В последнее время коллеги по "цеху" независимо друг от друга стали спрашивать меня: как получить c одного SDR-приемника одновременно все каналы Bluetooth? Полоса ведь позволяет, есть SDR с выходной полосой 80 МГц и более. Можно, конечно, сделать это на ПЛИС, но время такой разработки будет довольно большим. Мне давно было известно, что сделать такое на GPU довольно просто, но чтобы так!
Стандарт Bluetooth определяет физический уровень в двух версиях: Classic и Low Energy. Спецификация есть здесь. Документ ужасно большой, читать его целиком опасно для мозга. К счастью, большие компании, производящие измерительную технику, имеют средства для создания наглядных документов по теме. Tektronix и National Instruments, например. У меня совершенно нет шансов в конкуренции с ними по качеству представления материала. Интересующихся прошу изучать по ссылкам.
Все, что мне нужно знать о физическом уровне для создания многоканального фильтра, это шаг сетки частот и скорость модуляции. Они сведены в таблицу в одном из указанных документов:
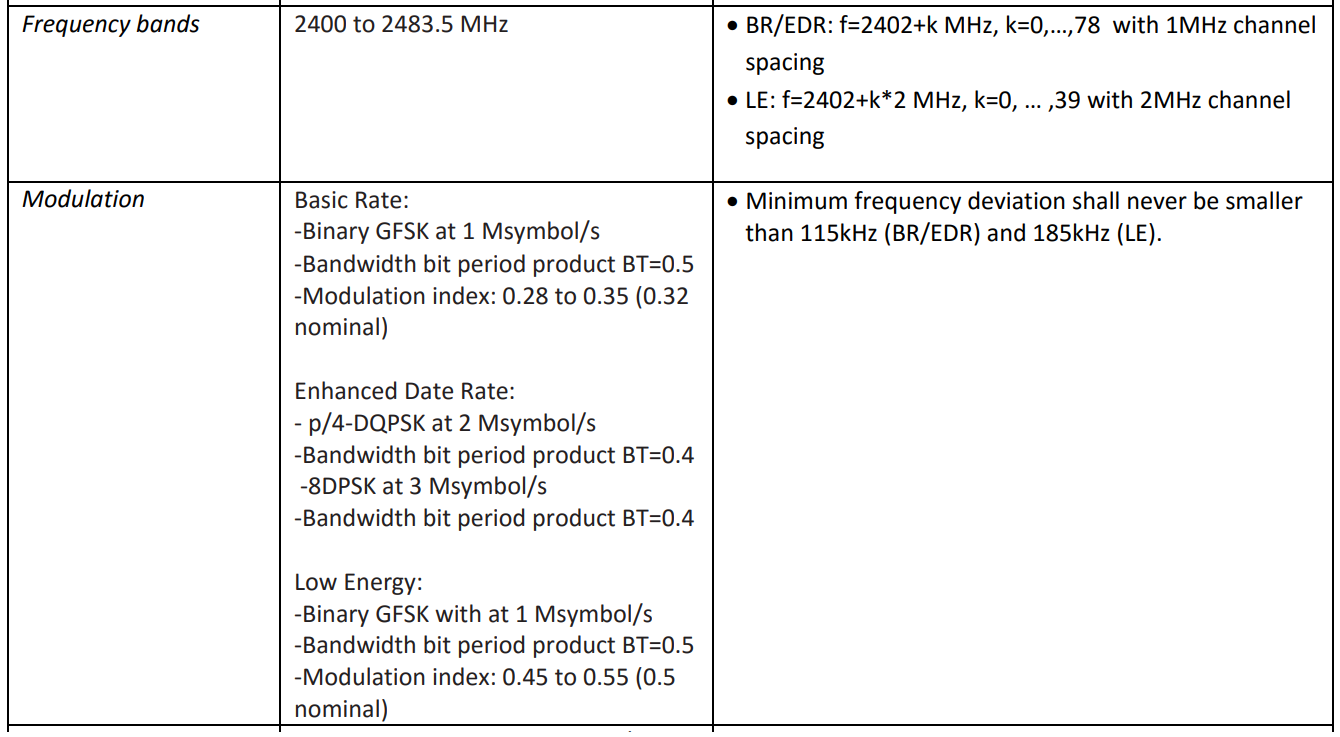
Таким образом, нам нужно нарезать полосу 80 МГц на 79 фильтров с шагом настройки 1 МГц и, одновременно с этим, на 40 фильтров с шагом настройки 2 МГц. Частоты следования отсчетов с выходов фильтров должны быть 1 МГц и 2 МГц, соответственно.
