
Привет, Хабр.
Сегодня я хочу рассказать про своё детище - платформу "qSOA.cloud", которая позволяет запускать приложения построенные по SOA в облаке по разумной цене. Например, стоимость размещения простого HTTP API сервиса, который обрабатывает ~400 000 запросов в сутки, может составлять от 3$/месяц. При этом всё устроено удобно и просто в "одном окне", так, что разработчикам сервисов не нужно думать об инфраструктурной обвязке, а нужно просто реализовывать бизнес логику. Логи, метрики, трейсинг, дискавери, рутинг, ... встроены в платформу, а сервис просто выполняет функцию, нужную бизнесу.
В SOA я очень глубоко погрузился 5 лет назад в одной E-Commerce компании из Юго-Восточной Азии. Строя там платформу, которая обрабатывает десятки тысяч RPS, мы набили много "шишек", которые были учтены в qSOA.cloud. Сейчас на платформе поддерживаются только сервисы написанные на Go, но в дальнейшем появится поддержка и других ЯП.
Под катом я коротко расскажу как это устроено и покажу как легко и быстро написать свой сервис, запустить его и какие доступны инструменты для анализа.
Как это устроено (кратко)
Сервис - это приложение, принимающее запросы по HTTP или gRPC. Между собой сервисы общаются по gRPC, но не напрямую, а через специальные сервисы - Runner'ы. Каждый физический сервер имеет 1 запущенный Runner, который запускает сервисы и проксирует трафик через себя, за счёт чего вся инфраструктурная логика хранится в нём. Runner отвечает за discovery, routing, так как знает какие он сервисы запустил и в каком они состоянии и знает, что запущено на других серверах, он собирает и отправляет в хранилище логи, основные метрики, кастомные метрики сервисов, ... Между собой Runner'ы общаются по gRPC с TLS. Схематично это выглядит так:
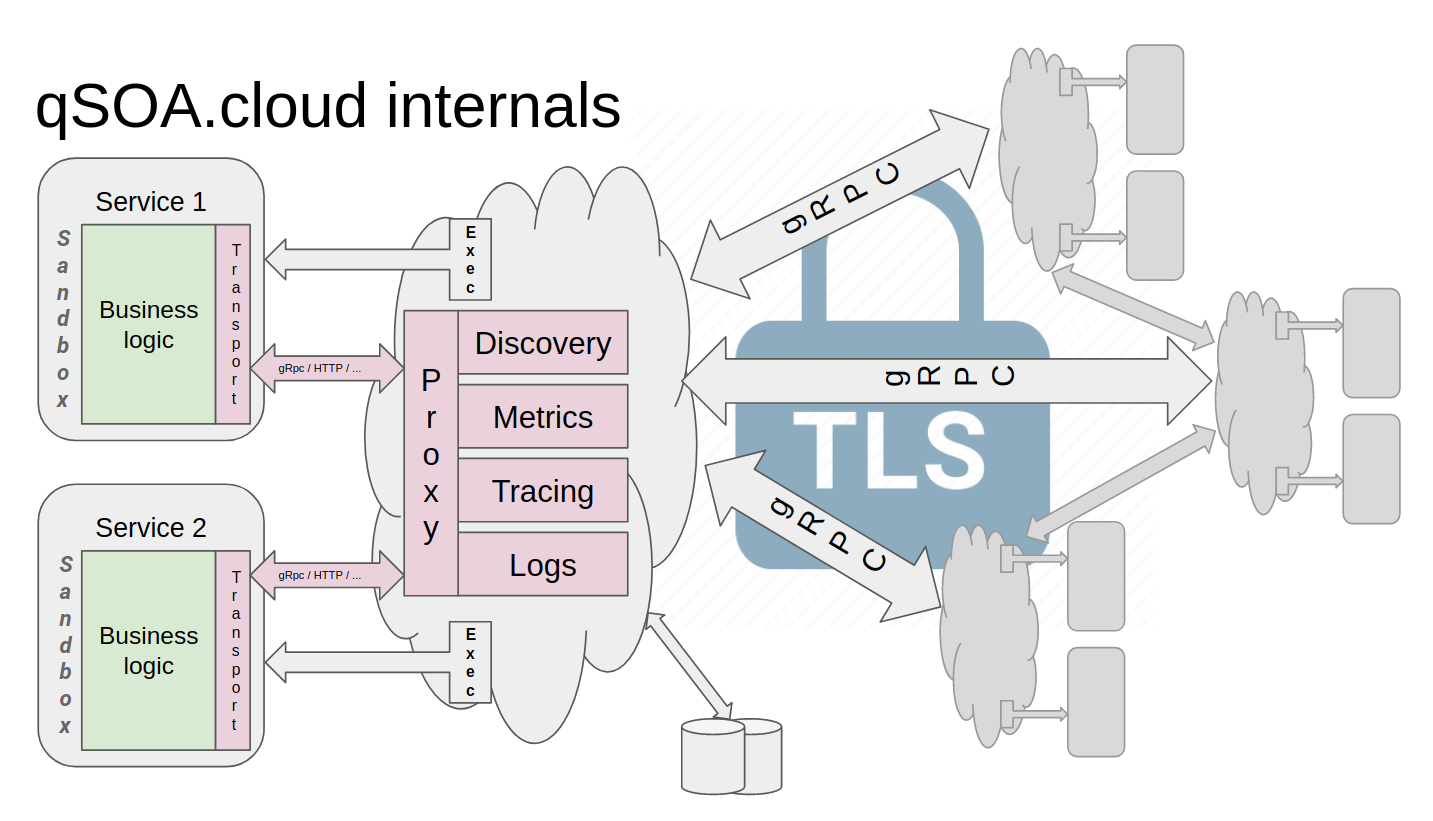
Благодаря тому, что инфраструктурная обвязка находится снаружи сервисов, изменение платформы происходит без пересборки всех сервисов, запущенных в ней. Как показала практика, организовать обновление инфраструктурных библиотек даже внутри одной компании - это очень большая проблема, продуктовый бэклог практически всегда побеждает.
