tl;dr: Упрощенный разброр статьи, в которой автор предлагает две интересные теоремы, на базе которых он нашел способ как из матрицы эмбеддингов извлечь скрытые векторы смыслов. Приведен гайд о том, как воспроизвести результаты. Ноутбук доступен на гитхабе.
Введение
В этой статье я хочу рассказать об одной потрясной вещи, которую нашел исследователь Санджев Арора в статье Linear Algebraic Structure of Word Senses, with Applications to Polysemy. Она является одной из серии статей, в которых он пытается дать теоретические обоснования свойства эмбеддингов слов. В этой же работае Арора делает предположение о том, что простые эмбеддинги, такие как word2vec или Glove, на самом деле включают в себя несколько значений для одного слова и предлагает способ как можно их восстановить. По ходу статьи я буду стараться придерживаться оригинальных примеров.
Более формально, за  обозначим некий вектор эмбединга слова tie, которое может иметь значение узла или галстука, а может быть глаголом "завязать". Арора предполагает, что этот вектор можно записать, как следующую линейную комбинацию
обозначим некий вектор эмбединга слова tie, которое может иметь значение узла или галстука, а может быть глаголом "завязать". Арора предполагает, что этот вектор можно записать, как следующую линейную комбинацию

где  это одно из возможных значений слова tie, а
это одно из возможных значений слова tie, а  — коэффициент. Давайте попробуем разобраться, как же так получается.
— коэффициент. Давайте попробуем разобраться, как же так получается.
Теория
Написано нематематиком, просьба сообщать обо всех ошибках, особенно в мат. терминологии.
Небольшая заметка о теории Ароры
Поскольку стартовая работа Ароры куда сложнее, чем эта, я пока не подготовил обзор полностью. Однако, мы вкратце посмотрим, что она из себя представляет.
Итак, Арора предлагает идею, согласно которой любой текст порождается генеративной моделью. В процессе ее работы на каждом временном шаге  генерируется слово
генерируется слово  . Модель состоит из вектора контекста
. Модель состоит из вектора контекста  и векторов эмбеддингов
и векторов эмбеддингов  . В отдельных размерностях(dimensions), или координатах, вектора кодируется информация и атрибуты слов. Например, мы могли бы сказать, что в каком-то абстрактном векторе положительное значение пятой размерности отвечает за мужественность (мужчина, король), а отрицательная — за женственность(женщина, королева), а положительное значение сотой размерности говорит о том, что слово будет глаголом, а отрицательное — существительным.
. В отдельных размерностях(dimensions), или координатах, вектора кодируется информация и атрибуты слов. Например, мы могли бы сказать, что в каком-то абстрактном векторе положительное значение пятой размерности отвечает за мужественность (мужчина, король), а отрицательная — за женственность(женщина, королева), а положительное значение сотой размерности говорит о том, что слово будет глаголом, а отрицательное — существительным.
Вектор контекста совершает медленное равномерно распределенное случайное блуждание, т.е. с течением времени значения его координат изменяются на какой-то вектор, семплированный из равномерного распределения. Таким образом кодируется информация о чем в данный момент идет речь. Условия медленной скорости и равномерности процесса нужны для того, чтобы слова близкие по смыслу имели большую вероятность быть сгенерированными вместе. Другими словами это условие позволяет генерировать взаимосвязный текст: последовательность слов "Девушка расчесывала свою косу" имеют большую вероятность быть сгенерированной, чем "Мужчина расчесывает свою косу". Однако, модель не налагает строгий запрет на "прыжки": в конце концов, некоторые мужчины действительно носят длинные волосы.
В отличие от вектора контекста, векторы эмбедингов статичны. По сути, это такие отображения, которые позволяют сопоставлять слово с конкретным набор информации, которая закодирована в координатах векторов.
Процесс генерации текста очень прост: двигаясь в пространстве векторов вектор контекста становится ближе то к одному слову, то к другому. Вероятность того, что на шаге будет сгенерировано слово определяется выражением

где  — вектор контекста на время ,
— вектор контекста на время ,  — эмбеддинг слова , а
— эмбеддинг слова , а  — это partition function. Она выполняет роль нормализатора, который дает гарантии, что мы получим валидную вероятность.
— это partition function. Она выполняет роль нормализатора, который дает гарантии, что мы получим валидную вероятность.
