Не так давно я познакомился с описанием E-A-T алгоритма от Google, который расшифровывается как «Expertise, Authoritativeness, Trustworthiness» (экспертность, авторитетность, достоверность). И мне, как автору, который пишет для разных сайтов стало интересно — насколько я сам соответствую критериям этого алгоритма и могу ли повлиять на текущую ситуацию. Тем более, что некоторые заготовки в виде открытой гугл таблицы для учета и мониторинга собственных публикаций LynxReport уже были.
Google Таблицы → Node.js → Google Charts → Сайт-визитка → Топ-3 место в поиске ФИО + специализация
На основании данных таблицы я решил дополнить сайт-визитку, сведениями о публикациях, которые бы генерировались автоматически. Что я хотел получить:
Как получилось можно посмотреть здесь. Реализовано на платформе Node.js с использованием Bootstrap, Google Charts и Google Таблицы для хранения исходных данных.
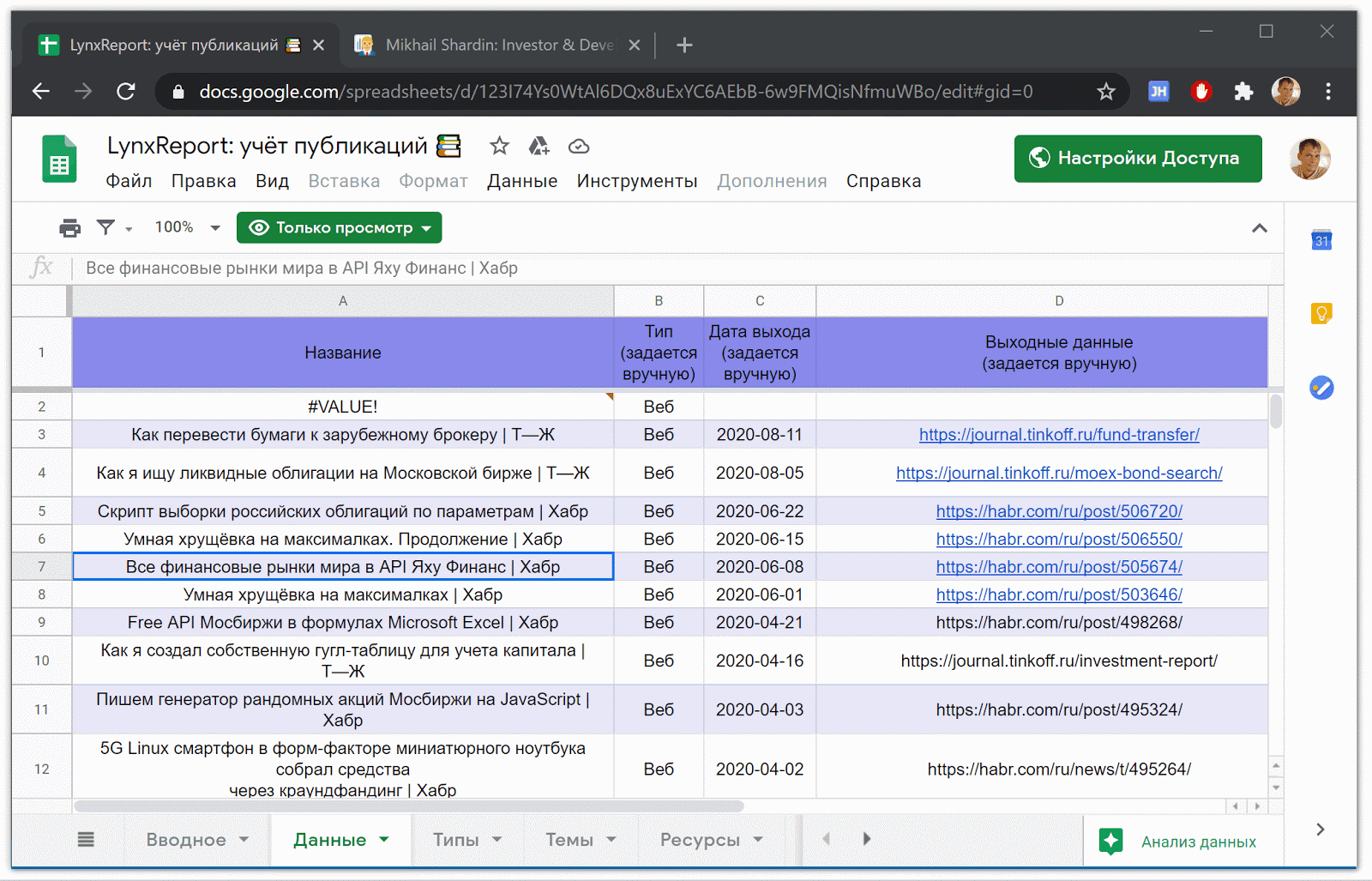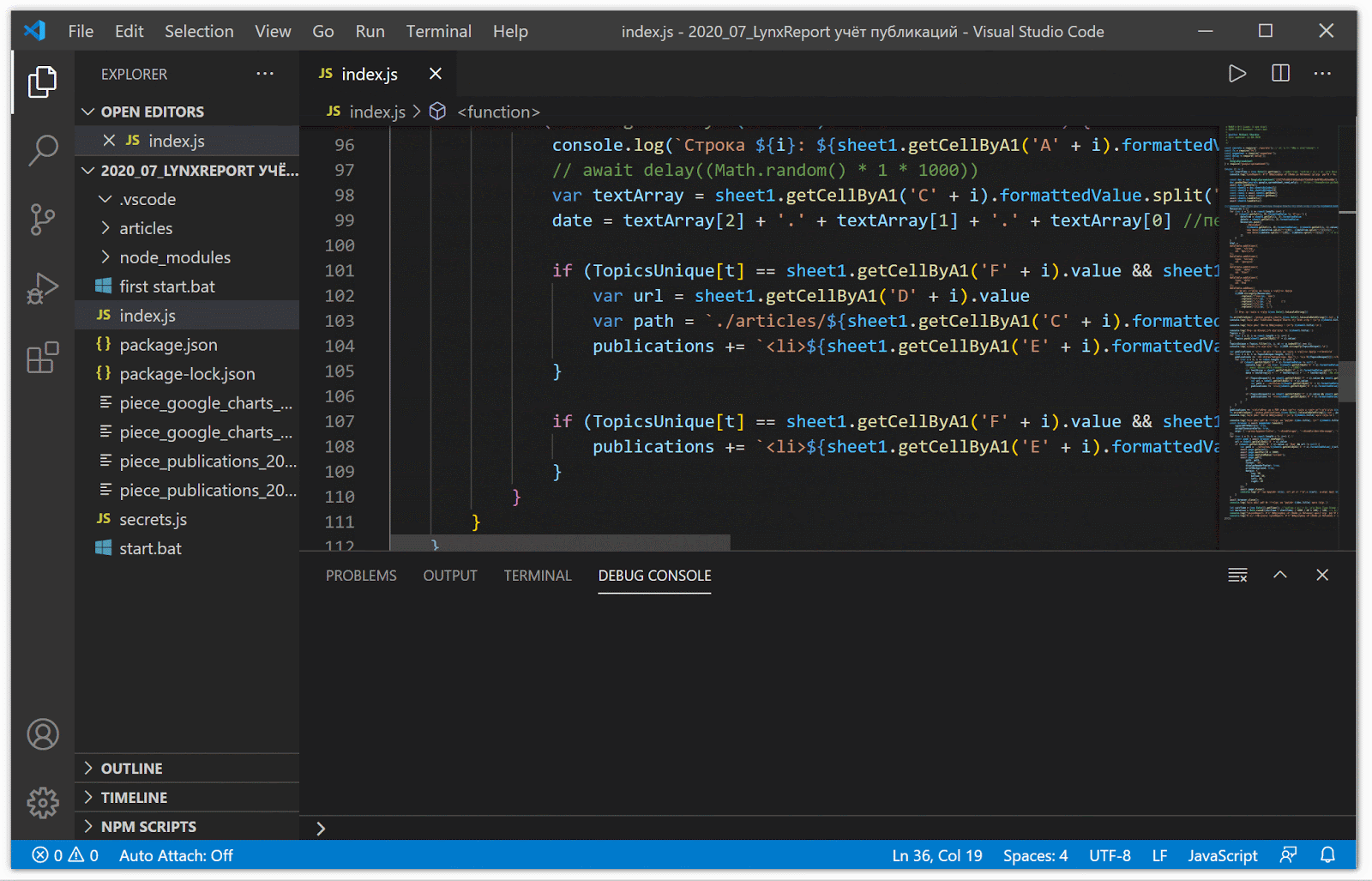