Таким образом, нам необходимо две гребенки фильтров.
Для начала выберем параметры этих фильтров исходя из полос сигналов Bluetooth Classic и Bluetooth Low Energy. Нам нужны их импульсные характеристики, чтобы рассчитать нагрузку на вычислительное устройство фильтра. Здесь сразу стоит оговориться, что длины импульсных характеристик мы выбрали исходя из требований "быстрого" алгоритма фильтрации. Суть от этого не меняется. И число коэффициентов импульсной характеристики не должно быть слишком большим, чтобы фильтр был реализуем на вменяемой вычислительной аппаратуре.
Для фильтров с шагом 1 МГц выберем полосу пропускания ФНЧ (половина полосы пропускания полосового фильтра) 500 кГц, длину импульсной характеристики подгоним к 480 отводам. Для фильтров с шагом 2 МГц эти параметры выберем 1 МГц и 240 отводов, соответственно. Тип окна выбираем Кайзера. Рассчитаем импульсные характеристики в filterDesigner и выгрузим их в формате С-header:




Можно решать задачу лобовым способом: строить соответствующий по числу фильтров массив DDC (Digital Down Converter). Такой подход хорош для ПЛИС, где возможна экономия за счет уменьшения разрядности вычислителей первых ступеней. Также ПЛИС — это наиболее энергетически-эффективный способ реализации. Но трудозатраты при этом способе наиболее высоки.
При выполнении гребенки фильтров на популярных нынче GPU появляется возможность реализации более хитрого алгоритма: полифазной гребенки фильтров на основе БПФ, который на CUDA доступен из библиотеки. В заграничной литературе алгоритм называется Polyphase or WOLA (Weight, Overlap and Add) FFT Filterbank. Лень к рисованию не дает мне возможности выполнить наглядное объяснение самостоятельно. В Сети есть много материалов по теме, особенно наглядный график выполнен здесь на странице 11 (огромное спасибо уважаемым авторам), вот он:
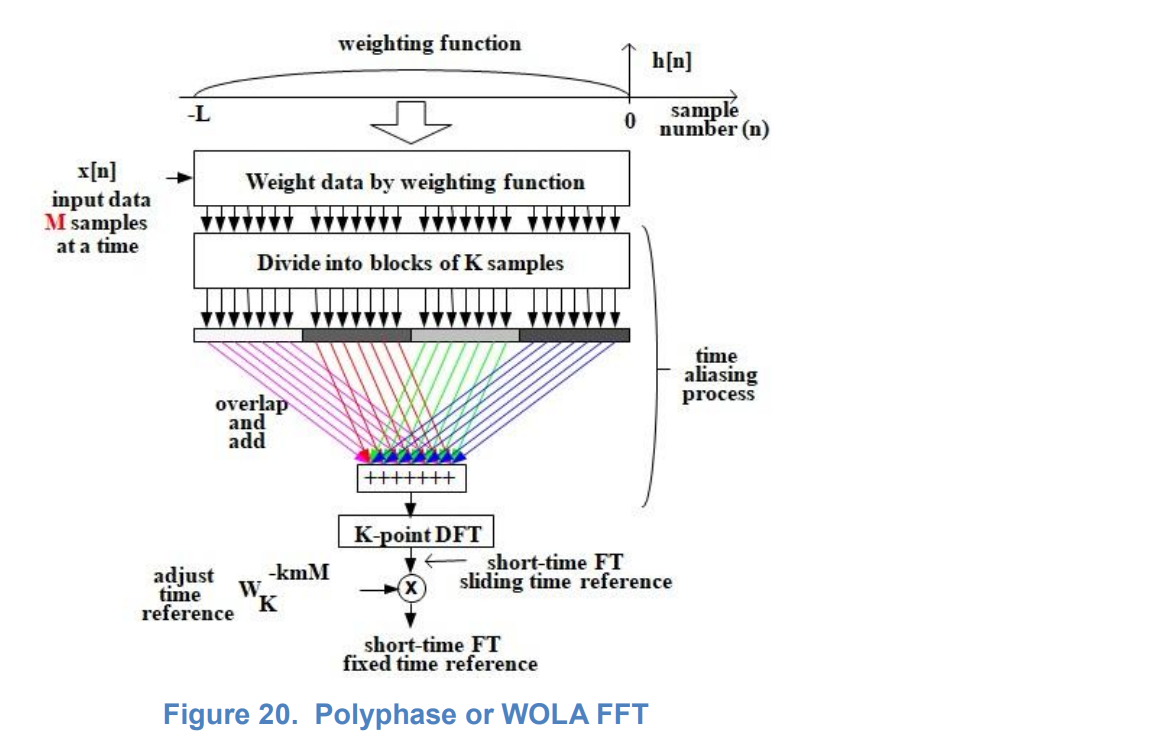
Я попробую пояснить схему обработки своими словами в рамках моих методических возможностей. БПФ есть свертка входного сигнала со всем спектром комплексных ортогональных гармоник, укладывающихся на интервале импульсной характеристики. Импульсная характеристика фильтра, на которую умножается сигнал перед входом БПФ, модулируется этим спектров гармоник. Другими словами, огибающая импульсных характеристик результирующих фильтров гребенки выносится за скобки. Далее, спектр гармоник прореживается в некоторое число раз, ввиду расширения полосы пропускания фильтра относительно фильтра в прямоугольным окном. На рисунке мы видим прореживание на четыре. Другими словами, после расширения полосы окном Кайзера (с одновременным увеличением затухания в полосе задержания), нам уже нужны не все фильтры а только четвертая их часть. Остальные избыточны, их частотные характеристики перекрываются. Из четырех точек БПФ, идущих подряд, выбираем только нулевую, вычисление которой есть суммирование четырех
