Павел Труханов, "Мониторинг Postgres по USE и RED"
Есть две методологии перформанс мониторинга: USE (Utilization, Saturation, Errors) Брендана Грегга и RED (Requests, Errors, Durations) от Тома Уилки. В докладе я хочу рассказать о том, как мы на них ориентировались и продолжаем ориентироваться, когда реализуем мониторинг Postgres в okmeter.io.

Меня зовут Павел. Я работаю в компании Okmeter. Мы делаем мониторинг, который знает, как работает Postgres и умеет показывать детально, что там происходит. Соответственно, мы про это много думаем, много делаем и я решил поделиться тем, как мы используем известные методологии мониторинга, такие, как USE и RED в том, как мы строим наши статистические представления работы Postgres.

Часто бывает ситуация, когда начинаются проблемы с производительностью базы. И вы думаете, что база работает плохо.

На самом деле проблемы, конечно, не буквально в софте баз данных, а в том, как она используется в данный момент. И это может быть какое-то неоптимальное использование. А может быть performance проблема возникает из-за того, что вы не знаете, что там в данный момент происходит и поэтому нужен способ, чтобы посмотреть, что там внутри происходит.
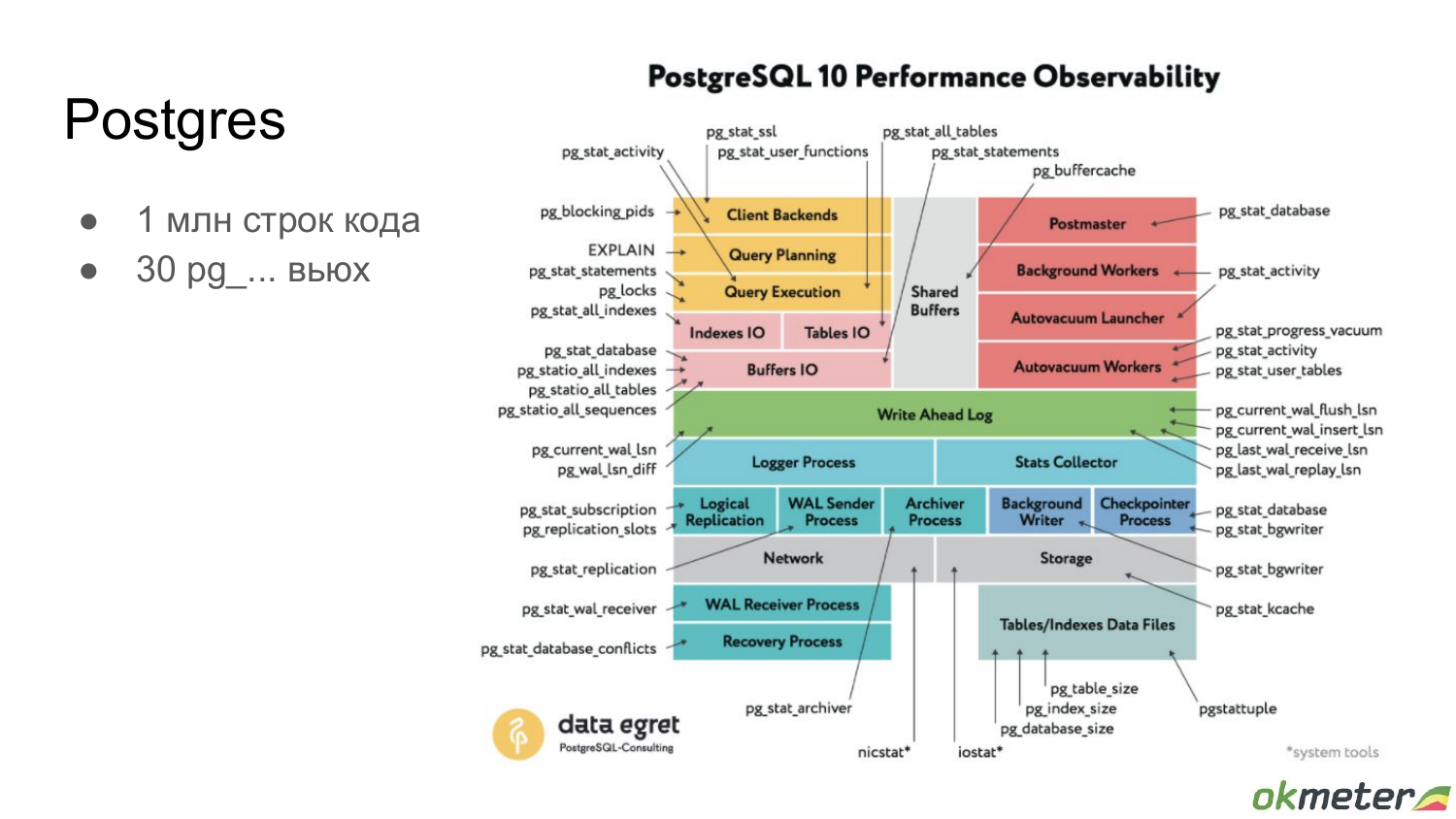
Но все, конечно, не так просто, потому что Postgres – это много кода, много подсистем, много системных вьюх. И если у вас есть опыт, то вы про многие из них что-то знаете, про производительность серверов вы представляете, что там можно смотреть, что там можно оптимизировать. Но все равно такой опыт в какой-то конкретной ситуации может сработать, может не сработать. И нужна какая-то система, как через все это продираться, когда у вас собственные гипотезы закончились.

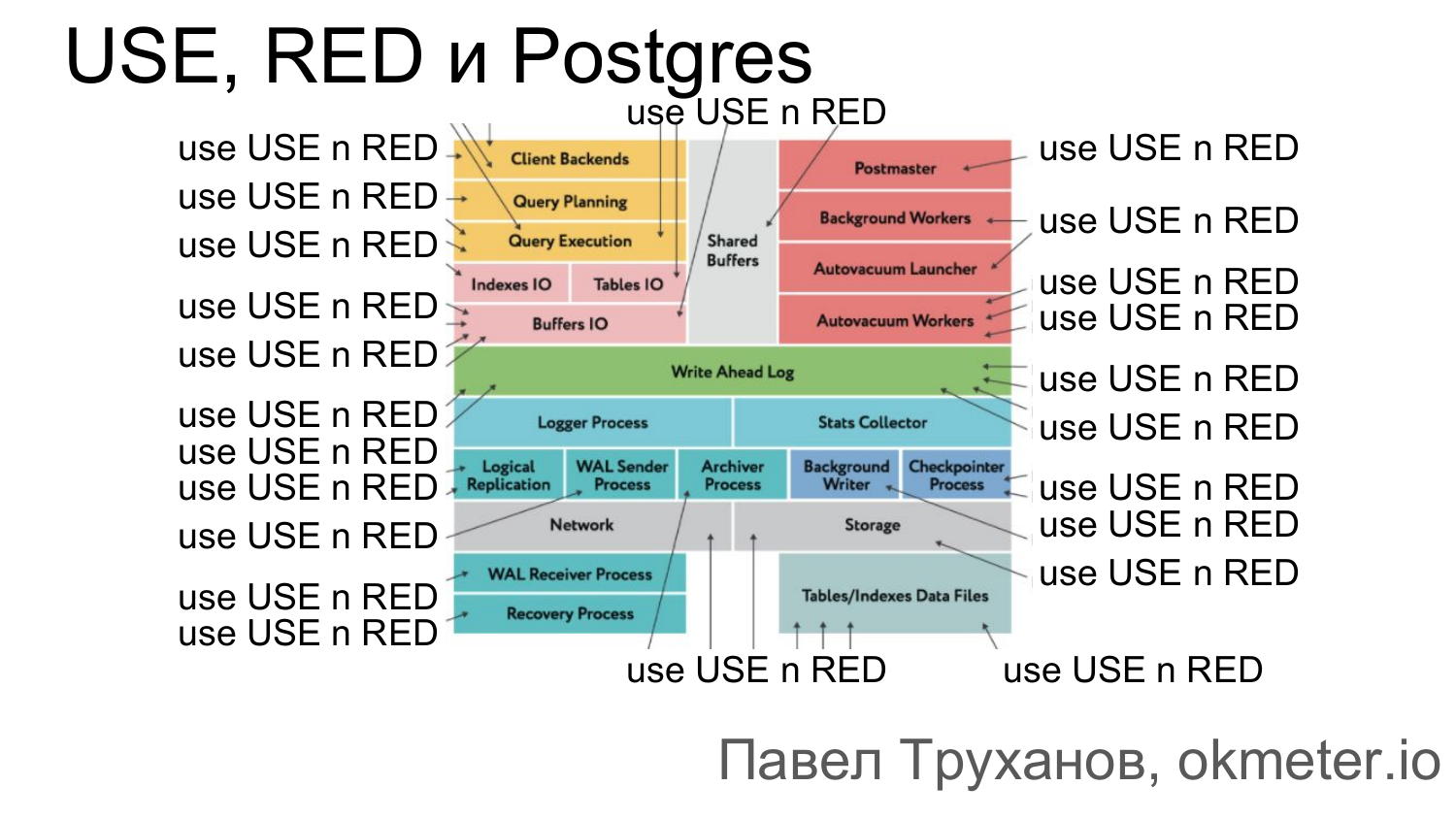
Есть такая методология USE. Она говорит, что все куски системы можно рассматривать как ресурсы. И, соответственно, эти ресурсы нужно мониторить в трех аспектах. В том, какая утилизация у данного ресурса, saturation насыщение и ошибки, которые этот ресурс возвращает.

Но зачем вообще методологии, когда есть стандартные вьюхи? Например, pg_stat_activity и прочие вьюхи. Зачем все притягивать к методологии? Затем, что это позволяет передавать знания. Например, вы разобрались в какой-то части системы, покрыли ее мониторингом или взяли готовый мониторинг. И, соответственно, вы хотите это коллегам рассказать. И это можно рассказывать как-то ситуативно, а можно использовать какую-то готовую модель, в которую можно вписывать конкретный аспект, и тогда будет проще передавать эти знания.
Что такое утилизация? Когда говоришь «утилизация», многим на ум приходит CPU Usage, который мы видим, и iostat – использование сети. Там есть параметры утилизации, которые уже за нас собирает операционная система. И, казалось бы, все просто. Мы видим, что они там высокие, допустим. И это значит плохо.

Но, допустим, это сервис баз данных, сервис Postgres. И вы пошли смотреть, что же в Postgres не так. Посмотрели всеми вашими стандартными способами. У видели, что никакой конкретный процесс, бэкенд не выделился. За эту картинку спасибо компании Data Egret. Вы посмотрели и ничего не находится, и нужно во всем этом разбираться.

Как натянуть фреймворк утилизации на что-нибудь из этого?
Мы начнем с левого верхнего угла. Это клиентские бэкенды. Это процессы, которые Postgres создал, чтобы обрабатывать соответствующие connection и запросы в этом connection от клиента.
Ресурсы можно разделить на два типа. Это условное деление. Я потом приведу примеры, когда деление не совсем правильное. Первый тип – это какие-то временные ресурсы. Например, процессорное время, дисковое время. И, соответственно, его утилизацию можно мерить по проценту времени, когда выполнялась полезная работа.
Тут возникает сразу вопрос: «Что такое полезная работа?». Например, когда на SpinLock крутится какой-то бэкенд, то, наверное, это не очень полезная работа. Но тем не менее CPU usage системный будет показывать, что процессор был занят выполнением работы.
Другой тип ресурсов – это пространственные. Это, например, память, свободное место на диске, какие-то слотовые вещи, которые есть в определенном количестве, и процесс, например, может взять какие-то вещи.
Зачем нужна утилизация? Затем, что у этих двух типов ресурсов есть capacity. И если 100 %, то значит, больше работы этот ресурс принять не может, если он принимает работу. Или больше выделенных слотов быть не может.
И возникает проблема. Когда новая работа приходит, она не может быть выполнена. Есть два варианта, куда она денется. Она либо денется в очередь. И тогда мы видим, что система тормозит. Либо происходит отказ, т. е. система не готова взять эту работу.
И для двух этих сценариев есть две другие метрики. Вся методология возникает из-за того, что мы меряем capacity. И что происходит, когда capacity заполнено? Происходят два сценария. Один это ставится в очередь. И нам тогда нужна saturation, которая мера насыщения этой очереди. Например, размер ее. И если не может, то это ошибки.
Посмотрим на бэкенды Postgres.
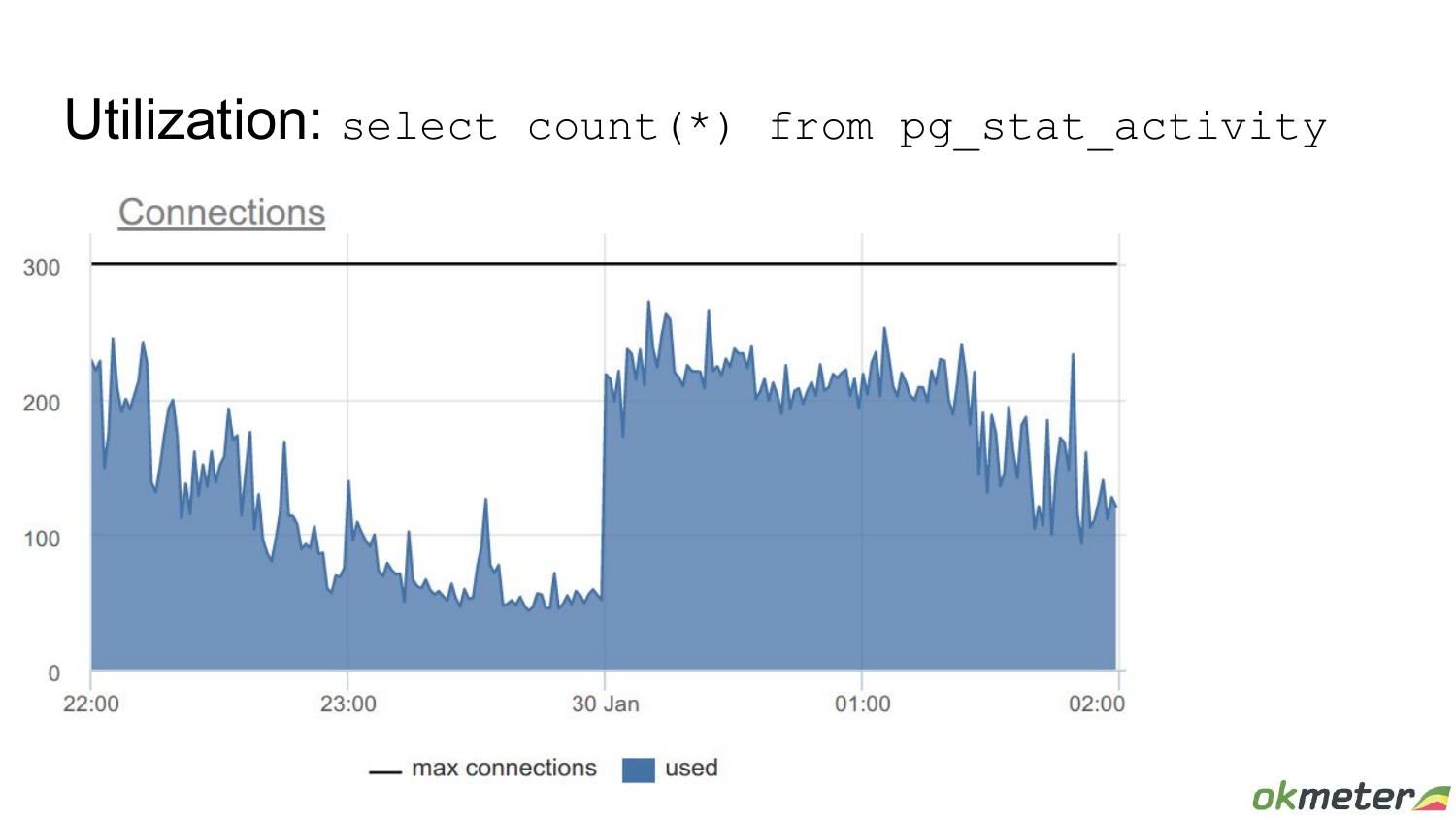
Конкретные бэкенды можно посмотреть в системной вьюхе pg_stat_activity. Вот какая-то картинка. Во времени мы видим, как она меняется. Вот тут ночью большой всплеск. И довольно высокая утилизация: из 300 connection мало остаются свободных. Но в целом нет такого, что в какие-то моменты система занята полностью. Кажется, что тут хоть и не стабильная, но более-менее нормальная ситуация.
