» DDD настаивает на том, что инфраструктура и домен должны быть разделены. А что делать, если инфраструктура становится частью домена. Как так? Легко. Например системы документооборота. Представьте, что вам нужно загружать и подписывать цифровыми подписями, а затем парсить и работать с данными из сотни тысяч документов. Каждый раз открывать бинарные файлы — не вариант. Поэтому вам потребуется механизм, гарантирующий консистентность данных в бинарных файлах и в реляционной структуре при добавлении новых или редактировании старых документов. 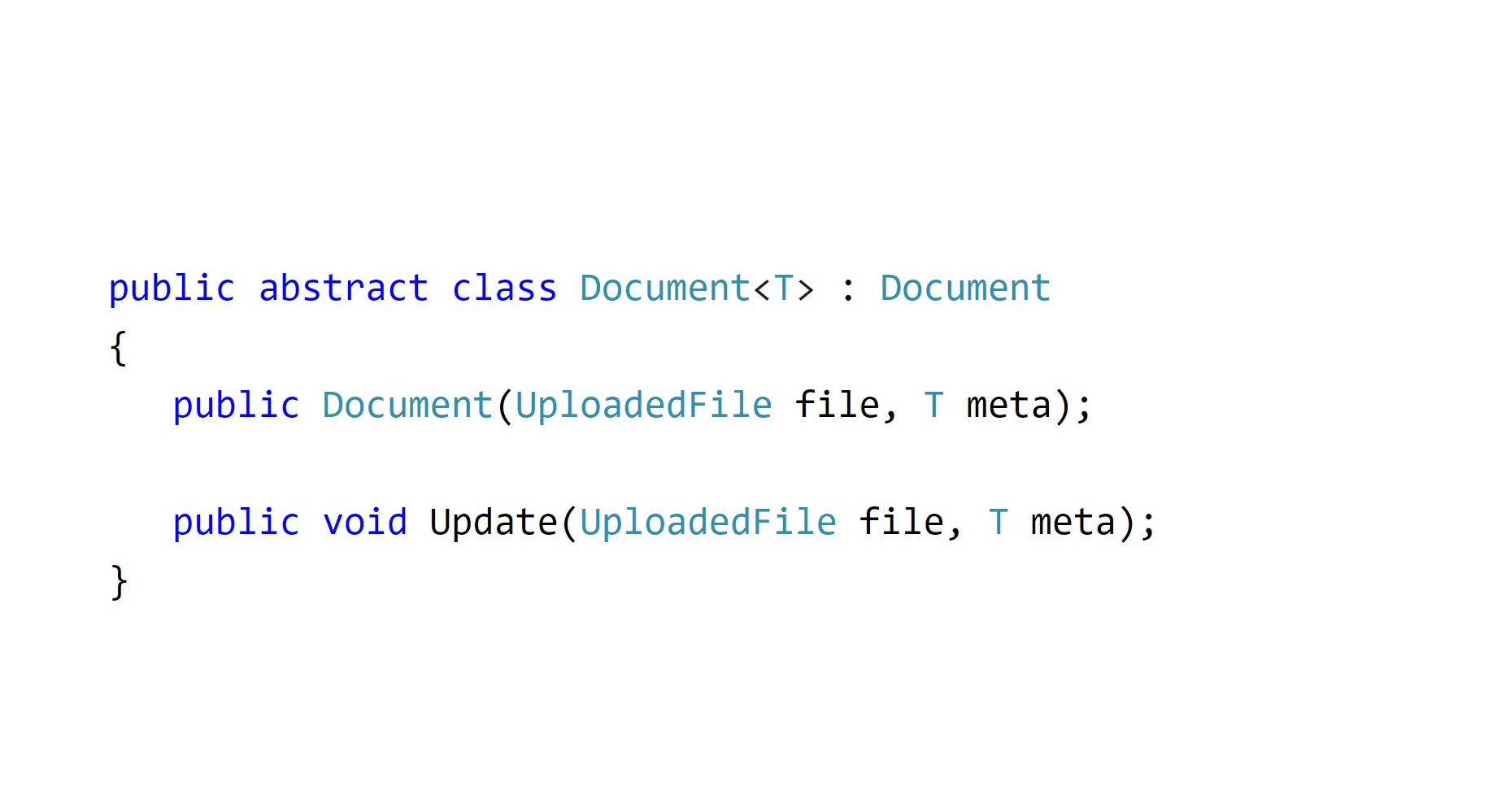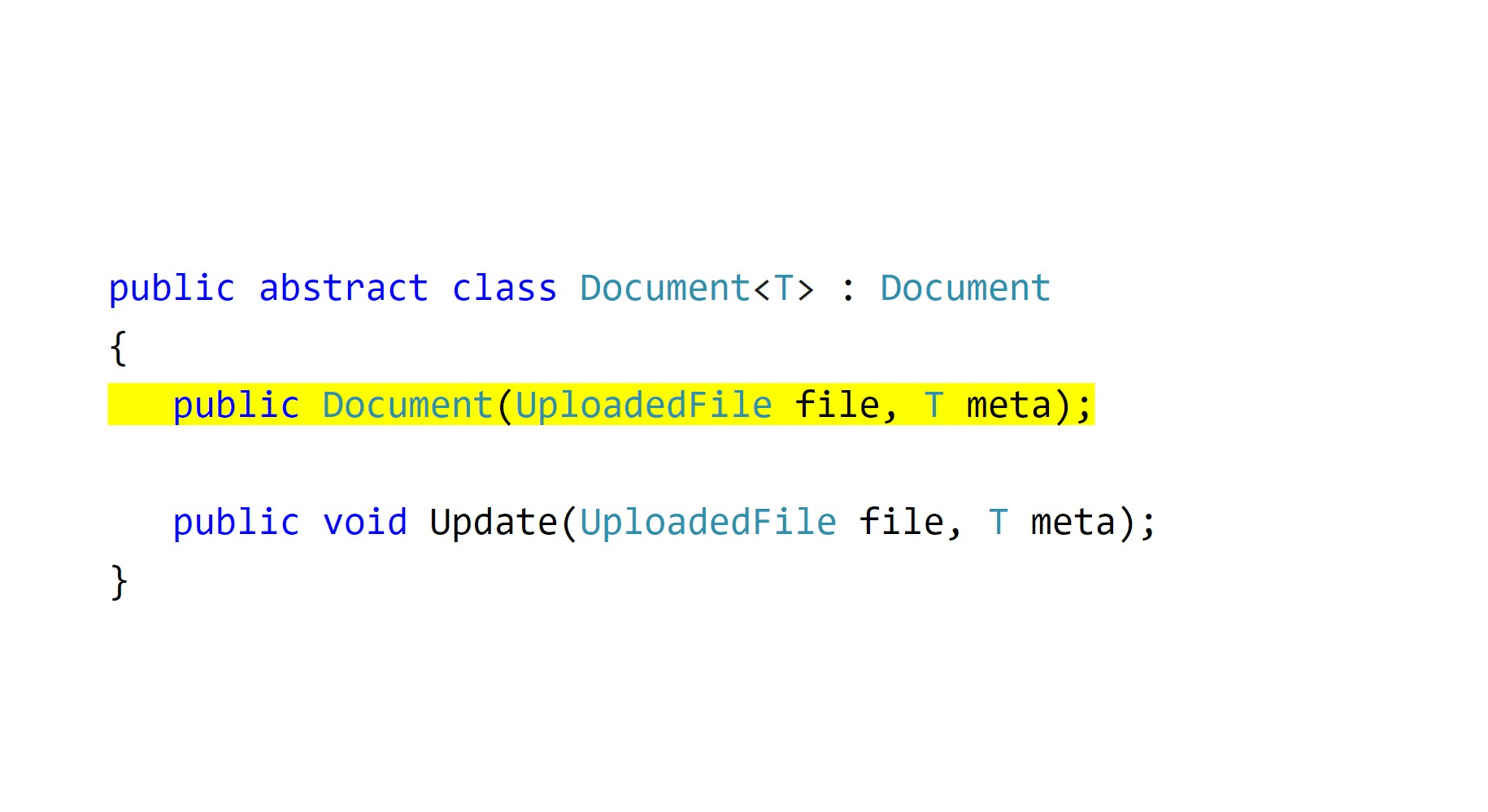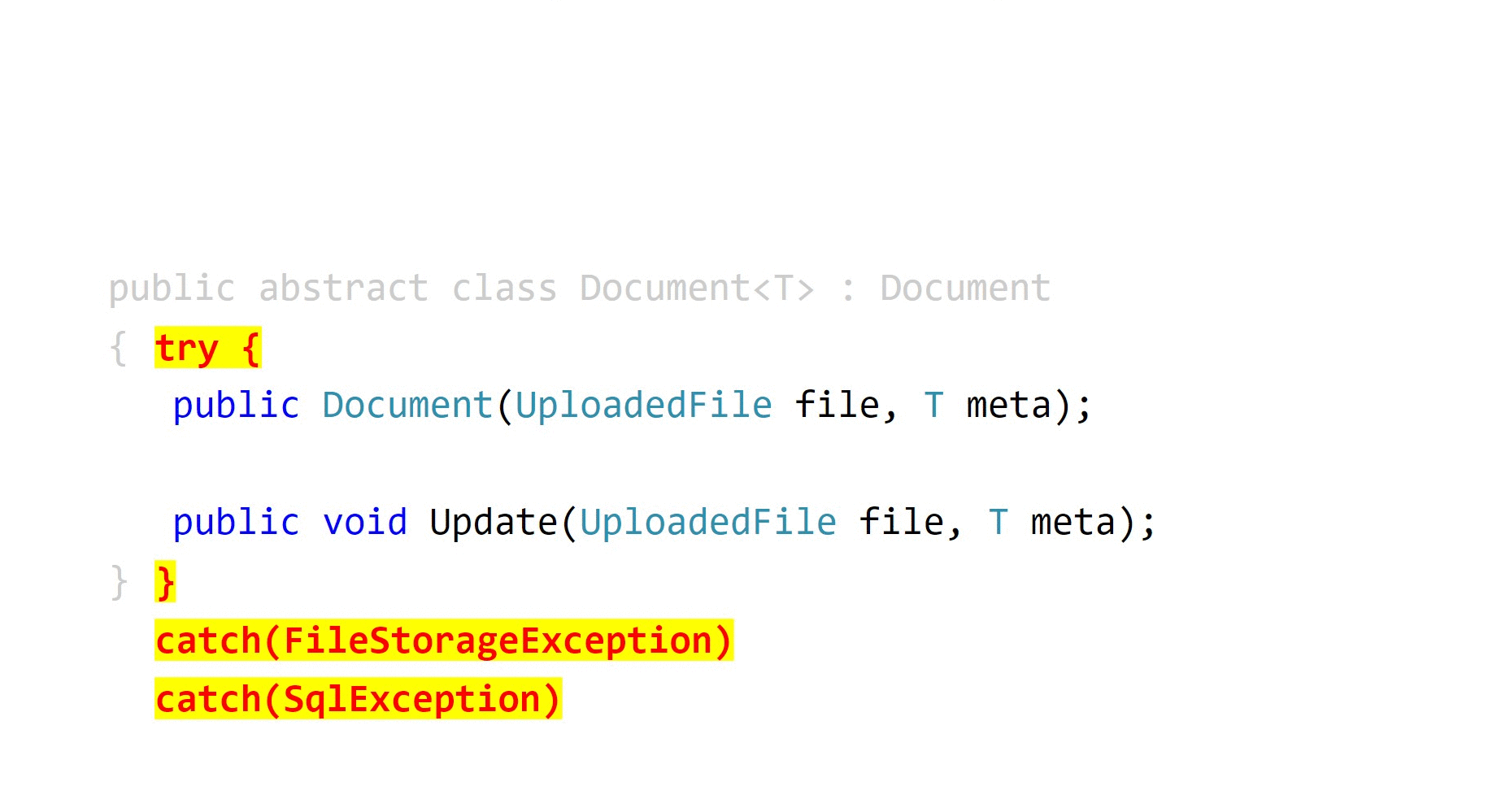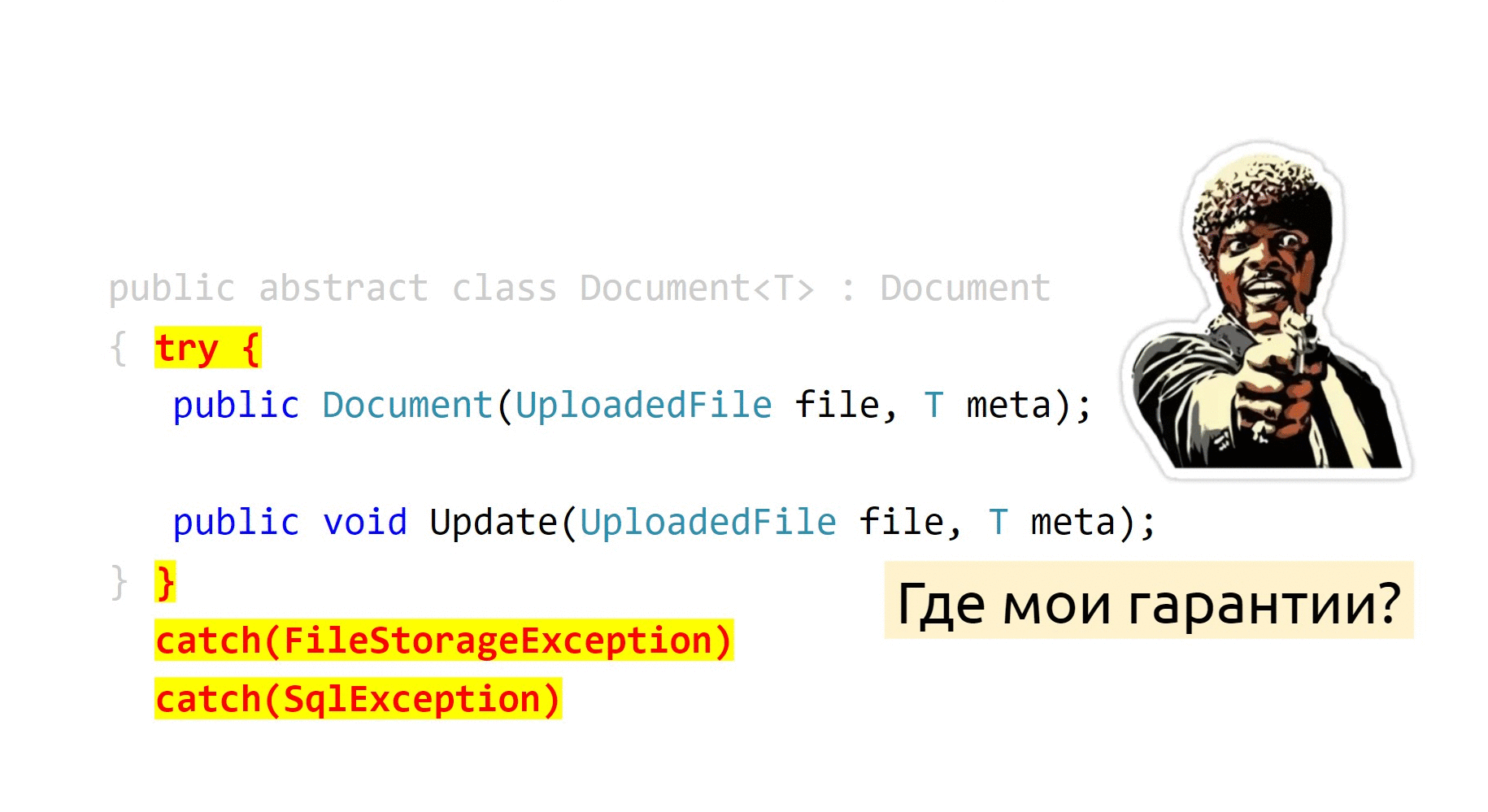
В основе таких гарантий лежит обработка ошибок, как связанных с системой хранения файлов, так и с БД. Если в момент обновления первого или второго происходит ошибка, то выполняется компенсация — удаляется загруженный файл или откатывается транзакция к БД. Да, существуют механизмы распределенных транзакций. Если бы они работали на любой инфраструктуре, с любыми хранилищами данных проблема бы не существовала. К сожалению это не так, и довольно часто приходится писать код, специфичный для конкретного проекта и его инфраструктуры.
Internal
Можно делегировать это разработчикам, но где гарантия того, что каждый из разработчиков окажется достаточно ответственным и не забудет что-то обработать? Мой опыт показывает, что таких гарантий дать нельзя. Счёт сравнивается 2:2.
Я считаю, что единственный способ что-то гарантировать — это отобрать возможность выбора. Если public заменить на internal, положить эти объекты в одну сборку, а публичный API предоставить через специализированные методы сервисов, то куда вы денетесь с подводной лодки?
public abstract class Document<T> : Document
{
try
{
internal Document(UploadedFile file, T meta);
internal void Update(UploadedFile file, T meta);
}
}
catch(FileStorageException)
// ...
catch(SqlException)
// ...
Сервисный слой
Для обновления документа мы:
- передаем в метод Update и сам документ, и загруженный файл;
- пытаемся загрузить файл в fileStorage;
- пытаемся записать данные в базу данных;
- пишем обработчик try-catch: если что-то пошло не так, пробуем откатить файловое хранилище; если файловое хранилище не откатывается, то попробуем залогировать эту ошибку, чтобы потом руками разобраться.

Теперь все будут использовать именно этот метод. Я предпочел бы этот страшный зашумлённый код никогда больше не писать и оставить здесь — чтобы он был только в одном сервисе, и ключевое слово internal нам помогает ровно так и сделать.
Слой сервисов в доменной модели гораздо более тонкий и служит для специфических задач. Он будет полезен не для всей бизнес логики, а, например, для коммуникации с инфраструктурой.
Все вместе
- Entity + Value Objects: свойства объектов корректны по отдельности и вместе.
- Aggregate: группы объектов корректны.
- Pattern Matching: разное поведение для разных состояний.
- Сервисы + internal: инфраструктура и домен синхронизированы.
Главный вопрос DDD, смысла жизни и всего такого?
Что делать, когда операция падает с OutOfMemoryException или выполняется 10 часов? Прежде чем ответить на этот вопрос, я бы хотел процитировать Джо Армстронга, разработчика языка Erlang:
Вы хотите получить банан, но получаете гориллу, которая держит в руках банан и вместе с ней все джунгли впридачу.
Слышите иронию над неявным изменяемым состоянием, которое присуще ООП? Если вы работаете с объектами по ссылке, тем более с интерфейсными ссылками, и не знаете настоящие реализации, вы не знаете сколько будет внешних ссылок. Так и получаются те самые «джунгли».

Действительно, 2:3. Большие агрегаты падают с OutOfMemoryException, сделать ничего нельзя. По крайней мере в объектной парадигме.
cRud
Если только вы не решите, что в стеке чтения вы не очень-то хотите это всё загружать. А в стеке чтения вы довольно часто не хотите ничего загружать. Поэтому в мире ООП ответ на этот вопрос несколько другой, он звучит так: напишите SQL-запрос.
До этого я рассказывал, что необходимо делать правильную модель домена, нельзя ни в коем случае писать никаких SQL-запросов, всё должно быть объектно, и тут я говорю: «Давайте напишем SQL-запрос». Не то, чтобы я переобуваюсь на ходу, просто DDD — это инструмент. Моделирование домена — это инструмент, паттерн. Не бывает швейцарских ножей, которые работают во всех обстоятельствах. Отчёты — это плохое применение для DDD.
Read-stack — это зачастую плохое применение для DDD, потому что нам нечего там контролировать. Нам надо просто читать данные.
Здесь я опускаю важный аспект предоставления доступа к данным. Конечно нужно «не просто» читать. Если вы используете ORM в read-stack, вас может заинтересовать статья Доступ к данным в многопользовательских приложениях.
А вот в стеке записи это вполне подходящая штука. Кроме того, CQRS, в принципе, некий симбионт для HTTP, потому как протокол HTTP явно говорит о том, что методы POST и DELETE должны менять состояние сервера, но не возвращать данные, а метод READ — читать. Соответственно, если ваше приложение в вебе, то почему бы не воспользоваться такой возможностью.
CrUD
Мы обошли проблему тем, что выбросили доменную модель в стеке чтения, что же делать в других случаях? Классический ответ такой: не ссылайтесь из одного агрегата на другой по ссылке, и будет вам счастье. С этим аргументом тоже есть определённые нюансы: кто-то считает, что это текучая абстракция, что это не очень хорошо — тем не менее, это работает. По крайней мере, пока у вас не очень большие агрегаты.

Как только они становятся чуть побольше или совсем большими, то у вас начинает падать не некоторый набор агрегатов, а он один. Если у вас именно такие агрегаты, то, возможно, это неправильные агрегаты и они делают неправильный мёд. Возможно, вы их неправильно нарезали. Но бывают, хотя очень редко, такие случаи, когда это неизбежно. Что тогда делать? Давайте я вас сразу предупрежу, что ответы, которые я сейчас дам, будут скатываться по наклонной от уровня «хуже» к «совсем плохо».
По наклонной («плохие» случаи)
Делаем не SOLIDно
Перейдём на уровень «похуже» и ответим для себя на вопрос: насколько мы вообще ценим SOLID? Если принцип D вам не очень близок, и вы не очень знаете, зачем абстракциям зависеть от абстракции или реализации, и вообще вам всё равно — отлично, просто засовываем сюда IQueryable и не паримся. Да, мы нарушили принцип — ну и что?