Теперь на примере картинок попытаемся это понять на максимально простом примере. Допустим, у нас есть двумерное пространство, в котором всего эмбеддинги для четырех слов: королева, король, женщина, мужчина. Мы могли бы закодировать информацию о статусе по оси Y, а по X закодировать пол. Тогда картинка могли бы выглядеть следующим образом
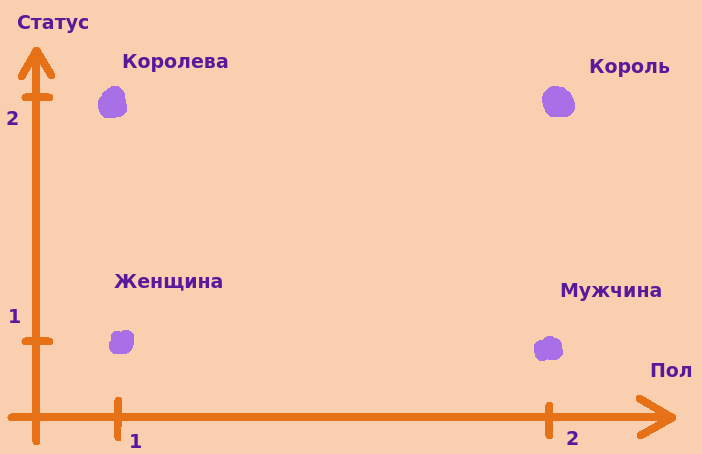
Теперь нам нужен вектор контекста. Это будет просто отдельная точка около какого-то вектора, которая оказалась там на каком-то временном шаге. Вот она
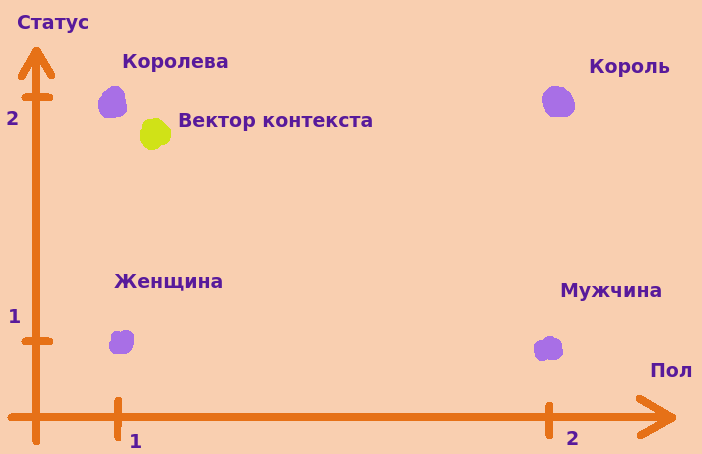
Теперь, давайте представим, что он медленно двигается. Условимся, что это значит, что он не может за отсчет пройти расстояние больше единичного и без "прыжков". Тогда траектория могла бы выглядеть так:
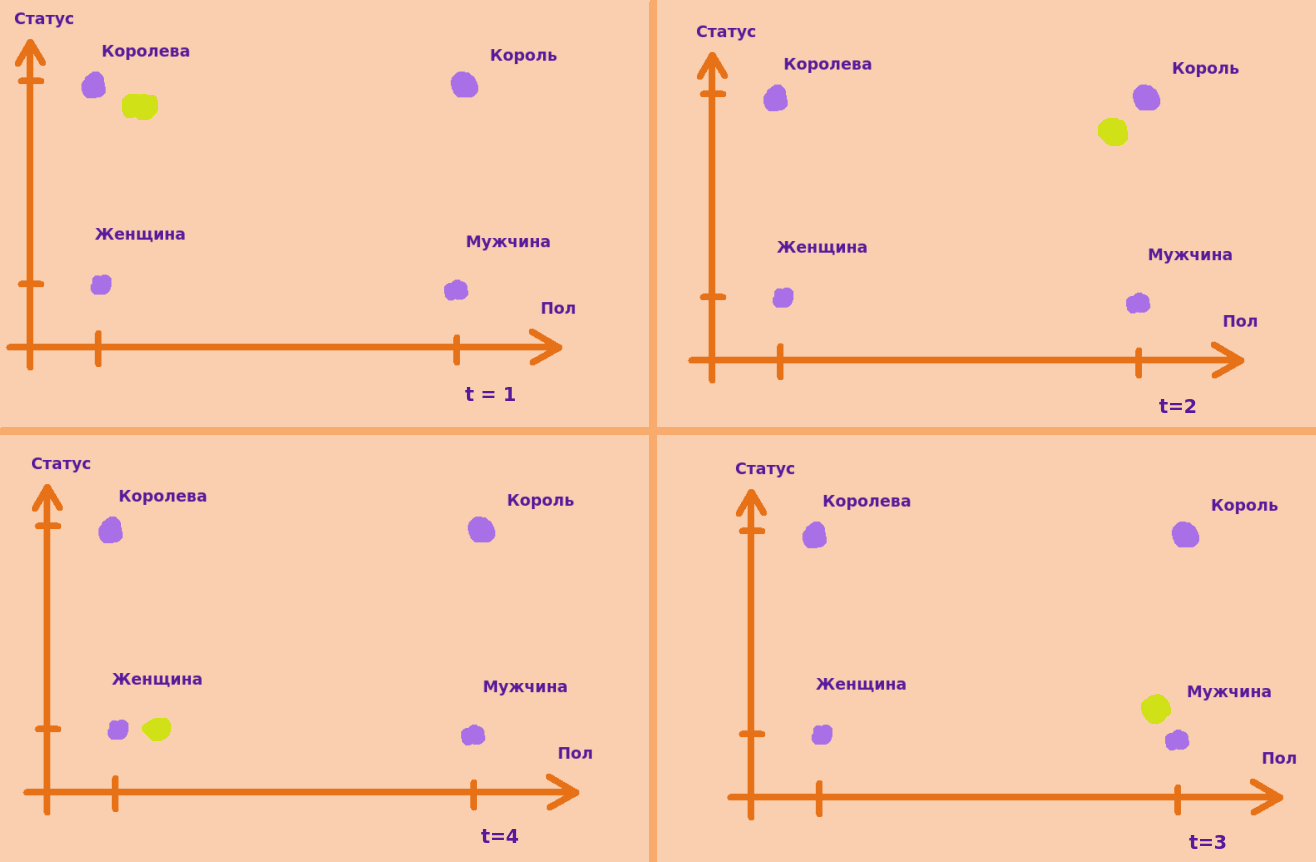
Получается, что такой обход по контуру квадрата сгенерирует нам текст "Королева, король, мужчина, женщина". В данном случае, для нашей простой модели именно такой текст является взаимосвязным, поскольку изменять расстояние мы можем не больше чем на единицу, значит получить текст "королева, мужчина, женщина, король" мы не можем, потому что они "как бы" не так сильно связаны статистически.
Возвращаемся
Арора начал с того, что внёс модификацию в его генеративную модель из прошлой статьи. В новой модели он предлагает заменить равномерное распределение, по которому движется вектор контекста, Гаусовским. Это порождает некоторые измения в выкладках из первой части, но мы их рассматривать не будем(на данный момент, во всяком случае). Далее, базируясь на этой модели, он выдвигает и доказывает две теоремы. Я приведу их здесь без доказательства.
Теорема 1
Предполагая выше описанную модель, пусть  это случайная переменная для окна длинной
это случайная переменная для окна длинной  слов. Тогда существует линейное преобразование
слов. Тогда существует линейное преобразование  такое, что