Как устроены разные части платформы, я расскажу в последующих статьях, иначе эта никогда не закончится?, а пока перехожу к тому, как написать сервис и запустить его.
Как написать сервис
Для примера возьмём задачу:
Нужен сервис, который будет принимать по HTTP 2 числа, складывать их и возвращать пользователю сумму, при этом параметры и результат должен логироваться в БД. Чтобы было интереснее, то предположим, что сумму он считать сам не умеет и ему нужен другой сервис, который будет по gRPC принимать 2 числа и возвращать их сумму.
Чтобы немного сократить повествование, я объединю оба сервиса в один и он будет вызывать сам себя по gRPC, так, как он вызывал бы другой сервис. Также я не буду рассказывать про имплементацию HTTP и gRPC хендлеров, они тривиальны, код можно посмотреть на GitHub. Всё самое интересное в main.go, код с подробными комментариями ниже:
package main import ( "database/sql" "log" // Очень простая сервисная обвязка "gopkg.qsoa.cloud/service" // Сервис предоставляет gRPC "gopkg.qsoa.cloud/service/qgrpc" // Сервис предоставляет HTTP "gopkg.qsoa.cloud/service/qhttp" // Драйвер облачного MySQL _ "gopkg.qsoa.cloud/service/qmysql" // Имплементация хендлеров "testservice/grpc" "testservice/grpc/pb" "testservice/http" ) func main() { // Подготавливаем gRPC клиент для вызова самого себя. // Обратите внимание на протокол qcloud:// и / в конце. conn, err := qgrpc.Dial("qcloud://" + service.GetService() + "/") if err != nil { log.Fatalf("Cannot dial grpc: %v", err) } defer conn.Close() grpcClient := pb.NewTestClient(conn) // Подготавливам подключение к MySQL. // Не нужен DSN, только имя БД, драйвер qmysql всё сделает db, err := sql.Open("qmysql", "example_db") if err != nil { log.Fatalf("Cannot open mysql database: %v", err) } defer db.Close() // Регистрируем HTTP хендлер qhttp.Handle("/", http.New(grpcClient, db)) // Регистрируем gRPC сервис pb.RegisterTestServer(qgrpc.GetServer(), grpc.Server{}) // Заупскаем service.Run() }
Вот и всё, отправляем в Git и запускаем в облаке.
