Извлечение текста — одна из популярных задач обработки PDF документов. Вам потребуется извлечь текст из PDF, чтобы:
- проиндексировать документ для полнотекстового поиска
- распарсить некоторые данные (например, названия и цены товаров в прайс-листе)
- выделить, удалить или заменить некоторое слово или фразу
Извлечь текст вручную можно так: откройте документ в любом PDF просмотрщике, выделите и скопируйте текст. В большинстве документов это сработает. Такие документы называются "доступные для поиска PDF" или "searchable PDF". Текст в них выводится с помощью специальных PDF операторов, а связанные объекты шрифтов содержат правильную информация о соответствии глифов значениям Unicode.
Многие PDF библиотеки умеют извлекать текст из доступных для поиска PDF.
Однако, часто встречаются и недоступные для поиска PDF ("non-searchable PDF") документы. В них текст обычно выводится как растровое изображение. Типичный пример — сканированный PDF документ. Также текст в недоступных для поиска PDF может выводиться векторными путями без использования шрифтов и специальных PDF операторов.
Для извлечения текста из недоступных для поиска PDF выполняйте оптическое распознавание текста (OCR). Оптическое распознавание не гарантирует правильного извлечения текста в 100% случаев. Результат зависит от качества документа и алгоритма распознавания. Также OCR существенно медленней, чем извлечение текста из доступных для поиска PDF.
Посмотрим, как выполнить оптическое распознавание и извлечь текст из PDF документов в программе для платформы .NET.
Подготовка
У вас есть недоступный для поиска PDF документ с английским текстом. Например, такой, как Partner.pdf. Требуется автоматически распознать и извлечь из этого документа текст без форматирования. Нужна поддержка .NET Standard для того, чтобы программа работала в Windows, Linux и macOS. И распознавание должно работать без подключения к Интернету.
Вам потребуется:
- Проверить, что PDF документ не позволяет извлечь текст обычным способом.
- Преобразовать страницы PDF документа в изображения высокого разрешения.
- Выполнить распознавание текста на изображениях и получить текст без форматирования.
Для выполнения пунктов 1 и 2 вы можете использовать библиотеку Docotic.Pdf или аналогичную PDF библиотеку, поддерживающую .NET Standard. На сайте библиотеки можно получить бесплатный временный ключ, чтобы обрабатывать PDF документы без ограничений.
Для распознавания текста в пункте 3 используйте бесплатный OCR движок Tesseract и его .NET обертку
Создайте новый проект Console App (.NET Core) на C# и установите NuGet пакеты для Docotic.Pdf и Tesseract:
https://www.nuget.org/packages/BitMiracle.Docotic.Pdf/
https://www.nuget.org/packages/Tesseract/4.1.0-beta1 (данная prerelease версия использует нативный Tesseract 4.1.0)
Используйте версию Tesseract не ниже 4.1.0. Предыдущая версия 4.0.0 очень бажная и просто не работает из приложений для .NET Core.
Для Tesseract потребуется дополнительная настройка:
- В Windows установите Microsoft Visual C++ 2015-2019 Redistributable
В Linux установите или скомпилируйте самостоятельно проекты "libleptonica-dev" и "libtesseract-dev". Скомпилированные библиотеки добавьте в ваш проект. Например, под Ubuntu 20.04:
cd ~/YourProject/x64 # Папка "x64" должна располагаться на одном уровне с "tessdata" sudo apt install libleptonica-dev ln -s /usr/lib/x86_64-linux-gnu/liblept.so.5 libleptonica-1.78.0.so sudo apt install libtesseract-dev ln -s /usr/lib/x86_64-linux-gnu/libtesseract.so.4.0.1 libtesseract41.so
Больше информации в обсуждении: https://github.com/charlesw/tesseract/issues/503
В macOS установите Tesseract с помощью brew:
brew install tesseract
Вместе с Tesseract будут установлены Leptonica и прочие зависимости. Больше информации тут.
После этого нужно добавить файлы для некоторых зависимостей в проект:
cd ~/YourProject ln -s /usr/lib/libdl.dylib liblibdl.so mkdir x64 cd x64 ln -s /usr/local/Cellar/leptonica/1.79.0/lib/liblept.5.dylib libleptonica-1.78.0.so ln -s /usr/local/Cellar/tesseract/4.1.1/lib/libtesseract.4.dylib libtesseract41.so
liblibdl.so должна оказаться уровнем выше относительно libleptonica-1.78.0.so и libtesseract41.so. В проекте для каждого из *.so файлов нужно установить свойство "Copy to output directory" в "Always copy".