такое, что
![$ \upsilon_w \approx A \mathbb{E}[\frac{1}{n}\sum_{w_i\in s}\upsilon_{w_i}|w \in s] $](https://habrastorage.org/getpro/habr/formulas/3b2/0c4/634/3b20c46348ce4023862618647ffc094e.svg)
Это значит, что между неким словом и его окном существует линейная зависимость. В статье рассматривается следующий мысленный эксперимент. Давайте возьмем некое слово и соберем для этого слова все окна. Множество всех окон обозначим за  . Затем, возьмем среднее
. Затем, возьмем среднее  каждого окна
каждого окна  , а затем возьмем среднее от всех средних по окнам и обозначим это
, а затем возьмем среднее от всех средних по окнам и обозначим это  . Тогда, согласно теореме, мы можем отобразить этот вектор в при помощи некой матрицы (которую еще найти надо). Тут следует сказать, что если такую матрицу найти, то это сократило бы проблемы out-of-vocabulary слов, поскольку посчитать среднее от всех окон и помножить это на матрицу явно проще, чем полностью переобучать все векторы с нуля.
. Тогда, согласно теореме, мы можем отобразить этот вектор в при помощи некой матрицы (которую еще найти надо). Тут следует сказать, что если такую матрицу найти, то это сократило бы проблемы out-of-vocabulary слов, поскольку посчитать среднее от всех окон и помножить это на матрицу явно проще, чем полностью переобучать все векторы с нуля.
Арора проводит эксперимент, чтобы проверить это. Для его понимания, необходимо понятие SIF эмбеддингов. Хотя в данной статье и есть про них заметка, вообще, им посвящена отдельная статья, которую я тоже разберу позже. Сейчас же будет достаточно знать, что SIF эмбеддинги  это эмбеддинги для окна текста k, который считается как среднее от эмбеддингов, входящих в это окно слов , умноженных на их TF-IDF.
это эмбеддинги для окна текста k, который считается как среднее от эмбеддингов, входящих в это окно слов , умноженных на их TF-IDF.