Если вы считаете, что при использовании LINQ вы ничего не нарушаете, попробуйте заменить лямбду x => x.OrderId == Id на любую другую и скажите — выполняется ли здесь принцип L? Если вы уверены, что принцип L здесь всегда выполняется — у меня для вас плохие новости. Это я к тому, что любая абстракция при определённых условиях начинает течь. Зависит от того, насколько ваше пуританское воспитание позволяет или не позволяет так делать.
public partial class Order : EntityBase
{
public IQueryable<OrderItem> ItemsQuery
=> _dbContext
.Set<OrderItem>
.Where(x => x.OrderId == Id);
}
Lazy Load
Вариант «ещё похуже» — я двигаюсь к абсолютному злу — включите Lazy Load. Он по многим причинам хорош:
- Tell Don’t Ask aka Закон Деметры
- Persistence Ignorance
- Меньше boilerplate
- Простота использования
Несмотря на это, у него есть также и множество всяких известных проблем:
- Производительность
- Непредвиденное IO
- Возможны проблемы с Reflection или кодом, сгенерированным в runtime
- Массовые операции
Проектирование — компромисс
Я уже, кажется, раза два повторил, что не бывает идеальных инструментов: всегда есть компромисс, и проектирование — это компромисс. С моей точки зрения, это настолько важный note point, что я его ещё раз повторю: если у вас никак не получается сделать DDD в read-stack, это не говорит о том, что вы не смогли в DDD, и не говорит о том, что DDD плохой — это говорит о том, что DDD плохой инструмент для этой задачи, поэтому просто возьмите другой инструмент.

Как только вы начинаете возводить всё в абсолют и говорить «нет, мы не будем писать так код, потому что Фаулер Эванс, Вернан — кто угодно — сказал, что „нельзя“, вы обязательно будете испытывать только расстройство. Только эти ребята (на слайде персонажи фильма „Звёздные войны“) возводят всё в абсолют. Поэтому, несмотря на все оговорки и не самое высокое качество тех решений, которые я предложил, давайте считать, что счёт у нас равный — 3:3.
Workarounds
Вернёмся к агрегатам: независимо от того, анемичную или богатую модель мы используем, большие агрегаты никуда не делись. То есть когда вы тащите половину базы данных, чтобы что-то посчитать, по умолчанию такой подход будет менее эффективным, чем просто выполнить запрос к базе данных. Ответить на рукописный запрос всегда будет эффективней, потому что не надо тащить данные по сети, поднимать их в оперативную память и там считать. База данных это делает внутри своего приложения. Значит ли это, что для определённого класса задач объектная модель никак не подходит? Если бы мы работали с Java, я бы сказал „да, так и есть“.
Expressions
В .NET у нас есть технология, которая позволяет преодолеть это ограничение — Expression Trees. Её можно использовать по прямому назначению, то есть писать C# код, а можно использовать как структуру данных — обходить и дальше трансформировать структуру данных тем способом, которым нам нужно.
Specification
Паттерн „Спецификация“ раньше работал только с объектами и создавал проблемы с производительностью, потому что нам нужно было сначала вытащить весь набор данных, а потом в оперативной памяти его отфильтровать. В C# этот паттерн обретает новую жизнь: если у нас есть правило о том, что для продажи только определённые товары, у которых цена больше нуля, мы можем объявить это правило как Expression.
public Spec<Product> IsForSale { get; } =>
new Spec<Product>(x => x.Price > 0);
Оно выглядит как C# код, соответственно, оно может быть частью нашей модели домена, но мы его никогда не выполняем как C# код — мы его используем для трансляции к запросу к базе данных.  При этом мы получаем довольно эффективные запросы. Также если ваши объекты, агрегаты или сущности слишком большие, не обязательно их читать целиком, можно, используя C# и проекции, читать только часть этих данных в виде DTO и делать более производительные программы. Причем необязательно даже делать анонимные типы. Если вы используете AutoMapper или Mapster, можно вообще снизить количество императивного кода и заменить его на декларативный.