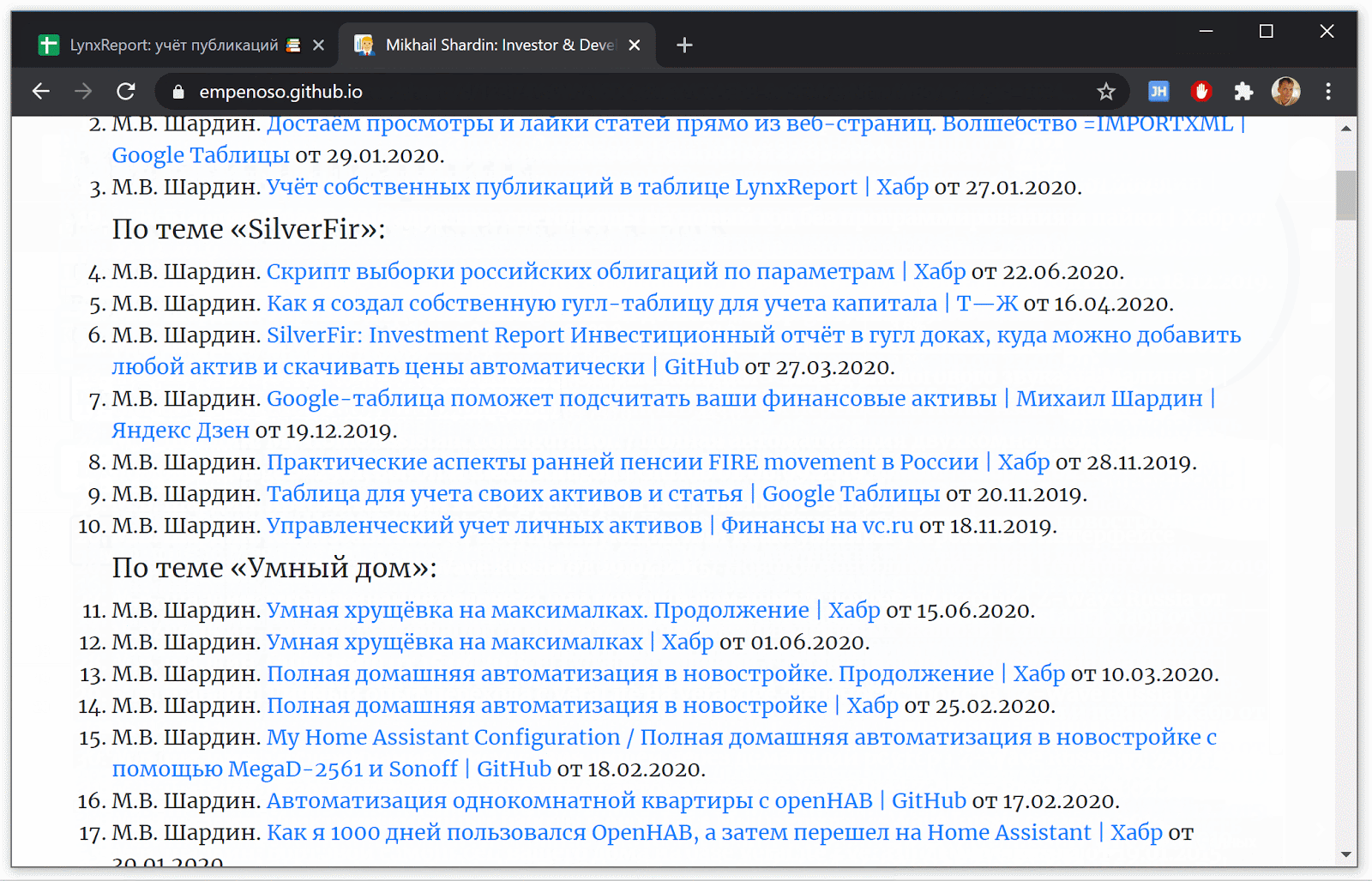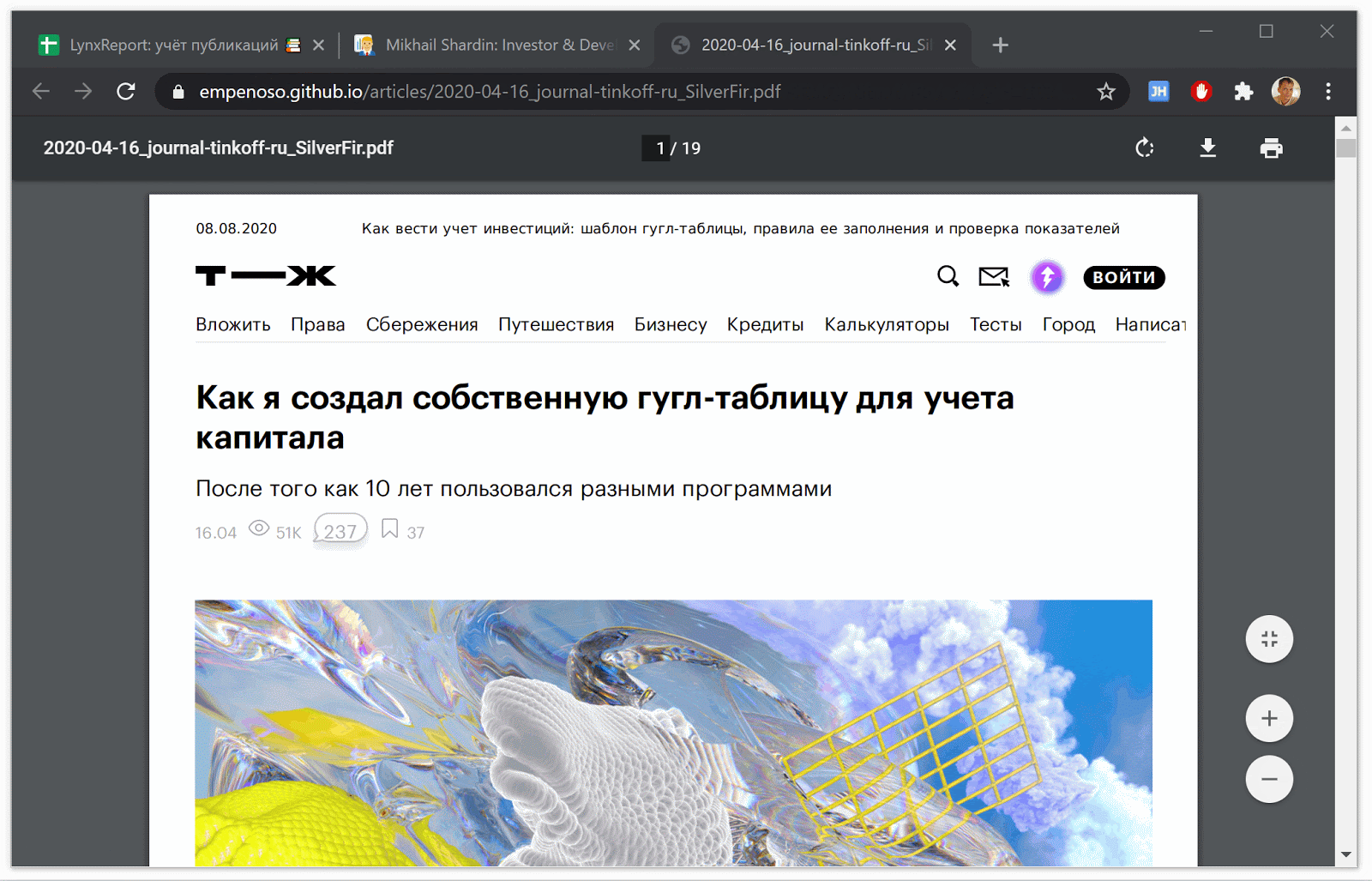
Гугл-таблица LynxReport: учёт публикаций содержит все исходные данные и аналитику по публикациям. Я поддерживаю актуальность сведений на вкладке «Данные», вручную вписывая новые ссылки на статьи, остальное скачивается по большей части автоматически.