К слову, оказывается, что с позиции теоремы 1, эти эмбеддинги являются максимальной оценкой правдоподобия для вектора контекста  . Как вы могли заметить, это и самый простой способ построить эмбеддинг какого-то куска текста, например, предложения.
. Как вы могли заметить, это и самый простой способ построить эмбеддинг какого-то куска текста, например, предложения.
Возвращаясь обратно к эксперименту. Представим, что у нас есть матрица эммбеддингов и какое-то слово , для которого нет эмбеддинга в матрице, но мы хотим его посчитать. Алгоритм будет выглядеть следующим образом:
- Случайно выберем много параграфов из Википедии. Обозначим словарь всего такого подкорпуса
 .
. - Для каждого слова
 , для которых известны эмбеддинги, и всех их вхождений среди параграфов по отдельности посчитаем SIF эмбеддинги для окон в 20 слов с центром в
, для которых известны эмбеддинги, и всех их вхождений среди параграфов по отдельности посчитаем SIF эмбеддинги для окон в 20 слов с центром в  , используя нашу известную матрицу эмбеддингов. В итоге для каждого слова мы получим множество векторов
, используя нашу известную матрицу эмбеддингов. В итоге для каждого слова мы получим множество векторов  , где n — количество входений слова в подкорпусе.
, где n — количество входений слова в подкорпусе. - Посчитаем среднее
 всех SIF эмбеддингов для каждого слова по формуле
всех SIF эмбеддингов для каждого слова по формуле  .
. - Решаем регрессию

- Берем среднее всех SIF эмбеддингов для нашего неизвестного слова и считаем

Арора показывает, что эти т.н. индуцированные эмбеддинги довольно хорошо приближены к своим оригиналам. Он подсчитал таким образом эмбеддинги для 1/3 слов от известной матрицы, произведя обучение матрицы A на оставшихся 2\3 части. В таблице ниже представлены результаты из оригинальной работы. Обратите внимание на количество параграфов.
| #paragraphs | 250k | 500k | 750k | 1 million |
|---|---|---|---|---|
| cos similarity | 0.94 | 0.95 | 0.96 | 0.96 |
Теорема 2
Предположим, что существует некое слово с двумя разными значениями  и
и  . Получим вектор для этого слова на каком-нибудь корпусе, где присутствуют оба этих значения. Затем, в этом же корпусе вручную проставим метки для этих значений, т.е. искусственно переделаем слова в псевдослова, например, tie_1 и tie_2, где слово tie_1 — это для значение для галстука, а tie2 — для узла.
. Получим вектор для этого слова на каком-нибудь корпусе, где присутствуют оба этих значения. Затем, в этом же корпусе вручную проставим метки для этих значений, т.е. искусственно переделаем слова в псевдослова, например, tie_1 и tie_2, где слово tie_1 — это для значение для галстука, а tie2 — для узла.
Для нового корпуса с нашими псевдословами снова посчитаем эмбеддинги и обозначим их, соответственно, $<!-- math>$inline$ \upsilon{w{s1} } $inline$</math -->$ и $<!-- math>$inline$\upsilon{w_{s2} } $inline$</math -->$. Вновь, предполагая нашу генеративную модель, теорема утверждает, что эти эмбеддинги будут удовлетворять  , где
, где  определяется как
определяется как

где  и
и  это число вхождений значений and в корпус. Как вы можете видеть, это ровно то же выражение, как и в начале статьи.
это число вхождений значений and в корпус. Как вы можете видеть, это ровно то же выражение, как и в начале статьи.
Окей, все это, конечно, хорошо, но как мы можем восстановить эту линейную комбинацию значений слова? Их может существовать же гигантское количество даже при условии, что мы будем знать  . На помощь нам снова придет генеративная модель. Предположим, что вектор контекста сейчас находится рядом с темой о девушках и следовательно о них модель и будет генерировать текст. Тогда логично предположить, что если в данный момент появится слово коса, то оно будет иметь значение прически. Более того, такие слова, как глаза, наряд, красивая, платье должны генерироваться с высокой вероятностью. Также, согласно нашей модели, эта вероятность определяется, как скалярное произведение(inner product) между вектором контекста и вектором слова. Тогда давайте положим, что тот вектор контекста, который имеет наибольшее внутреннее произведение со всеми контекстно-близкими словами (глаза, наряд, красивая, платье), и будет вектором для значения
. На помощь нам снова придет генеративная модель. Предположим, что вектор контекста сейчас находится рядом с темой о девушках и следовательно о них модель и будет генерировать текст. Тогда логично предположить, что если в данный момент появится слово коса, то оно будет иметь значение прически. Более того, такие слова, как глаза, наряд, красивая, платье должны генерироваться с высокой вероятностью. Также, согласно нашей модели, эта вероятность определяется, как скалярное произведение(inner product) между вектором контекста и вектором слова. Тогда давайте положим, что тот вектор контекста, который имеет наибольшее внутреннее произведение со всеми контекстно-близкими словами (глаза, наряд, красивая, платье), и будет вектором для значения  косы, как женской прически! Остается только извлечь эти векторы.
