Подготовка данных для настройки и обучения нейросети по детекции объектов.
Продолжаем тему детекции объектов. Для того, чтобы алгоритм различал объекты или был способен выявлять отклонения в процессе, его необходимо обучить на наборе данных, который соответствует общей картине анализируемых видеоматериалов. Подготовка обучающего набора является очень трудоемким процессом, от которого зависит как скорость обучения, так и качество работы алгоритма. Рассмотрим применение нескольких инструментов, которые помогут правильно подготовить данные.
Первый этап подготовки заключается в составлении первоначального набора данных. Как правило, чем больше объем данных и выше разнообразие анализируемого объекта, тем выше качество алгоритма. Если предполагается анализ видео с видеорегистраторов, то составление набора данных предпочтительней делать скрин-снимками с имеющихся видеоматериалов, т.к. в данном случае потребуется меньше данных и меньше времени на переобучение. В других случаях, набор данных составляется с учетом угла обзора, с которого запечатлен объект, его размера и т.д., насколько объекты с обучающего набора похожи на объекты с материалов, которые будут анализироваться алгоритмом. Набор данных необходимо составлять из различных вариаций, т.е. на которых будет отображен как один объект, так и несколько, например, человек и телефон в одном кадре.
Если составление набора данных осуществлялось при помощи фотоаппарата или телефона, вероятнее всего изображения будут иметь высокое разрешение, что негативно влияет на процесс обучения. Основной проблемой при высоком разрешении изображений будет ошибка «Out of memory», даже при малом значении параметра batch_size. Чтобы уменьшить вероятность возникновения данной ошибки необходимо уменьшить размер изображений. В этом нам поможет программа IrfanView. Данная программа позволяет пакетно обрабатывать изображения, т.е. нужно лишь указать путь к исходными изображениям, задать параметры преобразования и запустить процесс преобразования. В результате получим «облегченные» изображения в указанной папке. Для этого в стартовом окне программы нажмите клавишу B (русская раскладка «И») или во вкладке File выберите пункт «Batch Conversion/Rename», появится окно следующего вида:
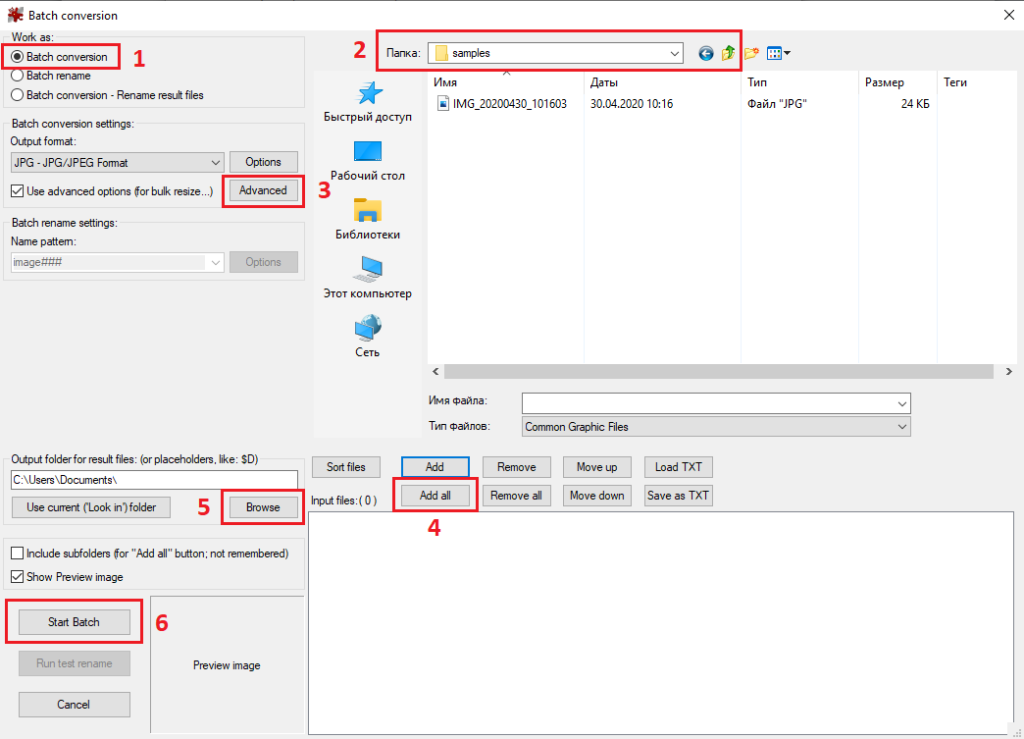
Далее нам необходимо:
В расширенных параметрах доступно множество различных преобразований, в данном примере мы лишь изменим размер исходного изображения, уменьшим размер в 10 раз (укажем 10% от исходного значения):
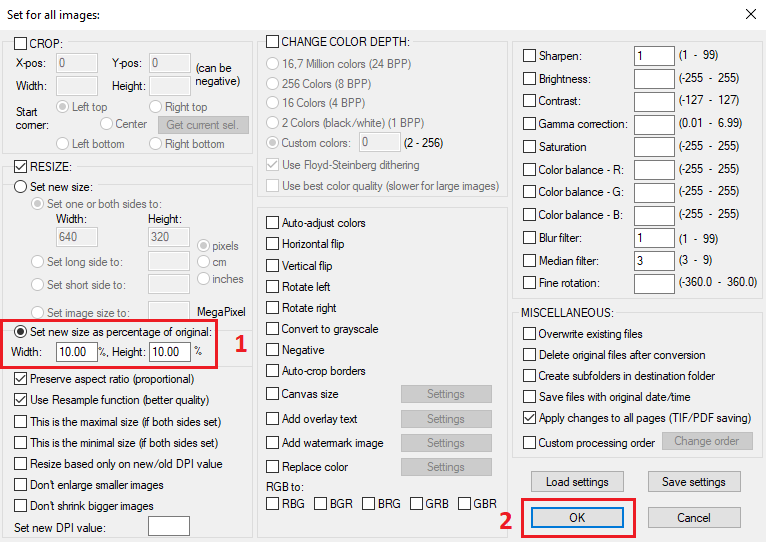
Таким образом, если исходное изображение было 4160 х 3120, то результирующее изображение станет 416 х 312 пикселей.
Формирование обучающей выборки достаточно утомительный процесс, будь то формирование скрин-снимков из видеоматериалов или съемка на фотоаппарат и телефон. Чтобы в разы увеличить объем набора данных применяют различные методы аугментации. Разберем несколько таких методов, реализованных в языке программирования Python с помощью библиотеки Pillow. Одним из самых популярных методов аугментации является «зеркальное отражение».
Для начала импортируем необходимые библиотеки:
Укажем путь расположения директории с исходными изображениями и путь для результата преобразования:
Напишем функцию для преобразования изображения в «зеркальное отражение»:
Еще одним популярным методом аугментации является поворот изображения. Стоит учитывать при полноразмерных объектах, что при данном методе аугментации теряется часть изображения. Напишем функцию для поворота изображения:
Значение (-30) – это угол поворота изображения, который подбирается исходя из типа объекта. Например, поворот на 180 градусов, если на изображении телефон, то это неплохой вариант аугментации, но если на изображении человек, то 180 градусов для данного изображения плохой пример, т.к. навряд ли вы встретите видео, на котором люди ходят вверх ногами.
И, наконец, проведем 2 типа аугментации для каждого изображения:
Пример аугментации «зеркальное отражение»:

Пример аугментации «поворот изображения»:

Существует множество различных методов аугментации (добавление шума, изменение контрастности и т.д.), все зависит от типа обрабатываемых данных. Таким образом, применив два метода аугментации, мы увеличили размер обучающих данных в три раза. Формирование обучающего набора завершено, осталось провести разметку объектов на изображениях.