входных точек, взятых через время, равное четверти длительности исходного БПФ.
Железо выберем то, которое есть под рукой. Это плата ввода компании "Инструментальные Системы" FMC126P. О ней я уже писал в одной предыдущей статье. В разъем FMC платы вставлен субмодуль той же компании с трансивером AD9371 с полосой 100 МГц. Весь поток с трансивера может быть непрерывно передан в компьютер для обработки.
Выберем видео-карту с GPU GTX 1050. (Соврал, это она нас выбрала: это все что было под рукой, была выдрана из вычислителя для расчета антенн, но тем удивительней было увидеть рабочую гребенку). Перейдем к программной части.
К сожалению, из-за лицензий мы не можем опубликовать полный код. Можем показать только ядра GPU. Впрочем, остальной код и не особо интересен.
Вот ядро, которое выполняет перемножение сигнала на окно и сложение, и обертка для его вызова:
__global__ void cuComplexMultiplyWindowKernel(const cuComplex *data, const float *window, size_t windowSize, cuComplex *result) { __shared__ cuComplex multiplicationResult[480]; multiplicationResult[threadIdx.x] = cuComplexMultiplyFloat(data[threadIdx.x + windowSize / 4 * blockIdx.x], window[threadIdx.x]); __syncthreads(); cuComplex sum; sum.x = sum.y = 0; if (threadIdx.x < windowSize / 4) { for(int i = 0; i < 4; i++) { sum = cuComplexAdd(sum, multiplicationResult[threadIdx.x + i * windowSize / 4]); } result[threadIdx.x + windowSize / 4 * blockIdx.x] = sum; } } cudaError_t cuComplexMultiplyWindow(const cuComplex *data, const float *window, size_t windowSize, cuComplex *result, size_t dataSize, cudaStream_t stream) { size_t windowStep = windowSize / 4; cuComplexMultiplyWindowKernel<<<dataSize / windowStep - 3, windowSize, 1024, stream>>>(data, window, windowSize, result); return cudaGetLastError(); }
Код обработки сигнала, который вызывает это ядро, в точности повторяет схему алгоритма, изображенную на рисунке выше, поэтому не вижу смысла приводить его здесь.
Гребенки были проверены на выходном спектре каналов в реальном времени. На вход AD9371 подавался сигнал генератора сигналов 2450 МГц, селективность фильтров соответствовала расчетной.