косы, как женской прически! Остается только извлечь эти векторы.
Давайте снова поиграем в математиков. Что мы хотим? Имея набор векторов слов в  и два целых числа
и два целых числа  . таких что
. таких что  , мы хотим найти набор векторов
, мы хотим найти набор векторов  , таких, чтобы
, таких, чтобы

где не больше  коэффициентов не равны нулю и
коэффициентов не равны нулю и  — вектор ошибок. Для решения этой задачи мы можем записать следующее оптимизационное уравнение
— вектор ошибок. Для решения этой задачи мы можем записать следующее оптимизационное уравнение

Эта типичная проблема разреженного кодирования, где k называется параметром разреженности (sparsity parameter), а m — количество т.н. атомов, которые в нашем случае являются теми самыми векторами. Это можно решить при помощи алгоритма k-SVD. Стоит заметить, что данная задача не чистое решение. Мы можем только надеяться на то, что среди множества существует ось, соответствующая определенным темам(у нас получается, что множество похоже на координатную систему). Для того, чтобы быть уверенными, что какой-либо атом  участвует в выражении своего атрибута или темы в словах, выражая контекст, а не является болваночной осью, нам нужно ограничить
участвует в выражении своего атрибута или темы в словах, выражая контекст, а не является болваночной осью, нам нужно ограничить  много меньше количества слов. Авторы оригинальной статьи называл это атомами дискурса.
много меньше количества слов. Авторы оригинальной статьи называл это атомами дискурса.
Практика
Давайте, наконец, закодим это и посмотрим на эти атомы своими глазами.
import numpy as np from gensim.test.utils import datapath, get_tmpfile from gensim.models import KeyedVectors from gensim.scripts.glove2word2vec import glove2word2vec from scipy.spatial.distance import cosine import warnings warnings.filterwarnings('ignore')
1. Загрузка эмбедингов с помощью Gensim
Здесь я загружаю и трансформирую векторы GloVe. Вы можете скачать их здесь
Обращаю внимание, что я и автор используем векторы в 300-мерном пространстве.
tmp_file = get_tmpfile("test_word2vec.txt") _ = glove2word2vec("/home/astromis/Embeddings/glove.6B.300d.txt", tmp_file) model = KeyedVectors.load_word2vec_format(tmp_file)
embeddings = model.wv index2word = embeddings.index2word embedds = embeddings.vectors
print(embedds.shape)
(400000, 300)
У нас есть 400000 уникальных слов.
2. Устанавливаем и применяем k-svd к матрице эмбеддингов
Теперь нам нужно получить атомы дискурса с помощью разреженного восстановления. Мы будем использовать пакет ksvd.
!pip install ksvd from ksvd import ApproximateKSVD
Requirement already satisfied: ksvd in /home/astromis/anaconda3/lib/python3.6/site-packages (0.0.3) Requirement already satisfied: numpy in /home/astromis/anaconda3/lib/python3.6/site-packages (from ksvd) (1.14.5) Requirement already satisfied: scikit-learn in /home/astromis/anaconda3/lib/python3.6/site-packages (from ksvd) (0.19.1)
В статье автор выбрал количество атомов, равное 2000 и параметр разрежености равный 5.
Я натренировал две версии: первая для 10000 эмбеддингов и вторая для всех. Поскольку этот процесс занимает довольно много времени, особенно, для полной матрицы, я сохранил результаты, чтобы вы смогли просто их загрузить.
%time aksvd = ApproximateKSVD(n_components=2000,transform_n_nonzero_coefs=5, ) embedding_trans = embeddings.vectors dictionary = aksvd.fit(embedding_trans).components_ gamma = aksvd.transform(embedding_trans)
CPU times: user 4 µs, sys: 0 ns, total: 4 µs Wall time: 9.54 µs
#gamma = np.load('./data/mats/.npz') # dictionary_glove6b_300d.np.npz - whole matrix file dictionary = np.load('./data/mats/dictionary_glove6b_300d_10000.np.npz') dictionary = dictionary[dictionary.keys()[0]]
#print(gamma.shape) print(dictionary.shape)
(2000, 300)
#np.savez_compressed('gamma_glove6b_300d.npz', gamma) #np.savez_compressed('dictionary_glove6b_300d.npz', dictionary)
3. Определение связей между атомами и исходной матрицей
Давайте поиграем с нашими атомами и посмотрим, что мы получили. Посмотрим на ближайших соседей нескольких выбранных атомов.