Для разметки будем использовать программу LabelImage, так как на мой взгляд она достаточно проста в использовании и многофункциональна. Данная программа способна возвращать результат разметки в двух форматах (PascalVOC и YOLO). Первый формат представлен в виде XML – файла, в котором обозначены параметры изображения, а также координаты прямоугольников, которые описывают местоположение объектов на изображении:
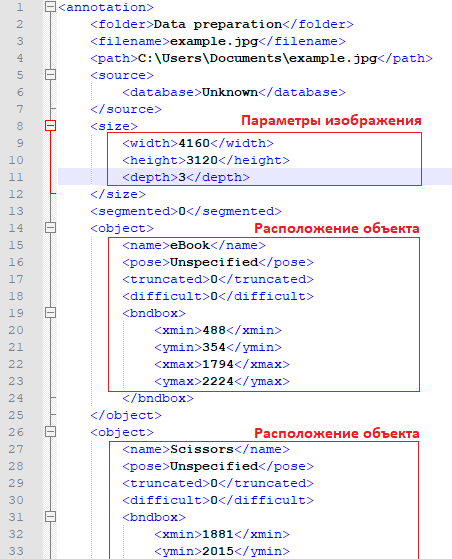
Такой XML – файл формируется для каждого изображения, в котором описаны все размеченные объекты. Имя файла разметки совпадает с именем изображения. Формат YOLO представлен в виде текстового файла, в котором обозначен класс объекта и координаты прямоугольников, описанные значениями x,y,w,h в нормализованном виде:
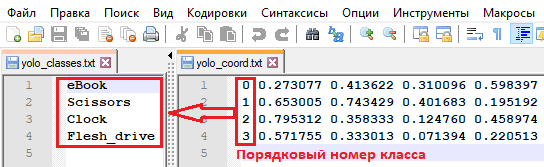
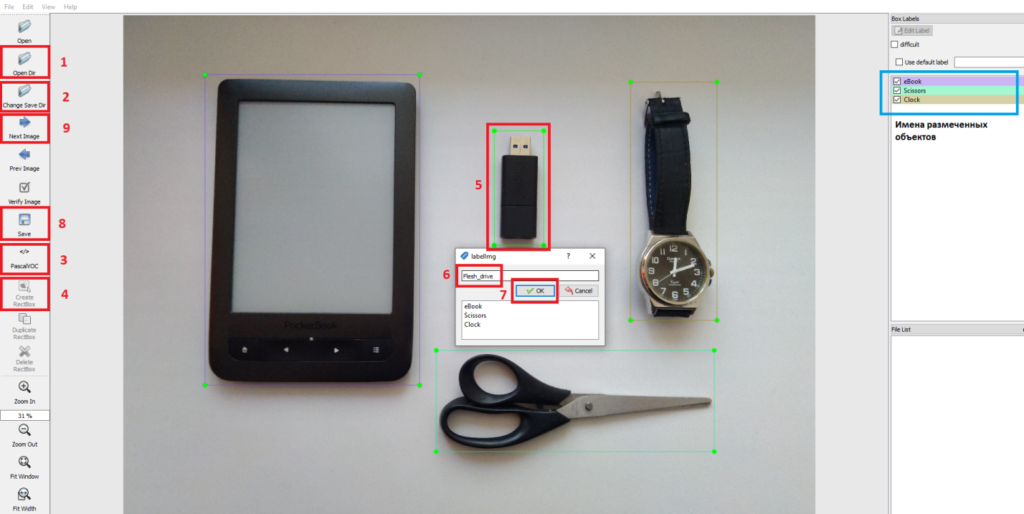
Помимо текстового файла с разметкой для формата YOLO, также формируется файл classes.txt, в котором указаны имена объектов. Порядковые номера имен объектов зависят от порядка появления при разметке изображений. Стоит отметить, что файл classes.txt может быть перезаписан при повторном открытии приложения, поэтому необходимо следить за последовательностью внесения имен в программе, в противном случае произойдет несогласованность координат. Разметка объектов происходит в следующей последовательности:
По завершении, количество файлов разметки должно соответствовать количеству изображений, с идентичными именами. Таким образом, мы рассмотрели инструменты и методы, которые позволяют изменить размер изображения, увеличить объем данных, а также разметить объекты на изображениях, которые будут детектироваться нейронной сетью. Формирование и подготовка данных – важный и трудоемкий этап, от которого зависит успех в создании алгоритма глубокого обучения.
Продолжаем тему детекции объектов. Для того, чтобы алгоритм различал объекты или был способен выявлять отклонения в процессе, его необходимо обучить на наборе данных, который соответствует общей картине анализируемых видеоматериалов. Подготовка обучающего набора является очень трудоемким процессом, от которого зависит как скорость обучения, так и качество работы алгоритма. Рассмотрим применение нескольких инструментов, которые помогут правильно подготовить данные.
Первый этап подготовки заключается в составлении первоначального набора данных. Как правило, чем больше объем данных и выше разнообразие анализируемого объекта, тем выше качество алгоритма. Если предполагается анализ видео с видеорегистраторов, то составление набора данных предпочтительней делать скрин-снимками с имеющихся видеоматериалов, т.к. в данном случае потребуется меньше данных и меньше времени на переобучение. В других случаях, набор данных составляется с учетом угла обзора, с которого запечатлен объект, его размера и т.д., насколько объекты с обучающего набора похожи на объекты с материалов, которые будут анализироваться алгоритмом. Набор данных необходимо составлять из различных вариаций, т.е. на которых будет отображен как один объект, так и несколько, например, человек и телефон в одном кадре.
Если составление набора данных осуществлялось при помощи фотоаппарата или телефона, вероятнее всего изображения будут иметь высокое разрешение, что негативно влияет на процесс обучения. Основной проблемой при высоком разрешении изображений будет ошибка «Out of memory», даже при малом значении параметра batch_size. Чтобы уменьшить вероятность возникновения данной ошибки необходимо уменьшить размер изображений. В этом нам поможет программа IrfanView. Данная программа позволяет пакетно обрабатывать изображения, т.е. нужно лишь указать путь к исходными изображениям, задать параметры преобразования и запустить процесс преобразования. В результате получим «облегченные» изображения в указанной папке. Для этого в стартовом окне программы нажмите клавишу B (русская раскладка «И») или во вкладке File выберите пункт «Batch Conversion/Rename», появится окно следующего вида:
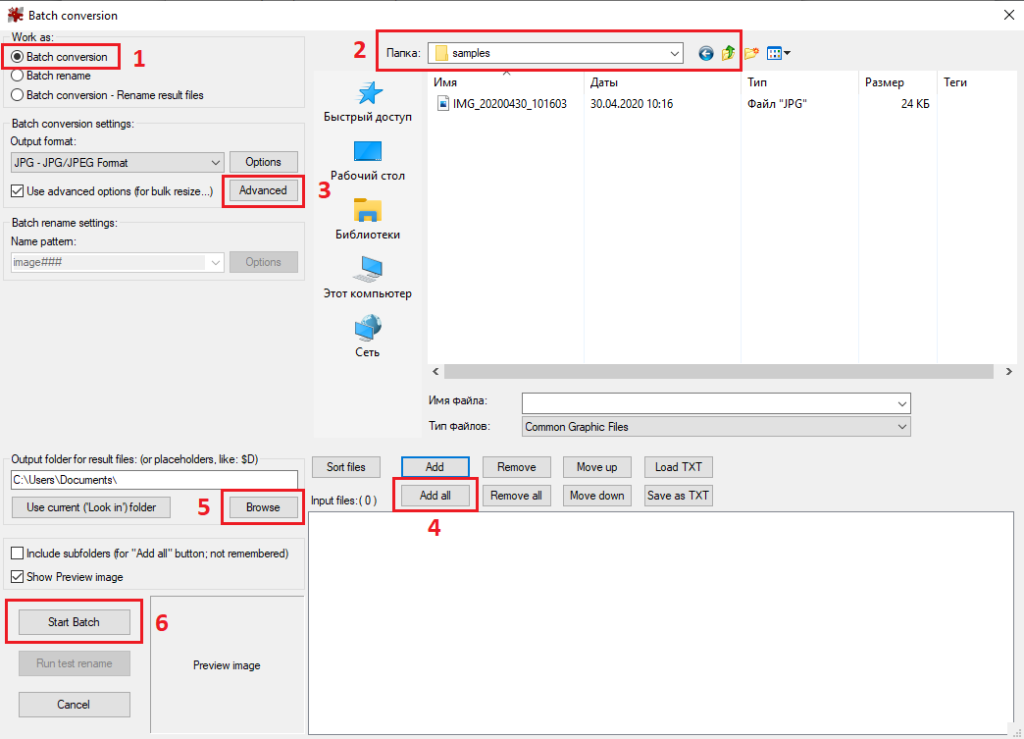
Далее нам необходимо:
- выбрать режим пакетного преобразования «Batch conversion»;
- выбрать папку, в которой находятся исходные изображения;
- настроить расширенные параметры «Advanced»;
- добавить все изображения;
- выбрать папку для результата преобразования;
- запустить пакетное преобразование.
В расширенных параметрах доступно множество различных преобразований, в данном примере мы лишь изменим размер исходного изображения, уменьшим размер в 10 раз (укажем 10% от исходного значения):

Таким образом, если исходное изображение было 4160 х 3120, то результирующее изображение станет 416 х 312 пикселей.