Обратите внимание, что с Tesseract может быть установлена иная версия зависимостей. Например, в моем случае была установлена Leptonica 1.79.0 вместо требуемой 1.78.0. Это нормально, если установленные версии совместимы с Leptonica 1.78 и Tesseract 4.1.
Реализация
Проверьте, требуется ли OCR
Прежде всего, проверьте, нужно ли вообще выполнять OCR. Если документ доступен для поиска, то достаточно просто извлечь текст.
using System.Text; using BitMiracle.Docotic.Pdf; var documentText = new StringBuilder(); using (var pdf = new PdfDocument("Partner.pdf")) { for (int i = 0; i < pdf.PageCount; ++i) { if (documentText.Length > 0) documentText.Append("\r\n\r\n"); PdfPage page = pdf.Pages[i]; string searchableText = page.GetText(); if (!string.IsNullOrEmpty(searchableText.Trim())) { documentText.Append(searchableText); continue; } // TODO: This page is not searchable. Perform OCR here } } using (var writer = new StreamWriter("result.txt")) writer.Write(documentText.ToString());
Этот код извлекает текст из PDF. Если текст найден, то обычно этого достаточно, и OCR не требуется.
Сохраните страницу PDF как изображение
Дополните код следующим фрагментом:
for (int i = 0; i < pdf.PageCount; ++i) { ... if (!string.IsNullOrEmpty(searchableText.Trim())) { documentText.Append(searchableText); continue; } // This page is not searchable. PdfDrawOptions options = PdfDrawOptions.Create(); options.BackgroundColor = new PdfRgbColor(255, 255, 255); options.HorizontalResolution = 300; options.VerticalResolution = 300; string pageImage = $"page_{i}.png"; page.Save(pageImage, options); // TODO: Perform OCR here }
Добавленный фрагмент преобразует содержимое PDF страницы в PNG изображение с белым фоном. У изображения будет разрешение 300x300 dpi.
Изображение сохраняется в файл, который после распознавания можно удалить. Другой способ — сохранить изображение в поток в памяти:
using (var pageImage = new MemoryStream()) { page.Save(pageImage, options); // TODO: Perform OCR here }
Распознайте текст
Пришло время использовать Tesseract для распознавания текста на созданном изображении. При распознавании Tesseract использует обученные модели для каждого языка. Важно, чтобы версия обученной модели соответствовала версии нативного Tesseract. Для Tesseract 4.1.0 возьмите языковые данные отсюда. Для английского языка достаточно файла eng.traineddata.
Создайте в проекте папку "tessdata". Поместите файл модели для английского языка (eng.traineddata) в папку tessdata. Установите для файла модели свойство "Copy to output directory" в "Сopy always" или "Copy if newer". Для английского языка можете использовать NuGet пакет Tesseract.Data.English, он проделает указанные действия автоматически.
После этого добавьте код для распознавания:
using Tesseract; using (var engine = new TesseractEngine(@"tessdata", "eng", EngineMode.Default)) { for (int i = 0; i < pdf.PageCount; ++i) { .. page.Save(pageImage, options); using (Pix img = Pix.LoadFromFile(pageImage)) { using (Page recognizedPage = engine.Process(img)) { Console.WriteLine($"Mean confidence for page #{i}: {recognizedPage.GetMeanConfidence()}"); string recognizedText = recognizedPage.GetText(); documentText.Append(recognizedText); } } File.Delete(pageImage); } }
using System; using System.IO; using System.Text; using BitMiracle.Docotic.Pdf; using Tesseract; namespace OCR { public static class OcrAndExtractText { public static void Main() { // BitMiracle.Docotic.LicenseManager.AddLicenseData("temporary or permanent license key here"); var documentText = new StringBuilder(); using (var pdf = new PdfDocument("Partner.pdf")) { using (var engine = new TesseractEngine(@"tessdata", "eng", EngineMode.Default)) { for (int i = 0; i < pdf.PageCount; ++i) { if (documentText.Length > 0) documentText.Append("\r\n\r\n"); PdfPage page = pdf.Pages[i]; string searchableText = page.GetText(); // Simple check if the page contains searchable text. // We do not need to perform OCR in that case. if (!string.IsNullOrEmpty(searchableText.Trim())) { documentText.Append(searchableText); continue; } // This page is not searchable. // Save the page as a high-resolution image PdfDrawOptions options = PdfDrawOptions.Create(); options.BackgroundColor = new PdfRgbColor(255, 255, 255); options.HorizontalResolution = 300; options.VerticalResolution = 300; string pageImage = $"page_{i}.png"; page.Save(pageImage, options); // Perform OCR using (Pix img = Pix.LoadFromFile(pageImage)) { using (Page recognizedPage = engine.Process(img)) { Console.WriteLine($"Mean confidence for page #{i}: {recognizedPage.GetMeanConfidence()}"); string recognizedText = recognizedPage.GetText(); documentText.Append(recognizedText); } } File.Delete(pageImage); } } } using (var writer = new StreamWriter("result.txt")) writer.Write(documentText.ToString()); } } }
Класс TesseractEngine при инициализации принимает путь к папке с данными моделей, а также язык документа и режим распознавания. Обычно достаточно одного объекта TesseractEngine для всех страниц. Но, при необходимости, вы можете использовать несколько объектов TesseractEngine (см. пример в разделе Текст на разных языках)
Методы Pix.LoadFromFile или LoadFromMemory загружают изображение страницы в класс Pix. Этот класс является .NET оберткой для объекта изображения в библиотеке Leptonica, которую Tesseract использует под капотом. Один объект класса Pix может использоваться многократно одним или несколькими объектами TesseractEngine.