embeddings.similar_by_vector(dictionary[1354,:])
[('slave', 0.8417330980300903), ('slaves', 0.7482961416244507), ('plantation', 0.6208109259605408), ('slavery', 0.5356900095939636), ('enslaved', 0.4814416170120239), ('indentured', 0.46423888206481934), ('fugitive', 0.4226764440536499), ('laborers', 0.41914862394332886), ('servitude', 0.41276970505714417), ('plantations', 0.4113745093345642)]
embeddings.similar_by_vector(dictionary[1350,:])
[('transplant', 0.7767853736877441), ('marrow', 0.699995219707489), ('transplants', 0.6998592615127563), ('kidney', 0.6526087522506714), ('transplantation', 0.6381147503852844), ('tissue', 0.6344675421714783), ('liver', 0.6085026860237122), ('blood', 0.5676015615463257), ('heart', 0.5653558969497681), ('cells', 0.5476219058036804)]
embeddings.similar_by_vector(dictionary[1546,:])
[('commons', 0.7160810828208923), ('house', 0.6588335037231445), ('parliament', 0.5054076910018921), ('capitol', 0.5014163851737976), ('senate', 0.4895153343677521), ('hill', 0.48859673738479614), ('inn', 0.4566132128238678), ('congressional', 0.4341348707675934), ('congress', 0.42997264862060547), ('parliamentary', 0.4264637529850006)]
embeddings.similar_by_vector(dictionary[1850,:])
[('okano', 0.2669774889945984), ('erythrocytes', 0.25755012035369873), ('windir', 0.25621023774147034), ('reapportionment', 0.2507009208202362), ('qurayza', 0.2459488958120346), ('taschen', 0.24417680501937866), ('pfaffenbach', 0.2437630295753479), ('boldt', 0.2394050508737564), ('frucht', 0.23922981321811676), ('rulebook', 0.23821482062339783)]
Восхитительный результат! Выглядит похоже, что атомы являются центрами для похожих слов. Давайте теперь специально возьмем пару многозначных слов и найдем для них ближайший атом. Для каждого атома выводится список ближайших соседей, который поможет понять, какой контекст этот атом описывает. Для английского попробуем взять "tie" и "spring" из статьи.
itie = index2word.index('tie') ispring = index2word.index('spring') tie_emb = embedds[itie] string_emb = embedds[ispring]
simlist = [] for i, vector in enumerate(dictionary): simlist.append( (cosine(vector, tie_emb), i) ) simlist = sorted(simlist, key=lambda x: x[0]) six_atoms_ind = [ins[1] for ins in simlist[:15]] for atoms_idx in six_atoms_ind: nearest_words = embeddings.similar_by_vector(dictionary[atoms_idx,:]) nearest_words = [word[0] for word in nearest_words] print("Atom #{}: {}".format(atoms_idx, ' '.join(nearest_words)))
Atom #162: win victory winning victories wins won 2-1 scored 3-1 scoring Atom #58: game play match matches games played playing tournament players stadium Atom #237: 0-0 1-1 2-2 3-3 draw 0-1 4-4 goalless 1-0 1-2 Atom #622: wrapped wrap wrapping holding placed attached tied hold plastic held Atom #1899: struggles tying tied inextricably fortunes struggling tie intertwined redefine define Atom #1941: semifinals quarterfinals semifinal quarterfinal finals semis semi-finals berth champions quarter-finals Atom #1074: qualifier quarterfinals semifinal semifinals semi finals quarterfinal champion semis champions Atom #1914: wearing wore jacket pants dress wear worn trousers shirt jeans Atom #281: black wearing man pair white who girl young woman big Atom #1683: overtime extra seconds ot apiece 20-17 turnovers 3-2 halftime overtimes Atom #369: snap picked snapped pick grabbed picks knocked picking bounced pulled Atom #98: first team start final second next time before test after Atom #1455: after later before when then came last took again but Atom #1203: competitions qualifying tournaments finals qualification matches qualifiers champions competition competed Atom #1602: hat hats mask trick wearing wears sunglasses trademark wig wore
simlist = [] for i, vector in enumerate(dictionary): simlist.append( (cosine(vector, string_emb), i) ) simlist = sorted(simlist, key=lambda x: x[0]) six_atoms_ind = [ins[1] for ins in simlist[:15]] for atoms_idx in six_atoms_ind: nearest_words = embeddings.similar_by_vector(dictionary[atoms_idx,:]) nearest_words = [word[0] for word in nearest_words] print("Atom #{}: {}".format(atoms_idx, ' '.join(nearest_words)))