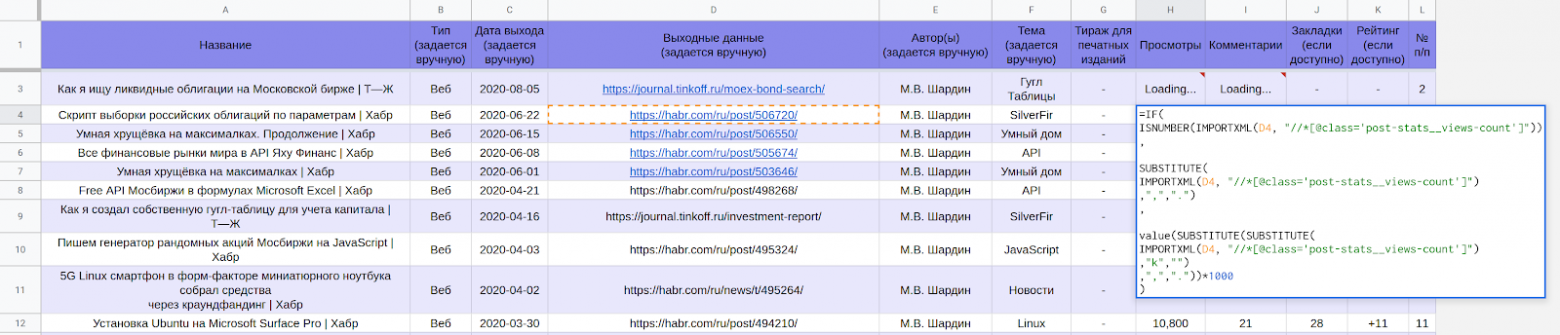
Часть таблицы LynxReport: учёт публикаций с исходными данными
Актуальные данные по просмотрам и комментариям подгружаются через формулы.
Например, чтобы получить количество просмотров со страниц Хабра в ячейке гугл таблиц используется формула:
Формулы это не самый быстрый вариант и для того, чтобы получить несколько сотен позиций приходится ждать около получаса. После окончания загрузки можно видеть все цифры как на скриншоте ниже. Они дают ответы какие темы популярны, а какие нет.
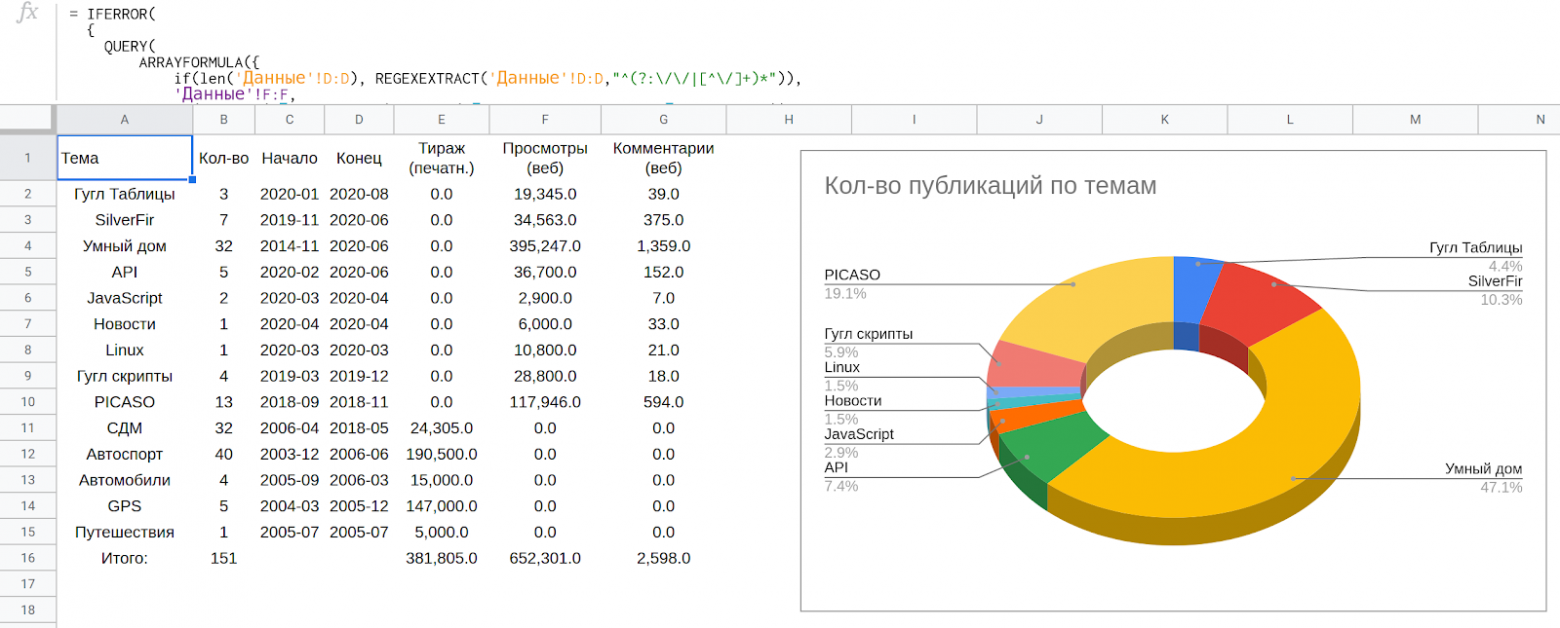
Часть таблицы LynxReport: учёт публикаций с аналитикой
Чтобы трансформировать эти сводные данные из гугл таблицы в сайт-визитку мне надо было преобразовать данные в формат временной шкалы Google Charts.

Получившаяся временная шкала Google Charts на сайте-визитке
Для того, чтобы корректно отрисовать такой график данные должны быть организованы следующим образом:

Данные для Google Charts на сайте-визитке в html виде
Чтобы выполнять все преобразования автоматически я написал под Node.js скрипт, который доступен на GitHub.
Если вы не знакомы с Node.js, то в своей предыдущей статье я подробно расписал как можно воспользоваться скриптом под разными системами:
Ссылка с инструкциями здесь. Принцип аналогичен.

Работа скрипта по преобразованию в нужный формат данных и генерации pdf версий статей с сайтов (все строки обрабатываются мгновенно — я специально поставил задержку, чтобы записать это видео)
Для того считывать данные из гугл таблицы в автоматическом режиме я пользуюсь авторизацией по ключу.
Получить этот ключ можно в консоли управления проектами гугла:

Учетные данные в Google Cloud Platform
После завершения работы скрипта должны сгенерироваться два текстовых файла с html данными графиков и все pdf копии онлайн статей.
Данные из текстовых файлов я импортирую в html код сайта-визитки.
При помощи Puppeteer сохраняю текущий вид статей вместе со всеми комментариями в pdf виде.
Если не ставить задержку, то несколько десятков статей по списку можно сохранить в виде pdf файлов всего за несколько минут.
А задержка нужна для того чтобы на некоторых сайтах (например на Т—Ж) успели подгрузиться комментарии.
Поскольку написание скрипта затевалось с целью большего соответствия поисковым алгоритмам, то оценить результаты можно воспользовавшись поиском.
