Только что вышла очередная версия плагина Big Data Tools — плагина для IntelliJ IDEA Ultimate, DataGrip и PyCharm, который обеспечивает интеграцию с Hadoop и Spark, позволяет редактировать и запускать интерактивные блокноты в Zeppelin.
Основная задача этого релиза — поправить как можно больше проблем и улучшить плагин изнутри, но два важных улучшения видно невооруженным глазом:
- соединяться с Hadoop и Spark теперь можно через SSH-туннели, создающиеся парой щелчков мыши;
- мониторинг Hadoop может ограничивать объем данных, загружаемых при просмотре списка приложений.

SSH-туннели
Зачастую нужный нам сервер недоступен напрямую, например если он находится внутри защищенного корпоративного контура или закрыт специальными правилами на файерволе. Чтобы пробраться внутрь, можно использовать какой-то туннель или VPN. Самый простой из туннелей, который всегда под руками, — это SSH.
Проложить туннель можно одной-единственной консольной командой:
ssh -f -N -L 1005:127.0.0.1:8080 user@spark.server
Немного автоматизировать процесс поможет файл ~/.ssh/config, в который ты один раз сохраняешь параметры соединения и потом используешь:
Host spark HostName spark.server IdentityFile ~/.ssh/spark.server.key LocalForward 1005 127.0.0.1:8080 User user
Теперь достаточно написать в консоли ssh -f -N spark — и туннель поднимется сам по себе, без вписывания IP-адресов. Удобно.
Но с этими способами есть две очевидных проблемы.
Во-первых, у кого-то может возникнуть масса вопросов. Что такое -f -N -L? Какой порт писать слева, а какой — справа? Как выбирать адреса для соединений? Для всех, кроме профессиональных системных администраторов, такие мучения не кажутся полезными.
Во-вторых, мы программируем не в эмуляторе терминала, а в IDE. Всё, что вы запустили в консоли, работает глобально по отношению ко всей операционной системе, а в IDE хотелось бы для каждого проекта иметь свой собственный набор туннелей.
К счастью, начиная с этой версии в Big Data Tools есть возможность создавать туннели без ручного управления SSH-соединениями.

На скриншоте видно, что можно не только вручную указать все адреса и порты, но и подключить заранее подготовленный файл конфигурации SSH.
Опция Enable tunneling работает для следующих типов соединений:
- Zeppelin
- HDFS
- Hadoop
- Spark Monitoring
Важно отметить, что под капотом у нее все то же самое, что делает SSH. Не стоит ждать особой магии: например, если ты пытаешься открыть туннель на локальный порт, который уже занят другим приложением или туннелем, то случится ошибка.
Это довольно полезная опция, которая облегчает жизнь в большинстве повседневных ситуаций. Если же тебе нужно сделать что-то действительно сложное и нестандартное, то можно по старинке вручную использовать SSH, VPN или другие способы работы с сетью.
Вся работа велась в рамках задачи BDIDE-1063 на нашем YouTrack.
Управляемые ограничения на отображение приложений
Люди делятся на тех, у кого на странице Spark Monitoring всего парочка приложений, и тех, у кого их сотни.

Загрузка огромного списка приложений может занимать десятки минут, и все это время о состоянии сервера можно только гадать.
В этой версии Big Data Tools вы можете существенно ограничить время ожидания, если вручную выберете диапазон загружаемых данных. Например, можно вызвать диалоговое окно редактирования диапазона дат и вручную выбрать только сегодняшний день.
Эта опция значительно экономит время тех, кто работает с большими продакшенами.
Работа велась в рамках задачи BDIDE-1077.
Подключение модулей в зависимости Zeppelin
У многих в Zeppelin используются зависимости на собственные JAR-файлы. Big Data Tools полезно знать о таких файлах, чтобы в IDE нормально работало автодополнение и другие функции.
При синхронизации с Zeppelin, Big Data Tools пытается получить все такие файлы. Но, по разным причинам, это не всегда возможно. Чтобы Big Data Tools узнал о существовании таких пропущенных файлов, необходимо вручную добавить их в IntelliJ IDEA.
Раньше в качестве зависимостей можно было использовать только артефакты из Maven либо отдельные JAR-файлы. Это не всегда удобно, ведь для получения этих артефактов и файлов нужно или их скачать откуда-то, или собрать весь проект.
Теперь любой модуль текущего проекта тоже можно использовать в качестве зависимости. Такие зависимости попадают в таблицу "User dependencies":
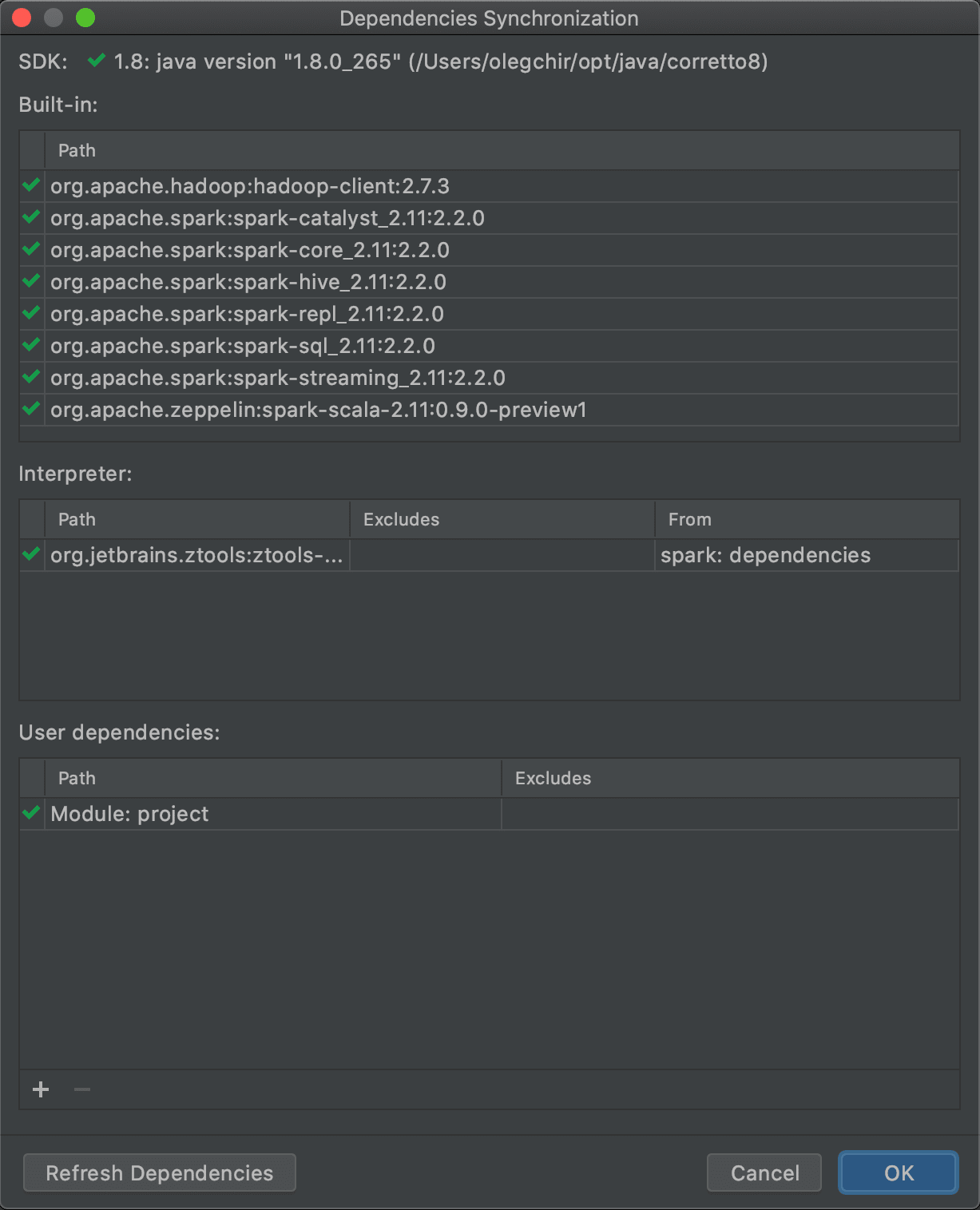
Работа велась в рамках задачи BDIDE-1087.
Множество свежих исправлений
Big Data Tools — молодой, активно развивающийся проект. В таких условиях неизбежно появление проблем, которые мы стараемся оперативно устранять. В EAP 10 вошло множество исправлений, значительная часть которых посвящена повышению удобства работы со Spark Monitoring.
- [BDIDE-1078] Раньше при сворачивании ячеек их заголовки просто не отображались. Теперь они правильно отображаются, но редактировать их из Big Data Tools все еще нельзя — это тема для будущих исправлений.
- [BDIDE-1137] Удаление соединения Spark Monitoring из Hadoop приводило к ошибке IncorrectOperationException.
- [BDIDE-570] В таблице Jobs в Spark Monitoring у выделенной задачи могло исчезать выделение.
- [BDIDE-706] При обновлении дерева задач в Spark Monitoring выделенная задача теряла выделение.
- [BDIDE-737] Если компьютер заснул и вышел из сна, получение информации о приложении в Spark Monitoring требовало перезагрузки IDE.
- [BDIDE-1049] Перезапуск IDE мог приводить к появлению ошибки DisposalException.
- [BDIDE-1060] Перезапуск IDE с открытым Variable View (функциональность ZTools) мог привести к ошибке IllegalArgumentException.
- [BDIDE-1066] Редактирование свойств неактивного соединения в Spark Monitoring приводило к его самопроизвольному включению на панели.
- [BDIDE-1091] Удаление только что открытого соединения с Zeppelin приводило к ошибке ConcurrentModificationException.
- [BDIDE-1092] Кнопка Refresh могла не обновлять задачи в Spark Monitoring.
- [BDIDE-1093] После перезапуска Spark в Spark Monitoring отображалась ошибка подключения.
- [BDIDE-1094] При отображении ошибки соединения в Spark Monitoring нельзя было изменить размеры окна с ошибкой.
- [BDIDE-1099] В Spark Monitoring на вкладке SQL вместо сообщения "Loading" могло неверно отображаться сообщение "Empty List".
- [BDIDE-1119] В Spark Monitoring свойства SQL продолжали отображаться даже при сбросе соединения или перезагрузке интерпретатора.
- [BDIDE-1130] Если в списке приложений в Spark Monitoring фильтр скрывал вообще все приложения, возникала ошибка IndexOutOfBoundsException.
- [BDIDE-1133] Таблицы отображали только один диапазон данных, даже если в свойствах таблицы было указано сразу несколько диапазонов.
- [BDIDE-406] Раньше при соединении с некоторыми экземплярами Zeppelin отображалась ошибка синхронизации. В рамках этого же тикета включена поддержка Zeppelin 0.9, в частности — collaborative mode.
- [BDIDE-746] При отсутствии выбранного приложения или задачи в Spark Monitoring на странице с детализацией отображалась ошибка соединения.
- [BDIDE-769] При переключении между различными соединениями к Spark Monitoring могла не отображаться информация об этом соединении.
- [BDIDE-893] Время от времени список задач в Spark Monitoring исчезал, и вместо него отображалось некорректное сообщение о фильтрации.
- [BDIDE-1010] После запуска ячейки, статус "Ready" отображался со слишком большой задержкой.
- [BDIDE-1013] Локальные блокноты в Zeppelin раньше имели проблемы с переподключением.
- [BDIDE-1020] В результате комбинации нескольких факторов могло сбиваться форматирование кода на SQL.
- [BDIDE-1023] Раньше не отображался промежуточный вывод исполняющихся ячеек, теперь отображается под ними.
- [BDIDE-1041] Непустые файлы на HDFS отображались как пустые, из-за чего их можно было случайно сохранить и стереть данные.
- [BDIDE-1061] Исправлен баг в отображении отображением SQL-задач. Раньше было неясно, является ли сервер Spark привязанным к задаче или это History Server.
- [BDIDE-1068] Временами ссылка на задачу в Spark терялась и появлялась вновь.
- [BDIDE-1072], [BDIDE-838] Раньше в панели Big Data Tools не отображалась ошибка соединения с Hadoop и Spark.
- [BDIDE-1083] Если при закрытии IDE работала хоть одна задача с индикатором прогресса, возникала ошибка "Memory leak detected".
- [BDIDE-1089] В таблицах теперь поддерживается интернационализация.
- [BDIDE-1103] При внезапном разрыве связи с Zeppelin не отображалось предупреждение о разрыве соединения.
- [BDIDE-1104] Горизонтальные полосы прокрутки перекрывали текст.
- [BDIDE-1120] При потере соединения к Spark Monitoring возникала ошибка RuntimeExceptionWithAttachments.
- [BDIDE-1122] Перезапуск интерпретатора приводил к ошибке KotlinNullPointerException.
- [BDIDE-1124] Подключение к Hadoop не могло использовать SOCKS-прокси.