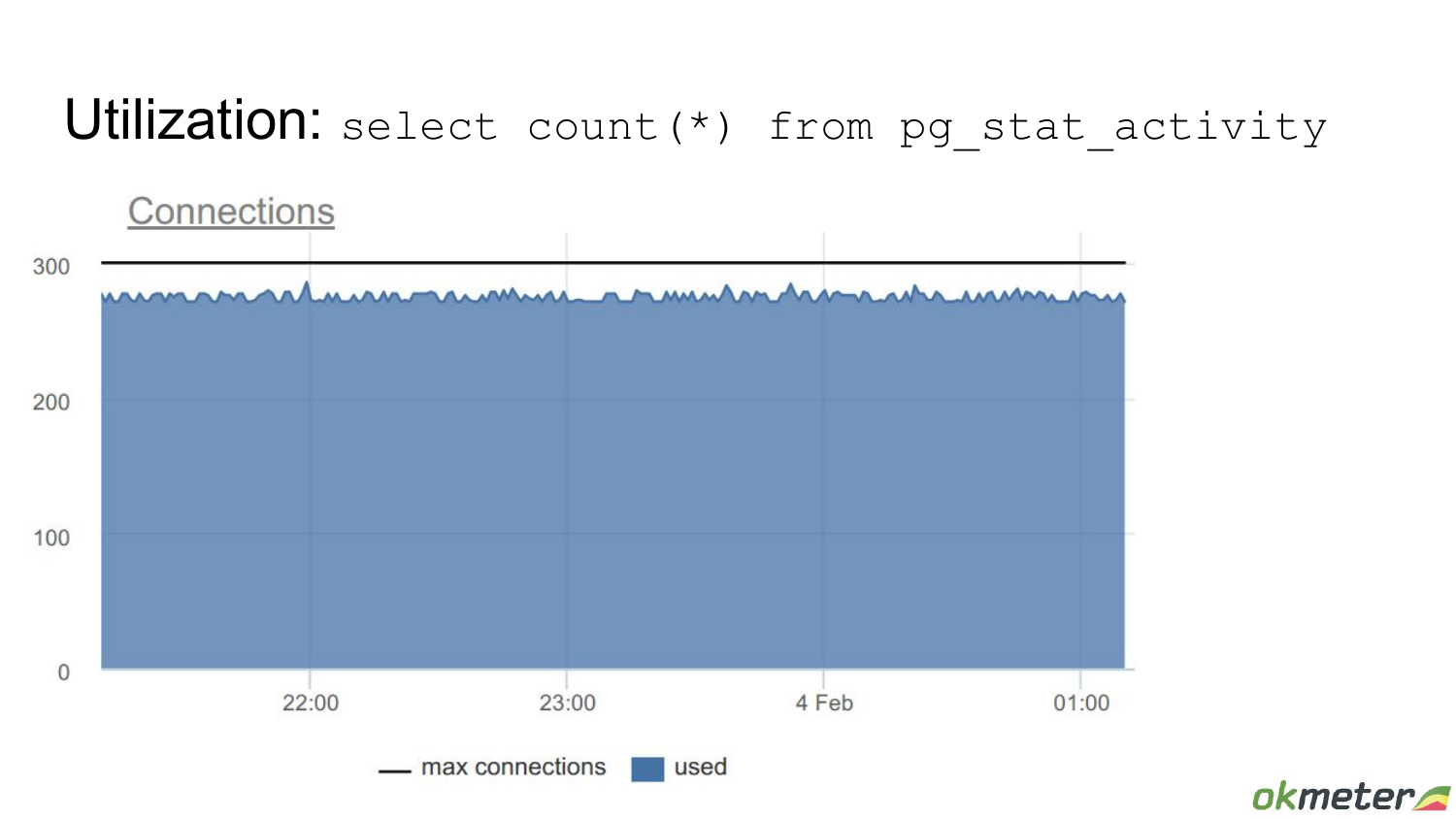
Вот другой пример, когда утилизация высокая. Здесь точный не выведен процент, но понятно, что это высокая утилизация. И если вдруг в систему приходят какие-то дополнительные задачи, которые она должна выполнять, то тут может capacity не хватить, т. е. именно конкретно этого пула бэкендов, который Postgres ограничивает с помощью max connections.
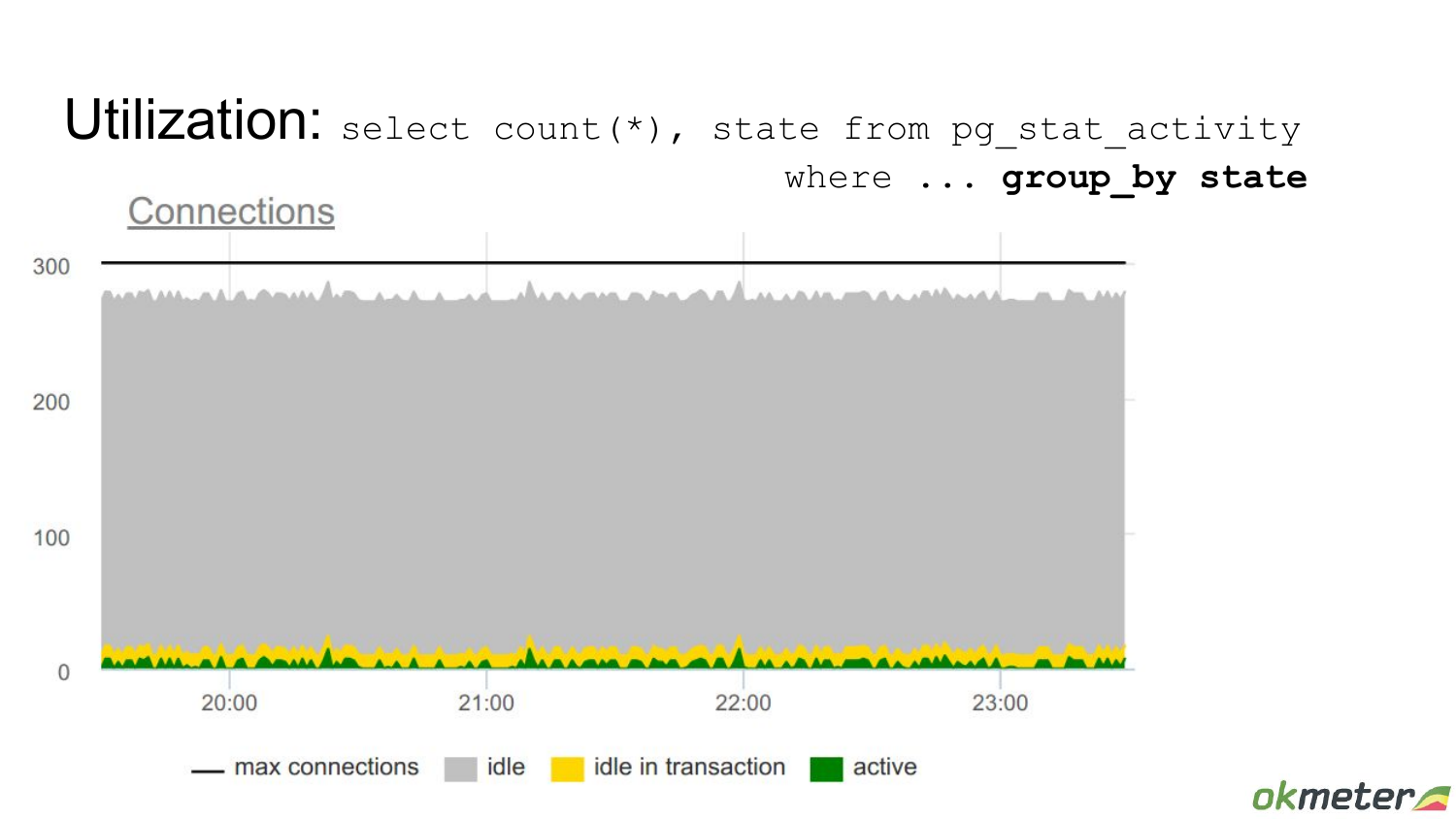
Но если посмотреть этот кейс подробней, если вывести state этого connection, то выясняется, что превалирующая часть этих используемых бэкендов, находится в состоянии idle, т. е. connection простаивает, в нем ничего не выполняется. Есть также какое-то количество idle in transaction. Это значит, что транзакция открыта, но запросы не идут. И есть малое количество active, которые что-то выполняют.

Сразу возникает подозрение, что тут утилизация не одна, а их три. И мы смотрели на одну, но на самом деле это нам не описывает полностью картину. Почему? Потому что эти три утилизации соответствуют трем разным ресурсам. Несмотря на то, что мы рассматриваем это как один какой-то ресурс, на самом деле там три ресурса. Один – это pool connections, другой – это транзакции, которые отрыты и, соответственно, это объем транзакций, который может быть открыт одновременно. И третий – это транзакции, которые выполняются. Там уже будут более детальные какие-то ресурсы: locks конкретных таблиц или что-то такое.
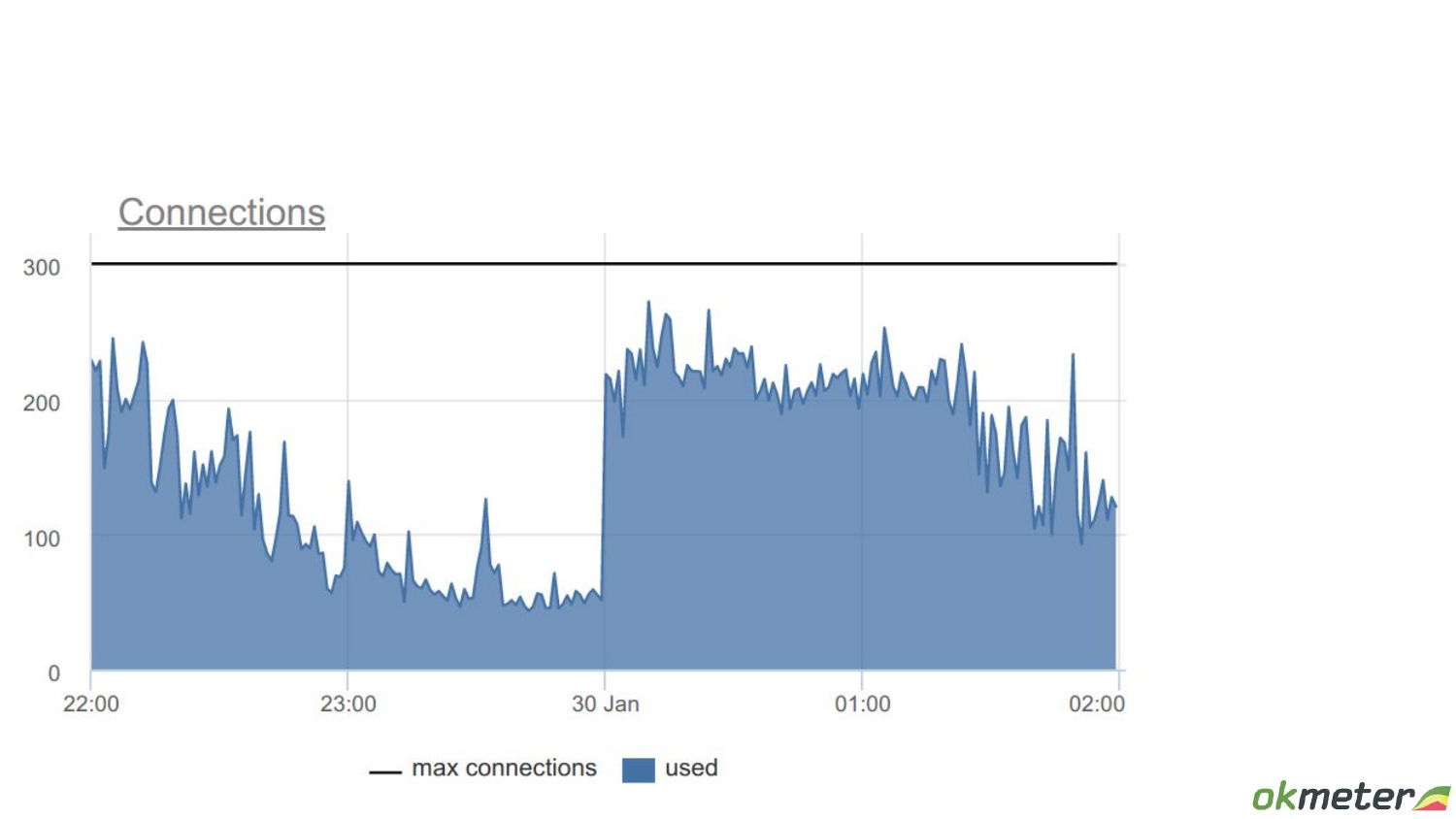
Вернемся к предыдущему примеру, где мы думали, что все лучше, чем в том.
Здесь в каком-то смысле полезную работу выполняют, дай бог, active 5 % connections. А утилизацию мы рапортовали как 95 % до этого. Здесь ситуация вот такая. Мы думаем, что она лучше.
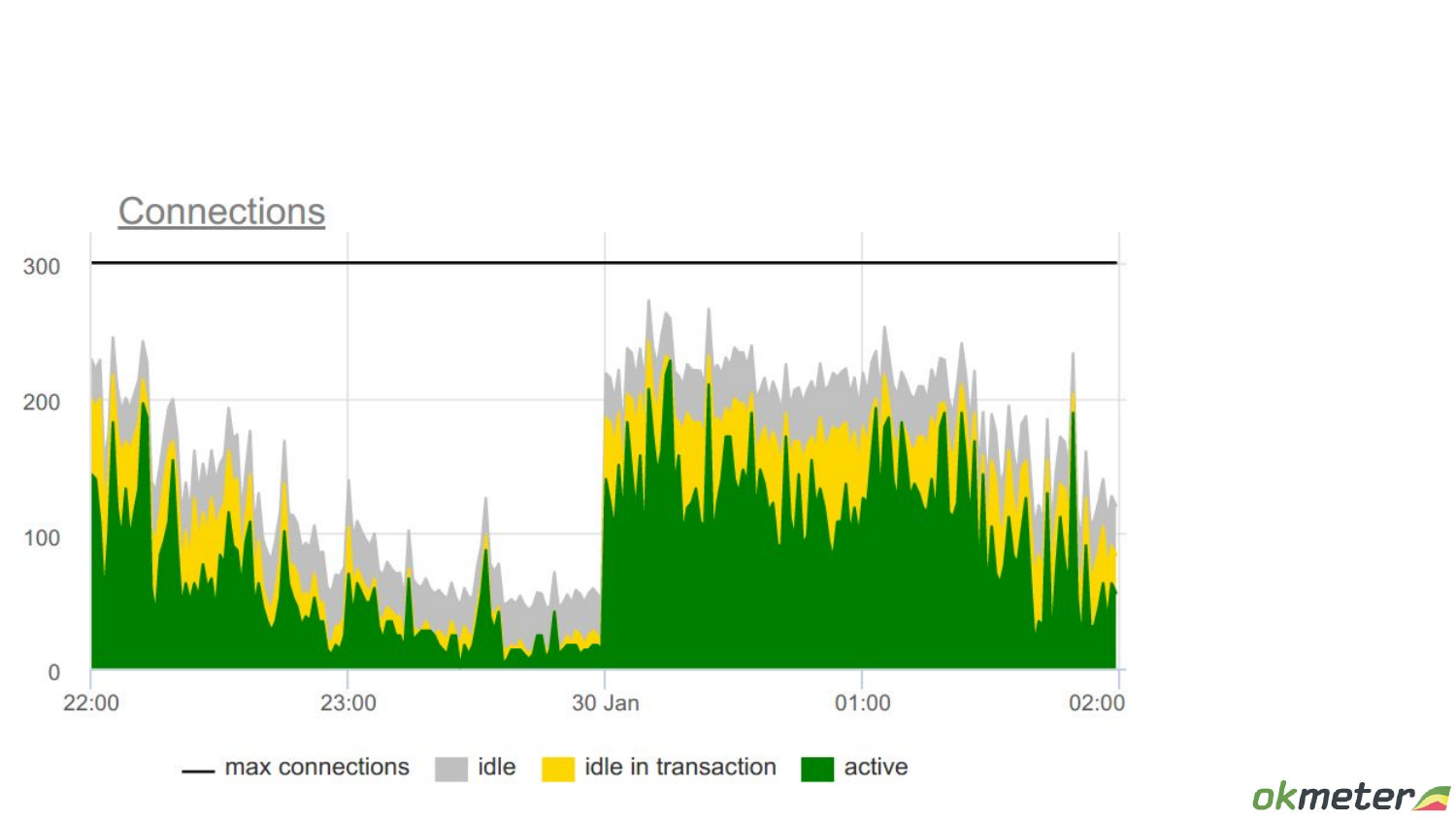
Но посмотрим, что у нее внутри. И получается, что полезной работы здесь connections выполняют много.