Поиск по имени и фамилии + указание специализации в обоих случаях возвращает ссылки на мои статьи и даже сайт-визитку:
В выдаче Яндекса:
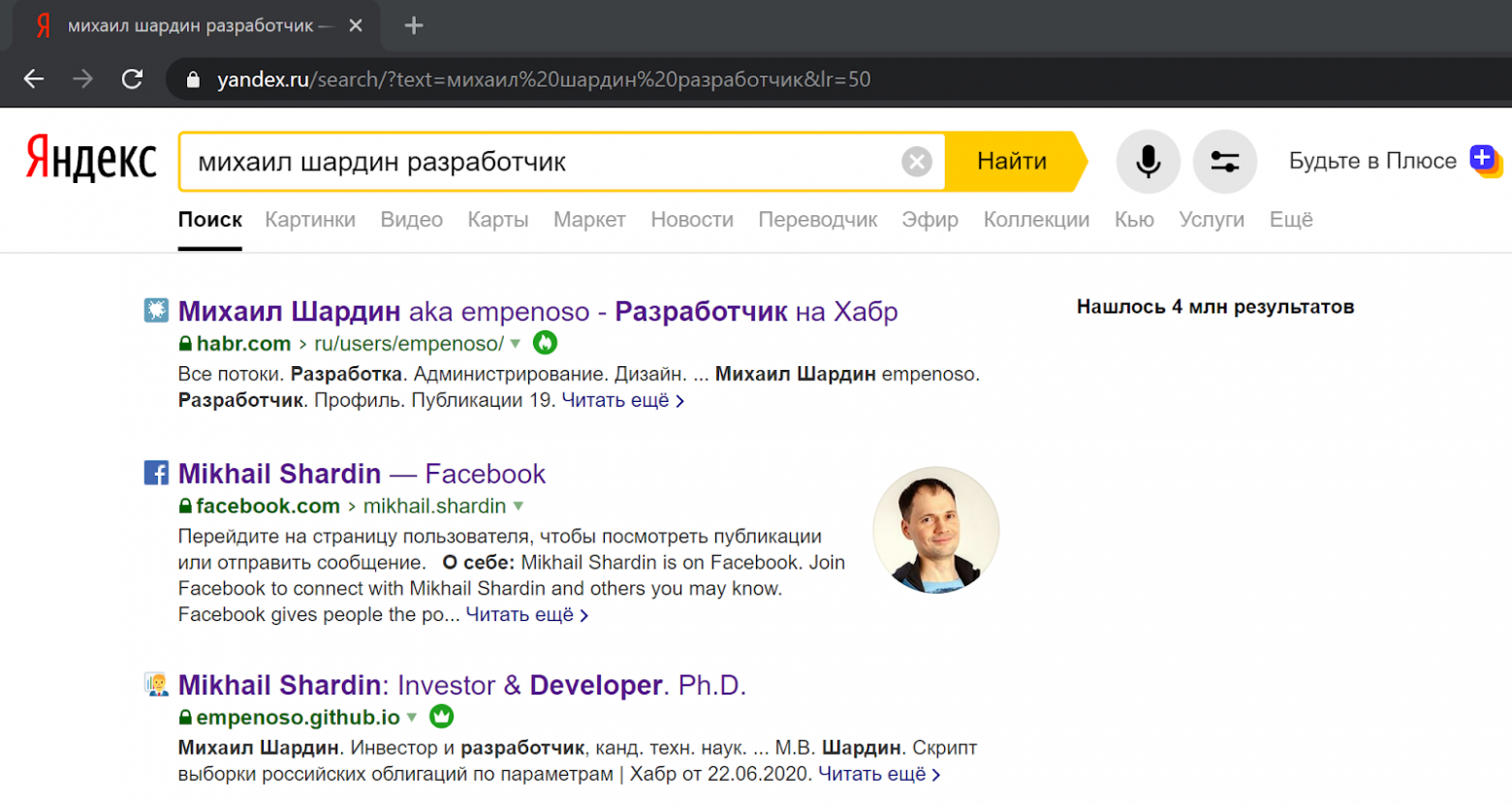
В выдаче Гугла:

Пока что не могу решить — стоит ли регистрировать отдельное доменное имя, если визитка empenoso.github.io и так находится на верхних строчках поиска?
UPD. Доменное имя таки зарегистрировал: https://shardin.name/
17 августа 2020 г.
Google Таблицы → Node.js → Google Charts → Сайт-визитка → Топ-3 место в поиске ФИО + специализация
На основании данных таблицы я решил дополнить сайт-визитку, сведениями о публикациях, которые бы генерировались автоматически. Что я хотел получить:
- Актуальную сводку публикаций, расположенную на временной шкале Google Charts.
- Автоматическую генерацию выходных данных и ссылок на статьи из гугл таблицы в html версию визитки.
- PDF версии статей со всех сайтов, из-за опасений закрытия некоторых старых сайтов в будущем.
Как получилось можно посмотреть здесь. Реализовано на платформе Node.js с использованием Bootstrap, Google Charts и Google Таблицы для хранения исходных данных.
Исходные данные о публикациях в Google Spreadsheet
Гугл-таблица LynxReport: учёт публикаций содержит все исходные данные и аналитику по публикациям. Я поддерживаю актуальность сведений на вкладке «Данные», вручную вписывая новые ссылки на статьи, остальное скачивается по большей части автоматически.