Строка using (Page recognizedPage = engine.Process(img)) выполняет распознавание текста в изображении. Оценить качество распознавания можно с помощью значения "confidence". Это вещественное число от 0 до 1, означающее степень уверенности нейронной сети Tesseract в точности результата. Метод Page.GetMeanConfidence() возвращает среднее арифметическое для confidence всех слов в распознанном тексте.
Confidence — это исключительно близость распознанных шаблонов к данным в обученной модели (tessdata). В общем случае значения mean confidence, близкие к 1, не гарантируют 100% правильного результата с точки зрения человека. И наоборот — низкие значения mean confidence не означают автоматически неправильный результат. Тем не менее, это полезная метрика, далее вы увидите практические примеры её использования.
Наконец, метод Page.GetText() возвращает распознанный текст. Tesseract также предоставляет возможность получить детальную информацию о каждом распознанном элементе с помощью метода Page.GetIterator(). Этот метод можно использовать, чтобы записать распознанный текст в исходный PDF документ и получить таким образом доступный для поиска PDF. Пример для этого сценария
Запустите текущий пример для документа Partner.pdf. Вы получите
The Microsoft Partner Program Guide for all Microsoft Partners March 2006 This guide describes the Microsoft Partner Program, including: the basic structure of the program, who should join, an overview of program requirements and benefits, as well as enrollment policies and processes. For more detailed information on membership, refer to the following three additional resources: 0 The Getting Started in the Microsoft Partner Program guides are three separate manuals that provide instructions on how to: — Enroll, re-enroll, or upgrade your membership. — Examine profile questions that you answer as part of your program enrollment. — Achieve a Microsoft Competency. o The Partner Program website provides detailed content on Microsoft Partner Program benefits and Microsoft Competencies. o The Partner