Проекты, окружения и сервисы
Перед тем, как запустить сервис в qSOA.cloud, надо создать проект. Проект объединяет в себе набор сервисов (сервисы из разных проектов не видят друг друга) и набор окружений. Окружения нужны для того, чтобы иметь несколько наборов сервисов с разными версиями. Например есть стабильное окружение - Production, в нём протестированные версии сервисов, к которым обращаются реальные пользователи, есть тестовое окружение, куда выкладываются готовые к тестированию версии сервиса и в которое ходят тестировщики, и так далее. Структурно это выглядит так:

Сервисы из разных окружений не видят друг друга. Внутри одного окружения одновременно могут быть запущены разные версии одного сервиса.
Из git в облако
Для примера я создал проект Example с ID example. Теперь в нём нужно создать новый сервис:
Если код лежит в приватном репозитории, то адрес можно передать в формате https://<login>:<password>@<domain>/<repo>.
После этого его нужно скомпилировать:
Для этого нужно кликнуть по иконке молотка справа от версии. Версии могут быть в любом формате, задаются тегами в git. Процесс сборки и ошибки можно посмотреть в логе:
В случае наличия GoDep.* файлов будет выполнено go dep ensure.
После успешной сборки сервис готов к запуску, для этого нужно создать окружение, например Production. После создания окружения надо кликнуть по кнопке Deploy:
В появившемся меню выбрать сервис и нужную версию, кликнуть в окне на кнопку Deploy и через короткое время сервис будет запущен:
Для каждого сервиса можно и нужно запускать несколько копий (instance'ов). Они будут распределяться по разным физическим серверам и, в дальнейшем, ДЦ для повышения отказоустойчивости. Но при этом балансировка запросов будет происходит к оптимальным instance'ам.
Каждый instance в интерфейсе представлен набором основных метрик, обновляющихся практически в реальном времени. Среди них количество запросов, количество успешных/ошибочных/прочих ответов, среднее время ответа, нагрузка на CPU, потребляемая память, ...
Доступ из Internet
Сейчас запущенный сервис живёт внутри облака и может обращаться сам к себе, но из внешнего мира к нему не добраться. Для открытия доступа надо создать шлюз. При создании проекта выделяется домен вида <project_id>.qsoa.cloud, можно использовать его или его поддомены для организации доступа к сервису:
При создании шлюза просто выбираете окружение, сервис и пишите доменное имя. Домен может быть своим, не обязательно в зоне <project_id>.qsoa.cloud.
После создания можно открыть https://example.qsoa.cloud, сертификат выпишется и будет перевыпускаться автоматически через Let's Encrypt. Это работает и для кастомных доменов:
Базы данных
По условиям задачи, сервис должен логировать в БД аргументы с суммой. Создадим БД с нужным именем:
Базы данных можно использовать в нескольких окружениях, поэтому при создании нужно выбрать в каких из них она будет доступна, в нашем случае только в Production.
В платформу встроен простейший UI для управления БД, сейчас он пригодится для создания таблички:
Его также можно использовать для вывода данных:
Внутри имена баз данных не совпадают с запрошенными, поэтому имя БД в выводе странное.
Трейсинг и логи
Теперь сервис полностью готов к эксплуатации. Если отправить запрос на https://example.qsoa.cloud/?n1=10&n2=20, то получите ответ:
В заголовках ответа можно найти x-span-id и x-trace-id, используя их в интерфейсе платформы можно проследить весь путь, который прошли данные от первого запроса к шлюзу через все внутренние сервисы и обратно.
Базовый интерфейс предоставляет список span'ов:
В таком виде он сейчас полезен для, например, поиска медленных запросов. Фильтр поддерживает сложные выражения, включая скобки, подробности можно посмотреть кликнув на знак ?
Для анализа одного конкретного трейса есть древовидное представление:
В нём, помимо стандартных полей span'ов, можно увидеть их иерархию и какое влияние оказывает каждый вложенный span на длительность родителя (тонкая жёлтая линия).