Atom #528: autumn spring summer winter season rainy seasons fall seasonal during Atom #1070: start begin beginning starting starts begins next coming day started Atom #931: holiday christmas holidays easter thanksgiving eve celebrate celebrations weekend festivities Atom #1455: after later before when then came last took again but Atom #754: but so not because even only that it this they Atom #688: yankees yankee mets sox baseball braves steinbrenner dodgers orioles torre Atom #1335: last ago year months years since month weeks week has Atom #252: upcoming scheduled preparations postponed slated forthcoming planned delayed preparation preparing Atom #619: cold cool warm temperatures dry cooling wet temperature heat moisture Atom #1775: garden gardens flower flowers vegetable ornamental gardeners gardening nursery floral Atom #21: dec. nov. oct. feb. jan. aug. 27 28 29 june Atom #84: celebrations celebration marking festivities occasion ceremonies celebrate celebrated celebrating ceremony Atom #98: first team start final second next time before test after Atom #606: vacation lunch hour spend dinner hours time ramadan brief workday Atom #384: golden moon hemisphere mars twilight millennium dark dome venus magic
Весьма неплохо! Мы действительно, хоть и с некоторыми ошибками, видим атомы, которые отражают разные значения слов.
Интересно, что если это сделать на всей матрице, то результат будет гораздо менее точным. Я подозреваю, тут сказывается неопределенность задачи, о которой говорилось ранее.
Давайте теперь попробуем тоже самое сделать и для русского языка. В качестве эмбеддингов возьмем fastText, предоставленный RusVectores. Они были натренированы на НКРЯ с размерностью 300.
fasttext_model = KeyedVectors.load('/home/astromis/Embeddings/fasttext/model.model')
embeddings = fasttext_model.wv index2word = embeddings.index2word embedds = embeddings.vectors
embedds.shape
(164996, 300)
%time aksvd = ApproximateKSVD(n_components=2000,transform_n_nonzero_coefs=5, ) embedding_trans = embeddings.vectors[:10000] dictionary = aksvd.fit(embedding_trans).components_ gamma = aksvd.transform(embedding_trans)
CPU times: user 1 µs, sys: 2 µs, total: 3 µs Wall time: 6.2 µs
dictionary = np.load('./data/mats/dictionary_rus_fasttext_300d.npz') dictionary = dictionary[dictionary.keys()[0]]
embeddings.similar_by_vector(dictionary[1024,:], 20)
[('исчезать', 0.6854609251022339), ('бесследно', 0.6593252420425415), ('исчезавший', 0.6360634565353394), ('бесследный', 0.5998549461364746), ('исчезли', 0.5971367955207825), ('исчез', 0.5862340927124023), ('пропадать', 0.5788886547088623), ('исчезлотец', 0.5788123607635498), ('исчезнувший', 0.5623885989189148), ('исчезинать', 0.5610565543174744), ('ликвидироваться', 0.5551878809928894), ('исчезнуть', 0.551397442817688), ('исчезнет', 0.5356274247169495), ('исчезание', 0.531707227230072), ('устраняться', 0.5174376368522644), ('ликвидируть', 0.5131562948226929), ('ликвидировать', 0.5120065212249756), ('поглощаться', 0.5077806115150452), ('исчезаний', 0.5074601173400879), ('улетучиться', 0.5068254470825195)]
embeddings.similar_by_vector(dictionary[1582,:], 20)
[('простой', 0.45191124081611633), ('простоть', 0.4515378475189209), ('простота', 0.4478364586830139), ('наибол', 0.4280813932418823), ('простототь', 0.41220104694366455), ('простейший', 0.40772825479507446), ('простотое', 0.4047147035598755), ('наиболь', 0.4030646085739136), ('наилучше', 0.39368513226509094), ('формула', 0.39012178778648376), ('простое', 0.3866344690322876), ('просто', 0.37968817353248596), ('наглядна', 0.3728911876678467), ('простейшее', 0.3663109242916107), ('первооснова', 0.3640827238559723), ('наибольший', 0.3474290072917938), ('первородство', 0.3473641574382782), ('легко', 0.3468908369541168), ('наилучший', 0.34586742520332336), ('авось', 0.34555742144584656)]
embeddings.similar_by_vector(dictionary[500,:], 20)