Membership Center online help provides instructions on how to administer and manage the partner account associated with your program membership. You can access this online help once you log in to the Partner Membership Center. TIP: How to Use This Guide Use the Table of Contents, displayed to the left of this page, to quickly find the topic you desire. Above the Table of Contents, click Options, and then Wrap Long Bookmarks, to view the Table of Contents in its entirety. As the Microsoft Partner Program evolves, this Program Guide will be updated with new and important information. Visit the Partner Program website at https://partner.microsoft.com often to stay up—to—date: 2006 Microsoft Corporation. All rights reserved. 1 Microsoft“ Pa rtner P rog ra m Program I l
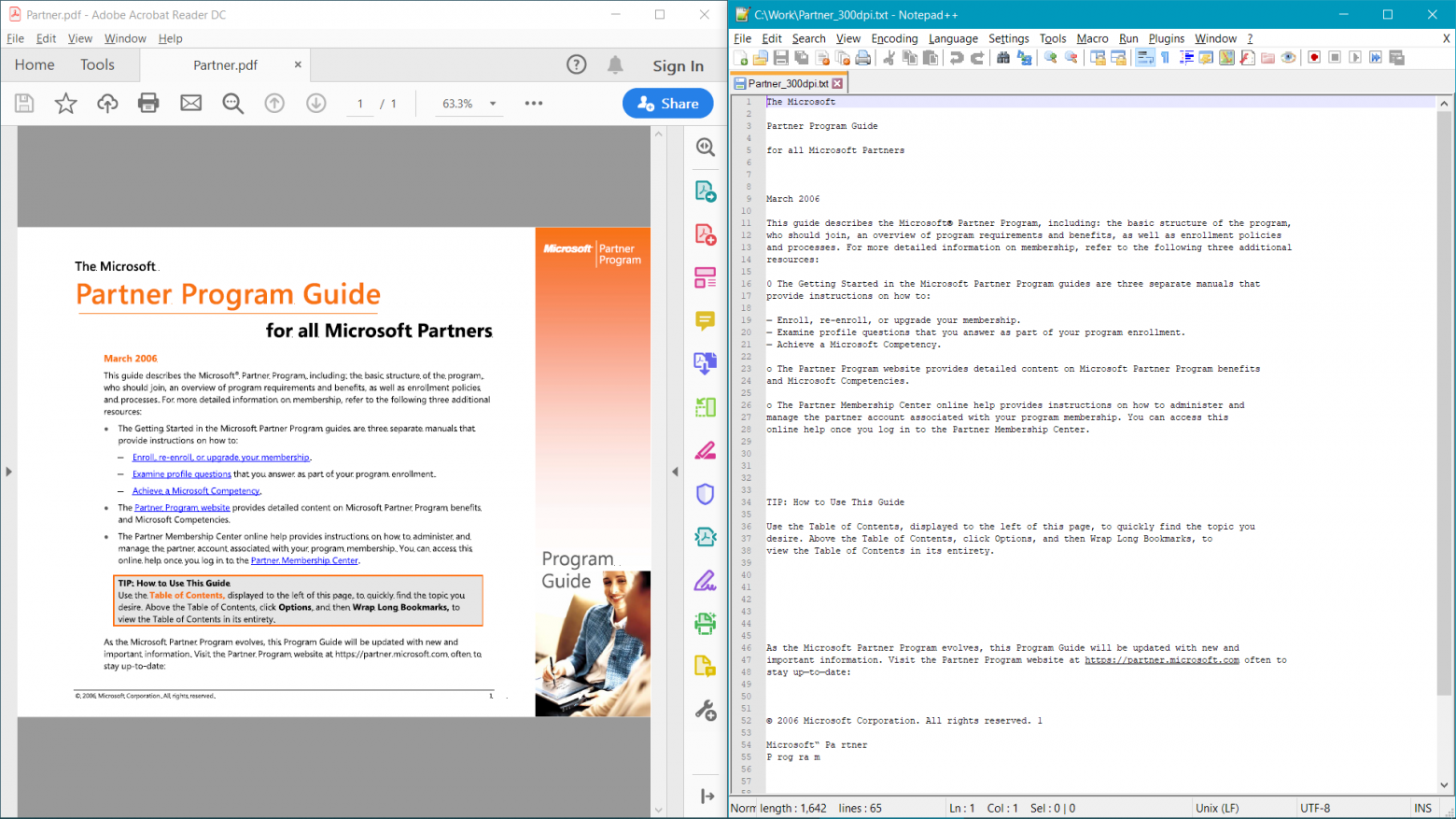
Обратите внимание, что текст в правой части документа распознался не совсем точно:
Microsoft“ Pa rtner P rog ra m Program I l
Как повысить качество распознавания
Есть множество способов попытаться улучшить качество распознавания. Описанные ниже способы могут как улучшить, так и ухудшить качество результата. Универсального метода нет. Ищите оптимальное решение, пробуя разные варианты. Используйте реальные документы во время проб. То, что оптимально для одних документов, может давать плохие результаты для других документов.
Настроить Tesseract
Улучшить результат могут различные конфигурационные параметры Tesseract.
Прежде всего, попробуйте режим EngineMode.LstmOnly. В этом режиме Tesseract использует наиболее актуальную реализацию распознавания на основе LSTM-сетей:
using (var engine = new TesseractEngine(@"tessdata", "eng", EngineMode.LstmOnly))
В режиме LstmOnly наш пример распознает
The Microsoft Partner Program Guide for all Microsoft Partners March 2006 This guide describes the Microsoft Partner Program, including: the basic structure of the program, who should join, an overview of program requirements and benefits, as well as enrollment policies and processes. For more detailed information on