Используя OpenTracing разработчики сервисов могут добавлять свои span'ы и отслеживать важные для бизнеса вещи.
Помимо трейсинга, на соседней вкладке можно посмотреть логи, причём как и те, что пришли из span'ов, так и те, что просто были выведены в STDOUT/STDERR. В данный момент сервис ничего не выводит, поэтому там пусто:
Метрики
Для любого запущенного сервиса собираются базовые метрики по запросам/ответам и производительности:
Counters:
Counters:
grpc_messages_in [from, env, service, instance, runner]
grpc_messages_out [from, env, service, instance, runner]
grpc_streams_close [from, env, service, instance, runner]
grpc_streams_errors [from, env, service, instance, runner]
grpc_streams_open [from, env, service, instance, runner]
grpc_out_messages_in [to, env, service, instance, runner]
grpc_out_messages_out [to, env, service, instance, runner]
grpc_out_streams_close [to, env, service, instance, runner]
grpc_out_streams_errors [to, env, service, instance, runner]
grpc_out_streams_open [to, env, service, instance, runner]
http_requests [env, service, instance, runner]
http_responses [code, env, service, instance, runner]
hw_cpu [type, env, service, instance, runner]
hw_mem [env, service, instance, runner]
Summaries:
grpc_messages_in_sz [from, service, instance, runner]
grpc_messages_out_sz [from, service, instance, runner]
grpc_streams_dur [from, service, instance, runner]
grpc_out_messages_in_sz [to, service, instance, runner]
grpc_out_messages_out_sz [to, service, instance, runner]
grpc_out_streams_dur [to, service, instance, runner]
http_requests_sz [service, instance, runner]
http_responses_dur [code, service, instance, runner]
http_responses_sz [code, service, instance, runner]
Посмотреть их можно на встроенных дашбордах:
Набор дашбордов можно редактировать, пока без редактора, в виде JSON:
Помимо стандартных метрик, можно делать свои, используя клиента Prometheus, они также будут доступны для построения графиков по префиксу prometheus вместо internal.
Язык запросов поддерживает сложные выражения, плейсхолдеры и будет развиваться в будущем.
Конец
Вот и всё, с помощью простых шагов сервис написан, запущен, для него доступны инструменты анализа, при этом разработчик не задумывался о том как настроть Nginx, Docker, Kubernetes, Prometheus, Grafana, ..., или где найти DevOps'а, который это сделает.
История и текущее состояние проекта
Проектом я начал заниматься больше года назад в качестве pet'а. Сейчас его можно классифицировать как MVP, в нём работают несколько моих сервисов, Текущее состояние - хороший "скелет", на который нужно наращивать "тело", но для понимания в какую сторону двигаться мне нужны внешние живые проекты. Есть большой бэклог, из ближайших планов в нём:
Инфраструктура:
Хостинг для статических файлов (CDN), сейчас их приходится встраивать в сервис, например с помощью генератора.
Новые ЯП для сервисов.
Новые БД: Postgres, Clickhouse, Mongo, …
Мониторинги и алерты.
CI/CD
Local runner: возможность запускать сервисы на локальной машине, но при этом имеющие доступ к определённому окружению в облаке и обратно. Будет удобно для разработки.
Собственные NS с редактором
...
Возможности интерфейса
Диаграмма потоков данных между сервисами в реальном времени (позволяет понимать какие сервисы какие вызывают, где нагрузка, задержки, кто является корнем проблем в случае ошибок, ...)
OpenAPI UI client: возможность вызывать методы конкретных инстансов с приятным интерфейсом
gRPC UI client: аналогичный OpenAPI клиент, но для gRPC, для определения структур данных использует рефлексию.
Инструмент для поиска корреляций на графиках: можно взять какой-то период на графике где произошло что-то плохое и найти другие метрики, где в этот момент происходило что-то похожее, причём не важно, были ли корреляция прямая или обратная. Это плзволяет легче определить корень проблем.
Генератор сервисов из *.proto файлов: по proto-описанию создаётся сервис, в котором нужно только реализовать gRPC методы.
...
Сервисы для сервисов:
Distributed locks
Event bus
Distributed cache
Cloud SQL
...