Что еще здесь хочется сказать?
Мы рассматривали, что вот здесь высокая утилизация. Но что значит высокая? Вот эти в данном случае 100 connections, которые max connections лимит, это вообще произвольное значение setting’а, которые мы установили для этой базы. Оно могло быть в два раза меньше, могло быть в два раза больше. И сразу у нас утилизация становится либо маленькой, либо 100 %. Соответственно, этот пул – это искусственное ограничение. И где-то мы ограничением можем управлять. Это зависит от того, какая часть системы нам подвластна. Где-то мы можем управлять этим ограничением, где-то мы этим ограничением управлять не можем.

Зачем вообще нужна saturation, ведь по высокому util уже и так все понятно? Saturation вводится для ситуации, когда utilization 100 % и работа откладывается в очередь. Зачем мерить ее, если и так уже понятно, что работа стала в очередь, потому что utilization близко к 100? Это значит, что работа встает в очередь.
Ситуация такая, что вы смотрите топ и видите, что CPU usage невысокий, но тем не менее load avarage очень высокий. Это типичный пример ситуации, когда утилизация не 100 %, а saturation высокий. Load avarage — это мера saturation, в каком-то смысле опосредованная. Она мерит все runnable процессы, т. е. те, которые готовы исполняться на процессоре, но процессор занят, и они стоят в очереди в планировщике.
И при этом мы видим, что CPU usage невысокий. Как такое происходит? Могут одновременно проснуться много процессов и хотеть исполниться. И в этот конкретный момент очень много стоят в load avarage. Load avarage оконным способом сглажен, поэтому он показывает вам немножко эту ситуацию назад. Но если мы этот топ смотрим раз в секунду, то внутри этой секунды процессор мог действительно какую-то значимую часть времени ничего не выполнять. А тем не менее процессы стоят и ждут. И с точки зрения response системы у нас ухудшается производительность.
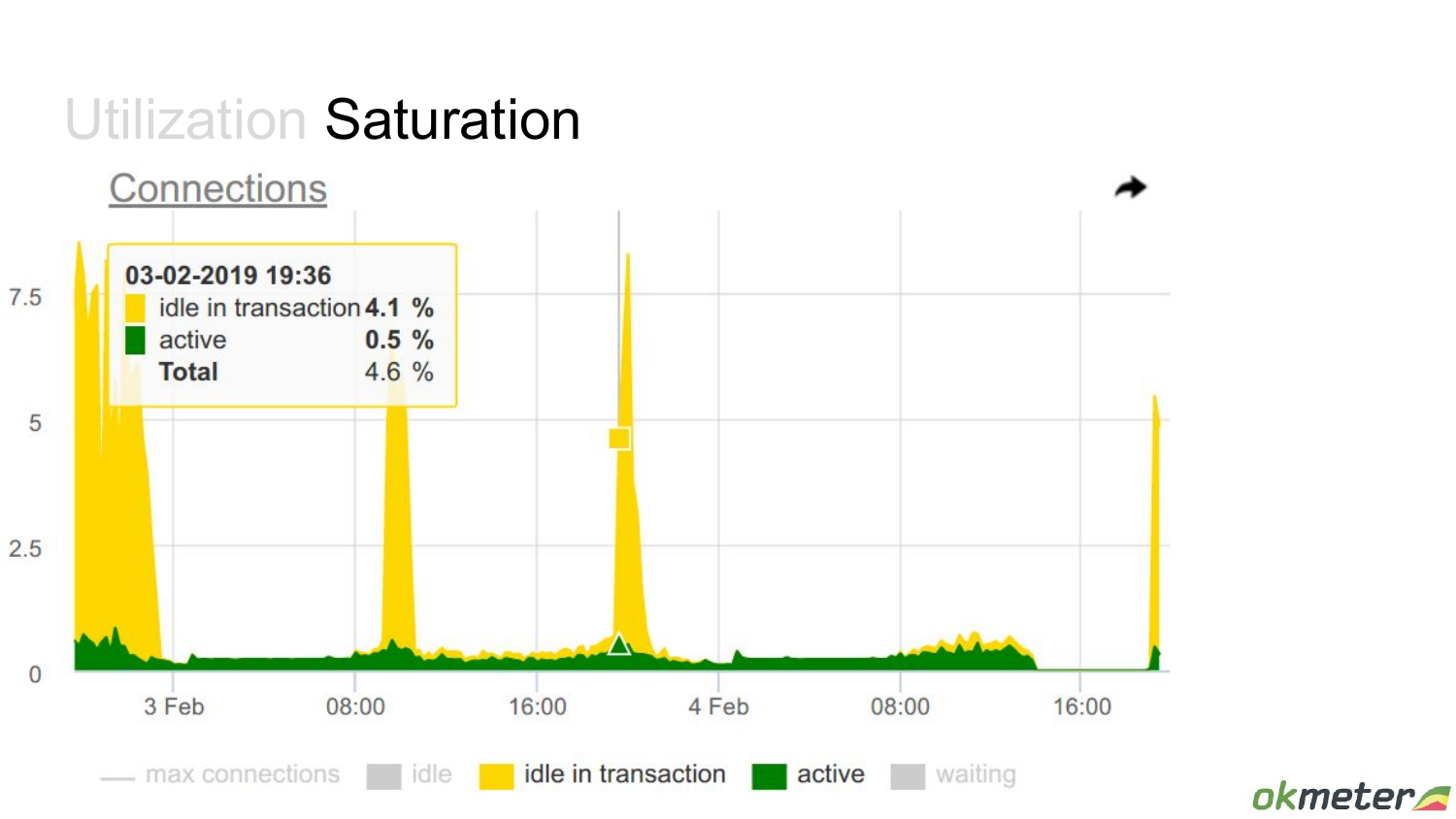
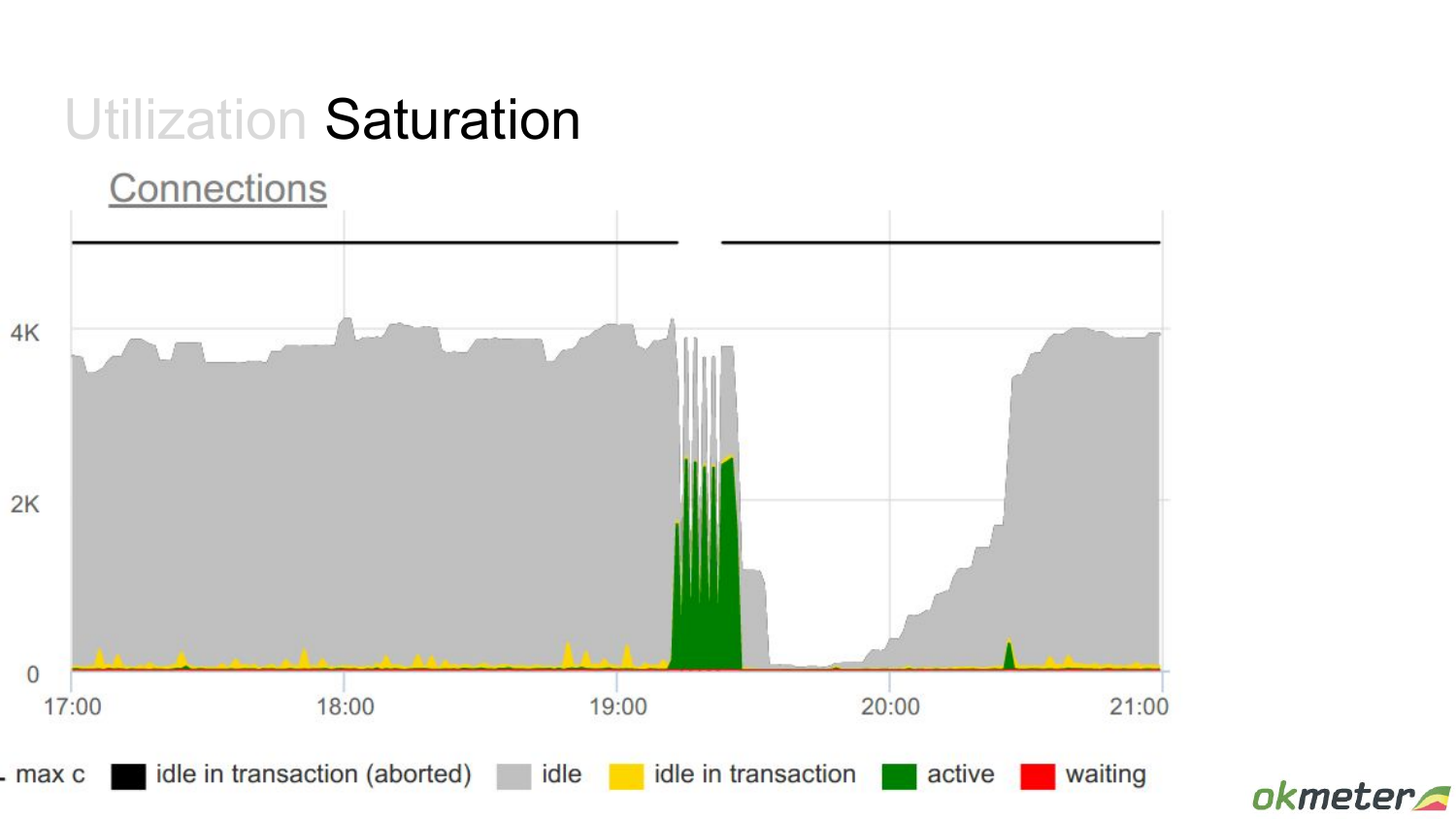
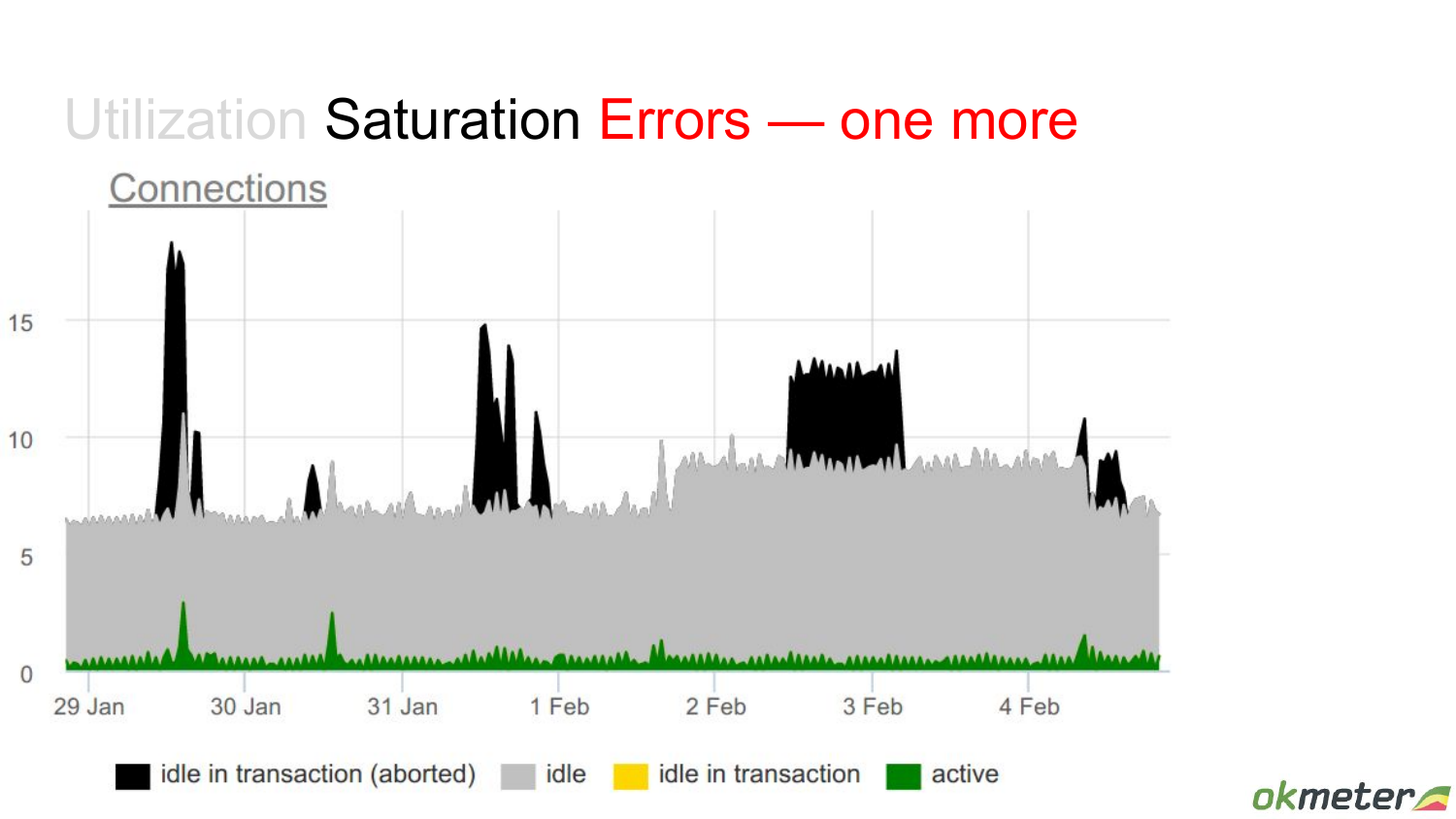
Еще один такой пример. Здесь уже какие-то выбросы есть – idle in transaction.