При этом мы получаем довольно эффективные запросы. Также если ваши объекты, агрегаты или сущности слишком большие, не обязательно их читать целиком, можно, используя C# и проекции, читать только часть этих данных в виде DTO и делать более производительные программы. Причем необязательно даже делать анонимные типы. Если вы используете AutoMapper или Mapster, можно вообще снизить количество императивного кода и заменить его на декларативный.
Default Interfaces Implementation
При этом возникают некоторые интересные лазейки, которые именно в классической ООП-парадигме не были бы возможными. Начнём с того, что с 8-ой версией C# у нас появились дефолтные реализации интерфейсов.
public class Product : EntityBase
{
public decimal Price { get; }
public decimal DiscountPercent { get; }
public decimal DiscountedPrice()
=> Price - Price / 100 * DiscountPercent;
}
Давайте представим, что у товара есть логика расчёта скидки, которую мы поместили в тот же объект, то есть мы попытались сделать богатую модель. Такому проектированию сопутствуют все проблемы, о которых я говорил до этого: если нам потребуется вытащить большое количество товаров, то память неминуемо закончится. Мы бы хотели это оптимизировать: вместо того, чтобы объявлять метод непосредственно в сущности, мы можем перенести его в интерфейс с дефолтной реализацией.
public interface IHasDiscount
{
decimal Price { get; set; }
decimal DiscountPercent { get; set; }
decimal DiscountedPrice()
=> Price - Price / 100 * DiscountPercent;
}
Теперь этот интерфейс можно „прилепить“ как к сущности, так и к DTO. Непосредственно код будет находиться ни в том, ни в другом объекте, а в реализации интерфейса.
public class ProductListItem : IHasDiscount
public interface IHasDiscount
{
decimal Price { get; }
decimal DiscountPercent { get; }
public decimal DiscountedPrice()
=> Price - Price / 100 * DiscountPercent;
}
Bulk Extensions
Для массовых операций Expressions дают тоже свободу действий. Если не хочется переносить логику в SQL, можно её оставить в Expressions в C# коде. Тогда можно использовать нечто вроде Bulk Extensions, чтобы использовать ту же самую спецификацию на C#: в данном примере — удалить все товары, которых у нас сейчас нет для продажи или поднять на 100 долларов или рублей стоимость товаров, которые мы всё-таки продаём. 
А может F#?

Однако как только я начинаю использовать некоторые такие лазейки, я задумываюсь: на том ли языке программирования я сейчас пишу и тот ли инструмент я использую? Потому что дефолтная реализация интерфейсов — это, фактически, функция, которую мы можем „прилеплять“ к любым типам данных, используя интерфейс. Стоит ли переходить на F#, чтобы реализовать модель домена — каждый решает сам, исходя из потребностей проекта. Мы так и не решились переезжать. Тем не менее, поглядывать в сторону каких-то других языков программирования бывает полезно, чтобы позаимствовать оттуда некоторые идеи.
Bounded Context
Независимо от того, какая модель используется — богатая или анемичная, неплохо было бы разделять приложения на приложения поменьше, хотя бы просто потому, что ими проще управлять.

Ложный агрегат
Я говорил о том, что агрегаты имеют свойство разрастаться. Это происходит, когда мы используем документацию Microsoft и следуем ей вслепую. Например, когда мы хотим объявить связанные коллекции, мы обычно связываем их в две стороны. А вот если пользователь может много чего делать в вашей системе, тогда и объект User будет довольно-таки большим. Это антипаттерн „Божественный объект“.
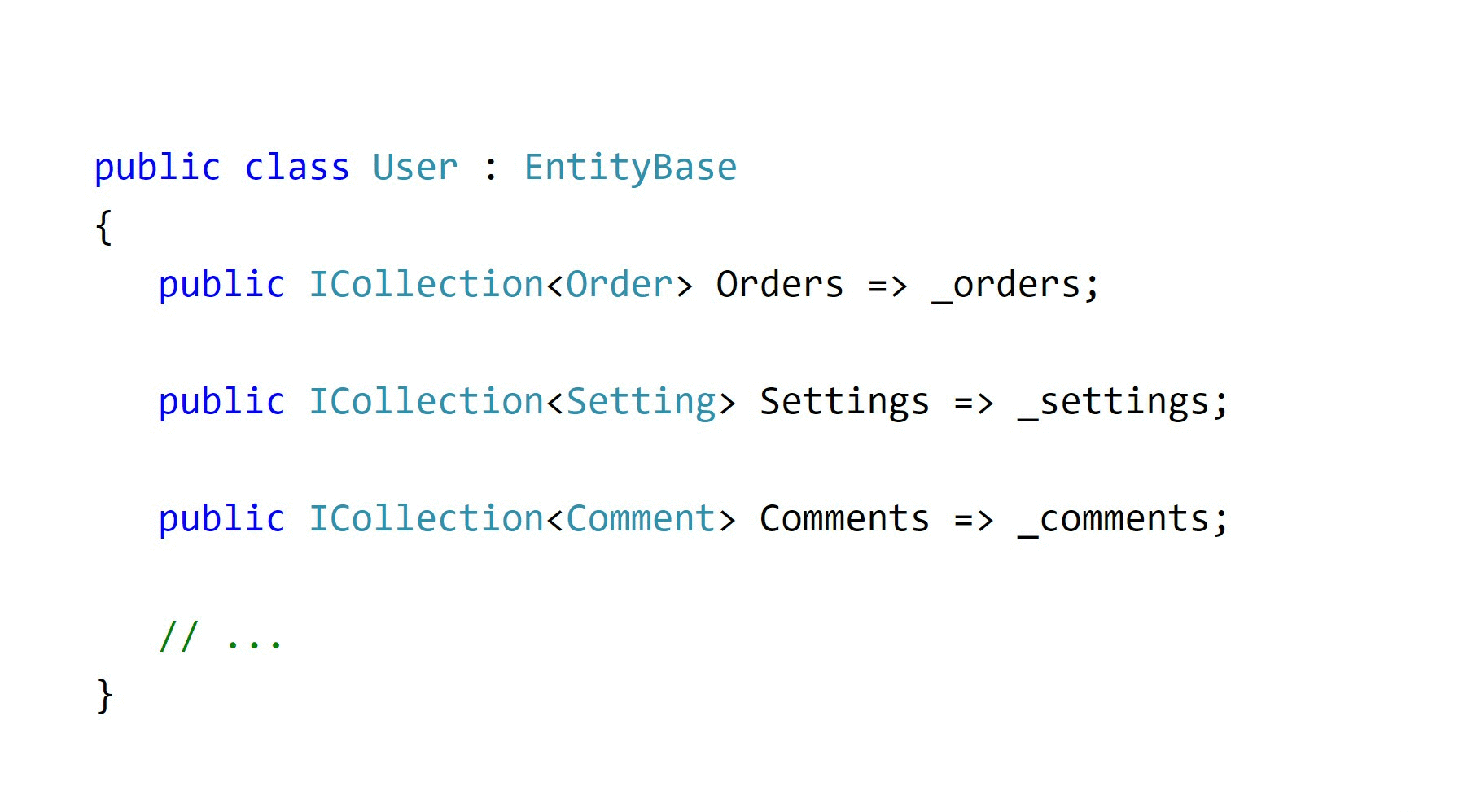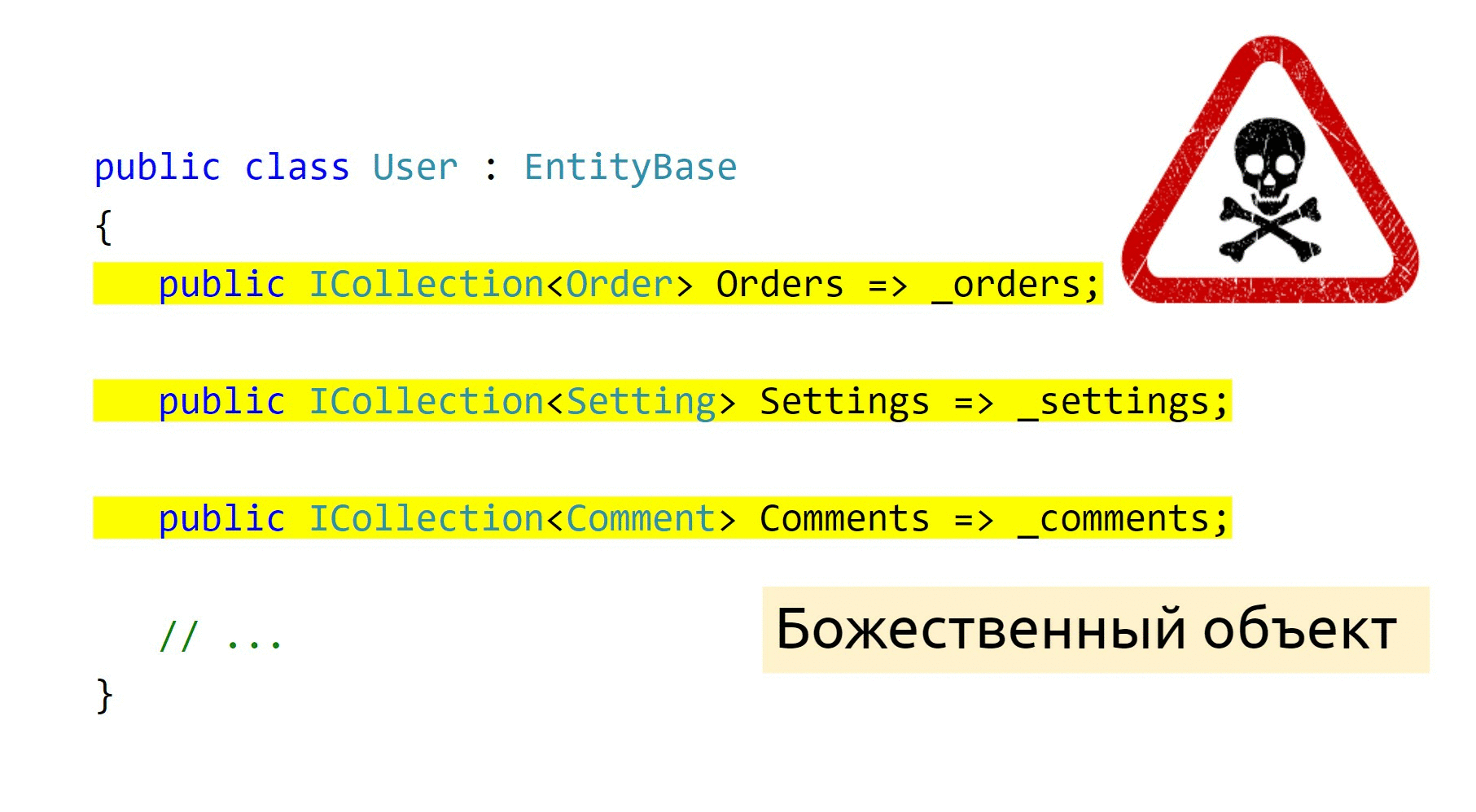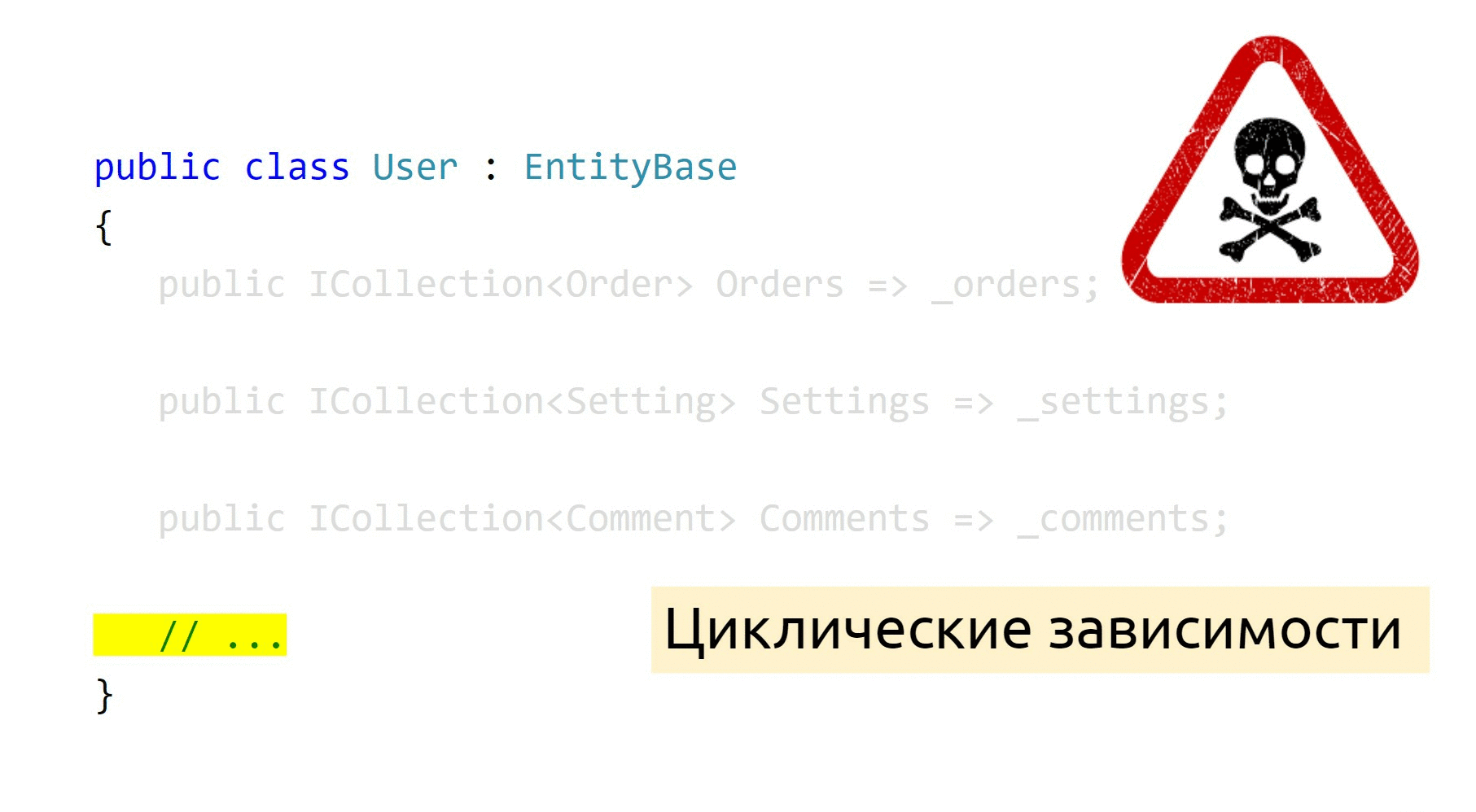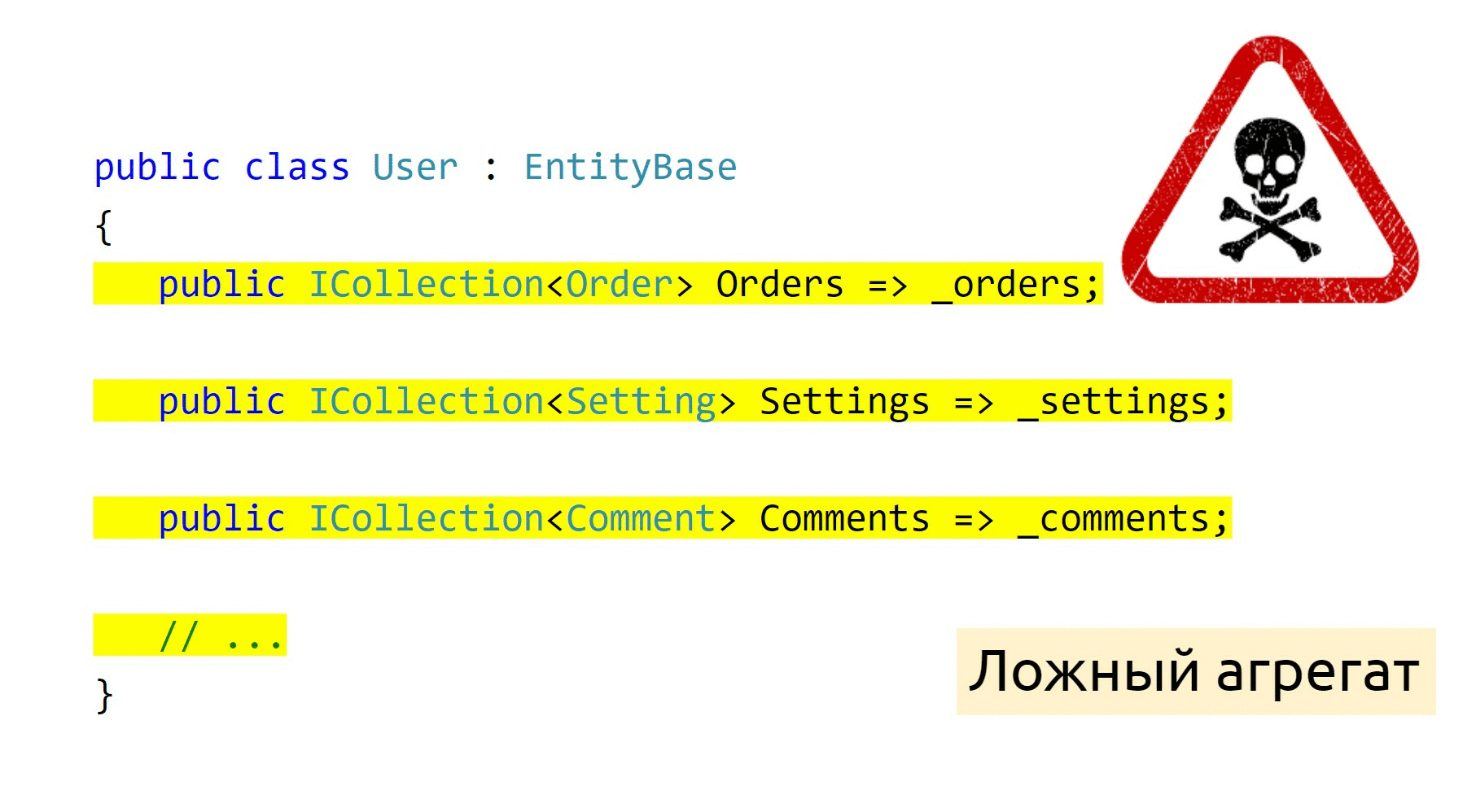
И ладно, если бы он только тратил ресурсы памяти — это мы можем оптимизировать с помощью Expressions. Такой подход ещё и порождает большое количество циклических зависимостей, потому что сейчас у заказов тоже может быть набор пользователей, у комментариев может быть набор товаров, и так далее.
Пока все эти объекты живут у вас в одной сборке, вы получаете такие „круговые“ зависимости: A зависит от B, B зависит от C, C зависит от A. В итоге получается большой и страшный монолит, который мы никак не можем распилить. Всё дело в том, что этот агрегат ложный, в реальном мире его не существует, потому что я объединил в класс пользователя всё, что только можно.
Как же тогда находить корни агрегации и выбирать их правильным способом? Есть два списка вопросов, ответив на которые вы сможете с очень высокой вероятностью понять, тот ли у вас агрегат.
Первый список вопросов (организационный и никак не связан с технологиями)
- Есть ли аналог в реальном мире? (Задайте этот вопрос вашим аналитикам.)
- Когда вы рассказываете о своём дизайне бизнес-пользователям, считают ли они вас местным сумасшедшим?
Если вас не считают сумасшедшим и говорят „да, мы так и работаем“, то вы правильно обнаружили агрегат, проверьте второй список вопросов.
Второй список вопросов (технологический)
- Агрегат не пересекает Bounded Context?
- Есть ли инвариант для этой группы объектов?
- Данные должны изменяться в рамках одной транзакции?
Если ответ на все его вопросы — „да“, значит, агрегат правильный. В нашем случае ответ на всё это — „нет“. Заказы — это отдельная штука, настройки пользователя — другая, отзывы о товарах — третья. Поэтому распилим этот агрегат на три маленьких, уменьшив количество циклических зависимостей. Кроме того, мы можем перенести их по разным сборкам и делегировать работу с этими классами командам.
public class Client : User
{
public ICollection<Order> Orders => _orders;
}
public class Account : User
{
public ICollection<Setting> Settings => _settings;
}
public class Blogger : User
{
public ICollection<Comment> Comments => _comments;
}
Как делить Domain Model на Bounded Context
Как же делить Domain Model на Bounded Context? Я уже сказал, что в итоге внутри контекста у нас будут сущности и агрегаты. Сущности редко имеют тенденцию расползаться, потому что они маленькие, а пример „божественного“ агрегата я приводил до этого. И если вы видите, что агрегат залез между двумя контекстами, значит, он неправильный. Но это правило работает и в обратную сторону: если вы уверены, что агрегат правильный, и ответ на вопросы выше — „да“, то, похоже, вы неправильно нарезали контекст. Поэтому ответ на вопрос „как же нарезать Domain Model на Bounded Context?“ — по границам агрегатов.

Монолит на микросервисы
Этот вопрос можно переформулировать более модно: как делить монолит на микросервисы? Я не считаю, что разделение программы на подмодули вообще зависит от того, распределённая у вас система или нет. Распределённая система сопровождается некоторыми дополнительными проблемами, связанными с тем, что данные у вас находятся в разных процессах, и вам нужно постоянно что-то сериализовывать и десериализовывать.

Но, тем не менее, ответ такой: мы растащили Domain Model на разные Bounded Context, сказали, что Bounded Context — это отдельный микросервис и получили из страшного монолита много маленьких красивых микросервисов. Причём, обратите внимание, все проблемы, связанные со страшными монолитами, которые не распиливаются, чаще всего связаны с тем, что у вас есть циклические зависимости, которые сложно растащить. Если в самый начальный момент этих зависимостей нет, значит и разделить приложение на несколько процессов будет сильно проще.
Как пересечь границу контекстов
Что же делать, если из одного контекста всё-таки надо обратиться к другому контексту? Несмотря на то что они независимые, такое тоже бывает. Вне зависимости от того, разные ли это у вас сервисы или это разные сборки, работающие в одном процессе — в одну сторону бывает дотянуться проще, потому что если один контекст зависит от другого, то и ссылки на эти объекты есть. В другую же сторону уже не получится, потому что циклические зависимости, которые были в рамках одной сборки неявными, становятся явными. Компилятор уже не позволит нам ссылаться двумя сборками друг на друга.

Классическое решение такой ситуации — использование событий. События могут быть сериализованными и пересекать границы контекстов. Как именно „кидаться“ событиями — отдельная история. Если это микросервис, значит, вам потребуется, скорее всего, шина. Если это одно приложение, то это можно сделать и в памяти. Так или иначе, вы закончите тем, что у вас будет диспетчер, который будет слушать все эти события и направлять их по типу на разные обработчики. Если вам требуется реагировать на какие-то события из одного контекста в другом, то „выкидывайте“ события и обрабатывайте их в том контексте, в котором вам нужно.
Что выбрать?
Что же выбрать? Богатую или анемичную модель? Мы остановились на том, что счёт у нас равный. Так или иначе, я занимаюсь управлением разработкой корпоративных систем 5-6 лет, и мне больше симпатизирует богатая модель. Но всегда, когда мы пытались реализовать богатую модель, мы понимали, что это не просто дорого, а невероятно дорого. Соответственно, прежде чем давать ответ на этот вопрос, я предлагаю начертить такую плоскость: по оси абсцисс будет сложность домена, а по оси ординат — техническая сложность проекта.
- Технически сложные проекты в простых доменах не следует делать в DDD, у них другие сложности: у них проблемы с технологиями.
- Я до сих пор не знаю, как делать технически сложные проекты в сложных доменах, поэтому предлагаю не делать такие проекты — не в смысле, что не делать их вовсе, а в смысле разбивать их на более мелкие.
- Простые проекты в простых доменах делайте как хотите — лишь бы подешевле.
- А вот технически простые проекты на сложных доменах — хорошее применение для DDD. Это, например, специализированное ПО для бухгалтерии, бюджета, для врачей, архитекторов — для кого угодно. Там, где домен сложный, можно получить хороший результаты за счет более ответственной работы с доменом как на этапе сбора требований и их анализа, так и на этапе реализации этих требований, но более формальным образом.

Эволюционный рефакторинг
Тем не менее, если вы в начале проекта не совсем ещё поняли, будет он сложным или нет. Или вы не уверены, что ваш проект будет длиться 3, 6, 12, 24 месяца — по моим наблюдениям, это начинает давать результаты где-то после 3 месяцев — то, опять же, ничто не мешает просто начать с анемичной модели и реализовывать некоторые паттерны, когда они вам начинают требоваться. На первом этапе вполне разумно ограничиться следующим:
- Инкапсуляция
- Спецификация
- Entity и Value Objects
Мы пришли к выводу, что накладных расходов на них почти нет, реализуются они легко, а вот дополнительной информации для программиста дают много. Следующим этапом можно начать использовать:
- Agregate
- Bounded Context
- Pattern Matching
Agregate и Bounded Context идут вместе ровно для того, чтобы правильно поделить их границы. В самую последнюю очередь идут:
- Массовые операции
- События
- IHas-интерфейсы
Если вы дошли до этого этапа, то вы, возможно, захотите сменить язык программирования или просто у вас сложный домен, здесь уже всё не так очевидно. Желательно внедрять эти методики как можно позже, потому что они тяжелые, и к ним нет четких и понятных инструкций, как делать лучше.
Полезные ссылки
Несмотря на то, что мы уже долго разбираем DDD, я рассказал, наверное 10% того, что вообще есть на эту тему. Поэтому я выбрал материалы, которые хорошо дополняют мой рассказ.
По-русски
- Деревья выражений в Enterprise-разработке
- Быстрорастворимое проектирование
- Жизнь после бизнес-объектов
- Domain-driven design: рецепт для прагматика
- Сущности в DDD-стиле с Entity Framework Core
- Шпаргалка по основам DDD
In English
- Tackling Complexity in the Heart of Software
- Domain Modeling Made Functional with the F# Type System
- Don’t delete
- Design Smell: Redundant Required Attribute
- EF Core 2.1 vs NHibernate 5.1: DDD perspective
- Value Object: a better implementation
В этом году я буду MC (Master of Ceremonies) на конфереции DotNext 2020 Piter, которая пройдет с 15 по 18 июня. Благодаря онлайн-формату в этом году можно будет задать вопросы известным спикерам, таким как Scott Hanselmann и Jon Skeet.
Спасибо indienkova за помощь в подготовке материала. Без нее расшифровка могла не выйти или выйти значительно позже.
DDD-жаргон
Прежде чем начать соревнование, напомню DDD-жаргон. Модель не монолитна, а разделена на несколько ограниченных контекстов. Вопрос соотношения терминов домен, субдомен и ограниченный контекст я оставляю за скобками, потому что он не важен в рамках доклада. Существование ограниченных контекстов объясняется организационными причинами. Чаще всего невозможно создать единую модель для всего предприятия, потому что такая модель не будет отражать реальную неоднородную структуру компании, разнящейся от отдела к отделу.
Скажем, решили вы заказать изготовление продукции. Пока вы ее не оплатите никто не поднимет пятой точки. Зато после оплаты заявка поступает в отдел производства. Отделу производства в свою очередь не важно оплачена заявка или нет. Для них актуальны сроки выполнения и наличие необходимых материалов на складе. Затем товар отправляется в доставку, которому вообще по барабану что это за товар. Их волнует только расстояние от склада отгрузки до точки доставки.
Таким образом, существует три заявки: на оплату, изготовление и доставку, обладающие разными характеристиками и имеющие смысл только внутри ограниченного контекста, а не всего предприятия. Словарь терминов, понимаемый одинаково в рамках ограниченного контекста называется единым языком. Внутри ограниченного контекста DDD предлагает три основных инструмента моделирования: Value Object, Entity и Aggregate.
Агрегаты — это деревья объектов, обладающие инвариантом для группы, а не для единичного объекта. Доступ к агрегатам осуществляется через «Корень агрегации» — объект, находящийся в корне дерева. Таким образом, корень обеспечивает инвариант всей группы с помощью инкапсуляции.
Сущности и Value Object — это основные строительные блоки приложения, которые могут как входить в агрегаты, так и не входить. Их основное отличие в том, что у сущностей есть уникальный идентификатор, а у объектов-значений — нет.
Дизайн на основе типов
Вернемся к пользователю интернет магазина. Попробуем смоделировать всего один объект в стиле «богатой» модели. Мы пришли к тому, что валидацию инварианта и контекстную валидацию необходимо разделить. Самый простой способ достижения цели — разделить класс, моделирующий пользователя. Напрашивается два основных подтипа:
- профиль пользователя — персональные данные, которые заставим заполнить позже.
- аккаунт пользователя, содержащий контактную информацию, необходимую для его идентификации и оформления заказа.
Подробнее этот подход в докладе Скотта Влашина Domain Modeling Made Functional или нашего с Вагифом Абиловым Жизнь после бизнес-объектов.
Вынести IO на границы (Anticorruption Layer)
Следующим шагом перенесем ввод-вывод на границы приложения. Данные, пришедшие извне по определению могут быть в любом состоянии: как в согласованном, так и нет. DDD даже предлагает специальный паттерн для пограничного контроля ограниченных контекстов — Anticorruption Layer, который, впрочем, отличается от обычного фасада лишь более узкой специализацией.
Все данные из-за пределов контекста сначала попадают в фасад, где происходит проверка. Некорректные данные отвергаются, а данные, прошедшие валидацию идут дальше в слой домена. Над ними выполняются операции бизнес-логики. Результаты покидают пределы слоя домена. Новые входные данные даже на базе результатов «чистого» слоя домена все-равно считаются «грязными» и операция повторяется.
Crud у всего есть начало
Таким образом в домен попадают только корректные данные. Сам же слой домена соблюдает все инварианты, поэтому входные и выходные параметры всех операций должны быть всегда согласованными. Первый рубеж, гарантирующий корректность — конструкторы классов. Конструкторы изначально были задуманы для того, чтобы создавать только согласованные объекты, но долгое время ORM и сериализаторы умели работать только с непараметрическими конструкторами. Кроме того, синтаксис конструкторов в C++ подобных языках оказался чересчур многословным. В итоге, мы можем наблюдать противостояние прививочников и антипрививочников тех, кто считает, что конструкторы нужны и полезны и тех, кто считает, что это слишком многословно.
Проблема инициализации параметров хорошо решена в TypeScript с помощью parameter properties. В C#9 нам обещают records. Эта функциональность планировалась еще в C#8, но разработчики языка решили доработать концепцию и, похоже, что в следующей версии языка мы все-таки их дождемся.
В случае богатой модели выбора нет, конструктор должен быть. Контактные данные сделаем обязательным полем, чтобы использовать их в качестве уникального идентификатора, а профиль пользователя — необязательный параметр конструктора.
public class User : EntityBase { public Contact Contact { get; protected set; } public UserName? UserName { get; protected set; } public User(Contact contact, UserName? userName = null) { Contact = contact; UserName = userName; } }
Контактные данные — это либо email, либо телефон. Необязательно заполнять и то и другое, кол-центр устроит любой способ связи, главное, чтобы он был заполнен верно. Для email — наличие собаки и домена в адресе, а для телефона знака "+" и следующих за ним цифр. Более точные правила валидации email и телефона намеренно опущены, потому что они сейчас не важны.
public class Contact { const string PhonePattern = @"\+?\d"; [EmailAddress] public string? Email { get; } [RegularExpression(PhonePattern)] public string? Phone { get; } private Contact(string? email, string? phone) { Email = email; Phone = phone; } }
Мы могли бы использовать вот такой конструктор, но в C# нет способа показать, что один из параметров является обязательным. Сигнатура метода будет сообщать о том, что оба параметра не обязательные. Поэтому сделаем конструктор закрытым, а вместо него предоставим два публичным метода с более говорящими названиями. В C# обычно используется префикс Try для операций, которые могут завершиться ошибкой, но не выбрасывают исключений. Можно реализовать конструктор таким образом.
public class Contact { public static bool TryParsePhone(string phone, out Contact c) { if (PhoneRegex.IsMatch(phone)) { c = new Contact(null, phone); return true; } c = null; return false; } }
Если не хотите использовать TryPattern, можете использовать атрибуты. Несмотря на то, что атрибуты — это мета-информация, вообще никак не влияющая на исполнение программы, существует уже готовое вполне удобное API, использовав которое в конструкторе мы заставим пройти все проверки.
public class UserName { public UserName(string firstName, string lastName, string? middleName) { FirstName = firstName; LastName = lastName; MiddleName = middleName; Validator.ValidateObject(this, new ValidationContext(this)); } [Required, StringLength(255)] public string FirstName { get; protected set; } [Required, StringLength(255)] public string LastName { get; protected set; } [StringLength(1)] public string? MiddleName { get; protected set; } }
Откуда берутся пользователи
На этом можно было бы остановиться, если бы за пару простых действий нельзя было сделать бизнес-правила более отчетливыми в коде программы. Из сигнатуры конструктора не ясно при каких обстоятельствах пользователи появились в системе. Заменим два параметра на один и дадим ему понятное название.
public class User : EntityBase { public Contact Contact { get; protected set; } public UserName? UserName { get; protected set; } public User (SignUp command) { Contact = command.Contact; UserName = command.UserName; } }
Теперь стало ясно, что пользователь может зарегистрироваться самостоятельно (SignUp) или зарегистрироваться по приглашению друга (SignUpByInvite). Механизм приглашений может натолкнуть читающего код на мысль о том что в системе существует реферальная программа. У этого изменения есть еще один неожиданный побочный эффект. Представьте, что в логах есть два разных сообщения об ошибке:
- Что-то пошло не так во время регистрации пользователя
- Что-то пошло не так, когда Маша пыталась зарегистрироваться по приглашению Паши
Второе гораздо информативнее. Конкретные Маша и Паша, конкретный процесс регистрации, а не абстрактная ошибка регистрации в вакууме. Таким образом, сопровождать продукт новым разработчикам, не знакомым со всеми требованиями станет несколько проще.
public class User : EntityBase { public User? Invitee { get; protected set;} public Contact Contact { get; protected set; } public UserName? UserName { get; protected set; } public User (InviteUser command) { Contact = command.Contact; UserName = command.UserName; Invitee = command.Invitee; } }
Поверья
Я не зря упомянул раньше ORM и сериализацию. Встречаются программисты, считающие, что и сейчас конструкторы с параметрами не поддерживаются. Медленно, но поддержка добавляется. В случаях, когда ORM не справляется с параметрическим конструктором всегда остается план B. Оставить конструктор без параметров приватным или защищенным (в зависимости от того, будете ли вы использовать прокси) и добавить необходимые публичные конструкторы.
public class User : EntityBase { public User? Invitee { get; protected set;} // For ORM public Contact Contact { get; protected set; } // For ORM public UserName? UserName { get; protected set; } // For ORM protected User () { } // For ORM public User (InviteUser command) public User (SignUp command) }
ORM будет пользоваться конструктором без параметров несмотря на модификаторы доступа, а в программном коде придется использовать публичные.
public class User : EntityBase { public User? Invitee { get; protected set;} // For ORM public Contact Contact { get; protected set; } // For ORM public UserName? UserName { get; protected set; } // For ORM protected User () { } // For ORM public User (InviteUser command) public User (SignUp command) }
К сожалению модификаторы доступа не защищают от коллег, меняющих доступ конструктора без параметров на public. Это вопрос проведения код-ревью, а не архитектуры системы.
Также, конструкторы не поддерживают async/await. Этот вопрос хорошо разобран в статье Марка Симана Asynchronous Injection.
В некоторых случаях вместо публичного конструктора может лучше подойти фабричный метод, реализующий TryPattern. Использовать ли исключения для ошибок бизнес-логики вопрос неоднозначный. Подробнее об этом в статье Об ошибках и исключениях.
Подведем первые итоги. Я считаю, что счет 1:0 в пользу богатой модели. Совершив несколько тривиальных преобразований мы улучшили читаемость кода и сделали бизнес-правила явными повысили надежность и удобство сопровождения программы. Перейдем к более сложным сценариям. Пока мы работали только с сущностями и value object. Как дела обстоят с агрегатами? Как будет обеспечиваться инвариант целой группы объектов?
Агрегаты
Классический пример агрегата — заказ в интернет магазине. Если заказ оплачен и доставлен, поздно добавлять в него новые товары. Поэтому список товаров в заказе не может быть публичным, иначе любой программист сможет воспользоваться этим свойством и добавить товар, несмотря на статус, и будет при этом абсолютно прав, потому что сигнатура класса никак не сообщила ему о зависимости между состоянием заказа и товарами в нем.
public class Order : EntityBase { private List<CartItem> _cartItems = new List<CartItem>(); public IReadOnlyList<CartItem> CartItems => _cartItems; public void Add(Product product) { _cartItems.Add(new CartItem(this, product)); } }
Столь же классическое решение этой проблемы — предоставить во вне readonly-список, а операции записи осуществлять с помощью специализированных методов, содержащих необходимые проверки. И с этого момента начинаются первые проблемы.
Паттерн Агрегат — очень хорошо выглядит на бумаге, но оказывается весьма неуклюжим, когда дело доходит до практики. Агрегаты по своей природе сложнее чем сущности или объекты-значения, потому что представляют собой не один объект, а целое дерево. Поэтому проблемы, которые казались на уровне сущностей незначительными, становятся весьма неприятными по мере роста дерева объектов и возможных комбинаций состояний. Рассмотрим типовой сценарий работы с заказом: проверка наличия на складе, отправка, отмена.
Нужно ли проверять наличие на складе до оплаты? Зависит от требований. Можно ли отправлять заказ до оплаты? Некоторые магазины разрешают оплачивать при получении курьером, правда чаще всего только если доставка осуществляется внутри города. Можно ли отменить заказ, удачно поставленный покупателю. Скорее всего в нашем дизайне не хватает статусов и лучше подойдет не «отменен», а новый статус «разбирательство», открывающий целый новый процесс: то ли мы разбили товар во время доставки, то ли на складе что-то перепутали, то ли покупатель что-то напутал и ему привезли ровно то что он заказывал.
Данные и методы, связанные с соответствующими состояниями заказа имеют смысл, только в рамках одного состояния. Мы же снова объединили все в одном классе и получили пусть и вкусный, но все-таки винегрет. Поэтому счет сравнялся — 1:1. Напоминаю, анемичная модель никогда не утверждала, что будет соблюдаться инвариант, тем более для группы объектов и не обещала того, что из программного кода будут понятны бизнес-правила, поэтому в рамках анемичной модели претензий к дизайну нет, а к богатой появились вопросы. Где выразительность? Где статический анализ для бизнес-правил? Его нет, по крайней мере в классических объектно-ориентированных языках. Зато такая возможность есть в функциональных ЯП с более сильной системой типов.
В F# все иначе
В F# существуют так-называемые алгебраические типы данных: records (да-да, те самые, что завезут в C#9) и discriminated union.
Поддержки discriminated union в C# в ближайшее время не планируется. Можно воспринимать их как enum на стероидах. В отличие от классического enum-а в перечислении discriminated union могут входить другие типы, в т.ч. и records. Именно поэтому, такая система типов называется «алгебраической». Record — это тип «и &», а discriminated union 0 это тип «или |». Таким образом все приложение может быть построено за счет комбинирования маленьких типов одним из способом.
В отличие, от привычного в ООП control flow, основанного на полиморфизме, в ФП часто используется передача управления с помощью pattern matching. Для каждого подтипа в discriminated union необходимо написать свою ветку выполнения, в которой будут доступны только данные и поведение, имеющее смысл в рамках в данного состояния объекта.Эта проблема решается и без применения F#, однако в C# решение выглядит менее элегантным. В статье Шаблон проектирования «состояние» двадцать лет спустя имитируется функциональный подход на основе классического ООП-паттерна с применением современных языковых конструкций C#. На момент написания статьи switch expression еще не зарелизили. С ним pattern matching выглядит лучше. Проконтролировать разбор всех наследников можно написав свой анализатор Roslyn.
Несмотря на то что мне пришлось сменить язык программирования, я считаю что можно выдать богатой модели еще одно очко. Счет становится 2:1. F# совместим с C# и поддерживает объектно-ориентированную парадигму, поэтому используя только F# или F# в сочетание с C# можно решить проблему разного поведения в разных состояниях. К сожалению, радоваться еще рано. У меня в запасе есть еще несколько сценариев проблематичных сценариев.Домен и инфраструктура
Распределенные транзакции
«Классическое фаулеро-эвансвое» DDD настаивает на том, что инфраструктура и домен должны быть разделены. А что делать, если инфраструктура становится частью домена. Как так? Легко. Например системы документооборота. Представьте, что вам нужно загружать и подписывать цифровыми подписями, а затем парсить и работать с данными из сотни тысяч документов. Каждый раз открывать бинарные файлы — не вариант. Поэтому вам потребуется механизм, гарантирующий консистентность данных в бинарных файлах и в реляционной структуре при добавлении новых или редактировании старых документов.
В основе таких гарантий лежит обработка ошибок, как связанных с системой хранения файлов, так и с БД. Если в момент обновления первого или второго происходит ошибка, то выполняется компенсация — удаляется загруженный файл или откатывается транзакция к БД. Да, существуют механизмы распределенных транзакций. Если бы они работали на любой инфраструктуре, с любыми хранилищами данных проблема бы не существовала. К сожалению это не так, и довольно часто приходится писать код, специфичный для конкретного проекта и его инфраструктуры.
Internal
Можно делегировать это разработчикам, но где гарантия того, что каждый из разработчиков окажется достаточно ответственным и не забудет что-то обработать? Мой опыт показывает, что таких гарантий дать нельзя. Счёт сравнивается 2:2.
Я считаю, что единственный способ что-то гарантировать — это отобрать возможность выбора. Если public заменить на internal, положить эти объекты в одну сборку, а публичный API предоставить через специализированные методы сервисов, то куда вы денетесь с подводной лодки?
public abstract class Document<T> : Document { try { internal Document(UploadedFile file, T meta); internal void Update(UploadedFile file, T meta); } } catch(FileStorageException) // ... catch(SqlException) // ...
Сервисный слой
Для обновления документа мы:
- передаем в метод Update и сам документ, и загруженный файл;
- пытаемся загрузить файл в fileStorage;
- пытаемся записать данные в базу данных;
- пишем обработчик try-catch: если что-то пошло не так, пробуем откатить файловое хранилище; если файловое хранилище не откатывается, то попробуем залогировать эту ошибку, чтобы потом руками разобраться.
Теперь все будут использовать именно этот метод. Я предпочел бы этот страшный зашумлённый код никогда больше не писать и оставить здесь — чтобы он был только в одном сервисе, и ключевое слово internal нам помогает ровно так и сделать.
Слой сервисов в доменной модели гораздо более тонкий и служит для специфических задач. Он будет полезен не для всей бизнес логики, а, например, для коммуникации с инфраструктурой.
Все вместе
- Entity + Value Objects: свойства объектов корректны по отдельности и вместе.
- Aggregate: группы объектов корректны.
- Pattern Matching: разное поведение для разных состояний.
- Сервисы + internal: инфраструктура и домен синхронизированы.
Главный вопрос DDD, смысла жизни и всего такого?
Что делать, когда операция падает с OutOfMemoryException или выполняется 10 часов? Прежде чем ответить на этот вопрос, я бы хотел процитировать Джо Армстронга, разработчика языка Erlang:
Вы хотите получить банан, но получаете гориллу, которая держит в руках банан и вместе с ней все джунгли впридачу.Слышите иронию над неявным изменяемым состоянием, которое присуще ООП? Если вы работаете с объектами по ссылке, тем более с интерфейсными ссылками, и не знаете настоящие реализации, вы не знаете сколько будет внешних ссылок. Так и получаются те самые «джунгли».
Действительно, 2:3. Большие агрегаты падают с OutOfMemoryException, сделать ничего нельзя. По крайней мере в объектной парадигме.
cRud
Если только вы не решите, что в стеке чтения вы не очень-то хотите это всё загружать. А в стеке чтения вы довольно часто не хотите ничего загружать. Поэтому в мире ООП ответ на этот вопрос несколько другой, он звучит так: напишите SQL-запрос.
До этого я рассказывал, что необходимо делать правильную модель домена, нельзя ни в коем случае писать никаких SQL-запросов, всё должно быть объектно, и тут я говорю: «Давайте напишем SQL-запрос». Не то, чтобы я переобуваюсь на ходу, просто DDD — это инструмент. Моделирование домена — это инструмент, паттерн. Не бывает швейцарских ножей, которые работают во всех обстоятельствах. Отчёты — это плохое применение для DDD.
Read-stack — это зачастую плохое применение для DDD, потому что нам нечего там контролировать. Нам надо просто читать данные.
Здесь я опускаю важный аспект предоставления доступа к данным. Конечно нужно «не просто» читать. Если вы используете ORM в read-stack, вас может заинтересовать статья Доступ к данным в многопользовательских приложениях.
А вот в стеке записи это вполне подходящая штука. Кроме того, CQRS, в принципе, некий симбионт для HTTP, потому как протокол HTTP явно говорит о том, что методы POST и DELETE должны менять состояние сервера, но не возвращать данные, а метод READ — читать. Соответственно, если ваше приложение в вебе, то почему бы не воспользоваться такой возможностью.
CrUD
Мы обошли проблему тем, что выбросили доменную модель в стеке чтения, что же делать в других случаях? Классический ответ такой: не ссылайтесь из одного агрегата на другой по ссылке, и будет вам счастье. С этим аргументом тоже есть определённые нюансы: кто-то считает, что это текучая абстракция, что это не очень хорошо — тем не менее, это работает. По крайней мере, пока у вас не очень большие агрегаты.
Как только они становятся чуть побольше или совсем большими, то у вас начинает падать не некоторый набор агрегатов, а он один. Если у вас именно такие агрегаты, то, возможно, это неправильные агрегаты и они делают неправильный мёд. Возможно, вы их неправильно нарезали. Но бывают, хотя очень редко, такие случаи, когда это неизбежно. Что тогда делать? Давайте я вас сразу предупрежу, что ответы, которые я сейчас дам, будут скатываться по наклонной от уровня «хуже» к «совсем плохо».
По наклонной («плохие» случаи)
Делаем не SOLIDно
Перейдём на уровень «похуже» и ответим для себя на вопрос: насколько мы вообще ценим SOLID? Если принцип D вам не очень близок, и вы не очень знаете, зачем абстракциям зависеть от абстракции или реализации, и вообще вам всё равно — отлично, просто засовываем сюда IQueryable и не паримся. Да, мы нарушили принцип — ну и что?
Если вы считаете, что при использовании LINQ вы ничего не нарушаете, попробуйте заменить лямбду
x => x.OrderId == Id на любую другую и скажите — выполняется ли здесь принцип L? Если вы уверены, что принцип L здесь всегда выполняется — у меня для вас плохие новости. Это я к тому, что любая абстракция при определённых условиях начинает течь. Зависит от того, насколько ваше пуританское воспитание позволяет или не позволяет так делать.public partial class Order : EntityBase { public IQueryable<OrderItem> ItemsQuery => _dbContext .Set<OrderItem> .Where(x => x.OrderId == Id); }
Lazy Load
Вариант «ещё похуже» — я двигаюсь к абсолютному злу — включите Lazy Load. Он по многим причинам хорош:
- Tell Don’t Ask aka Закон Деметры
- Persistence Ignorance
- Меньше boilerplate
- Простота использования
Несмотря на это, у него есть также и множество всяких известных проблем:
- Производительность
- Непредвиденное IO
- Возможны проблемы с Reflection или кодом, сгенерированным в runtime
- Массовые операции
Проектирование — компромисс
Я уже, кажется, раза два повторил, что не бывает идеальных инструментов: всегда есть компромисс, и проектирование — это компромисс. С моей точки зрения, это настолько важный note point, что я его ещё раз повторю: если у вас никак не получается сделать DDD в read-stack, это не говорит о том, что вы не смогли в DDD, и не говорит о том, что DDD плохой — это говорит о том, что DDD плохой инструмент для этой задачи, поэтому просто возьмите другой инструмент.
Как только вы начинаете возводить всё в абсолют и говорить «нет, мы не будем писать так код, потому что Фаулер Эванс, Вернан — кто угодно — сказал, что „нельзя“, вы обязательно будете испытывать только расстройство. Только эти ребята (на слайде персонажи фильма „Звёздные войны“) возводят всё в абсолют. Поэтому, несмотря на все оговорки и не самое высокое качество тех решений, которые я предложил, давайте считать, что счёт у нас равный — 3:3.
Workarounds
Вернёмся к агрегатам: независимо от того, анемичную или богатую модель мы используем, большие агрегаты никуда не делись. То есть когда вы тащите половину базы данных, чтобы что-то посчитать, по умолчанию такой подход будет менее эффективным, чем просто выполнить запрос к базе данных. Ответить на рукописный запрос всегда будет эффективней, потому что не надо тащить данные по сети, поднимать их в оперативную память и там считать. База данных это делает внутри своего приложения. Значит ли это, что для определённого класса задач объектная модель никак не подходит? Если бы мы работали с Java, я бы сказал „да, так и есть“.
Expressions
В .NET у нас есть технология, которая позволяет преодолеть это ограничение — Expression Trees. Её можно использовать по прямому назначению, то есть писать C# код, а можно использовать как структуру данных — обходить и дальше трансформировать структуру данных тем способом, которым нам нужно.
Specification
Паттерн „Спецификация“ раньше работал только с объектами и создавал проблемы с производительностью, потому что нам нужно было сначала вытащить весь набор данных, а потом в оперативной памяти его отфильтровать. В C# этот паттерн обретает новую жизнь: если у нас есть правило о том, что для продажи только определённые товары, у которых цена больше нуля, мы можем объявить это правило как Expression.
public Spec<Product> IsForSale { get; } => new Spec<Product>(x => x.Price > 0);
Оно выглядит как C# код, соответственно, оно может быть частью нашей модели домена, но мы его никогда не выполняем как C# код — мы его используем для трансляции к запросу к базе данных.
При этом мы получаем довольно эффективные запросы. Также если ваши объекты, агрегаты или сущности слишком большие, не обязательно их читать целиком, можно, используя C# и проекции, читать только часть этих данных в виде DTO и делать более производительные программы. Причем необязательно даже делать анонимные типы. Если вы используете AutoMapper или Mapster, можно вообще снизить количество императивного кода и заменить его на декларативный.Default Interfaces Implementation
При этом возникают некоторые интересные лазейки, которые именно в классической ООП-парадигме не были бы возможными. Начнём с того, что с 8-ой версией C# у нас появились дефолтные реализации интерфейсов.
public class Product : EntityBase { public decimal Price { get; } public decimal DiscountPercent { get; } public decimal DiscountedPrice() => Price - Price / 100 * DiscountPercent; }
Давайте представим, что у товара есть логика расчёта скидки, которую мы поместили в тот же объект, то есть мы попытались сделать богатую модель. Такому проектированию сопутствуют все проблемы, о которых я говорил до этого: если нам потребуется вытащить большое количество товаров, то память неминуемо закончится. Мы бы хотели это оптимизировать: вместо того, чтобы объявлять метод непосредственно в сущности, мы можем перенести его в интерфейс с дефолтной реализацией.
public interface IHasDiscount { decimal Price { get; set; } decimal DiscountPercent { get; set; } decimal DiscountedPrice() => Price - Price / 100 * DiscountPercent; }
Теперь этот интерфейс можно „прилепить“ как к сущности, так и к DTO. Непосредственно код будет находиться ни в том, ни в другом объекте, а в реализации интерфейса.
public class ProductListItem : IHasDiscount public interface IHasDiscount { decimal Price { get; } decimal DiscountPercent { get; } public decimal DiscountedPrice() => Price - Price / 100 * DiscountPercent; }
Bulk Extensions
Для массовых операций Expressions дают тоже свободу действий. Если не хочется переносить логику в SQL, можно её оставить в Expressions в C# коде. Тогда можно использовать нечто вроде Bulk Extensions, чтобы использовать ту же самую спецификацию на C#: в данном примере — удалить все товары, которых у нас сейчас нет для продажи или поднять на 100 долларов или рублей стоимость товаров, которые мы всё-таки продаём.
А может F#?
Однако как только я начинаю использовать некоторые такие лазейки, я задумываюсь: на том ли языке программирования я сейчас пишу и тот ли инструмент я использую? Потому что дефолтная реализация интерфейсов — это, фактически, функция, которую мы можем „прилеплять“ к любым типам данных, используя интерфейс. Стоит ли переходить на F#, чтобы реализовать модель домена — каждый решает сам, исходя из потребностей проекта. Мы так и не решились переезжать. Тем не менее, поглядывать в сторону каких-то других языков программирования бывает полезно, чтобы позаимствовать оттуда некоторые идеи.
Bounded Context
Независимо от того, какая модель используется — богатая или анемичная, неплохо было бы разделять приложения на приложения поменьше, хотя бы просто потому, что ими проще управлять.
Ложный агрегат
Я говорил о том, что агрегаты имеют свойство разрастаться. Это происходит, когда мы используем документацию Microsoft и следуем ей вслепую. Например, когда мы хотим объявить связанные коллекции, мы обычно связываем их в две стороны. А вот если пользователь может много чего делать в вашей системе, тогда и объект User будет довольно-таки большим. Это антипаттерн „Божественный объект“.
И ладно, если бы он только тратил ресурсы памяти — это мы можем оптимизировать с помощью Expressions. Такой подход ещё и порождает большое количество циклических зависимостей, потому что сейчас у заказов тоже может быть набор пользователей, у комментариев может быть набор товаров, и так далее.
Пока все эти объекты живут у вас в одной сборке, вы получаете такие „круговые“ зависимости: A зависит от B, B зависит от C, C зависит от A. В итоге получается большой и страшный монолит, который мы никак не можем распилить. Всё дело в том, что этот агрегат ложный, в реальном мире его не существует, потому что я объединил в класс пользователя всё, что только можно.
Как же тогда находить корни агрегации и выбирать их правильным способом? Есть два списка вопросов, ответив на которые вы сможете с очень высокой вероятностью понять, тот ли у вас агрегат.
Первый список вопросов (организационный и никак не связан с технологиями)
- Есть ли аналог в реальном мире? (Задайте этот вопрос вашим аналитикам.)
- Когда вы рассказываете о своём дизайне бизнес-пользователям, считают ли они вас местным сумасшедшим?
Если вас не считают сумасшедшим и говорят „да, мы так и работаем“, то вы правильно обнаружили агрегат, проверьте второй список вопросов.
Второй список вопросов (технологический)
- Агрегат не пересекает Bounded Context?
- Есть ли инвариант для этой группы объектов?
- Данные должны изменяться в рамках одной транзакции?
Если ответ на все его вопросы — „да“, значит, агрегат правильный. В нашем случае ответ на всё это — „нет“. Заказы — это отдельная штука, настройки пользователя — другая, отзывы о товарах — третья. Поэтому распилим этот агрегат на три маленьких, уменьшив количество циклических зависимостей. Кроме того, мы можем перенести их по разным сборкам и делегировать работу с этими классами командам.
public class Client : User { public ICollection<Order> Orders => _orders; } public class Account : User { public ICollection<Setting> Settings => _settings; } public class Blogger : User { public ICollection<Comment> Comments => _comments; }
Как делить Domain Model на Bounded Context
Как же делить Domain Model на Bounded Context? Я уже сказал, что в итоге внутри контекста у нас будут сущности и агрегаты. Сущности редко имеют тенденцию расползаться, потому что они маленькие, а пример „божественного“ агрегата я приводил до этого. И если вы видите, что агрегат залез между двумя контекстами, значит, он неправильный. Но это правило работает и в обратную сторону: если вы уверены, что агрегат правильный, и ответ на вопросы выше — „да“, то, похоже, вы неправильно нарезали контекст. Поэтому ответ на вопрос „как же нарезать Domain Model на Bounded Context?“ — по границам агрегатов.
Монолит на микросервисы
Этот вопрос можно переформулировать более модно: как делить монолит на микросервисы? Я не считаю, что разделение программы на подмодули вообще зависит от того, распределённая у вас система или нет. Распределённая система сопровождается некоторыми дополнительными проблемами, связанными с тем, что данные у вас находятся в разных процессах, и вам нужно постоянно что-то сериализовывать и десериализовывать.
Но, тем не менее, ответ такой: мы растащили Domain Model на разные Bounded Context, сказали, что Bounded Context — это отдельный микросервис и получили из страшного монолита много маленьких красивых микросервисов. Причём, обратите внимание, все проблемы, связанные со страшными монолитами, которые не распиливаются, чаще всего связаны с тем, что у вас есть циклические зависимости, которые сложно растащить. Если в самый начальный момент этих зависимостей нет, значит и разделить приложение на несколько процессов будет сильно проще.
Как пересечь границу контекстов
Что же делать, если из одного контекста всё-таки надо обратиться к другому контексту? Несмотря на то что они независимые, такое тоже бывает. Вне зависимости от того, разные ли это у вас сервисы или это разные сборки, работающие в одном процессе — в одну сторону бывает дотянуться проще, потому что если один контекст зависит от другого, то и ссылки на эти объекты есть. В другую же сторону уже не получится, потому что циклические зависимости, которые были в рамках одной сборки неявными, становятся явными. Компилятор уже не позволит нам ссылаться двумя сборками друг на друга.
Классическое решение такой ситуации — использование событий. События могут быть сериализованными и пересекать границы контекстов. Как именно „кидаться“ событиями — отдельная история. Если это микросервис, значит, вам потребуется, скорее всего, шина. Если это одно приложение, то это можно сделать и в памяти. Так или иначе, вы закончите тем, что у вас будет диспетчер, который будет слушать все эти события и направлять их по типу на разные обработчики. Если вам требуется реагировать на какие-то события из одного контекста в другом, то „выкидывайте“ события и обрабатывайте их в том контексте, в котором вам нужно.
Что выбрать?
Что же выбрать? Богатую или анемичную модель? Мы остановились на том, что счёт у нас равный. Так или иначе, я занимаюсь управлением разработкой корпоративных систем 5-6 лет, и мне больше симпатизирует богатая модель. Но всегда, когда мы пытались реализовать богатую модель, мы понимали, что это не просто дорого, а невероятно дорого. Соответственно, прежде чем давать ответ на этот вопрос, я предлагаю начертить такую плоскость: по оси абсцисс будет сложность домена, а по оси ординат — техническая сложность проекта.
- Технически сложные проекты в простых доменах не следует делать в DDD, у них другие сложности: у них проблемы с технологиями.
- Я до сих пор не знаю, как делать технически сложные проекты в сложных доменах, поэтому предлагаю не делать такие проекты — не в смысле, что не делать их вовсе, а в смысле разбивать их на более мелкие.
- Простые проекты в простых доменах делайте как хотите — лишь бы подешевле.
- А вот технически простые проекты на сложных доменах — хорошее применение для DDD. Это, например, специализированное ПО для бухгалтерии, бюджета, для врачей, архитекторов — для кого угодно. Там, где домен сложный, можно получить хороший результаты за счет более ответственной работы с доменом как на этапе сбора требований и их анализа, так и на этапе реализации этих требований, но более формальным образом.
Эволюционный рефакторинг
Тем не менее, если вы в начале проекта не совсем ещё поняли, будет он сложным или нет. Или вы не уверены, что ваш проект будет длиться 3, 6, 12, 24 месяца — по моим наблюдениям, это начинает давать результаты где-то после 3 месяцев — то, опять же, ничто не мешает просто начать с анемичной модели и реализовывать некоторые паттерны, когда они вам начинают требоваться. На первом этапе вполне разумно ограничиться следующим:
- Инкапсуляция
- Спецификация
- Entity и Value Objects
Мы пришли к выводу, что накладных расходов на них почти нет, реализуются они легко, а вот дополнительной информации для программиста дают много. Следующим этапом можно начать использовать:
- Agregate
- Bounded Context
- Pattern Matching
Agregate и Bounded Context идут вместе ровно для того, чтобы правильно поделить их границы. В самую последнюю очередь идут:
- Массовые операции
- События
- IHas-интерфейсы
Если вы дошли до этого этапа, то вы, возможно, захотите сменить язык программирования или просто у вас сложный домен, здесь уже всё не так очевидно. Желательно внедрять эти методики как можно позже, потому что они тяжелые, и к ним нет четких и понятных инструкций, как делать лучше.
Полезные ссылки
Несмотря на то, что мы уже долго разбираем DDD, я рассказал, наверное 10% того, что вообще есть на эту тему. Поэтому я выбрал материалы, которые хорошо дополняют мой рассказ.
По-русски
- Деревья выражений в Enterprise-разработке
- Быстрорастворимое проектирование
- Жизнь после бизнес-объектов
- Domain-driven design: рецепт для прагматика
- Сущности в DDD-стиле с Entity Framework Core
- Шпаргалка по основам DDD
In English
- Tackling Complexity in the Heart of Software
- Domain Modeling Made Functional with the F# Type System
- Don’t delete
- Design Smell: Redundant Required Attribute
- EF Core 2.1 vs NHibernate 5.1: DDD perspective
- Value Object: a better implementation
В этом году я буду MC (Master of Ceremonies) на конфереции DotNext 2020 Piter, которая пройдет с 15 по 18 июня. Благодаря онлайн-формату в этом году можно будет задать вопросы известным спикерам, таким как Scott Hanselmann и Jon Skeet.
Спасибо indienkova за помощь в подготовке материала. Без нее расшифровка могла не выйти или выйти значительно позже.