membership, refer to the following three additional resources: e The Getting Started in the Microsoft Partner Program guides are three separate manuals that provide instructions on how to: — Enroll, re-enroll, or upgrade your membership. — Examine profile questions that you answer as part of your program enrollment. — Achieve a Microsoft Competency. e The Partner Program website provides detailed content on Microsoft Partner Program benefits and Microsoft Competencies. e The Partner Membership Center online help provides instructions on how to administer and manage the partner account associated with your program membership. You can access this online help once you log in to the Partner Membership Center. TIP: How to Use This Guide Use the Table of Contents, displayed to the left of this page, to quickly find the topic you desire. Above the Table of Contents, click Options, and then Wrap Long Bookmarks, to view the Table of Contents in its entirety. As the Microsoft Partner Program evolves, this Program Guide will be updated with new and important information. Visit the Partner Program website at https://partner. microsoft.com often to stay up-to-date: 2006 Microsoft Corporation. All rights reserved. 1 Microsoft | Partner Program Program I |
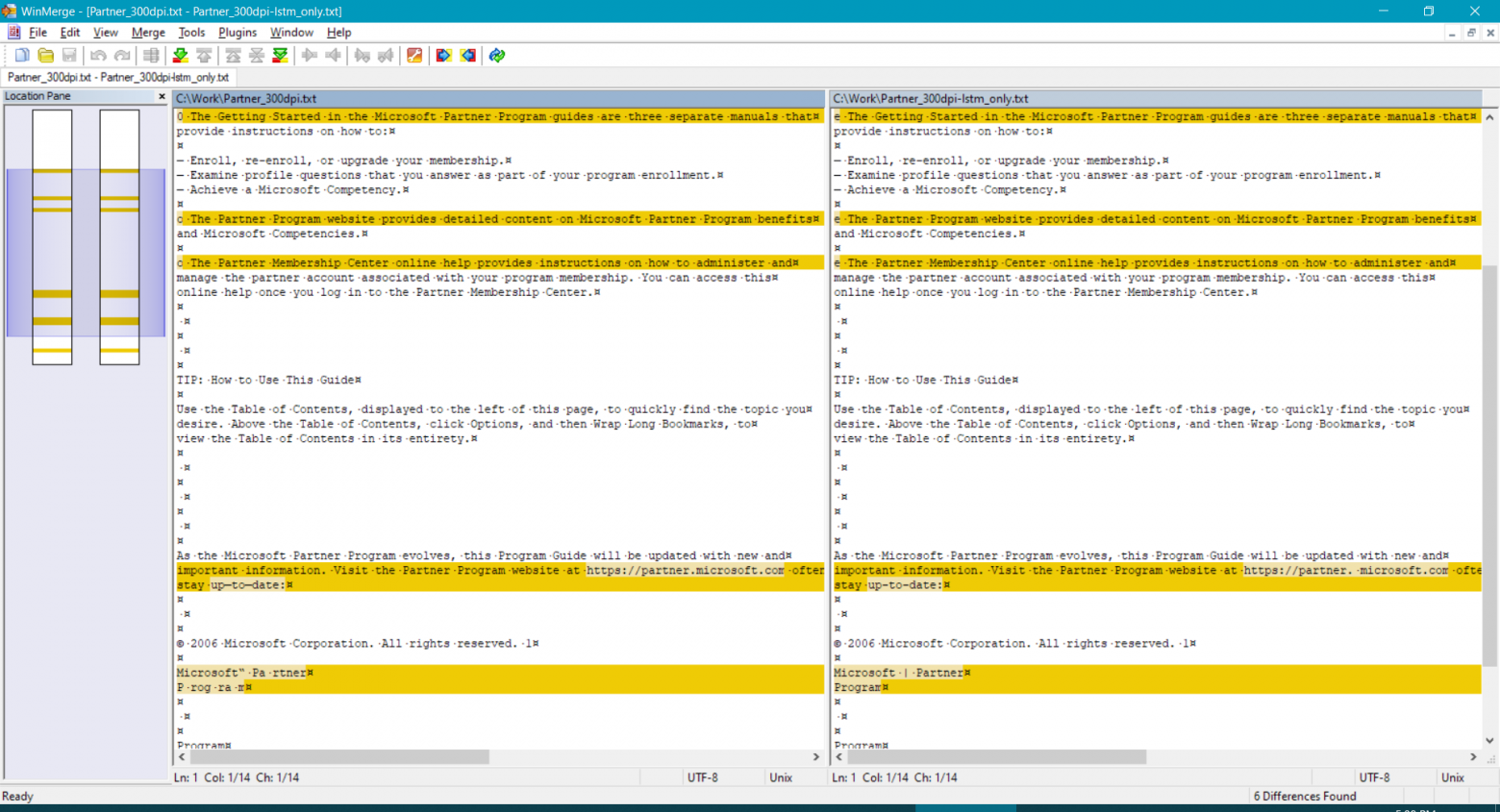
| Было | Стало | Качество улучшилось? |
|---|---|---|
| Символы списка распознаются как "0" и "o" | Сейчас распознаются как "e" | И да, и нет — текст теперь одинаковый во всех случаях, но "o" было бы правильней |
https://partner.microsoft.com |
https://partner. microsoft.com |
Нет |
| up—to—date (тире) | up-to-date (дефисы) | Да |
| Microsoft“ Pa rtner | Microsoft | Partner | Да |
Распознавание URL'a ухудшилось, а остальные изменения в лучшую сторону. В большинстве случаев режим LstmOnly дает лучшие результаты.
Обратите внимание — при этом confidence изменилась с 0.91 до 0.93. Т.е. по мнению Tesseract точность распознавания выросла на 2%. На мой взгляд, в данном случае разница в результатах распознавания не столь однозначна и существенна.