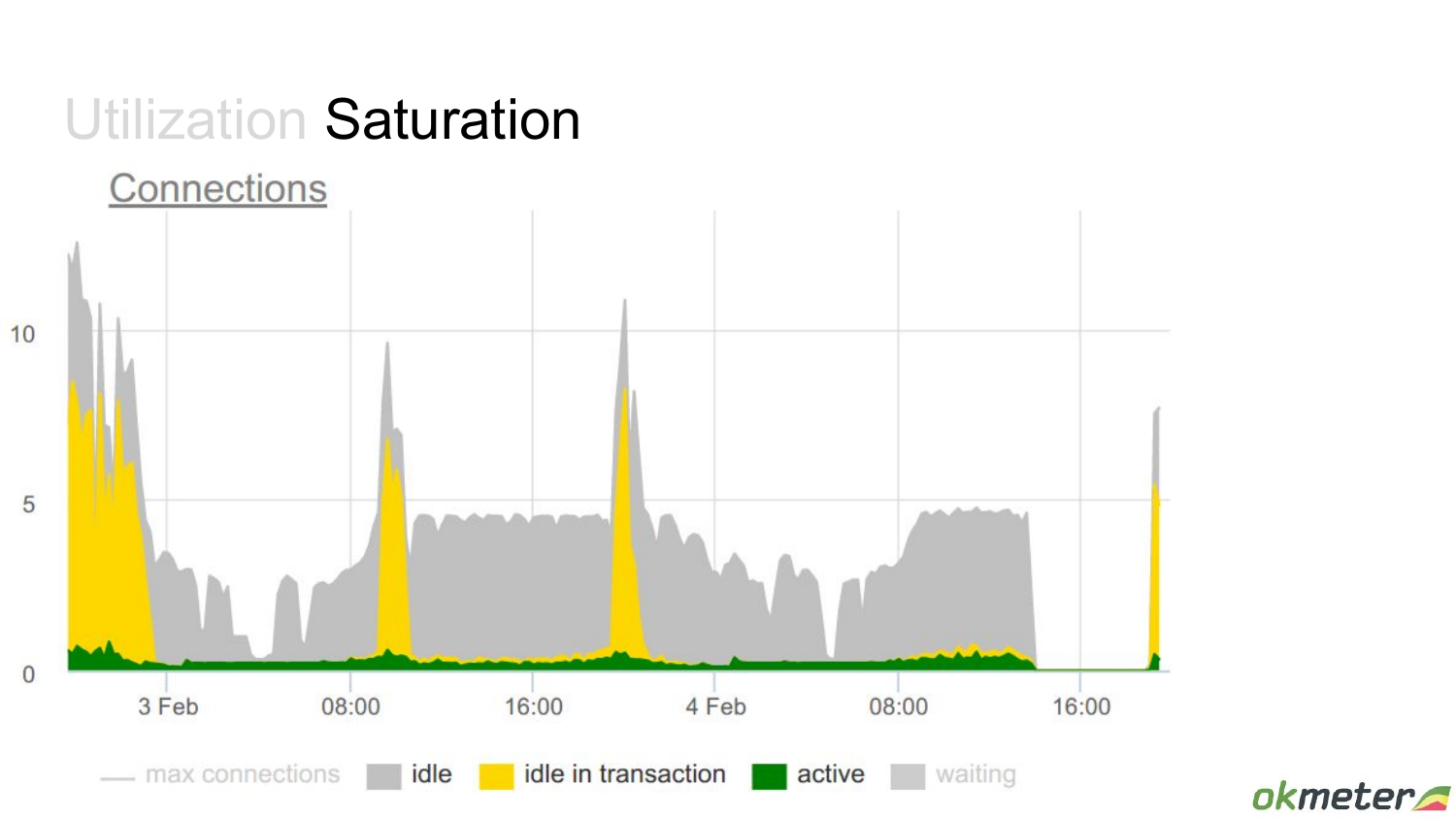
Т. е. у нас есть какие-то моменты, когда много вдруг транзакций открывается. Это я хотел привести пример как saturation переходит в ошибки.
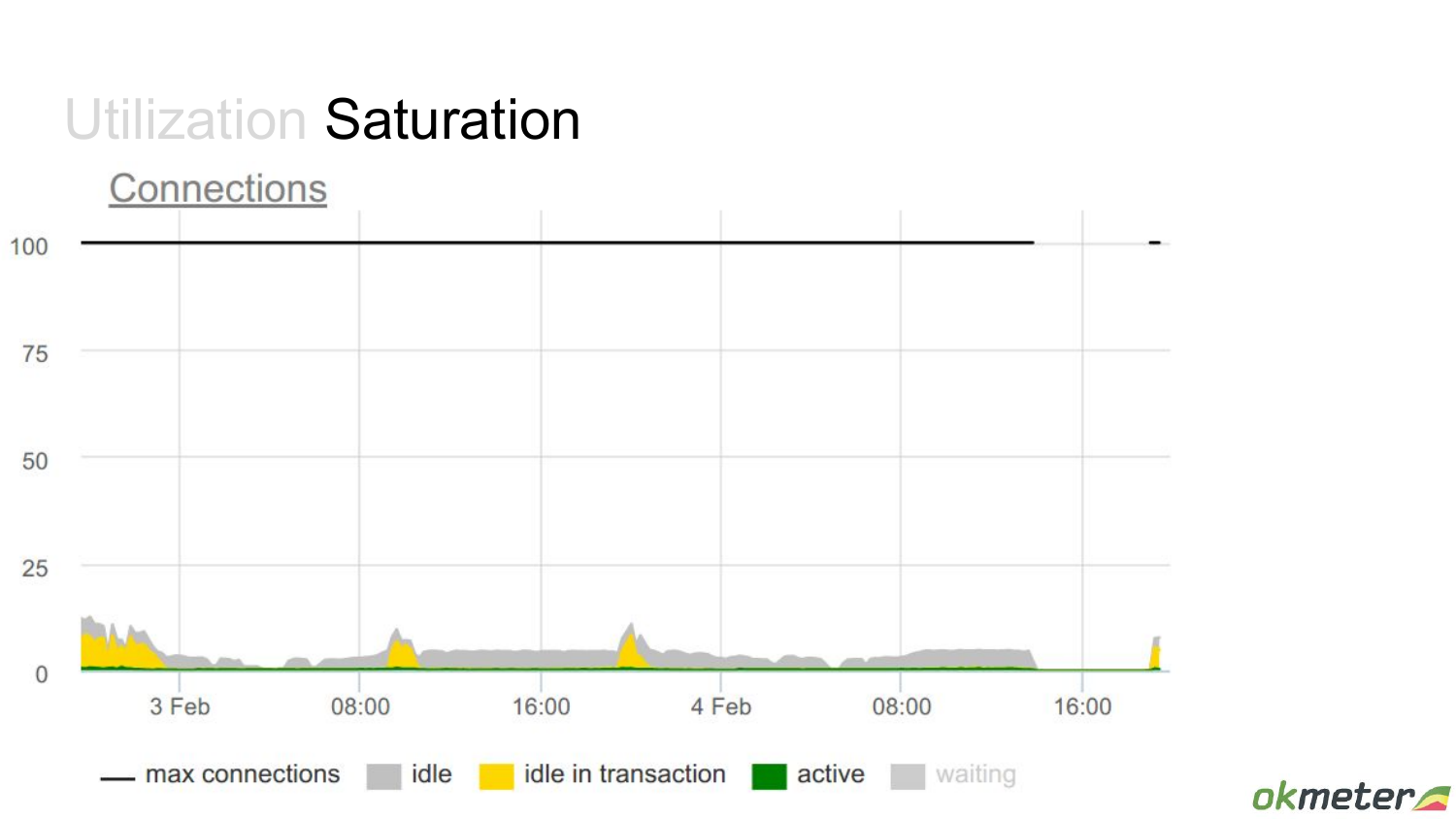
Здесь мы еще добавили на график idle. Добавим на график max connections, чтобы видеть в относительном масштабе все. И кажется, что здесь вообще проблемы никакой нет. Только дырка справа есть почему-то.
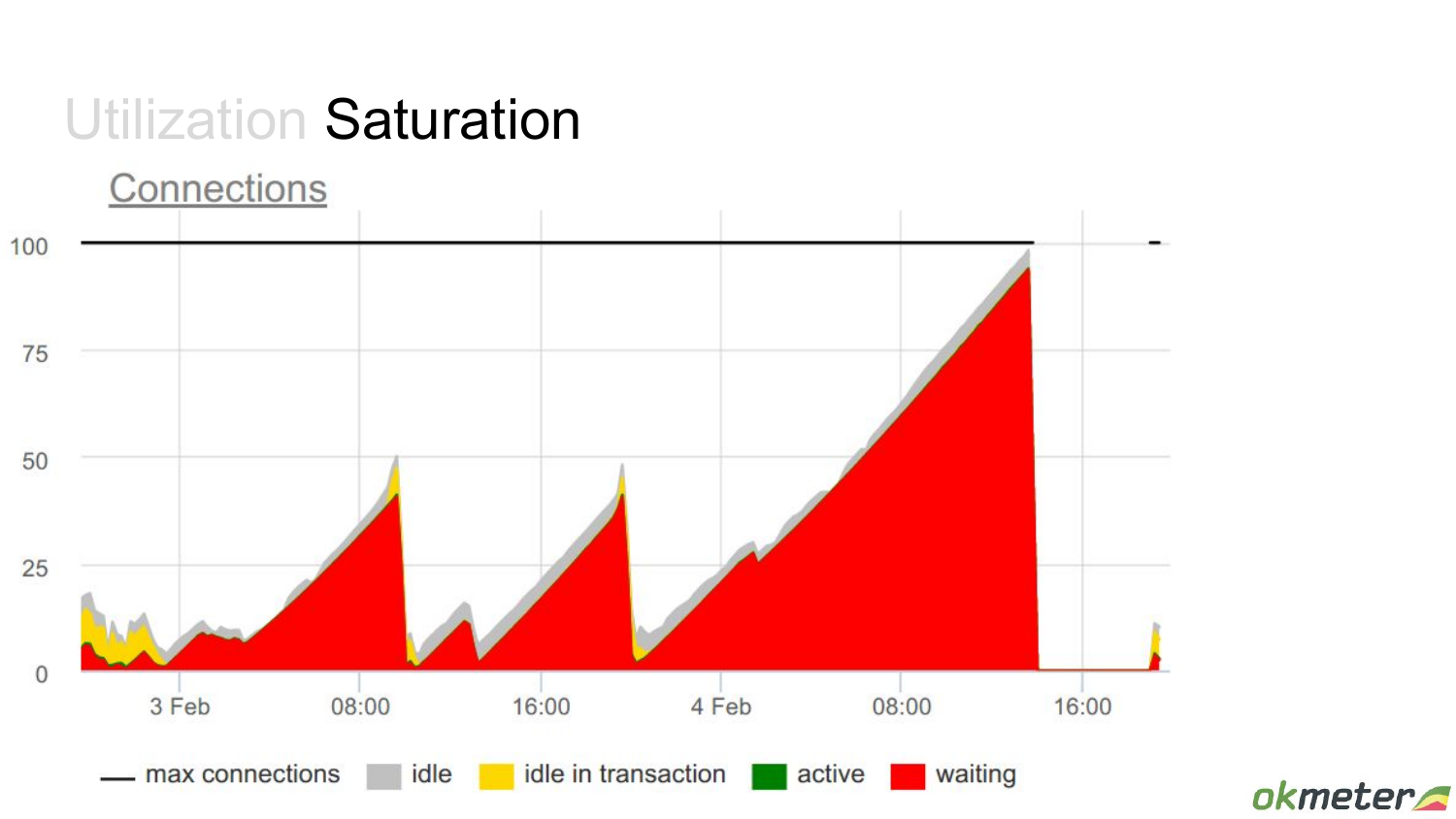
Но на самом деле я вас тут обманываю, потому что все в select’е из pg_stat_activity я не взял connections, который waiting был try. Т. е. они на самом деле в active state, они выполняют какие-то запросы, но ожидают чего-то. Они в состоянии waiting.
И здесь сразу другое понимание ситуации возникает, если это вывести. И вот у нас доросла utilization этого connection pool до 100 %.
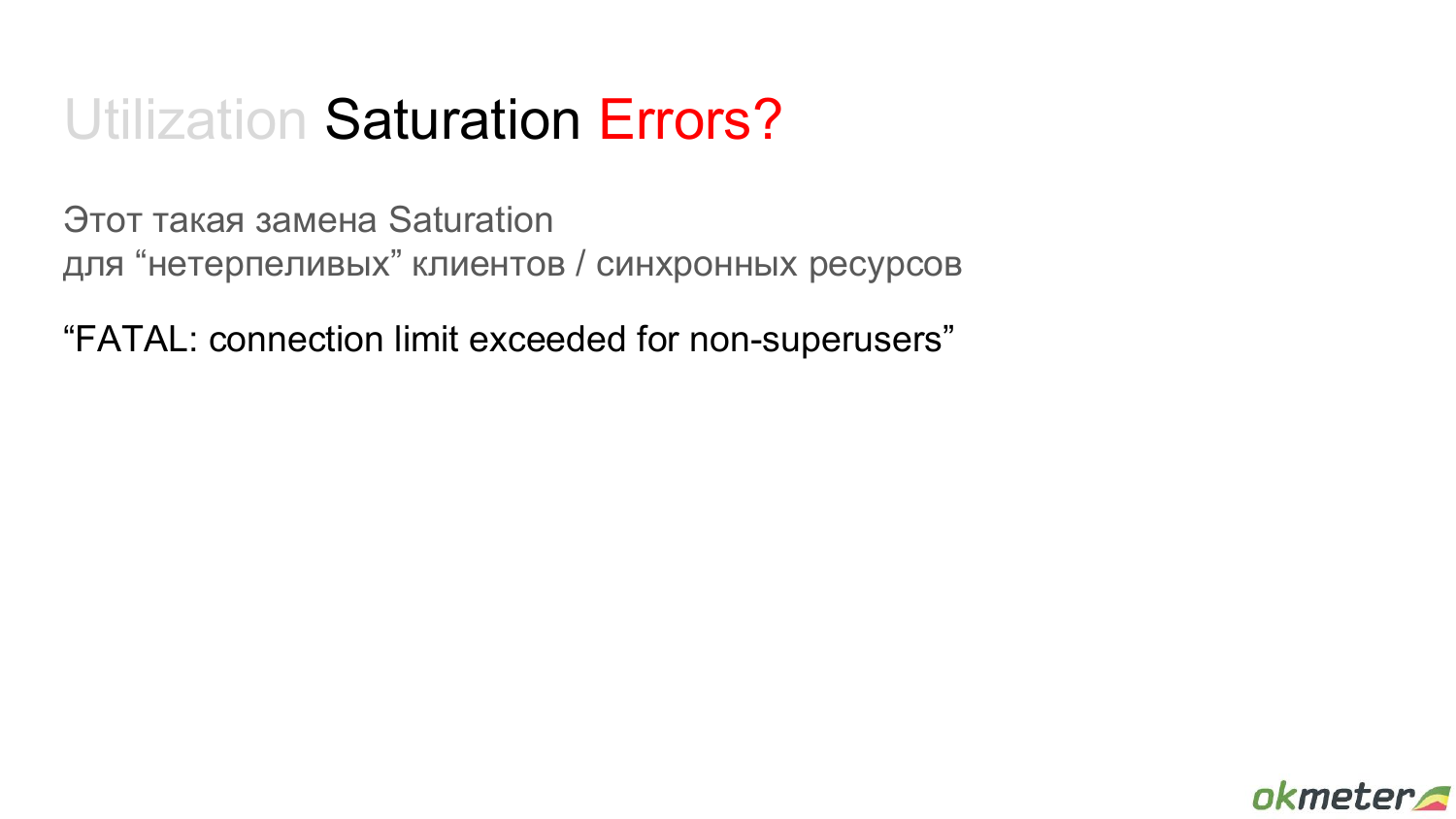
И после этого мониторинг перестал работать, потому что он не может ничего от базы получить.