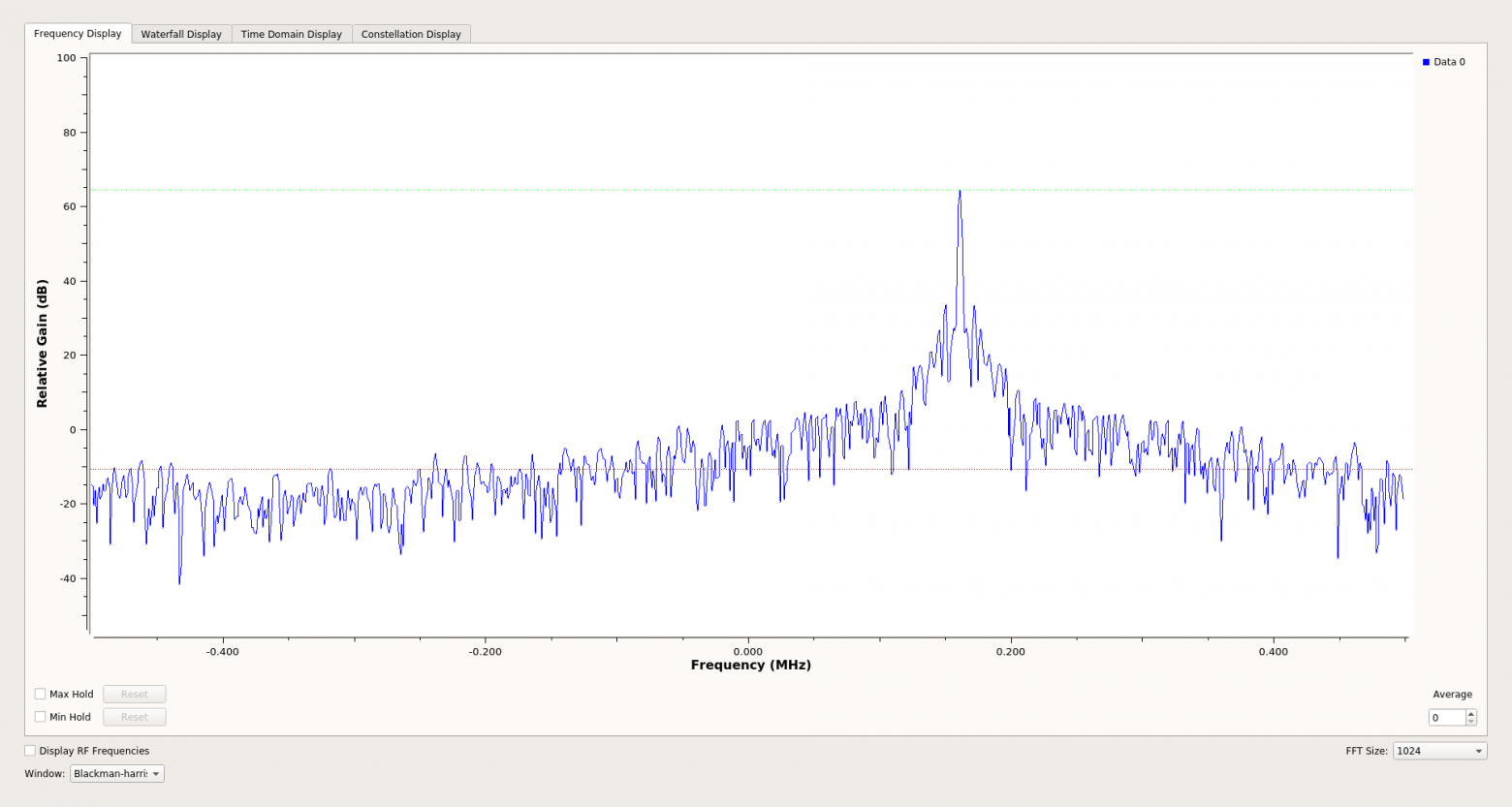
В планах: адаптация софта на плату XRTX и реализация поиска пакетов, если это кому-нибудь окажется нужно или будет свободное время.
Всю работу по софту выполнил gaudima, слава ему!