Еще один пример на тему относительности значений mean confidence. Рассмотрим простой документ Hello.pdf. В режимах Default, TesseractAndLstm и LstmOnly текст распознается одинаково и 100% правильно:
HELLO, PDF! lorem ipsum dolor sit amet
Однако, значение mean confidence равно 0.9 для режимов Default/TesseractAndLstm и 0.95 для LstmOnly.
Если известно расположение контента на странице, то можно попробовать опцию Page Segmentation Mode. Например:
using (Page recognizedPage = engine.Process(img, PageSegMode.SingleBlock))
Tesseract предоставляет множество параметров для управления процессом распознавания. Основные указаны тут: https://tesseract-ocr.github.io/tessdoc/ControlParams.html. Больше опций ищите в исходном коде. Например:
- https://github.com/tesseract-ocr/tesseract/blob/4.1/src/ccmain/tesseractclass.h#L782
- https://github.com/tesseract-ocr/tesseract/blob/4.1/src/textord/makerow.h#L42
Передайте параметр "configFiles" в конструктор TesseractEngine, чтобы изменить "Init only" параметры. Значения остальных параметров изменяйте с помощью метода TesseractEngine.SetVariable так:
engine.SetVariable("textord_min_linesize", 2.5); engine.SetVariable("lstm_choice_mode", 2);
Изменить разрешение изображения
При конвертации страницы PDF документа в изображение использовалось разрешение 300dpi. Попробуйте более высокое разрешение. Например, 600dpi.
Для документа Partner.pdf в режиме LstmOnly при разрешении 600dpi получается
Microsoft | Partner Program The Microsoft Partner Program Guide for all Microsoft Partners March 2006 This guide describes the Microsoft Partner Program, including: the basic structure of the program, who should join, an overview of program requirements and benefits, as well as enrollment policies and processes. For more detailed information on membership, refer to the following three additional resources: oe The Getting Started in the Microsoft Partner Program guides are three separate manuals that provide instructions on how to: — Enroll, re-enroll, or upgrade your membership. — Examine profile questions that you answer as part of your program enrollment. — Achieve a Microsoft Competency. eo The Partner Program website provides detailed content on Microsoft Partner Program benefits and Microsoft Competencies. e The Partner Membership Center online help provides instructions on how to administer and manage the partner account associated with your program membership. You can access this online help once you log in to the Partner Membership Center. P og Fam I TIP: How to Use This Guide Use the Table of Contents, displayed to the left of this page, to quickly find the topic you desire. Above the Table of Contents, click Options, and then Wrap Long Bookmarks, to view the Table of Contents in its entirety. As the Microsoft Partner Program evolves, this Program Guide will be updated with new and important information. Visit the Partner Program website at https.//partner.microsoft.com often to stay up-to-date: 2006 Microsoft Corporation. All rights reserved. 1
Результат распознавания ухудшился — появились избыточные пустые строки, символы списка стали распознаваться как "eo" и "oe", вместо "https:" ошибочно распозналось "https.".
Более того, результат ухудшится еще больше, если использовать разрешение 900dpi.
Microsoft | Partner
Program
The Microsoft
Partner Program Guide
for all Microsoft Partners
March 2006
This guide describes the Microsoft Partner Program, including: the basic structure of the program,
who should join, an overview of program requirements and benefits, as well as enrollment policies
and processes. For more detailed information on membership, refer to the following three additional
resources:
eo The Getting Started in the Microsoft Partner Program guides are three separate manuals that
provide instructions on how to:
— Enroll, re-enroll, or upgrade your membership.
— Examine profile questions that you answer as part of your program enrollment.
— Achieve a Microsoft Competency.
eo The Partner Program website provides detailed content on Microsoft Partner Program benefits
and Microsoft Competencies.
eo The Partner Membership Center online help provides instructions on how to administer and
manage the partner account associated with your program membership. You can access this
online help once you log in to the Partner Membership Center. P 0g I'd 8
Guide
TIP: How to Use This Guide
Use the Table of Contents, displayed to the left of this page, to quickly find the topic you
desire. Above the Table of Contents, click Options, and then Wrap Long Bookmarks, to
view the Table of Contents in its entirety.
J
hb
{a
Ty
N = i
§ L rr re
% Hl Wa
1 r wa i La Fs x
d Ro Ee TUE )
. E er Te,
i i; + rl
f LS '
Fl — J
. o a.
|
3
wil
= i
re at
A
i. hg L al
As the Microsoft Partner Program evolves, this Program Guide will be updated with new and
important information. Visit the Partner Program website at https://partner.microsoft.com often to
stay up-to-date:
2006 Microsoft Corporation. All rights reserved. 1
Изображение с разрешением 900dpi содержит больше точек, и Tesseract начинает ошибочно распознавать изображение справа внизу как текст.