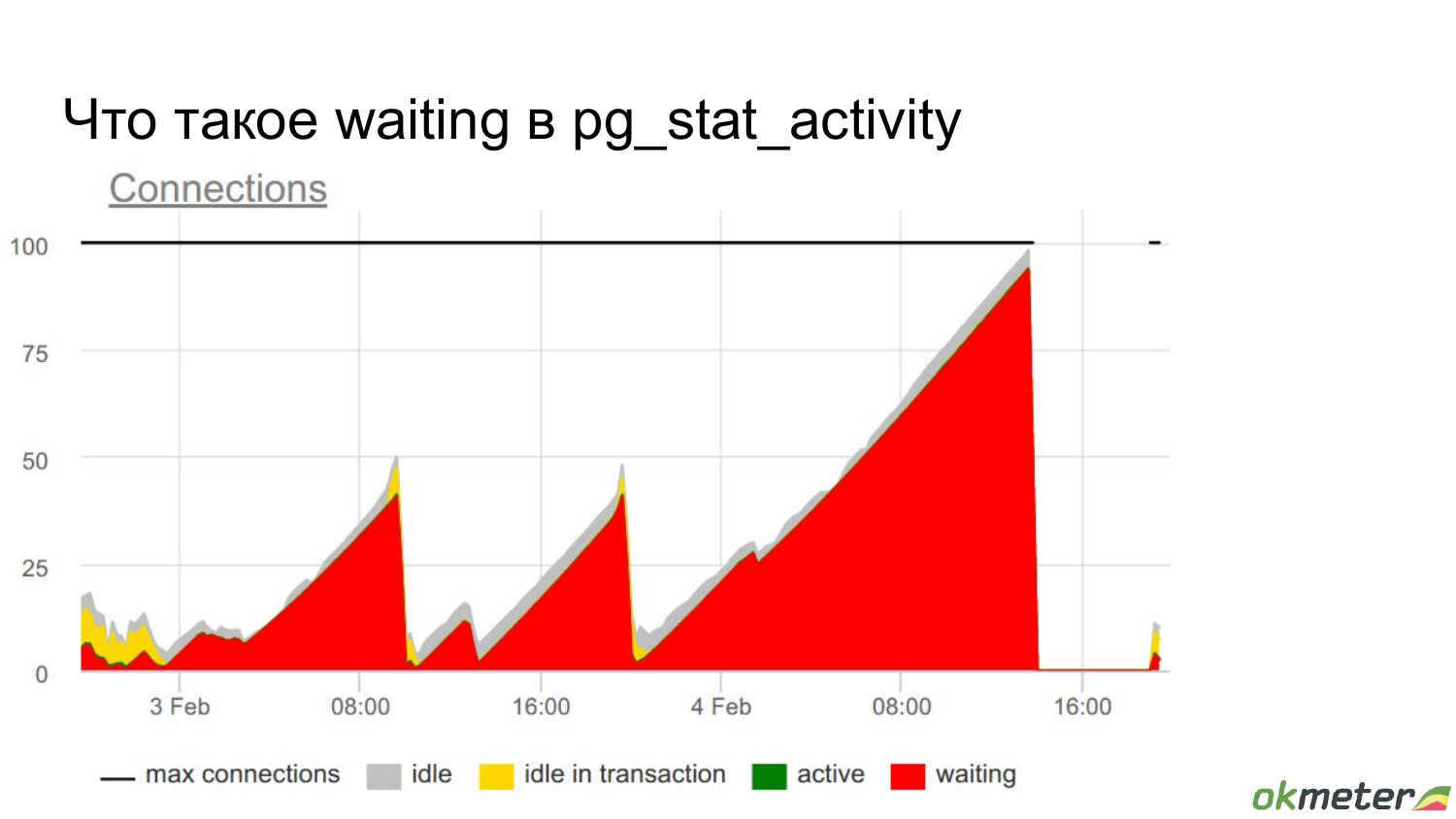
Что такое waiting на самом деле? На самом деле здесь высокая утилизация ресурса этого. Она связана с тем, что где-то произошел saturation внутри, т. е. во всем этом stack Postgres, который мы рассматривали, где-то внутри уперлась в какой-то лимит. Но это довольно просто.
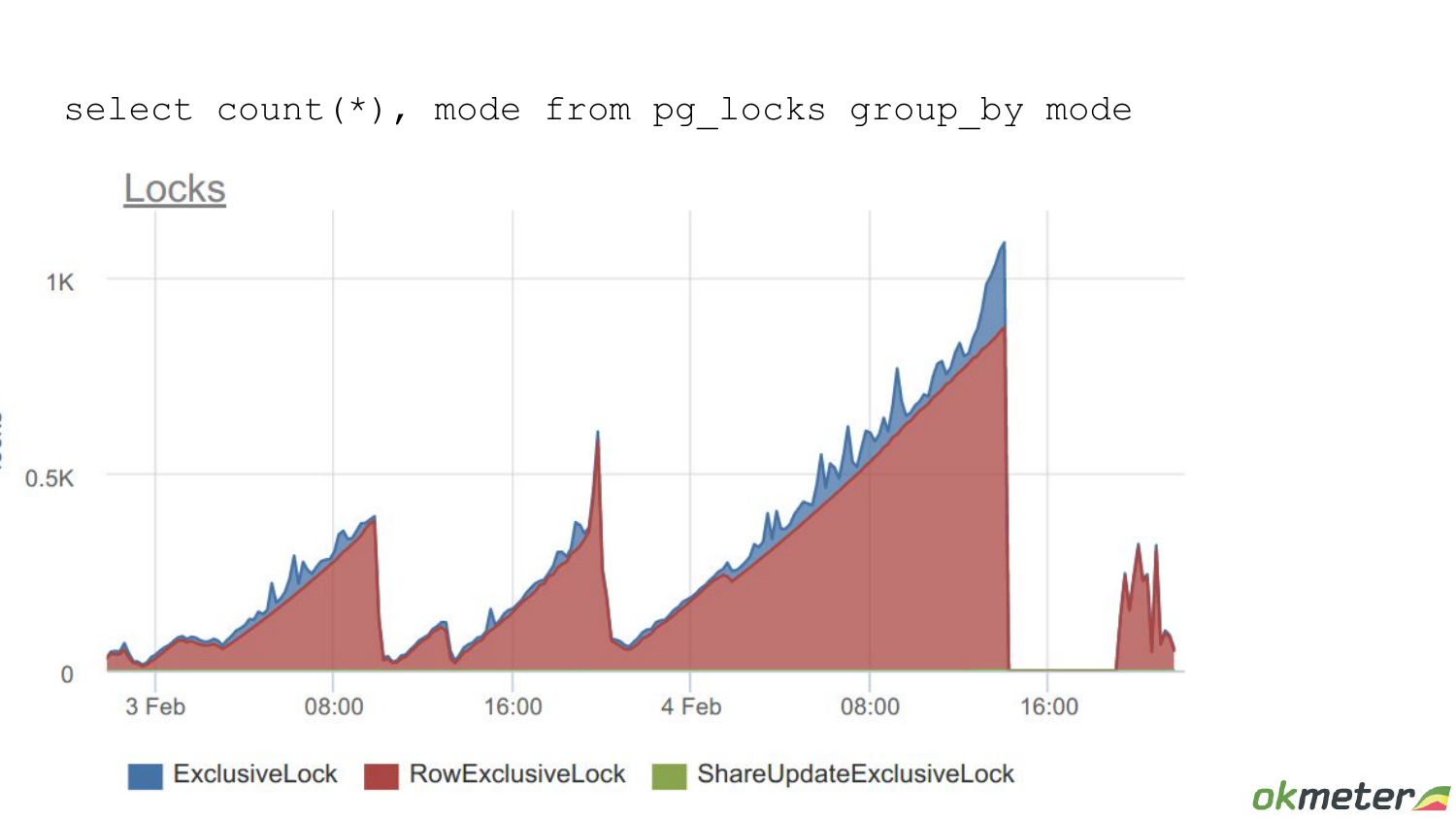
В данном случае – это locks. Один запрос ожидает, когда другой освободит ему lock. Мы видим, что locks росли-росли и, соответственно, connections. Бэкенды росли, которые ожидают этих locks.
И все застопорилось. Т. е. на самом деле какой-то lock был утилизирован полностью, он был занят.
И с одной стороны lock – это space ресурс, у которого утилизацию надо мерить – он занят или он свободен. С другой стороны, нужно смотреть на время, которое этот конкретный lock бывает занят. И, соответственно, connections, которые ожидают этих locks, — это мера saturation уже конкретного lock.
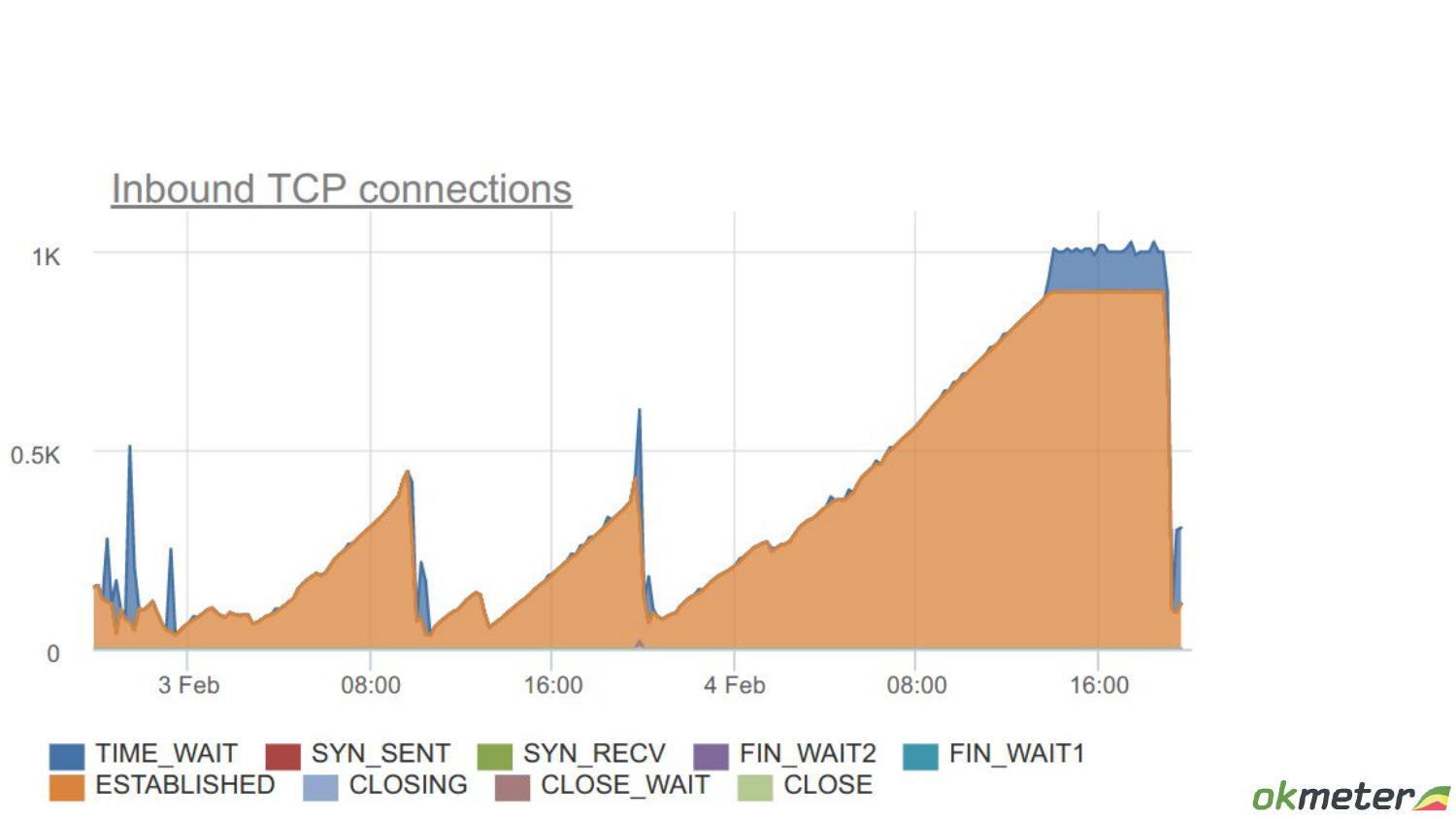
Прежде чем Postgres создаст процесс бэкенда, этот connection должен от клиента прийти. В данном случае рассматриваем TCP-соединение. И он устанавливает TCP-соединение. Post master его принимает. И только потом создает бэкенд или решает, что все, мы больше не создаем, мы всех отправляем и говорим им «reset». И они в time wait сваливаются.
Почему это важно? Потому что мы думаем, что connections у нас ограничены вот этим.
Но connections у нас ограничены одновременно много чем.
Сейчас я еще объясню, чем еще этот connection pool ограничен. С одной стороны, он слотовый, но, с другой стороны, временной. Что мы здесь видим? В какой-то момент было много активно работающих клиентов. Но чем эта ситуация принципиально отличается от других? Вот здесь провал какой-то, про который мы сейчас поговорим. На самом деле здесь лимит connections стоит 5 000. Это очень много бэкендов на этом Postgres сконфигурировано. Что здесь происходит? Здесь в какой-то момент были дропнуты все connections. И, соответственно, они потом клиентами восстанавливались заново.
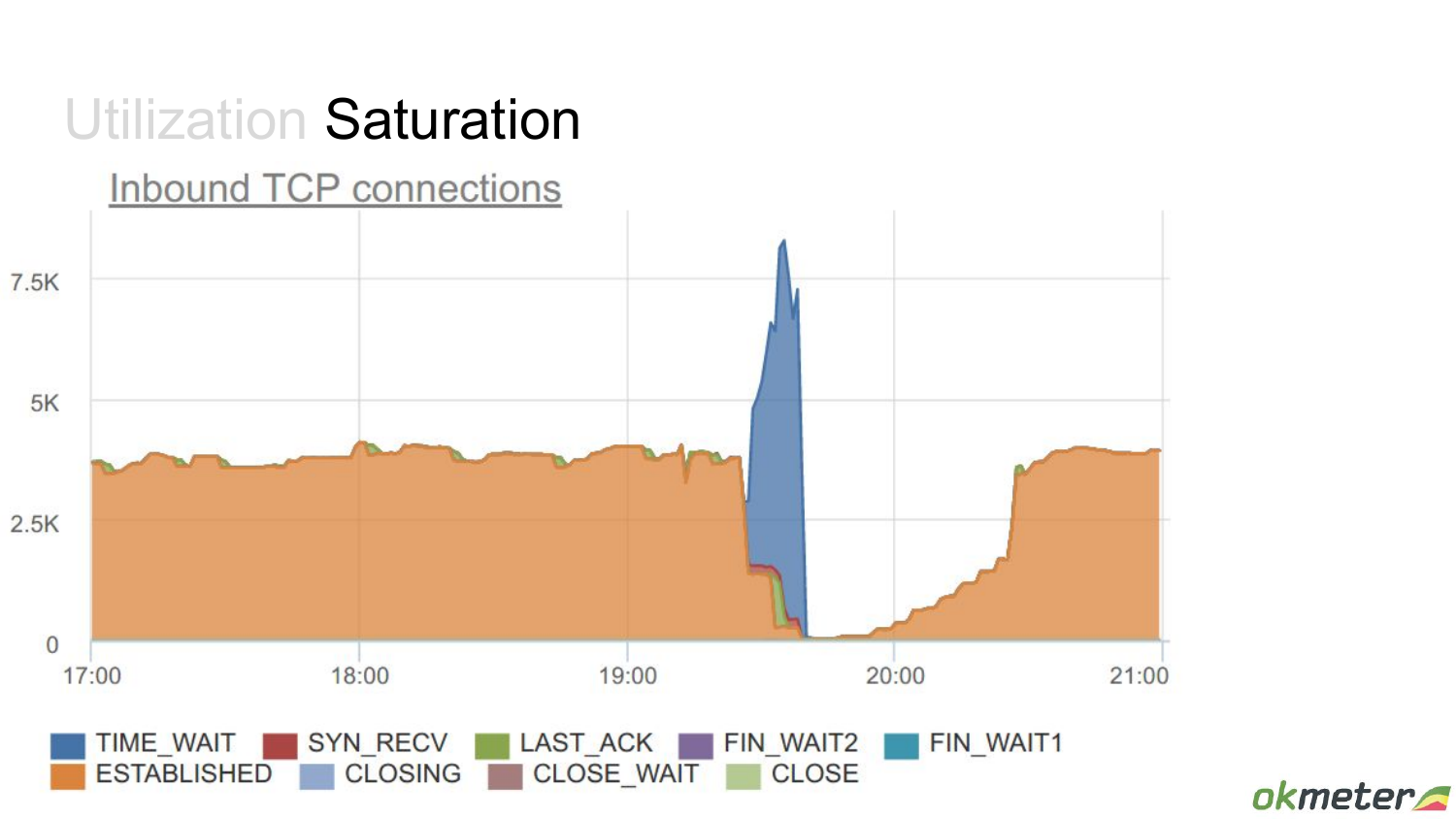
С точки зрения TCP это выглядит так. Все они ушли в time wait, а потом клиенты, которые хотят все-таки в Postgres что-то делать, они наоткрывали эти соединения.