Часть таблицы LynxReport: учёт публикаций с исходными данными
Актуальные данные по просмотрам и комментариям подгружаются через формулы.
Например, чтобы получить количество просмотров со страниц Хабра в ячейке гугл таблиц используется формула:
=IF( ISNUMBER(IMPORTXML(D6, "//*[@class='post-stats__views-count']")) , SUBSTITUTE( IMPORTXML(D6, "//*[@class='post-stats__views-count']") ,",",".") , value(SUBSTITUTE(SUBSTITUTE( IMPORTXML(D6, "//*[@class='post-stats__views-count']") ,"k","") ,",","."))*1000 )
Формулы это не самый быстрый вариант и для того, чтобы получить несколько сотен позиций приходится ждать около получаса. После окончания загрузки можно видеть все цифры как на скриншоте ниже. Они дают ответы какие темы популярны, а какие нет.
Часть таблицы LynxReport: учёт публикаций с аналитикой
Считывание данных из Таблицы и преобразование в формат Google Charts
Чтобы трансформировать эти сводные данные из гугл таблицы в сайт-визитку мне надо было преобразовать данные в формат временной шкалы Google Charts.
Получившаяся временная шкала Google Charts на сайте-визитке
Для того, чтобы корректно отрисовать такой график данные должны быть организованы следующим образом:
Данные для Google Charts на сайте-визитке в html виде
Чтобы выполнять все преобразования автоматически я написал под Node.js скрипт, который доступен на GitHub.
Если вы не знакомы с Node.js, то в своей предыдущей статье я подробно расписал как можно воспользоваться скриптом под разными системами:
- Windows
- macOS
- Linux
Ссылка с инструкциями здесь. Принцип аналогичен.
Работа скрипта по преобразованию в нужный формат данных и генерации pdf версий статей с сайтов (все строки обрабатываются мгновенно — я специально поставил задержку, чтобы записать это видео)
Для того считывать данные из гугл таблицы в автоматическом режиме я пользуюсь авторизацией по ключу.
Получить этот ключ можно в консоли управления проектами гугла:
Учетные данные в Google Cloud Platform
После завершения работы скрипта должны сгенерироваться два текстовых файла с html данными графиков и все pdf копии онлайн статей.
Данные из текстовых файлов я импортирую в html код сайта-визитки.
Генерация pdf копий статей с сайтов
При помощи Puppeteer сохраняю текущий вид статей вместе со всеми комментариями в pdf виде.
Если не ставить задержку, то несколько десятков статей по списку можно сохранить в виде pdf файлов всего за несколько минут.
А задержка нужна для того чтобы на некоторых сайтах (например на Т—Ж) успели подгрузиться комментарии.
Результаты
Поскольку написание скрипта затевалось с целью большего соответствия поисковым алгоритмам, то оценить результаты можно воспользовавшись поиском.
Поиск по имени и фамилии + указание специализации в обоих случаях возвращает ссылки на мои статьи и даже сайт-визитку:
В выдаче Яндекса:
В выдаче Гугла:
Пока что не могу решить — стоит ли регистрировать отдельное доменное имя, если визитка empenoso.github.io и так находится на верхних строчках поиска?
Вместо заключения
- Возможно, эта статья заставит кого-то задуматься о том, как он выглядит в интернете.
- Возможно, эта статья поможет кому-то наладить учёт и организацию публикаций.
- Исходный код скрипта расположен на GitHub.
UPD. Доменное имя таки зарегистрировал: https://shardin.name/
Автор: Михаил Шардин
🔗 Моя онлайн-визитка
📢 Telegram «Умный Дом Инвестора»
17 августа 2020 г.
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
Вы пишите статьи для сайтов?
22.73%Да5
72.73%Нет16
4.55%Только в соц. сетях1
Проголосовали 22 пользователя. Воздержались 5 пользователей.
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
Стоит ли регистрировать отдельное доменное имя, если визитка empenoso.github.io и так на верхних строчках поиска?
45%Да9
55%Нет11
Проголосовали 20 пользователей. Воздержались 6 пользователей.