Так что большее разрешение не гарантирует лучший результат.
Однако, можно попробовать уменьшить разрешение. Вот тут есть мини-исследование на эту тему: https://groups.google.com/forum/#!msg/tesseract-ocr/Wdh_JJwnw94/24JHDYQbBQAJ
При использовании разрешения 200dpi для тестового документа получается
Microsoft | Partner Program The Microsoft Partner Program Guide for all Microsoft Partners March 2006 This guide describes the Microsoft Partner Program, including: the basic structure of the program, who should join, an overview of program requirements and benefits, as well as enrollment policies and processes. For more detailed information on membership, refer to the following three additional resources: e The Getting Started in the Microsoft Partner Program guides are three separate manuals that provide instructions on how to: — Enroll, re-enroll, or upgrade your membership. — Examine profile questions that you answer as part of your program enrollment. — Achieve a Microsoft Competency. e The Partner Program website provides detailed content on Microsoft Partner Program benefits and Microsoft Competencies. e The Partner Membership Center online help provides instructions on how to administer and manage the partner account associated with your program membership. You can access this online help once you log in to the Partner Membership Center. P rog ram TIP: How to Use This Guide Use the Table of Contents, displayed to the left of this page, to quickly find the topic you desire. Above the Table of Contents, click Options, and then Wrap Long Bookmarks, to view the Table of Contents in its entirety. As the Microsoft Partner Program evolves, this Program Guide will be updated with new and important information. Visit the Partner Program website at https://partner.microsoft.com often to stay up-to-date: 2006 Microsoft Corporation. All rights reserved. 1
С меньшим разрешением также появились избыточные пустые строки, но зато исправилось распознавание URL'a https://partner.microsoft.com.
Модифицировать содержимое PDF
До сих пор не удалось заставить Tesseract правильно распознать слово "Guide" в правой части. Неудачный эксперимент с разрешением 900dpi наталкивает на мысль, что, вероятно, мешает изображение справа снизу. Попробуем перед распознаванием заменить это изображение на 1-пиксельное прозрачное изображение:
using (var engine = new TesseractEngine(@"tessdata", "eng", EngineMode.LstmOnly)) { ... foreach (PdfImage image in page.GetImages()) { // simple hack to replace the right-bottom image only if (image.Height == 512) image.ReplaceWith("1px.png"); } // Save PDF page as high-resolution image PdfDrawOptions options = PdfDrawOptions.Create(); options.BackgroundColor = new PdfRgbColor(255, 255, 255); options.HorizontalResolution = 200; options.VerticalResolution = 200; ...
И после этого изменения, наконец, фраза "Program Guide" в правой части корректно распознается.
The Microsoft Partner Program Guide for all Microsoft Partners March 2006 This guide describes the Microsoft Partner Program, including: the basic structure of the program, who should join, an overview of program requirements and benefits, as well as enrollment policies and processes. For more detailed information on membership, refer to the following three additional resources: e The Getting Started in the Microsoft Partner Program guides are three separate manuals that provide instructions on how to: — Enroll, re-enroll, or upgrade your membership. — Examine profile questions that you answer as part of your program enrollment. — Achieve a Microsoft Competency. e The Partner Program website provides detailed content on Microsoft Partner Program benefits and Microsoft Competencies. e The Partner Membership Center online help provides instructions on how to administer and manage the partner account associated with your program membership. You can access this online help once you log in to the Partner Membership Center. TIP: How to Use This Guide Use the Table of Contents, displayed to the left of this page, to quickly find the topic you desire. Above the Table of Contents, click Options, and then Wrap Long Bookmarks, to view the Table of Contents in its entirety. As the Microsoft Partner Program evolves, this Program Guide will be updated with new and important information. Visit the Partner Program website at https://partner.microsoft.com often to stay up-to-date: 2006 Microsoft Corporation. All rights reserved. 1 Microsoft | Partner Program Program Guide
Естественно, данный метод неприменим в общем случае и для произвольного документа. Например, для сканированных документов с одним изображением на странице. Даже в тестовом документе Partner.pdf нельзя просто удалить все изображения — градиент справа-вверху также является изображением. После его удаления получится белый текст "Microsoft | Partner Program" на белом фоне, который Tesseract не увидит.