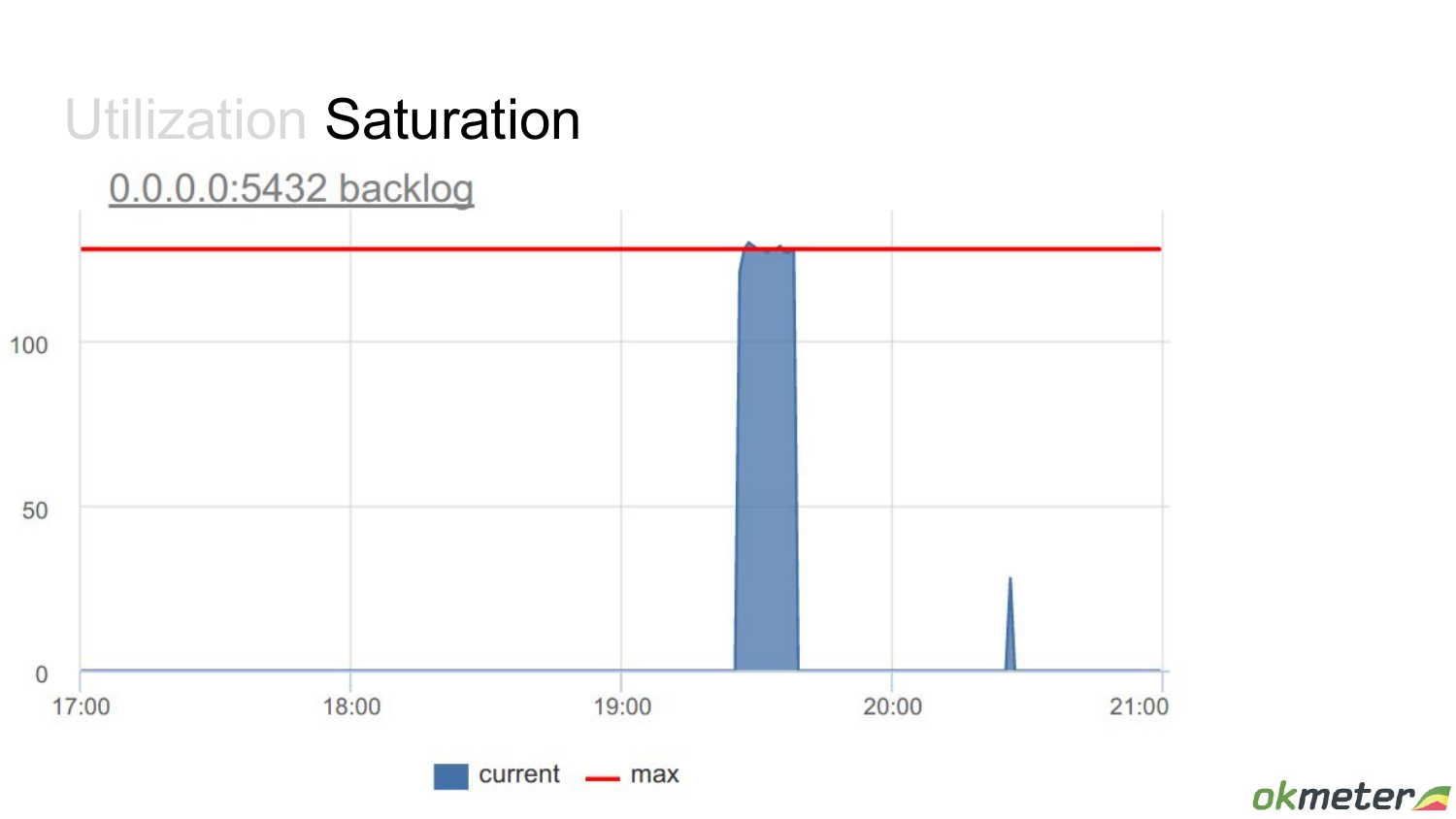
Но что происходит еще раньше в операционной системе, когда приходит connect? Если postmaster не успевает принимать достаточно быстро, то connections помещаются в backlog list сокета. И мы видим в тот момент, когда там был search, backlog этого конкретного сокета занят на 100. Он тоже имеет ограниченные размеры. Это тоже ресурс и он занят на 100 %. И для того ресурса – это показатель того, что здесь кто-то стоит в очереди – это метрика saturation. А здесь – это метрика утилизации бэкенд процесса.
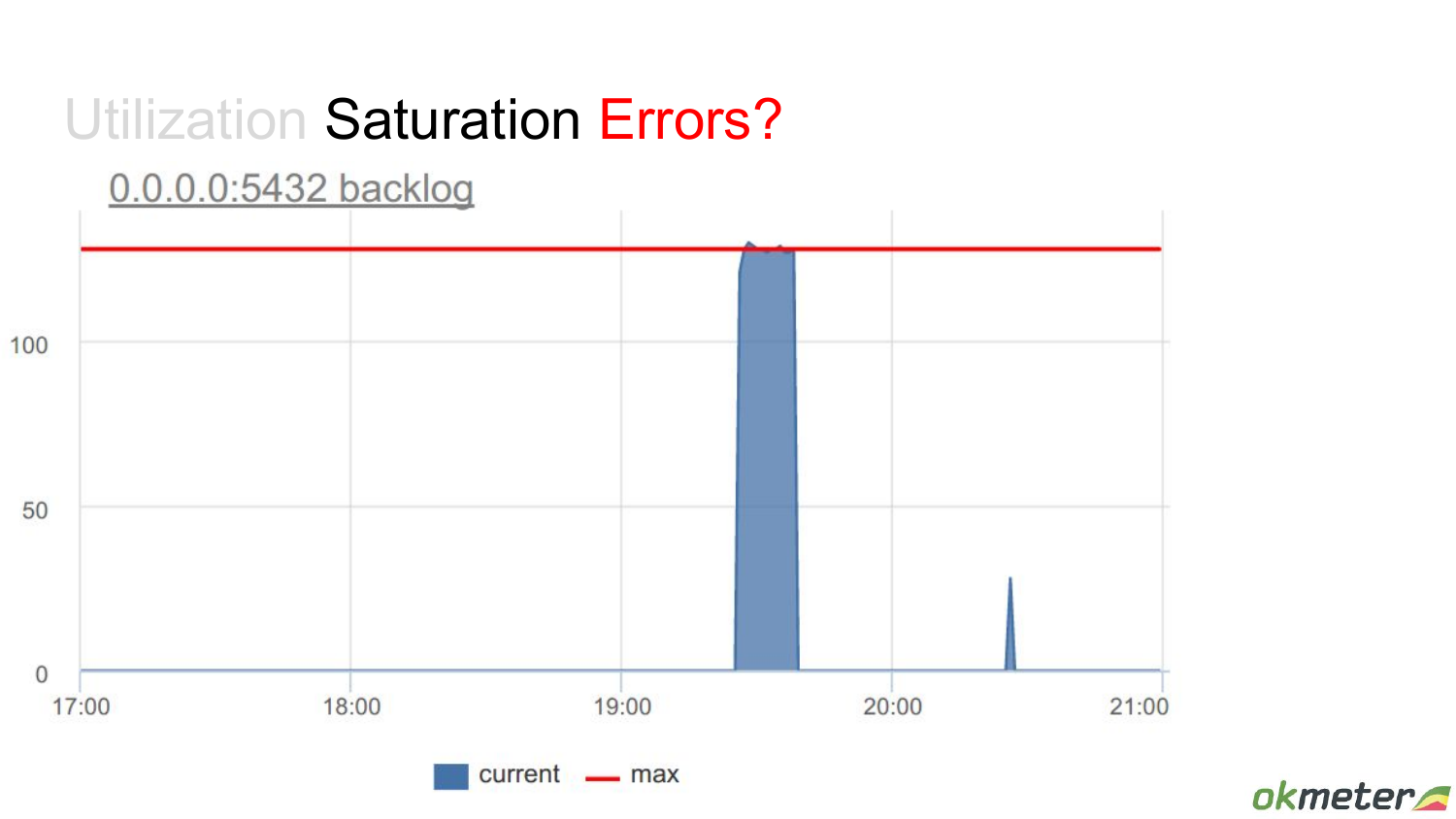
И тем, кто в этот backlog не встал, им система отправила reset.
Это значит, что на клиентском уровне это вообще ошибка. Клиент пытается к Postgres подключиться, а ему на уровне TCP говорят «извините».

Зачем нужен RED, если есть USE? Вы можете быть DBA, вы можете быть, серверный админ инфраструктурный, вы можете быть, разработчик или что-то среднее из этого. Предыдущее все годилось для оценки производительности и улучшения ее, если вы можете менять что-то с базой данной. Но зачастую вы используете какую-то базу данных, которую вам поставляет другой отдел. И вам подконтрольны только запросы. И вас только парит то, насколько быстро Postgres отвечает на эти запросы.

Тогда вам лучше подойдет методология RED, которая говорит, что для каждого сервиса, который обслуживает запросы, нужно мониторить:
- сколько было этих запросов,
- сколько было этих ошибок,
- и распределение времен ответов в соответствующих запросов.
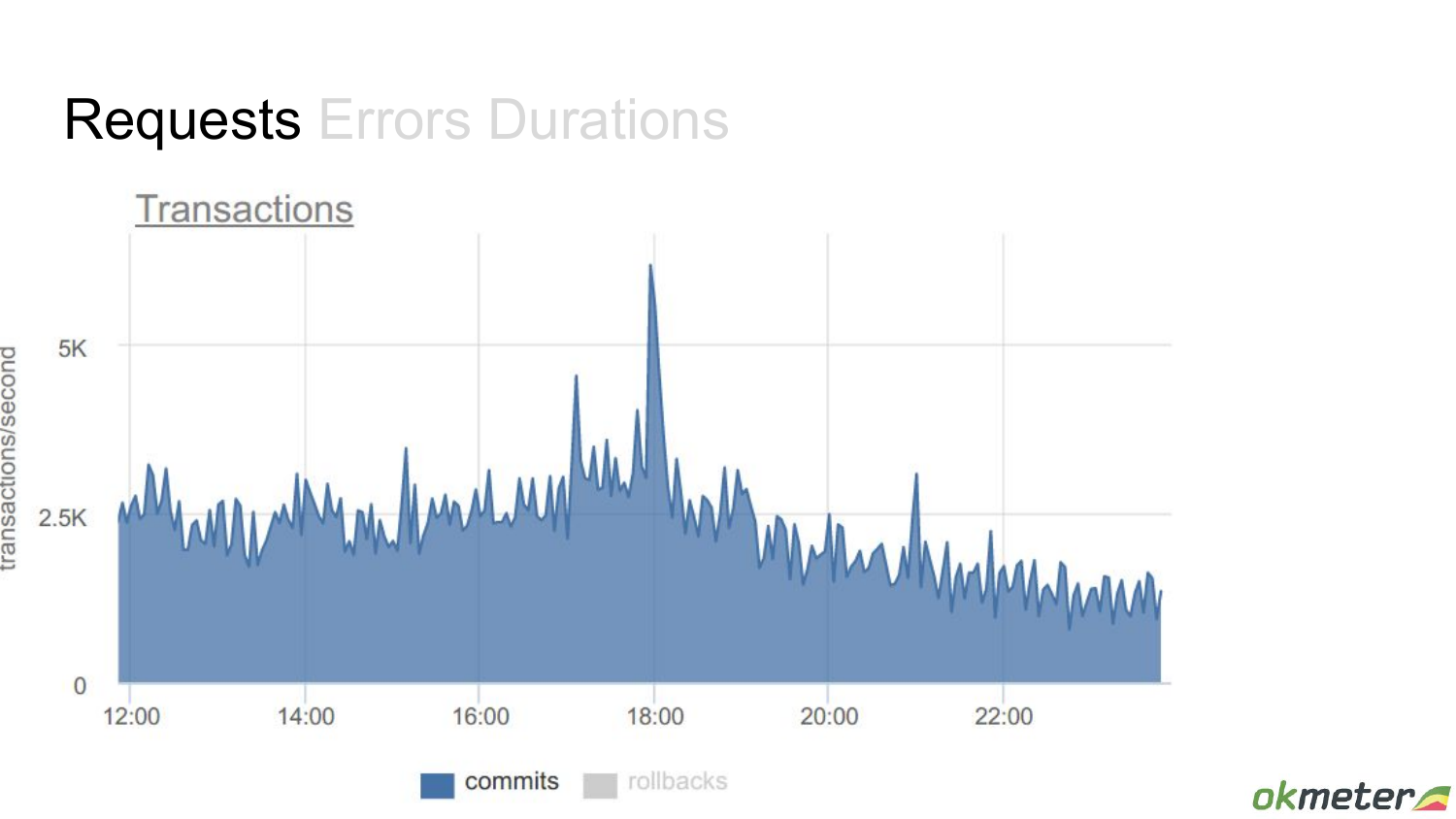
Соответствующий пример для Postgres. Например, запросами могут быть транзакции. Вот они приходят, потом они закрываются или что-то такое. Здесь мы видим стабильную картину. Где-то к концу дня все улеглось, поменьше транзакций стало.
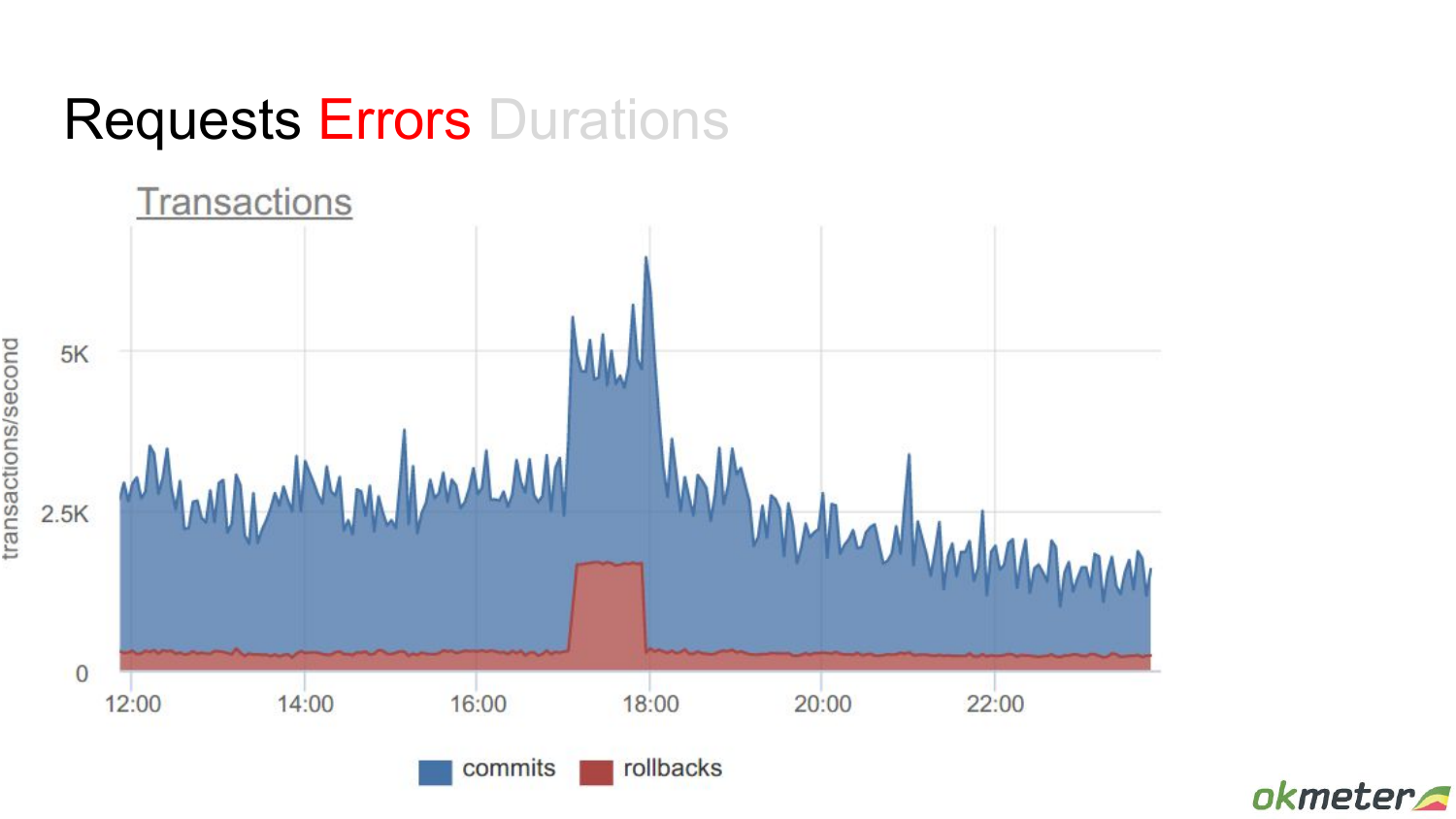
Если посмотрим на rollbacks, то вот этот пик, который был в 6 часов, он становится более понятным, потому что часть транзакций откатывались, потом все заработало и, соответственно, был search в этих транзакциях, т. е. пик, который какое-то количество клиентов создали.