[('фонд', 0.6874514222145081), ('-фонд', 0.5172050595283508), ('фондю', 0.46720415353775024), ('жилфонд', 0.44713956117630005), ('госфонд', 0.4144558310508728), ('фильмофонд', 0.40545403957366943), ('гвардия', 0.4030636250972748), ('хедж-фонд', 0.4016447067260742), ('генофонд', 0.38331469893455505), ('литфонд', 0.37292781472206116), ('госфильмофонд', 0.3625457286834717), ('фондан', 0.35121074318885803), ('стабфонд', 0.3504621088504791), ('фондъ', 0.34097471833229065), ('тонд', 0.33320850133895874), ('бонд', 0.3277249336242676), ('эхо', 0.3266661763191223), ('ржонд', 0.31865227222442627), ('юрий::левада', 0.30150306224823), ('ргва', 0.2975207567214966)]
itie = index2word.index('коса') ispring = index2word.index('ключ') tie_emb = embedds[itie] string_emb = embedds[ispring]
simlist = [] for i, vector in enumerate(dictionary): simlist.append( (cosine(vector, string_emb), i) ) simlist = sorted(simlist, key=lambda x: x[0]) six_atoms_ind = [ins[1] for ins in simlist[:10]] for atoms_idx in six_atoms_ind: nearest_words = embeddings.similar_by_vector(dictionary[atoms_idx,:]) nearest_words = [word[0] for word in nearest_words] print("Atom #{}: {}".format(atoms_idx, ' '.join(nearest_words)))
Atom #185: загадка загадк загадкай загад проблема вопрос разгадка загадать парадокс задача Atom #1217: дверь дверью двери дверка дверной калитка ставень запереть дверь-то настежь Atom #1213: папка бумажник сейф сундук портфель чемодан ящик сундучк пачка сундучок Atom #1978: кран плита крышка вентиль клапан электроплита котел плитка раковина посуда Atom #1796: карман пазуха кармашек бумажник карманута карманбыть пазух карманчик карманьол кармашка Atom #839: кнопка кнопф нажимать кноп клавиша нажать кнопа кнопочка рычажок нажатие Atom #989: отыскивать искать отыскиваться поискать разыскивать разыскиваться поиск поискивать отыскать отыскаться Atom #414: молоток молот топор пила колот молотобоец молотой кувалда молота умолот Atom #1140: капиталец капитал капиталовек капиталист капитально капитализм -капиталист капитальный капиталоемкий капиталовложение Atom #878: хранитель хранить храниться хранивший хранивать хранимый храниваться хранилище хранеть хранившийся
simlist = [] for i, vector in enumerate(dictionary): simlist.append( (cosine(vector, tie_emb), i) ) simlist = sorted(simlist, key=lambda x: x[0]) six_atoms_ind = [ins[1] for ins in simlist[:10]] for atoms_idx in six_atoms_ind: nearest_words = embeddings.similar_by_vector(dictionary[atoms_idx,:]) nearest_words = [word[0] for word in nearest_words] print("Atom #{}: {}".format(atoms_idx, ' '.join(nearest_words)))
Atom #883: косой русый кудряшка косичка челка русой черноволосой кудрявый кудряш светло-русый Atom #40: кустарник заросль осока ивняк трава бурьян папоротник кустик полукустарник бурьяна Atom #215: ниточка паучок бусинка паутинка жердочка стебелька веточка стебелек травинка пупырышек Atom #688: волос валюта кудри валютный борода валютчик ус бивалютный коса усы Atom #386: плечотец грудь шея подбородок бедро грудью ляжка плечо затылок живот Atom #676: веревка канат бечевка веревочка бечевкий шест репшнур жердь веревочный ремень Atom #414: молоток молот топор пила колот молотобоец молотой кувалда молота умолот Atom #127: сюртучок сюртук галстучок фрак панталоны галстучек сюртуки галстук платье галстух Atom #592: салфетка скатерть салфеточка платок шаль полотенце кружевной кружевцо кисея шелка Atom #703: шлюпка катер баркас фок-мачта грот-мачта мачта фрегат судно корвет шхуна
#np.savez_compressed('./data/mats/gamma_rus_fasttext_300d.npz', gamma) #np.savez_compressed('./data/mats/dictionary_rus_fasttext_300d.npz', dictionary)
Результат тоже довольно впечатляет.
Заключение
В обзор статьи не вошли некоторые вещи из статьи, такие как алгоритм для индукции смысла слов (Word sense indection), который базируется на всех этих выкладках, а также я не провел опыт для теоремы 1. Данная статья — один из кирпичиков в понимании того, как устроены эмбеддинги. Наперед скажу, что есть статьи которые показывают, что не все предположения данного автора корректны. Однако, удивительно, но эксперименты показывают, что подход работает. Будем смотреть, что будет дальше.
UPD: Спасибо knagaev за множественные правки опечаток.

