Сводная таблица – один из самых базовых видов аналитики. Многие считают, что создать её средствами SQL невозможно. Конечно же, это не так.
Предположим, у нас есть таблица с данными закупок нескольких видов товаров (Product 1, 2, 3, 4) у разных поставщиков (A, B, C):

Типичная задача – определить размер закупок по поставщикам и товарам, т.е. построить сводную таблицу. Пользователи MS Excel привыкли получать такую аналитику буквально парой кликов:

В SQL это не так быстро, но большинство решений тривиальны.
Самый простой и очевидный способ получения сводной таблицы – это хардкод с использованием оператора
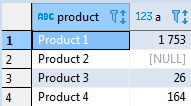
Если добавить
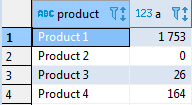
Если продублировать код для всех поставщиков (которых у нас три — A, B, C), мы получим необходимую нам сводную таблицу:
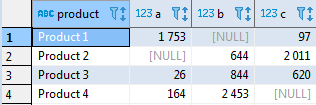
В неё можно добавить итог по строкам (как обычную сумму, т.е.
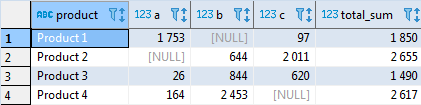
Не составит труда добавить и итог по столбцам. Для этого необходим использовать оператор
Результат можно сделать ещё красивее, заменив NULL на собственную подпись итога. Для этого можно использовать функцию
Можно (но вряд ли стоит) использовать какую-либо из вендоро-специфичных функций вместо стандартного
Особенность
В других СУБД есть ряд эквивалентов CASE, не предусмотренных стандартом: IF в MySQL, DECODE в Oracle, IIF в SQL Server 2012+, и т.д. В большинстве случаев их использование не несёт никаких преимуществ, лишь усложняя поддержку кода в будущем.
Описанный выше подход трудно назвать красивым. Как минимум, хочется не дублировать код для каждого поставщика, а просто их перечислить. Сделать это позволяет разворот (PIVOT) таблицы, доступный в в SQL Server и Oracle. Хотя этот оператор не предусмотрен стандартом SQL, обе СУБД предлагают идентичный синтаксис.
Для начала нам необходима таблица с агрегированной статистикой, которую мы «развернём». Казалось бы, для этого достаточно взять суммы по товару и провайдеру:

И этого будет достаточно – если нам нужны итоги только по товарам и по провайдерам. Если же мы хотим получить все возможные итоги, необходимо выбрать все возможные сочетания товара и провайдера, в том числе такие где товар или провайдер

Этот запрос можно существенно упростить, используя оператор
Если мы хотим получить подпись итогов как 'total_sum' вместо
К такому результату уже можно применять PIVOT:
Здесь мы «поворачиваем» таблицу из прошлого запроса, используя агрегатную функцию суммы
В принципе, для «поворота» таблицы нам не нужен оператор PIVOT как таковой. Этот запрос можно легко переписать, используя стандартный синтаксис — комбинацию CTE (common table expression) и соединений. Для этого будем использовать тот же запрос, что и для PIVOTа:
Из результатов, полученных в
… к которым можно поочередно присоединять объем закупок для каждого отдельно взятого поставщика:
Здесь мы используем левое соединение т.к. у поставщика может не быть поставок по некоторым продуктам.
Окончательный запрос будет выглядеть таким образом:
Конечно, такой запрос — это proof-of-concept, поэтому выглядит он довольно экзотично.
В PostgreSQL доступна функция
В отличие от PIVOT, для «разворота» таблицы нам необходимо указывать не только названия столбцов, но и типы данных. Например, так:
Ещё один нюанс состоит в том, что
… вернёт совсем не то, что мы хотим:
Как можно заметить, там, где были NULL-овые значения, всё «съехало» влево. Например, в первой строке для Product1 итог по строке оказался в столбце для поставщика С, а поставки С — в столбце поставщика В (для которого поставок не было). Корректно проставлены данные только для Product3 т.к. для этого товара у всех поставщиков были значения. Иными словами, если бы у нас не было NULL-овых значений, запрос был бы корректным и вернул нужный результат.