 Надо понимать, что в RED есть два типа ошибок. Есть клиентские ошибки, а есть серверные ошибки. Почему я про это говорю? Потому что можно замониторить только одну сторону, а про другую забыть. И вы будете думать, что видите все ошибки, но на самом деле серверные ошибки вы не видите. Эти ошибки влияют на производительность системы, но вы упускаете их из виду.
Надо понимать, что в RED есть два типа ошибок. Есть клиентские ошибки, а есть серверные ошибки. Почему я про это говорю? Потому что можно замониторить только одну сторону, а про другую забыть. И вы будете думать, что видите все ошибки, но на самом деле серверные ошибки вы не видите. Эти ошибки влияют на производительность системы, но вы упускаете их из виду.
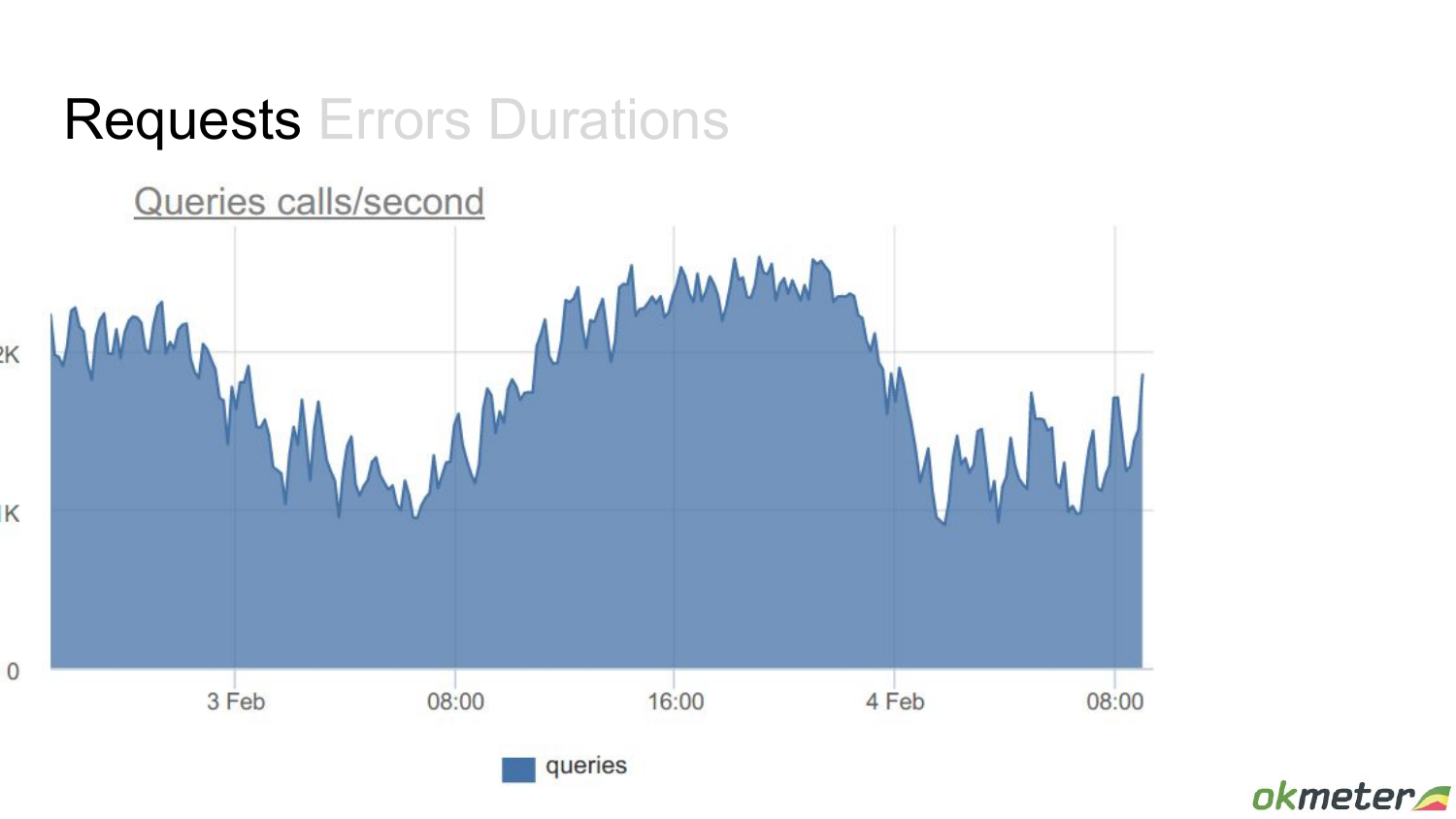
Посмотрим на queries внутри транзакции. Какая-то стабильная картина в каком-то смысле. В 8 часов начинает расти нагрузка, к ночи она заканчивается.
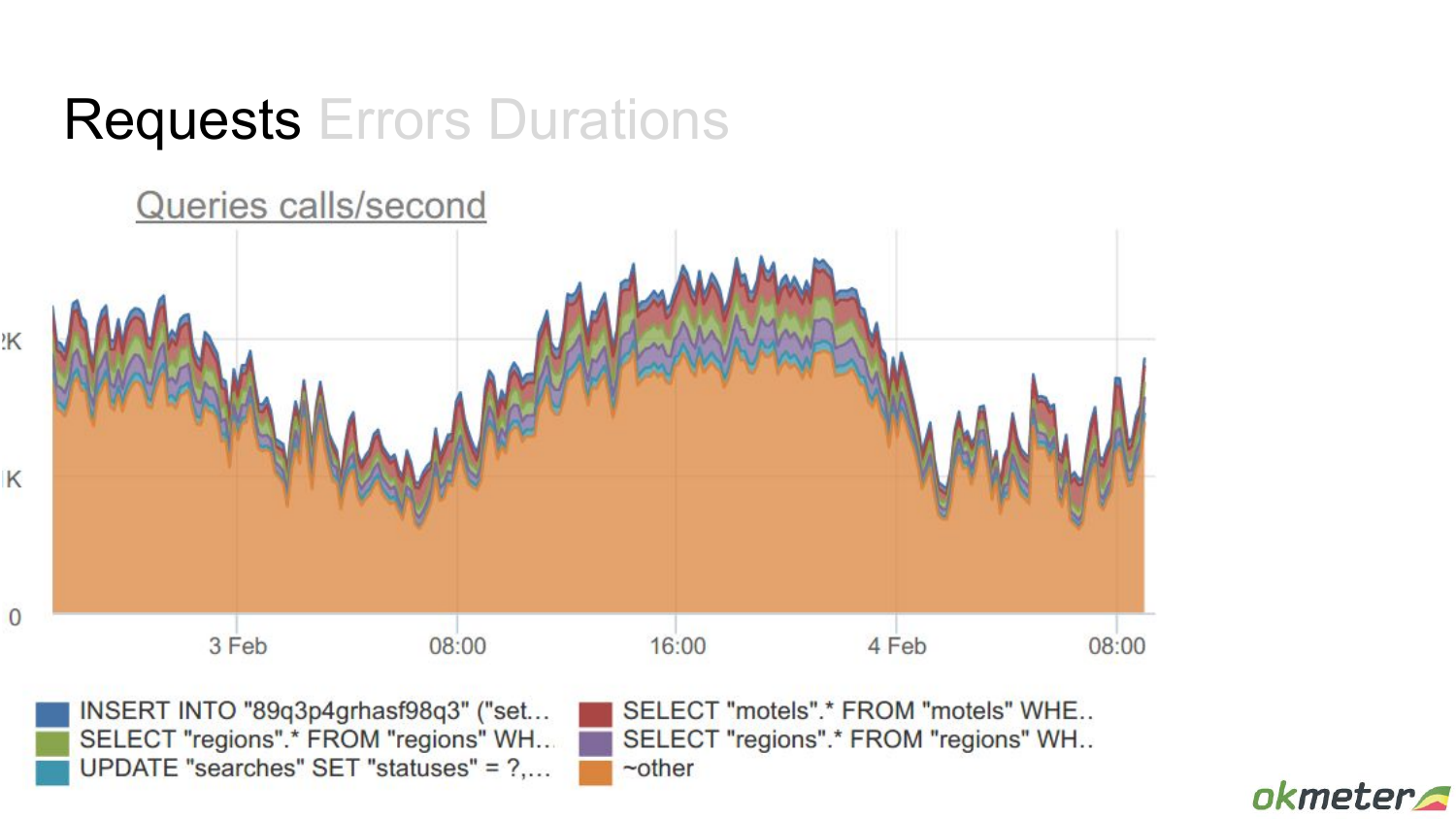
Если посмотреть эти приходящие запросы в разбивке конкретных видах запросов, то какая-то более детальная картина возникает. Но в данном случае вроде бы все стабильно. В целом select как идет, так и идет.
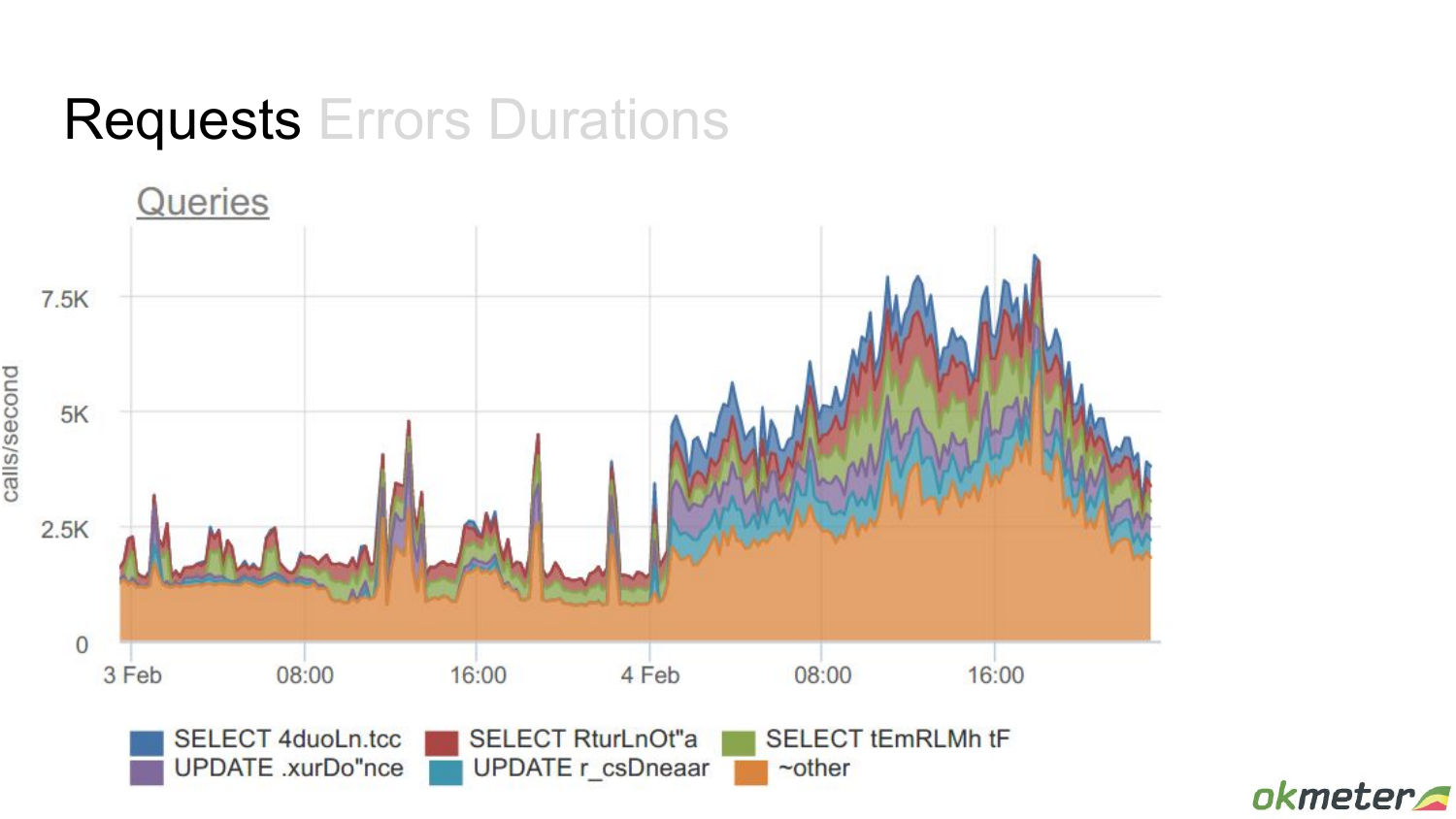
Здесь картина совсем другая. Например, была более-менее стабильная картина, т. е. стабильная нагрузка с какими-то выбросами. А после этого пришли новые запросы. Каких-то из этих запросов не было раньше. Они были временами, но не все время. А теперь они все время создают нагрузку. И важно смотреть. Потому что вы думаете: «О боже, у меня база затормозила», но это новые запросы пришли, которые эту базу тормозят.
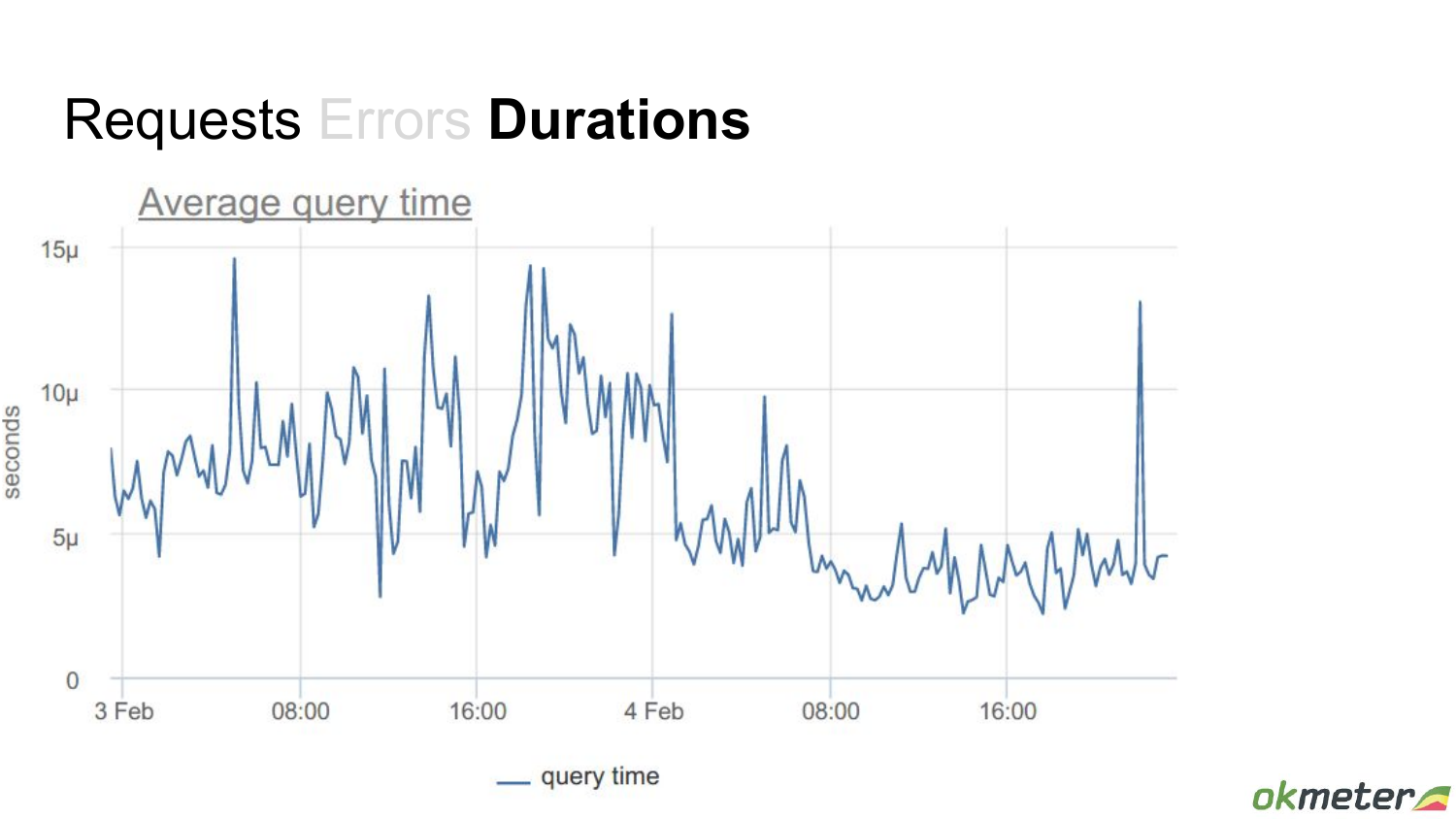
Этот график, который комплементарный к предыдущему. Из pg_stat_statements мы можем взять общее время, сколько времени база потратила на конкретный запрос. И можем построить среднее время запроса. Здесь довольно шумная картина, но в целом видно, что в соответствующий момент время обработки запросов упало. Что странно. Нагрузка возросла, а среднее время запросов упало. Это потому что среднее время запросов – это метрика довольно дурацкая. Пришло много запросов. Каждый из них, может, выполняется чуть-чуть быстрее, чем те, которые были до этого. И среднее по всем упало.