В зависимости от содержимого страницы можно использовать и другие подготовительные действия. Например, изменить ориентацию неправильно повернутой страницы (пример документа):
page.Rotation = PdfRotation.None; page.Save(pageImage, options);
Или отсечь часть ненужного содержимого перед созданием изображения:
page.CropBox = new PdfBox(0, 0, 600, 500); page.Save(pageImage, options);
Подготовить изображение
Вы можете модифицировать изображение, чтобы упростить распознавание OCR движку. Подробнее описано тут: https://tesseract-ocr.github.io/tessdoc/ImproveQuality#image-processing
Использовать другую модель
В примере используется дефолтная модель tessdata. Tesseract 4 предоставляет еще две модели.
Используйте модель tessdata_fast, чтобы ускорить распознавание, пожертвовав качеством результата. Или используйте модель tessdata_best, чтобы улучшить качество при более долгом процессе распознавания.
Попробуйте использовать модель tessdata_best. Для этого используйте в проекте файл eng.traineddata из tessdata_best. Для тестового документа Partner.pdf использование tessdata_best не влияет на результат и особого смысла не имеет.
Существующие модели Tesseract могут не дать нужных результатов, если в документе используется какой-то причудливый шрифт или незнакомый язык. В этом случае можете натренировать модель самостоятельно. Информация на эту тему: https://github.com/tesseract-ocr/tessdoc/blob/master/Training-Tesseract.md
Обновить версию Tesseract
На момент публикации статьи ведется разработка Tesseract 5, а также доступен релиз 4.1.1. Обновление до последней версии может улучшить результат. Следите за релизами тут: https://github.com/tesseract-ocr/tesseract/releases
Задать вопрос сообществу
Обсуждение Tesseract ведется в https://groups.google.com/forum/#!forum/tesseract-ocr. Там могут посоветовать хорошие идеи, как улучшить результаты распознавания. Там же есть предыдущие обсуждения способов улучшения OCR в различных ситуациях.
Особые случаи
Описанный подход хорошо работает для большинства документов. Рассмотрим ситуации, когда требуются дополнительные действия.
Текст на разных языках
Документ может содержать страницы на разных языках. И в общем случае неизвестно, какие языки используется на конкретной странице.
Tesseract позволяет использовать несколько языков при распознавании. Для этого:
- В папку tessdata добавьте файлы моделей для каждого из используемых языков.
- И укажите языки при инициализации TesseractEngine, например, так:
using (var engine = new TesseractEngine(@"tessdata", "eng+rus", EngineMode.LstmOnly))
Естественно, желательно примерно представлять, какие языки могут встречаться в документе. Чем больше языков используется — тем дольше работает распознавание.
Иногда Tesseract некорректно обрабатывает случаи, когда текст на разных языках встречается рядом в одной строке. В таких случаях попробуйте ранее перечисленные способы по улучшению качества распознавания. Если не поможет, то попробуйте обходной путь — распознавайте отдельные слова на разных языках и в каждом случае выбирайте результат с большим значением confidence. Пример кода:
using (var eng = new TesseractEngine(@"tessdata", "eng", EngineMode.LstmOnly)) using (var rus = new TesseractEngine(@"tessdata", "rus", EngineMode.LstmOnly)) { .. using (Pix img = Pix.LoadFromFile(pageImage)) { using (Page rusPage = rus.Process(img)) using (Page engPage = eng.Process(img)) { using (ResultIterator rusIter = rusPage.GetIterator()) using (ResultIterator engIter = engPage.GetIterator()) { const PageIteratorLevel Level = PageIteratorLevel.Word; rusIter.Begin(); engIter.Begin(); do { ResultIterator bestIter = rusIter.GetConfidence(Level) > engIter.GetConfidence(Level) ? rusIter : engIter; string text = bestIter.GetText(Level); documentText.AppendLine(text); } while (rusIter.Next(Level) && engIter.Next(Level)); } } } } ..
Страница содержит неправильный текст
Встречаются доступные для поиска PDF документы, из которых текст извлекается, но неправильно. Это происходит, когда документ не содержит информацию о соответствии глифов значениям Unicode. Или содержит неправильную информацию. Например, для глифа 'A' указано соответствие U+0007, а для глифа 'B' указано U+00B6 и т.д.
Первая задача — определить, что текст извлекается неверно. Можете сделать это, проверив извлеченный текст на соответствие языку документа:
- Проверить наличие популярных слов (для английского — "the", "be", "to")
- Проверить наличие и количество символов из алфавита нужного языка
- Использовать сторонние библиотеки для определения языка текста
Определили, что текст или большая его часть не соответствует языку — делайте OCR. Убедитесь, что распознанный текст лучше исходного. Для этого проверьте распознанный текст на соответствие нужному языку и сравните результаты с первой проверкой.
Заключение
Для распознавания текста в недоступных для поиска PDF документах используйте библиотеки Docotic.Pdf и Tesseract.
Примеры на GitHub:

