
Вы только что установили PostgreSQL и запустили ваш первый кластер, создали несколько таблиц, загрузили данные, и даже немного подкрутили конфигурацию PostgreSQL для улучшения производительности. Теперь вы думаете о том, как сделать ваш кластер высокодоступным. К сожалению, PostgreSQL не умеет сам выполнять автоматическое переключение при недоступности мастера, но, к счастью для нас, этого можно достичь с помощью сторонних утилит. Задача ясна, и вы начинаете изучать преимущества и недостатки всех утилит, чтобы выбрать лучшую. И… вы уже на неправильном пути, потому что в первую очередь вы должны определиться со значениями SLA, RTO и RPO. В этом докладе я планирую рассказать о ряде ошибок, которые допускают администраторы баз данных при настройке и эксплуатации высокодоступного кластера Постгреса с автоматическим переключением.

Здравствуйте! Меня зовут Александр. Уже 6 лет я живу в Берлине. Работаю в Zalando. Меня люди знают, как разработчика решения для high availability postgres’ового для автоматического переключения под названием Patroni.

Я так думаю, что многие из вас должны представлять, что такое Zalando. Если нет, то это брат или сестра Lamoda. Но мы работаем в Европе и не доставляем ничего в Россию.

Наш бизнес очень активно использует Postgres. И у нас до сих пор есть очень много кластеров на железе в дата-центре.
Порядка 4-х лет назад мы начали активно запускать новые вещи в Amazon. И стали переносить не очень активные старые кластера в Amazon. Первая цифра потихоньку падает, вторая цифра растет, причем растет достаточно быстро. Часть кластеров в Amazon работают на EC2 instances, часть работает в Kubernetes, которая опять же работает на EC2 instances.

И ко мне приходят много вопросов, как что-то лучше делать. Или у людей бывают какие-то неправильные ожидания от системы для high availability. И я решил сделать доклад на эту тему, чтобы объяснить, что такое high availability и каким образом оно относится к disaster recovery, и почему одно не может жить без другого.
А также расскажу, о каких вещах надо знать, когда вы строите high availability систему и как правильно делать автоматический failover.
Я пройдусь через несколько инцидентов, которые были публично обсуждены и прошумели на весь мир. Эти инциденты не из нашей компании, но все равно очень полезно с ними познакомиться, потому что хорошо учиться на чужих ошибках.
Обсудим ряд проблем, которые HA не должна решать, хотя люди ожидают, что она будет это делать. И в завершении дам несколько советов.

Давайте начнем с простого (или со сложного?). Что такое высокая доступность или HA?

Давайте начнем действительно простого. Что такое доступность? С доступностью все очень просто. Мы измеряем время, в течение которого система была доступна. Например, в течение года, делим на общее время, т.е. когда система была доступна и недоступна. И мы получаем наше значение доступности.

Причины недоступности могут быть разными. Это какие-то плановые работы, когда мы, например, хотим обновить железо, переехать на другой сервер, обновить BIOS или какой-то софт.
Бывают незапланированные downtime. Дата-центр может пострадать в результате наводнения, извержения вулкана и всего чего угодно. Или, например, кто-то кабель перерубил, причем разный кабель: сетевой или с электричеством. Сеть может пострадать. Может ваш сервер сгореть. В конце концов, это все программное обеспечение, которое не лишено багов. Баги случаются. Или просто ошибка человеческая. Люди иногда по ошибке удаляют данные, дропают таблицу, запускают update или delete без where clause. Иногда даже просто удаляют директорию, что тоже случается.
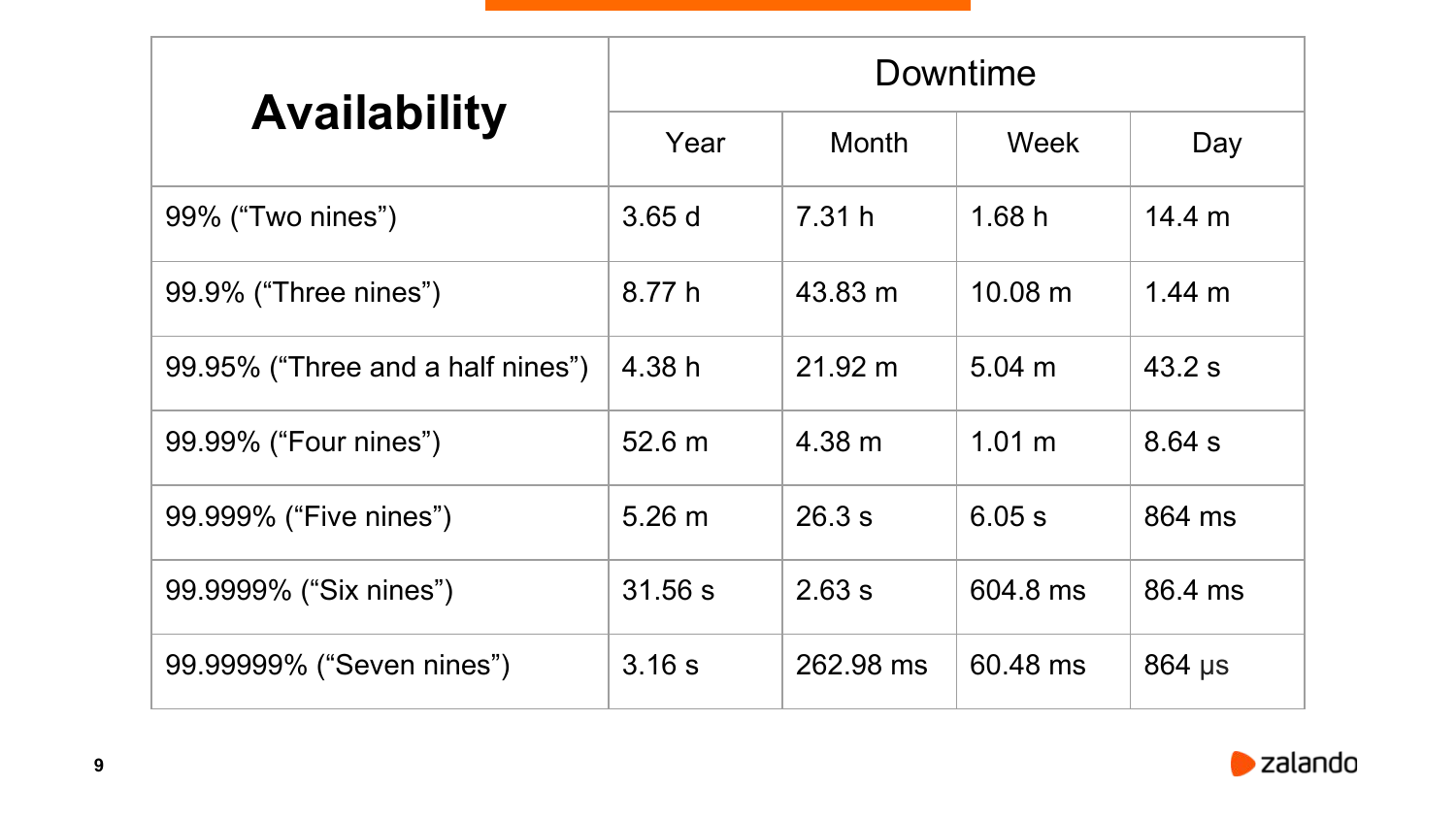
Теперь вернемся назад к доступности. Она измеряется в девятках. Начинается все с двух девяток, заканчивается семью-восьмью-девятью.
Если считать, как много система может быть доступной или недоступной за год, то в двух девятках – это три с половиной дня. Это достаточно много. В день вы можете выключить сервер на 15 минут и быть все равно в пределах этих двух девяток.
Есть одна очень интересная вещь как 99,95 %, т. е. три с половиной девятки. Почему я поместил ее здесь? Потому что, например, Amazon, когда продает вам RDS, они гарантируют вот эти три с половиной девятки. Это и не три девятки, и не четыре, но это и не посередине на самом деле, если посмотреть, сколько может быть система не доступна.
И чем больше мы девяток набираем, тем быстрее у нас должно происходить переключение при сбое.
Уже на семи девятках в год мы не можем быть не доступны больше, чем три секунды. Это очень маленький промежуток. И только гигантские корпорации такие, как Google или Amazon могут себе позволить строить системы, которые доступны больше, чем семь девяток или восемь девяток.

Что же такое все-таки высокая доступность? На самом деле официального определения не существует. Есть определение от IBM, где они измеряют высокую доступность как некоторое количество девяток. И если девяток больше, то там есть другие названия для этого.
На Википедии есть такая фраза, что это характеристика системы, которая нацелена на какой-то уровень производительности или доступности выше каких-то договоренных значений. Мы здесь говорим о каком-то agreed.

Что это такое? На самом деле есть такая вещь, как сервис level an agreed. Я не знаю, как это на русский переводить. Но это стандартная вещь. Это соглашение, в котором описывается тип сервиса, который мы предоставляем, каким образом он мониторится, какая у нас должна быть производительность, доступность и т. д. Как мы можем сообщать о каких-то проблемах с сервисом, как сервис провайдер должен реагировать на эти проблемы, и как быстро должен их разрешать.
Соответственно, мониторинг в том числе отвечает за то, чтобы измерять какой-то сервис level indication. Например, наш availability. И сервис level objective – это самая последняя вещь, которую отсюда надо знать. Она говорит о том, на какой уровень мы целимся. Т.е. мы хотим, чтобы у нас availability был, например, четыре девятки. Если мы не достигли за год четырех девяток, то значит, мы нарушили договоренность и за это следуют обычно какие-то санкции.
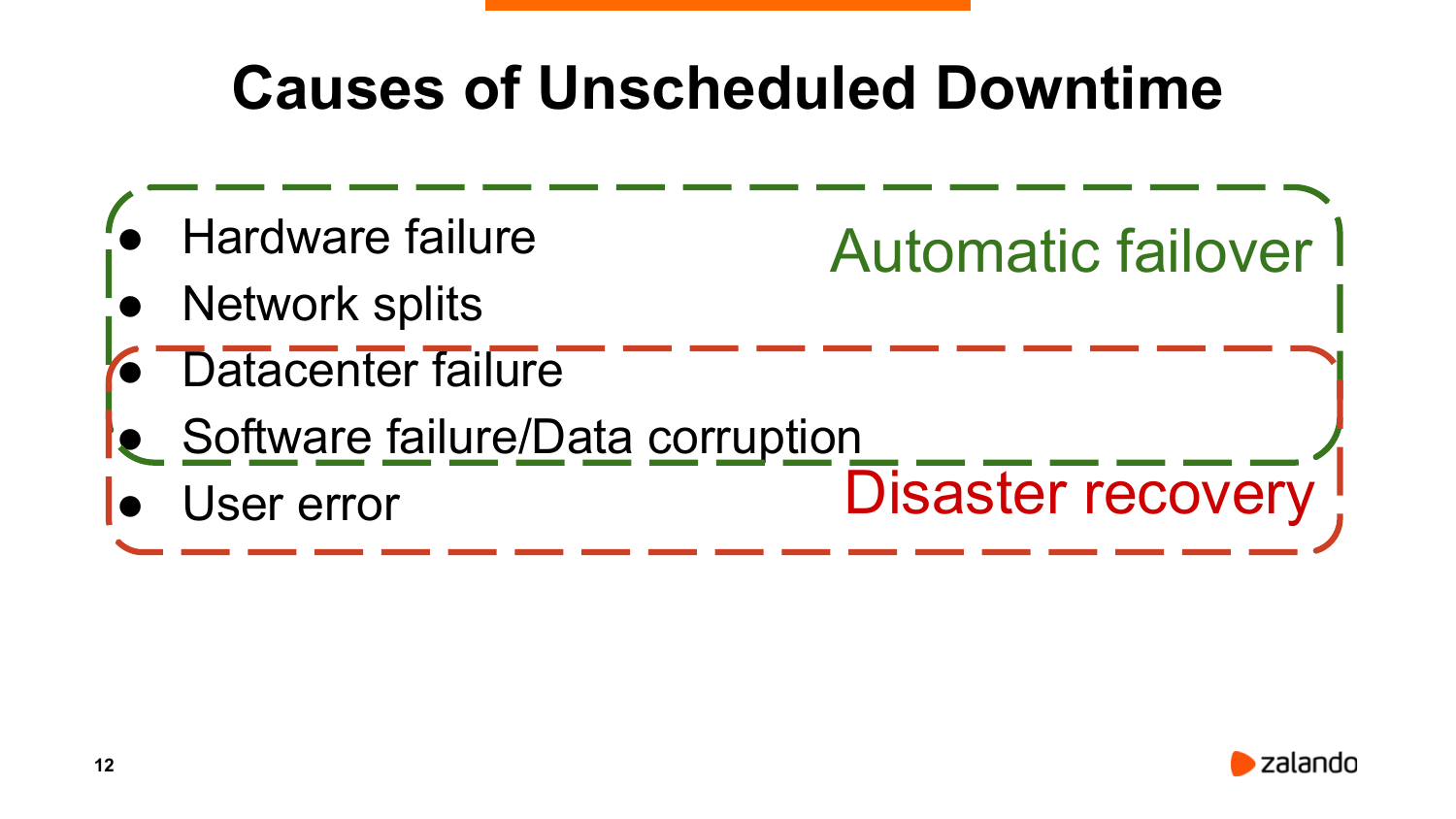
Еще раз посмотрим, какие могут быть причины недоступности.
Могут быть проблемы:
- С железом.
- С сетью.
- С дата-центром полностью.
- С софтом.
- Или ошибка юзера.

Что из них может решить наше автоматическое переключение? Очевидно не весь класс проблем. Ряд проблем могут быть решены только при помощи disaster recovery, т.е. аварийного восстановления.

Когда мы строим HA, то мы в первую очередь должны задуматься об аварийном восстановлении. Мы должны подготовить какой-то план.
Причем этим планом должен заниматься не просто DBA или сисадмин, сюда должны быть вовлечены бизнес-люди. Потому что в первую очередь мы должны понять, сколько транзакций мы можем потерять в результате какого-то disaster, либо как быстро мы должны вернуть нашу систему назад в строй.
Есть две ключевые вещи. Это RPO (recovery point objective), т. е., сколько транзакций мы можем потерять и за какой период. И RTO (recovery time objective). Это как быстро мы должны систему вернуть назад в рабочее состояние.
И посмотреть, как это относится к SLA, SLI, то SLA измеряется за большой промежуток времени, за год. А RTO – это для данного конкретного инцидента.

https://en.wikipedia.org/wiki/File:RPO_RTO_example_converted.png
Обычно рисуют вот такой график для disaster recovery. У нас есть RPO, RTO. Это картинка с Википедии. На данном конкретном графике недоступность сервиса превысила наш RTO (время восстановления).
На самом деле будет гораздо интереснее, если мы добавим на этот график еще несколько линий. Чем больше данных мы теряем, тем больше потери для бизнеса в деньгах. И чем дольше наш сервис не доступен, тем выше потери для бизнеса.
Но с другой стороны, сделать бэкапы, которые гарантируют абсолютное отсутствие потерь, может стоить достаточно дорого. В случае с PostgreSQL мы можем использовать синхронную репликацию (доступную из коробки), но стоимость может всё равно преподнести сюрприз. Или например если мы хотим сделать переключение в случае падения мастера за какое-то минимальное время (секунды), то такая система тоже будет стоить бессмысленно дорого.
Когда выбираем RPO и RTO – это дело балансирования вот на этих двух кривых. Т. е. сколько вы готовы потратить на нашу систему бэкапов, сколько мы готовы потратить на поддержку систем автоматического переключения, чтобы их стоимость не превысила потери бизнеса в случае инцидента.

И как все это относится с Postgres? Очевидно, что автоматический failover не поможет нам сделать бэкапы и восстановить данные. Соответственно, нам нужна какая-то система бэкапов. Мы обязаны включить архивирование логов в Postgres.
Мы можем это сделать явным образом, вызывая какую-то archive command. Но мы должны выбрать при этом какой-то адекватный тайм-аут. Т. е. если у нас нет большой активности, то Postgres переключается на следующий WAL через какой-то тайм-аут. По умолчанию, по-моему, archive_timeout установлен в ноль, т. е. он будет на этом файле ждать до тех пор, пока он не заполнится. И какие-то адекватные значения, например, 5 минут или 30 минут, они должны быть выбраны совместно с менеджментом компании.
Есть еще вариант запустить pg_receivewal на какой-то другой ноде. Это позволяет получить наш поток данных и наш архив логов, не загружая мастер. Это дает некоторые преимущества по сравнению с archive_command.
Восстановление из бэкапа, если кто-то удалил данные, занимает достаточно долгое время. Если мы разговариваем о базах, которые размером в терабайты, то это могут быть часы или десятки часов.
Но, к счастью, в Postgres есть способ это обойти. Мы можем запустить реплику, которая отстает от мастера на какой-то промежуток времени. Например, на час, на два, на три. Мы в Zalando в дата-центре держим одну реплику, которая отстает на час. Соответственно, если кто-то удалил важные данные, у нас есть час, чтобы вытащить их из реплики.
RTO тоже очень важно. Если, например, вы можете себе позволить RTO больше, чем 15 минут, то автоматический failover вам, может быть, даже не нужен. Т. е. достаточно иметь какую-то систему мониторинга, которая оповестит DBA. И он разберется, что происходит. Например, это действительно мастер умер или он не отвечает из-за высокой нагрузки. И в случае, если действительно что-то не так, DBA произведет переключение на реплику.
И синхронная репликация очень важна, если вы не можете себе позволить потерять данные в результате failover.

Люди очень часто хотят какой-то автоматический failover, который отрабатывает за доли секунды или максимум за секунду. В принципе, наверное, это возможно. Но такое решение будет достаточно дорогим и сложным. И самое интересное, что сложность такой системы очень часто влияет обратно пропорционально на availability, на нашу доступность.
Всегда должен быть какой-то баланс между тем, как быстро мы определяем – это наш мастер не досткпен или, может быть, с сетью что-то произошло. И, соответственно, мы хотим избежать каких-либо ошибочных переключений.

Высокая доступность и аварийное восстановление не могут существовать отдельно друг друга. И очень часто аварийное восстановление включает в себя высокую доступность, т. е. какое-то решение для высокой доступности. В первую очередь вы всегда должны подумать про RPO и RTO.

Как правильно делать автоматическое переключение?

Очень часто люди ко мне обращаются: «А давайте возьмем мультимастер и у нас не будет никаких проблем. Мы можем писать на любую ноду. И если одна из них выходит из строя, то мы продолжаем работать с другой. Все хорошо».
Какие у нас есть решения для Postgres? У нас есть PostgreSQL XC/XL. Это достаточно честный мультимастер, но там есть единая точка отказа – global transaction manager. И тем самым мы просто перемещаем нашу проблему из одной точки в другую. Нам нужно будет все равно придумывать какую-то высокую доступность для global transaction manager.
BDR основан на логической репликации. И есть какой-то способ разрешения конфликтов. Если подумать про разрешение конфликтов, то на самом деле – это получается eventual consistency. Если одни и те же данные на разных нодах перезаписываются, мы не можем гарантировать какой-то определенный порядок. Это будет работать только так, как настроили. Например, тот, кто по времени был чуть-чуть впереди, выиграет. Или еще по каким-то айдишникам.
Eventual consistency – это к сожалению не всегда что-то приемлемое. Зато у этого решения есть огромное преимущество. Оно будет работать в географически распределенных системах. Т. е. у вас может быть один сервер в Европе, другой в Америке, третий где-то в Азии, четвертый в Австралии.
Есть еще решение от Postgres Pro. Это более-менее честный мультимастер. Какие недостатки? Он за деньги – это раз. И два – это то, что он рассчитан на то, чтобы работать в одной сети. Т. е. между нодами latency должна быть достаточно маленькая. Но, в принципе, судя по описанию, это честный мультимастер. Если вы можете себе это позволить, то, наверное, имеет смысл потестировать и, может быть, купить.

Какие свойства у хорошего решения для высокой доступности?
Во-первых, должен быть quorum. Quorum очень важен. Он позволяет нам различать проблемы падения сервера от сетевых проблем. Т. е. если не работает Google, то вы обращаетесь к своему соседу и спрашиваете: «А у вас тоже Google не работает?». Он говорит: «Да, не работает». Что это означает? Либо что-то с Google, что мало вероятно, либо вы оказались в сети, которая отрезана от интернета. И quorum отвечает за разрешение таких ситуаций.
Вторая вещь, которая необходима, — это fencing. Если мы хотим переключить какую-то реплику в новом мастер, то мы должны убедиться, что старый мастер абсолютно не доступен. И, как правило, люди еще хотят сделать STONITH (Shoot The Other Node In The Head) для старого мастера, т. е. выполнить какой-то скрипт, который его добьет, если он живой и шевелится.
Есть несколько способов это сделать. Можно подключиться на какой-то switch и отрубить этот порт. Можно реально отрубить электричество у данной конкретной ноды. Можно еще что-нибудь придумать.
И третий важный компонент высокодоступных систем – это watchdog. Если наша система высокой доступности, которая присматривает за Postgres, вдруг упала, что тоже может случится, потому что в любом софте есть баги, то эта нода не должна продолжать работать как мастер.
Есть такая замечательная вещь как Linux watchdog, например. И если он не получает пинги, то через какой-то определенный промежуток времени, то он просто перезагрузит ноду, тем самым не даст ей продолжать работать как мастер и обеспечит отсутствие split-brain.

Почему quorum, fencing, watchdog важны? Есть примеры. Я уже приводил такие примеры на презентациях. Но я нашел одну реальную имплементацию, которая доступна на GitHub.

https://github.com/MasahikoSawada/pg_keeper
Как люди обычно делают? Мы хотим все сделать просто, поэтому мы напишем какой-то простой скрипт, запустим его на slave, он будет пинговать мастер. Если мастер недоступен, то мы запромоутим slave.
Что происходит на деле? У нас происходит network split, т. е. одна нода не видит другую. Промоутим slave в мастер. И получаем два мастера – split-brain.
Как я говорил, есть пример. Эта утилита сделана Masahiko Sawada. Пожалуйста, не пользуйтесь.

Как можно сделать лучше? Давайте запустим какую-то третью ноду, которая будет мониторить и primary, и standby, и принимать решения о том, что делать.
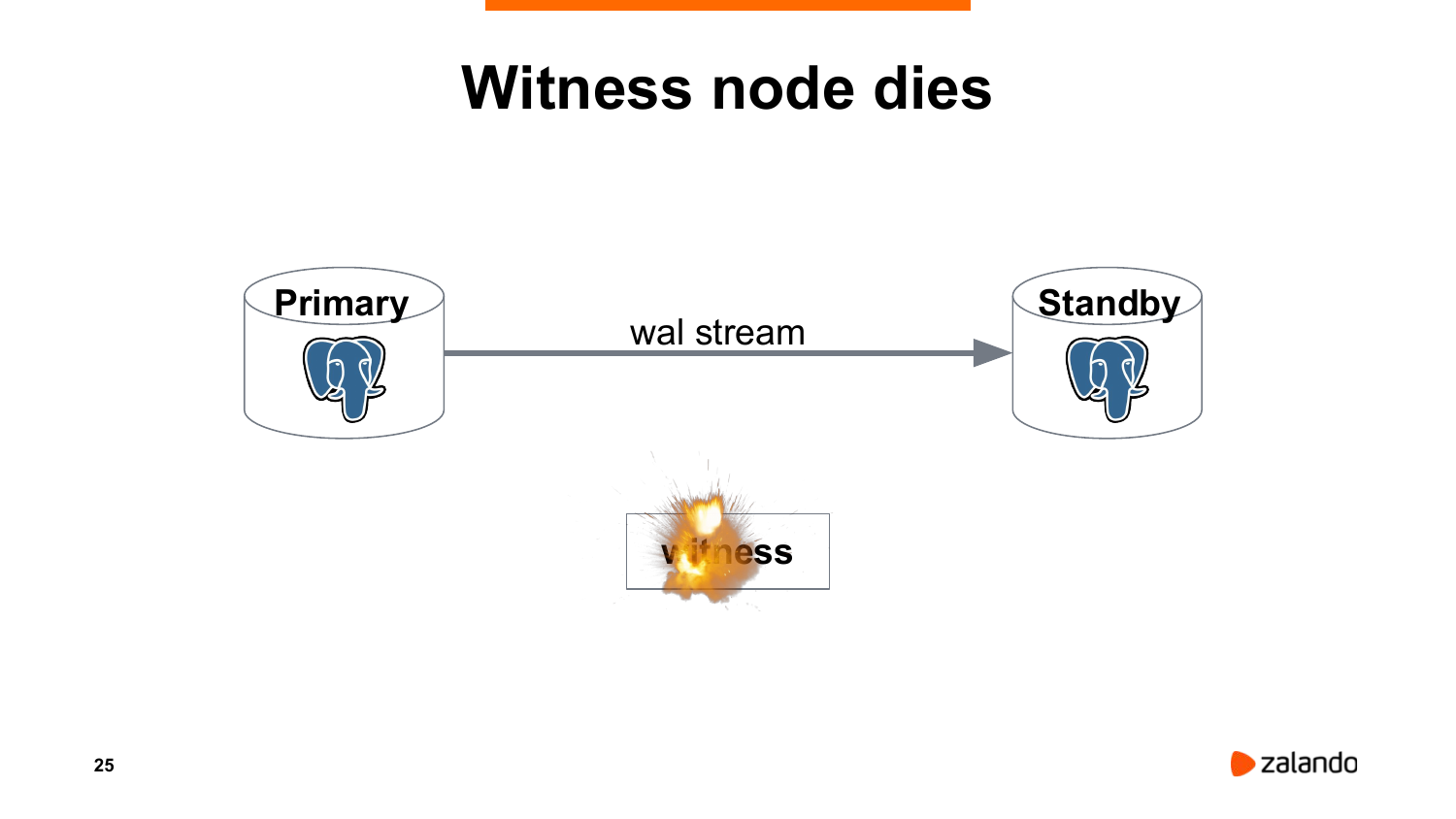
Очевидная проблема в том, что такая нода – это единая точка отказа. Если она умерла, у нас никакой высокой доступности нет. Но это еще не так страшно, потому что и мастер, и реплика продолжают работать как ни в чем не бывало.

Другая проблема в том, что может произойти какой-то network split, нода будет видеть только standby. Мастер для нее будет не доступен.

И промоутим standby. Т. е. fencing в такой ситуации должен быть обязателен. Но, к сожалению, иногда, чтобы его корректно имплементировать, вам нужно подумать о каком-то втором сетевом канале, что не всегда возможно.

Правильным решением будет использовать какую-то систему, которая опирается на quorum. Quorum нам гарантирует, что, если мы можем писать данные в нашу систему, например, Etcd, то мы находимся в части сети, которую все остальные видят. И только в случае этого мы можем работать как мастер. По такому принципу работает Patroni. Patroni периодически пингует Etcd, что он лидер (мастер), что он все еще здесь и доступен.
Если таких пингов не приходит, то ключ лидера пропадёт из Etcd, standby узнают о том, что у нас лидера нет и начинают выборы.

Я расскажу три интересные истории.

https://gocardless.com/blog/incident-review-api-and-dashboard-outage-on-10th-october/
Первая – есть организация, которая занимается банковскими платежами, банковскими переводами. Она называется GoCardless. Они построили свою систему высокой доступности на Corosync + Pacemaker. В принципе, все хорошо, все правильно.
Pacemaker обеспечивает quorum. Он умеет переключать виртуальные IP для того, чтобы подключаться к мастеру, он умеет корректно работать с watchdog. Все, казалось бы, хорошо.

Но что произошло на практике? На мастере вышел из строя RAID-контроллер. Он начал выдавать ошибки, но продолжал работать. Что решили сделать инженеры? Они подумали, давайте мы перезагрузим(выключим) мастер, и Pacemaker должен отработать, т. е. переключить мастера на ноду, которая является синхронной.
К несчастью, в момент, когда проверялось состояние этой синхронной ноды, один из postgres’овых процессов закрэшился. И как результат начался crash recovery, подконнектиться туда было нельзя, и автоматический failover не произошел.
Ребята потратили полтора часа, пытаясь запромоутиться с помощью Pacemaker. В конце концов, они просто отключили Pacemaker и выполнили переключение вручную.
Общее время инцидента составило практически два часа.

Какие отсюда выводы? Чему мы отсюда должны научиться?
Любые системы, особенно те, которые занимаются высокой доступностью, очень сложные. В некотором смысле они похожи на автопилот. Автопилот может управлять гигантским лайнером. Например, Airbus A380. Но автопилот тоже может сломаться. Он может получать какие-то некорректные данные, принимать некорректные решения.
Вы должны знать, как работает postgres’овая репликация, как строить реплики, как переключаться. Вы должны уметь летать на обычном штурвале.
И если вы начинаете использовать какую-то новую систему, то поднимаете ее в тестовом окружении, попытайтесь сломать. Попытайтесь сломать различные компоненты, посмотрите, что будет произойдёт чтобы быть готовыми. Тренируйтесь.

https://github.blog/2018-10-30-oct21-post-incident-analysis/
Еще один инцидент. Он произошел не очень давно. И произошел с GitHub, который Postgres не использует, но отсюда тоже можно поучиться интересным вещам.
У GitHub есть два дата-центра. Один находится в восточной части Северной Америки, другой в западной части Северной Америки. Мастер находится в восточной. Реплики находятся в восточной и в западной части. Но проблема в том, что приложения, которые работают с этой базой, они несимметричные. Например, Jobs и GitHub.com работают только в восточном ДЦ. Latency между двумя дата-центрами составляет 60 миллисекунд.

Что произошло? Были запланированы технические работы в сети. И в результате сеть пропала на насколько секунд. Система автоматического переключения решила, что восточный ДЦ не доступен и сделала переключение на запад.
Но приложения Jobs и GitHub.com начали работать с мастером, который теперь находится на западе, прибавляя к общему времени ответа 60 миллисекунд. Это было неприемлемо долго. Все начало тормозить. К сожалению, быстрое переключение назад было невозможно, потому что часть данных с востока на запад не были реплицированы (буквально несколько секунд нереплицированных данных).
Единственное, что можно было сделать, это перестроить все реплики на востоке и переключиться вручную. Итого, заняло сутки, чтобы восстановить сервис. Это очень долго.

Чему мы можем поучиться отсюда? Failover между географически распределенными регионами может быть не всегда желательным. Если вы закладываетесь на такой failover, то подумайте о том, чтобы все ресурсы были, как минимум, симметричны.
И второй важный вывод. Pg_rewind очень важен. И в MySQL, к сожалению, подобной технологии нет. С Postgres мы могли бы просто откатиться на эти несколько секунд назад и быстро переключиться с запада на восток, не перестраивая реплики.

https://about.gitlab.com/blog/2017/02/10/postmortem-of-database-outage-of-january-31/
И последний пример, который тоже очень интересный. Он произошел чуть больше двух лет назад с GitLab. У них не было системы автоматического переключения. Обычная система из мастера и реплики.
В какой-то момент на мастере произошел гигантский апдейт, и реплика начала отставать. Они не использовали слоты репликации. И в результате WAL-сегменты на мастере, которые были необходимы для реплики, были удалены.
Дежурный инженер начал перестраивать реплику с помощью pg_basebackup. Он запускает pg_basebackup, ничего не происходит. Он жмет Ctrl+C, подчищает PGDATA, запускает еще раз – ничего не происходит.
В чем проблема? По умолчанию pg_basebackup делает checkpoint spread, т. е. он ждет, когда произойдет checkpoint. И если в опциях не включить verbose mode, то мы не видим чем занимается pg_basebackup.
В результате нескольких попыток инженер случайно удаляет дата-директорию на мастере.
Что делать в такой ситуации? Конечно же, они умные ребята, у них есть бэкапы. Есть три вида бэкапов.
Pg_dump, к сожалению, сконфигурирован запускаться раз в сутки ночью. И, к сожалению, не работал, потому что он запускался c другого сервера. Использовалась какая-то хитрая система, которая подключалась к локально работающему Postgres и пыталась понять, какой версии у нас сервер и определить, какую версию pg_dump надо использовать.
Если на сервере бекапов не работал Postgres, то она использовала самую младшую версию pg_dump. Возник конфликт интересов. Настоящий сервер работал на 9.5, pg_dump использовался 9.2 и отказывался работать с 9.5. Т. е. дампы пустые, а ошибки никто не мониторил.
Второй тип бэкапов – это дисковые снапшоты Microsoft Azure. Они для серверов баз данных были отключены, потому что кто-то потестировал их и понял, что скорость восстановления из снапшотов очень медленная и смысла их использовать нет.
Третий вид бэкапа – снапшоты LVM, тоже выполнялись раз в сутки. К счастью, снапшоты периодически тестировались на staging. И только в результате того, что они периодически их разворачивали – это был единственный вид бэкапа, который работал. Но не забывайте, что бэкапы делались всего раз в сутки.
И здесь им повезло. Один из инженеров за 6 часов до инцидента сделал еще один снапшот. Т. е. инцидент произошел ближе к полуночи, когда обычно бэкап отрабатывает. Итого они могли потерять практически 24 часа данных. Но, к счастью, снапшот 6-ти часовой давности их в некотором смысле спас.

Чему мы отсюда должны поучиться?
RPO и RTO очень важны, и должны выбираться адекватно к вашему бизнесу.
Очевидно, что снапшоты или какие-то бэкапы, которые делаются раз в сутки, дают RPO 24 часа, а это неприемлемо.
Репликация не является бекапом и не поможет восстановить данные. Потеряли реплику и все, до свидания.
Еще очень важная вещь, которую хотелось бы отменить. Инженер использовал Runbooks. У них было задокументировано, что делать в какой-то ситуации. Пропала реплика – используйте pg_basebackup для того, чтобы ее реинициализировать.
Но, к сожалению, они не делали периодические тренировки. Если бы инженер хотя бы раз в полгода запускал pg_basebackup вручную и смотрел, как он себя ведет, он бы знал про эту особенность. Но очевидно, что это не происходило. Вы должны периодически надо прогонять сценарий нашего disaster.
И мы мы должны мониторить, что бэкапы снимаются. И мы обязательно должны пробовать их развернуть. И нужно мониторить, что они разворачиваются и что они нормальные.

Теперь про ряд проблем, которые высокая доступность не сможет решить.

Высокая доступность в некотором смысле помогает мониторингу. Например, Patroni не запромоутит реплику, которая очень сильно отстает от мастера. Но система высокой доступности не будет мониторить логи постгреса. Она не будет мониторить загрузку CPU, т. е., в принципе, может, но не должна. Она не будет мониторить, сколько у вас свободного места для ваших данных, для ваших логов. Она не будет мониторить, что у вас автовакуумы работают и, что с checkpoints нет никаких проблем. Она не будет мониторить ничего из этого. Это не задачи системы высокой доступности.

Мониторинг очень важен. Если у вас есть правильно настроенный мониторинг, он может вам дать alert. И если RTO (на слайде ошибка: RTO, а не RPO) позволяет, то вы можете не использовать систему высокой доступности, но мониторить обязаны. Вы должны мониторить все. И вашу систему высокой доступности, и Postgres, и бэкапы, и так далее. Мониторинга много не бывает.

Очень часто люди меня спрашивают: «Почему Patroni тут не поменяет postgres’овую конфигурацию?». В некотором смысле Patroni, например, позволяет прибить гвоздями max connections на мастере и реплике, чтобы они всегда были одинаковыми, иначе будут проблемы.
Но системы высокой доступности не оттюнят Linux, они не настроят huge pages, а также shared memory, semaphores, overcommit и т. д.
Patroni и другие системы не будут тюнить postgres’овую конфигурацию, т. е. shared_buffers, max_wal_size, checkpoint completion_target, random_page_cost и т. д. Не будут они этого делать. В принципе, можно научить, но они не должны.

И потихоньку мы завершаем доклад.
Всегда следует начинать с планирования аварийного восстановления. Вы должны определить ваши RPO и RTO. Они нужны и важны.

В зависимости от того, какой RTO, вам, может быть, и не нужно HA, если у вас, конечно, не десяток или сотен кластеров.
Не следует целится на availability, у которой семь девяток или восемь девяток. Вы это просто не потянете.
Пытайтесь построить то, что вам нужно, а не то, что вы бы хотели в теории.
И обязательно все тестируйте. Попытайтесь сломать, попытайтесь починить систему высокой доступности. Делайте бэкапы. И очень важно периодически прокатывать ваш disaster recovery план.
На это у меня все. Спасибо, что послушали! Надеюсь, вам будет это полезно.

Questions
Спасибо большое за презентацию. Презентация была на английском, я смог прочесть ее. Это очень интересная тема для обсуждения, потому что мы должны слышать бизнес. Мы с таким сталкиваемся в Индонезии очень часто. Я согласен с вами, что HA нужно определять. Но я не понял, как добавлять аварийное восстановление в высокую доступность. Высокая доступность должна быть включена в бизнес-политике. Вы это написали. Т. е. disaster recovery – это не высокая доступность.
Аварийное восстановление не заменяет высокую доступность. Мы можем включить, но все зависит от клиентов, от того, что они хотят. Все правильно, можно найти примеры, когда вам не нужна высокая доступность или, когда вы вообще не думаете об аварийном восстановлении. Просто мы должны понимать, что они идут рука об руку. Но иногда аварийное восстановление включает в себя практики высокой доступности.
Да, у нас тоже есть такие конфигурации, когда аварийное восстановление включает в себя средства высокой доступности. Иногда вы обеспечиваете доступности шесть или семь девяток. И, мне кажется, что это слишком много, потому что здесь уже речь идет не об отказоустойчивости. А отказоустойчивость – это 100 % надежности.
Есть определение от IBM, которое указывает, что слишком много девяток обеспечат высокую доступность.
Вы сказали, что 99,99. Я бы добавил это в отказоустойчивую систему.
Да, но все зависит от того, как вы определяете. Нет никакого официального определения: у IBM одно количество девяток, у отказоустойчивых решений другое количество девяток. И сама формулировка определения высокой доступности разная у каждой компании, у каждого клиента. Все зависит от них самих. Мы просто должны убедиться в том, что вы можете перебросить данные с одного сервера на другой.
Да, но у нас компания гарантирует, что мы производим перебросы за 10 секунд.
Это хорошо, это здорово, но иногда вы можете столкнуться с ложными срабатываниями. На это тоже надо обращать внимание.
И еще один вопрос. Вы сказали, что потенциальная проблема – это скорость сетевого подключения. Здесь я не согласен, потому что нужно это учитывать в том же плане. Не в другом плане, а в том же плане. Потому что используется тот же физический сегмент сети. И это происходит при сетевых сплитах.
Но даже если у switch есть какая-то избыточность, он все равно может выйти из строя. Поэтому это тоже нужно учитывать.
Если одна нода не подключается к другой?
Тогда мы говорим о сетевом сплите.
Но если проблема с оборудованием, тогда, что будет, если мы будем использовать несколько switches?
Да, я думаю, мы можем об этом поговорить позже в кулуарах.
Александр, большое спасибо за доклад и за Patroni. Вы упомянули о том, что классно иметь реплику, отложенную на какое-то время, чтобы в случае косяка восстановиться. А Patroni каким образом позволяет это сделать?
В Patroni можно указать любые параметры для recovery.conf и он их туда запишет. Если вы укажете в конфигурации recovery_min_apply_delay, то он его туда пропишет. И в Patroni с помощью тэгов можно контролировать – отключить для такой реплики load balancing среди реплик, потому что вы, наверное, не хотите читать stale данные. Плюс можно отключить автоматический failover для данной конкретной реплики.
Понятно, спасибо!
Добрый день! Вопрос простой. Сколько, на ваш взгляд, серверов нужно, чтобы построить хороший HA? Я понимаю, что двух недостаточно, потому что нужен witness. Это уже три. Witness нужно резервировать – это уже четыре. Т. е. минимальное количество?
В принципе, трех достаточно. Если у нас есть три сервера, то мы можем определить quorum. Quorum из трех – это два. Если один из трех серверов выходит из строя, у нас остаются два. Если они друг друга видят, то все хорошо. И у нас есть время для того, чтобы заменить третий сервер. В принципе, три. Причем на третьем сервере необязательно даже запускать Postgres. Т. е. там нужно запустить что-то, что будет являться частью quorum.
Спасибо!
Спасибо за доклад! Вы в начале презентации сказали, что у вас Zalando, много очень своих кластеров, но постепенно вы переходите в Amazon. Получается, что цена в Amazon на высокую доступность меньше, чем вы это делаете сами?*
Нет, не совсем так. Если иметь свои сервера в дата-центре – это обходится дешевле. Но с дата-центром есть свои проблемы. Он недостаточно эластичен. Т. е. у нас есть контракт, например, на сервер на три года. И даже если мы его не используем, то мы вынуждены за него платить. Это, конечно, сейчас редко бывает, но тем не менее. В Amazon мы можем получить новые сервера в течение нескольких минут. Это огромный плюс. Это ускоряет разработку, это ускоряет все на свете. Но за это приходится платить. Т. е. по моим прикидкам Amazon обходится дороже раза в два.
В определенный момент наши инженеры, которые занимаются дата-центром просто не успевали устанавливать новые сервера, настолько быстро новые проекты клепали. Проект есть, а деплоить его некуда.
Здравствуйте! Спасибо за доклад. Если можно, то вопрос про Patroni? Он, может быть, не очень по теме.
Ничего страшного.
Планируется ли интеграция метрик, которые сейчас отдает Patroni по слэш Patroni в json, в формат Prometheus или нет?
В принципе, Patroni – это открытый проект. Если вы хотите, то вы можете имплементировать, сделать pull request. Я с удовольствием его просмотрю и смержу.
Спасибо!
Там даже ticket, по-моему, на этот счет был открыт.
Вопросов больше нет, всем спасибо!


{kind=link}