Также часто предлагают включить slow log. Slow log – это недостаточный мониторинг для durations запросов. Потому что он вам покажет выбросы, т. е. какие конкретно запросы тормозили, но он не покажет, что база тормозит из-за того, что в нее пришел вал вот таких быстрых запросов.
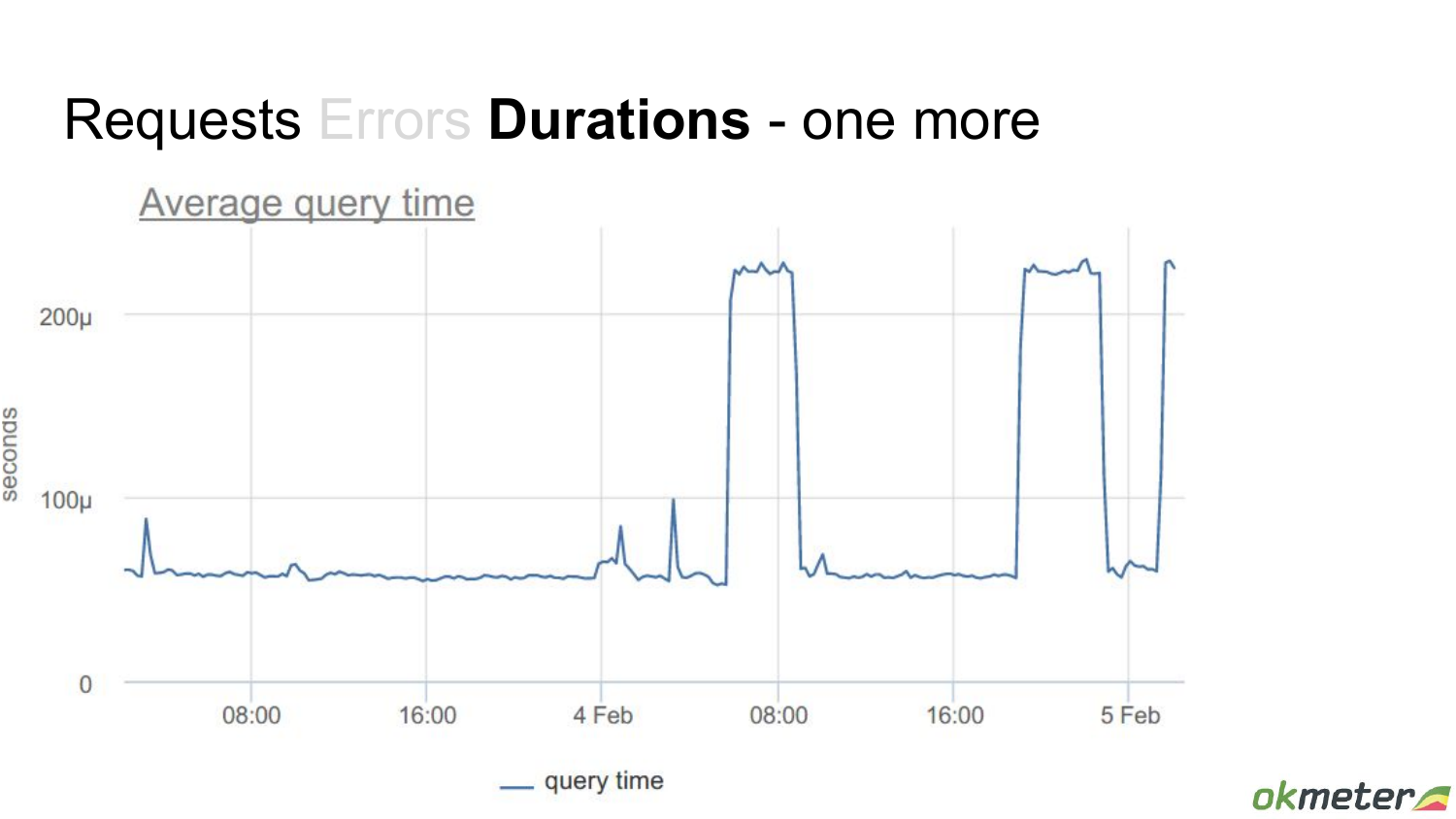
Тут у меня еще два примера, которые это в экстрим сводят. Мы видим, что было какое-то большое время ответа базы, потом был большой всплеск.

Запросы практически в ноль провалились. Не совсем в ноль, там какое-то количество происходит. А время большое. Это, наверное, проблема. Но конкретно – это не проблема того, что вдруг начало все медленнее отвечать.
И вот этот пример я еще покажу. Он более-менее стабильный.
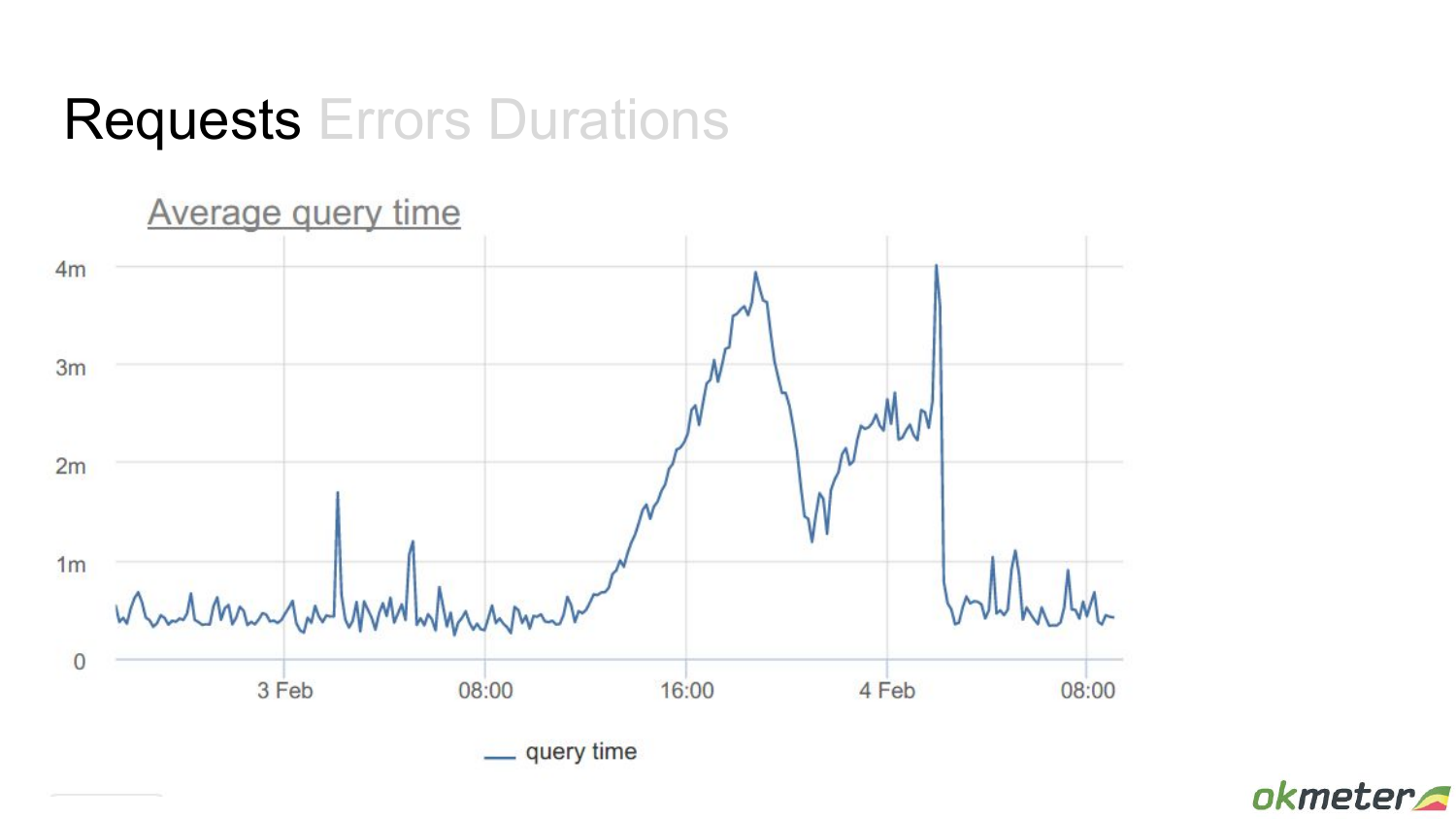
Но если мы посмотрим соответствующий график времени ответа базы, получается, что тут что-то непонятное происходит. Происходит какой-то большущий рост, потом пик.

И если снова посмотреть в разрезе конкретных запросов, то у вас картина проясняется. Вы знаете, какие конкретно запросы начали вот это генерировать. Они могли начать приходить с другими параметрами, планировщик мог передумать, как их исполнять. Это дает вам картину.
Я закончил, время у меня закончилось. Используйте USE, RED, чтобы вы могли все свои ad-hoc мониторинги, ad-hoc tools в какую-то систему ввести и понять, что есть что и на что вы, может быть, еще не смотрите, что вы упустили.
Спасибо.
Вопросы
Готовы ли решения для мониторинга Postgres, которые USE, RED методологии реализуют? Т. е. чтобы не писать все самому руками.
Okmeter, который мы делаем. Но я бы не сказал, что нужны какие-то решения, которые сугубо в этой методологии работают. Дело не в том, чтобы натянуть его всюду, чтобы у нас все было классно, потому что мы галочку поставили, что мы его натянули. Дело в том, что когда вы пытаетесь какой-то системой апеллировать и хотите ее мониторингом покрыть, то полезно думать про свой мониторинг в терминах USE, RED. И тогда вы поймете, что вы пропускаете. Тогда вы поймете, что вот здесь я замониторил ресурс, я утилизацию вижу, а saturation соответствующего нет. У него, может, утилизация невысокая, а saturation есть. И вы об этом не знаете, и проблема производительности в этом. И эта методология для того, чтобы вы что-то не упустили. Таких систем, которые не упускают ничего, наверное, нет. Так или иначе, это всегда компромисс между гигантским количеством информации и детальностью, которую они дают.
Привет! Спасибо за доклад! Я хотел узнать твое мнение, насчет 4-х золотых сигналов.
4 золотых сигнала – это полуобъединение USE и RED. Они говорят, что нужно мониторить вот это как USE, но только еще и как durations. Потому что errors есть и там и там. RED говорит, что надо еще requests и durations. Но в каком-то смысле они меньше, чем USE и RED вместе. Т. е. они не показывают какие-то аспекты. Они не покажут, например, что профиль нагрузки изменился.
Там есть сигнал – сколько трафика приходит на конкретный instance.
Да, но только про какой конкретно ресурсы мы говорим? Трафик – это ресурс сетевой. А тут для базы ресурс – это могут быть транзакции, requests и т. д.
Понял, спасибо большое!
Спасибо за доклад! У меня вопрос практической направленности. Какую использовать методологию – это выбор каждого, но в конечном итоге мы хотим исправить какие-то ошибки, которые мешают заказчику пользоваться нашей системой, чтобы он был доволен. Какая из этих методологий позволяет быстрее эти ошибки выявлять, может быть, за счет меньшего количества метрик и т. д.? Т. е. какая дает больше профита в итоге?
На мой взгляд, вопрос некорректный. Зависит от того, что вам подвластно изменять. Если вы владеете вот этой частью, т. е. частью, которая, может быть, рассмотрена, как ресурсы, то вам надо USE использовать. Если вы, наоборот, владеете запросами, которые в систему летят, например, вы разработчик и вы пишите selects, которые грузят базу, а эксплуатацию базы вам обеспечивает ваш заказчик, то вам подконтрольны только requests и вам тогда надо мониторить их. Вам надо говорить, что вот эти requests тормозят.
А если нам подвластны и ресурсы, и запросы, то что нам удобнее, то мы и выбираем, да?
Вам нужно то и то. По запросам вы понимаете, какие части тормозят. Например, вы видите, что база обрабатывает очень много времени именно эти запросы. И уже потом смотреть на них, какие ресурсы они потребляют. На этом примере можно выделить такую ситуацию. Здесь есть конкретные два апдейта, которые все грузят. Здесь понятно. А есть ситуации как здесь. Здесь нельзя сказать, что конкретно грузит. Тут какой-то внутренний ресурс, который равноценен для всех этих запросов, стал причиной. В него уперлись. И вот эта ситуация отличается тем, что ресурс не queries зависимый. Он какой-то общий для всех. Значит, вам надо смотреть на все ресурсы.
С точки зрения системы, в конце концов, у вас вот этот весь красивый Postgres упирается все равно в железные ресурсы. Поэтому вам надо понять, какой железный ресурс страдает. Потом понять, кто из этих создает на него нагрузку.
Спасибо большое за доклад! Очевидно, что вы собираете очень много данных о непосредственно instance Postgres на какой-то конкретной ноде. А как вы боретесь с тем, что это дает дополнительную нагрузку? Как правило, ресурсы на серверах с BD на вес золота.
Мы боремся двумя способами. Первый – мы предупреждаем об этом. И мы боремся в том смысле, что если вы не готовы к дополнительной нагрузке, вы готовы вслепую лететь, как он работает, так и работает, потому что вы не готовы тратить ресурсы сервера. И, соответственно, платить за это в каком-то смысле. Об этом мы предупреждаем, и заказчик делает выбор. Это первый способ.
Второй способ, которым мы боремся, это оптимизация. Мы оптимизируем то, что мы делаем. Эффективно Okmeter делает запросы в эти вьюхи регулярно, но довольно редко, раз в минуту.
Т. е. это не real time?
Это сложный вопрос, что такое real time. Давайте мы это обсудим отдельно. Но нагрузка ограничена тем, как много запросов вы делаете. Эти запросы не очень тяжелые все. Их несколько десятков. И даже если их будете делать в каком-то смысле более real time, чем раз в минуту, то все равно эта нагрузка довольно ограниченная. Вот пример, сколько запросов летит в базу. Тут их несколько тысяч. Соответственно, даже если эти несколько десятков опрашиваются раз в секунду, то это все равно доля.
Понятно, спасибо!

