Перевод статьи подготовлен в преддверии старта курса «Промышленный ML на больших данных». Интересно развиваться в данном направлении? Смотрите записи трансляций бесплатных онлайн-мероприятий: «День Открытых Дверей», «Вывод ML моделей в промышленную среду на примере онлайн-рекомендаций».

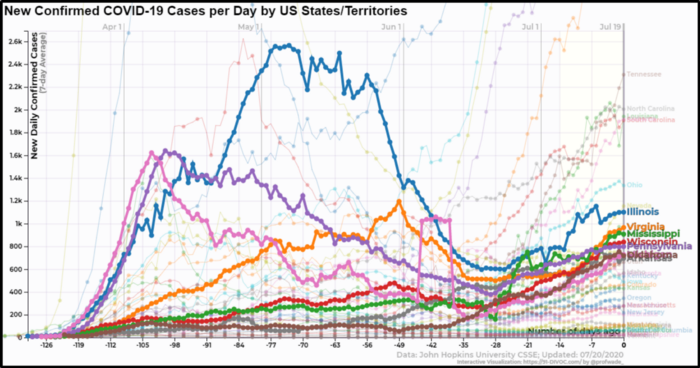
Визуализация новых случаев заражения COVID-19 по дням для каждого штата США без алгоритма позиционирования лейблов
Одной из наиболее сложноконтролируемых областей при визуализации данных в реальном времени является расположение лейблов. В огромном количестве визуализаций я старался вообще избегать большого количества лейблов, чтобы они не накладывались друг на друга, но в последний раз выйти из ситуации таким способом не получилось.
Моя визуализация 91-DIVOC пандемии COVID-19 позволяет пользователям получить самые последние данные о коронавирусе из Университета Джонса Хопкинса с помощью интерактивной визуализации, построенной на библиотеке d3.js. Поскольку визуализация использует данные, которые обновляются несколько раз в день, а пользователи имеют возможность изучать данные и создавать более миллиона различных визуализаций, все должно рендериться программно.
Есть множество ограничений, которые часто встречаются, когда речь заходит о комбинировании линейных графов, поэтому сделать лейблы читаемыми бывает совсем непросто:
- Линий может быть много, и они все могут заканчиваться в одной точке.
- Некоторые линии важнее, чем другие. В визуализации 91-DIVOC пользователь может выделить одну или несколько стран, тогда линия станет темнее и толще, а лейбл увеличится в размерах.
- Большинство пользователей используют мобильные устройства, что ограничивает вычислительные ресурсы.
Без использования алгоритма позиционирования лейблов, визуализация новых случаев COVID-19 выводит несколько нечитаемых выделенных лейблов и еще более нечитаемых невыделенных.
Популярный подход: Силовые алгоритмы визуализации графов
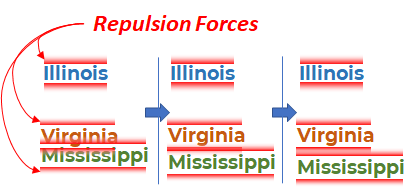
Этапы моделирования силового алгоритма размещения лейблов на трех лейблах. На третьем этапе лейблы Mississippi и Virginia наконец разделились.
Распространенный подход к решению проблемы позиционирования лейблов – это компонент «force» в d3.js, который реализует force-directed граф. Force-directed граф – это модель, основанная на физике, в которой у всех элементов есть сила притяжения и отталкивания относительно других элементов. Если говорить об алгоритмах позиционирования лейблов, то у каждого элемента появляется небольшая сила отталкивания от других элементов, в результате чего симуляция отталкивает элементы друг от друга, когда это возможно, создавая читаемые лейблы. Когда в результате моделирования симуляция достигает стабильного конечного состояния, итог получается довольно хорошим, поэтому такой подход признан вполне рабочим.
К сожалению, force-directed графы медленные. Время работы force-directed алгоритмов растет кубически по отношению к входному значению, O(n³). То есть области, в которых много элементов, требовали большого количества вычислительной мощности. В более ранних экспериментах с силовыми алгоритмами больше времени было потрачено на построение force-directed графа, чем на обработку и визуализацию. Пришло время для нового решения.
Быстрое решение: «Render или Nudge»
Меня постигла неудача с force-directed графами, которые оказались слишком медленными. Нужно было, чтобы время выполнения любого решения было минимальным. Дабы сэкономить время на позиционирование одного лейбла, размещение каждого из них сводилось к решению «render или nudge»:
- Если в данный момент в области не отображается ни один лейбл, отрендерите его. Такое решение сработает незамедлительно, а местоположение не будет изменено.
- Если другой лейбл, который был отрендерен раньше, теперь перекрывается новым лейблом, подтолкните (nudge) его, чтобы попробовать найти позицию получше.
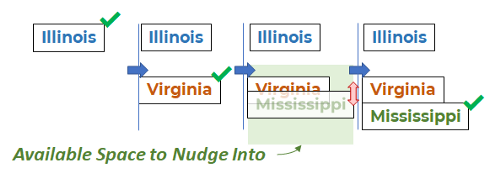
Стратегия позиционирования лейблов «Render или Nudge», показанная на примере трех меток, где «подталкивается» лейбл Mississippi
В процессе подталкивания лейбла, он сдвигается на высоту лейбла выше или ниже предполагаемого положения. Если подходящего места не найдено, то лейбл будет отображаться в исходной позиции, создавая наложение. (Смещение лейбла дальше предполагаемого места часто приводит к визуальному разрыву между данными и лейблом.)
Если лейблы просматриваются единожды, то алгоритм выполняется за линейное время O(n) и будет отнесен к «жадным» алгоритмам позиционирования лейблов.
Результат
После реализации алгоритма, результаты по скорости работы алгоритма были ошеломляющими. Ниже вы видите, что все выделенные лейблы читаемы, да и многие другие из 40+ невыделенных лейблов, тоже читаемы.
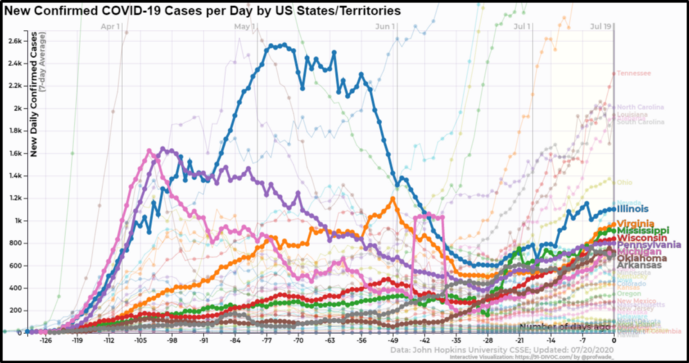
Визуализация количества заражений COVID-19 в день для каждого штата США с позиционированием лейблов по стратегии «render или nudge»
При размещении лейблов во время визуализации данных, подумайте о недорогих решениях, которые не затрагивают глобальное позиционирование. Несмотря на то, что данное решение не гарантирует, что ни один лейбл не накладывается на другой, оно значительно улучшает бесхитростное позиционирование и серьезно улучшает читаемость любой визуализации с десятками и сотнями лейблов.
(Кстати, мою визуализацию с этим алгоритмом позиционирования лейблов вы можете посмотреть тут: 91-DIVOC #01: «An interactive visualization of the exponential spread of COVID-19»)
Узнать подробнее о курсе «Промышленный ML на больших данных»