Формирование обучающей выборки достаточно утомительный процесс, будь то формирование скрин-снимков из видеоматериалов или съемка на фотоаппарат и телефон. Чтобы в разы увеличить объем набора данных применяют различные методы аугментации. Разберем несколько таких методов, реализованных в языке программирования Python с помощью библиотеки Pillow. Одним из самых популярных методов аугментации является «зеркальное отражение».
Для начала импортируем необходимые библиотеки:
from PIL import Image, ImageOps
import os
import numpy
Укажем путь расположения директории с исходными изображениями и путь для результата преобразования:
path_to_origin = "images/"
output_folder = "Augmentation_result/"
img_names = os.listdir(path_to_origin)
if not os.path.exists(output_folder):
os.makedirs(output_folder)
Напишем функцию для преобразования изображения в «зеркальное отражение»:
def mirror(path_to_origin, img_name, output_folder):
im = Image.open(path_to_origin + img_name)
ImageOps.mirror(im).save(output_folder+"mirror"+img_name, "JPEG")
Еще одним популярным методом аугментации является поворот изображения. Стоит учитывать при полноразмерных объектах, что при данном методе аугментации теряется часть изображения. Напишем функцию для поворота изображения:
def rotate(path_to_origin, img_name, output_folder):
im = Image.open(path_to_origin + img_name)
im.rotate(-30).save(output_folder+"rotate_"+img_name, "JPEG")
Значение (-30) – это угол поворота изображения, который подбирается исходя из типа объекта. Например, поворот на 180 градусов, если на изображении телефон, то это неплохой вариант аугментации, но если на изображении человек, то 180 градусов для данного изображения плохой пример, т.к. навряд ли вы встретите видео, на котором люди ходят вверх ногами.
И, наконец, проведем 2 типа аугментации для каждого изображения:
for img in img_names:
rotate(path_to_origin, img, output_folder)
mirror(path_to_origin, img, output_folder)
Пример аугментации «зеркальное отражение»:

Пример аугментации «поворот изображения»:

Существует множество различных методов аугментации (добавление шума, изменение контрастности и т.д.), все зависит от типа обрабатываемых данных. Таким образом, применив два метода аугментации, мы увеличили размер обучающих данных в три раза. Формирование обучающего набора завершено, осталось провести разметку объектов на изображениях.
Для разметки будем использовать программу LabelImage, так как на мой взгляд она достаточно проста в использовании и многофункциональна. Данная программа способна возвращать результат разметки в двух форматах (PascalVOC и YOLO). Первый формат представлен в виде XML – файла, в котором обозначены параметры изображения, а также координаты прямоугольников, которые описывают местоположение объектов на изображении:

Такой XML – файл формируется для каждого изображения, в котором описаны все размеченные объекты. Имя файла разметки совпадает с именем изображения. Формат YOLO представлен в виде текстового файла, в котором обозначен класс объекта и координаты прямоугольников, описанные значениями x,y,w,h в нормализованном виде:

Помимо текстового файла с разметкой для формата YOLO, также формируется файл classes.txt, в котором указаны имена объектов. Порядковые номера имен объектов зависят от порядка появления при разметке изображений. Стоит отметить, что файл classes.txt может быть перезаписан при повторном открытии приложения, поэтому необходимо следить за последовательностью внесения имен в программе, в противном случае произойдет несогласованность координат. Разметка объектов происходит в следующей последовательности:

- Выбрать директорию с изображениями;
- Выбрать директорию, в которую будут сохраняться файлы разметки;
- Выбрать формат разметки (PascalVOC или YOLO);
- Выбрать инструмент выделения объекта «клавиша W»;
- Выделить объект на изображении;
- Задать имя объекта (при повторной операции можно выбрать из списка, под кнопкой ОК);
- Подтвердить;
- Сохранить «Ctrl+s» (повторить пункты 4-8 для каждого необходимого объекта);
- Перейти на следующее изображение.
По завершении, количество файлов разметки должно соответствовать количеству изображений, с идентичными именами. Таким образом, мы рассмотрели инструменты и методы, которые позволяют изменить размер изображения, увеличить объем данных, а также разметить объекты на изображениях, которые будут детектироваться нейронной сетью. Формирование и подготовка данных – важный и трудоемкий этап, от которого зависит успех в создании алгоритма глубокого обучения.