Чтобы не сталкиваться с таким поведением
… а полный запрос будет выглядеть так:
Запрос с PIVOT или CROSSTAB уже функциональнее, чем изначальный с
Здесь чистого SQL недостаточно. Он подразумевает статическую типизацию: для создания плана запроса СУБД нужно заранее указать число столбцов. Поэтому, например, синтаксис PIVOT не позволяет использовать подзапрос. Но это ограничение легко обойти с помощью динамического SQL! Для этого названия столбцов необходимо преобразовать в строку формата
Например, в SQL Server мы можем использовать STUFF для получения такой строки
… а затем включить её в окончательный запрос:
Динамический SQL вполне можно применить и к самому первому решению с
Здесь используется цикл для итерации по доступным поставщикам в таблице
Во многих СУБД доступно аналогичное решение. Тем не менее, мы уже слишком отдалились от чистого SQL. Любое использование динамического SQL подразумевает углубление в специфику конкретной СУБД (и соответствующего ей процедурного расширения SQL).
Итого: как мы выяснили, сводную таблицу можно легко создать средствами SQL. Более того, это можно множеством разных методов — достаточно лишь выбрать оптимальный для вашей СУБД.
Предположим, у нас есть таблица с данными закупок нескольких видов товаров (Product 1, 2, 3, 4) у разных поставщиков (A, B, C):
Типичная задача – определить размер закупок по поставщикам и товарам, т.е. построить сводную таблицу. Пользователи MS Excel привыкли получать такую аналитику буквально парой кликов:
В SQL это не так быстро, но большинство решений тривиальны.
Тестовые данные
-- таблица с полями: поставщик (supplier), товар (product), объем поставки (volume) create table test_supply (supplier varchar null, -- varchar2(10) в Oracle, и т.п. product varchar null, -- varchar2(10) в Oracle, и т.п. volume int null ); -- тестовые данные insert into test_supply (supplier, product, volume) values ('A', 'Product 1', 928); insert into test_supply (supplier, product, volume) values ('A', 'Product 1', 422); insert into test_supply (supplier, product, volume) values ('A', 'Product 4', 164); insert into test_supply (supplier, product, volume) values ('A', 'Product 1', 403); insert into test_supply (supplier, product, volume) values ('A', 'Product 3', 26); insert into test_supply (supplier, product, volume) values ('B', 'Product 4', 594); insert into test_supply (supplier, product, volume) values ('B', 'Product 4', 989); insert into test_supply (supplier, product, volume) values ('B', 'Product 3', 844); insert into test_supply (supplier, product, volume) values ('B', 'Product 4', 870); insert into test_supply (supplier, product, volume) values ('B', 'Product 2', 644); insert into test_supply (supplier, product, volume) values ('C', 'Product 2', 733); insert into test_supply (supplier, product, volume) values ('C', 'Product 2', 502); insert into test_supply (supplier, product, volume) values ('C', 'Product 1', 97); insert into test_supply (supplier, product, volume) values ('C', 'Product 3', 620); insert into test_supply (supplier, product, volume) values ('C', 'Product 2', 776); -- проверка select * from test_supply;
1. Оператор CASE и аналоги
Самый простой и очевидный способ получения сводной таблицы – это хардкод с использованием оператора
CASE. Например, для поставщика А можно вычислить размер поставок как sum(case when t.supplier = 'A' then t.volume end). Чтобы получить объем поставок для разных товаров достаточно просто добавить группировку по полю product:select t.product, sum(case when t.supplier = 'A' then t.volume end) as A from test_supply t group by t.product order by t.product;
Если добавить
else 0, то для товаров, по которым не было поставок, вместо null будут выведены нули:select coalesce(t.product, 'total_sum') as product, sum(case when t.supplier = 'A' then t.volume end) as A from test_supply t group by t.product;
Если продублировать код для всех поставщиков (которых у нас три — A, B, C), мы получим необходимую нам сводную таблицу:
select t.product, sum(case when t.supplier = 'A' then t.volume end) as A, sum(case when t.supplier = 'B' then t.volume end) as B, sum(case when t.supplier = 'C' then t.volume end) as C from test_supply t group by t.product order by t.product;
В неё можно добавить итог по строкам (как обычную сумму, т.е.
sum(t.volume)):select t.product, sum(case when t.supplier = 'A' then t.volume end) as A, sum(case when t.supplier = 'B' then t.volume end) as B, sum(case when t.supplier = 'C' then t.volume end) as C, sum(t.volume) as total_sum from test_supply t group by t.product;
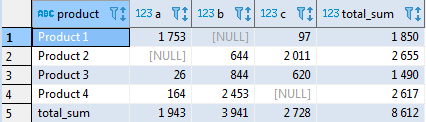
Не составит труда добавить и итог по столбцам. Для этого необходим использовать оператор
ROLLUP, который позволит добавить суммирующую строку. В большинстве СУБД используется синтаксис rollup(t.product), хотя иногда доступен и альтернативный t.product with rollup (например, SQL Server).select t.product, sum(case when t.supplier = 'A' then t.volume end) as A, sum(case when t.supplier = 'B' then t.volume end) as B, sum(case when t.supplier = 'C' then t.volume end) as C, sum(t.volume) as total_sum from test_supply t group by rollup(t.product);
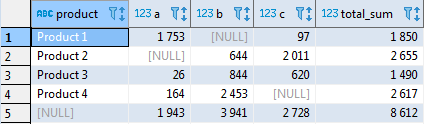
Результат можно сделать ещё красивее, заменив NULL на собственную подпись итога. Для этого можно использовать функцию
coalesce(): coalesce(t.product, 'total_sum'), или же любой специфичный для конкретной СУБД аналог (например, nvl() в Oracle). Результат будет следующим:select coalesce(t.product, 'total_sum') as product, sum(case when t.supplier = 'A' then t.volume end) as A, sum(case when t.supplier = 'B' then t.volume end) as B, sum(case when t.supplier = 'C' then t.volume end) as C, sum(t.volume) as total_sum from test_supply t group by rollup(t.product);
Если СУБД не поддерживает ROLLUP ...
Если ваша СУБД настолько стара, что не поддерживает rollup, – придётся использовать костыли. Например, так:
select t.product, sum(case when t.supplier = 'A' then t.volume end) as A, sum(case when t.supplier = 'B' then t.volume end) as B, sum(case when t.supplier = 'C' then t.volume end) as C, sum(t.volume) as total_sum from test_supply t group by t.product union all select 'total_sum', sum(case when t.supplier = 'A' then t.volume end), sum(case when t.supplier = 'B' then t.volume end), sum(case when t.supplier = 'C' then t.volume end), sum(t.volume) as total_sum from test_supply t;
Можно (но вряд ли стоит) использовать какую-либо из вендоро-специфичных функций вместо стандартного
CASE. Например, в PostgreSQL и SQLite доступен оператор FILTER:select coalesce(t.product, 'total_sum') as product, sum(t.volume) filter (where t.supplier = 'A') as A, sum(t.volume) filter (where t.supplier = 'B') as B, sum(t.volume) filter (where t.supplier = 'C') as C, sum(t.volume) as total_sum from test_supply t group by rollup(t.product);
Особенность
FILTER в том, что он является частью стандарта (SQL:2003), но фактически поддерживается только в PostgreSQL и SQLite. В других СУБД есть ряд эквивалентов CASE, не предусмотренных стандартом: IF в MySQL, DECODE в Oracle, IIF в SQL Server 2012+, и т.д. В большинстве случаев их использование не несёт никаких преимуществ, лишь усложняя поддержку кода в будущем.
MySQL: IF
select coalesce(t.product, 'total_sum') as product, sum(IF(t.supplier = 'A', t.volume, null)) as A, sum(IF(t.supplier = 'B', t.volume, null)) as B, sum(IF(t.supplier = 'C', t.volume, null)) as C, sum(t.volume) as total_sum from test_supply t group by rollup(t.product);
Oracle: DECODE
select coalesce(t.product, 'total_sum') as product, sum(decode(t.supplier, 'A', t.volume, null)) as A, sum(decode(t.supplier, 'B', t.volume, null)) as B, sum(decode(t.supplier, 'C', t.volume, null)) as C, sum(t.volume) as total_sum from test_supply t group by rollup(t.product);
SQL Server 2012 или выше: IIF
select coalesce(t.product, 'total_sum') as product, sum(iif(t.supplier = 'A', t.volume, null)) as A, sum(iif(t.supplier = 'B', t.volume, null)) as B, sum(iif(t.supplier = 'C', t.volume, null)) as C, sum(t.volume) as total_sum from test_supply t group by rollup(t.product);
2. Использование PIVOT (SQL Server и Oracle)
Описанный выше подход трудно назвать красивым. Как минимум, хочется не дублировать код для каждого поставщика, а просто их перечислить. Сделать это позволяет разворот (PIVOT) таблицы, доступный в в SQL Server и Oracle. Хотя этот оператор не предусмотрен стандартом SQL, обе СУБД предлагают идентичный синтаксис.
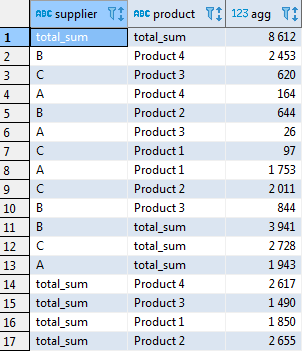
Для начала нам необходима таблица с агрегированной статистикой, которую мы «развернём». Казалось бы, для этого достаточно взять суммы по товару и провайдеру:
select t.supplier, t.product, sum(t.volume) as agg from test_supply t group by t.product, t.supplier;
И этого будет достаточно – если нам нужны итоги только по товарам и по провайдерам. Если же мы хотим получить все возможные итоги, необходимо выбрать все возможные сочетания товара и провайдера, в том числе такие где товар или провайдер
NULL:select t.supplier, t.product, sum(t.volume) as agg from test_supply t group by t.supplier, t.product union all select null, t.product, sum(t.volume) from test_supply t group by t.product union all select t.supplier, null, sum(t.volume) from test_supply t group by t.supplier union all select null, null, sum(t.volume) from test_supply t;
Этот запрос можно существенно упростить, используя оператор
CUBE:select t.supplier, t.product, sum(t.volume) as agg from test_supply t group by cube(t.supplier, t.product);
Если мы хотим получить подпись итогов как 'total_sum' вместо
NULL запрос необходимо немного откорректировать:select coalesce(t.supplier, 'total_sum') as supplier, coalesce(t.product, 'total_sum') as product, sum(t.volume) as agg from test_supply t group by cube(t.supplier, t.product);
К такому результату уже можно применять PIVOT:
select * from ( select coalesce(t.supplier, 'total_sum') as supplier, coalesce(t.product, 'total_sum') as product, sum(t.volume) as agg from test_supply t group by cube(t.supplier, t.product) ) t pivot (sum(agg) -- NB: ниже в SQL Server - двойные кавычки, в Oracle DB - одинарные for supplier in ("A", "B", "C", "total_sum") ) pvt ;
Здесь мы «поворачиваем» таблицу из прошлого запроса, используя агрегатную функцию суммы
sum(agg). При этом заголовки столбцов мы берём из поля supplier, а с помощью in ("A", "B", "C", "total_sum") указываем какие конкретно поставщики должны быть выведены (total_sum отвечает за столбец с итогами по строкам).3. Common table expression
В принципе, для «поворота» таблицы нам не нужен оператор PIVOT как таковой. Этот запрос можно легко переписать, используя стандартный синтаксис — комбинацию CTE (common table expression) и соединений. Для этого будем использовать тот же запрос, что и для PIVOTа:
with cte as ( select coalesce(t.supplier, 'total_sum') as supplier, coalesce(t.product, 'total_sum') as product, sum(t.volume) as agg from test_supply t group by cube(t.supplier, t.product) ) select * from cte;
Из результатов, полученных в
cte нам необходимы только уникальные значения товаров:select distinct t.product from cte t
… к которым можно поочередно присоединять объем закупок для каждого отдельно взятого поставщика:
left join cte a on t.product = a.product and a.supplier = 'A'
Здесь мы используем левое соединение т.к. у поставщика может не быть поставок по некоторым продуктам.
Окончательный запрос будет выглядеть таким образом:
with cte as ( select coalesce(t.supplier, 'total_sum') as supplier, coalesce(t.product, 'total_sum') as product, sum(t.volume) as agg from test_supply t group by cube(t.supplier, t.product) ) select distinct t.product, a.agg as A, b.agg as B, c.agg as C, ts.agg as total_sum from cte t left join cte a on t.product = a.product and a.supplier = 'A' left join cte b on t.product = b.product and b.supplier = 'B' left join cte c on t.product = c.product and c.supplier = 'C' left join cte ts on t.product = ts.product and ts.supplier = 'total_sum' order by product;
Конечно, такой запрос — это proof-of-concept, поэтому выглядит он довольно экзотично.
4. Функция CROSSTAB (PostgreSQL)
В PostgreSQL доступна функция
CROSSTAB, которая примерно эквивалентна PIVOT в SQL Server или Oracle. Для работы с ней необходимо расширение tablefunc:create extension tablefunc; -- для PostgreSQL 9.1+
CROSSTAB принимает в качестве основного аргумента запрос как text sql. Он будет практически тем же, что и для PIVOT, но с обязательным использованием сортировки:select coalesce(t.product, 'total_sum') as product, coalesce(t.supplier, 'total_sum') as supplier, sum(t.volume) as agg from test_supply t group by cube(t.supplier, t.product) order by product, supplier;
В отличие от PIVOT, для «разворота» таблицы нам необходимо указывать не только названия столбцов, но и типы данных. Например, так:
"product" varchar, "A" bigint, "B" bigint, "C" bigint, "total_sum" bigint.Ещё один нюанс состоит в том, что
CROSSTAB заполняет строки слева направо, игнорируя NULL-овые значения. Например, такой запрос:select * from crosstab ( $$select coalesce(t.product, 'total_sum') as product, coalesce(t.supplier, 'total_sum') as supplier, sum(t.volume) as agg from test_supply t group by cube(t.supplier, t.product) order by product, supplier $$ ) as cst("product" varchar, "A" bigint, "B" bigint, "C" bigint, "total_sum" bigint);
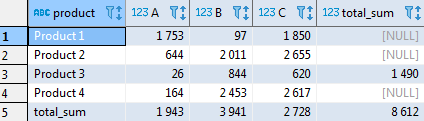
… вернёт совсем не то, что мы хотим:
Как можно заметить, там, где были NULL-овые значения, всё «съехало» влево. Например, в первой строке для Product1 итог по строке оказался в столбце для поставщика С, а поставки С — в столбце поставщика В (для которого поставок не было). Корректно проставлены данные только для Product3 т.к. для этого товара у всех поставщиков были значения. Иными словами, если бы у нас не было NULL-овых значений, запрос был бы корректным и вернул нужный результат.
Чтобы не сталкиваться с таким поведением
CROSSTAB нужно использовать вариант функции с двумя параметрами. Второй параметр должен содержать запрос, выводящий список всех столбцов в результате. В нашем случае это все названия поставщиков из таблицы + «total_sum» для итогов:(select distinct tt.supplier as supplier from test_supply tt order by supplier) union all select 'total_sum'
… а полный запрос будет выглядеть так:
select * from crosstab ( $$select coalesce(t.product, 'total_sum') as product, coalesce(t.supplier, 'total_sum') as supplier, sum(t.volume) as agg from test_supply t group by cube(t.supplier, t.product) order by product, supplier $$, $$ (select distinct tt.supplier as supplier from test_supply tt order by supplier ) union all select 'total_sum' $$ ) as cst("product" varchar, "A" bigint, "B" bigint, "C" bigint, "total_sum" bigint);
5. Динамический SQL (на примере SQL Server)
Запрос с PIVOT или CROSSTAB уже функциональнее, чем изначальный с
CASE (или CTE), но названия поставщиков все ещё необходимо вносить вручную. Но что делать, если поставщиков много? Или если их список регулярно обновляется? Хотелось бы выбирать их автоматически как как select distinct supplier from test_supply (или же из словаря, если он есть).Здесь чистого SQL недостаточно. Он подразумевает статическую типизацию: для создания плана запроса СУБД нужно заранее указать число столбцов. Поэтому, например, синтаксис PIVOT не позволяет использовать подзапрос. Но это ограничение легко обойти с помощью динамического SQL! Для этого названия столбцов необходимо преобразовать в строку формата
"элемент_1", "элемент_2", …, "элемент_n", и использовать их в запросе.Например, в SQL Server мы можем использовать STUFF для получения такой строки
declare @colnames as nvarchar(max); select @colnames = stuff((select distinct ', ' + '"' + t.supplier + '"' from test_supply t for xml path ('') ), 1, 1, '' ) + ', "total_sum"';
… а затем включить её в окончательный запрос:
-- T-SQL (!) declare @colnames as nvarchar(max), @query as nvarchar(max); select @colnames = stuff((select distinct ', ' + '"' + t.supplier + '"' from test_supply t for xml path ('') ), 1, 1, '' ) + ', "total_sum"'; set @query = 'select * from ( select coalesce(t.supplier, ''total_sum'') as supplier, coalesce(t.product, ''total_sum'') as product, sum(t.volume) as agg from test_supply t group by cube(t.supplier, t.product) ) as t pivot (sum(agg) for supplier in (' + @colnames + ') ) as pvt'; execute(@query);
Динамический SQL вполне можно применить и к самому первому решению с
CASE. Например, так:-- T-SQL (!) select distinct supplier into #colnames from test_supply; declare @colname as nvarchar(max), @query as nvarchar(max); set @query = 'select coalesce(t.product, ''total_sum'') as product'; while exists (select * from #colnames) begin select top 1 @colname = supplier from #colnames; delete from #colnames where supplier = @colname; set @query = @query + ', sum(case when t.supplier = ''' + @colname + ''' then t.volume end) as ' + @colname end; set @query = @query + ' , sum(t.volume) as total_sum from test_supply t group by rollup(t.product)' drop table #colnames; execute(@query);
Здесь используется цикл для итерации по доступным поставщикам в таблице
test_supply (можно заменить на словарь, если он есть), после чего формируется соответствующий кусок запроса:sum(case when t.supplier = '<Поставщик 1>' then t.volume end) as <Поставщик 1> , sum(case when t.supplier = '<Поставщик 2>' then t.volume end) as <Поставщик 2> ... , sum(case when t.supplier = '<Поставщик n>' then t.volume end) as <Поставщик n>
Во многих СУБД доступно аналогичное решение. Тем не менее, мы уже слишком отдалились от чистого SQL. Любое использование динамического SQL подразумевает углубление в специфику конкретной СУБД (и соответствующего ей процедурного расширения SQL).
Итого: как мы выяснили, сводную таблицу можно легко создать средствами SQL. Более того, это можно множеством разных методов — достаточно лишь выбрать оптимальный для вашей СУБД.

